Excel Functions for Statistics
advertisement

Basic Statistics with Microsoft Excel
Excel Functions for Statistics
DESCRIPTIVE STATISTICS: FREQUENCIES
Using COUNTIF to Construct a Frequency Distribution
The spreadsheet below shows how COUNTIF can be used to calculate how many times each
country appears in the list in Column A.
To calculate Frequency select D2 and enter the function:
=COUNTIF(A$2:A$17, C2)
A2:A17 is the range to be evaluated (need absolute row
reference ($) to make sure function will fill down correctly).
C2 is the country to be counted.
To calculate Relative Frequency, divide Frequency (D2) by Total (D7).
To calculate Percent Frequency, multiply Relative Frequency (E2) by 100.
Note: Cells D2:F7 show the formulas used. Cells D11:F16 show the results.
1
Basic Statistics with Microsoft Excel
Using FREQUENCY to Construct a Frequency Distribution
The FREQUENCY function involves the use of array formulas that provide multiple values (in this
case the class frequencies) as output.
1. Select cells D2:D5 where the
frequencies are to appear.
2. Type
the
formula:
=FREQUENCY
(A2:A16,{9,14,19,24})
3. Press CTRL + SHIFT +
ENTER and the array
formula will be entered into
each of the cells D2:D6.
Because we entered an array
formula, the formula that Excel
displays in each of the cells is the
same, but the values are not - they
are the frequencies for each class.
The class upper limits in the second
argument of the FREQUENCY
function tell Excel which frequency to put in each cell within the range of the array formula.
Using PivotTable Report to Construct a Crosstabulation
PivotTable Report provides a general tool for summarising the data for two or more variables
simultaneously.
1.
2.
3.
4.
5.
6.
7.
Select the Data menu and choose PivotTable and PivotChart Report.
Choose Microsoft Excel list or database.
Choose PivotTable and select Next.
Enter the data range in the Range box and select Next.
Select New Worksheet (if required).
Click on the Layout button.
Drag the field buttons to the ROW, COLUMN and DATA sections of the diagram as
appropriate.
8. Double click the Sum of … field button in the data section.
9. Choose Count under Summarise by: and click OK.
10. Click OK and the Finish.
2
Basic Statistics with Microsoft Excel
DESCRIPTIVE STATISTICS: NUMERICAL METHODS
The following spreadsheet shows the functions used to calculate the mean, median, mode,
percentiles and quartiles for a cell range named hours.
Displaying the Mean, Median, and Mode
=AVERAGE(array), =MEDIAN(array), =MODE(array)
Percentiles and Quartiles
=PERCENTILE(array, percentile) where percentile is between 0 and 1
=QUARTILE(array, quart) where quart is 1, 2, 3 or 4
1st Quartile = 25th Percentile, 2nd Quartile = 50th Percentile, 3rd Quartile = 75th Percentile
Deviation and Squared Deviation About the Mean
The sum of the deviations about the mean will always equal 0.
To calculate the square of a value enter =A1^2.
The sample variance (difference between the value of each observation and the mean) will be the
sum of the Squared Deviation divided by n-1. In the example above this will be 41320/4 = 10330
3
Basic Statistics with Microsoft Excel
Sample Variance and Sample Standard Deviation
To calculate the Variance use =VAR(range).
To calculate the Standard Deviation use =STDEV(range).
Using the Descriptive Statistics Tool
The Descriptive Statistics Tool is one
of Excel’s Data Analysis Tools
(which are available from the
Analysis Toolpak Add-In) and
allows the user to compute a variety
of statistics at once.
1. Make sure that the Analysis
Toolpak has already been
installed. (If not, go to
Tools/Add-Ins and select
Analysis Toolpak).
2. Select Data Analysis from
the Tools menu.
3. Choose Descriptive
Statistics from the list of
Analysis Tools. The
Descriptive Statistics box will
open.
4
Basic Statistics with Microsoft Excel
4. In the Input Range: box,
enter the range for your
data (B3:B18).
5. Select Columns in the
Grouped By: section.
6. Select Labels in first row.
7. Enter where you want the
statistics to appear in the
Output Range: box (D3).
8. Select Summary statistics.
9. Click OK.
Covariance and the Correlation Coefficient
Covariance is a measure of linear association between two variables. Positive values indicate a
positive relationship; negative values indicate a negative relationship. The correlation coefficient
is another measure of linear association between two variables that takes on values between -1 and
+1. Values near +1 indicate a strong positive linear relationship, values near -1 indicate a strong
negative linear relationship, and values near 0 indicate the lack of a linear relationship.
The covariance function =COVAR() treats the data as a population and the correlation function
=CORREL() treats the data as a sample. The result obtained using the covariance function must be
adjusted to provide the sample covariance. The formula for the population covariance requires
dividing by the total number of observations in the data set, but the formula for the sample
covariance requires dividing by the total number of observations minus 1. Therefore to compute the
sample covariance multiply the population covariance by n/(n-1).
5
Basic Statistics with Microsoft Excel
PROBABILITY
Computing Posterior Probabilities
The spreadsheet below shows the prior probabilities for two mutually exclusive events A1 and A2.
Prior probability is the initial estimate of the probability of an event.
Conditional probability is the probability of an event given that another event has occurred.
Joint probability is the probability of two events both occurring (intersection of two events) in the
case above the prior probability multiplied by the conditional probability.
Posterior probability is the revised probability of an event based on additional information.
6
Basic Statistics with Microsoft Excel
DISCRETE PROBABILITY DISTRIBUTIONS
Expected Value, Variance, and Standard Deviation
Expected value is a measure of the mean or central location of a random variable.
Variance is a measure of the variability or dispersion of a random variable.
Standard deviation is the positive square root of the variance.
The SUMPRODUCT function multiplies each value in one range by the corresponding value in
another range and sums the products.
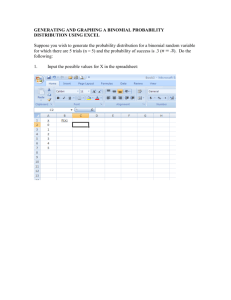
Binomial Probabilities
A binomial experiment has the following four properties:
1. The experiment consists of a sequence of n identical trials.
2. Two outcomes are possible on each trial – a success and a failure.
3. The probability of a success, denoted by p, does not change from trial to trial. Consequently
the probability of a failure, denoted by 1-p, does not change from trial to trial.
4. The trials are independent.
Excel’s BINOMDIST function can be used to compute binomial probabilities and cumulative
binomial probabilities. The spreadsheet below shows how to calculate the probability of 0, 1, 2 and
3 successful outcomes given 3 trials if each trial has a 0.3 probability of success.
7
Basic Statistics with Microsoft Excel
If you prefer to use the Insert Function
command, select the Statistical category and
click on BINOMDIST. Enter the arguments
for the first calculation as shown, using
absolute referencing where necessary.
Using POISSON to Compute Poisson Probabilities
A Poisson probability
distribution is a
probability distribution
showing the probability of
x occurrences of an event
over a specified interval of
time or space. The
POISSON function
requires three arguments
and has the following
syntax:
=POISSON(x, mean,
cumulative).
If you prefer to use the Insert Function
command, select the Statistical category and
click on POISSON. Enter the arguments for
the first calculation as shown, using absolute
referencing where necessary.
To calculate the cumulative probabilities, the
third argument will be TRUE.
8
Basic Statistics with Microsoft Excel
Using HYPGEOMDIST to Compute Hypergeometric Probabilities
The HYPGEOMDIST function is the function used to
compute the probability of x successes in n trials
when the trials are dependent. HYPGEOMDIST will
only compute probabilities, not cumulative
probabilities and has four arguments: x, n, r, and N.
Its syntax is:
=HYPGEOMDIST(sample_s, number_sample,
population_s, number_pop)
If a sample of 5 children contains 3 girls and 2 boys,
the probability of selecting 2 children who are both
girls will be 0.3.
9
Basic Statistics with Microsoft Excel
CONTINUOUS PROBABILITY DISTRIBUTIONS
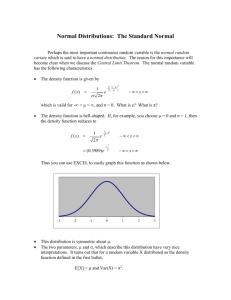
Normal Probabilities
In a normal probability distribution the probability density function is bell shaped and
determined by its mean µ and standard deviation σ. A standard normal probability distribution
is a normal distribution with a mean of zero and a standard deviation of one.
Excel has two functions for computing probabilities and z values for a standard normal probability
distribution: NORMSDIST and NORMSINV. The NORMSDIST function is used to compute the
cumulative probability given a z value and its syntax is =NORMSDIST(z) where z is the value for
which you want the distribution. The NORMSINV function is used to compute the z value given a
cumulative probability and has the syntax =NORMSINV(probability) where probability is a value
between 0 and 1. The letter S reminds us that the functions relate to the standard normal probability
distributions.
The NORMSDIST function provides the area under the standard normal curve to the left of a given
z value. For nonnegative z values, the NORMSDIST function provides the same cumulative
probability we would obtain if we used a cumulative normal probabilities table. However, unlike a
table, the NORMSDIST function provides cumulative probabilities for negative z values as well.
To calculate the probability of z being in an interval you must calculate the value of NORMSDIST
at the upper end point and subtract the value of NORMSDIST at the lower endpoint of the interval.
To calculate the area under the standard normal curve to the right of a given z value you must take
the cumulative probability away from 1.
10
Basic Statistics with Microsoft Excel
The NORMSINV function is the inverse of the NORMSDIST function; it takes a cumulative
probability (lower tail area) input and provides the z value corresponding to that cumulative
probability. To work out the z value for an upper tail probability, subtract the probability from 1.
Two similar functions, NORMDIST and NORMINV are available for computing the cumulative
probability and the x value for any normal distribution. The NORMDIST function provides the area
under the normal curve to the left of a given value of the random variable x. Its syntax is
=NORMDIST(x, mean, standard_dev, cumulative). If cumulative is TRUE it will return the
cumulative distribution function; if FALSE it returns the probability mass function (height of the
curve).
The NORMINV function is the inverse of NORMDIST and takes a cumulative probability as input
and provides the value of x corresponding to that cumulative probability. Its syntax is
=NORMINV(probability, mean, standard_dev).
11
Basic Statistics with Microsoft Excel
Exponential Probability Distribution
The EXPONDIST function can be used to compute exponential probabilities. Its syntax is
=EXPONDIST(x, lambda, cumulative) where x is the random variable, lambda is 1/µ and
cumulative will always be TRUE.
12