intro
advertisement

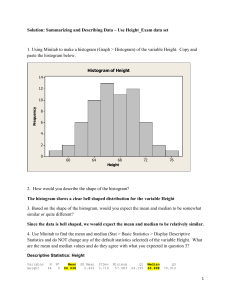
U.B.C. BIOLOGY 300 BIOMETRICS COMPUTER LAB ASSIGNMENTS 1. INTRODUCTION The purpose of these computer lab exercises is to provide you with an additional means of understanding basic statistics taught in lectures and to provide exposure to data analysis using a modern microcomputer system. In the lab, you are provided access to a computer network containing the necessary programs, especially JMPin, the student version of JMP from the SAS institute. JMP is one of the most versatile and easiest to use statistical programs and is widely used in academic, government and corporate settings. Although a number of features have been included in this package of programs that are beyond the scope of most introductory biostatistics courses, this package is easy to use and designed to introduce novice users to statistical analysis. The program is designed to emphasise the graphical and exploratory requirements of statistics. The package of programs is entirely menu driven and runs in Windows and MacIntosh environments. The program is installed on all the computers in the Biostatistics lab in room 4329, as well as on the computers in Zoolab, the undergraduate computer lab on the second floor of the biology building. To run a personal copy of JMPin at home you will need Windows 3.01 or higher or Windows 95 or 98, a 386 or higher microprocessor, and at least 4mb of RAM. To run the program on a MAC, you need a current MacIntosh with at least 2mb of free RAM. This program is not designed to replace the JMPin documentation. It is designed as a set of exercises to provide you with practical, hands on experience with biostatistics. This is our second year using JMPin and these new lab exercises, so bear with us as we continue to remove any glitches. We welcome your comments for suggested changes and improvements. By all means, experiment with the program and try new things. The odds are that you will discover useful tricks that we haven’t mentioned. Outline of Topics for this Week 1. Logging onto the System 2. Using JMPin in the labs and at home 3. Data Entry and Editing 4. Data Description and Exploration: Levels of Measurement Data Types Plotting Distributions Histograms Quantile Box Plots Outlier Box Plots Other Graphic Techniques Descriptive Statistics Measures of Central Tendency Measures of Dispersion Using The Program In Class: General Start-up Instructions Our computer network and server require passwords to allow you access. You will be assigned a password and user-id during your first lab. The user-id will be valid for the duration of the course and will allow access to the network, the Internet, assorted applications and a home directory where you can store several megabytes of files. The password you will be given will be temporary. You should change it during the first lab session to protect you from hackers, etc. Follow the instructions you will be given in class to change your password using the telnet program. This is the only way that you can change your password. Write your password and id down in a secure location. You will need them for the rest of term to access the system. To access the system, type your user-id and password into the windows networking dialog box that will be displayed on the screen of your computer. If a further dialog box appears asking if you want to use this password for windows, hit cancel. This dialog box has no function and will be disappearing from the computers shortly. Once windows has booted up, click on the START button in the bottom left corner of the screen. Use the mouse to move to the PROGRAMS option, then to JMPin. 2. DATA ENTRY AND EDITING Data may be entered from experimental designs or observational studies involving simple random sampling. Random sampling requires that each member of the population has an equal and independent chance of being selected. This requirement can be met by assigning each individual in a population a number and using a table of random numbers to decide which individuals will be included in the sample. More often, the researcher simply uses all of the individuals available and assumes that the sample is a random representation of the population about which inferences are to be made (i.e., the sample of convenience). Using the Program Before you can use any of the exploratory or inferential statistics programs, data must be put into the computer's memory. Data may be entered directly or may be stored in a file from a previous session. When you first open JMPin, you will see a table labeled untitled 1. This is where you will enter data. The table is currently blank, with 1 column and 0 rows. To enter data you will need to add some rows. Double clicking on the ROWS menu choice, then choosing add rows, allows you to specify how many data points you wish to enter. You may also double click directly on the chart at any point to add rows down to the cell in which you have moved the mouse cursor. Columns may be added to the table in a similar fashion. Rows and columns may be deleted by selecting the rows or columns you wish to remove (move the cursor to the desired location, hold down the left mouse button, and drag the cursor over the rows or columns you wish to remove), and then accessing the pull down menus for rows and columns. Try adding some rows and columns to the table and then deleting them again. Editing values is as simple as selecting and changing them. More advanced tools are also available including formatting, transforming and grouping data points. We will explore some of these tools in future exercises. In general, each column on the screen represents a single variable. A variable is simply the measurement of interest. Each cell on the screen represents a single data point. Accessing Files from the Server The procedure to access files from the shared drive is to choose the open file menu. From the drive sub-menu choose shared. From the shared directory choose the file that you want. Problems 1. Ten randomly chosen sections of a river showed the following number of spawning coho salmon: 22, 18, 40, 16, 12, 17, 23, 41, 29, 33. a) What is a "variable"? How many variables are in this data set? b) Enter these data and save them in a file named salmon. (Note: if you have changed your password but didn't log out afterwards, the computer will not let you save your data, since your password will be different from what you logged in with. In future labs this should not be a problem.) c) Change the third value to 19 and the eighth value to 27. d) Insert a value of 16 after the second record. e) Delete the fourth and fifth values. f) Add the following values to the data set: 17, 15, 11, 21, 23, 26. Your data set should now include the following values: 22, 18, 16, 12, 17, 23, 27, 29, 33, 17, 15, 11, 21, 23, 26. 3. EXPLORING AND DESCRIBING DATA The first thing to do with a set of data is to inspect it visually. Inspection affords an opportunity to determine the shape of a distribution. This information is of interest on its own, but will also help to determine the type of analysis to carry out next on the data. There are a number of useful tools for this, including descriptive statistics, histograms and boxplots. JMPin offers all of these (including two different variations of the boxplot) plus a number of additional exploratory tools. For now, however, we will limit ourselves to these three methods as they are the most widely useful and most widely used. A. Histograms A histogram is a plot of the commonness of different values of a variable. The X-axis of such a plot consists of the range of values that the variable can assume. The Y-axis indicates the frequency of observations occurring in each interval of X-values. This frequency is represented by a bar that allows the viewer to easily compare frequencies of observations in different intervals of X. The number and width of X intervals used in a histogram is arbitrary, and there is no set rule for determining how many classes to use. By luck of the draw some classes of X will be over-represented in a sample and others will be under-represented. If the X-axis is finely divided into too many intervals, many classes will contain no observations as the result of chance alone, and the histogram will resemble the skyline of a city dominated by skyscrapers. Someone viewing such a histogram will have difficulty determining the shape of the true distribution. Using fewer, larger classes can alleviate this problem. Holes in the distribution are smoothed over, giving a better picture of the shape of the distribution. It is possible to go overboard with smoothing. Histograms consisting of a few very wide classes may hide significant features of a distribution. As the number of classes is increased, take note of how robust the overall pattern is and of new features as they appear. Are features real, or are they simply the result of chance variation in the sample of observations? There is no set rule for answering this question; however, you can form an opinion by performing a small mental experiment. Suppose that you were to increase the size of the sample by a few observations and that you were to strategically place those observations on the histogram in such a way that they reduce the conspicuousness of a feature that interests you. The feature is likely to be an aberration if it is wiped out but real if it remains conspicuous. Once you understand the distribution of a sample, how many x intervals should you use to present the data to an audience? Divide the axis as finely as possible without requiring the viewer to do too much smoothing to see the pattern. Why? Viewers will miss your point or not bother with the histogram at all if they must take the time to smooth the pattern themselves. The fineness with which the x-axis is divided provides viewers with a means of judging the strength of whatever pattern is purported to be present. Viewers will be convinced by a pattern that remains clearly visible when many classes are used, whereas they will be suspicious when relatively few classes are used for large samples. Indeed, it is probably safe to assume that most people who present data will operate according to this strategy, and it is reasonable to judge histograms on the assumption that investigators follow the same rule. Using the Program To produce a histogram, choose ANALYZE, then DISTRIBUTION OF Y from the pulldown menus. Select the variable you wish to analyze. The graph that appears provides a rough estimate of the distribution. You can increase the amount of information the program provides by modifying the graph. First, choose the check mark icon at the lower left of the histogram window. This accesses the controls for this set of analyses. Change to a horizontal layout and the histogram will be in the same orientation you have seen in class. Add a count axis, so that you can more easily see the frequencies for each interval. If you use the pointing tool (arrow) that is the default tool and click on the histogram you will be able to enlarge the diagram by clicking and dragging the small square appearing in the bottom right corner of the graph. Problems 1. Open the data file bigclass by choosing file, then open, from the menus at the top of the screen. The file is located in the shared directory (along with most of the data files we will use this term). Select the variable weight, then carry out the procedures mentioned above. a) Describe the general shape of the data distribution using the terms explained to you by your TA (normal, uniform, skewed left or right, platykurtic, leptokurtic or bimodal). b) Choose the hand tool and move it within the histogram. What happens when you move the hand parallel to the X axis? Why is this happening? c) How strongly is the histogram affected by changes in interval start points? d) What happens when you move the hand parallel to the count (frequency) axis? e) What are the consequences of too few intervals in a histogram? Too many? f) Try highlighting one bar of the histogram using the pointer tool (arrow). What effect does this have on the original data table when you examine it? g) The check menu provides several other useful tools. Display a normal or bell-shaped curve over your histogram. The normal curve is one of the most useful distributions for statistical analyses. It is often this shape that we hope to find in a plot of our data. How well does your histogram approximate a normal curve? (In future sessions we will learn about more powerful tools for testing normality.) B. Descriptive statistics Qualitative descriptions of distributions are also useful. The most common method of describing the location of a distribution is the mean. Breadth of a distribution can be described using the standard deviation. Mean and standard deviation completely describe a distribution that conforms to a normal bell-shaped curve. They are less apt descriptors of non-normal distributions, particularly distributions that are skewed or contain outliers. Another related statistic is the standard error, which we will deal with in future sessions. Quantiles or percentiles of a distribution are alternative descriptors that can be used to describe both the location and spread of a distribution. The median or 50th percentile is often used as a measure of location. The difference between the 75th percentile (or 3rd quartile) and the 25th percentile (or 1st quartile) can be used to describe the breadth of a distribution. This distance is often referred to as the interquartile range. These quantiles are particularly useful in the form of a boxplot, described in the next session. Problems 1. Continuing to use your histogram data, examine the statistics given in the tables beside the histogram. a) How similar are the values for the mean and median of the weight data? Do you think that this result will always occur? b) Change the weight for Tim, data point 6, to 384 (note that this is an American program, so weights are given in pounds. Also note that JMPin, like most statistics programs differs from spreadsheets like Excel. It does not automatically refresh graphs when you change your data. You must produce a new analysis to see the change. This allows you to view the effects of changes by comparing a new graph to the original.). How does this affect the mean and median of your data set? Which measure of central tendency is more sensitive to outliers (unusual or aberrant data points)? DO NOT SAVE THE EDITED DATA SET. C. BOXPLOTS In order to conduct many parametric statistical tests it must be assumed that data have been sampled from normally-distributed populations. This assumption can be tested using goodness of fit tests such as chi-squared or the Kolmogorov-Smirnov test. Prior to testing, however, the general distribution of a data set should be scrutinised graphically. Both histograms and boxplots provide graphical summaries of data to help indicate the distribution of the variable in the population. Histograms indicate the frequency of occurrence of all values, whereas boxplots summarise only the most prominent features of a data set. A boxplot shows the centre and spread of a data set, as well as the extent and nature of departures from symmetry. A boxplot is particularly useful for detecting outliers. Outliers are observations that lie unusually far from the main body of the data. These unusual observations may reflect an unusual distribution of the variable in the population (e.g., the data may be highly skewed), but sometimes they are errors of measurement or transcription, or represent individuals from a population other than the one under study. Whatever the cause, a decision must be made to either use these extreme values or to eliminate them from further analyses. When should outliers be deleted? There is no correct answer to this question. If an outlier is not an error but is deleted, then valuable information is lost and a bias is introduced into later statistical tests. Yet including an erroneous outlier also has harmful consequences. The decision to delete an observation or not should always be based on what is known about the sampling procedure and the experimental design. A good strategy is to conduct analyses with and without the suspect observation and compare the results. If the conclusions from the two analyses are different then the decision to reject a value or not must be made with great care. Boxplots are also informative about other aspects of a distribution, such as asymmetry. If a distribution is asymmetrical, and hence not normal, then a transformation of the data may often result in a more normal distribution. If no simple transformation is satisfactory, then nonparametric statistics should be used in subsequent analyses. Statistics such as the mean and standard deviation can be drastically affected by even a single outlier. Therefore, boxplots are based on measures that are resistant to the presence of a few outliers. These measures are the median and the interquartile range. To draw a basic boxplot, the n observations in a data set are first ordered from smallest to largest and the overall median is determined. The overall median is then plotted as a horizontal line. Next, the median of the smallest half of the data (lower quarter) and the median of the largest half of the data (upper quarter) are determined. Note that the overall median will be considered in both halves of the data set if n is odd. The interquartile range is then calculated simply as the difference between the medians of the upper and lower halves of the data set. The interquartile range is shown graphically by plotting the medians of each half of the data set as horizontal lines and then joining the ends of the lines to form a box. If the data set is symmetrical (i.e. from a uniform or normally-distributed population), then the box will appear to be divided equally into two halves by the overall median. A vertical line is then drawn between the smallest and the largest values in the data set to indicate the range. In a symmetrical data set, this vertical line will extend the same distance on either side of the box. Using the Program JMPin produces two variants of the boxplot: an outlier boxplot and a quantile boxplot. Both are available from the check menu for distribution of y analyses. The default version displayed by the program is the outlier box plot. In this figure, the tail is shown as a solid line to a distance of 1.5 times the interquartile range away from the central box. Data points beyond this are shown individually as outliers, or aberrant points. A red line on the side of the plot illustrates the range for the most closely grouped set of 50% of the data points. The quantile boxplot shows the distribution from the quartiles to the minimum and maximum values in the data set as solid lines but puts tick marks at selected quantiles along the tails. These can include values such as the 90% quantile, the 95% quantile or the 99% quantile (see the help menu of the program for a diagram showing quantiles on a quantile boxplot). This quantile boxplot also shows a diamond which represents a 95% confidence interval around the mean of the data set. We will deal with confidence intervals in a future lab session. Problems 1. Using the bigclass data set and the weight variable, examine the outlier and quantile boxplots. a) Does the data contain any outliers? Use the selection tool (arrow) to highlight any such values in the data set. b) Is the interquartile range (box) symmetrical about the overall median? Does the range of the data set extend equally on either side of the box? Are the data normally distributed? c) Use the cross tool on the outlier boxplot and use it to locate which quantiles are represented by tick marks on the quantile boxplot. Compare the values to those displayed in the quantiles chart for this analysis. How can these tick marks be useful for checking the symmetry or normality of a data set? d) As you may recall, we altered the value for Tim’s weight from 84 to 384 pounds. Change the value back to 84 pounds. What effect does this have on the boxplots? 2. Use the same data set, but examine the height variable (given in inches). Format the output as you did for the weight variable. a) Compare the information from the boxplots and histogram. Which graphic tool provides more information about the distribution of the data? b) Use the hand tool to alter the number of intervals and their starting points in the histogram. How strongly does this affect the shape of the histogram? Is there any change in the accompanying boxplots? What does this suggest about the reliability of histograms as a sole tool for exploring data distributions? c) What information can you gather about normality of the data from the boxplots? 3. Use the same data set, but examine the sex variable. a) What happens to the boxplots for this variable? Why do you think this might happen? b) Mosaic plots such as the one displayed for sex, are most useful for comparing breakdowns of responses across subsets of a variable. What type of data is information about sex? We will work more with this data type in future weeks. Answers for this Lab Assignment Return to Main Lab Page Return to Main Course Page