Statistics for Planet Earth
advertisement

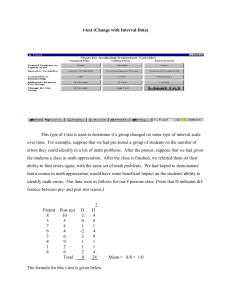
Significant Science: Statistics for Planet Earth A lesson developed through the Environmental Science Institute’s NSF GK-12 Program at the University of Texas Beth Dawson, Fellow, University of Texas at Austin bethdawson@mail.utexas.edu Kirstin Busch, Teacher, LBJ High School kbusch@austinisd.org The Problem Students were mis-interpreting the significance of their Biodiversity Project field data Average Number of Individuals by Proximity to Water at Mayfield Preserve 40 Number of Individuals 35 30 25 20 15 10 5 0 5m 270m Proximity to Water (m) The Solution Students were led through a 2-day exercise: 1. To apply the terms population, sample, and learn to calculate mean and standard deviation 2. To learn how to perform and interpret a twosample t-test using Excel The Results Students successfully reported the results from their t-test and communicated these results through a written conclusion # Individuals: Close to Water Far from Water 27 33 23 27.67 5.03 34 36 40 mean # indiv. 36.67 STDEV # indiv 3.06 P-value 0.05713 5.71% Result: The number of individuals living near the water is not significantly larger than the number of species living far from the water (p=.05713). Lesson Plans Included on the Environmental Science Institute’s Lesson Plan Website (http://www.esi.utexas.edu/gk12/lessons.php) Student handouts Teacher notes Spreadsheet of examples and solutions Math concepts and t-test formula Helpful References and Links Choosing and Using Statistics, Calvin Dytham (Blackwell Science) http://www.ruf.rice.edu/~lane/rvls.html http://mathworld.wolfram.com http://www.StatisticalPractice.com http://www.ccnmtl.columbia.edu/projects/qmss/t_about.html http://www-micro.msb.le.ac.uk/1010/1011-17.html http://www.esi.utexas.edu/gk12/index.html Page 1 Statistics: Teacher notes for the two-sample t-test Goals • Students learn to use statistics to test hypotheses • Students discuss concepts such as population, sample, mean, and standard deviation • Students learn how to perform and interpret a two-sample t-test Materials • Teacher notes • Student handouts with practice problems • Excel spreadsheets with examples and solutions • Math background Overview This lesson helps high school science students learn how statistics are used to interpret results of scientific experiments. It helps resolve misunderstandings about data and shows students how mathematics can help test hypotheses. This lesson plan was developed to help students test their own hypotheses with data collected during field trips. Any data appropriate for a two-sample t-test can be used for the final project. We encourage you to read through these notes, practice with the examples, and use the statistics with your students’ own data. Math teachers can use these notes and the accompanying math background document to build lesson plans to support this curriculum. We’ve created a student handout to guide the students through discussion questions and give them structured space to take notes. There is also a Microsoft Excel spreadsheet of examples and practice problems. Contact us! This lesson was developed by Beth Dawson, a graduate student in Integrative Biology at the University of Texas, Austin, and Kirstin Busch, a life science teacher at the Liberal Arts and Science Academy at LBJ High School, Austin Independent School District, Texas. We worked together as part of a National Science Foundation GK-12 grant to the Environmental Sciences Institute at the University of Texas in Austin. We would like to thank Dr. Susan Empson and Dr. Jay Banner for their help and encouragement. We’d love to get your feedback on this lesson and hear how you’ve incorporated statistics into your classroom. Please email: bethdawson@mail.utexas.edu kbusch@austinisd.org Page 2 Introduction – Are boys the same height as girls? Let’s start by asking a question: are boys the same height as girls? Or are they usually taller? We could probably find an example in our class of a girl who is taller than a boy. Can we take that one example and use it to conclude that all girls are taller than all boys? Let’s take our discussion and use it to formulate a hypothesis: Hypothesis #1: boys are not the same height as girls We could write an even more specific hypothesis: Hypothesis #2: boys are taller than girls Today, we’re going to learn how scientists use math to test hypotheses. And we’re going to test these two hypotheses. First, let’s collect data. Let’s separate the class into boys and girls and have each group write down their heights, in inches. We can use a spreadsheet to chart the heights. (NOTE: See the data table in Student Handouts. You can use the Microsoft Excel spreadsheet of examples to enter student data and generate a histogram similar to the figure below. The example uses 14 girls and 14 boys. Note that this works best with large class sizes; if you have a small class, you might want to combine data from other classes. You may enter the data from your own class into the spreadsheet or use the data supplied in the example. If you use your own data, you will need to regenerate the histogram and create new charts. To generate a histogram in Excel, select “Data Analysis” under the Tools menu, then select “Histogram” and follow the directions. Put the output for boys in cell D5 and the output for girls in F5.) Histogram of Heights 7 6 5 4 boys girls 3 2 1 0 57 59 61 63 65 67 69 Height (inches) 71 73 75 77 Page 3 Here’s our chart. It looks like most boys are taller than most girls, but there is some overlap. If we were studying this, what conclusion might we draw if we happened to select very short boys and very tall girls for our study? Is it possible that we might conclude that boys and girls are generally the same height? Just looking at this chart, can you prove or disprove our hypothesis? Now let’s define some key terms and look at how scientists use math to answer these types of questions. Population and sample When scientists design their studies, they need to be very careful about how they word their hypothesis and how they collect their data. Each scientist defines two key terms: sample and population. Population: all of the organisms that can be included in the study The term “population” is used to refer to all of the plants, animals, humans, etc. that could be included in your study. Another way to look at this: it’s the group to which you want to apply your results. Let’s think about an example. Let’s say we want to study musical abilities in U.S. high school students. Our population is defined as “all high school students in the United States.” Because we have selected only high school students, we can’t apply our results to elementary school students. If we wanted to study musical abilities in everyone younger than 18, then we would need to redefine our population to include younger students. In our study of student heights, our population might be all of the high school students in our town, or our state. Often, populations are so large that scientists can’t study every single member of the population. How many high school students are there in the United States? Thousands? Millions? Scientists use samples from the population. Sample: a subset of the population Samples let scientists study fewer people (or plants or animals) but still apply their results to the population at large. In our study of musical abilities in high school students, we could select 1500 high school students from across the U.S. Or, we could just take all of the students enrolled in band and use them. Could we? Would this be a good sample? Would we get different results if our sample included only students enrolled in art class? It is very important that the sample meet the same definition as the population. Generally, scientists select their sample at random, with no bias. Can you think of a way to randomly select 100 students from your high school? Page 4 Mean and Standard Deviation Every population and every sample can be described mathematically. Most of you probably know or have heard the word “average.” But can you define it? Can you calculate the average for your group’s height? Average: the middle point of a dataset, defined as the total of all values divided by the number of values Average is also called “mean” and is a very good way to describe your data. If you wanted to tell someone how tall everyone in your class is, you could give them a list of all of the heights, or you could just tell them the average height. Average is a good way to describe your data. Let’s calculate the average height for the boys and then for the girls. Another way to describe your data is to look at the “spread” of data. We could look at our data of heights like this: Scatterplot of Height Data 75 73 Height (inches) 71 69 67 65 boys girls 63 61 59 57 55 (If you enter the height data for your students in the Excel spreadsheet, this chart should automatically update with your students’ data. If you have more than 14 boys or girls, you will need to update the source data for this chart to include the additional data. Select the chart, then choose Source Data, Data Series and update the Y values.) Describe what you see in this chart. We can talk about whether the boys are generally taller than the girls. But what can you say about the “spread” of the heights? Are girls more or less the same height? Do the heights of boys differ more? We can mathematically calculate the “spread” of the data using standard deviation. Page 5 Standard deviation: a measure of the spread, or dispersion, of data relative to the mean Standard deviation can be calculated with a spreadsheet or a calculator. Let’s look at the standard deviation of our height data. (In the example spreadsheet supplied, the girls have a much smaller standard deviation than do the boys. If you are using your class’s own data, you will have different results.) (In the StatsPractice.xls spreadsheet, you will find sample datasets that your students can use to practice calculating mean and standard deviation.) Writing and testing hypotheses Statistics are used to test hypotheses, so it is very important to carefully write your hypothesis. Let’s go back to our example of heights. We can write two hypotheses: H1: boys are not the same height as girls H2: boys are taller than girls Notice that the first hypothesis is very general. It simply predicts that the two samples are essentially different. The second hypothesis makes a more specific prediction. It says that boys are taller than girls. But can we test either hypothesis by looking at our data? Or at the chart? What is the population for these hypotheses? How have we sampled that population for the data in our chart? (Charts can be used to visualize data but that visualization can be imprecise and inaccurate. The populations are “boys” and “girls”. Our sample isn’t really random – since all of our boys and girls are about the same age and attend the same school.) One way to think about testing this hypothesis is to look at your sample of boys and your sample of girls and ask if they come from the same population. In terms of height, are boys and girls essentially the same or different? Statistics Years ago, in fact back in the 1800’s, scientists realized that they needed a more definite way to test hypotheses. One scientist in particular was a man named William Gossett. He was a chemist employed by the Guinness Brewery in Ireland to make sure that each batch of beer met a specific standard. Every day, he took a sample of beer and performed various chemistry tests. Then, he compared the tests from that batch of beer to the results they wanted and asked the question “are these two batches of beer the same?” He devised a mathematical formula for comparing two samples to test the hypothesis that the two samples are from the same population. In 1908, he published his work under the pen Page 6 name “Student” and described a test known as Student’s t-test. Gossett also designed other mathematical tests that are widely used in statistics. He was an important contributor to the field of statistics. Statistics: a field of mathematics used to interpret scientific data There are many statistical tests, each designed to be used for a different type of data and to test different relationships. Scientists design their experiments with statistics in mind, planning how they will analyze their data even before they collect it. Gossett’s t-test is a widely used statistical test. Two-sample t-test: a mathematical test that compares two groups to test the hypothesis that the two samples come from populations with the same mean A t-test produces a result known as a “p value” or the probability value. For example, a p value of 0.5 means there is a 50% chance that your two samples are really the same. In this case, you could not reject the hypothesis that the two samples come from two populations with the same mean. A p value of 0.1 means there is a 10% probability that these two samples are essentially the same. If you are looking to find differences between your two samples, then a lower the p value is “better” in terms of testing your hypotheses. Let’s do a two-sample t-test with our height data. Remember our first hypothesis: H1: boys are not the same height as girls This is the simplest way to say “these two samples are not from the same population.” Performing the t-test Many spreadsheet software programs can perform a t-test for us. You need to have data for the first group, data for the second group and then you need to make some decisions about how to perform the t-test. The t-test has some assumptions that must be met. One of these is that your data is normally distributed, that is to say that it is on a bell curve. Our histogram shows us that our data is normally distributed so we’re fine there. Another assumption is that the “spread” between the two groups is equal. We performed a standard deviation so we know the result of that, too. If your standard deviations are fairly close, then you can assume the spread of your data is equal. If your standard deviations are very difference, just to be safe, don’t assume that your spread is equal. Here are the steps to perform a t-test in Microsoft Excel. Under the Insert menu, select Function. This brings up a window that lists all of the functions. Select statistical then select “ttest” to insert a two-sample t-test. This brings up a dialog window similar to this: Page 7 For Array1, select the cells that contain the boys’ heights. For Array2, select the cells that contain the girls’ heights. Where it says “tails”, type a 2. We’ll explain this in a minute. For type, you need to decide whether your standard deviations are the same (in other words, do you have equal variance?). If you have equal variance, type 2. If not, type 3. (For now, we won’t do a paired t-test, which is type 1.) This produces a p value for your two samples, which is the probability that the two samples are from the same population. Now, the question is how to interpret this p value. How different is different enough? Scientists use a standard p value of 0.05 to conclude that two samples are not from the same population. That is to say, there is a 5% chance that they are but a 95% chance that they aren’t from the same population. This is a pretty stringent requirement and ensures that before we say two samples are different we are pretty confident of that result. What if your p value is 0.06? You’re almost to that magic 0.05 but not quite. What can you do? The best way to respond is to collect more data. In general, the larger the sample size, the more powerful your result from the t-test. Tails and more tails In the example above, we selected “2” for tails, to perform a two-tailed t-test. What’s all this about tails? Let’s look at our histogram of heights and our original hypothesis: Page 8 Histogram of Heights 7 6 5 4 boys girls 3 2 1 0 57 59 61 63 65 67 69 71 73 75 77 Height (inches) H1: boys are not the same height as girls Our hypothesis doesn’t predict whether boys are taller or shorter than girls. That is to say, we don’t know if the blue line is going to be on one “tail” or the other “tail” of the girls’ distribution. A two-tailed t-test tests for differences in either direction – taller or shorter. If we have a pre-existing reason to predict that boys are going to be taller than girls, we can use our second hypothesis: H2: boys are taller than girls This hypothesis makes a more specific prediction. To test this, we can ignore the case where boys are shorter than girls and just test whether boys are taller. In t-test language, this means we can perform a “one-tailed” t-test. Try re-doing your t-test in Excel. This time, when the dialog box asks for “tails,” type 1. Interpreting the p value Now, back to that p value. We’ve decided that a p value of less than 0.05 supports the hypothesis that our two samples are from a different population. Let’s write that in a sentence as if we were presenting our results in a scientific publication: “We determined that boys are significantly taller than girls (p=0.0000165).” Notice that we used the word “significantly.” If you want to use the word “significant,” you need to perform some type of statistical test to establish that significance. In this example, our two groups are very significantly different, with a very small p value. Page 9 The most important step to a t-test is writing your results. Just reporting a p value isn’t enough; you need to know how to state your results and when to use the word “significant.” As you practice performing a t-test with practice data and with your own data, remember that the final step is writing a sentence like the one above. Congratulations! You are well on your way to statistical significance! Now you can not only perform scientific experiments and record your data but you also know how to use one of the most important statistical tests – the t-test – to interpret the significance of your results! Challenging students Students who are strong in math may want to go beyond this lesson. There are several steps you can take with these students. The first is to present the formula for a t-test and have the students build a spreadsheet that calculates their t-test. In this case, you will need a statistics textbook (or any one of a number of sites on the Internet) to look up the results of their t-test and find the associated p value. The calculation for a t-test is included in the math background. Students who quickly grasp this lesson can also be valuable mentors for other students. You could pair them with a student who’s just learning the t-test and have the two share their experiences. Another commonly-used t-test is the paired t-test. This is a valuable tool in “before/after” experiments. For example, we might measure the height of students at the beginning of the year and at the end. For each student we will have a pair of data – beginning and end. Many scientific experiments produce data that is best studied using a paired t-test. In Excel this is easy to perform; simply enter “1” for type in the t-test dialog box. Have students write their hypothesis, results and conclusions for the experiments performed in class. This is an important exercise to let them learn how to use a t-test to test hypotheses and how to interpret the results of a t-test. Another exercise would be to build more sampling distributions, as we did in the beginning of this with the histogram of student heights. You might encourage students to build a data log of the number of species of birds they see on the way to school every morning throughout the school year. You could use a paired t-test to test if the number of species seen in the fall is the same as the number of species seen in the spring. This would be a good way to connect the statistical tests with an ecology lesson on native species of birds. Page 10 For more information See the Links section on our Stats.ppt file for links to valuable teaching sites on the Internet. You can find more in-depth explanations of the t-test on these sites, practice problems, and more advanced statistical tests. Statistics: Math background for the two-sample t-test Goals • Students learn to use statistics to test hypotheses • Students discuss concepts such as population, sample, mean, and standard deviation • Students learn how to perform and interpret a two-sample t-test Materials • Teacher notes • Student handouts with practice problems • Excel spreadsheets with examples and solutions • Math background Overview These notes are designed to support the Statistics lesson plan for biology teachers. Math teachers can use the Statistics teacher notes and this math background document to build lesson plans to support this curriculum. The goal is for students to understand the mathematics behind mean, standard deviation (variance) and the two-sample t-test. This eliminates the “black box” mystery behind these statistical tests and helps students understand how to interpret statistical tests. The Microsoft Excel spreadsheet of examples and practice problems also has a section for the math examples used here. Contact us! This lesson was developed by Beth Dawson, a graduate student in Integrative Biology at the University of Texas, Austin, and Kirstin Busch, a life science teacher at the Liberal Arts and Science Academy at LBJ High School, Austin Independent School District, Texas. We worked together as part of a National Science Foundation GK-12 grant to the Environmental Sciences Institute at the University of Texas in Austin. We would like to thank Dr. Susan Empson and Dr. Jay Banner for their help and encouragement. We’d love to get your feedback on this lesson and hear how you’ve incorporated statistics into your classroom. Please email: bethdawson@mail.utexas.edu kbusch@austinisd.org Math Concepts for the t-test • • • Mean Standard Deviation Variance Mean Also called average, the arithmetic mean of a dataset is a way to describe the middle point of the data. Along with standard deviation and variance, it is a common descriptive statistic that can be easily calculated by hand or with computer spreadsheet software. Mean is calculated as the sum of all data divided by the number of data. For example, here are the test scores from a History class: Test scores: 95, 77, 82, 85, 91, 76, 88, 87 Number of scores (n) = 8 First, we need to add all of the test scores. Then we divide that sum by n (the number of scores). Sum = Number of scores (n) Sum / n 95 77 82 85 91 76 88 87 681 8 85.125 If students are not comfortable with calculating the mean, encourage them to work through several examples. Ideally, students should be able to calculate the mean themselves before they use the “AVERAGE” function in Microsoft Excel to perform this calculation for them. Standard Deviation and Variance Both of these are also descriptive statistics. They describe the “spread” of your data, or how far from the mean each datum is. They can be used to evaluate the dispersion of the data. In other words, are the values in your data pretty similar or are they all very different? Standard deviation can defined as the positive square root of the variance. This definition is valuable because it is always a positive number and it will always have the same units as the original data. To calculate standard deviation, we first need to define variance. The definition of variance is more of a tongue twister: it is the mean of the squared deviations of data from their mean. Variance is not in the same units as the original data but it is used in many statistical tests, so we need to think about how it is calculated. For any given sample, here is a mathematical definition for the sample variance: Sample variance (s2) = average squared deviation of values from the mean It sounds a bit intimidating but it’s really easy if you break it down into steps. 1. 2. 3. 4. 5. Calculate the mean. Subtract the mean from each observation (obs-mean). Square each value from step 2 (squares). Add all the values from step 3 (sum of squares). Divide by the total number of observations minus one (variance). From here, standard deviation is easy! It’s just the square root of the variance. T-Test When students are confident with mean and standard deviation, then the formula for the two-sample t-test is fairly straight forward. For this test, we always have two sets of data – set 1 and set 2 – and we are testing the hypothesis that they come from populations that are essentially the same population. A t-test lets us either reject the null hypothesis that the two samples are from populations with the same mean or the t-test says we should fail to reject this hypothesis. Hypothesis: the population mean for sample 1 = the population mean for sample 2 1. Calculate the mean and the variance for each of your two samples. Do this as above so you have the sum of squares for each data set (i.e. SS1 and SS2). 2. Divide SS1+SS2 by (number of data -1) in set 1 and number of data-1) in set 2. 3. Divide this value by the n in set 1 and then divide it by the n for set 2. Add these values then take the square root. 4. Subtract the mean of set 1 from the mean of set 2 then divide by the value from Step 3. This is your t-test statistic. Now, you need a table of critical values for the t distribution o look up your results. Use alpha (p value) of 0.05, two-tailed, and a degrees of freedom equal to your combined (n-1). Rejecting or failing to reject our hypothesis comes from comparing our calculated t statistic to the critical value from the t distribution. If the absolute value of your calculated t is greater than or equal to the critical t value, then you should reject the hypothesis that the population means are equal. If you use an alpha value of 0.05, then there is at least a 95% probability that the two samples come from populations that do not have the same mean. Assumptions The t-test makes assumptions about your data. The first assumption is that your data are continuous, not discrete. Also, the t-test assumes your data come from a normal distribution and that the variances of the two samples are the same. Some statistical software programs test these assumptions before performing a t-test. While the t-test is fairly robust to minor deviations from these assumptions, it is best to use data that meet these assumptions for teaching the t-test. Conclusion This is a very brief introduction to one of the simplest statistical tests – the two-sample ttest. For more information, there are a number of valuable textbooks that present basic statistics. We encourage you to read more about sampling distributions, t-test, analysis of variance and related topics to gain more familiarity with statistics. Page 1 Statistics: Student notes Goals • Learn to use statistics to test hypotheses • Discuss population, sample, mean, and standard deviation • Learn how to perform and interpret a two-sample t-test Sections 1. Introduction 2. Mean and standard deviation 3. Statistics and the t-test Section 1. Introduction – Are boys the same height as girls? Hypothesis 1 = Hypothesis 2 = Your height data BOYS GIRLS Page 2 Discussion Questions If we were studying the heights of students, what conclusion might we draw if we happened to select only very short boys and very tall girls for our study? If we selected students from the basketball teams for our height data, how would this data compare to the data from your class? Key Definitions Population = Sample = Discussion Questions How would you randomly select 100 students from your school? Is it possible for a randomly selected sample of 100 students to include only boys? Page 3 Section 2. Mean and Standard Deviation Key Definitions Average (mean) = Standard deviation = Practice problems for Mean and Standard Deviation In Microsoft Excel, "mean" is called "average." Enter the data below. Click on the cell below your data. From the Insert menu, select Function. Then click on Statistical and select AVERAGE. Where the dialog box says "number 1" select all of the test scores. Press enter to calculate the mean. Practice problem – English grades A group of students took an English exam and made these grades. Calculate the mean and standard deviation for these test scores. 92 78 77 67 52 84 86 Mean (average) = Standard Deviation = Practice problem – height data Now, calculate the mean and standard deviation for your height data. Boys Mean (average) Standard Deviation Girls Page 4 Describe your student height data. Using the mean and standard deviation, write a short paragraph that describes the data for boys and the data for girls. Practice Problem – Birds. A biologist wants to know if birds that live in cities are smaller or larger than birds that live in the country. He measured the weight of birds in town and in the country. Calculate the mean and standard deviation for both samples. Weight of birds in town (grams) 13 22 11 18 26 15 19 20 16 Weight of birds in country (grams) 27 12 11 23 29 18 27 28 21 Mean (average) Standard Deviation Write a short paragraph that compares these two samples – the weight of birds in town versus the weight of birds in the country. Use the mean and standard deviation you calculated in your paragraph. What conclusions do you think the biologists might make from this data? Page 5 Section 3. Statistics and the t-test Key Definitions Statistics = Two-sample t-test = Performing the t-test Here are the steps to perform a t-test in Microsoft Excel. First, enter two sets of data. To start, we’ll use the height data for boys and girls that you have already entered. Under the Insert menu, select Function. This brings up a window that lists all of the functions. Select statistical then select “ttest” to insert a two-sample t-test. This brings up a dialog window similar to this: For Array1, select the cells that contain the boys’ heights. For Array2, select the cells that contain the girls’ heights. Where it says “tails”, type a 2. We’ll explain this in a minute. For type, enter a 3. p value = Page 6 Interpreting the p value Write your interpretation of the p value: Practice problem – doing a two-sample t-test on frog data. A scientist is studying the call of male frogs that live in a creek. She performs an experiment to measure the duration of the calls of frogs that live upstream and the calls of frogs that live downstream. The water in the upstream part of the creek is from a fresh spring and tends to be very cold. The water downstream is warmer. She wants to test this hypothesis: H: Frogs call differently in the warm water than they do in the cold water. Here is her data on the duration of frog calls at each location, measured in seconds: Upstream, cold 37.1 41.0 38.4 40.9 38.5 38.8 36.5 40.3 41.3 39.8 37.6 Downstream, warm 44.3 46.6 40.3 50.5 42.7 41.9 50.8 44.5 42.1 48.3 41.9 Mean = St Dev = P value = Write 2-3 sentences interpreting the result of your t-test: Stats example: are boys taller than girls? Sample data for height in inches boys 74 67 66 74 68 64 70 68 71 68 72 66 64 67 girls 62 62 63 65 64 65 66 61 65 60 63 63 64 62 68.50 3.28 bins 57 59 61 63 65 67 69 71 73 75 77 Bin 57 59 61 63 65 67 69 71 73 75 77 More Frequency Bin 0 0 0 0 2 4 3 2 1 2 0 0 More Frequency 57 59 61 63 65 67 69 71 73 75 77 0 0 2 6 5 1 0 0 0 0 0 0 63.21 MEAN 1.72 ST DEV Histogram of Heights 7 6 5 4 boys 3 girls 2 1 0 57 59 61 63 65 67 69 Height (inches) 71 73 75 77 Stats example: are boys taller than girls? Sample data for height in inches boys 74 67 66 74 68 64 70 68 71 68 72 66 64 67 girls 62 62 63 65 64 65 66 61 65 60 63 63 64 62 68.50 3.28 63.21 1.72 Two-sample t-test 0.0000165 p value 0.00165% as a percentage one-tailed test not assuming equal variance MEAN ST DEV Scatterplot of Height Data Height (inches) 75 70 65 60 55 boys girls Practice - English grades 92 78 77 67 52 84 86 Mean (average) 76.57 Standard Deviation 13.41 Practice - Birds Mean (average) Standard Deviation town 13 22 11 18 26 15 19 20 16 17.78 country 27 12 11 23 29 18 27 28 21 21.78 4.63 6.83 cold 37.1 41.0 38.4 40.9 38.5 38.8 36.5 40.3 41.3 39.8 37.6 39.11 warm 44.3 46.6 40.3 50.5 42.7 41.9 50.8 44.5 42.1 48.3 41.9 44.90 1.66 0.0001107 3.65 Practice - Frogs Mean (average) Standard Deviation p value Examples from Math lesson Test Scores - calculating - calculating - calculating from History Class mean (average) variance standard deviation Observation s 95 77 82 85 91 76 88 87 Sum = Number of scores (n) Mean (sum/n) Sum of squares (SS) n-1 Variance (SS divided by n-1) Standard Deviation (sqrt of var) Calculated by Excel Variance Standard Deviation 681 8 85.125 302.8750 7 43.2679 6.5778 43.2679 6.5778 obs-mean 9.875 -8.125 -3.125 -0.125 5.875 -9.125 2.875 1.875 squares 97.516 66.016 9.766 0.016 34.516 83.266 8.266 3.516 Examples from Math lesson Test Scores - Comparing History vs. English - calculating a t-test (obs - mean) squared Step 1 Mean Variance n n-1 History (1) 92 71 82 75 91 70 88 82 English (2) 88 72 98 94 71 70 96 89 81.375 75.411 8 7 84.750 140.786 8 7 Sum of squares Step 2 Step 3 Step 4 Calculated t Critical t SS1 + SS2 / (n-1)1 + (n1)2 1 112.89 107.64 0.39 40.64 92.64 129.39 43.89 0.39 2 10.56 162.56 175.56 85.56 189.06 217.56 126.56 18.06 527.8750 985.5000 108.098 Divide each by its n Add them together Take the square root 13.512 27.025 5.199 Subtract mean1 from mean2 Divide by -3.375 5.199 Your t statistic is 0.649 absolute value Alpha Degrees of Freedom t (0.05, 14) = 0.05 14 2.145 this is an established value combined n-1 look this up in a table of critical values of the t distribution 13.512 Our calculate t is less than the critical t, so we can not reject the hypothesis that our two samples are from populations with the same mean. Excel's calculated p value 0.527