Group Bibliographic Essay - Southern Connecticut State University
advertisement

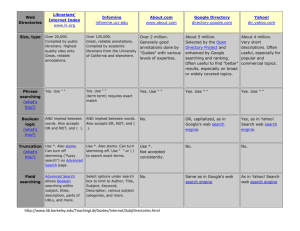
Bibliographic Essay Unit 5 Christine Cox & Graham Sherriff Searching: Using technology to locate information 1. The World Wide Web The World Wide Web has opened up a whole new world of information to the public, but having access to information is not necessarily the same as being able to locate it, understand it or use it. Librarians have a key role in helping searchers to do these things and in teaching how to do them independently. Size and structure Searching for specific information has often been likened to searching for the proverbial needle in a haystack. How big is the internet? Google – widely considered the most comprehensive search engine – in 2004 claimed to have an index of 8 billion pages, while CEO Eric Schmidt in 2005 stated that based on his company’s data the Internet was made up of approximately 5 million terabytes, of which Google had only indexed 170 terabytes. This shows that search engines are only indexing a small amount of the web (Sullivan, 2006). To put the size of existing information into perspective, Schmidt also stated that based on Google’s data for 1998-2005, it would need 300 years to index the existing 5 million terabytes of data, not withstanding any additional new content (Mills, 2005). Unlike a library, the web has no comprehensive catalog. This lack of structure plays an important part in understanding how searching works. Search engines can be unhelpful if the searcher does not know how to use them properly or has not fully developed their question. At this point, the experience and training of librarians is crucial (Builder.com, 2004). 2. Searching with directories Web directories specialize in linking to other websites and organizing the links into categories. Thus they provide a catalog-style structure to the web content they cover. Browsing a directory involves searching by subject titles rather than keywords, so the user must be familiar with not only the subject being researched, but also the directory and the categories it offers. When an inexperienced user seeks information from a directory, the expertise of a librarian is an important factor in not only locating the information, but also identifying the appropriate subject areas to browse. 3. Searching with engines Search engines The development of search engines is a landmark achievement in the field of information location and retrieval. Instead of a table of contents, search engines function like the index of a book (Sherman & Price, 2001). This is especially useful because during the first years of the worldwide web, creators and administrators of online content made little effort to facilitate its retrieval. Consequently, improvements have had to be made mostly on the “demand side”, in the form of searching. The appearance of search engines prompted fears they would replace the librarian. They are now normally the first (and often only) means of searching for information, especially in secondary and higher education (Clyde, 2001). In addition, most searchers use one of a small number of engines. Approximately 92% of web searches are performed by Google, Yahoo!, Microsoft and ask.com (Reuters, 2007). However, search engines vary greatly in how they index the web and how they retrieve search results from their indexes. Limitations Relying on a small number of search engines might not be such a concern if they were reliably effective. However, a key concern for librarians is to recognize the relative advantages and disadvantages of regular search engines. The “Big Four” have the largest (and fastest-growing) indexes, but they also have their limitations, principally the use of algorithms that prioritize popularity. This is good for searchers who want to reference popular sites, but for many searchers the greatest need is relevancy, timeliness or credibility. Search engines are also limited by their for-profit orientation and their commercial rivalry: they have a market-driven incentive to perform extensively and efficiently, but commercialization provides a rationale for the manipulation of results in the form of paid-for placements or arbitrarily filtered results. Google in January 2007 acknowledged amending its results returns in order to protect its own corporate image (Cutts et al, 2007). Commercialization also makes engines susceptible to fads: in recent years, some have neglected searching development in favor of personalization and portalization (Hock, 2001). Librarians need to keep in mind that regular search engines cover only part of the web. Indexing will be a work in progress as long as the web continues to grow and renew. Estimates of regular search engines’ coverage range from 50% of web content to as little as 0.2% (Bergman, 2001). The “deep web” It is not only unpopular websites that fall under the radar of search engines’ crawlers. Sherman & Price (2001) identify four areas of the “deep web”: 1. The “opaque web”: text and pages from a website that exceed an engine’s programmed limits; unlinked pages. 2. The “private web”: content barred to engines by Robot Exclusion Protocol, passwords or “noindex” tags. 3. The “proprietary web”: access regulated by membership, dependent on registration, subscription or fees. 4. The “truly invisible web”: non-HTML formats such as PDF and Flash; compressed files; and content created dynamically by relational databases. (Another area is streamed data, like news ticker-tapes (Clyde, 2001).) Thus there is a wealth of unindexed web content. This content is also broad, with no category lacking significant representation of content, and it is widely thought to offer greater relevancy. A 2001 survey estimated the deep web’s “quality yield” as three times that of the “surface web” (12.3% vs. 4.7%) (Bergman, 2001). Perhaps most importantly, the deep web contains information that simply is not found elsewhere. This might not be a problem when searching for highly popular information such as celebrity gossip or sports news. But specialized research will yield better results in the deep web than in Google. Regular search engines have already taken steps to provide access to the deep web. Google and MSN can now search for PDF and Word files; others specialize in retrieving audio and video files. Increased access to academic resources is expanding rapidly as engines index library catalogs and collections, and incorporate databases, effectively shifting deep-web content onto the surface web. Examples include Google Book Search, Google Scholar and Windows Live Academic. This trend of engines embracing deep-web content is likely to continue (Cohen 2001, 2006). Metasearch engines When trying to maximize recall, librarians might be tempted to use metasearch engines. These submit enquiry terms to several search engines simultaneously and combine or aggregate the results. These therefore have greater breadth than the average regular search engine. This is particularly useful when seeking comprehensive recall or trying to find obscure information. However, they also have their drawbacks. Compared to regular search engines, a searchenginewatch.com survey found that their results feature a higher proportion of paid-for placements and that these placements are less clearly distinguished from ones not paid for. For example, the survey indicated that 86% of Dogpile results are paid-for placements (Sullivan, 2000). They are also limited by ceilings on retrievals per search engine, time-outs, engines’ different interpretation of enquiry terms and the fact that none searches a combination of the largest regular engines (Hock, 2001). Federated search engines Federated search engines are similar to metasearch engines, but include authentication services that let users use restricted-access sources. These can therefore return results from private or fee-based websites, and aim to be a “onestop shop” for searchers. Examples include MuseGlobal, Webfeat and ExLibris. Yahoo! in 2005 added a subscriptions-based search facility. However, these are normally commercial enterprises that cover access costs by charging search fees. In addition, the authentication set-up can be timeconsuming, and there are outstanding copyright issues (Fryer, 2004). 4. Searching techniques Asking the question: Precision vs. recall An important factor when searchng is precision versus recall. A search with a high precision rate indicates most results will be relevant. A search with a high recall rate indicates you have retrieved most of the available records, though these might also include irrelevant ones (Dugan, 2006). “The goal of information retrieval scientists is to provide the most precise or relevant documents in the midst of the recalled search results” (Lager, 1996). Asking the question: Advanced Query Operators Many search engines offer search functions that use advanced query operators (AQMs), such as Boolean operators (AND, OR and NOT). Only 10% of web searchers use these operators (Eastman, 2003). In addition, using AQMs does not have a significant impact on search results when applied by the average user. “Approximately 66% of the top ten results on average will be the same regardless of how the query is entered” (Jansen, 2003). Librarians, with expert searching skills, may have better results in using AQMs. According to Bernard Jansen and Caroline Eastman: “The amount of training and practice that would be needed to enable most users to correctly formulate and use advanced operators, along with the apparent need to understand the particular IR (information retrieval) system, is not justified by the relatively small potential improvement in results. So, training and experience in more sophisticated searching techniques and strategies could reasonably be limited to information professionals who might be expected to have a use for them, are knowledgeable on a particular system or set of systems, and engage in intricate searching tasks” (2003). Getting the answer: Evaluating results The credibility of search results is a major concern. Elizabeth Kirk, librarian at John Hopkins University, underlines the importance of skeptical evaluation: “When you use a research or academic library, the books, journals and other resources have already been evaluated by scholars, publishers and librarians. Every resource you find has been evaluated in one way or another before you ever see it. When you are using the World Wide Web, none of this applies. There are no filters. Because anyone can write a Web page, documents of the widest range of quality, written by authors of the widest range of authority, are available on an even playing field. Excellent resources reside along side the most dubious” (Kirk, 1996). Kapoun, a librarian at Southwest State University, bases his web evaluation on five criteria: accuracy, authority, objectivity, coverage and currency (Kapoun, 1998). Currency is a particularly important consideration for web content. It is often said that search engines “search the Internet”, but this is not true. “Each one searches a database of the full text of web pages selected from the billions of web pages out there residing on servers. When you search the web using a searching engine, you are always searching a somewhat stale copy of the real web page” (Barker, 2006). How “stale” is the copy of the page that you have searched? Ellen Chamberlain, Library Director at the University of South Carolina’s Beaufort Campus states: “There is no way to freeze a web page in time. Unlike the print world with its publication dates, editions, ISBN numbers, etc., web pages are fluid. [...] The page you cite today may be altered or revised tomorrow, or it might disappear completely” (2006). And librarians are ideally suited to evaluating the quality of information – it has always been an integral aspect of their professional responsibilities. According to Chris Sherman, the executive editor of SearchEngineWatch.com, “There’s a problem with information illiteracy among people. People find information online and don’t question whether it’s valid or not... I think that’s where librarians are extremely important” (Mills, 2006) 5. Current trends and future developments Recall The web is growing. The number of sites might be stabilizing, but the amount of data is expanding. With greater access to deep-web resources, the amount of retrievable data is soaring. Librarians and patrons have to navigate through more and more information to find exactly what they are looking for. Search engines are becoming more efficient and more powerful, enabling them to index deeper and more frequently. Technology is making possible huge gains in recall. Sherman & Price (2001) even suggest hypertext queries that treat the web as a single database, enabling truly comprehensive searches. Increased recall is also being made possible by specialized search engines, from A (agview.com for agriculture) to Z (fishbase.org for zoology). Specialized metasearchers have also appeared, like familyfriendlysearch.com for childfriendly search engines (Hock, 2001; Mostafa, 2005). Precision As recall increases, the next major challenge will be precision. One approach is to use technology to refine results. Mooter is a search engine that presents results in sub-groups leading to further sub-groups. Kartoo presents results on a “map”, organized horizontally rather than ranking vertically. But the greatest effort is being put into eliminating unwanted retrievals – in other words, increasing precision while maintaining recall. PowerScout and Watson customize the searching process, based on patterns of search history by the user and other users with similar search interests. In this way, the engine builds up a profile of what the searcher is likely to be looking for (Mostafa, 2005). Another promising path for development is a “supply side” solution: web content is tagged with data (“metadata”) that can be read by index crawlers. For example, a tag might state that the ‘Georgia’ in a web article’s title is the American Georgia, not the ex-Soviet Georgia. Search engines can then scan this data instead of superficial content that can be misleading, and ignore nonrelevant pages, such as “false drops” (O’Neill et al, 2003). An example of a metadata-reading search engine is the rapidly-expanding OAIster. There are drawbacks to metadata. It is vulnerable to spamming; there are legal issues over the use of trademarked terms, as in the legal saga of Terri Welles vs. Playboy (Sullivan, 2004); and it requires a lot of (human) data entry. However, the advantages would be huge gains in searching precision; the ability to certify content in different ways, helping searchers to assess its provenance and credibility; and possibly a basis for the next evolutionary stage of the web: the semantic web. Whereas metadata is currently processed statistically (a crawler calculates the frequency of terms, proximity, etc.), the semantic search engine processes metadata logically, combining one search function with another, or with other data-processing programs (Berners-Lee et al, 2001). Librarians and search engines No matter what advances are made in search technology, librarians’ expertise in locating and evaluating information will remain a valuable part of the searching process. Search engines are simultaneously complex and limited, and librarians who master searching technology are fulfilling their traditional responsibility of being able to guide patrons to the desired information. The article, “Librarians Versus the Search Giants,” details a panel conversation between librarians and representatives from Google and Microsoft: “One issue not in doubt during the conversation was the fact that the world will continue to need librarians. Indexes of knowledge - and Google, MSN, Yahoo!, etc. are indexes, not libraries - will still require someone to make sense of all the information” (Krozser, 2006). Librarians’ research skills and experience also prove useful when the internet fails. Their knowledge of information resources goes far beyond the web. Joe Janes, an associate professor in the Information School at the University of Washington in Seattle, comments: “When Google doesn't work, most people don't have a plan B. Librarians have lots of plan B's. We know when to go to a book, when to call someone, even when to go to Google” (Selingo, 2004). Bibliography Information taxonomy plays a critical role in Web site design and search processes. (2003, July 1). Builder.com. Retrieved February 12, 2007, from http://builder.com.com/5100-6374_14-5054221.html?tag=search Barker, J. (2006). Finding Information on the Internet: A Tutorial. Retrieved February 10, 2007, from http://www.lib.berkeley.edu/TeachingLib/Guides/Internet/FindInfo.html Bergman, M. K. (2001, August). The Deep Web: Surfacing Hidden Value. [Electronic version]. The Journal of Electronic Publishing, 7 (1). Berners-Lee, T., Hendler, J. & Lassila, O. (2001, May 17). The Semantic Web. ScientificAmerican.com. Retrieved February 12, 2007, from http://www.sciam.com/article.cfm?articleID_00048144-10D2-1C7084A9809EC588EF21&catID=2 Bopp, R.E., & Smith, L.C. (2001). Reference and Information Services: An Introduction. Englewood, CO: Libraries Unlimited. Chamberlain, E. (2006). Bare Bones 101: A Basic Tutorial on Searching the Web. Retrieved February 9, 2007, from http://www.sc.edu/beaufort/library/pages/bones/bones.shtml Clyde, A. (2002, April). The Invisible Web [Electronic version]. Teacher Librarian, 29 (4). Retrieved February 12, 2007, from WilsonWeb database. Cohen, L. (2001, December 24). The Deep Web. Retrieved February 7, 2007, from http://www.internettutorials.net/deepweb.html Cohen, L. (2006, December). The Future of the Deep Web. Library 2.0. Retrieved February 11, 2007, from http://liblogs.albany.edu/library20/2006/11/the_future_of_the_deep_web.ht ml Cutts, M., Moulton, R & Carattini, K. (2007, January 25). A Quick Word about Googlebombs. Official Google Webmaster Central Blog. Retrieved February 13, 2007, from http://googlewebmastercentral.blogspot.com Dugan, J. (2006) Choosing the Right Tool for Internet Searching: Search Engines vs. Directories. Perspectives: Teaching Legal Research and Writing, 14 (2). Eastman, C.M., & Jansen, B.J. (2003). Coverage, Relevance, and Ranking: The Impact of Query Operators on Web Search Engine Results. ACM Transactions on Information Systems, 21 (4). Fryer, D. (2004, March/April). Federated Search Engines. Online, 28 (2). Retrieved February 13, 2007, from EBSCO Host database. Hock, R. (2001). The Extreme Searcher’s Guide to Web Search Engines (2nd edition). Medford, New Jersey: CyberAge Books. Jansen, B.J. (2003, May 18-21). Operators Not Needed? The Impact of Query Structure on Web Searching Results. Information Resource Management Association International Conference, Philadelphia, PA. Kapoun, J. (1998). Teaching undergrads WEB evaluation: A guide for library Instruction. College & Reseach Libraries News, 59 (7). Kirk, E.E. (1996). Evaluating Information Found on the Internet. Retrieved February 12, 2007, from http://www.library.jhu.edu/researchhelp/general/evaluating Krozser, K. (2006, March 12). Librarians Versus the Search Giants. Medialoper.com. Retrieved February 9, 2007, from http://www.medialoper.com Lager, M. (1996). Spinning a Web Search. Retrieved February 11, 2007, from http://www.library.ucsb.edu/untangle/lager.html Mills, E. (2005, October 8). Google ETA? 300 years to index the world’s info. CNET News.com. Retrieved February 8, 2007, from http://news.com.com/Google+ETA+300+years+to+index+the+worlds+info/2 100-1024_3-5891779.html Mills, E. (2006, September 29). Most reliable search tool could be your librarian. CNET News.com. Retrieved February 9, 2007, from http://news.com.com/Most+reliable+search+tool+could+be+your+librarian/2 100-1032_3-6120778.html Mostafa, J. (2005, January 24). Seeking Better Web Searches. ScientificAmerican.com. Retrieved February 12, 2007, from http://www.sciam.com/article.cfm?articleID=0006304A-37F4-11E8B7F483414B7F0000 O’Neill, E.T., Lavoie, B.F. & Bennet, R. (2003, April). Trends in the Evolution of the Public Web 1998-2002. D-Lib Magazine, 9 (4). Retrieved February 7, 2007, from http://www.dlib.org/dlib/april03/lavoie/04lavoie.html Google, Yahoo gain share in U.S. Web search market. (2007, January 15). Reuters. Retrieved February 13, 2007, from http://news.yahoo.com/s/nm/20070115/wr_nm/google_search_dc_1 Selingo, J. (2004, February 5). When a Search Engine Isn’t Enough, Call a Librarian. NYTimes.com. Retrieved February 11, 2007, from http://www.nytimes.com/2004/02/05/technology/circuits/05libr.html?ex=139 1403600&en=26c6c8a9c0c4212f&ei=5007&partner=USERLAND Sherman, C. & Price, G. (2001). The Invisible Web: Uncovering Information Sources Search Engines Can’t See. Medford, New Jersey: CyberAge Books. Sullivan, D. (2000, August 2). Invisible Web Gets Deeper. SearchEngineWatch.com. Retrieved February 11, 2007, from http://searchenginewatch.com/showPage.html?page=2162871 Sullivan, D. (2004, April 21). Meta Tag Lawsuits. SearchEngineWatch.com. Retrieved February 11, 2007, from http://searchenginewatch.com/showPage.html?page=2156551 Sullivan, D. (2006, August 22). Nielsen NetRatings Search Engine Ratings. SearchEngineWatch.com. Retrieved February 10, 2007, from http://searchenginewatch.com/showPage.html?page=2156451