STAT 2000 Test Review 3
advertisement

Confidence Intervals
• Calculate the sample mean/proportion from data
• Point Estimate = sample mean/proportion
• Calculate the width based on level of confidence and standard
error
• You crete a range of plausible values for the true population
mean/proportion
Confidence Intervals for Proportions
point
confidence
standard
±
×
estimate
level
error
p̂ = point estimate
r
p̂ ±
z×
|
p̂(1 − p̂)
{z n }
margin of error = width of C.I.
z depends on confidence level
r
p̂(1 − p̂)
= standard error
n
r
p̂(1 − p̂)
z×
= margin of error
n
Computing A Confidence Interval
• First get the point estimator (p̂ or x̄)
• Get the margin of error
- Is it given to you?
- z*(standard error) or t*(standard error)
- Also (upper limit - point estimate) - this can only be used if the
interval is already provided
• Having obtained the necessary numbers, compute (point
estimate ± margin of error)
• You are 95% confident the population mean/proportion is in the
interval
Properties of a C.I.
• The sample mean/proportion is ALWAYS inside the confidence
interval!
• In fact it is always in the center
r
p̂ ± z ×
p̂(1 − p̂)
n
• The population mean/proportion may or may not be inside the
confidence interval
Interpretation of a C.I.
• Any number falling within a confidence interval is a plausible
value for the true population mean, while any number outside the
interval is not.
• Example: a 98% interval is (60, 75)
- With 98% confidence, the true mean is above 60 and below 75
- It is plausible that the population mean could be 68 (inside the
interval)
- It is not plausible that the population mean could be 50 (outside the
interval)
Interpretation of a C.I.
• The main interpretation of a 95% interval is as follows:
We are 95% confident the population mean/proportion is
somewhere inside the interval.
- The population mean, while unknown, is fixed
- What changes is the interval
• Warning: It is incorrect to say “The population mean is in the
confidence interval 95% of the time."
- This is because this statement implies that the population mean
changes and sometimes happens to be in the interval
- Incorrect because the population mean is fixed
Another Way to Interpret a C.I.
• A 95% C.I. also means that about 95% of all C.I.s constructed
contain the true population mean/proportion, and about 5% do
not
• A 99% C.I. means that about 99% of all C.I.s constructed contain
the true population mean/proportion, and about 1% do not
• Example: 1000 intervals
- At 95%, about 950 (give or take) contain the true proportion
- At 99%, about 990 (give or take) contain the true proportion
C.I. (HW 8.1-8.2)
• The annual salaries of 100 randomly selected people in
Vancouver have a mean of $49,000 and a margin of error of
$8000 with 95% confidence.
- Find the point estimate for this sample.
49000
- Construct the 95% C.I.
(49000 − 8000, 49000 + 8000)
= (41000, 57000)
We are 95% certain the true salary average falls somewhere
between $41000 and $57000.
Determining z
• z = level of confidence
- 95% C.I. : z = 1.96
(memorize)
- For others: use at least 5
decimals
• To get these numbers...
- 95%, 5% is left over
- Half of that is 2.5%
- P(z >=?) = .025 in
StatCrunch
• What about 85%?
85%, 15% is left over
Half of that is 7.5%
So .075 in right box
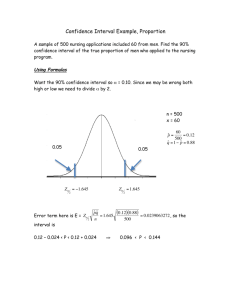
Proportions C.I.(HW 8.1-8.2)
• A random sample of 200 people were asked if they believed in
the Loch Ness Monster. 160 said yes.
- Find a point estimate for the proportion of people who said yes.
p̂ =
160
200
= .80
- Find the standard error.
q
q
p̂(1−p̂)
.80(1−.80)
=
= .02828
n
200
- Will we get a valid confidence interval?
Yes because:
np̂ = 200 × .80 = 160 ≥ 15
n(1 − p̂) = 200 × (1 − .80) = 40 ≥ 15
Proportions C.I.(HW 8.1-8.2)
• Continuing with Nessie....
- Find the margin of error for a 95% C.I.
q
p̂)
95% so 1.96 ∗ p̂(1−
= 1.96 ∗ .02828 = .05544
n
- Construct the 95% C.I.
(.80 − .05544, .80 + .05544) = (.74456, .85544)
- Can we conclude that more than 70% of all people believe in the
Loch Ness Monster?
Yes, because .70 is beneath this interval
- How about less than 88%?
Yes, because .88 is above this interval
Proportions C.I.(HW 8.1-8.2)
• Now suppose another, different sample, also of size 200, is
taken, and the confidence interval from this new sample is (.76,
.80).
- If possible, find the population proportion and the new sample
proportion.
We can not compute the population proportion: it’s unknown
The sample proportion’s in the center: .76+.80
= .78 = p̂
2
- What is the new margin of error?
The distance between the center and an endpoint:
.80 − .78 = .02
- Compare this interval with our earlier 95% interval, which was
(.74456, .85544). Is this new interval more likely a 91% or a 98%
interval?
91% since shorter, yet same sample size
C.I. Properties
• Increasing level of confidence (z) widens the interval
• Decreasing level of confidence (z) shortens the interval
• This is because the z score gets larger as the level of confidence
gets smaller
q
p̂)
p̂ ± z ∗ p̂(1−
n
• Intuition: narrowing your field for the true proportion means
you’re not as certain it really does fall inside the interval
C.I. Properties
• Increasing the sample size shortens the C.I.
• Decreasing the sample size widens the C.I.
• This is because standard error decreases as n increases, so the
margin of error (width) decreases as well.
q
p̂)
p̂ ± z ∗ p̂(1−
n
• Intuition: a larger sample size gives a more accurate estimate
and allows you to zero in on the true proportion.
Summary of C.I. Width Factors
Confidence Level (z)
• As z increases, C.I. widens
• As z decreases, C.I. shortens
• Assumptions for proportion C.I.
1. Sample is randomly selected
2. np̂ ≥ 15
3. n(1 − p̂) ≥ 15
Sample Size (n)
• As n increases, C.I. shortens
• As n decreases, C.I. widens
Confidence Interval for Means
• Same general idea:
point
estimate
±
confidence
level
×
standard
error
• But we use a different formula:
s
x̄ ± t × √
n
• With proportions, use z
• With means, use t
Mean + t ⇒ meant, which is a proper word
Proportion + t ⇒ proportiont, which is not a word
Confidence Interval for Means
point
confidence
standard
±
×
estimate
level
error
x̄ ±
s
t×√
n
| {z }
margin of error = width of C.I.
x̄ = point estimate
t depends on confidence level
s
√ = standard error
n
s
t × √ = margin of error
n
The T Calculator
• Only new feature: degrees of
freedom
• DF = n - 1
• Same strategy as before: with
95%
- 5% is left over, and half of
that is 2.5%
- P(X ≥?) = .025 with 18
observations, so DF =17
Confidence Interval for Means
• T vales change as degrees of freedom change
• Degrees of Freedom = n - 1
• Assumptions when doing a C.I. for Means:
- Random Sample
- One of the two needs to be true
• Sampling from normal population
• n ≥ 30
C.I. with Means (HW 8.3-8.4)
• 480 people responded to a question on how many children they
have:
Mean = 3
S.D. = 1.78
- Find the point estimate for the sample.
x̄ = 3
- Find the standard error of the sample.
√s
n
=
1.78
√
480
= .08125
- Suppose the 95% C.I. is (2.84,3.16). Choose an answer:
With 95% confidence, the true mean lies (above, below, within)
this interval.
- Is it plausible that the true population mean is 2? Why or why
not?
No, because 2 is below the interval, not inside it.
C.I. with Means (HW 8.3-8.4)
• Consider the band of knights from Monty Python... The Knights
Who Say “Ni!" A certain number of knights are selected at
random, and we count the number of times in one minute each
says “Ni!". We then build a 95% confidence interval for the
average.
- What is the point estimate?
The sample average, which is 15
- How many knights did we sample?
Since d.f . = n − 1 = 9, we sampled 10 knights
C.I. with Means (HW 8.3-8.4)
• Same sample of Knights Who Now Say “Ekke Ekke Ekke Ekke
Ptangya Ziiinnggggggg Ni!" ....
- In order to obtain the margin of error, we will need to multiply
standard error by what value?
The T value with df = 9
- True/False: The T value does not change as sample size
increases.
False: a Z value does not change with sample size, but T does
- True/False: Keeping sample size fixed and increasing confidence
level, the standard error will increase.
False: standard error alone does not depend on confidence level
(unlike margin of error)
C.I. with Means (HW 8.3-8.4)
• Same sample of Knights Who ‘Till Recently Said “Ni!"....
- If the confidence interval is (11.78, 18.22), find the margin of
error.
Margin of error is the distance from the upper endpoint to the
center of the interval (the point estimate), so 18.22 - 15 = 3.22
Also the distance from the center to the lower endpoint
- What effect will increasing sample size have on this 95%
interval?
Keeping 95% fixed, increasing sample size will shorten the
interval.
Confidence Intervals
(StatCrunch)
MEANS with DATA
PROPORTIONS
• Stat >Proportions >One
Sample >With Summary
• # Successes and #
Observations
• C.I., level, Standard-Wald,
Calculate
• Tells you the C.I. and
standard error
• Does not tell you the margin
of error
• Stat >T-Statistics >One
Sample >With Data
• Select var1, Next
• C.I., level of confidence,
calculate
MEANS with SUMMARY
• Stat >T-Statistics >One
Sample >With Summary
• Enter sample mean, s.d.,
sample size
• C.I., level of confidence,
calculate
Choosing Sample Size
• Idea: We have a given confidence level and a desired margin of
error
• What sample size is needed to achieve that?
• Formula is different for proportions and means (see formula
sheet)
Sample Size Formulas
p̂(1 − p̂)z 2
n=
m2
n = sample sized needed
p̂ = “guess" on sample proportion
z = z-score for confidence level
m = desired margin of error
n=
σ2 z 2
m2
n = sample sized needed
σ = standard deviation from
previous sample
z = z-score for confidence level
m = desired margin of error
What do we choose for the sample proportion?
1. p̂ from previous sample
2. If no previous sample, use p̂ = .50 (this gives largest possible
sample, see next slide)
Sample Size (HW 8.3-8.4)
• We are interested in the proportion of people at a college that
has read The Hunger Games. We want to estimate it with
probability .95 and within 0.06.
- What sample size do we need, if no previous study is known?
p̂ = .50
n=
m = .06
p̂(1−p̂)z
m2
2
=
z = 1.96 (95% confidence)
.50(1−.50)(1.96)2
(.06)2
= 266.77778 ⇒ 267
We round up since sample size must be a whole number
- All other things the same, if we instead estimate with probability
.98, will we need more or fewer subjects?
This will use a higher number for z (from the normal calculator),
so the numerator is bigger and therefore the whole fraction is
bigger. Thus, we would need more subjects.
Sample Size (HW 8.3-8.4)
• Now suppose we’re told that a previous study at Harvard said
that 75% of people at college have read The Hunger Games.
- Before doing any calculations, will the required sample size for a
margin of error of .06 be larger or smaller than before?
Smaller, since p̂ = .50 is the “worst case scenario." Any other
choice will yield a smaller needed sample size.
- Find the new sample size, again with probability .95.
p̂ = .75
n=
m = .06
p̂(1−p̂)z
m2
2
=
z = 1.96 (95% confidence)
.75(1−.75)(1.96)2
(.06)2
= 200.08333 ⇒ 201
- What is the advantage to knowing a previous study proportion?
We get to use a different choice for p̂, which won’t require as
large a sample size.
Sample Size (HW 8.3-8.4)
• We are estimating the average number of acres on a farm to
within 23, with probability 95%. In a previous study, the sample
s.d. was 202 acres.
- Find the sample size needed.
σ = 202
n=
2 2
σ z
m2
m = 23
=
2
z = 1.96 (95% confidence)
(202) (1.96)2
232
= 296.31880 ⇒ 297
- All other things being equal, if we wanted a smaller margin of
error, will we need more or fewer subjects?
The denominator will be smaller, so the overall number will be
bigger. Therefore we would need more subjects.
Proportions Summary
Assumptions for a Valid
Confidence Interval
• Random Sample
• Need:
- np̂ ≥ 15 and
- n(1 − p̂) ≥ 15
Finding Sample Size
n=
p̂(1 − p̂)z 2
m2
Confidence Interval
• Point Estimate = p̂
q
p̂)
• Standard Error = p̂(1−
n
• Level of Confidence = use z
q
p̂)
• Margin of Error = z × p̂(1−
n
q
p̂)
• Lower Limit = p̂ − z × p̂(1−
n
q
p̂)
• Upper Limit = p̂ + z × p̂(1−
n
Means Summary
Assumptions for a Valid
Confidence Interval
• Random Sample
• Need one of the following:
- Sample from a normal
population, or
- n ≥ 30
Confidence Interval
• Point Estimate = x̄
• Standard Error =
√s
n
• Level of Confidence = use t
• Margin of Error = t ×
√s
n
Finding Sample Size
• Lower Limit = x̄ − t ×
√s
n
σ2 z 2
m2
• Upper Limit = x̄ + t ×
√s
n
n=
Hypotheses
• The alternative hypothesis HA tests if a parameter is greater
than, less than, or not equal to a suspected number.
• The null hypothesis H0 sets the parameter equal to the suspected
number stated in the alternative. (Null is always equals!)
• We test parameters p or µ
• We never test statistics p̂ or x̄
The last points are important! If we collect a sample and get x̄ = 2.7
then the probability that x̄ = 2.7 is 1. We do not need to test this.
Example Hypotheses
H0 : p = .31
H0 : p = .56
H0 : µ = 11
HA : p < .31
HA : p > .56
HA : µ 6= 11
left-tailed
right-tailed
two-tailed
Hypotheses (HW 9.1-9.3)
• Suppose the average number of hours spent watching TV used
to be 40 hours per week. Set up the null and alternative
hypotheses for these situations:
- You believe the mean number of hours has changed.
H0 : µ = 40
HA : µ 6= 40
- You believe the mean number of hours has increased.
H0 : µ = 40
HA : µ > 40
Test Statistic, P-Value
• Compute the test statistic
- z (for proportions)
- t (for means)
normal calculator
T calculator
• Look up the p-value on the calculator
- Left-tailed test:
- Right-tailed test:
- Two-tailed test:
Below z or t
Above z or t
Above z or t and below -z or -t
P-Value Interpretation
• The p-value is the probability that you could observe a given
sample mean, or further away, if in fact the null is true. Consider
this example:
H0 : µ = 40
HA : µ > 40
x̄ = 50
p-value = .12 (say)
- The probability of observing a sample mean of 50 (or higher) if
the true mean were 40, is .12. In other words, if in fact the mean
is 40, we only have a 12% chance of getting a sample mean at
least as extreme as 50.
Hypothesis Testing Notation
p = population proportion
p0 = hypothesized population proportion (what is stated in H0 )
p̂ = sample proportion
z-stat = test statistic
µ = population mean
µ0 = hypothesized population mean (what is stated in H0 )
x̄ = sample mean
t-stat = test statistic
p-value = probability that you observe as sample statistic (x̄ or p̂)
as or more extreme if H0 is true
Hypothesis Testing Steps
Means
Proportions
H0 : p = p0
HA : p >, <, 6= p0
z=
p̂−p0
se
se =
q
p0 (1−p0 )
n
p-value
conclusions
H0 : µ = µ0
HA : µ >, <, 6= µ0
t=
x̄−µ0
se
se =
√s
n
p-value
conclusions
Conclusions
If p-value ≤ α (alpha)
- Reject H0
- Test is significant
- There is enough evidence to
suggest a change, increase,
etc.
- Strong evidence against the
null
- Possible Type I Error
If p-value > α
- Fail to reject H0 (but never
accept it!)
- Test is insignificant
- There is insufficient
evidence to suggest a
change, increase, etc.
- No strong evidence against
the null
- Possible Type II Error
P-Value (HW 9.1-9.3)
• Suppose H0 : p = .81, and z = .98. For the test HA : p < .81,
and without finding the p-value ...
- What would your decision be? (Reject null or not?) Hint: draw a
sketch!
Left-tailed test, so we shade the area
to the left of 0.98. The probability to
the left of 0 is 0.50, and z=.98 is to the
right of 0. So the probability to the left
of z=0.98 must be greater than 0.50.
Since we compare to α, which is
always small (around .05 or so), we
will fail to reject the null, since our
p-value will be higher than any choice
of α. Also p value > .5.
P-Value (HW 9.1-9.3)
• Suppose in a test we get a p-value of .03.
- What is the decision at α = .05?
Reject the null, test is significant
Sufficient evidence for the alternative
- How about at α = .01?
Don’t reject the null, test is insignificant
Insufficient evidence for the alternative
P-Value
Assumptions for Testing
Proportions
Means
• Categorical data
• Quantitative variable
• Random samples
• Random samples
• Independent samples
• Independent samples
• np0 > 15
• One of these two:
• n(1 − p0 ) > 15
- n > 30
- Population’s normal
Testing (HW 9.4 - 9.5)
• It is said that when nobody’s watching, 47% of people drink
straight from the milk carton. A researcher doubts this, thinking
the proportion must be higher. In a random sample of 200, 102
admitted to doing this secretly. The standard error is .03529.
- Set up the hypotheses to be tested.
H0 : p = .47
HA : p > .47
- Find the point estimate.
p̂ =
102
200
= .51
- Find the test statistic.
(The sample proportion is 1.1335 standard errors above the
supposed null proportion.)
.51−.47
0
z = p̂−p
s.e. = .03529 = 1.1335
Testing (HW 9.4 - 9.5)
• Same Problem....
- The p-value is 0.1285. State the conclusion, using α = .05.
Fail to reject the null, the test is not significant, and there is no
evidence that the proportion of people that secretly drink straight
from the milk carton is significantly higher than .47.
- What would the p-value be if we instead did a two-tailed test?
Test statistic is positive, and right-tailed p-value is 0.1285. So the
two-tailed test will be double this: 0.257.
- Are the results from this test valid?
Subjects are independent and random, and data is categorical
(response is either yes or no)
n × p0 = 200 × .47 = 94 > 15
n × (1 − p0 ) = 200 × (1 − .47) = 106 > 15, so yes
Errors
Reject H0
Don’t Reject H0
H0 was true
Type I
Correct
HA was true
Correct
Type II
• Type I: reject the null when in fact you shouldn’t have: it was
actually the true conclusion
- Concluding the alternative’s true when really the null is true
• Type II: fail to reject the null when in fact you should have: the
alternative was the correct one
- Concluding there’s no sufficient evidence to contradict the null,
when in fact the alternative is true
Errors (HW 9.1-9.3)
• Suppose we are interested in determining whether the average
number of roller coaster rides an individual takes in one visit to a
theme park is significantly greater than 8.
- Set up the hypotheses.
H0 : µ = 8
HA : µ > 8
- In the context of this problem, describe what a Type I Error would
be.
Concluding that the average number of roller coaster rides (in
one visit) is higher than 8, when in fact it’s no different from 8
- Do the same for a Type II Error.
Concluding that the average number of roller coaster rides (in
one visit) is not significantly higher from 8, when in fact it’s
greater than 8
Errors (HW 9.1-9.3)
• You need to decide whether or not it will rain today, and then take
an umbrella or leave it behind, based on your decision.
H0 : It will not rain (so you’d leave the umbrella at home)
HA : It will rain (so you’d take the umbrella with you)
- Describe, in the context of this problem, what a Type I and II error
would be.
Type I: you reject the null, conclude that there’s strong evidence it
will rain, so you take an umbrella. In fact it doesn’t rain, so you
carry an umbrella unnecessarily.
Type II: you fail to reject the null, conclude that there’s no
evidence it will rain, so you don’t take an umbrella. In fact it does
rain, so you get wet.
- For this problem, which error is more serious?
Type II because it’s worse to get drenched from rain than to walk
around with an umbrella when you don’t need one.
Errors (HW 9.1-9.3)
• You have an appointment and need to decide what time to leave
for it. So you need to guess what traffic will be like.
H0 : There won’t be much traffic
HA : There will be traffic (so you’d depart earlier)
- Describe what a Type I and Type II error would be in this
situation. Which is more serious?
Type I: You decide there’s strong evidence that there will be
heavy traffic, so you leave early, but actually traffic conditions are
reasonable, so you arrive at your appointment too early.
Type II: You decide there’s not enough evidence that there will be
heavy traffic, so you don’t allow for extra time when leaving.
Actually traffic turns out to be heavy, so you arrive late.
Obviously a Type II is more serious!
Level Of Significance
If we do a hypothesis test versus a confidence interval, we should
reach the same conclusion at a specified significance level.
• Question: given a certain percent confidence interval, if we did
the equivalent hypothesis test with the same data, what is our
level of significance α?
- For a 95% CI, we do the following:
(100 - 95)% = 5%, as a decimal that is .05
So here α = .05.
- Can you work out what α should be if we used a 91% CI?
(100 - 91)% = 9%, as a decimal that is .09
So α = .09 is the level.
Significance (HW 9.1-9.3)
• Suppose we fail to reject the null at the significance level .03 on a
two-tailed test. Answer “true", “false", or “unable to determine":
- The p-value is smaller than .03.
False: fail to reject, so it’s greater than .03.
- We’d also fail to reject the null at α = .01.
True: p-value is greater than .03, so it’s also greater than .01.
- We may have made a Type I error.
False: we might have made a Type II error, but not a Type I
- The null value will be inside the 97% confidence interval.
Yes, since we failed to reject at significance .03.
- The null value will be inside the 99% confidence interval.
Yes, a 99% CI is wider than a 97%. Since the null value is in the
97% CI, it will also be in the 99%.
Hypothesis (HW 9.4-9.5)
- A researcher is testing H0 : p = .50 versus HA : p 6= .50. She
gets z = 2 and a p-value of .0455. What is her decision at α =
.05? If she’s in error, what type is it?
Reject null, test is significant, enough evidence for alternative.
Possible Type I error.
- The confidence interval is (.5125,.5875). How can we reach the
same conclusions, and what extra information does this interval
tell us? Is the population proportion most likely above or below
.50?
p = .50 is not a plausible value as it lies outside the interval.
So we reject the null.
The C.I. tells us a range of plausible values for the true
proportion.
The whole interval is above .50, so the population proportion
most likely is above .50 as well.
Hypothesis (HW 9.4-9.5)
- A second researcher, testing the same hypotheses (not equals),
gets z = 2.06229 and a p-value of .01959. What is his conclusion
at α = .05?
Reject null, test is significant (possible Type I error).
- If we disregard the p-value and just say “less / greater than .05",
what information do we lose?
The p-value tells us how significant a test is.
The lower the p-value, the more significant the test.
By just labeling “reject / don’t reject", we lose that significance.
- Calculate the p-value if we had instead done a left-tailed test.
A two-tailed test is double a right-tailed test, so the p-value for a
right-tailed test is (1/2)*.01959 = .009795.
So the p-value for a left-tailed test is 1 - .009795 =.990205.
StatCrunch Commands
Proportions
• Stat > Proportions > One
Sample > With Summary
• # Successes & Sample Size
• Choose hypothesis or C.I.
• Calculate
StatCrunch Commands
Means with Data
Means with Summary
• Stat > T-statistics > One
Sample > With Data
• Stat > T-statistics > One
Sample > With Summary
• Choose column, etc.
• Enter summary, etc.
StatCrunch Commands
Proportions
• Stat > Proportions > One
Sample > With Summary
• # Successes & Sample Size
• Choose hypothesis or C.I.
• Calculate
Means With Data
• Stat > T-statistics > One
Sample > With Data
• Choose column, etc.
Means With Summary
• Stat > T-statistics > One
Sample > With Summary
• Enter summary, etc.
Notation
We use different letters for population parameters versus sample
statistics.
µ = population mean
x̄ = sample mean
σ = population standard deviation
s = sample standard deviation
p = population proportion
p̂ = sample proportion
Know the difference among these!
Notation (HW 7.1-7.3)
- What symbol is used to denote the population standard
deviation?
σ
- What symbol is used to estimate the population mean?
x̄
- What symbol is used to describe the number of subjects who
have a certain trait divided by the sample size?
p̂