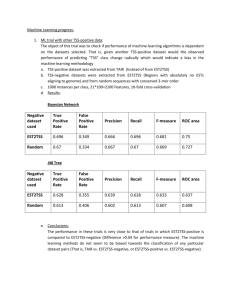
Concept Boundary Detection for Speeding up SVMs
advertisement

Concept Boundary Detection for Speeding up SVMs
panda@cs.ucsb.edu
Navneet Panda
Dept. of Computer Science, UCSB, CA 93106, USA
Edward Y. Chang
Dept. of Electrical and Computer Engg., UCSB, CA 93106, USA
echang@ece.ucsb.edu
Gang Wu
Dept. of Electrical and Computer Engg., UCSB, CA 93106, USA
gwu@engineering.ucsb.edu
Abstract
Support Vector Machines (SVMs) suffer from
an O(n2 ) training cost, where n denotes the
number of training instances. In this paper,
we propose an algorithm to select boundary
instances as training data to substantially reduce n. Our proposed algorithm is motivated
by the result of (Burges, 1999) that, removing non-support vectors from the training set
does not change SVM training results. Our
algorithm eliminates instances that are likely
to be non-support vectors. In the conceptindependent preprocessing step of our algorithm, we prepare nearest-neighbor lists for
training instances. In the concept-specific
sampling step, we can then effectively select
useful training data for each target concept.
Empirical studies show our algorithm to be
effective in reducing n, outperforming other
competing downsampling algorithms without
significantly compromising testing accuracy.
1. Introduction
Support Vector Machines (SVMs) (Vapnik, 1995) are
a core machine learning technology. They enjoy strong
theoretical foundations and excellent empirical successes in many pattern-recognition applications. Unfortunately, SVMs do not scale well with respect to the
size of training data. Given n training instances, the
time to train an SVM model is about O(n2 ). Consider
applications such as intrusion detection, video surveillance, and spam filtering, where a classifier must be
Appearing in Proceedings of the 23 rd International Conference on Machine Learning, Pittsburgh, PA, 2006. Copyright 2006 by the author(s)/owner(s).
trained quickly for a new target concept, and on a
large set of training data. The O(n2 ) training time
can be excessive rendering SVMs an impractical solution. Even when training can be performed offline,
when the amount of training data and the number
of target classes are large (e.g., the number of document/image/video classes on desktops or on the Web),
the O(n2 ) computational complexity is not acceptable.
The goal of this work is to develop techniques to reduce n for speeding up concept-learning without degrading accuracy. (We contrast our approach with
others’ in Section 2.) We propose a technique to identify instances close to the boundary between classes.
(Burges, 1999) shows that if all non-support vectors
are removed from the training set, the training result
is exactly the same as that of using the whole training
set. Our boundary-detection algorithm aims to eliminate instances most likely to be non-support vectors.
Using only the boundary instances can thus substantially reduce the training data size, and at the same
time achieve our accuracy objective.
Our boundary-detection algorithm consists of two
steps: concept-independent preprocessing, and conceptspecific sampling. The concept-independent preprocessing step identifies the neighbors for each instance.
This step incurs a one-time cost, at worst O(n2 ), and
can absorb insertions and deletions of instances without the need to reprocess the training dataset. Once
the preprocessing has been completed, the conceptspecific sampling step prepares training data for each
target concept. For a given concept, this step determines its boundary instances, reducing the training
data size substantially. Empirical studies show that
our boundary-detection algorithm can significantly reduce training time without significantly affecting classprediction accuracy.
Concept Boundary Detection for Speeding up SVMs
2. Related Work
Prior work in speeding up SVMs can be categorized
into two approaches: data-processing and algorithmic.
The data-processing approach focuses on training-data
selection to reduce n. The algorithmic approach devises algorithms to make the QP solver faster (e.g.,
(Osuna et al., 1997; Joachims, 1998; Platt, 1998;
Chang & Lin, 2001; Fine & Scheinberg, 2001)). Our
approach falls in the category of data processing, and
hence we discuss related work only in this category.
To reduce n, one straightforward data-processing
method is to randomly down-sample the training
dataset. Bagging (Breiman, 1996) is a representative sampling method, which enjoys strong theoretical
backing and empirical success. However, the random
sampling of bagging may not select the most effective training subset for each of its bags. Furthermore,
achieving high testing accuracy usually requires a large
number of bags. Such a strategy may not be very productive in reducing training time.
The cascade SVMs (Graf et al., 2005) are another
down-sampling method. It randomly divides training
data into a number of subsets, with each one being
trained using one SVM. Instead of training only once,
the cascade SVMs uses a hierarchical training structure. At each level of the hierarchy, the training data
are the support vectors obtained in the previous iteration or hierarchical level. The same strategy is repeated until the final level (with only one SVM classifier) is reached. The support vectors obtained at the
final level are then cycled to the leaf nodes hence completing the cycle. The advantage of cascade SVMs over
the bagging method is that it may have fewer support
vectors at the end of the training, favorably impacting
the classification speed. Both cascade SVMs and bagging can benefit from parallelization but so can aspects
of the approach developed in this paper.
Instead of performing random sampling on the training set, some “intelligent” sampling techniques have
been proposed to perform down-sampling (Smola &
Schölkopf, 2000; Pavlov et al., 2000; Tresp, 2001).
Recently, (Yu et al., 2003) uses a hierarchical microclustering technique to capture the training instances
that are close to the decision boundary. However,
since the hierarchical micro-clusters would not be isomorphic to the high-dimensional feature space, such a
strategy can be used only for a linear kernel function
(Yu et al., 2003). Another method is Information Vector Machines (IVMs) (Lawrence et al., 2003), which
attempts to address the issue by using posterior probability estimates of the reduction in entropy to choose
a subset of instances for training.
Our boundary-detection algorithm complements the
algorithmic approach (such as SMO) for speeding up
SVMs. Comparing our approach to representative
data-processing algorithms, we show empirically that
our boundary-detection algorithm achieves markedly
better speedup over both bagging and IVMs.
3. Boundary Identification
Our proposed algorithm comprises two stages:
concept-independent preprocessing and concept-specific
sampling. The first step is concept-independent, thus
allowing for learning different concepts at a later stage.
The second step is concerned with the actual selection
of a relevant subset of the instances once the concept
of interest has been identified. Following the selection
of the subset, the relevant learning algorithm (SVMs)
is applied to obtain the classifier.
We assume the availability of a large corpus of training instances for preprocessing. This does not preclude
the addition or removal of instances from the dataset,
as we explain at the end of Section 3.1. The same
dataset is used for learning multiple concepts defined
by varying labels. For each concept, a classifier must
be learned to classify unseen instances. Thus, if we use
SVMs as the classifier algorithm, multiple hyperplanes
would need to be learned, one for each class. Essentially, the second step dictates the reuse of the training
dataset with varying labels. Such a scenario is common in data repositories where the data is available for
preprocessing with periodic updates adding/removing
instances.
3.1. Concept-independent Preprocessing
The first preprocessing step is performed only once for
the entire dataset. This concept-independent stage determines the set of nearest neighbors of each instance.
At the end of this stage, we have a data structure
containing the indexes and distances of the k nearest
neighbors of every instance in the dataset.
Computing the nearest neighbors of every instance in
the dataset can be an expensive operation for large
datasets. Given n training instances, naive determination of nearest neighbors takes O(n2 ) time. However,
if only an approximate set of k nearest neighbors will
suffice, then relatively efficient algorithms are available in database literature. One such approach, locality sensitive hashing (LSH) (Gionis et al., 1999), has
been shown to be especially useful in obtaining approximate nearest neighbors with high accuracy1 . Recent
1
Increasing the number of hash functions considerably
reduces the error rate. Though the computational cost
increases with increase in the number of hash functions,
Concept Boundary Detection for Speeding up SVMs
More specifically, a family of functions is called
locality-sensitive if, for any two instances, the probability of collision decreases as the distance between
them increases. In essence, LSH uses multiple hash
functions, each using a subset of the features, to map
instances to buckets (A similar idea is used in (Achlioptas et al., 2002) to approximate inner products between instances). For every instance xi whose approximate nearest neighbors are sought, LSH uses the same
hash functions to map the instance to buckets. All
instances in the dataset mapping to the same buckets are then examined for their proximity to xi . Interested readers are referred to (Gionis et al., 1999)
for details on LSH. The total cost of determining the
neighborhood list for all n instances is O(n m), where
m is the average number of instances mapping into
the same bucket, and typically m << n. The structure containing the k approximate nearest neighbors
of each instance is obtained by examining the buckets to which each instance hashes. Since this stage is
label-independent, its cost is a one-time expense for
the entire dataset.
1
0.8
Score
work by (Liu et al., 2005) has shown vast improvements in performance over LSH. We reiterate that any
such approximate-NN approach may be used to determine the neighborhood lists of all instances.
0.6
0.4
0.2
0
τj
Distance
Figure 1. Plot of Scoring Function
yi ∈ {−1, 1}. Let xi and xj be instances from different classes (i.e., yi 6= yj ). Let kNN(xj ) be the
top-k nearest-neighbor list of instance xj . When we
specifically refer to the k th nearest neighbor of xj ,
we use the notation of kNNk (xj ). When we express
xi ∈ kNN(xj ), we say that instance xi is on the the
top-k neighborhood list of xj . Let c(xi , xj ) denote the
score accorded to xi by xj and τj be the square of the
distance from xj to the closest instance of the opposite
class on its neighborhood list. Our proposed scoring
function is given by
c(xi , xj ) = exp(−
k xi − xj k22 −τj
).
γ
(1)
3.2. Concept-specific Sampling
The parameter, γ, for the exponentially decaying scoring function is the mean of k xi −xj k22 −τj . The exponential decay is just one possible choice for the scoring
function and is used because of the ease of parameter
determination. The score accorded to xi by xj has the
maximum value, 1, when it is the first instance of the
opposite class in the neighborhood list of xj . The score
decays exponentially as the proximity to the instance
xj decreases. Figure 1 shows the variation of the scores
with increase in distance from the instance. The peak
occurs at the distance of the nearest neighbor from the
opposite class and then decreases continuously.
The second step is the concept-dependent stage where,
given the class labels of the instances, a subset of the
instances is selected to be used as input for the learning
algorithm. We adopt the idea of continuous weighting
of instances, based on their proximity to the boundary, to develop a scoring function for instances. The
objective of the scoring function is to accord higher
scores to instances closer to the boundary between the
positive and negative classes.
In order to obtain the cumulative score of xi , we
sum over the contributions of all oppositely labeled
instances with xi in their neighborhood lists. Normalization by the number of contributors (#xi ) is necessary to avoid issues arising from variations in density
of data instances. The normalized score, Sxi , is given
by
X
1
c(xi , xj ),
(2)
Sxi =
# xi
Given the training data vectors {x1 . . . xn } in space
X ⊆ R d , for a specific target concept, we also know
the labels {y1 . . . yn } of the training instances where
where, #xi is the number of instances with xi ∈
kNN(xj ) and yi 6= yj .
Insertions and Deletions: Insertion of a new instance into the dataset involves computing the buckets to which it hashes. The neighborhood list of the
new instance is formed by examining the proximity of
instances in the dataset mapping to the same buckets.
Also, the neighborhood lists of only the instances in
the mapped buckets may change upon addition of the
new instance. Deletion of instances is noted by setting
a flag.
this cost is much lower than the cost of the brute force
algorithm. Our experiments did not show a significant difference in overall accuracy using LSH.
xj s.t. xi ∈kNN(xj )
Let us use an example in Figure 2 to illustrate how
the concept-specific step works. In the figure, the positive instances are enclosed within the solid curve, and
the negative instances lie outside. For the purpose
Concept Boundary Detection for Speeding up SVMs
−
−
−
−
−
−
−
−
−
+
−
x2
−
−
−
+
_
x2
+
+
+
−
−
x3
−
−
−
+
+
−
−
−
−
Notation
n
= # of instances in dataset
k
= # of nearest neighbors
Sx i
= Normalized score of instance xi
#xi = # of contributors to the score of instance xi
kNNk (xi )= k th nearest neighbor of instance xi
Dxj i = Squared distance between xi and kNNj (xi )
−
−
−
−
−
−
−
−
−
−
−
−
+
+
+
−
−
x+1
_
x1
−
_
+
x+3 +
−
+
+
+
+
− −
−
+
+
−
−
−
−
−
−
−
−
−
−
−
−
−
−
Figure 2. Functioning of the Scoring Function
of demonstration, we pick three of the positive in+
+
stances x+
1 , x2 , x3 and three of the negative instances
−
−
−
x1 , x2 , x3 . These instances are placed at varying distances from the boundary and from each other. Analyzing the scores accorded to the positive instances
−
+
+
x+
1 , x2 , x3 by the negative instance x1 , we see that
the maximum increment in their respective scores is re+
ceived by the nearest neighbor, x+
3 , and then x2 and
+
x1 . Considering only instances of the opposite class in
the neighborhood list, instances towards the top of the
list tend to enjoy a higher normalized scores. Since the
objective is to prune out instances far from the boundary, selection of instances based on their normalized
score helps us obtain the desired subset. Similar rea−
soning applies to the higher scores of x−
1 and x2 when
−
compared with the score of x3 .
The process of scoring involves every instance examining its neighborhood list for instances of the opposite
class and then computing scores. Since the values of
the distances of the nearest neighbors have also been
stored in the neighborhood lists, the values of τj and
k xi − xj k2 are already available. Figure 3 presents
the steps of the scoring algorithm for reference.
procedure Determine Scores
Input : n, k, X, y
Output : S
/* Determine exponential decay parameter γ */
γ=0
counter = 0
for i = 1 to n
nearest-opposite-neighbor-found = false
for j = 1 to k
if yi 6= ykNNj (xi )
if (!nearest-opposite-neighbor-found)
nearest-opposite-neighbor-found = true
τi = Dxj i
γ = γ + Dxj i − τi
counter = counter + 1
γ = γ/counter
/* Determine the scores of instances */
for i = 1 to n
nearest-opposite-neighbor-found = false
for j = 1 to k
if yi 6= ykNNj (xi )
if (!nearest-opposite-neighbor-found)
nearest-opposite-neighbor-found = true
τi = Dxj i
SkNNj (xi ) + =exp(−
#kNNj (xi ) ++
for i = 1 to n
Sxi = Sxi /#xi
return S
j
−τi
Dx
i
γ
)
Figure 3. Computation of Scores
As can be seen in Figure 3, the outer loop iterates over
all instances in the dataset and the inner loop over the
nearest neighbors of each instance. Since we have assumed that the number of instances on the neighborhood list is k, the total cost of the operation is O(n k).
Since k is a relatively small constant compared to n,
this is linear with respect to the number of instances
in the dataset. The obtained scores of the instances
are then sorted and a subset of the training instances
is selected with a preference towards instances with
higher scores. Sorting the instances on scores adds
an additional cost of O(n log n). This stage takes
O(n k + n log n) time.
neighborhood lists does not come into play at the concept learning stage and is amortized over all concepts
in the dataset. These concepts include the concepts
already formulated and the concepts which may be
formulated using the dataset instances in the future.
The underlying assumption is that the number of concepts in the dataset, L, is large. The amortized cost of
2
n
forming the neighborhood list is given by O( n log
)
L
n m+n m log m
) using
using the naive algorithm and O(
L
LSH.
Note that, the neighborhood lists have already been
constructed at the end of the concept-independentpreprocessing step (performed only once for the entire dataset) and do not need to be reconstructed on a
per-concept basis. Thus, the cost of constructing the
The scoring algorithm devised above is partial to outliers in that, outliers almost certainly receive high
scores. However, indications of an instance being an
outlier can be obtained by examining its neighborhood
list. For example, in a balanced dataset, an instance
Concept Boundary Detection for Speeding up SVMs
whose list is made up of more than 95% instances from
the opposite class is with high probability an outlier
that can be removed from consideration.
3.3. Selection of Subset Size
Having obtained the scores of instances in the dataset,
we now need to prune out instances based on their
scores. We outline two strategies for the choice of the
number of instances.
The first strategy leaves the choice of the number of
instances to be chosen with the user. Given the computational resources available, a user may choose the
number of instances that form the subset. Assuming a
worst-case behavior of the learning algorithm (in case
of SMO the worst case behavior has been empirically
demonstrated to be O(n2.3 ) (Platt, 1998)), the number of instances forming the subset can be suitably
picked. The actual instances are then chosen by picking the required number of instances with the highest
scores.
The second strategy involves using the distribution of
the scores of the instances to arrive at the size of the
subset. We first obtain the sum, G, of the
Pn sorted scores
of all instances in the dataset (G = i Sxi ). Then,
starting with the instance with the highest score, we
keep picking instances till the sum of the scores of selected instances is within a pre-specified percentage
of G, the goal being to select instances contributing
significantly to the overall score. In the section evaluating the performance of our approach (Section 4), we
present performance measures with multiple percentage choices.
Example functioning of the boundary detection algorithm is presented on three toy datasets in Figures 4,
5, and 6. In all the dataset figures, the first figure
presents the distributions of the positive and negative instances (indicated by separate colors) and the
second figure presents the boundary instances picked.
The first dataset demonstrates the boundary for instances derived from two different normal distributions. The second dataset consists of points generated randomly and labeled according to their distances
from pre-chosen circle centers. The third dataset consists of a 4 by 4 checkerboard. The data instances
were generated randomly and labeled according to the
basis of the square occupied by them. The average
number of instances selected is about 10% of the original dataset size in each of the cases. These are toy
datasets in 2D; results for higher-dimensional datasets
are presented in the section presenting experimental
validation (Section 4).
4. Experiments
We performed experiments on five datasets (details follow shortly) to evaluate the effectiveness of our approach. The objectives of our experiments were
• to evaluate the speedup obtained,
• to evaluate the effects of parameters k and G on
our algorithm, and
• to evaluate the quality of the classifier using our
algorithm.
All our experiments were performed using the Gaussian RBF kernel exp(−ψ k xi − xj k22 ). The parameters used for the datasets (chosen on the basis
of experimental validation) are reported in Table 1.
The training of SVMs was performed using SVMLight (Joachims, 1999). The value of k was set to
100 in all the experiments. We also present results
for experiments with other values of k ranging over
200, 300, 400, 500 and 600 for the Mnist dataset. The
choice of k = 100 lowers both storage and processing
costs while retaining reasonable accuracy levels. We
show that that a larger k may not be helpful in improving classification accuracy. We report average results over five runs. The experiments were performed
on a Linux machine with a 1.5GHz processor and 1GB
DRAM. The quality measures used in our experiments
are accuracy (percentage of correct predictions), and
traditional precision/recall.
Dataset
ψ
Training
Testing
Table 1. Dataset Details
Mnist
1.666
60000
10000
Letter
9.296
16000
4000
25K
0.1666
18729
6271
Corel
0.111
42386
8260
4.1. Datasets
The Mnist dataset (LeCun et al., 1998) consists of
images of handwritten digits. The training set contains 60, 000 vectors each with 576 features. The test
set consists of another 60, 000 images. However, instead of the entire test set, we used 10, 000 instances
for evaluation as in (LeCun et al., 1998).
The letter-recognition dataset available in the UCI
repository consists of feature descriptors for the 26
capital letters of the English alphabet. Of the 20, 000
instances in the dataset, 16, 000 were randomly chosen
as the training set, with the rest forming the test set.
The 25K-image dataset contains images gathered
from both web sources and the Corel image collection categorized into over 400 categories. Of these,
we present results for the 12 largest categories. 75%
of the dataset was used as the training set while the
remaining instances served as the test set.
Concept Boundary Detection for Speeding up SVMs
Figure 5. Circular +ve Class
The Corel and Corbis (http://pro.corbis.com)
datasets contain about 51K and 315K images respectively. The categories in the two datasets number more
than 500 1, 100 respectively. Images in some related
categories in the Corel dataset were grouped together.
The details of the groupings and the top categories
chosen for evaluation are presented in Table 2. Feature extraction yielded a 144-dimension feature vector
representing color and texture information for each image. 15% of the dataset was randomly chosen as the
test set with the rest being retained as the training
set.
Table 2. Corel Categories
0 :
3 :
6 :
9 :
12:
Asianarc
Flora
Magichr
Objects(I-VIII)
Water
1 :
4 :
7 :
10:
13:
Ancient Architecture
Architecture(I-X)
Museums
Textures
Coastal
2 :
5 :
8 :
11:
14:
Food
Landscape
Old Buildings
Urban
Creatures(I-V)
4.2. Results
We report the results of our experiments on the Mnist
dataset in Table 3 and Figures 7 to 10. Figure 7
presents the variation of the accuracy with different
choices of percentages of G. After computing the total sum, G, of the scores of all instances, the subset
was determined by choosing instances making up the
top 30, 50, 70, 80, 90 and 99% of G. The 100% curve
presents the performance using SVMs on the entire
training set. Figures 8 and 9 present precision and recall figures with only the higher percentages (> 70%).
Figures 10 and 11 present the variation of speedup
with the different percentages. These figures show
that when G > 70%, the training data selected by
our boundary-detection algorithm can achieve about
the same testing accuracy compared to using the entire dataset for training. When taking the conceptindependent preprocessing (first step) time into consideration, our algorithm can achieve an average of
five time speedup. When we do not consider the preprocessing time, the speedup can exceed ten times.
Table 3 details the results for G = 80% on the Mnist
dataset. In the table, we compare our approach with
bagging and IVM. The table presents qualitative comparisons for the accuracy, precision and recall achieved
by the proposed technique as compared to SVMs on
entire dataset. Comparisons of the number of support
Figure 6. Checkerboard
vectors selected indicate that the classification time of
unseen instances using our approach would always be
smaller. The table also presents timing comparisons
where the time taken by SVMs on the entire dataset
is compared with our approach. For our approach,
we present both the time taken for SVM learning on
subset (TL ), and the time taken to obtain the subset (TB ). Speedup computations are performed after
summing up TL , TB and the amortized list construction time (≈ 93s). Experiments with bagging indicate
that, to attain the same levels of accuracy multiple
bags need to be used and the cumulative training time
for these bags is comparable to the time taken by the
SVM learning algorithm on the entire dataset. Our approach achieves much higher speedup than IVM. The
accuracy levels in all the cases are comparable to the
accuracy levels of SVMs on the entire training dataset.
To understand the speedup values obtained we examined the decay of the scores of instances in the case
of Mnist digit 0. Figure 12 shows the variation of the
sorted scores of instances with the fraction of instances
chosen on the x-axis and the score on the y-axis. We
also present an exponential fit to the data. As can
be seen from the figure, the sorted scores of instances
show a roughly exponential decay. Such a decay helps
in limiting the number of instances picked, even when
we select instances with sum of scores within a high
percentage of the respective sum G.
1
Score
Exponential Fit
0.9
Normalized Score
Figure 4. Gaussian Classes
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
Instance / Num-data
Figure 12. Mnist Digit 0 Dataset
Results with k values ranging from 200 to 600 are
presented in Figure 13. The accuracy figures remain
almost unaltered when compared to the figures for
Concept Boundary Detection for Speeding up SVMs
100
99.95
99.9
99.9
99.8
99.85
99.8
99.6
99.4
Accuracy
99.6
99.5
99.4
99.75
99.7
30
50
70
80
99.3
99.2
0
2
4
6
8
Precision
99.8
99.7
Accuracy
100
80
90
99
100
98.8
99.6
98.6
99.55
98.4
2
4
6
8
12
70
80
90
99
100
4
99
10
8
Speedup
98.5
98
97.5
97
10
5
2
6
8
0
10
0
2
4
Digit
6
8
10
0
30
50
70
80
90
99
0
2
Digit
Figure 9. Recall (Mnist)
10
15
4
4
8
20
6
96.5
6
Figure 8. Precision (Mnist)
30
50
70
80
90
99
Speedup
99.5
2
2
Digit
Figure 7. Accuracy Results(Mnist)
0
0
10
Digit
100
96
70
80
90
99
100
98.2
0
Digit
Recall
99
99.65
99.5
10
99.2
4
6
8
10
Digit
Figure 10. Speedup (Mnist)
Figure 11. Speedup w/o Stg. 1
Table 3. Results for Mnist Dataset (SVM on whole dataset, Subset within 80% of G) (CBD – Our approach, T L – Time
taken by learner on subset, TB – Time taken for score evaluation, CBD* – Speedup without list construction cost)
Accuracy
SVM
CBD
99.93
99.92
99.89
99.89
99.79
99.78
99.80
99.83
99.80
99.78
99.82
99.84
99.82
99.80
99.75
99.75
99.74
99.68
99.55
99.56
#
0
1
2
3
4
5
6
7
8
9
Precision
SVM
CBD
100.00
99.80
99.65
99.65
99.51
99.61
99.50
99.60
99.49
99.28
99.66
99.77
99.68
99.26
99.41
99.02
99.79
99.89
99.39
99.39
Recall
SVM
CBD
99.29
99.39
99.38
99.38
98.35
98.26
99.51
98.71
98.47
98.47
98.32
98.43
98.43
98.64
98.15
98.54
97.54
96.82
96.13
96.23
|SV |
SVM
CBD
2215
896
1772
775
3156
1897
2915
2004
2784
1552
2960
1735
2142
1093
2801
1630
3217
2225
2829
2175
99.95
99.9
99.85
99.8
99.75
99.7
99.65
99.6
99.55
99.5
200
300
400
500
600
5
4
Speedup
Accuracy
k = 100, while the speedup figures dip because of the
extra processing needed.
200
300
400
500
600
0
3
2
1
1
2
3
4
5
6
7
8
9
0
0
1
2
3
Digit
4
5
6
7
8
9
Digit
100
99.8
99.6
99.4
99.2
99
98.8
98.6
98.4
98.2
3.5
Speedup
T(sec)
TL
15.88
15.09
98.65
111.12
70.78
93.19
23.41
75.23
159.97
121.54
TB
59.33
56.87
55.84
56.85
55.85
57.69
56.94
83.08
56.39
83.12
Bagging
1.12
1.05
1.15
1.14
1.07
1.15
1.05
1.13
1.19
1.21
Speedup
IVM
CBD
2.04
6.15
2.02
5.14
1.76
5.92
1.68
5.32
2.02
5.88
1.57
5.68
1.98
5.97
2.03
5.09
1.93
4.69
1.42
4.33
CBD*
14.79
11.58
9.37
8.17
10.06
9.07
12.67
7.98
6.64
6.23
Similar experiments were also performed with the
Letter-recognition, the 25K-image and the image
datasets. Because of space limitations, we present only
results with the highest percentage (99% of G) of selected instances for these datasets. Figure 14 presents
the variation of the accuracy and speedup over the
26 different categories in the letter-recognition dataset
(We include concept-independent preprocessing time
in all cases). Figures 15, 17 and 16 present the results
over different categories of the image datasets. Average speedup values for these datasets were about 3.5,
3 and 10 times respectively. Accuracy results for both
the datasets were close to those obtained by SVMs on
the entire dataset.
3
Speedup
Accuracy
Figure 13. Accuracy and Speedup Variation with k (Mnist)
SVM
1112.44
833.93
1447.90
1372.72
1273.93
1369.26
1018.45
1264.60
1438.34
1276.75
5
10
15
Class
2
1.5
Subset
Original
0
2.5
20
25
1
0
5
10
15
Class
20
Figure 14. Accuracy & Speedup (Letter-recognition)
25
Our experiments indicate that over all the categories
in each of the datasets, our proposed approach attains
speedup over the SVM training algorithm while retaining reasonably high accuracy levels. Experiments
over diverse choices of k and percentages of G indi-
Concept Boundary Detection for Speeding up SVMs
99.8
99.6
99.4
99.2
99
98.8
98.6
98.4
98.2
98
5
Subset
SVM
Speedup
4.5
4
Speedup
Accuracy
cate that the proposed technique is not very sensitive
to the choices of these parameters and even a small
neighborhood list of 100 instances suffices.
3
2.5
2
2
4
6
8
10
1
12
0
2
4
Class
6
8
10
12
Class
7
Subset
SVM
5
4
3
2
0
2
4
6
8
10
12
1
14
0
2
4
Class
6
8
10
12
14
Class
Speedup
12
Speedup
Accuracy
14
Subset
SVM
10
8
6
4
2
0
5
10 15 20 25 30 35 40
Class
0
0
5
10
15
20
25
30
Joachims, T. (1998). Making large-scale svm learning practical. Advances in Kernel Methods - Support Vector
Learning.
Joachims, T. (1999). Making large-scale svm learning practical. Advances in Kernel Methods - Support Vector
Learning. MIT-Press.
Figure 16. Accuracy & Speedup (Corel)
99.8
99.7
99.6
99.5
99.4
99.3
99.2
99.1
99
98.9
Gionis, A., Indyk, P., & Motwani, R. (1999). Similarity
search in high dimensions via hashing. The VLDB Journal (pp. 518–529).
Graf, H. P., Cosatto, E., Bottou, L., Dourdanovic, I., &
Vapnik, V. (2005). Parallel support vector machines:
The cascade svm. In L. K. Saul, Y. Weiss and L. Bottou (Eds.), Advances in neural information processing
systems 17, 521–528. MIT Press.
Speedup
6
Speedup
Accuracy
Figure 15. Accuracy & Speedup (25K)
99.8
99.6
99.4
99.2
99
98.8
98.6
98.4
98.2
98
97.8
Chang, C.-C., & Lin, C.-J. (2001). LIBSVM: a library for support vector machines. Software available at
http://www.csie.ntu.edu.tw/ cjlin/libsvm.
Fine, S., & Scheinberg, K. (2001). Efficient SVM Training Using Low-Rank Kernel Representation. Journal of
Machine Learning Research, 243–264.
3.5
1.5
0
methods. In Advances in Kernel Methods: Support Vector Learning, MIT Press.
35
40
Class
Figure 17. Accuracy & Speedup (Corbis)
5. Conclusion
We have described an efficient strategy to obtain instances close to the boundary between classes. Our experiments over more than 100 different concepts indicate the applicability of the method in speeding up the
training phase of support vector machines. An interesting aspect of the proposed approach is the smaller
number of support vectors defining the classifier. Having fewer support vectors bodes well for faster classification of the test instances. As future work, we would
like to explore the performance of the approach with
other learning algorithms having robust loss functions
like SVMs. In particular, we would like to develop a
robust algorithm which generalizes efficiently to the
multi-class case.
Lawrence, N. D., Seeger, M., & Herbrich, R. (2003). Fast
sparse gaussian process methods: the informative vector machine. S. Becker, S. Thrun and K. Obermayer
(eds) Advances in Neural Information Processing Systems. MIT Press.
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998).
Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86, 2278–2324.
Liu, T., Moore, A. W., Gray, A., & Yang, K. (2005). An
investigation of practical approximate nearest neighbor
algorithms. In L. K. Saul, Y. Weiss and L. Bottou (Eds.),
Advances in neural information processing systems 17,
825–832. Cambridge, MA: MIT Press.
Osuna, E., Freund, R., & Girosi, F. (1997). An improved
training algorithm for support vector machines. IEEE
Workshop on Neural Networks for Signal Processing.
Pavlov, D., Chudova, D., & Smyth, P. (2000). Towards
scalable support vector machines using squashing. ACM
SIGKDD (pp. 295–299).
Platt, J. (1998). Sequential minimal optimization: A fast
algorithm for training support vector machines (Technical Report). Microsoft Research.
Smola, A. J., & Schölkopf, B. (2000). Sparse greedy matrix
approximation for machine learning. ICML.
References
Tresp, V. (2001). Scaling kernel-based systems to large
data sets. Data Min. Knowl. Discov., 5, 197–211.
Achlioptas, D., McSherry, F., & Schölkopf, B. (2002). Sampling techniques for kernel methods. Advances in Neural
Information Proc. Systems.
Vapnik, V. (1995). The nature of statistical learning theory.
New York: Springer.
Breiman, L. (1996). Bagging predictors. Machine Learning,
24, 123–140.
Yu, H., Yang, J., & Han, J. (2003). Classifying large data
sets using svm with hierarchical clusters. In Proceedings
of ACM International Conference on Knowledge Discovery and Data Mining.
Burges, C. (1999). Geometry and invariance in kernel based