Within-Subjects ANOVA Example
advertisement

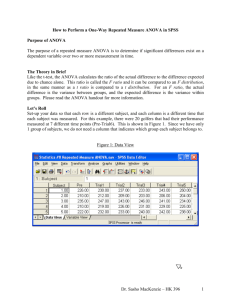
Newsom USP 634 Data Analysis I Spring 2013 1 Within-Subjects ANOVA General Comments As with the rationale for the paired t-test, the within-subjects ANOVA is used under similar circumstances. The within-subjects ANOVA, however, is more general than the paired t-test in that it also can be used with more than two repeated measures. The within-subjects ANOVA is appropriate for repeated measures designs (e.g., pretest-posttest designs), within-subjects experimental designs, matched designs, or multiple measures. It is sometimes difficult to understand that two dependent measures (e.g., the DV at pretest and posttest) function as two “levels” of the independent variable. So, for instance, in the case of the pretest-posttest design the independent variable is “time.” Within-subjects designs have advantages over between-subjects designs, because, in general, they have greater power to detect significance. The fact that each participant serves as his or her own control (or there is a related other used as a control) leads to the advantage of eliminating variance due specifically to individual differences. Thus, the error term used in within-subjects ANOVA is a more precise one, because individual differences have been removed from it. The separate estimation of variance due to individual differences is explicit in the sum of squares for subject (SSS). Most of the other general procedures are similar to what we have done before. Definitional Formulas The only new quantity in these formulas is SSS, which is the sum of squares for subject. This is computed by finding the mean score for each case (averaging across rows of the data). SSs represents individual variation. Individual variation is thus a function of variation of average scores for an individual around the average of all scores for the sample, SST. Source A S AxS SS = SS A n∑ (Y. j − Y.. ) = SS S a ∑ (Yi. − Y.. ) = SS AxS df 2 a −1 2 n −1 ∑∑ (Y − Y i. − Y. j + Y.. ) or SS AxS = SST − SS A − SS S T = SST ∑ (Y ij − Y.. ) 2 2 ( a − 1)( n − 1) ( a )( n ) MS F SS A df A SS MS S = S df s SS MS AxS = AxS df AxS FA = MS A = MS A MS AxS Newsom USP 634 Data Analysis I Spring 2013 2 Example Consider a hypothetical example in which non-native English speaking students are tested before and after the implementation of an “immersion” approach to teaching proficiency in English to eight students. Thus, we test students on a language usage scale (say with values from 1-10) during the traditional bilingual education program and then after the conversion to immersion. 1 Yij − Y.. (Y .5 -.5 2.5 1.5 2.5 -.5 -1.5 -.5 .25 .25 6.25 2.25 6.25 .25 2.25 .25 Student Bilingual 1 2 3 4 5 6 7 8 4 3 6 5 6 3 2 3 ij − Y.. ) Immersion 2 2 3 4 5 4 3 2 1 Y.1 = 4 Yij − Y.. (Y -1.5 -.5 .5 1.5 .5 -.5 -1.5 -2.5 2.25 .25 .25 2.25 .25 .25 2.25 6.25 ij − Y.. ) 2 Yi. Yi. − Y.. (Y 3 3 5 5 5 3 2 2 -.5 -.5 1.5 1.5 1.5 -.5 -1.5 -1.5 .25 .25 2.25 2.25 2.25 .25 2.25 2.25 i. − Y.. ) ∑ (Y Y.2 = 3 i. 2 − Y.. ) = 12 2 Y.. = 3.5 2 2 SS A= n∑ (Y. j − Y.. ) = 8 ( 4 − 3.5 ) + ( 3 − 3.5 ) = 4 2 SS S = a ∑∑ (Yi. − Y.. ) = 2 [.25 + .25 + 2.25 + + 2.25 + 2.25] = 24 2 SS AxS = SST − SS A − SS S = 32 − 24 − 4 = 4 SST = 32 ( 4 − 3.5) + ( 3 − 3.5) + + ( 2 − 3.5) + (1 − 3.5) = ∑ (Yij − Y.. ) = 2 2 2 Source A (Language Program) SS 4 df S 24 n −1 = 8 −1 = 7 AxS 4 1) (1)(= 7) ( a − 1)( n −= T 32 Fcrit ( df= 1, df AxS= A 2 a −1 = 2 −1 = 1 2 )( 8 ) ( a= )( n ) (= 7= ) 5.59 MS F SS A 4 = = 4 df A 1 SS S 24 MS= = = 3.4 S df s 7 SS AxS 4 MS AxS= = = .57 df AxS 7 = FA MS A= 7 2 MS A 4 = = 7.02 MS AxS .57 16 Language usage scores were significantly higher when students received bilingual education, F(1,7)=7.01, p<.05. The average difference between language scores when students were in the bilingual versus the immersion program was 1.00. 1 As discussed earlier in the course, this kind of pretest-posttest design with only one group is subject to many potential threats to internal validity, so it is not a very good research design. Newsom USP 634 Data Analysis I Spring 2013 3 Analyze General Linear Model Repeated Measures SPSS Output General Linear Model Within-Subjects Factors Measure: MEASURE_1 langprog 1 2 Dependent Variable biling immerse Tests of Within-Subjects Effects Measure: MEASURE_1 Source langprog Error(langprog) Type III Sum of Squares 4.000 4.000 4.000 4.000 4.000 4.000 4.000 4.000 Sphericity Assumed Greenhouse-Geisser Huynh-Feldt Lower-bound Sphericity Assumed Greenhouse-Geisser Huynh-Feldt Lower-bound df 1 1.000 1.000 1.000 7 7.000 7.000 7.000 Mean Square 4.000 4.000 4.000 4.000 .571 .571 .571 .571 F 7.000 7.000 7.000 7.000 Sig. .033 .033 .033 .033 Tests of Within-Subjects Contrasts Measure: MEASURE_1 Source langprog Error(langprog) langprog Linear Linear Type III Sum of Squares 4.000 4.000 df 1 7 Mean Square 4.000 .571 F 7.000 Tests of Between-Subjects Effects Measure: MEASURE_1 Transformed Variable: Average Source Intercept Error Type III Sum of Squares 196.000 24.000 df 1 7 Mean Square 196.000 3.429 F 57.167 Sig. .000 Sig. .033