Multivariate Analysis Overview: Techniques & Applications
advertisement

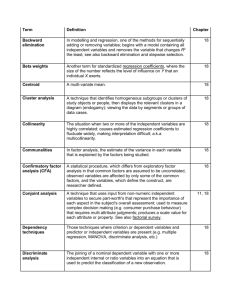
Multivariate Analysis: An Overview CHAPTER LEARNING OBJECTIVES After reading this chapter, students should understand… 1. How to classify and select multivariate techniques. 2. That multiple regression predicts a metric dependent variable from a set of metric independent variables. 3. That discriminant analysis classifies people or objects into categorical groups using several metric predictors. 4. How multivariate analysis of variance assesses the relationship between two or more metric dependent variables and independent classificatory variables. 5. How structural equation modeling explains causality among constructs that cannot be directly measured. 6. How structural equation modeling explains causality among constructs that cannot be directly measured. 7. How principal components analysis extracts uncorrelated factors from an initial set of variables and (exploratory) factor analysis reduces the number of variables to discover the underlying constructs. 8. The use of cluster analysis techniques for grouping similar objects or people. 9. How perceptions of products or services are revealed numerically and geometrically by multidimensional scaling. CHAPTER LECTURE NOTES INTRODUCTION In recent years, multivariate statistical tools have been applied with increasing frequency to research problems. Multivariate analysis—statistical techniques that focus upon and bring out in bold relief the structure of simultaneous relationships among three or more phenomena. SELECTING A MULTIVARIATE TECHNIQUE Classifications of multivariate techniques may be classified as dependency and interdependency techniques. 19-1 Dependency techniques—those techniques where criterion or dependent variables and predictor or independent variables are present. – Interdependency techniques—techniques where criterion or dependent variables and predictor or independent variables are not present. Examples include multiple regression, multivariate analysis of variance MANOVA, and discriminant analysis. Examples include factor analysis, cluster analysis, and multidimensional scaling. Measures to be checked: Metric measures—statistical techniques using interval and ratio measures. Nonmetric measures—statistical techniques using ordinal and nominal measures. DEPENDENCY TECHNIQUES Multiple Regression Multiple regression—statistical tool used to develop a self-weighting estimating equation that predicts values for a dependent variable from the values of independent variables. Multiple regression is used as a descriptive tool in three types of situations: It is often used to develop a self-weighting estimating equation by which to predict values for a criterion variable (DV) from the values for several predictor variables (IVs). A description application of multiple regression calls for controlling for confounding variables to better evaluate the contribution of other variables. Multiple regression can be also used to test and explain causal theories. This approach is referred to as path analysis (e.g., describes, through regression, an entire structure of linkages advanced by a causal theory). Multiple regression is also used as an inference tool to test hypotheses and to estimate population values. Method Multiple regression is an extension of the bivariate linear regression discussed in Chapter 18. Dummy variables—nominal variables converted for use in multivariate statistics. Regression coefficients are stated either in raw score units (the actual X values) or standardized coefficients (regression coefficients in standardized form [mean = 19-2 0] used to determine the comparative impact of variables that come from different scales. When regression coefficients are standardized, they are called beta weights (β) (standardized regression coefficients where the size of the number reflects the level of influence X exerts on Y), and their values indicate the relative importance of the associated X values, particularly when the predictors are unrelated. Example Most statistical packages provide various methods for selecting variables for the equation. Forward selection—sequentially adds the variable to a regression model that results in the largest R2 increase. Backward elimination—sequentially removes the variable from a regression model that changes R2 the least. Stepwise selection—a method for sequentially adding or removing variables from a regression model to optimize R2 . – Collinearity—when two independent variables are highly correlated. – Multicollinearity—when more than two independent variables are highly correlated. – A solution to the above problem can be the holdout sample (the portion of the sample exclude for later validity testing when the estimating equation is first computed). Discriminant Analysis Discriminant analysis is frequently used in market segmentation research. Method Discriminant analysis is a technique using two or more independent interval or ratio variables to classify the observations in the categories of a nominal dependent variable. Once the discriminant equation is found, it can be used to predict the classification of a new observation. The most common use for discriminant analysis is to classify persons or objects into various groups; it can also be used to analyze known groups to determine the relative influence of specific factors for deciding into which group various cases fall. MANOVA Multivariate analysis of variance (MANOVA) assesses the relationship between two or more dependent variables and classificatory variables or factors. 19-3 Method MANOVA: Is similar to univariate ANOVA, with the added ability to handle several dependent variables. Uses special matrices to test for differences among groups. Examines similarities and differences among the multivariate mean scores of several populations. Centroids—term used for the multivariate mean score in MANOVA. Before using MANOVA to test for significant differences, you must first determine that the assumptions for its use are met. Example When MANOVA is applied properly, the dependent variables are correlated. If the dependent variables are unrelated, there would be no need for a multivariate test. Structural Equation Modeling Since the 1980s, marketing researchers have relied increasingly on structural equation modeling to test hypotheses about the dimensionality of, and relationships among, latent and observed variables. Structural equation modeling (SEM) uses analysis of covariance structures to explain causality among constructs. It is most commonly called LISREL (linear structural relations) models. The major advantages of SEM are: Multiple and interrelated dependence relationships can be estimated simultaneously. It can represent unobserved concepts, or latent variables, in these relationships and account for measurement error in the estimation process. Method Researchers using SEM must follow five basic steps: 19-4 Model specification. A formal statement of the model’s parameters. – Specification error—an overestimation of the importance of the variables included in a structural model. Estimation. – – Often uses an iterative method such as maximum likelihood estimation (MLE). Evaluation of fit. – Goodness-of-fit tests are used to determine if the model should be accepted or rejected. Respecification of the model. Interpretation and communication. – SEM hypotheses and results are most commonly presented in the form of path diagrams (presents predictive and associative relationships among constructs and indicators in a structural model). Conjoint Analysis The most common applications for conjoint analysis are market research and product development. Method Conjoint analysis measures complex decision making that requires multiattribute judgments. The objective of conjoint analysis is to secure utility scores (e.g., a score in conjoint analysis used to represent each aspect of a product or service in a participant’s overall preference ratings—also called partworths), that represent the importance of each aspect of a product or service in the subject’s overall preference ratings. The first step in a conjoint study is to select the attributes most pertinent to the purchase decision. Possible values for an attribute are called factor levels. After selecting the factors and their levels, a computer program determines the number of product descriptions necessary to estimate the utilities. INTERDEPENDENCY TECHNIQUES Factor Analysis Factor analysis is a technique for discovering patterns among the variables to determine if an underlying combination of the original variables (a factor) can summarize the original test. 19-5 Method Factor analysis begins with the construction of a new set of variables based on the relationships in the correlation matrix. The most frequently used approach is the principle components analysis (one of the methods of factor analysis that transforms a set of variables into a new set of composite variables). These linear combinations of variables, called factors (the result of transforming a set of variables into a new set of composite variables through factor analysis), account for the variance in the data as a whole. The best combination makes up the first principal component and is the first factor (and so on). The process continues until all the variance is accounted for. Loadings—the correlation coefficients that estimate the strength of the variables composing the factor. Eigenvalues—the proportion of total variance in all the variables that is accounted for by a factor. Communalities—the estimate of the variance in each variable that is explained by the factors being studied. Rotation—a technique used to provide a more simple and interpretable picture of the relationship between factors and variables. – See chapter section for a complete description of the factor loading and rotation process. – The interpretation of factor loadings is largely subjective. – For this reason, factor analysis is largely used for exploration. Example See chapter section for a student grades example; note exhibits that follow. Interpretation If factor analysis’s results are examined with care, it can be a powerful tool. Cluster Analysis Cluster analysis identifies homogeneous subgroups of study objects or participants and then studies the data by these subgroups. Often used in the fields of medicine, biology, and other sciences. 19-6 Cluster analysis offers a means for segmentation research and other marketing problems where the goal is to classify similar groups. Cluster analysis starts with an undifferentiated group of people, events, or objects and attempts to reorganize them into homogeneous subgroups. Method Five steps are basic to the application of most cluster studies: Selection of the sample to be clustered. Definition of the variables on which to measure the objects, events, or people. Computation of similarities among the entities through correlation, Euclidean distances, and other techniques. Selection of mutually exclusive clusters or hierarchy arranged clusters. Cluster comparison and validation. Example The average linkage method (evaluates the distance between two clusters by first finding the geometric center of each cluster and then computing distances between the two centers) is demonstrated. The resulting diagram is called a dendogram. Multidimensional Scaling Multidimensional scaling (MDS) is a scaling technique to simultaneously measure more than one attribute of the participants or objects. A perceptual map is created. 19-7