Chapter 2 Designing a CPU
advertisement

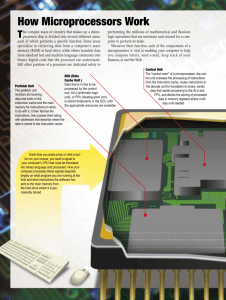
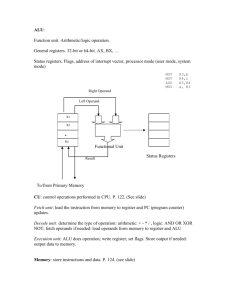
Chapter 2 Designing a CPU 2.1 Hardware and Software Processing Environment We have learned that computers from desktop PCs to mobile phones, game consoles and iPods contain some form of processor, some memory and connections to various input and output devices. Also we have seen that there are various classes of processor, some are general purpose programmable engines (such as the various Intel and AMD families), others are programmable, but specialised, such as Texas Digital Signal Processing (DSP) processors, and others are application-specific (ASICS), which are embedded into dedicated products such as calculators, engine-management systems or microwave cookers, delivering application specific functionality; they are hardwired and not malleable via programming In this chapter, we are interested in the general purpose programmable processor like the one probably now at work in your PC. We shall discover which building-blocks are needed to construct a simple, although meaningful Central Processing Unit (CPU), and how these blocks are combined in a particular architecture. The details of the inside working of our CPU are discussed, and you will be presented with a Java simulator of our CPU to investigate for yourself how it works, you’ll even write some assembler programs. As its name suggests, the CPU lies at the centre of other components such as program memory, data memory and input-output devices. Data memory holds numbers, words, whole text documents, music, images or any other information which can be distilled into bits and bytes as we have already seen. The program memory holds a list of atomic instructions which the CPU fetches, then executes. Segments of code and data memory are often situated on the CPU chip, where they are referred to as code (program) cache and data cache. These are highlighted in Fig.1 which shows the layout of the Intel?? CPU die. You should know that the actual size of this die is ?? and it contains over 3 million transistors! We shall discover how the functional blocks outlined on this chip can work together to provide the most fundamental level of processing which ultimately supports our “User Application” such as an Excel spreadsheet or a computer game such as Unreal Tournament 2004. Figure 1 Photograph of the Intel Pentium chip die, shown with an overlay of the main functional blocks. This chip contains 3.2 million transistors. Acknowledgement here. Let’s consider first how programs are both represented to the User and fundamentally in program memory, to be fed into the Central Processing Unit. As often in computing, it’s useful to consider a hierarchy of levels (see Fig.2). At the top of the hierarchy is found what you, the user, sees when you open up e.g., an Excel spreadsheet. There is a formula in cell B3 which adds the values of cells B2 and C3 together. This is how you write to “program” in Excel. But like most applications, Excel has been constructed out of a “High-Levellanguage” (HLL), such as “C” which you can think of as situated at a middle level. In this language, an addition is coded as the statement “w = x + y”. C is a high-level language, which means it cannot be fed directly into the CPU hardware and executed. Instead it must be compiled into the into a series of atomic or primitive instructions which the CPU hardware can execute; this is the bottom of our hierarchy shown in Fig,2. This fundamentallevel assembler program consists of some “mov” instructions, (we’ll see what they are shortly), and an “add” which is clearly where the addition takes place. Application (Excel) w=x+y; High-Level Language (e.g. “C”) mov ax,[x] mov bx,[y] add ax, bx mov [w],ax Code fed to CPU (assembler) Figure 2 The operation of addition shown at a number of levels. At the top, the computer user sets up an addition in the application Excel. The operation of addition is coded within excel in a High-Level language, such as “C”. The bottom this High-Level addition is coded as a number of atomic “mov” and “add” operations which are fed into the CPU hardware and executed. The chip layout shown in Fig.1 is now hopefully beginning to make sense. The code cache holds these primitive instructions which are fetched into the “execution unit”, (also known as the “arithmetic logic unit”, or “ALU”) where they are invoked. Data involved in the processing are stored in a separate area of memory known as the “data cache”. 2.2 A Minimalist CPU Architecture Let’s start designing our CPU which will be able to run our exemplar Excel addition. How do we add, and for that matter subtract, multiply and perform other arithmetic functions? How to we check to see if one number is greater than another, or negative (these are called “logical” operations)? Clearly we need an “Arithmetic Logic Unit” (ALU), containing electronic circuits to perform these tasks. The electronic-engineering symbol for an ALU is shown in Fig.3(a) where it is performing an addition. There are two important points concerning this ALU symbol to note here. First, data comes in at the top where there are two inputs (since we must add two numbers), and the result exits at the bottom through a single output. The routing of data through the entire CPU chip is called the “data path”, and consists of a complex engineered network of paths for data to follow. The second point to note is the signal arriving at the side of the ALU. This is a “control” signal which informs the inner ALU circuitry whether it should add or subtract (or perform some other operation). The routing of control signals is known as the “control path”. 3 0 5 3 5 8 add / sub 1 3 ALU 5 8 (a) (b) 4 MAR ALU 8 4 Data cache 0 Mov ax,[0] 4 mov bx,[1] 8 add ax,bx 12 mov [4],ax 3 5 3 (c) 5 8 4 8 MAR 8 IP Data cache Code cache IR ax bx MDR d) Code cache Data cache Figure 3. Steps in building a simple CPU: (a) shows the ALU adding two numbers, (b) the data cache which contains these numbers is added; the memory address register (MAR) points here to cell 4 which receives the result 8, (c) the code cache is now added which contains the program code; IP, the instruction pointer points to line 8 which contains the add instruction, (d) Registers ax and bx used in data movement and the MDR (memory data register) are shown added. Also the instruction register (IR) used to decode the program code. Where do all these inputs to the ALU come from? The data clearly originates in the data cache, but what about the control signal? This originates from the program code, which informs the ALU whether an add or a subtract (or other) operation must be performed, e.g., the line of code “add ax bx” could set a logic “1” on the add/subtract control input, while a “sub ax,bx” would put a logic “0” on this line. The ALU’s internal electronic circuits reads the control line state and effects the appropriate operation. It’s interesting to note that an ALU may be able to add more than just individual numbers. Intel architecture has been developed to add images (well, at least parts of images). This is known as the “MultiMedia Extension” or “MMX architecture. Clearly an important response to market demand for powerful multi-media applications. Let’s now take our basic ALU and add some data cache and then program cache blocks. First, the data cache. This is connected to the ALU as shown in Fig.3(b). In the example shown, two numbers are being moved from data cache into the ALU which then forms the sum, and this in turn is written back into data cache. The important point is that ALU and data cache need to communicate, and this communication needs to be coordinated in time. Also, the correct data has to be fetched, and since data is located in a cell with an address, then the data cache circuits have to be provided with the correct address to retrieve the correct data. This address is stored in the “Memory Address Register” (MAR). Registers are small high-speed memory cells with dedicated functions located on the CPU; the MAR is dedicated to pointing to the correct cell within data cache to retrieve or store data. Now let’s add in the program cache (see Fig. 3(c)). This contains a list of atomic assembler instructions which will ultimately send those control signals we mentioned above to the ALU (and most other components) to actually execute our program. Assembler instructions are stored in a list and are fetched into the CPU internals one at a time, so there needs to be a pointer to the instruction currently being read in and processed, in other words the address of this instruction in code memory. This is the function of the “Instruction Pointer” (IP), which is stored in the IP register, just like the MAR, dedicated to this pointing function. Note there is a nice symmetry here, both code and data cache have associated address registers pointing to either the code or the data currently being accessed. Let’s dwell for a moment on these registers: Registers are very useful CPU components, a typical CPU will contain many registers. It’s useful to think of these as “parking places” where data can be stored temporarily as it moves through the CPU circuits. A register may hold the results of an intermediate calculation, or just store or “buffer” a data element while it is waiting for the following CPU component to become available. Two important registers “ax” and “bx” are located at the inputs to the ALU. In fact, when data is brought into the ALU, they are first loaded into registers “ax” and “bx”. These registers are available to the assembler programmer, e.g., they appear in the instruction “add ax,bx” seen above. The Intel x86 (aka “Pentium”) architecture contains a small number of registers such as “ax”, “bx”, “cx”, “dx”, “si”, “di”, etc. There are other registers in the CPU which are not available to the programmer. One such register is used to buffer data going in and out of the data memory. This is the “Memory Data Register” (MDR) whose purpose is to coordinate movement of data. The MAR, IP and IR (instruction register, which we shall discuss later) are other examples. Our minimalist CPU is almost complete, from the diagram in Fig.3(d) you can see how the components introduced above are connected together. These connections show the “datapath”, (how and where data is shunted around), the control signals are not explicitly shown. There is one more register shown here, the “Instruction Register” which we shall discuss at the end of this chapter. For the moment glance forwards to Fig.?? which shows a screenshot of the Java simulator you will use in the Activities presented at then end of this chapter and check out the location of the components introduced here. This CPU is named “SAM”, “Simple Although Meaningful”, it’s important to give a CPU an interesting name, to help with marketing, like “Pentium”, “Athlon”, “Itanium”, “SAM”. 2.3 The Instruction Set and its Function The lines of assembler code such as “add ax,bx” form part of the Instruction Set of the CPU, a coherent set of atomic instructions, which has been designed as an integrated whole to enable the CPU to perform useful high-level functions. The complete set of SAM’s instructions is shown in Table.1 We have designed SAM to implement a subset of Intel’s Pentium instructions, so as you experiment with the SAM simulator, you will also be learning how to program a real Intel Pentium in assembly language. Let’s take a couple of these instructions individually and see how they can be combined to implement a program which adds two numbers in data cache and stores the result back into data memory. Mnemonic mov mov add inc jmp dest ax , ax , ax , ax c src Operation bx [1] bx - moves the contents of register bx into register ax - moves the contents of memory address 1 into ax - adds the contents of bx to ax, result is put into ax - increases the contents of ax by 1 - go to the line of code at address c Table 1. SAM’s “Instruction Set” . Each line comprises the instruction mnemonic, and the destination and source of data to be processed. Intel’s convention places the destination before the source. Let’s continue with our example of adding two numbers. The assembler program which does this is listed in Fig.5. Let’s wee what we need to do: First we have to get the numbers (data) from memory into the registers ax and bx from where they will pass into the ALU. 0 4 8 12 mov ax,[1] mov bx,[2] add ax,bx mov [4], ax Figure 5. Simple assembler program to add two numbers located at data memory addresses 1 and 2, and to write the result back at data memory address 4. The numbers on the left are the addresses of the instructions in code memory. This is the purpose of the two instructions “mov ax,[1]” and “mov bx,[2]”. The first instruction mov ax,[1] moves data into ax, the second moves data into bx. This may be a little surprising, but Intel designed all their instructions so that the destination of the data follows after the name of the instruction, here “mov”. So in general our instructions will all have the form mnemonic destination, source Consider the instruction mov ax,[1]. What’s the source of the data being moved into ax? You may think that this instruction loads ax with the number 1, but that’s not the case. The square brackets indicate that we are loading from memory, and that the “1” is the address in memory where we’re loading the data from. Therefore, as shown in Fig.3(d), these two lines of code move the numbers 3 and 5 into registers ax and bx respectively. Now let’s turn to the instruction add ax,bx. This does just what it says, and will add 3 and 5 within the ALU circuitry. But where is the result 8 which comes out of the ALU deposited? Following Intel’s convention, the result is placed in the destination register, ax which will now contain 8. Of course, if we had written a line of code “add bx,ax”, we still would have still got 8 but this would have been written into bx. But we didn’t so the situation we now have is shown in Fig.3(c). Finally, to complete this example of addition we must move the result from ax back into memory, let’s say to address 4. Again following Intel’s convention, we need to use the instruction “mov [4],ax.” which moves the contents of register ax (the source) into memory address 4 (the destination). That’s about all you need to know to get a good feel of how to write assembler, more instructions will be introduced and explained in the Activities. Now we must move onto examine the details of this computational process. For the moment, it’s interesting to reflect on the general principle of this architecture: Numbers are loaded from memory into registers, operated upon and the result, dropped into a register, is then explicitly written back into memory. We can’t add numbers directly in memory without passing them through the registers. We’ll have more to say about this later. 2.4 The Fetch-Execute cycle When a program is running, there is potentially a large amount of data moving through the data-path, and some organisation of control is required to orchestrate a desired computational result. Think of your town centre, with traffic-lights, bus lanes and a sprinkling of one-way streets. The data elements (people?) move in complex patterns on paths controlled by traffic lights, bollards and other signs, policemen and common sense. But unlike most towns centres which, despite their original planning, have grown organically, i.e. over time without global organisation, computer architects have had the freedom to design simple and efficient control mechanisms from scratch. The control mechanism within a typical CPU uses a prescribed sequences of stages each of which carries out a particular action. This sequence is known as the “Fetch-Execute” cycle. As we shall discover, each line of assembler takes a cycle of 5 stages to execute, whether it’s a mov operation, an add operation, or anything else. In each state of the cycle a specific movement of data or other action takes place, e.g. on stage 3 any ALU operations required by the assembler instruction are carried out, and on stage 4 any memory access is carried out. Let’s run around this cycle for the add ax,bx instruction, noting the actions and data movement. Fig.5 a diagrammatic summary of the 5 stages in the cycle, Fig.6 and Fig.7 show two examples presented as screenshots from the SAM simulator you shall use in this chapter’s activities. Let’s first consider the “add ax,bx” instruction. Fig.5 presents the overview, Fig.6 shows the details of the add ax,bx instruction’s operation. Refer to both figures while reading the following commentary. 5. Do any writes to registers 1. Fetch instruction from code cache Write result into ax Load instruction “add ax,bx” 2. Decode instruction; do any register reads 4. Do any access to memory (read/write) Read ax and bx into ALU Nothing to do here 3. Do any ALU operations Do the add ax + bx Figure 5. Fetch-Execute cycle showing the five stages in the processing of the “add ax,bx” instruction Stage 1. Here the instruction is fetched from code memory and placed into the instruction register. Stage 2. Here the instruction in this register is “decoded”, it is converted to electrical control and perhaps data signals which spread through the CPU. Also any register reads are performed. The instruction add ax,bx loads the contents of both ax and bx into the ALU; since these are register reads, they must happen now. Stage 3. Here any ALU operations required by the instruction are performed. Since our current instruction is an “add”, the required addition is carried out on this stage. Stage 4. Here any memory access is performed, which means either routing data into memory from a register, or reading data out of memory into a register. The add instruction makes no reference to memory, so nothing happens on this state. Stage 5. Here registers are written to if required, any data located in a parking place (e.g. MDR, or the ALU output) is written into a register. Since our add ax,bx writes the result of the addition into ax, that write happens here. It’s important to realise that the classes of actions effected at each stage of the FE-Cycle are identical, irrespective of the actual assembler instruction being executed during these five stages as that instruction is fetched and executed. As mentioned above, all ALU operations happen at stage 3.We shall return to this point in ??. You may have noticed that only four of the five states are actually used during the fetch and execution of our add. State 4 did nothing, it was apparently a waste of time. Would it not have been more efficient to have used a four-state cycle? Perhaps, but other instructions need the full five states, and it makes the design of the control circuitry simpler (and therefore cheaper) if a common five-state cycle is used, even though not all instructions need the full five stages. Figure 6. Fetch Execute cycle for the mov ax.[1] line of code in the SAM simulator. (1) The instruction is placed into the IR, the address “1” is sent towards the MAR. (2) The instruction is decoded and control signals generated (not shown). (3) There is no ALU op to perform, but the address “1” is written into the MAR. (4) The memory access is performed, the data from cell whose address is in the MAR (cell “1”) is placed into the MDR. (5) The data in the MDR (Lisa) is written into the register ax. Let’s now take a second example of a fetch-execute cycle in operation, for the instruction mov ax,[1] which moves the contents of memory location address 1 into register ax. Stage 1. The instruction mov ax,[1] is fetched from code memory into the instruction register. Stage 2. Once in the instruction register, it is decoded and the control signals generated. Any register reads are done in this state. We do not read a register in this instruction (the ax is the register where we shall write to), but we do need to get at the address 1. That is read out from the instruction register and placed into the data path to start its journey to the MAR. Stage 3. Any ALU operations are done in this state. There are none to do, for this “mov” operation, but here the address 1 is placed into the MAR parking place. Stage 4. This is the opportunity to do any memory access. Here “mov ax,[1]” implies reading the data at memory address 1, and placing the result into the MDR parking place. Stage 5. Finally, any register writes are performed. Here the data loaded into the MDR in the previous stage is now written into the destination register, ax. Finally, the addition is complete. Figure 7. Fetch Execute cycle for the add ax,bx instruction: (1) Intruction is fetched into the IR and (2) decoded. Here also register reads are performed. Lisa and Marge (which have already been moved into ax and bx) are read into the ALU. (3) Here the ALU operation of addition is performed, just like Intel’s MMX instruction, images are added. (4) There is nothing to do here on the memory write stage. (5) The result is taken from the ALU and written back into the destination register ax. There are some interesting observations which we can make from these two examples. First, the data pathways and fetch-execute states can be used to handle data from several sources: A register read, and an address read can both take place at stage 2. An ALU operation and an address insertion into the MAR cab both occur on stage 3. The CPU architecture has been designed by the engineer to allow this to happen. While it is beyond the level of this text and the SAM-2 simulator to explain these issues, a more advanced SAM-4 simulation and tutorial is available from the author’s web-site. Second, while some parts of the data-path are one-way (the inputs to the registers are at the top, outputs at the bottom); and the same with the ALU, which means that no direct write from MDR into the register along the short paths can occur, (the data is forced to take the long way round), some parts of the data-path are bidirectional, such as the long path connecting instruction register, the registers ax, and bx, the ALU output, the MAR and MDR. The five-cycle fetch-execute cycle has been designed so that data can only flow one way along these paths at any one time, and of course, that no two different data elements can be placed on the same part of the data path at the same time. So there’s quite a lot of organisation packed into the fetch-execute cycle. 2.5 The Structure of the Intel Pentium It is useful to revisit the photograph of the Intel Pentium chip die and identify where activity associated with the 5 fetch-execute states is located. These are shown in Fig.?? Of course this labelling is somewhat simplistic, nevertheless gives a good indication of where data is flowing. 1 2 3 4 5 Figure 8. Pentium Chip die with indication of data flow during the 5-stages of the FetchExecute cycle shown as labelled arrows 1-5. 2.8 Advanced Issues. Why the 5-stage Fetch-Execute Cycle ? 2.7 Activities In these activities, we'll use a Java Applet “SAM-2” to simulate and investigate the working of a CPU plus memory. SAM ("Simple Although Meaningful") consists of a CPU based on an “Instruction Set Architecture”, and contains a small set of instructions to allow storage and retrieval of data from memory, and simple mathematical operations in the ALU. Its instructions look very like Intel's Pentium instructions, so when you learn SAM’s instructions, you are also learning the Pentium’s. The simulation applet is located on the CD, together with Sun’s runtime environment which you need to install on your machine. The first activities are designed to help you get to grips with the “Fetch-execute cycle”, subsequent ones teach you how to program in assembler, and finally there are a series of tasks, where you are invited to write assembler programs to solve some problems. But first let’s take a quick tour of SAM, to discover where it’s various elements of userinterface are located. Load prepared programs Load data sets Stepping button Area to write your own code Figure ?? Screenshot of SAM CPU Simulator showing buttons to load prepared code and data, the stepping button to move through the 5 stages of the fetch-execute cycle and the area where you can write your own program. (1) At the lst if the programming area (“Code Memory”) where you will soon write your own assembler code. But first we shall load prepared examples using the (2) “Yellow” C-for-code buttons in the menu bar. (3) “Green” D-for-data buttons are used to load various data sets, either images or numbers, into the memory (“Data Memory”). Sam can work with both numbers and images. (4) The “cycle-step” button, which steps through each state of the Fetch-Execute cycle. Remember, each assembler instruction takes 5 cycles. Using SAM is easy; you select a program (or write one), you select a data set and you run the program by repeatedly pressing the cycle-step button. As you progress, SAM responds by highlighting the line of code you are currently executing in read, and by displaying the state you are at within the FE-Cycle at any time. So you see a slow-motion execution of your program. ACTIVITY 1 Question 1. Load the program “Yellow 1”. The first instruction is mov ax,[1]. This means 'load register ax with the contents of memory at address 1'. Run through the 5 stages of the Fetch-Execute cycle and note down what happens at each stage. (Use vocabulary from the diagram above). Write down in simple English how the data from address 1 gets into register ax. Question 2. Now step through the second line of code and note the difference in where the data is written - into bx. Question 3 Finally step through the third line of code (add ax bx). Write down what happens on each of the 5 stages of the Fetch-Execute cycle. On which stage does nothing much happen? Question 4 Load up program 'Yellow 2'. This contains some code like 'mov [2],ax' which moves the contents of ax into memory. Investigate how this instruction works. Note down the 5 stages for this instruction. Question 5. Load up program 'Yellow 3', which contains a mixture of moves from registers to memory and from memory to register. Make sure you understand what is happening. Don't write anything down. Try experimenting with numeric as well as iconic data. Question 6. Program 'Yellow 4' is intended to reveal to you how to move data from register to register, eg the mov ax,bx instruction. Experiment and learn. Note down anything you wish. Question 7. Program 'Yellow 5' concerns addition. Add it to your understanding. Mmm. Actually this program also introduces a new instruction "move immediate" which is not the same as a move. The first line is 'mvi ax,2' which does not load from memory at address 2. Find out what 'move immediate' does ACTIVITY 2 Question 8. Write a program (first on paper) to load X into AX and Y into BX. That's all. (You find these icons in dataset 1). Now write the program in the Applet and check if it works. Question 9. Write a program (first on paper) to swap the position of Bart and Crusty the Clown in memory. Yes, you must first mov them into registers. Yes, now enter your code in the Applet and pray. Question 10. Write (yes first on paper) a program to add up the first three numbers from dataset 5, and to write the result back into memory. (Look at Yellow 1 for inspiration). Question 11. Now that you've written it on paper, write a program to mov in Crusty the Clown and to overwrite all memory icons with Crusty the Clown. Question 12. Write a program to reverse the order of the icons in any data set. Who needs paper? ACTIVITY 3 Web Searches Web Search 1. See how many images of CPU chips you can find. Try words like 'chip die photo' in your search engine. Web Search 2. Find out all you can about the latest "64-bit CPU Chips" from Intel and AMD. Web Search 3. Manufacturer's give each chip a name, a sort of nickname. Here's some examples - 'Sledgehammer', 'Wilamette', 'Katmai'. Compile a list of nicknames and group them in manufacturer's families.