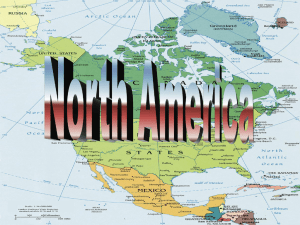
Alissa Marturano
advertisement

Alissa Marturano Assignment 6 For my analysis, I am going to look at priority areas along highways in Vermont for the placement of land bridges based off of roadkill data. To determine the best areas for the bridges, I had to look at several important factors that could influence an area’s priority. I considered the roads with the highest collision numbers and what animals were hit most often in these areas. I also looked into which collisions occurred within biological hotspots, which are areas that represent high biological significance (home to threatened or endangered species) or high biological diversity. Finally, I looked at sections of roads with high wildlife crossing values (≥8). A high value suggests that the area is a significant area for animal traffic. All of these factors together will help me narrow down an area of a specific road in Vermont that would benefit the greatest from a land bridge. Queries Performed: 1. I first performed a select by attribute for roadkill by species that occurred from the year 2000 – 2006, which was the latest record the layer included. I wanted my data to be fairly up to date, and since the attribute table showed dates from 1971, I thought that the last 6 years would be a good way to narrow down the data. I created a new layer for this data. 2. I first performed a summary of the all the species of roadkill to see which were most common throughout the state of Vermont. Though deer roadkill was separated by type of deer (adult, doe, fawn, unknown, buck), as a total, deer represented the highest number of animals killed at 463. The table showed that moose were a close second with 455. Other was the next highest, but since I have limited information on what that category really includes, I decided to dismiss it. Instead, I looked at the next highest species, which was bear at 100. I think that a species’ potential threat to human safety should be considered when addressing where to put a land bridge. Moose, bears, and deer are large animals that can total a car and even possibly kill a driver during a collision. Thus, I chose to zero in on the roadkill for these three species. 3. Before I continued, I used the field calculator to combine all of the deer data into one species type. I added a field which I named species and specified the type as text. Before I was able to use the calculator, I needed to select by attribute all of the deer types; thus, the calculator would work on the selected roadkill data only. I used the field calculator to make species = deer, and all selected roadkill were then labeled deer. I switched the selection for all other roadkill in the attribute table and used the field calculator to make species=MSRI_code, which relabeled the species by their original label. 4. I performed a select by attribute for all roadkill data points that were of bears, moose, or deer and made a new layer out of this data. 5. From this new data layer, I then performed a summary on the roads and highways throughout Vermont to see which have the most collisions. The table on the next page showed that there were large differences in some of the numbers of collisions. There were some roads with less than 10 collisions over a 6 year period. At the same time, there were two roads with more than 50 collisions. Those roads were I 91 (206 collisions), I 89 (99 collisions). There was a category on the table that had the highest number of collisions, but these collisions were not associated with a particular road or highway, so I decided to dismiss them. I decided to narrow in on these 2 roads for potential land bridge areas, since I believe anything less than 50 collisions over a 6 year period would not create alarm. Keep in mind that the collision numbers are for moose, bear, and deer only. 6.Next, I took the new layer I created (roadkill for bear, moose, and deer) and performed a select by attribute for the two highways: I 91 and I 89. For some reason, I was not getting any selection highlights. To work around this error, I opted for selecting I91 and I89 from my roads layer and created a new layer from this selection. Then, I performed a select by location for roadkill within a distance of 100 meters of my 191 and 189 layer. From this new selection, I made a new layer. Since most of my data lacked a route description in the attribute table, I needed to find a way to connect the roadkill points to either I89 or I91. To accomplish this, I performed a spatial join between my I91 and I89 roads layer and the layer of roadkill of bear, deer, and moose. This way, I would have the information of whether each roadkill point was from I89 or I91. I wanted to find the mean of the distances of the points from the highways. To do this, I performed statistics on the field “distance” from the spatial join. The mean was around 25.5 meters, which indicates that the average distance of the actual location of the road kill was around 25.5 meters from either I89 or I91. The minimum was 0, meaning that the roadkill was found exactly on the highway, and the maximum was 97 meters. This could have been because the road kill was moved off the road before the data collector arrived or because the data collector took the coordinates from the side of the road due to safety concerns. (There was one deer representative: adult doe) I wanted to see which species, if any, was being hit more than another species. Thus, I performed a summary on the roadkill. This table revealed interesting information. Moose were the clear winner with 103 collisions, while bear represented 20 and deer only represented 1. 7. In order to choose which road, either I91 or I89, would benefit the most from a land bridge, I wanted to take a look at the surrounding area of the highways. Unfortunately, I could not find a land use data layer for Vermont, which would have been useful in showing where forested areas were along the highways. Forested areas would have been good indicators of wildlife habitat and a bridge should be built where there is forest on either side of the highway. Instead, I opted for using biological hotspots along the highway. If I found a pattern where many collisions occurred within a biological hotspot, I could potentially put a land bridge in that area. I performed a select by location for roadkill found within ecological hotspots and created a layer from this data. Since I could not perform statistics on this data due to the fact that there weren’t any numbers attached to the data, I checked the attribute table of this layer for the count of the collisions in a biological hotspot. There were 28 out of 124. Therefore, biological hotspots may not be the best indicator for where to place a land bridge. Collisions in Hotspots Biological Hotspots 8. Before I make a conclusion on whether or not to use biological hotspots as criteria for land bridge placement, I wanted to look at other factors that could influence animal traffic along the highways. In particular, I wanted to see what parts of the highways had a high wildlife crossing value, one that was ≥ 8. I chose 8 as a minimum because, on a scale from 5-9, 8 seemed like an appropriate number. In order to do this, I needed to make a select by attribute for the WCV layer and select out I91 and I89. Then on this selected layer, I was able to do a select by attribute for a WCV value ≥8. For I91 and I89, there was no part that had a WCV value of 9, so I looked for values of 8 and 8.5. On the map, very few sections of the highways were highlighted. In order to find the actual amount of selected sections, I looked at the statistics. The count was 180 out of 2353, which is really small. Since I could not find a stretch of either I91 of I89 that had a crossing value ≥8, it seems like collisions occurred arbitrarily and were not correlated to a high WCV. Thus, it may make more sense to choose biological hotspots as criteria for land bridges instead. 7. I want to find out more information about each highway so that I can choose which one I will focus on for land bridge placement. To narrow down the exact highway that had the most of the collisions, I preformed a summary on the two highways in the layer from the spatial join. The table revealed that both highways had around the same amount of collisions, but I91 had more with 69. Thus, I would recommend that we place a land bridge on I91 where a biological hotspot contains many collisions. This will require more research that is beyond the goals of this assignment. It is possible that my road data is incorrect as far as placement because I did not compare it to an orthophoto to check for accuracy. This would affect the average distance of the roadkill from the road. In addition, almost all of the data for the bear, moose, and deer roadkill that was selected by location near I91 and I89 did not include information as to which road each animal was found on. Though the spatial join provided me with that information, when I did a summary on the number of collisions for I91 and I89, I was given a different number than I initially did. In my first summary, I found I91 with 206 and I89 with 99, but after the spatial join, I91 collisions reduced to 69 and I89 reduced to 55. This is a huge difference, but the general pattern with I91 being higher is the same. I believe this is because in the first summary, I summarized by the attribute Route_Des. I couldn’t do this after the spatial join because that attribute was blank, hence the purpose of the spatial join. I had to summarize by the LR_ETE attribute. If I am choosing to put a land bridge on the road with the highest collision number, this difference can cause error in my decision. Also, when I did my select by location for roadkill near I89 and I91, I made a buffer of 100m. This picked up 2 data points that were from other highways that were within this 100m buffer. Though the roadkill data indicated they were from other highways (Route_Des), after the spatial join, they were counted on I89 (LR_ETE). Obviously 2 data points will not cause too much error, but it is still a cause for concern because collision numbers were so close (69 and 55).