Evidence Based Medicine: Review of the basics
advertisement

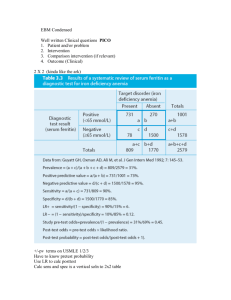
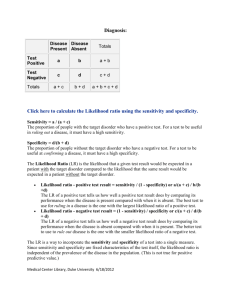
Evidence Based Medicine: Review of the basics DEB BYNUM, MD AUGUST 2010 Moving beyond sensitivity and specificity Hierarchy of Strength of Evidence N of 1 randomized controlled trial Systematic reviews of randomized controlled trials Single randomized trial Systematic review of observational studies addressing patient important outcomes Single observational study addressing patient important outcomes Physiologic studies Unsystematic clinical observations Where to start? The Clinical Question Focus Question types: Diagnosis Harm Prognosis Treatment Next Step: Research Basic Steps in reviewing an article 1. Are the results of the study valid? 2. What are the results? 3. How can I apply these results to patient care? Therapy 1. Are the results valid? Were patients randomized? Was randomization concealed? Were patients analyzed in the groups to which they were randomized? Were patients in treatment and control groups similar? Were patients aware of group allocation? (?blinded?) Were clinicians aware of group allocation? Was follow up complete? 2. What are the results? How large was the treatment effect? How precise was the estimate of treatment effect? 3. How can I apply the results to patient care? Were the study patients similar to the patient in my practice? Were all clinically important outcomes considered? Are the likely treatment benefits worth the potential harm and costs? Therapy: Analyzing Results How good was the treatment? Absolute Risk Reduction Relative Risk Relative Risk Reduction Absolute Risk Reduction Absolute difference in outcomes between the treatment and control groups X% have outcome in control group, Y% have outcome in treatment group ARR = X-Y Relative Risk Risk of events among patients in the treatment group compared to/relative to the risk in the control group Y/X Relative Risk Reduction RRR (1-Y/X) x 100 Why is this the most commonly reported measure of treatment effect? How can this be misleading???? RRR … small treatment effect Pink Potion is new on the market, and is a wonder drug according to Big Bucks Pharmaceutical Company. When taken every day for 20 years, it decreases the risk of developing cell phone related brain cancer by 50% ! (RRR is 50%) You find the risk of such cancers to be 0.25 % in one high risk population. With this 20 year treatment, 0.13% of the population developed the cancer… Risk Reduction: Take Home Beware RRR Calculate ARR whenever possible – this often will put the overall treatment effect into perspective Most reports (especially when advertising/promoting a treatment) will report effects as RRR… How precise was treatment effect? Confidence Intervals: 95% 95% CI defines a range of results that includes the true treatment effect result 95% of the time P <.05 Larger sample size – narrower the CI Using CI to estimate treatment importance “positive study”– look at lower limit for CI, if that number is the true treatment effect, is that important/beneficial when applied to your patient? “negative study” –look at upper limit for CI– if that number is true, would that be clinically important? Study may not prove that a treatment is of benefit, but at same time may not prove that it is not of benefit… Treatment: Applying results to patient care Were the study patients similar to patients in my practice? Were all clinically relevant outcomes considered? Are the likely treatment benefits worth the potential harm and costs? Number Needed to Treat (NNT) NNT Number of patients who must receive a treatment/intervention to prevent one bad outcome or produce one positive outcome 1/ ARR (Pink Potion: NNT = 1/.12% = 1/.0012= 833== need to treat 833 people for 20 years to prevent one case of cell phone related brain cancer…) Number Needed to Harm (NNH) Absolute risk of adverse outcome with treatment – risk of adverse outcome without treatment NNH = 1/ absolute difference in adverse outcomes (just like NNT) Weight NNT with NNH…. Reviewing studies looking at Harm Are the results valid? Was there demonstrated similarity in all known determinants of outcome? Did they adjust for differences in their analysis? Were exposed patients equally likely to be identified in the two groups? Were outcomes measured the same way each group? Was follow up sufficiently complete? What are the results? How strong is the association between exposure and outcome? How precise is the estimate of risk? How can I apply the results to patient care? Were the study patients similar to my patients? Was the duration of follow up adequate? Was was the magnitude of the risk? Should I try to stop the exposure? Design Starting Point Assessment Strengths Weaknesses Cohort Exposure status Outcome event status Feasible when not able to randomize Bias, limited validity Case-control Outcome event status Exposure status Overcomes delays, may only need small sample size Bias, limited validity RCT Exposure status Adverse event status Low susceptibility to bias Feasibility, generalizabilit y Assessing Harm in Case Control Studies Cannot use RR (RR depends upon determining the proportion of patients with outcome – in a case control study, the proportion of individuals with an outcome is chosen by the investigator) Odds Ratio: Odds of a case patient being exposed / odds of a control patient being exposed OR and RR Outcome: yes Outcome: no Exposure: yes A B Exposure: no C D RR= a/(a+b) / c/(c+d) OR = (a/b) / (c/d) If outcome is infrequent in both treatment and control groups, then OR and RR Be nearly the same Studies looking at Harm Can I apply the results to my patient? Were the study patients similar? Was the duration long enough? How big is the risk? Should I stop the exposure? (does risk outweigh any benefit? Is there alternative therapy with less risk?) Diagnostic Testing Thresholds Probability of diagnosis: 0-100% Test threshold Treatment threshold Probability below test threshold: no testing Probability in between : test Probability above treatment threshold: no testing, treat Looking at Diagnostic Tests Are the results valid? Did clinicians face diagnostic uncertainty Was there a blind comparison with an independent Gold Standard applied to both Treatment and Control groups Did the results of the test being studied influence the decision to perform the reference/gold standard? What are the results? What are the Likelihood Ratios associated with the range of possible test results How can I apply the results to patient care? Will the reproducibility of the test result and its interpretation be doable in my clinical setting? Are the results applicable to my patients? Will the results change my management strategy? Will patients be better off as a result of the test? Sensitivity and Specificity Disease + Disease - Test + A B Test - C D Sensitivity: If the patient has the disease, how likely is it that he will have a + test? a/a+c “rules out” disease (not really….) Specificity: If the patient does not have the disease, how likely is he to have a negative test? d/b+d “rules in” disease (again, not really….) The problem with sensitivity and specificity In real life, the question is “the patient has a positive test, how likely is it that he has the disease? Or the patient has a negative test, how likely is it that he does not have the disease?” Predictive Values Disease + Disease - Test + A B Test - C D Positive Predictive Value: How many (%) people with a positive test will have the disease? PPV = a/ a+b Negative Predictive Value: How many people with a negative test will NOT have the disease? NPV = d/c+d Problem: depend upon prevalence (low prevalence population, positive test is more Likely to be a false positive; high prevalence, a negative more likely to be a false negative) Likelihood Ratios LR does not depend upon prevalence and can be more easily applied to a specific patient with a known test result to estimate the post-test probability that the patient has “disease” Points: Not affected by prevalence Can be made specific to your patient (based upon pretest probability of disease) Can be linked with other LRs to come up with a post test probability Does not rely upon test being dichotomous (positive or negative) Likelihood Ratio The likelihood that disease is present given X test result (positive, negative, intermediate, 250) LR: How many patients with X test result HAVE disease compared to number of patients with X test result who do NOT have disease Points about the LR X test result can be positive, negative, intermediate, a number LR always looks at ONE certain test result and always compares likelihood of having disease to likelihood of not having disease LR for a positive test (Positive LR) Likelihood that disease is present given a “positive” test How many patients with a + test HAVE disease compared to # patients with a + test who do NOT HAVE disease True Positive Rate/False Positive Rate LR + test: a /(a+c) / b/(b+d) = sensitivity/1-specificity Higher # (over 10) : better predicting LR + “infinity” = 100% specificity (if the test is positive, the patient has disease, no false positives) LR for Negative Test (-LR) Likelihood that disease is present given a negative test How many patients with a Negative test HAVE disease compared to # patients with a Negative Test who DO NOT HAVE disease False negative rate/true negative rate c/(a+c) / d/(b+d) 1-sensitivity/ specificity Smaller number = better test (fewer patients with a negative test HAVE disease compared to DO NOT HAVE disease) LR – of <.10 usually signficant LR – of 0 = 100% sensitivity (if the test is negative, the patient does NOT have disease – rules “out” disease… Review the chart again… Disease + Disease - Test + A B Test - C D Sensitivity: a/a+c Specificity: d/b+d PPV=a/a+b NPV=d/c+d LR + test: a/(a+c) / b/(b+d) LR – test: c/(a+c) / d/(b+d) How to use the LR LR is ODDS note a % Determine pretest probability (ok to estimate) Determine pre test ODDS (odds= probability/1- probability) Determine Post test ODDS: pretest odds x LR Convert post test ODDS back to probability LR Nomogram P. 129 Looking at Summaries of Evidence Systematic Reviews Meta-analyses Summary articles Are the results valid? Did the review explicitly address a sensible clinical question? Was the search for relevant studies detailed and exhaustive (publication bias) Were the primary studies high quality? Were assessments of studies reproducible? What are the results? Were the results similar from study to study? Were the outcomes the same (comparing apples to apples…) What are the overall results? How precise were the results? How can I apply the results to patient care? How can I interpret the results? Were all clinically important outcomes considered? Are the benefits worth the costs and potential risks? Developing a CAT sheet: Critically Appraised Topic Clinical Question Clinical Bottom Lines Methods Summary of Results (create table if needed) Comments (strengths, weaknesses, limitations) How can I apply this to my patients? References