EBM Review
advertisement

EBM Condensed
Well written Clinical questions PICO
1. Patient and/or problem
2. Intervention
3. Comparison intervention (if relevant)
4. Outcome (Clinical)
2 X 2 (kinda like the ark)
+/-pv terms on USMLE 1/2/3
Have to know pretest probability
Use LR to calc posttest
Calc sens and spec is a vertical soln to 2x2 table
Use LR calc posttest prob of disease
Pretest prob of disease (prob before diagnostic test)
Sensitivity: a/a+c
Test positive with disease
Specificity: d/b+d
Test negative without disease
• Likelihood Ratio for a Positive test: (LR+) sensitivity/1-specificity
• Likelihood Ratio for a Negative test : (LR-) 1-sensitivity/specificity
Alphabetical order (sensitivity before specificity)
–
Are the Results Valid?
• Was there an independent “blind” comparison with a reference
standard?
• Did the patient sample include an appropriate spectrum for whom
the test will be applied in clinical practice? i.e. Was there a
selection bias?
• Was the reference (gold) standard performed in all cases or did the
result of the test being evaluated influence the decision to perform
the reference standard?
• Were the methods of the test described in sufficient detail to permit
replication?
Use the 20, 50, 80 percent rule for pre-test probability of disease, in order to determine
the post-test probability of disease after applying the test
20% not very likely to have the disease
50% coin toss
80% pretty likely to have the disease
SCREENING: making early diagnoses in pre-symptomatic disease among well
individuals in the general public. Is there a RCT? Are early diagnosed patients willing to
engage in treatement? Is it worth the $?
•
Pre-test probability is: The probability that your patient has the disease after
you have performed a history and physical examination
•
Post-test probability is: The probability that your patient has the disease after
you have applied the LR to the pre-test probability
Pre-test Prob___
1 – Pre-test Prob
=
Pre-test Odds
Pre-Test Odds x Likelihood Ratio = Post-Test Odds
Post-test Odds
1 + Post-test odds
=
Post-test Probability
Pos(+) test Odds
Using the Likelihood Ratios at the bedside (it will help you manner)
• Pre-test Prob 20% -- .20/1- .20 = .2/.8 - .25
•
Pre-test Prob 50% -- .50/1-.50 = 1
•
•
•
Pre-test Prob 80% -- .80/1-.80 = 4
So, all you have to remember are three numbers: .
25, 1 and 4, These numbers correspond to the 20, 50, 80% rule
LR+ is 12; pretest prob of disease 80%; 48/49=high
Lr – is .40; pretest is 80% 4*.4 1.6/2.6 post test is 60%
First we need more knowledge; look for differential diagnosis
Quantifying treatment effects
• ARR – Absolute Risk Reduction
• RRR – Relative Risk Reduction
• NNT – Number Needed to Treat
CER = Control Event Rate
CER = # of patients in control group who had an event
total # of patients in the control group
EER = Experimental Event Rate
EER = # of patients in experimental group who had an event
total # of patients in experimental group
ARR = |EER-CER|
RRR = |EER-CER|
CER
Relative risk reduction (RRR) should be used in conjunction with ARR or NNT or both
since the RRR alone can be misleading
•
•
•
•
ABI – Absolute Benefit Increase
RBI – Relative Benefit Increase
NNT – Number Needed to Treat
ARI -- Absolute Risk Increase
ABI = |EER-CER|
RRI = |EER-CER|
CER
NNH =
1___
ARI
Types of hypotheses for Clinical trials of therapy
• Superiority - hypothesis of a clinically important difference in outcome
(eg. drug A is more effective than drug B)
• Non-inferiority - hypothesis of “no clinically important difference” in outcome
(eg. drug A is not less effective than drug B by more than a pre-specified amount,
known as the “non-inferiority margin”)
Statistically significant (p-value < alpha)
Alpha = .05
Clinically significant (difference > 15%)
Systematic Review of RCT’s
• Summarize results of multiple trials
• Must state explicit inclusion and exclusion criteria (to ensure high quality)
• Should include results for different subgroups of people
• Must include as many studies (that qualify) as possible
• High quality RCT’s– high quality SR
• Meta-analysis pools data across studies to provide an overall estimate of
treatment effect
Randomized Controlled Trial
• Experiment in which individuals are randomly allocated to receive or not
receive an experimental preventative, therapeutic, or diagnostic procedure
and then followed to determine the effect of the intervention.
• Minimize bias by controlling for known and unknown confounders
• Strongest single trial evidence
• Typically expensive
Cohort Studies
• A group (or cohort) of people exposed to a treatment and a group of
people not exposed are followed for the outcome of interest
• Non-randomized
• Beware of hidden confounders
• Seek adjustments for known confounders
• Less expensive and common to study harm
Case-control Studies
• Patients who already have the target outcome (cases) are compared to
patients who are reasonably similar to the cases in important determiners
of disease but don’t have the target outcome (controls) for previous
exposure to a treatment or harmful agent
• Retrospective
• Subject to a high degree of bias
• Useful for rare outcomes or those that take a long time
• Used much more to assess harm
Qualitative Studies (vs. quantitative)
• Emphasize understanding of feelings and values of patients
• Relatively new in medicine
Clinical decision analysis
Economic analysis
Clinical practice guidelines
Reader’s Guides to Critical Appraisal
• Address validity, importance of results, and applicability
Validity
1. Was the assignment of patients to treatment randomized?
2. Was the randomization concealed?
3. Were the groups similar at the start of the trial? Was adjustment made?
4. Was the f/u (follow up) of patients sufficiently long and complete?
5. Were all patients analyzed in the groups to which they were randomized?
6. Were patients, clinicians, and study personnel kept blind to treatment
group?
7. Were groups treated equally, apart from experimental therapy?
Importance of results
1. What is the magnitude of the treatment effect?
2. How precise is the estimate of the treatment effect?
Applicability
1. Is our patient so different from those in the study that its results cannot
apply?
2. Is the treatment feasible in our setting?
3. What are our patient’s potential benefits and harms from the therapy?
4. What are our patient’s values and expectations for both the outcome we
are trying to prevent and the treatment we are offering?
General Rules
1. Assess journal, research site, and authors
2. Assess funding
3. Read the abstract
4. Reader’s Guide questions can be taken in any order (i.e. applicability first)
Special consideration: Errors
• Type I error
The finding of a significant difference between treatment groups
when, in fact, none exists (alpha=0.05)
Results should generally be verified by subsequent studies
• Type II error
No significant difference is detected between treatment groups
when, in fact, such a difference exists in the larger population
(beta=0.1-0.2, specified in advance)
Often due to low power (not enough subjects)
Importance of results
• 95% confidence interval
Range of values likely to include the true benefit (or risk)
Quantifies the uncertainty in measurement
Poor man’s p-value (and vice versa)
Narrow CI– highly reproducible results
Examine clinical significance of CI limits
Absolute risk reduction: The absolute arithmetic difference in rates of bad outcomes
between experimental and control participants in a trial, calculated as [EER-CER] and
accompanied by a 95% CI.
Blinding or masking: The participant of interest is unaware of whether the patients have
been assigned to the experimental or control group.
Confidence interval: Quantifies the uncertainty in measurement. It is usually reported as
95% CI, which is the range of values within which we can be 95% sure that the true value
for the whole population lies.
Co-intervention: An intervention other than the treatment under study that may be
differentially applied to the experimental and control groups and, thus, potentially bias
the results of a study.
Contamination: Occurs when participants in either the experimental or control group
receive the intervention intended for the other arm of the study.
Hazard ratio: Investigators may compute the relative risk over a period of time, as in a
survival analysis, and call it a hazard ratio, the weighted relative risk over the entire
study.
Intention-to-treat: A method of analysis for randomized trials in which all patients
randomly assigned to one of the treatments are analyzed together, regardless of whether
or not they completed or received that treatment.
Number needed to treat: The number of patients who need to be treated to achieve one
additional favorable outcome, calculated as 1/ARR and accompanied by a 95% CI.
p-value: The probability that the observed data (results) or more extreme data (results)
would occur if the null hypothesis of no difference were true.
Randomization: Allocation of individuals to groups by chance.
Relative risk: Ratio of the risk of an event among an exposed (treated) population to the
risk among the unexposed (untreated; control group), calculated as [EER/CER] and
accompanied by a 95% CI..
Relative risk reduction: The proportional reduction in rates of bad outcomes between
experimental and control participants in a trial, calculated as [EER-CER/CER], and
accompanied by a 95% CI.
EER= experimental event rate (treatment group)
CER= control event rate (control group)
Types of Harm Articles
Review of RCTs or RCTs remain the gold standard.
However, because of ethics, size, duration and cost, RCTs are ill-suited in
analyzing harm
Cohort Studies
A group (or cohort) of people exposed to a treatment and a group of
people not exposed are followed for the outcome of interest
Non-randomized
Beware of hidden confounders
Seek adjustments for known confounders
Less expensive and common to study harm
Case-control Studies
– Patients who already have the target outcome (cases) are compared to
patients who are reasonably similar to the cases in important determiners
of disease but don’t have the target outcome (controls) for previous
exposure to a treatment or harmful agent
– Retrospective
– Subject to a high degree of bias
– Useful for rare outcomes or those that take a long time
– Used much more to assess harm
RR (relative risk) = [a/(a + b)]/ [c/(c + d)]
OR (odds ratio) = ad/bc
OR and RR values >1 indicate that there is an increased risk of the adverse
outcome associated with the exposure.
If the RR=1 or OR=1, the adverse event is no more likely to occur with than
without the exposure to the suspected agent.
Conversely, when the ORs and RRs <1, the adverse event is less likely to occur
with the exposure to the putative agent than without.
If the confidence intervals of an individual RR or OR include 1, the event is no
more likely to occur.
NNH can be calculated directly from trials and cohort studies in a fashion
analogous to the NNT
NNH = 1/ARI (absolute risk increase) or
NNH = 1/{[a/(a+b)] - [c/(c+d]}
PEER – the patient-expected event rate (adverse event rate among individuals
with no exposure). To calc NNH in case control studies use PEER.
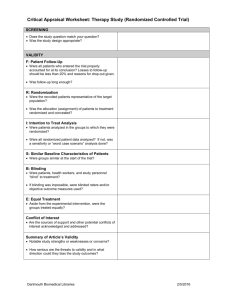
Critical Review Form for Therapy Articles
Citation:
Is this evidence about therapy valid?
Was the assignment of patients
to treatment randomized?
Was the randomization
concealed?
Were the groups similar at the
start of the trial?
Was follow-up of patients
sufficiently long and complete?
Were all patients analyzed in the
groups to which they were
randomized?
Were patients, clinicians, and
study personnel kept blind to
treatment?
Were groups treated equally,
apart from the experimental
therapy?
Is this evidence about therapy important?
What is the magnitude of the
treatment effect?
How precise is the estimate of
the treatment effect?
Are the results applicable to our patient?
Is our patient so different from
those in the study that its results
cannot apply?
Is the treatment feasible in our
setting?
What are our patient’s potential
benefits and harms from the
therapy?
What are our patient’s values
and expectations for both the
outcome we are trying to
prevent and the treatment we are
offering?
Critical Review Form for Harm Articles
Is this evidence about harm valid?
Were there clearly defined groups of
patients, similar in all important ways
other than the exposure to the treatment
or other cause?
Were treatments/exposures and clinical
outcomes measured in the same ways in
both groups? (Was the assessment of
outcomes either objective or blinded to
exposure?)
Was the follow-up of the study patients
sufficiently long (for the outcome to
occur) and complete?
Do the results of the harm study
fulfill some of the diagnostic tests
for causation?
Is it clear that the exposure
preceded the onset of the
outcome?
Is there a dose-response gradient?
Is there any positive evidence
from a “challenge-rechallenge”
study?
Is the association consistent from
study to study?
Does the association make
biological sense?
Are the results of this harm study valid?
What is the magnitude of the
association of the exposure and the
outcome?
What is the precision of the estimate of
the association of the exposure and the
outcome?
What are the results
95 % interval. How tight? Don’t cross 1.
Can this evidence about harm be applied to our patient?
Is our patient so different from those
included in the study that its results
cannot apply?
What is our patient’s risk of benefit and
harm from the agent?
What are our patient’s preferences,
concerns, and expectations from this
treatment?
What alternative treatments are
available?
HARM CHEAT SHEET
Is this evidence about harm valid?
Were there clearly defined groups of patients, similar in all important ways other
than exposure to the treatment or other cause?
For cohort and randomized controlled trials, make sure the patients are
similar. Is a statement that made that there were no significant differences
between the groups made in the paper. Better yet, are p-values given. (For
most articles, this is table one)
For case-control trials (like the one done on March 21st), look again for
similarities in all but the exposure being looked at. In attempts to get
around the inherent weaknesses of this design, investigators usually have
more than one control per study subject – (our article on March 21st
strived for 4 and averaged 3). This increases the strength of the study
Were treatments/exposures and clinical outcomes measured in the same ways in
both groups? (Was the assessment of outcomes either objective or blinded to
exposure?)
Make sure all interactions between the patients, controls and the
investigators and study personnel are the same for both groups. Blinding
should include 3 groups – 1. Pts 2. Study personnel (ie. Principal
investigators, nurses, lab techs, etc. 2. Persons interpreting the results – ie.
Chest x-ray readers, angiogram readers etc.
Was the follow-up of the study patients sufficiently long (for the outcome to
occur) and complete?
As we learned, this is most important for cohort and randomized
controlled trials. As you learn more about pathophysiology, you will be
able to make better judgements here. i.e. years with estrogen and breast
cancer but only hours or days for an allergic reaction.
A moot point for case-control trials.
Do the results of the harm study satisfy some of the diagnostic tests for causation?
For these sets of questions, the overall answers are critical – not the individual
answers to each question. Some of these items (challenge-rechallenge) are rare.
Is it clear that the exposure preceded the onset of the outcome?
Pretty straight-forward. The exposure has to predate
Is there a dose–response gradient?
In other words, does the frequency or severity of the response
parallel the dose of the toxic substance the patient is exposed to.
Is there any positive evidence from a “dechallenge–rechallenge” study?
Does removal of the agent cause abatement of the effect and does
re-introduction cause recurrence.
Is the association consistent from study to study?
May require knowledge of the research in the field – i.e. familiarity
with other studies
Does the association make biological sense?
Usually based on what you learn about the pathophysiology. i.e. It
makes sense that phenylpropanolamine(an sympathetic amine)
would be associated with increased intracranial bleeds as it can
raise BP – it was removed from the market as a result.
Are the valid results of this harm study important?
What is the magnitude of the association between the exposure and outcome?
Basically, what are the results – the numbers.
What is the precision of the estimate of the association between the exposure and
outcome?
Tight confidence intervals that do not cross 1. p-values less than 0.05
Can this valid and important evidence about harm can be applied to our
patient?
Is our patient so different from those included in the study that its results cannot
apply?
Does the study look at an isolated group of patients in the upper Amazon
or a group of patients seen in a suburban practice/
What is our patient’s risk of benefit and harm from the agent?
Here, you have to consider what the patient get in benefits and what the pt
is willing to risk. Some of my patients threaten me if I suggest taking
away their estrogen while others are deathly afraid of estrogen.
What are our patient’s preferences, concerns, and expectations from this
treatment?
See above. Make sure the patient understands what the risks and benefits
are. It is sometimes difficult to discuss population statistics with patients.
If an outcome occurs in that pt, they will have an outcome of 1005. I
sometimes begin the discussion by talking about groups of 100 and how
many of the patients will have the specific outcome.
What alternative treatments are available?
Again, if no other treatments are available and the outcome is not lifethreatening, a patient might be willing to stick with the treatment and
accept the risk. On the flip side, if a lot of treatments are available, the
patient might be less inclined to assume the risk.
ODDS RATIOS
Ad/bc
EBM Therapy Cheatsheet
MS1 Spring 2005-2006
Was the assignment of patients to treatment randomized? Takes care of known and
unknown confounders. Patient characteristics equally distributed between groups
supports effective randomization.
Was randomization concealed? Look for distance (telephone, central), permuted
blocks. Often not stated, in which case your answer is “not explicitly stated”.
Were the groups similar at start of trial? Check table of characteristics. Look for all
p-values to be non-significant. Look for statement that “no significant differences existed
between study groups”.
Was follow-up of patients sufficiently long and complete? Was there enough time for
a disease to get worse or better, or for an adverse event to occur? Requires some
knowledge of disease natural history and prognosis.
Were all patients analyzed to the groups in which they were randomized?
Specifically look for the term “intention-to-treat”, which assures us that the answer to this
question is “yes”. If a placebo subject received the treatment in question, they should
still be analyzed in the placebo group. Were last results carried forward for subjects who
dropped out or did not follow-up after randomization (as they should)?
Were patient, clinicians, and study personnel kept blind to treatment? Placebo
usually applies to patients and clinicians. For study personnel, look for terms like
“blinded interpretation” referring to outcomes, or interpreters that were “unaware of
treatment assignment”.
Were groups treated equally apart from the experimental therapy? Did anyone from
the placebo group get the treatment (contamination)? Did any group preferentially
receive a treatment, other than the one being studied, that would influence outcome
(cointervention)?
What is the magnitude of the treatment effect? ARR=CER-EER NNT=1/ARR Is
the NNT such that it will influence your use of the treatment under study?
How precise is the estimate of the treatment effect? Is there an associated 95% CI? If
so, is it wide or narrow (big time judgment call)? Does it cross “1” (for relative numbers
like RR or RRR) or cross “0” (for absolute numbers like ARR)? If so, this corresponds to
a non-significant p-value. Look at both ends of the 95% CI. If both are important
enough that it would impact how you practice, then the 95% CI is “precise enough” and
clinically important.
Is our patient so different from those in the study that its results cannot apply?
Look at age, gender, severity of disease. Can ask this question about a specific patient, or
about your practice in general. If your patient has a different age or gender than the study
population, ask “does this disease/treatment behave differently in people with a different
age or gender”? You may not know the answer to that question.
Is the treatment feasible in our setting? Is our patient in question (or are our patients
in our practice) similar enough to consider using the treatment? Is the treatment even
available? Cost may be an issue, but most pure treatment studies don’t address cost
directly. That is often done in subsequent studies.
What are our patient’s potential benefits and harms from the therapy? Risk-benefit
analysis. Do the potential benefits outweigh the risks (what are the risks-- look at the
adverse events in the study)? Did adverse events occur more frequently in the treatment
group than the control group?
What are our patient’s values and expectations for both the outcome we are trying
to prevent and the treatment we are offering? Ideally, we would ask our patient what
she wants and expects from treatment. We would assess her desire to get better
(successful treatment) and compare it to her desire to avoid getting worse (adverse effects
or failure of the treatment). We would then make a recommendation for or against
treatment. In our case, let’s figure she wants to get better but really wants to avoid
bleeding or having to limit her lifestyle any more than possible.
Knowing is half the battle:
A likelihood ratio expresses the odds of the presence of disease, given a particular diagnostic test
result.
Reliability is the ability to get approximately the same answer each time.
Kappa is a way to compare expert opinions.
Rate is the number of cases per population.
Cumulative incidence is a proportion.
In actual medical practice, predictive value is more helpful than sensitivity or specificity
The measure that is frequently used as a denominator to calculate the incidence rate is:
Person-years of observation
A proxy indicator is a substitute measure for the actual variable in which we are interested.
Odds ratio is used to calculate risk for backward-looking studies.
Ecological
fallacy
Numerator-only data
2.
Modification
3.
4.
Proxy Indicator
A study is still truly randomized if the control group gets only 33 percent of the participants, if and
only if all participants have an equal chance of that allocation.
Prevalence is frequently used as the prior probability in a Bayesian analysis
A p-value of less than .05 indicates that there is no significant random error in a study.
P-values and confidence intervals are measures of the same thing, that is, statistical significance