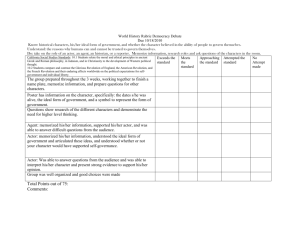
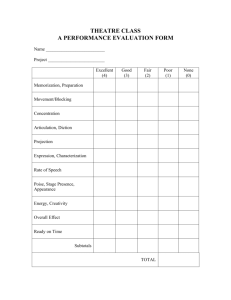
PERSPECTIVE AND ACTION UNDERSTANDING
advertisement

Perspective and Action Understanding 1 Running head: PERSPECTIVE AND ACTION UNDERSTANDING Perspective-taking Promotes Action Understanding and Learning Sandra C. Lozano Bridgette Martin Hard Barbara Tversky Stanford University Perspective and Action Understanding 2 Abstract People often learn actions by watching others. In this paper, we propose and test the hypothesis that perspective-taking promotes encoding a hierarchical representation of an actor’s goals and subgoals—a key process for observational learning. Observers segmented videos of an object assembly task into coarse and fine action units. They described what happened in each unit from either the actor’s, their own, or another observer’s perspective and later performed the assembly task themselves. Participants who described the task from the actor’s perspective encoded actions more hierarchically during observation and learned the task better. KEYWORDS: perspective-taking, observational learning, action understanding, intentional inference; hierarchical encoding Perspective and Action Understanding 3 Perspective-taking Promotes Action Understanding and Learning One way to learn how to do things is to watch others do them. A first step in learning by watching is to infer the goals of the actions being performed. Even small children can infer goals, and use those goals as the basis for imitating others’ behavior (e.g., Meltzoff, 1995). Inferring goals becomes more complex for real world tasks that consist of long, interrelated sequences of actions, such as making a cake or assembling a piece of furniture. To learn such tasks, observers need to infer how actions are organized into goal-subgoal hierarchies. (Hard, Lozano, & Tversky, in press; Whiten, 2002; Zacks, Tversky, & Iyer, 2001). Here, we explore whether the ability to infer goal-subgoal organization in action is influenced by perspective-taking. We take our notion of perspective-taking from Galinsky, Ku, and Wang (2005, p. 110), who define it as “the process of imagining the world from another’s vantage point or imagining oneself in another’s shoes.” Put differently, taking another person’s perspective implies establishing overlap between one’s own mental representations and the mental representations of the other person (e.g., Davis, Conklin, Smith, & Luce, 1996; Galinsky & Moskowitz, 2000; Vorauer & Cameron, 2002).1 We report a series of studies that test whether perspective-taking promotes understanding of goal-subgoal organization in observed behavior, thereby promoting observational learning. But first, we assemble the pieces of evidence underlying our reasoning. Action is Planned and Encoded as a Hierarchy of Goals and Subgoals People plan actions hierarchically according to an overarching goal that is decomposed into subgoals that are, in turn, decomposed into even smaller subgoals (Newell & Simon, 1972). These plans are instantiated into hierarchically organized behaviors, like making a bed, or even playing a violin (e.g., Lashley, 1951). Imitative behavior also shows evidence of hierarchical Perspective and Action Understanding 4 organization: when people and even other primates imitate others’ behavior, they do so in a way that suggests they’ve encoded that behavior as a hierarchy of goals and subgoals (e.g., Byrne & Russon, 1998; Travis, 1997; Whiten, 2002). In fact, people encode hierarchical organization when observing behavior in real time, even when they are not intending to learn that behavior. Evidence for this comes from several sources, notably using a segmentation task, in which people observe a video of goal-oriented behavior, pressing a key to indicate when, in their judgment, one action is completed and the next begins (Newtson, 1973). The action boundaries that people identify are referred to as breakpoints. For a wide range of goal-directed behaviors, people reliably segment units of action corresponding to the completion of goals and subgoals by the actor (Baldwin, Baird, Saylor, & Clark, 2001; Hard, Zacks, & Tversky, 2006; Newtson, 1973; Zacks, Tversky, & Iyer, 2001). Zacks, Tversky, and Iyer (2001) found that when asked to segment action sequences into coarse and fine units on separate viewings, observers select units that are hierarchically nested: the boundaries of coarse units coincide with the boundaries of fine units well above chance. When observers are asked to report what happens in each coarse or fine unit as they segment, in many cases they even give descriptions of how sets of fine units can be summarized into a coarse unit (Hard, Lozano, & Tversky, in press). The nature of these descriptions, combined with the consistency of hierarchical organization within and across observers, has been taken to reflect observers’ attempts to understand observed behavior by encoding its hierarchical organization. Other paradigms (e.g., Hard, Tversky, & Lang, in press; Martin, 2006; Zacks, Tversky, & Iyer, 2001), including studies of brain activation during passive viewing (Zacks, Braver, Sheridan, et al., 2001), corroborate these claims. One possible benefit of hierarchical encoding in terms of goals and subgoals is an Perspective and Action Understanding 5 action representation with the structure of an action plan, which in turn, facilitates performance of the action sequence by observers. Supporting this possibility, the degree of hierarchical organization in segmentation predicts accuracy of observational learning (Hard, Lozano, & Tversky, in press).2 People Describe Action from the Actor’s Perspective Although people naturally and frequently describe the world from their own point of view (e.g., Hart & Moore, 1973; Levelt, 1989; Piaget & Inhelder, 1956; Shelton & McNamara, 1997), there are notable exceptions. One of these is in describing observed actions (Lozano, Hard, & Tversky, in press). For example, in a recent study, observers gave play-by-play reports of an action sequence performed by an actor who faced them (Hard, Lozano, & Tversky, in press). Close examination of these reports revealed that when participants included specific spatial information, such as the locations of objects or which of the actor’s hands performed an action, it was using the actor’s spatial reference frame rather than their own. For example, participants were more likely to say “she puts the block on her left” than “she puts the block on my right.” This suggests that when observers describe actions, they seem to put themselves in the actor’s shoes. There is evidence that observers of action put themselves in the actor’s shoes, not only in their descriptions of actions, but also at the neural level: observing action activates many of the same brain mechanisms involved in planning and executing action (e.g., Grafton, Arbib, Fadiga, & Rizzolatti, 1996; Iacoboni, 2005; Iacoboni, Woods, Brass, Bekkering, Maziotta, & Rizzolatti, 1999). As some have put it, observing others’ actions produces motor simulation, in which an individual internally copies those actions (Fadiga, Craighero, & Olivier, 2005; c.f., Rizzolatti, Perspective and Action Understanding 6 Fadiga, Fogassi, & Gallese, 1999). These findings have been taken to mean that a component of understanding others’ actions is mapping them to actions of the self. Outside the domain of action understanding, increased self-other overlap during perspective-taking3 can have useful social consequences, such as increasing feelings of liking, rapport, empathy, and sympathy toward others (e.g., Batson, 1991; Chartrand & Bargh, 1999; Cheng & Chartrand, 2003). The self-other overlap that takes place when people observe actions has been proposed to promote action understanding, perhaps by facilitating inferences about the goals and intentions of others (e.g., Arbib & Rizzolatti, 1996; Rizzolatti & Arbib, 1998), or by generating predictions that guide the perception of ongoing behavior (Wilson & Knoblich, 2005). As yet, there is little direct evidence supporting these proposals, however. There is some recent evidence that perspective-taking is related to action understanding, specifically to hierarchical encoding of goal-subgoal structure. In a study described earlier, where participants provided play-by-play descriptions as they segmented a video of an object assembly task, participants who spontaneously described actions from the actor’s perspective both showed more hierarchical organization in their segmentation and assembled the object better (Hard, Lozano, & Tversky, in press). These findings were unexpected and only showed a correlation between perspective-taking and hierarchical encoding. Thus, it remains an open question as to whether perspective-taking leads to better action understanding or whether the relationship works in the opposite direction. Testing the Role of Perspective-taking in Action Understanding and Learning Taking the actor’s perspective might allow better encoding of the hierarchical organization of the actor’s intentions, that is, the goals and subgoals of the task. By promoting hierarchical encoding, perspective-taking should also promote observational learning. Together, Perspective and Action Understanding 7 these predictions form the hypothesis investigated here. In a series of studies, observers segmented a video of an object assembly task at coarse and fine levels, describing what happened in each segment as they segmented. In the first study, half the observers were instructed to describe the action from their own perspective, using their own body as a reference frame, and half from the actor’s perspective, using the actor’s body as a reference frame. As predicted, those who described actions from the actor’s perspective encoded actions more hierarchically and learned them better than those who described actions from their own perspective. A follow-up study confirmed that observers naturally describe action from an actor’s perspective, leading them to hierarchically encode and learn actions better than observers instructed to describe from a self-perspective. But surprisingly, instructions to describe from the actor’s perspective enhance hierarchical encoding and learning above and beyond what people do naturally. The third study rejected the possibility that taking any perspective other than one’s own can facilitate action understanding and performance. Study 1a: Describing from a Self versus Actor’s Perspective The first study tested whether describing actions from an actor’s perspective improves hierarchical encoding and learning. Participants watched a video of a person assembling an object, a TV cart, pressing a key to indicate when they thought one action segment ended and another began. They did this twice, once for the largest units that made sense and once for the smallest units that made sense. As they segmented, they described what happened, either from their own perspective (e.g., “she puts the board on my right”) or from the perspective of the actor (e.g., “she puts the board on her left”). After describing and segmenting the video twice, participants were asked to assemble the TV cart. Half the participants had been told of the Perspective and Action Understanding 8 assembly task, but half had not, so that effects of task awareness on performance could also be evaluated. Method Participants and Design Forty Stanford University undergraduates participated in exchange for course credit. A 2 x 2 x 2 x 2 Mixed Factorial design was used. Segmentation level (fine, coarse) was varied within participants; and assigned perspective (actor, self), segmentation order (coarse-fine, fine-coarse), and awareness of the later assembly task (aware, unaware) were varied between participants. Stimuli and Materials All participants viewed two videos, one for practice and one for test. The practice video, used for practicing the segmentation procedure, was created by Zacks, Tversky, and Iyer (2001) and showed a woman assembling a saxophone. The test video involved a woman assembling a TV cart made by Talon Systems Inc®. The TV cart measured 17” x 25” x 21” in size, and consisted of two sideboards, a lower shelf, an upper shelf, a support board, pegs for attaching the support board, screws, screwdriver, and wheels (see top half of Figure 1). The actor faced the camera during filming, and performed approximately equal numbers of actions with her left and right hand, following the script described in Appendix A. All videos were presented on a 21-inch, flat screen computer monitor. Response times were recorded with a keyboard attached to a Macintosh G4 computer, using a program written in PsyScope 1.2.5 (Cohen, MacWhinney, Flatt, & Provost, 1993). Verbal descriptions were recorded with a hand-held tape recorder, and TV cart assembly performances were recorded with a digital video camera. Perspective and Action Understanding 9 Procedure At the beginning of the study, participants received a brief introduction to segmentation. They were told that to make sense of their experiences, people break them down into events of varying sizes, some small, some large. Participants were never explicitly informed that large and small events could be hierarchically related, so that we could observe how and when hierarchical encoding occurred spontaneously and as a function of the experimental manipulations. Participants did receive everyday examples of both large and small events; but these events were in no way related to each other. The exact instructions that participants received are in Appendix B. Following this introduction, participants were told that they would see two videos of a person assembling an object. Their job was to divide these videos into separate units by pressing the spacebar every time one meaningful action ended and another began. Each time they pressed the spacebar, participants were instructed to briefly describe, from the perspective they had been randomly assigned (actor or self), what happened in the segment they had just observed. To demonstrate how to do this, participants were shown a still frame from the practice video that depicted a woman placing a saxophone on a table. They were given examples of how this picture could be described either from an actor- or self-perspective and were then reminded of which of the two perspectives they should describe. To practice segmenting and describing actions, participants viewed a practice video of saxophone assembly and were instructed to mark whatever units felt natural and meaningful to them. Participants then viewed and segmented the test video, which was 6 minutes 35 seconds long and showed an actor assembling the TV cart in the same room where participants were being tested. Half of the participants were instructed to indicate the smallest units that seemed Perspective and Action Understanding 10 natural and meaningful to them (fine-coarse); the other half were instructed to indicate the largest units that seemed natural and meaningful (coarse-fine). Participants then segmented the test video a second time according to the opposite unit-size instructions. Viewing the videos twice was necessary to create a measure of hierarchical encoding (Hard, Lozano, & Tversky, in press; Hard, Tversky, & Lang, in press; Zacks, Tversky, & Iyer, 2001). For both viewings, participants were reminded to describe all action units they indicated in terms of their assigned perspective. Participants in the aware condition were also told that after segmenting and describing the test video twice, they would have to assemble a TV cart themselves. The experimenter was not present during the segmentation task. After performing the segmentation task, participants were presented with all assembly materials needed to build the TV cart. The assembly materials were placed in a central, neutral position on the same table used by the actor in the test video. Participants were instructed that they could perform the task however they wanted; their task was simply to assemble the TV cart as quickly and accurately as possible. Participants received no further instructions and any suggestion of which perspective to use during assembly was explicitly avoided. Their performance was videotaped from the same visual angle as the test video, and the experimenter was not present during assembly. Results Overview of Analyses For all results in the present and subsequent studies, dependent measures were submitted to a factorial Analysis of Variance (ANOVA), with all independent variables (e.g., assigned perspective, awareness of the later assembly task, segmentation order) as factors, unless otherwise indicated. For all analyses, an alpha level of less than .05 was used as the criterion for Perspective and Action Understanding 11 significance. Nonsignificant effects are noted with a marking of ns. As estimates of effect size, a partial eta squared value (ηp²) is reported for significant ANOVA effects, and a Cohen’s d is reported for significant t-test effects. Does Perspective Affect Hierarchical Encoding? Hierarchical encoding was evaluated in two ways. The first measure, enclosure, assessed the hierarchical organization of participants’ segmentation pattern, using a technique developed by Hard, Lozano, and Tversky (in press). Enclosure is defined as the proportion of coarse breakpoints that fall after their closest fine breakpoint in time. When this proportion is high, then most of the coarse breakpoints take account of or enclose all the relevant fine units. If a coarse breakpoint precedes the breakpoint of the final fine segment, it violates strict hierarchical encoding. In the present study, most but not all the coarse breakpoints in fact fell after the closest fine breakpoint (M = 5.33, SEM = 0.97), instead of before it (M = 3.07, SEM = 0.76), pairedt(39) = 4.07, d = 0.66, replicating previous findings by Hard, Lozano, and Tversky (in press). Further rationale behind enclosure scores is provided in Appendix C, along with a more detailed explanation of how they are calculated. The second measure of hierarchical encoding assessed participants’ descriptions for hierarchical structure. This second measure provided a more transparent assessment of hierarchical encoding, and it was also used to validate the enclosure measure. During fine segmentation, although observers were instructed to identify fine-level actions, some of them offered summaries that grouped the preceding set of fine-level actions (e.g., “She inserted the first screw,” “She inserted the second screw,” etc.) into a coarse-level action (e.g., “She attached the top shelf”). The number of verbal summaries each participant gave during fine segmentation was used as a verbal measure of hierarchical encoding. Replicating findings of Hard, Lozano, Perspective and Action Understanding 12 and Tversky (in press), the number of verbal summaries correlated positively with enclosure scores, r(38) = .41, validating enclosure scores as a measure of hierarchical encoding. By both measures of hierarchical encoding, describing from an actor-perspective was superior to describing from a self-perspective. As the upper part of Figure 2 shows, participants who described from an actor-perspective had higher enclosure scores than self-perspective participants, F(1, 32) = 11.53, MSE = 0.28, ηp² = .40; and they used more verbal summaries (M = 2.45 to 1.00, SEM = 0.38 to 0.31), F(1, 32) = 10.92, MSE = 0.28, ηp² = .33. Awareness of the later assembly task had no effect on hierarchical encoding and no interactions were other variables. Segmentation order did affect hierarchical encoding, however. Replicating findings from Hard, Lozano, and Tversky (in press), participants who segmented in coarse-fine order had higher enclosure scores (M = .71, SEM = .05) than did participants who segmented in fine-coarse order (M = .59, SEM = .03), F(1, 32) = 4.77, MSE = 0.28, ηp² = .15. The influence of segmentation order on verbal summaries was less clear. There was a significant interaction between segmentation order and perspective instructions, F(1, 32) = 10.92, ηp² = .25. Participants using an actor-perspective summarized more often if they segmented in coarse-fine order (M = 3.30, SEM = 0.30) than in fine-coarse order (M = 1.60, SEM = 0.31), but participants using a self-perspective summarized more often if they segmented in fine-coarse order (M = 1.60, SEM = 0.20) rather than in coarse-fine order (M = 0.40, SEM = 0.10). Does Perspective Affect Learning? Videotapes of assembly performance were coded for errors and assembly time. Errors were counted even if the participant later corrected them. Errors could take three forms: attaching pieces in the wrong order (e.g., building the entire TV cart before trying to insert the middle support board), attaching pieces that should not be connected to each other (e.g., Perspective and Action Understanding 13 attaching wheels to the top shelf), or attaching a piece in the wrong orientation (e.g., attaching the top shelf upside down). On average, participants made 2.20 errors (SEM = 0.22) and completed the TV cart assembly in 10.00 minutes (SEM = 35.33 s). Assembly errors positively correlated with assembly time, r(38) = .58, suggesting that participants did not sacrifice accuracy for speed. If hierarchical encoding facilitates learning, then measures of hierarchical encoding (enclosure scores and verbal summaries) should predict learning. Confirming this, enclosure scores and verbal summaries predicted fewer assembly errors, r(38) = -.50 and -.72, respectively. If hierarchical encoding facilitates learning, then factors that improve hierarchical encoding should also improve learning. Confirming this prediction, participants who described the assembly video from an actor-perspective not only had better hierarchical encoding, but also made half as many assembly errors, as the lower portion of Figure 2 shows, F(1,32) = 16.65, MSE = 0.34, ηp² = .43. Similarly, segmenting in coarse-fine order improved hierarchical encoding and led to fewer assembly errors than segmenting in fine-coarse order (M = 1.95, SEM = 0.38 vs. M = 2.50, SEM = 0.38), F(1, 32) = 4.00, MSE = 0.34, ηp² = .19. However, segmentation order interacted with perspective, F(1, 32) = 7.15, ηp² = .22. When participants used an actor-perspective, assembly performance did not depend on segmentation order, coarse-fine or fine-coarse (M = 1.70, SEM = 0.30 vs. M = 1.30, SEM = 0.21). When participants used a self-perspective, assembly performance was better for those who segmented in coarse-fine rather than fine-coarse order (M = 2.20, SEM = 0.35 vs. M = 3.70, SEM = 0.44). Does Hierarchical Encoding Mediate Effects of Perspective on Learning? Perspective and Action Understanding 14 Assigned perspective affected measures of hierarchical encoding and also later assembly performance. Did perspective affect these two variables independently or did hierarchical encoding mediate the effect of perspective on learning? To address this question, a mediation analysis was performed using the mediation techniques of Baron and Kenny (1986), shown in Figure 3. According to Baron and Kenny (1986) and Kenny and Judd (1981), several preconditions must be met to establish mediation. First, the initial variable (assigned perspective) must predict both the potential mediator (hierarchical encoding, as measured by enclosure scores) and the outcome variable (assembly errors). As described in the top half of Figure 4, a linear regression analysis confirmed that assigned perspective4 predicted hierarchical encoding, t(1) = 15.17 and assembly errors, t(1) = -5.39. Second, the potential mediator (enclosure) must predict the outcome variable (assembly errors), even when controlling for the initial variable (assigned perspective). Indeed, hierarchical encoding predicted assembly errors when controlling for perspective, t(1) = -2.52. Based on these correlations, a Sobel test (Sobel, 1982) showed that mediation was significant, z = -2.48. Finally, to determine whether hierarchical encoding completely mediated the effect of perspective on assembly errors, it must be shown that the initial variable (assigned perspective) no longer predicted the outcome variable (assembly errors) when controlling for the mediator (enclosure). Controlling for hierarchical encoding, the effect of assigned perspective on assembly errors was no longer significant, t(1) = -0.24, ns. Thus, hierarchical encoding fully mediated the effects of assigned perspective on assembly errors. Does Perspective at Encoding Affect Perspective during Assembly? All participants performed the assembly task in the same room and at the same table where the actor was filmed. Thus, videotapes of assembly performances could be coded for the Perspective and Action Understanding 15 spatial perspective participants adopted during assembly (see Figure 5 for an example of this). Most participants adopted the same perspective during assembly that they had described during segmentation: 95% of participants who had described from an actor-perspective assembled the TV cart by taking the actor’s perspective, meaning that they built the TV cart in the same orientation and stood on the same side of the table as the actor. Of the participants who had described the video from a self-perspective, 75% assembled the TV cart from a self-perspective, meaning that they oriented the TV cart pieces in the opposite direction as the actor and stood on the opposite (observer) side of the table, Х12 = 23.41. This result confirms a link between assembly perspective and the way that participants perceived and encoded observed actions. Neither segmentation order nor awareness of the later assembly task had reliable effects on participants’ later assembly perspective. A fourth of self-perspective participants performed the assembly task from an actorperspective. This raises the possibility that self-perspective participants performed the assembly performance poorly not because they encoded a self-perspective, per se, but because some of them lacked the insight to perform the assembly task from the same perspective they encoded. As a first way of addressing this concern, we compared the assembly performances of selfperspective participants who chose to assemble from an actor-perspective with those who chose to assemble from a self-perspective. If incompatibility between action encoding and later action execution accounted for the poor assembly performance in the self-perspective condition, then those who assembled from an incompatible perspective should have made more assembly errors. Surprisingly, participants who described from a self-perspective but performed assembly from an actor-perspective outperformed those who maintained a self-perspective, making slightly but not Perspective and Action Understanding 16 reliably fewer assembly errors (M = 1.67, SEM = 1.20 vs. M = 2.95, SEM = 0.33), t(19) = 1.60, ns. As a second way of addressing this concern, we re-analyzed the assembly error data and excluded participants in the self-perspective condition who chose an actor-perspective for assembly, as well as the one actor-perspective participant who performed assembly from a selfperspective. Even with these participants excluded, participants who described from an actorperspective made fewer assembly errors (M = 1.44, SEM = 0.20) than those who described from a self-perspective (M = 3.33, SEM = 0.46), F(1, 25) = 24.50, MSE = 27.52, ηp² = .50. Combined, these analyses indicate that differences in assembly performance were not due to participants in the self-perspective condition choosing an incompatible perspective at assembly. Why is Describing from an Actor-Perspective Beneficial? The above analyses show that describing actions from the actor’s perspective instead if one’s own improves hierarchical encoding and imitative learning. How might encoding actions from the actor’s perspective serve action understanding? Are there other differences between actor- and self-perspective describers that provide clues? In this section, we explore some possibilities. Did perspective affect attention to action in general? Perhaps adopting the actor’s perspective facilitates hierarchical encoding and learning because it simply focuses attention on action more generally. To address this possibility, verbal descriptions of actor- and selfperspective describers were compared for differences in the overall type of information encoded. This analysis showed that descriptions in the two conditions were remarkably similar. Each participant’s descriptions were broken down into separate clauses and each clause was classified into three mutually exclusive categories: action statements, depiction statements, Perspective and Action Understanding 17 or comments. Action statements contained action verbs and described movements of the actor or objects (e.g., “She moved to the left side of the table” or “She inserted the screw”). Depiction statements contained verbs of possession or state-of-being verbs and conveyed physical or structural characteristics of objects (e.g., “The cart has four wheels” or “The screws are silver”). Comments were any statements that were unrelated to the video itself (e.g., “Oops, I forgot to hit the spacebar for that last action I described”). For each participant, the percentage of statements of each type was calculated, and participants in the two perspective conditions were compared. On average, 84% of participants’ descriptions were action statements, 9% were depiction statements, and 7% were comments. Actor-perspective and self-perspective participants did not differ in the mean percentages of action, depiction, or comment statements that they made, (from all three categories, highest t(38) = 1.10, ns). Thus, the content of descriptions did not differ as a function of perspective. Did perspective affect number of segmented units? To determine whether perspective instructions influenced how coarsely or finely participants segmented the action sequence, the numbers of fine and coarse units that they identified were examined. During segmentation, participants identified approximately three times as many fine units (M = 29.90, SEM = 2.84) as coarse units (M = 8.90, SEM = 1.88), paired-t(39) = 10.54, d = 1.76. This ratio of coarse to fine units is consistent with previous findings using everyday activities (Zacks, Tversky, & Iyer, 2001), as well as abstract action sequences (Hard, Tversky, & Lang, in press). Perspective did not affect how many coarse units participants identified, but did influence the number of fine units. Participants who described from an actor-perspective identified more fine units (M = 35.10, SEM = 2.67) than participants who described from a self-perspective (M = 24.70, SEM = 2.67), F(1, 32) = 4.30, MSE = 0.17, ηp² = .12. Participants who segmented in fine- Perspective and Action Understanding 18 coarse order identified more fine units (M = 36.30, SEM = 3.55) than participants who segmented in coarse-fine order (M = 23.50, SEM = 3.55), F(1, 32) = 6.52, ηp² = .17. No other effects or interactions on the number of action units segmented were significant. Can these differences in number of segmented fine units explain why describing from an actor-perspective led to better hierarchical encoding and learning? Perhaps describing from an actor-perspective is a more stimulating task than describing from a self-perspective, leading to more attention and thus to encoding a finer level of detail. The results do not support this hypothesis, because numbers of segmented fine units did not predict enclosure scores or assembly errors. Numbers of segmented coarse units and the ratio of coarse to fine units were equally non-predictive. Did perspective affect encoding of spatial information? Did perspective instructions affect how often participants described spatial information or the kind of spatial relations they attended to? To answer this question, participants’ descriptions were broken down into separate clauses. Each clause was categorized as containing perspective-relevant information from one of four mutually exclusive categories: no perspective (e.g., “She inserted the screw”); neutral perspective (e.g., “She inserted the screw from the side”); actor-perspective (e.g., “She inserted the screw on her left”); or self-perspective (e.g., “She inserted the screw on my right”). The total number of descriptions in each category was determined for each participant.5 These analyses yielded several key insights. First, participants followed instructions: self-perspective descriptions were more common in the self-perspective condition (M = 9.85 descriptions, SEM = 1.35) than in the actorperspective condition (M = 0.20, SEM = 0.20), t(38) = 7.07, d = 2.26. In contrast, actorperspective descriptions were more common in the actor-perspective condition (M = 14.45, SEM Perspective and Action Understanding 19 = 1.82) than in the self-perspective condition (M = 1.70, SEM = 0.45), t(38) = 6.79, d = 2.15. The top of Figure 6 illustrates these differences in proportions of descriptions. Second, regardless of the perspective participants were assigned to describe, they were equally likely to describe spatial information. This was determined by comparing the two groups on the mean number of statements describing any spatial perspective, be it neutral, actor, or self (for self-perspective describers, M = 17.65, SEM = 1.94; for actor-perspective describers, M = 23.00, SEM = 2.86), t(38) = -1.55, ns. This result suggests that any differences in the two groups were due to the specific perspective that participants encoded, not to how much attention participants were paying to spatial information in general. Third, as Figure 6 shows, participants in the self-perspective condition were more likely to describe from the wrong (i.e., unassigned) perspective than participants in the actorperspective condition. Although it was common for self-perspective participants to incorrectly use the actor’s perspective at least once (M = 1.44, SEM = 0.41), actor-perspective participants almost never used a self-perspective (M = 0.20, SEM = 0.13), t(38) = 2.26, d = 3.67. Selfperspective describers were also more likely to qualify their perspective (M = 2.11, SEM = 0.72) than actor-perspective describers (M = 0.10, SEM = 0.10), t(38) = 2.89, d = 5.00. That is, they were more likely to state the perspective they were using (e.g., “She inserted the screw on the right, but that’s only if it’s my right that we’re talking about”). Combined, these results suggest that describing action from a self-perspective might actually be more difficult than describing action from the actor’s perspective. Could the difficulty of describing action from a self-perspective explain why selfperspective describers had difficulty hierarchically encoding and learning actions? Perhaps describing from a self-perspective was such a demanding task that it interfered with action Perspective and Action Understanding 20 processing. Additionally, self-perspective describers gave less consistent descriptions from their assigned perspective. Perhaps this led to “mixed-up” representation of the spatial relations in the task. The data suggest against both of these possibilities. Mistakes in description perspective were uncorrelated with hierarchical encoding and with later assembly performance, highest r(38) = .10, ns. Self- and actor-perspective also differed in the kind of spatial information they were likely to describe. Participants were far more likely to describe which of the actor’s hands, left or right, was used to perform a given action if they described from the actor’s perspective (M = 1.35, SEM = 0.21) instead of their own (M = 0.25, SEM = 0.20), t(38) = -3.77, d = 1.21. Actorand self-perspective describers did not differ in their likelihood of describing locations in space, as in left or right sides of the table (M = 13.30, SEM = 1.92 vs. M = 11.30, SEM = 1.54), t(38) = .81, ns. Importantly, the number of descriptions concerning which of the actor’s hands performed an action predicted better hierarchical encoding, as measured by enclosure, r(38) = .35, and by verbal summaries, r(38) = .42. References to the actor’s hands also predicted fewer later assembly errors, r(38) = -.47. The number of descriptions concerning locations on the table predicted neither measure of hierarchical encoding, r(38) = .01, ns, r(38) = -.02, ns, nor assembly errors, r(38) = -.15, ns. Given that actor- and self-perspective describers differed both in their tendency to describe hands and in hierarchical encoding, and that descriptions of hands correlated with hierarchical encoding, did differences in the tendency to describe hands mediate effects of perspective on hierarchical encoding? In fact, references to hands fully mediated effects of perspective on enclosure scores (see the upper half of Figure 7). First, a linear regression analysis confirmed that assigned perspective predicted both enclosure scores, t(1) = Perspective and Action Understanding 21 4.64, and hand references, t(1) = 3.77. Second, hand references predicted hierarchical encoding when controlling for assigned perspective, t(1) = 5.51. According to a Sobel test, mediation was significant, z = 3.12. Finally, controlling for hand references, the effect of assigned perspective on hierarchical encoding was no longer significant, t(1) = 0.81, ns. In sum, these results indicate two potentially revealing differences between actor- and self-perspective describers. First, describing actions from an actor-perspective appears to be easier than describing actions from a self-perspective. Second, describing from an actorperspective focuses observers’ attention on the actor’s body. This increased attention on the actor’s body appears to be beneficial, as it accounts for the fact that actor-perspective describers had higher hierarchical encoding than self-perspective describers. Discussion The results from the present study support the hypothesis that adopting the actor’s perspective facilitates both action understanding and action learning. In the present study, participants who described actions from the actor’s perspective, rather than from their own perspective, encoded the action sequence more hierarchically and later performed the action sequence faster and with fewer errors. This effect held whether participants were learning the actions intentionally or incidentally. Furthermore, adopting the actor’s perspective was beneficial to action learning precisely because it encouraged observers to encode actions hierarchically: hierarchical encoding mediated effects of description perspective on action learning. Notably, describing from the actor’s perspective elicited detailed descriptions of the actor’s body, and, in particular, of which hand the actor was using to perform the actions. The number of descriptions of the actor’s hands predicted hierarchical encoding and according to a mediation analysis, accounted for why actor- and self-perspective describers differed in Perspective and Action Understanding 22 hierarchical encoding. This suggests that focusing on the hands that accomplish the task is associated with better encoding of the task’s goal-subgoal structure. In sum, actively describing action from the actor’s perspective provides an effective link from action perception to action execution, far more effective than describing from one’s own perspective. Remarkably, adopting the actor’s perspective appeared to be the more natural way to describe action. Self-perspective describers were more likely than actor-perspective describers to describe the wrong perspective by mistake and to qualify the perspective they were describing. Although these description mistakes and qualifications were uncorrelated with hierarchical encoding and action learning, it remains possible that describing from a self-perspective is unnatural and therefore interferes with action understanding. Alternatively, describing from an actor-perspective might enhance it. These possibilities are not mutually exclusive—both might be true. Study 1b addressed these possibilities by comparing participants in the present study to participants who were not instructed to adopt a perspective. If describing from a self-perspective interferes with action understanding, then explicitly describing from a self-perspective should lead to worse hierarchical encoding and learning than describing freely. If describing from an actor-perspective enhances action understanding, then describing from an actor-perspective should lead to better hierarchical encoding and learning than describing freely. Study 1b: Describing Freely versus Describing from a Self or Actor’s Perspective Method Ten Stanford undergraduates from the same population of introductory psychology students used in Study 1a participated in exchange for course credit. The stimuli, materials, and procedure were identical to those used in Study 1a, except that participants were not given instructions to describe from any spatial perspective, nor were they given examples of the Perspective and Action Understanding 23 different perspectives one might use to describe actions. Because awareness of the later assembly task had no effect on performance in Study 1a, all participants in the present group were unaware that they would be performing the assembly task themselves. Study 1b participants were run within two weeks after completion of Study 1a. The ten participants run in the present condition were then compared to the 20 unaware participants from Study 1a, yielding a 3 x 2 factorial design, with assigned perspective (actor, self, free) and segmentation order (coarse-fine, fine-coarse) as between-subjects factors. Results Segmentation order did not affect any of the dependent measures reported below, nor did it interact with any other factors. Thus, all data were collapsed across segmentation order. When an effect of assigned perspective was reliable, post-hoc analyses using Dunnett’s (two-sided) ttests compared the actor- and self-perspective conditions to the free-describe condition. A summary of the findings, including means and standard errors, are reported in Table 1. Differences in Number of Segmented Units During segmentation, participants identified approximately four times as many fine units (M = 29.53, SEM = 2.60) as coarse units (M = 7.67, SEM = 0.67), paired-t(29) = 11.55, d = 1.86. Description perspective did not affect how many coarse units or fine units participants identified, for both F(2, 27) < 1, ns. Differences in Hierarchical Encoding How do self- and actor-perspective describers compare to free describers in hierarchical encoding? An ANOVA with assigned perspective as a between-subjects factor revealed a reliable difference among the three conditions in hierarchical encoding, as indexed by both enclosure scores, F(2, 27) = 21.47, MSE = 0.02, ηp² = .61, and verbal summaries, F(2, 27) = Perspective and Action Understanding 24 29.24, MSE = 0.77, ηp² = .68. Self-perspective participants showed impaired hierarchical encoding compared to free-describe participants, with reliably lower enclosure scores, and fewer verbal summaries. Actor-perspective participants showed enhanced hierarchical encoding compared to free-describe participants, with reliably higher enclosure scores, and more verbal summaries. Differences in Learning Assigned perspective reliably affected the number of assembly errors participants made F(2, 27) = 24.54, MSE = 1.04, ηp² = .65. For action learning, as for hierarchical encoding, selfperspective describers showed impaired performance compared to free-describers, and actorperspective describers showed enhanced performance. Self-perspective participants made reliably more errors than free-describe participants, and actor-perspective participants made reliably fewer errors than free-describe participants. Across the three conditions, participants made an average of 2.47 errors (SEM = 0.30) and completed the TV cart assembly in 10 minutes and 15 seconds (SEM = 4.20 s). Assembly errors positively correlated with assembly time, r(28) = .72, suggesting that participants did not sacrifice accuracy for speed. Differences in Description and Assembly Perspectives Whose perspective did free-describers take when describing the assembly task and when performing the assembly task themselves? As in Study 1a, participants’ descriptions were divided into four mutually exclusive categories: no perspective, neutral perspective, actorperspective, or self-perspective. Within the free-describe condition, participants described more often from an actor-perspective than a self-perspective, (M = 2.40, SEM = 0.40 for number of actor-perspective statements vs. M = 0.40, SEM = 0.16 for number of self-perspective statements), paired-t(9) = -6.00, d = 1.67, replicating findings by Hard, Lozano, and Tversky (in Perspective and Action Understanding 25 press). Also, the more actor-perspective statements that free-describe participants gave, the more hierarchically they encoded observed actions, as indexed both by enclosure scores, r(8) = .71, and numbers of verbal summaries provided, r(8) = .54. Adopting the actor’s perspective was not only more frequent in descriptions of actions, it was more frequent in assembly performance: free describers were more likely to perform the assembly task from the actor’s perspective (80%) rather than their own (20%). How often did free-describers describe from actor- and self-perspectives compared to participants assigned to those perspectives? Assigned perspective reliably affected the number of actor-perspective descriptions participants gave, F(2, 27) = 23.92, MSE = 0.13, ηp² = .67, (see Table 1). Although free-describers tended to adopt the actor’s perspective, they did so reliably less often than actor-perspective describers, and equally as often as self-perspective describers. Free-describers were, however, less likely to describe from a self-perspective than selfperspective describers, t(18) = 4.62, d = 2.52. Actor-perspective describers never adopted a selfperspective.6 Analysis of the kind of spatial information participants described showed no differences across the three groups in how often they described locations in space, as in left or right sides of the table F(2, 27) = 1.02, ns. The three groups did differ in how often they described which of the actor’s hands, left or right, was used to perform a given action, F(2, 27) = 13.90, MSE = 1.05, ηp² = .30 (see Table 1). Actor-perspective describers made more hand references than did free describers, but free describers did not differ from self-perspective participants in how many hand references they made. Discussion Perspective and Action Understanding 26 The present study confirms that observers naturally describe actions from the actor’s perspective, and that their tendency to do so predicts hierarchical encoding and learning. Furthermore, instructing participants to describe from their own perspective led to poorer hierarchical encoding and learning than instructing participants to describe freely. Describing from a self-perspective might interfere with hierarchical encoding and learning because it is incompatible with the way action is naturally described: forcing observers to describe in an unnatural way might be difficult and thus compete with other processes, such as hierarchical encoding. It is also possible that describing from a self-perspective is incompatible with the way action is naturally understood. We explore this possibility further in the General Discussion. Although observers spontaneously adopted the actor’s spatial perspective to describe actions, they showed enhanced hierarchical encoding and learning when they were explicitly instructed to adopt the actor’s perspective. This result supports the hypothesis that adopting the actor’s perspective serves action understanding, specifically inferences about goal-subgoal structure. This result also has practical implications: calling observers’ attention to the actor’s perspective is a useful means of improving action understanding and learning. This leads to a larger question: why is adopting the actor’s perspective beneficial? One possibility, which we return to in the General Discussion, is that adopting the actor’s perspective encourages observers to simulate observed action— this increased simulation helps them infer how actions are organized. But it is also possible that differences in attention or motivation could explain the superior performance of actor-perspective describers relative to free- and selfperspective describers. Describing from the actor’s perspective might be more engaging than freely describing or than describing from one’s own perspective, leading to fewer description errors and to richer encoding of the observed task. In other words, it may be that describing from Perspective and Action Understanding 27 any perspective other than one’s own, not necessarily from the actor’s perspective, would improve hierarchical encoding and learning. Study 2 examined whether action understanding and learning are improved by adopting any perspective other than one’s own, or by adopting the actor’s perspective specifically. Study 2 addressed this question by showing participants a video portraying an actor and an observer, both of whom were rotated 90 degrees from the participant viewing the video. Participants described actions from the perspective of either the actor or the observer in the video and later executed the action sequence themselves. If adopting any perspective other than one’s own is sufficient to improve hierarchical encoding and learning, then the two groups should perform equivalently. A second aim of Study 2 was to generalize several findings from Studies 1a and 1b to a different assembly task. Study 2: Describing From the Actor’s versus an Observer in the Scene’s Perspective Method Participants and Design Sixteen Stanford University undergraduates participated in exchange for course credit. A 2 x 2 x 2 x 2 Mixed Factorial design was used. Segmentation level (fine, coarse) was varied within participants; and assigned perspective (actor, observer), segmentation order (coarse-fine, fine-coarse), and actor position (left or right) were varied between participants. Stimuli and Materials As in Studies 1a and 1b, participants viewed one practice video and one test video. The practice video showed a female observer watching a female actor make coffee. The test video contained the same observer and actor, but showed the actor assembling two horses and a heart using red, yellow, green, and blue Duplo blocks made by Lego® (see Appendix A for a detailed Perspective and Action Understanding 28 script of assembly). The test video was 3 minutes 28 seconds long. In both videos, the observer and actor were 180 degrees opposite each other and at a 90-degree angle from the camera (see the bottom of Figure 1). Two versions of the test video were created, each shown to half the participants: the actor was on the left side of the table in one video and on the right side of the table in the other. Procedure Prior to testing, participants completed the Vandenberg Mental Rotation Test (MRT), a measure of spatial ability (Vandenberg & Kuse, 1978). Aside from this, the procedure was identical to that of Study 1a, except that when describing each video, participants were instructed to adopt a perspective that was offset by 90 degrees from their viewing perspective (see Appendix B for the exact instructions that participants received). Participants were randomly assigned to a perspective, actor or observer, and were instructed to describe all units that they segmented from that perspective. After performing the segmentation task, participants received the same instructions for the assembly task used in Studies 1a and 1b. Results and Discussion Does Perspective Affect Hierarchical Encoding? As in Studies 1a and 1b, hierarchical encoding was evaluated by both segmentation patterns (enclosure scores) and descriptions (verbal summaries). As before, these measures were correlated, r(14) = .57. As the upper half of Figure 8 shows, participants describing from an actor- perspective encoded actions more hierarchically than participants describing from an observer-perspective, according to enclosure scores, F(1, 8) = 8.31, MSE = 0.17, ηp² = .38, and to verbal summaries (M = 1.63, SEM = 0.32 vs. M = 0.13, SEM = 0.13), F(1, 8) = 19.64, MSE = Perspective and Action Understanding 29 0.17, ηp² = .44. No other effects or interactions were reliable. Thus, it is adopting the actor’s perspective specifically, and not any other perspective, that enhances hierarchical encoding. Does Perspective Affect Learning? Videotapes of assembly performance were coded for errors (e.g., attaching a block of the wrong size or color to another block) and assembly time. On average, participants made 7.80 errors (SEM = 1.78) and completed the assembly task in 8.80 minutes (SEM = 105.00 s). Assembly errors positively correlated with assembly time, r(14) = .60, suggesting that there was no speed-accuracy tradeoff in performance. Consistent with findings from Study 1a, participants who described the actions from an actor-perspective performed the task better than those who described from an observerperspective. As the lower half of Figure 8 shows, participants who described from an observerperspective made about four times as many assembly errors as those who described from an actor-perspective, F(1, 8) = 13.96, MSE = 0.22, ηp² = .48. Participants who segmented in finecoarse order made over twice as many errors (M = 11.13, SEM = 2.83) as participants who segmented in coarse-fine order (M = 4.50, SEM = 1.58), F(1, 8) = 7.78, ηp² = .27. No other effects or interactions were reliable. Spatial ability, as measured by MRT scores, did not predict assembly time or errors. As in Studies 1a and 1b, enclosure scores predicted fewer errors on the later assembly task, r(14) = .50. Similarly, using more verbal summaries led to fewer assembly errors, r(14) = -.60. Does Hierarchical Encoding Mediate Effects of Perspective on Learning? Can the effects of perspective on assembly errors be explained by changes in hierarchical encoding? To answer this question, a mediation analysis was again conducted using the techniques of Baron and Kenny (1986). As described in the bottom half of Figure 4, linear Perspective and Action Understanding 30 regression confirmed that assigned perspective7 reliably predicted assembly errors, t(1) = -3.13 and hierarchical encoding, as measured by enclosure scores, t(1) = 3.44. Hierarchical encoding also predicted assembly errors when controlling for assigned perspective, t(1) = -4.29. A Sobel test confirmed that significant mediation had occurred, z = -2.39. Controlling for hierarchical encoding, the effect of assigned perspective on assembly errors was no longer significant, t(1) = 0.59. Thus, hierarchical encoding fully mediated the effects of assigned perspective on assembly errors. Does Perspective at Encoding Affect Perspective during Assembly? As in Study 1a, assembly perspective was consistent with encoding perspective. Of the participants who had described from an actor-perspective, 100% performed the Lego® assembly task by taking that same (actor’s) perspective, meaning that they oriented the blocks as they had appeared to the actor in the video and stood on the same side of the table as the actor. Of participants who described the video from an observer-perspective, 63% assembled from the observer’s perspective, meaning that they oriented the blocks as they had appeared to the observer in the video and stood on the observer’s side of the table, Х12 = 9.29. Notably, the actor’s perspective was the “preferred” perspective overall and was associated with better assembly performance overall: participants in the observer-perspective condition who performed assembly from the actor’s perspective made slightly fewer errors (M = 8.33, SEM = 1.15) than those who maintained an observer-perspective during assembly (M = 12.25, SEM = 2.45), ns. Furthermore, when we re-analyzed the assembly error data and excluded those who described from an observer-perspective but chose an actor-perspective for assembly, participants who described from an actor-perspective still made fewer assembly errors (M = 3.38, SEM = 1.41) than those who described from a self-perspective (M = 8.08, SEM = 3.61), Perspective and Action Understanding 31 F(1, 11) = 11.43, MSE = 33.92, ηp² = .51. Collectively, these analyses indicate that differences in assembly performance were not attributable to self-perspective describers choosing an incompatible perspective at assembly. Does Perspective Affect Attention to Action in General? As in Study 1a, all descriptions were categorized as action, depiction, or comment statements. On average, 85% of participants’ descriptions were action statements, 12% were descriptions, and 3% were comments. Consistent with findings from Study 1a, there were no differences between actor-perspective and observer-perspective participants in the mean percentages of action, depiction, or comment statements that they used (for all three statement types, highest t(14) = 1.18, ns.) Does Perspective Affect Number of Segmented Units? Participants identified approximately four times as many fine units (M = 36.94, SEM = 4.92) as coarse units (M = 8.69, SEM = 1.06), paired-t(15) = 8.20, d = 5.92. This ratio of fine to coarse units was slightly larger than that found in Study 1a but is equivalent to that found in previous research using this same assembly task (Hard, Lozano, & Tversky, in press). In contrast to Study 1a, actor- and observer-perspective participants did not differ in the number of fine units segmented (M = 36.25, SEM = 4.86 vs. M = 37.63, SEM = 5.10). There were no effects of segmentation order on the number of segmented units (M = 36.94, SEM = 4.94 for fine-coarse vs. M = 34.35, SEM = 4.85 for coarse-fine). This difference from Study 1a is likely attributable to the task differences associated with assembling a TV cart versus assembling Lego® creations. Neither the total number of coarse units segmented, the total number of fine units segmented, nor the ratio of coarse to fine units segmented reliably predicted assembly errors. Did Perspective Affect Encoding of Spatial Information? Perspective and Action Understanding 32 As in Study 1a, descriptions were also categorized as no perspective, neutral perspective, actor-perspective, or observer-perspective. The results of this coding can be seen in the lower half of Figure 6. As in Study 1a, participants followed instructions: the only observer-perspective descriptions were given by participants in the observer-perspective condition (M = 9.00, SEM = 2.98). The only actor-perspective descriptions were given by participants in the actor-perspective condition (M = 8.38, SEM = 2.47). Furthermore, the mean number of spatial descriptions— descriptions that coded any perspective—was equal for actor- (M = 22.25, SEM = 6.13) and observer-perspective participants (M = 21.13, SEM = 4.39), t(14) = 0.15, ns. Once again, later differences in assembly performance were due to the spatial perspective that participants encoded actions from, not to differences in attention to space more generally. Similar to Study 1a, observer-perspective participants had more difficulty maintaining their assigned perspective, six of the eight observer-perspective participants made description errors (M = 1.50, SEM = 0.87), whereas none of the eight actor-perspective participants did (Yates’ corrected Х12 = 6.67). Furthermore, five of the eight observer-perspective participants qualified their perspective (M = 0.63, SEM = 0.26), whereas none of the eight actor-perspective participants did (Yates’ corrected Х12 = 4.65).8 Also similar to Study 1a, actor-perspective participants focused more on the actor’s body than observer-perspective participants, giving more descriptions that indicated which hand, left or right, had performed an action (M = 3.00, SEM = 0.82 vs. M = 0.75, SEM = 0.37), t(14) = 2.50, d = 1.25. Actor- and observer-perspective participants did not differ in the number of times they described left or right locations on the table (M = 5.38, SEM = 2.29 vs. M = 8.25, SEM = 2.74), t(14) = -0.81, ns. As in Study 1a, the number of references to the actor’s left or right hand predicted better hierarchical encoding, as measured by enclosure, r(14) = .91, and by verbal Perspective and Action Understanding 33 summaries, r(14) = .64. The number of descriptions of the actor’s hands also positively correlated with later assembly errors, r(14) = -.69. Descriptions concerning left and right locations on the table did not predict hierarchical encoding and did not correlate with assembly performance. Finally, just as in Study 1a, references to hands fully mediated effects of perspective on enclosure scores (see the lower half of Figure 7). A linear regression analysis confirmed that assigned perspective predicted both enclosure scores, t(1) = 2.73 and hand references, t(1) = 2.50. Hand references predicted enclosure scores when controlling for assigned perspective, t(1) = 6.18, and according to a Sobel test, mediation was significant, z = 2.50. Finally, controlling for hand references, the effect of assigned perspective on enclosure scores was no longer significant, t(1) = .91, ns. Thus, references to hands fully mediated the effects of assigned perspective on hierarchical encoding. General Discussion Learning new skills through observation is not automatic, or everyone would be expert skiers, dancers, and tennis players. Nevertheless, people do acquire a wide range of complex skills through observation. This suggests that people are adept at translating tasks they see into tasks they can do. An important component to this translation appears to be segmenting and organizing an observed task into a hierarchical representation of goals and subgoals—a representation that can be implemented as an action plan (Hard, Lozano, & Tversky, in press; Zacks, Tversky, & Iyer, 2001). Here, we have proposed that taking the perspective of the actor while observing action facilitates hierarchical encoding of action and thus promotes action learning. Perspective and Action Understanding 34 The studies reported here support that hypothesis. In one study, participants observed and segmented an object assembly task while giving a verbal play-by-play of the actions from the actor’s or their own perspective. Describing actions from the actor’s perspective instead of their own led to better encoding of the hierarchical, goal-subgoal organization of those actions and better subsequent performance of those actions. A follow-up to this study showed that explicitly describing from an actor’s perspective was superior for action understanding and learning relative to freely describing, and both were superior to explicitly describing from a selfperspective. A final study showed that describing actions from any perspective other than one’s own is not beneficial: it is adopting the actor’s perspective specifically that promotes hierarchical encoding and learning. What are observers doing in the present studies when they are “taking the actor’s perspective”? There are a number of possibilities that are not mutually exclusive. It may be that observers are simply engaging in visuospatial perspective-taking—imagining where objects are located in space, relative to the actor. It may be that observers are engaging in mentalistic perspective-taking—imagining what their own goals and subgoals would be if they were executing the observed task themselves. Finally, it may be that observers are engaging in motoric perspective-taking—mapping observed actions onto a representation of their own body. Although all of these possibilities might be true, the data do seem to strongly support the idea that observers are engaging in motoric perspective-taking, or simulation: when participants described from the actor’s perspective, they spontaneously described which hand was performing certain actions. This tendency to describe which hand performed an action was associated with better hierarchical encoding, and in fact, seemed to account for the fact that actor-perspective describers encoded action more hierarchically than self- or observer-perspective describers. In Perspective and Action Understanding 35 contrast, descriptions of the location of an object in space from the actor’s perspective were not associated with hierarchical encoding. The fact that observers spontaneously described which of the actor’s hands performed an action when describing from the actor’s perspective is consistent with findings that motor simulation occurs as if observers are mapping observed actions anatomically to their own bodies. In one demonstration of this, observers viewed simple actions, such as moving toward a red dot, performed by another person’s left or right hand. When observing left hand actions, motor evoked potentials (MEPs) were larger in observers’ left hands, whereas when observing right hand actions, MEPs were larger in observers’ right hands (Aziz-Zadeh, Maeda, Zaidel, Mazziotta, & Iacoboni, 2002). Similar evidence for an anatomical mapping has been found when people observe actions performed by the feet (Cheng, Tzeng, Hung, Decety, & Hsieh, 2005). How might motor simulation explain findings from the present studies? When people try to understand actions, some form of motor simulation might be automatic, such that observers implicitly relate the actor’s body to their own. This view predicts that describing actions from the actor’s perspective, especially which hand is performing those actions, should be natural and easy. In contrast, describing actions from one’s own or another observer’s perspective should be difficult, and might impair hierarchical encoding by directly competing with it. Describing actions from a self-perspective impairs action understanding, but describing actions from the actor’s perspective also enhances it. This could mean that motor simulation can be enhanced by encouraging observers to put themselves in the actor’s shoes. Consistent with this view, instructing participants to explicitly adopt the actor’s perspective led to more descriptions about the actor’s hands than instructing participants to describe freely. Alternatively, encouraging observers to take the actor’s perspective might change the way they use their motor Perspective and Action Understanding 36 simulations for understanding observed actions and their organization (c.f., Barsalou, 1999, 2003; Wilson & Knoblich, 2005). Although motor simulation might account for the present findings, it remains to be seen whether describing actions from the actor’s perspective actually elicits neural structures involved in planning and executing actions. Future studies using TMS or fMRI methods could provide valuable insight into the nature of the perspective-taking processes observed in the present research. The powerful links shown here between perspective-taking, action understanding, and action learning thus raise many questions. For example, do benefits of adopting the actor’s perspective depend on verbalizing that perspective, or are there non-verbal means of perspectivetaking that are equally beneficial? Can taking an actor’s perspective enhance understanding and performance of other actions, in particular, the actions that are at the core of effective social behavior? Also, what really happens when observers begin to think about space, and actions performed in that space from an actor’s point of view? The present data open the intriguing possibility that spatial perspective-taking provides a window into the actor’s mind, giving observers insight into an actor’s goals, intentions, and future behaviors. Perspective and Action Understanding 37 References Arbib, M. A., & Rizzolatti, G. (1996). Neural expectations: A possible evolutionary path from manual skills to language. Communication and Cognition, 29, 393-424. Aziz-Zadeh, L., Maeda, F., Zaidel, E., Mazziotta, J., & Iacoboni, M. (2002). Lateralization in motor facilitation during action observation: A TMS study. Experimental Brain Research, 144, 127-131. Baldwin, D. A., Baird, J. A., Saylor, M. M., & Clark, M. A. (2001). Infants parse dynamic action. Child Development, 72, 708-717. Baron, R. M., & Kenny, D. A. (1986). The moderator-mediator variable distinction in social psychological research: conceptual, strategic, and statistical considerations. Journal of Personality and Social Psychology, 51, 1173-1182. Barsalou, L. W. (1999). Perceptual symbol systems. Behavioral and Bain Sciences, 22, 577-609. Barsalou, L. W. (2003). Situated simulation in the human conceptual system. Language and Cognitive Processes, 18, 513-562. Batson, C. D. (1991). The altruism question: Toward a social-psychological answer. Hillsdale, NJ: Lawrence Erlbaum Associates. Byrne, R. W., & Russon, A. E. (1998). Learning by imitation: A hierarchical approach. Behavioral and Brain Sciences, 21, 667-709. Chartrand, T. L., & Bargh, J. A. (1999). The chameleon effect: The perception–behavior link and social interaction. Journal of Personality and Social Psychology, 76, 893–910. Cheng, C. M., & Chartrand, T. L. (2003). Self-monitoring without awareness: Using mimicry as a nonconscious affiliation strategy. Journal of Personality and Social Psychology, 85, 1170-1179. Perspective and Action Understanding 38 Cheng, Y. W., Tzeng, O. J. L., Hung, D, Decety, J.,& Hsieh, J. C. (2005). Modulation of spinal excitability during observation of bipedal locomotion. Neuroreport, 16, 1711-1714. Cohen, J. D., MacWhinney, B., Flatt, M., & Provost, J. (1993). PsyScope: An interactive graphic system for designing and controlling experiments in the psychology laboratory using Macintosh computers. Behavior Research, Methods, Instruments & Computers, 25, 257271. Davis, M. H., Conklin, L., Smith, A., & Luce, C. (1996). Effect of perspective taking on the cognitive representation of persons: A merging of self and other. Journal of Personality and Social Psychology, 70, 713–726. Fadiga, L., Craighero, L., & Olivier, E. (2005). Human motor cortex excitability during the perception of others’ action. Current Opinion in Neurobiology, 15, 213-218. Galinsky, A. D., Ku, G., & Wang, C. S. (2005). Perspective-taking and self-other overlap: Fostering social bonds and facilitating social coordination. Group Processes and Intergroup Relations, 8, 109-124. Galinsky, A. D., & Moskowitz, G. B. (2000). Perspective-taking: Decreasing stereotype expression, stereotype accessibility, and in-group favoritism. Journal of Personality and Social Psychology, 78, 708–724. Grafton, S. T., Arbib, M. A., Fadiga, L., & Rizzolatti, G. (1996). Localization of grasp representations in humans by positron emission tomography, 2: Observation compared with imagination. Experimental Brain Research, 112, 103-111. Hard, B. M., Lozano, S. C., & Tversky, B. (in press). Hierarchical encoding of behavior: Translating perception into action. Journal of Experimental Psychology: General. Perspective and Action Understanding 39 Hard, B. M., Tversky, B., & Lang, D. (in press). Segmenting abstract events: Building event schemas. Memory and Cognition. Hard, B. M., Zacks, J. M., & Tversky, B. (2006). Inferring structure in behavior: the role of goals and language. Unpublished manuscript, Stanford University and Washington University in St. Louis. Hart, R. A., & Moore, G. T. (1973). The development of spatial cognition. In R. M. Downs & D. Stea (Eds.), Image and environment (pp. 246-288). Chicago: Aldine. Iacoboni, M. (2005). Understanding others: Imitation, language, empathy. In S. Hurley & N. Chater (Eds.), Perspectives on imitation: From neuroscience to social science (Vol. 1, pp. 77-100). Cambridge, MA: MIT Press. Iacoboni, M., Woods, R. P., Brass, M., Bekkering, H., Mazziotta, J. C., & Rizzolatti, G. (1999). Cortical mechanisms of human imitation. Science, 286, 2526–2528. Kenny, D. A., & Judd, C. M. (1986). Consequences of violating the independence assumption in analysis of variance. Psychological Bulletin, 99, 422-431. Lashley, K. S. (1951). The problem of serial order in behavior. In L. A. Jeffress (Ed.), Cerebral mechanisms in behavior: The Hixon Symposium (pp. 112-146). Oxford, England: Wiley. Levelt, W. J. M. (1989). Speaking: From intention to articulation. Cambridge, MA: MIT Press. Lozano, S. C., Hard, B. M., & Tversky, B. (in press). Putting action in perspective. Cognition. Martin, B. A. (2006). Reading the language of action: Hierarchical encoding of behavior. Unpublished doctoral dissertation. Stanford University. Meltzoff, A. N. (1995). Understanding of the intentions of others: Re-enactment of intended acts by 18-month-old children. Developmental Psychology, 31, 838-850. Perspective and Action Understanding 40 Newell, A., & Simon, H. A. (1972). Human problem solving. Englewood Cliffs, NJ: PrenticeHall. Newtson, D. (1973). Attribution and the unit of perception of ongoing behavior. Journal of Personality and Social Psychology, 28, 28-38. Piaget, J., & Inhelder, B. (1956). The child’s conception of space. London: Routledge and Kegan Paul. Rizzolatti, G., & Arbib, M. A. (1998). Language within our grasp. Trends in Neuroscience, 21, 188-194. Rizolatti, G., Fadiga, L., Gallese, V., & Fogassi, L. (1996). Premotor cortex and the recognition of motor actions, Cognitive Brain Research, 3, 131-141. Rizzolatti, G., Fadiga, L., Fogassi, L., & Gallese, V. (1999). Resonance behaviors and mirror neurons. Archives Italiennes de Biologie, 137, 85-100. Shelton, A. L., & McNamara, T. P. (1997). Multiple views of spatial memory. Psychonomic Bulletin and Review, 4, 102-106. Sobel, M. E. (1982). Asymptotic intervals for indirect effects in structural equations models. In S. Leinhart (Ed.), Sociological methodology (pp.290-312). San Francisco: Jossey-Bass. Travis, L. L. (1997). Goal-based organization of event memory in toddlers. In P. W. van den Broek, P. J. Bauer, & T. Bourg (Eds.), Developmental spans in event comprehension and representation: Bridging fictional and actual events (pp. 111-138). Mahwah, NJ: Lawrence Erlbaum Associates. Vandenberg, S. G., & Kuse, A. R. (1978). Mental rotations, a group test of three-dimensional spatial visualization. Perceptual and Motor Skills, 47, 599-604. Perspective and Action Understanding 41 Vorauer, J. D., & Cameron, J. J. (2002). So close, and yet so far: Does collectivism foster transparency overestimation? Journal of Personality and Social Psychology, 83, 1344– 1352. Whiten, A. (2002). The imitator’s representation of the imitated: Ape and child. In A. N. Meltzoff & W. Prinz (Eds.), The imitative mind: Development, evolution, and brain bases (pp. 98-121). Cambridge, UK: Cambridge University Press. Wilson, M., & Knoblich, G. (2005). The case for motor involvement in perceiving conspecifics. Psychological Bulletin, 131, 460-473. Zacks, J. M., Braver, T. S., Sheridan, M. A., Donaldson, D. I., Snyder, A. Z., Ollinger, J. M., Buckner, R. L., & Raichle, M. E. (2001). Human brain activity time-locked to perceptual event boundaries. Nature Neuroscience, 4, 651-655. Zacks, J. M., Tversky, B., & Iyer, G. (2001). Perceiving, remembering, and communicating structure in events. Journal of Experimental Psychology: General, 130, 29-58. Perspective and Action Understanding 42 Appendix A: Test Video Scripts The following script describes the steps followed by the actor in the TV cart assembly test video. All spatial locations mentioned in the script are described relative to the actor. Steps listed in bold italic font correspond to higher-level actions. 1. The actor places four pegs in a line at the upper left corner of table, using both hands. 2. The actor places screws in a line below the pegs, using both hands. 3. The actor places four wheels in a line below the screws, using both hands. 4. The actor places a screwdriver below the wheels, using both hands. 5. The actor places the one sideboard on the lower right corner of the table and then stacks the other sideboard on top of the first one, using both hands. 6. The actor places the support board above the stacked sideboards, using both hands. 7. The actor places the bottom shelf above the support board, using both hands. 8. The actor stacks the top shelf on top of the bottom shelf using both hands. 9. The actor picks up the top shelf, flips it upside down, and positions it in the center of the table, using both hands. 10. The actor has now finished organizing the parts on the table. 11. The actor picks up the first sideboard and positions it upright and perpendicular to the top shelf on the left side, using both hands. 12. The actor picks up a screw and inserts it to the upper left corner of the first sideboard and top shelf, using her left hand. 13. The actor picks up another screw and inserts it to the lower left corner of the first sideboard and top shelf, using her left hand. Perspective and Action Understanding 43 14. The actor picks up the screwdriver and screws in the screws she just inserted to the first sideboard and top shelf, starting with the upper left screw and then moving to the lower left screw, using her left hand. 15. The actor has now finished attaching the first sideboard. 16. The actor picks up two pegs and inserts them to the inside of the first sideboard, using her left hand. 17. The actor picks up the support board and attaches it to the pegs on the inside of the first sideboard, using both hands. 18. The actor picks up two pegs and attaches them to the right end of the support board, using her right hand. 19. The actor picks up the second sideboard and attaches it to the pegs in the right side of the support board, using both hands. 20. The actor has now finished attaching the support board. 21. The actor picks up a screw and inserts it to the upper right corner of the second sideboard and top shelf, using her right hand. 22. The actor picks up another screw and inserts it to the lower right corner of the second sideboard and top shelf, using her right hand. 23. The actor picks up the screwdriver and screws in the screws she just inserted to the second sideboard and top shelf, starting with the upper right screw and then moving to the lower right screw, using her right hand. 24. The actor has now finished attaching the second sideboard. 25. The actor picks up the bottom shelf and positions it in between the two sideboards, using both hands. Perspective and Action Understanding 44 26. The actor picks up a screw and inserts it to the upper left corner of the first sideboard and bottom shelf, using her left hand. 27. The actor picks up another screw and inserts it to the lower left corner of the first sideboard and bottom shelf, using her left hand. 28. The actor picks up the screwdriver and screws in the screws she just inserted to the first sideboard and bottom shelf, starting with the upper left screw and then moving to the lower left screw, using her left hand. 29. The actor picks up a screw and inserts it to the upper right corner of the second sideboard and bottom shelf, using her right hand. 30. The actor picks up another screw and inserts it to the lower right corner of the second sideboard and bottom shelf, using her right hand. 31. The actor picks up the screwdriver and screws in the screws she just inserted to the second sideboard and bottom shelf, starting with the upper right screw and then moving to the lower right screw, using her right hand. 32. The actor has now finished attaching the bottom shelf. 33. The actor picks up a wheel and inserts it to the upper left corner of the first sideboard, using her left hand. 34. The actor picks up a wheel and inserts it to the upper right corner of the second sideboard, using her right hand. 35. The actor picks up a wheel and inserts it to the lower right corner of the second sideboard, using her right hand. 36. The actor picks up a wheel and inserts it to the lower left corner of the first sideboard, using her left hand. Perspective and Action Understanding 45 37. The actor has now finished attaching the wheels to the cart. 38. The actor flips the now completed television cart over, so that it is now in an upright position, using both hands. 39. The TV cart is now complete. The following script describes the steps followed by the actor in the Lego® assembly test video. All spatial locations mentioned in the script are described relative to the actor. Steps listed in bold italic font correspond to higher-level actions. 1. The actor places nine yellow blocks in a vertical line on the left side of the table, using her left hand. 2. The actor places twelve red blocks in a vertical line to the right of the yellow blocks, using her left hand. 3. The actor places nine green blocks in a vertical line to the right of the red blocks, using her right hand. 4. The actor places thirteen blue blocks in a vertical line to the right of the green blocks, using her right hand. 5. The actor has now finished organizing the blocks on the table. 6. The actor stacks three small blue blocks on top of a small red block to form the first leg of a horse, using her right hand. 7. The actor stacks three small blue blocks on top of a small red block to form the second leg of a horse, using her right hand. 8. The actor connects the two legs with a large yellow block, using her right hand. Perspective and Action Understanding 46 9. The actor stacks three small blue blocks on top of the large yellow block to form the horse’s neck, using her right hand. 10. The actor places a medium blue block on top of the horse’s neck to form its nose, using her right hand. 11. The actor places a small yellow block, with a picture of an eyeball on it, on top of the horse’s nose, using her right hand. 12. The actor places a red block, shaped like a saddle, on top of the large yellow block that forms the horse’s back, using her right hand. 13. The actor places the completed horse on the right side of the table, using her right hand. 14. The blue horse is now complete. 15. The actor stacks three small green blocks on top of a small red block to form the first leg of a horse, using her left hand. 16. The actor stacks three small green blocks on top of a small red block to form the second leg of a horse, using her left hand. 17. The actor connects the two legs with a large yellow block, using her left hand. 18. The actor stacks three small green blocks on top of the large yellow block to form the horse’s neck, using her left hand. 19. The actor places a medium green block on top of the horse’s neck to form its nose, using her left hand. 20. The actor places a yellow block, with a picture of an eyeball on it, on top of the horse’s nose, using her left hand. 21. The actor places a red block, shaped like a saddle, on top of the large yellow block that forms the horse’s back, using her left hand. Perspective and Action Understanding 47 22. The actor places the completed horse on the left side of the table, using her left hand. 23. The green horse is now complete. 24. The actor connects four small blue blocks together to form a plus shape, using both hands. 25. The actor connects five small red blocks together to form a staircase shape, using both hands. 26. The actor connects five small yellow blocks together to form a staircase shape, using both hands. 27. The actor connects the yellow staircase on top of the red staircase, using her right hand. 28. The actor connects the blue plus on top of the yellow staircase, so as to form a heart, using her left hand. 29. The actor places the completed heart in between the two horses, using both hands. 30. The heart is now complete. Perspective and Action Understanding 48 Appendix B: Video Segmentation Instructions The following is the introduction to segmentation that all participants received: “Human experience is very complex. As we go about our day-to-day lives, we encounter a lot of information that we need to make sense of. One way that we do this is to break down our experiences into events. For example, when you think about your day, you think about it in terms of the events that happened, such as eating lunch or going to class. These are examples of events that you were directly involved in. You can think about all of these events on a variety of scales. For example, you can think about the day in terms of very small events, like reaching for the alarm clock, picking up a box of cereal, or dropping your keys on the floor. You can also think of the day in terms of larger events, such as eating lunch, riding to class, or attending a party. Thus, we can think about events as being as big or as small as we want. The following is the introduction to action description that all participants in Studies 1a received. Instruction differences corresponding to different assigned perspectives appear in bold font: “In this experiment we’re interested in how people understand events when thinking about them from someone else’s (their own) perspective. You will watch two videos involving a person assembling objects. We will ask you to divide this video into separate events. You will do this by using the SPACEBAR to mark off where you believe one event has ended and another event has begun. Every time you press the spacebar, please briefly state, in terms of the actor’s (your own) perspective what happened in the segment you just observed.” The following is the introduction to action description that all participants in Study 2 received. Instruction differences corresponding to different assigned perspectives appear in bold font: Perspective and Action Understanding 49 “In this experiment we’re interested in how people understand events when thinking about them from an actor’s (an observer’s) perspective. You will watch two videos involving a person assembling objects. We will ask you to divide each video into separate events. You will do this by using the SPACEBAR to mark off where you believe one event has ended and another event has begun. Every time you press the spacebar, please briefly state, in terms of the actor’s (the observer’s) perspective what happened in the segment you just observed. Perspective and Action Understanding 50 Appendix C: Calculation of Enclosure Scores Enclosure is a measure of hierarchical encoding that takes into account the conceptual relation between the boundaries of coarse units—coarse breakpoints—and the boundaries of fine units—fine breakpoints. If action is perceived hierarchically, then fine units should represent substeps of a corresponding coarse unit. For example, the fine units “she built one leg,” “she built a second leg,” “she attached the two legs to a body,” “she built the neck and head,” are substeps of the coarse unit “she built the blue horse.” Thus, if we pair a given coarse breakpoint (e.g., “she built the blue horse”) with the closest fine breakpoint in time, that fine breakpoint should represent the final substep of that coarse unit (e.g., “she built the neck and head”). When this relationship between a coarse breakpoint and its closest fine breakpoint holds true, the fine breakpoint tends to be enclosed by, that is, fall before, the corresponding coarse breakpoint. In previous studies (Hard, Lozano, & Tversky, in press), and in the current ones, when fine breakpoints are not enclosed by the corresponding coarse breakpoints, over 75% of the time they are not hierarchically related to the coarse unit. In previous studies, and in the current ones, the enclosure pattern is the dominant one: within participants, coarse breakpoints more frequently follow their closest fine breakpoint than precede it (Study 1a: paired-t(39) = 4.07, d = 0.66; Study 2: paired-t(15) = 6.06, d = 0.54). The following is an example of how the enclosure score for each participant is calculated: Step 1: Below on the left is a chronological list of the points in time (starting from the beginning of the video in ms) that a participant marked coarse and fine breakpoints. We begin by lining up each coarse breakpoint with the fine unit it is temporally closest to. The results of this are shown in the first two columns of the table below. Perspective and Action Understanding 51 Step 2: Once a coarse breakpoint is lined up with a fine breakpoint, we determine whether that coarse breakpoint fell temporally before or after the fine breakpoint. The results of this determination are shown in the final column of the table. Step 3: We now calculate the numerator of the enclosure score. We do this by first checking for cases in which multiple coarse breakpoints share (i.e., are closest to) the same fine breakpoint. For each such case, we determine which of the coarse breakpoints the fine breakpoint is in fact closest to. Only this pairing will be used in determining the participant’s enclosure score; the other pairing is excluded. In the example below, we have highlighted shared cases and the breakpoints within that count toward the final enclosure score. The numerator of the enclosure score is then equal to the total number of cases in which a coarse breakpoint fell after its nearest fine breakpoint. Thus, our example participant has an enclosure score numerator equal to 9. Step 4: Enclosure is calculated by taking the numerator calculated in Step 3 and dividing it by the total number of coarse units. In our example, the participant has a total of 16 coarse units, so we calculate the enclosure score to be 9/16 = .56. Coarse Breakpoints Fine Breakpoints 15828 33428 44606 57843 66292 71449 75351 83828 86347 90515 93472 144188 155832 190967 1630 12839 28443 37702 50078 57303 66713 70159 75655 82995 86238 91303 98414 102119 Coarse Breakpoints 15828 33428 44606 57843 66292 71449 75351 83828 86347 90515, 93472 Fine Breakpoints 1630 12839 28443 37702 50078 57303 66713 70159 75655 82995 86238 91303 98414 102119 Is coarse breakpoint before or after fine breakpoint? After Before Before After Before After Before After After Before, After Perspective and Action Understanding 52 192802 200147 108956 111892 118374 124911 138553 142889 153310 160646 173990 186743 192239 197879 144188 155832 190967, 192802 200147 108956 111892 118374 124911 138553 142889 153310 160646 173990 186743 192239 197879 After After Before, After After Perspective and Action Understanding 53 Author Note Sandra C. Lozano, Bridgette Martin Hard, and Barbara Tversky, Department of Psychology, Stanford University. We gratefully acknowledge Jane Solovyeva, Herb Clark, Jonathan Winawer, and Angela Kessell for their helpful comments, and the following grants: Office of Naval Research, Grants Number NOOO14-PP-1-O649, N000140110717, and N000140210534 to Stanford University. We also thank Cecilia Heyes and another anonymous reviewer, for their helpful comments and suggestions. Please address correspondence concerning this article to Sandra C. Lozano, at the Department of Psychology, Stanford University, Building 01-420, Jordan Hall, Stanford, CA 94305. Email: scl@psych.stanford.edu. Perspective and Action Understanding 54 Footnotes 1 Perspective-taking can take many forms, none of which are mutually exclusive. That is, perspective-taking can involve self-other overlap in the form of emotional, social, mentalistic, behavioral, or motor representations, or all of the above simultaneously. 2 Hierarchical encoding was operationalized as the proportion of coarse unit boundaries that fell after their closest fine unit boundary, a measure that correlated highly with hierarchical descriptions of the action sequence. 3 It remains an open question whether perspective-taking is driven more by seeing the self in the other or by seeing the other in the self. Regardless of the directionality of self-other overlap, the downstream consequences of perspective-taking (e.g., liking, rapport, empathy, sympathy, etc.) seem to be the same (for a discussion of this, see Galinsky et al., 2005). 4 In Study 1a, assigned perspective was dummy coded: self-perspective = 0, actor- perspective = 1. 5 When participants switched perspectives within a description (e.g., “She put a block on the left, I mean the right”) only the final utterance (e.g., “the right”) was used to determine the perspective coding for that description. This rule was applied so that participants who made perspective errors would not appear to have an inflated number of perspective descriptions. Descriptions of this type were coded as a perspective error, however. 6 The mean number of self-perspective descriptions for actor-perspective describers was not submitted to an ANOVA because it had no variance and therefore violated the normality assumption. 7 In Study 2, assigned perspective was dummy coded: observer-perspective = 0, actor- perspective = 1. Perspective and Action Understanding 55 8 Yates-corrected Chi-square tests were adopted here instead of t-tests because actor- perspective participants made no perspective errors and never qualified their perspective, resulting in a violation of the normality assumption. Perspective and Action Understanding 56 Table 1: Effects of Description Perspective on Dependent Measures in Study 1b Self-Perspective Free-Describe Actor-Perspective Enclosure .41 (.04) .59 (.05) .85 (.05) Summary Statements 0.40 (0.22) 1.70 (0.26) 3.40 (0.34) Assembly Errors 4.10 (0.46) 2.40 (0.16) 0.90 (0.27) Assembly Perspective 20% actor, 80% self 80% actor, 20% self 100% actor, 0% self Total Fine Units 22.40 (5.96) 32.30 (6.26) 33.90 (8.01) Total Coarse Units 6.50 (1.15) 7.00 (1.03) 7.70 (1.35) 2.00 (0.65) 2.40 (0.40) 15.00 (2.40) 8.60 (0.64) 0.40 (0.16) 0.00 (0.00) 13.20 (1.20) 12.00 (1.72) 11.50 (1.65) 0.25 (0.10) 0.20 (0.10) 1.48 (0.22) Actor-Perspective Statements Self-Perspective Statements Left/Right Side References Left/Right Hand References Perspective and Action Understanding 57 Figure Captions Figure 1. Still frames from the object assembly videos used in Studies 1a and 1b (top) and Study 2 (bottom). The top still frame shows the actor with the fully assembled TV cart. The bottom still frame shows the observer (right) and actor (left) with the fully assembled horses and heart. Figure 2. Mean enclosure scores (top) and number of assembly errors (bottom) in Study 1a, as a function of assigned perspective. Figure 3. The figure illustrates Baron and Kenny’s (1986) mediation technique. Standardized path coefficients are represented by a, b, c, and c’, where, a represents the association between IV and mediator; b represents the association between the mediator and the DV (when IV is also a predictor of DV); c represents the association between IV and DV; and c’ represents the association between IV and DV when controlling for the mediator. Figure 4. The figure illustrates the mediation analyses testing whether hierarchical encoding mediated the relationship between assigned perspective and assembly errors. Values have been substituted for the corresponding variables described in Figure 3. The top half of the figure corresponds to the mediation analysis for Study 1a, while the bottom half of the figure corresponds to the mediation analysis for Study 2. Figure 5. Illustration of the actor from the video (top), participants assembling from the actor’s perspective (middle) and participants assembling from a self-perspective (bottom). Figure 6. Mean proportion of description references made from each of the four spatial perspective categories, as a function of assigned perspective, for Study 1a (top), and Study 2 (bottom). Figure 7. Mediation analysis showing that references to the actor’s hands mediated effects of assigned perspective on hierarchical encoding, as measured by enclosure scores. Values have Perspective and Action Understanding 58 been substituted for the corresponding variables described in Figure 3. The top half of the figure corresponds to the mediation analysis for Study 1a, while the bottom half of the figure corresponds to the mediation analysis for Study 2. Figure 8. Mean enclosure scores (top) and number of assembly errors (bottom) in Study 2, as a function of assigned perspective. 0.8 0.6 0.4 0.2 0 Actor Self Assigned Perspective 4 Assembly Errors Enclosure Score 1 0 Actor Self Assigned Perspective Proportion of References 1 0.8 None Neutral Self Actor 0.6 0.4 0.2 0 Actor Self Proportion of References Assigned Perspective 1 0.8 None Neutral Observer Actor 0.6 0.4 0.2 0 Actor Observer Assigned Perspective Enclosure Score 1 0.8 0.6 0.4 0.2 0 Actor Observer Assigned Perspective Assembly Errors 16 12 8 4 0 Actor Observer Assigned Perspective