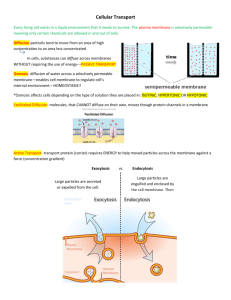
Introduction
advertisement

1 Introduction 1 INTRODUCTION 1.1 Sorting in polarised cells 1.1.1 Epithelial cells In mammals, epithelial cells form continuous cell layers that cover the body surface and enclose all organs and cavities inside the body. Epithelial cells thus have structural and biological differences, but also many important functions in common. They serve as selective permeability barriers, separating fluids with different chemical composition (Alberts et al., 1994). Different epithelial cell types have adapted to quite different environments on each side of their cell layers, and thus the cell membrane is polarised in two separate plasma membrane domains. This polarisation is not unique for epithelial cells, but is a general characteristic common to many cell types. For instance, the plasma membrane in neurones is differently organised in axons and in dendrites. The polarised epithelial cell membrane is divided into apical, lateral and basal domains. To form the selective permeability barrier, individual epithelial cells are joined to each other by tight junctions (Figure 1-1). Tight junctions encircle the cells at the apical end of the lateral membrane in a particular net-like network (Staehelin, 1973). They are crucial for the development of cell surface polarity, since they form an intramembrane diffusion barrier that restricts diffusion of lipids in the exoplasmic leaflet of the plasma membrane (Dragsten et al., 1981). Expression of a mutant occludin, the only known transmembrane component of the tight junctions, disrupts this diffusion barrier (Balda et al., 1996), which shows the importance of this junction in maintenance of polarisation. The tight junctions separate only the outer apical plasma membrane domain from the basal and lateral membranes. The membrane contents in the basal and lateral domains therefore mix freely, and these two membrane regions are thus often referred to as the basolateral domain. Tight junctions Apical Microvilli Lateral Basal Figure 1-1: The structure of the epithelial cell. 5 1 Introduction The tight junctions regulate the passage of ions between the cells. They do not always form an absolute diffusion barrier, but are semipermeable and allow selective passage of certain solutes, but not others (Balda and Matter, 1998). Exchange of larger molecules from one domain to the other is performed by transport through the cells. This transport is selective and depends on the origin of the epithelial cell. The permeability for various substances thus varies among epithelium, and can also change in response to physiological and pathological stimuli. The apical membrane faces the lumen in the cavities or the external environment surrounding the body, while the basal- and the lateral membranes faces the internal environment of the body and are in contact with the blood stream. This reflects the membrane composition of the two domains, which is important, because the two domains have specific functions in adsorption, secretion and ion transport. The basolateral domain has a high content of phosphatidylcholine and proteins involved in the absorption of nutrients. It contains receptors for transferrin, lipoproteins and growth factors, and has the same functions as the membrane in non-polarised cells. This membrane domain is also responsible for adhesion of the cell to the extracellular matrix, and contains cell-cell adherent junctions and cell-matrix adherent junctions (Alberts et al., 1994). The apical membrane contains microvilli and proteins specific for epithelial cells. This domain has an enrichment of sphingolipids, often in the glycosylated form, as glycosphinoglipid. The enrichment of glycosphinoglipids probably protects the apical membrane from degradation by the harsh conditions in the "external" environment. Epithelial cells in the kidney The epithelial cells in the kidney are polarised with the apical membrane facing the filtrate, while the basolateral membrane faces a basal membrane connected to a single layer of endothelial cells (Figure 1-2). This double cell layer functions as a filtration barrier that absorbs nutrients, macromolecules and ions from the filtrate and transports them back to the circulating blood. The waste products are not absorbed, but prevented from re-entering the blood, and remain in the filtrate until secreted with the urine. The epithelial cell layer becomes tighter closer to the collecting duct, the tubule region that transports the urine into the urine bladder. The origin of the kidney epithelial cell thus partly determines the permeability of the epithelial cell layer. Non absorbed molecules are secreted in the urine Filtrate Epithelial cell layer Basal membrane Endothelial cell layer Selective adsorption and transport back to the blood Figure 1-2: The filtration barrier in the kidney. 6 Circulating blood 1 Introduction The Madin-Darby canine kidney cell line The Madin-Darby canine kidney cell line was isolated from a male canine kidney by Madin and Darby in 1958, and used frequently for several years before it was characterised (Gaush et al., 1966). The cell line forms tight junctions, has the morphological properties of distal tubular epithelial cells and lacks several proximal tubular enzyme markers (Rindler et al., 1979). When the cells are cultured on filter membranes, the MDCK cells obtain a morphology that resembles the in vivo situation, and form confluent monolayers, composed of morphologically and functionally polarised cells, with apical and basolateral domains (Barker and Simmons, 1981). The cell line has therefore been used frequently for studies of cellular processes in epithelial cells, and is so far the best characterised epithelial cell line (Simons and Fuller, 1985). Two sublines of MDCK, both distinct and stable in culture, have been characterised (Barker and Simmons, 1981; Richardson et al., 1981). The two cell strains can be distinguished by morphological characteristics, due to different polypeptide composition of the apical membrane (Richardson et al., 1981). The most striking difference between the two strains is, however, their electrical resistance across the epithelial monolayer (Barker and Simmons, 1981). The MDCK I cells resemble tight epithelia by developing a high electrical resistance, whereas much lower values are measured for MDCK II (Barker and Simmons, 1981; Richardson et al., 1981). The difference is also seen in terms of the ion permeability. The ion transport across the monolayer in MDCK I cells is of a small magnitude, whereas MDCK II cells show indications of a more leaky epithelium (Simmons, 1981). 1.1.2 The mutual transport route The formation and maintenance of the apical and basolateral domains, requires a continuous synthesis and delivery of membrane molecules to the right domain. Molecules designed for the apical or the basolateral domain, are first transported through a mutual transport route that starts in the endoplasmic reticulum (ER), goes through the Golgi apparatus and ends in the trans-Golgi network (TGN). The transport starts during translation where secretory, membrane bound and transmembrane proteins are separated from proteins designated for cytosolic localisation. While cytosolic localised proteins are translated on free ribosomes in the cytosol, secretory or transmembrane proteins are translated in complex with the ER (Nunnari and Walter, 1992). Secretory and transmembrane bond proteins contain a N-terminal signal peptide that is recognised by signal recognition particle (SRP) in the cytosol. Binding of the SRP to the ribosome, stops the translation until the complex is bound to the SRP receptor in the ER membrane (Gilmore, 1993). The protein is then co-translationally imported into the ER during translation of the remaining polypeptide. In soluble proteins, the signal protein is removed after translation and the protein released into the ER lumen. Some proteins are attached to the membrane by a glycosylphosphatidylinositol (GPI) anchor, by a phosphoester bond to the C-terminal carboxyl group. Transmembrane proteins contain at least one hydrophobic amino acid segment that stops the translocation, and facilitate integration of the peptide into the ER membrane. Most soluble and transmembrane proteins are N-glycosylated with a 14 sugar residue on asparagine, in the sequence Asn-X-Ser/Thr, during or after the translocation. Addition of oligosaccharides may benefit during maturation, by making the folding intermediate more soluble (Helenius et al., 1997), but it has also other functions. The oligosaccharide is processed 7 1 Introduction in several steps in the lumen of the ER during the folding of the new synthesised protein. After removal of two terminal glucose residues, the oligosaccharide intermediate binds to calreticulin or calnexin, two molecular chaperones in the ER. This binding facilitates correct folding of the protein, in a process helped by another chaperone, binding protein (BiP). BiP recognises incorrectly folded proteins by binding to hydrophobic amino acids, and hydrolyses ATP to provide energy for its role in protein folding (Alberts et al., 1994). Calnexin contains a Cterminal RKPRRE sequence and calreticulin contains a KDEL sequence, both signals that serve as ER localisation signals. Since the chaperones do not dissociate from the protein before it is correctly folded, they function as a quality control mechanism, because the chaperones will prevent that incorrectly folded proteins are leaving the ER (Helenius et al., 1997). The vesicles that transport cargo from the ER to the Golgi apparatus are formed in the smooth ER. In this region, nearly all of the lipids required for elaboration of new cell membranes are synthesised. Newly synthesised lipids and correctly folded proteins are packaged into COPII coat vesicles for anterograde transport. ER resident proteins, like BiP and calnexin, are excluded from COPII vesicles (Barlowe et al., 1994; Rowe et al., 1996). After release from the ER, COPII vesicles rapidly loose their coat (Aridor et al., 1995) and associate with the ER-Golgi intermediate compartment (ERGIC) (Bannykh and Balch, 1997). Transported ER-resident proteins are packaged into COPI vesicles and returned to the ER with retrograde transport, while the new synthesised lipids, transmembrane- and secretory proteins are guided to the Golgi apparatus. The Golgi apparatus consists of a collection of flat cisternae and thus resembles a stack of plates (Rambourg et al., 1995). It has two distinct faces, a cis face aligned towards the ER, and a trans face aligned towards the cell membrane. The mechanism for shipping of cargo through the Golgi apparatus is not known, mainly because the anatomy of the Golgi apparatus is still unclear. Two models are accepted for transport through the Golgi apparatus, which causes frustration in the field. The disagreement is whether each Golgi stack are in a steady state position, or if they float towards the cell membrane (Figure 1-3). Meanwhile, each Golgi stack contains distinct enzymes that process the transported cargo (Machamer, 1993), which catalyse further trimming of the oligosaccharides attached in the ER, O-linked glycosylation, phosphorylation, attachment of glycosaminoglycan chains and sulphation. Information targeting these enzymes to the Golgi apparatus, seems to be contained in the cytoplasmic tails of transmembrane proteins (Machamer, 1993). How they remain in the Golgi apparatus is not clarified, but the transmembrane domains of Golgi resident enzymes are shorter than the transmembrane domains of proteins found in the plasma membrane (Bretscher and Munro, 1993). Since the membranes tend to become thicker, in the direction from the ER to the plasma membrane, the length of the hydrophobic transmembrane domain may thus facilitate protein localisation. 8 1 Introduction A Vesicle shuttle model B Maturation model Trans-Golgi COPI ? COPI COPI Cis Golgi COPI ERGIC COPII COPI COPII ER Figure 1-3: Models for transport of cargo through the Golgi apparatus. A: Vesicle shuttle model: The first model illustrates that movement of cargo between the ER, ERGIC, and individual cisternea of the Golgi stacks require distinct vesicular carriers at each step. Recycling between stacks is mediated by the COPI machinery. B: Maturation model: The second model envisions that COPII vesicles fuse to form the ERGIC, which subsequently assemble to form the first stack. Cargo does not exit the CGN, rather COPI recycling vesicles continuously transport Golgi specific enzymes towards the Cis-face, and with that maturate each Golgi cisternae (Bannykh and Balch, 1997). A combination of both models is also possible. 1.1.3 The selective transport routes A number of different constitutive and regulated routes that deliver proteins to either the cell surface or to a number of compartments of the endosomal system emerge from the TGN. The TGN is the main sorting station with direct routes to the apical and basolateral surface, as well as sorting routes to the endosomal system and secretory granules. A second sorting station in the biosynthetic pathway is early endosomes. They sort apical proteins in cells that use the transcytotic pathway for apical delivery and recycling of lysosomal proteins, and might in addition be involved in the sorting of some basolateral proteins (Keller and Simons, 1997). Sorting signals One basic issue in the biosynthetic pathway is how cells sort the newly synthesised basolateral, endosomal and apical proteins to the right domain. A great majority of the produced molecules are not sorted in TGN, but probably packaged into a casual vesicle and delivered to the apical or the basolateral domain. The distribution of such non-sorted molecules is in accordance with the surface area of the two membrane domains (Scheiffele et al., 1995). However, some molecules show a more strict delivery to one membrane compartment, and they require packaging into the rights transport vesicle. This process is driven by signal(s) in the cargo molecule, which causes selective movement and/or aggregation into the right transport vesicle. 9 1 Introduction Apical secretion signals The first evidence for an apical sorting signal was found in the glycosylphosphatidylinositol (GPI) membrane anchor. When the expression of several GPI-anchored proteins in MDCK cells was examined, several GPI-anchored proteins were found on the apical plasma membrane exclusively (Lisanti et al., 1988). Lisanti et al. thus concluded that that the GPI-anchor may contain the necessary information for targeting to the apical surface. This was confirmed later, when normal basolateral sorted vesicular stomatitis virus glycoprotein (VSV G) was anchored to a small GPI-anchored protein, and this hybrid molecule was secreted apically (Brown et al., 1989). In another experiment, blocking of the GPI-synthesis with mannosamine resulted in nonpolarised secretion of GPI-anchor proteins (Lisanti et al., 1991). Although proteins linked to the membrane via GPI-anchors are delivered to the apical surface, it is not established that GPIanchors themselves function as apical signals. For instance, GPIs that are not linked to proteins are distributed in a non-polarised fashion in MDCK cells (van't Hof et al., 1995). Several years later, it was discovered that N-glycans also might function as sorting signals. A role of N-glycans in apical and basolateral sorting of membrane proteins was excluded by early studies using an inhibitor for the synthesis of N-glycans (tunicamycin), which lead to accumulation of most of the newly synthesised proteins in the endoplasmic reticulum (Green et al., 1981). However, instead of removal of the N-glycans to prove their function as sorting signal, the signal was transferred to a non-sorted molecule. Rat growth hormone (GH), which is nonglycosylated and secreted from both sides of MDCK cell layers (Gottlieb et al., 1986), was secreted to the apical membrane when N-glycosylated (Scheiffele et al., 1995). This proved the role of N-glycans as signals for apical transport of soluble proteins. The reason for the nonsuccess, and accumulation in the ER during the tunicamycin experiments, might be that Nglycans are required for transport out of ER and through the Golgi apparatus. When both the apical sorting determinant (N-glycans) and basolateral sorting cytoplasmic domain determinants were removed in three transmembrane proteins, the proteins accumulated in the ER (Gut et al., 1998). However, all proteins with attached N-glycans were targeted apically, which shows that N-glycans might function as apical sorting signals for transmembrane proteins as well. Other specific determined signals have not been found for apical targeting. However, a protein with a putative lectin-like domain, named VIP-36, has been isolated form apical transport vesicles in MDCK II cells (Fiedler et al., 1994). VIP-36 itself is N-glycosylated, and the luminal domain is capable of binding Ca2+ and N-acetyl-D-galactosamine (Fiedler and Simons, 1996). It has thus been proposed that VIP-36 is involved in the apical targeting of glycoproteins. Moreover, characterisation of a gp40 protein in MDCK I cells has opened for that also other saccharides may function as apical targeting signals. The gp40 is highly O-glycosylated (mucintype) but lack N-glycans, and thus do not contain any of the apical targeting signals known. Still, the molecule is localised on the apical membrane domain in MDCK I cells (Zimmer et al., 1997). When this gp40 was transfected into MDCK II cells, which normally do not express the glycan, it was also delivered to the apical surface. The mechanism underlying carbohydrate-mediate cell surface transport and apical sorting is not known. However, recent evidence for apical transport, suggests a model in which sphingolipidcholesterol "rafts" form within the exoplasmic leaflet of the trans-Golgi membrane (Keller and Simons, 1997). According to Simons and Ikonen (1997), "rafts" are tightly packed microdomains assembled within the fluid bilayer in the TGN, that act as sorting platforms for inclusion of protein cargo designed for delivery to the apical membrane. It has been postulated for a long time, that GPI-anchored proteins use their GPI-anchor to associate with these "rafts" (Brown et 10 1 Introduction al., 1989; Lisanti et al., 1989), and it seems like this signal is sufficient for apical targeting in most epithelial cells lines examined so far. Raft-association can also be mediated by the transmembrane domain of influenza virus HA (Scheiffele et al., 1997). Extraction of cholesterol from cells disrupts the interaction of HA with "rafts", and this is accompanied by reduced apical transport and basolateral delivery of the protein. It could also be conceivable that N-linked glycans interact with "rafts" by binding to lectin-like molecules, like VIP-36 and gp40. The association of lectins with "rafts" can be mediated either by the transmembrane domains of the lectins, or by binding to carbohydrates of the glycolipids, which results in membrane subdomains in the TGN containing glycolipids, cholesterol, GPIanchored proteins, and glycosylated membrane and secretory proteins (Gut et al., 1998). However, there have been found apically secreted N-linked molecules that do not seem to associate with "rafts", for instance bovine enteropeptidase, which contains two apical targeting signals, a N-linked glycosylation domain, and an O-glycosylated mucin-like domain (Zheng et al., 1999). There is also considerably evidence supporting that some integral membrane proteins might use peptidic sorting signals for apical targeting without integration into "rafts". For instance the CD3-, a non-glycosylated protein, is delivered to the apical surface by a glycolipid independent transport pathway (Alonso et al., 1997). These results indicate that there are at least two transport routs for apical delivery emerging from the TGN. However, it has been difficult to really determine how much of a certain protein that is raft-associated, since different laboratorygroups have used different detergent extraction methods to determine "rafts"-association. The different experimental results may thus not be directly comparable. Basolateral secretion signals Until 1991, the existing model for transport of cargo to the cell surface in MDCK II cells was that transport of cargo to the basolateral domain in MDCK II cells followed a "default pathway". This model was established since the basolateral membrane was similar to the membrane in most non-polarised cells, and thus, molecules destined for the basolateral surface did not need sorting signals. Instead, most work was gathered on finding signals for apical targeting, since that domain contained the epithelial cell specific molecules, which were supposed to be selectively delivered to that domain. However, this model was reconsidered when Casanova et al. found evidence for a basolateral targeting signal. A mutant polymeric immunoglobulin receptor (pIgR), lacking a 14 residue segment of the 103 amino acid cytoplasmic domain, directed the receptor to the apical surface instead of the natural basolateral localisation (Casanova et al., 1991). Furthermore, when this sequence was coupled to placental alkaline phosphatase, it was sufficient to redirect this apical membrane protein to the basolateral plasma membrane. They concluded that this sequence contained an autonomous signal, which specifies sorting from the TGN to the basolateral surface, and thus refused that the process occurs by default. Further analysis of the cytoplasmic tail of another receptor, the mannose-6-phosphate receptor/insulin-like growth factor-II (MPR/IGF-II), known to circle between the Golgi, endosomes and the plasma membrane, demonstrated that the tail contained two targeting signals. Deletion of a carboxyl terminal Leu-Leu-His-Val reduced the sorting to the membrane surface, while deletion of the endocytotic signal (Tyr-Lys-Tyr-Ser-Lys-Val) had little effect on the Golgi sorting, but increased the membrane designation. However, deletion of both signals resulted in a complete loss of cycling and delivery to endosomes, indicating that both signals function independently as signals for transport out of the TGN (Johnson and Kornfeld, 1992b). The 11 1 Introduction presence of two signals in the cytoplasmic tail indicates the importance of guiding the receptor to the late endosome/lysosome. Similar signals are later found in other basolateral localised proteins. Until now, three classes of basolateral targeting signals are found, all dependent on cytoplasmic determinants. The first set of signals relies on a critical tyrosine residue placed in the context of at least one large hydrophobic amino acid (YxxØ, where Ø is a bulky hydrophobic amino acid). This group includes the VSV G (Thomas et al., 1993) and influenza virus HA (Brewer and Roth, 1991). The second type consists of a motif grouped around a leucine-leucine or a leucine-isoleucine pair. The di-leucine motif is used by the two MPR receptors for guiding lysosomal proteins towards lysosomes (Johnson and Kornfeld, 1992a; Johnson and Kornfeld, 1992b). The third group contains signals that are neither tyrosine- nor di-leucine-based. Such signals are found in the distal domain of the LDL receptor (Matter et al., 1992), and the pIgR (Aroeti et al., 1993). All these signals differ considerably in their structure, but it is conceivable that the putative sorter can recognise a common structural motif. The basolateral tyrosine signals are related to signals for clathrin mediated endocytosis (Distel et al., 1998), which for the transferrin receptor, originally was believed to be mediated by a -turn in the tyrosine based endocytosis signal (Collawn et al., 1990). Alteration of the tyrosine signal, when it contains an overlapped signal for both endocytosis and basolateral targeting, affects the two processes differently, which indicates that the signals are not identical. For instance, mutation studies in the overlapped signal in the short 19-amino acid cytoplasmic domain of lysosomal acid phosphatase (LAP), revealed that a mutation of the tyrosine to phenylalanine blocked only the endocytosis, whereas a mutation from tyrosine to alanine blocked both processes (Prill et al., 1993). Prill et al. thus postulated that the last mutation resulted in higher destabilisation of the -turn in the signal motif (Lehmann et al., 1992), and that the -turn structure was important in both signals, but most important for endocytotic clathrin assembly. However, a recently published crystal structure of the endocytotic internalisation signal, has revealed that the signal peptide adopts an extended conformation, rather than the expected -turn (Owen and Evans, 1998). Most likely, also the tyrosine-based basolateral targeting signal, forms this extended conformation, rather than the -turn. Transcytosis signals Most molecules are secreted with the direct route to the membrane of destination. However, some follows the indirect route and are transported to the opposite membrane, and then endocytosed and transported to the final destination domain. In most cases, the proteins are transported to the basolateral surface, and then transcytosed to the apical membrane domain. One well studied molecule, pIgR, follows this transport route in epithelial cells (Casanova et al., 1991). The pIgR is normally delivered from the Golgi to the basolateral surface where it binds polymeric IgA and IgM and may transport these to the apical surface. Without ligand binding, the receptor recycles between endosomes and the basolateral surface. This recycling is mediated by the same amino acids initially used for basolateral sorting in the TGN (Aroeti and Mostov, 1994). However, phosphorylation of a serine residue near this determinant results in its inactivation, and, as a consequence, the endocytosed receptor is no longer recycled back to the basolateral surface but is apically transcytosed. Mutation of this amino acid to aspartic acid, not only increases transcytosis, but also increases the direct TGN to apical surface delivery (Mostov and Cardone, 1995). Thus, phosphorylation of serine within basolateral targeting signals can function as transcytosis signals. Still, this can not be the only transcytosis signal, since also nonphosphorylated proteins are transcytosed. 12 1 Introduction The mechanism for packaging into vesicles Sorting signals are recognised by distinct molecular machineries in the TGN, which seem to differ for apical and basolateral secretory vesicles. Separate machineries are required, since apical signals seem to be luminal, whereas the basolateral signals are found in the cytoplasmic tails of transmembrane proteins. Factors involved in the different packaging machineries, may also contain signals for separation of apical and basolateral vesicles once they have budded of from the TGN. There is considerable evidence that annexin XIIIb somehow is involved in packaging and/or transport of cargo from the TGN to the apical surface. Annexin XIIIb is myristoylated, which promotes membrane association. The protein is localised to the trans-Golgi network (TGN), vesicular carriers and the apical cell surface (Fiedler et al., 1995). Annexin XIIIb, in its native myristoylated form, stimulates specifically apical transport, whereas the unmyristoylated form inhibits this route. Moreover, formation of apical carriers from the TGN is inhibited by antiannexin XIIIb antibody, whereas the formation is stimulated by myristoylated recombinant annexin XIIIb (Lafont et al., 1998). It is also shown that annexin XIIIb associates with influenza virus HA in tubular and vesicular-like structures and "rafts" in TGN. These results suggest that annexin XIIIb directly participates in apical delivery, but the role for this annexin in apical transport is not clear. Annexin XIIIb is localised on the cytosolic side of the transport vesicles, whereas all known apical sorting signals seem to be luminal. The protein can be involved in assembly of "rafts"-lipids and proteins into apical vesicles, while another possibility is that it leads to the binding of other molecules to the apical transport carriers, e.g. microtubule motors (Lafont et al., 1998). The packaging machinery that mediates basolateral sorting in the TGN has not been entirely identified, but it seems to have considerable similarity with the mechanism for endocytic signals (Hirst and Robinson, 1998). Until now, two different carriers are found involved in packaging of basolateral vesicles. The first one identified was the AP-1 adaptor complex. It consists of four subunits, and is involved in the recruitment and assembly of clathrin coat for budding of vesicles (Traub et al., 1995). The AP-1 adaptor complex co-localises with the pIgR destined for basolateral delivery (Orzech et al., 1999), and may also function as a sorter in TGN to endosomal and lysosomal transport (Le Borgne et al., 1998; Ohno et al., 1998). Association of AP-1 to TGN is dependent of the small GTPase ARF-1. Cells treated with the drug brefeldin A, which prevents the GTP/GDP-exchange from ARF proteins and causes them to be cytosolic rather than membrane bound, show a rapidly redistribution of AP-1 adaptors to the cytoplasm (Robinson and Kreis, 1992; Wong and Brodsky, 1992). Moreover, removal of ARF from cytosol prevents binding of AP-1 to the TGN, while addition of recombinant ARF-1 restores this ability (Stamnes and Rothman, 1993; Traub et al., 1993). ARF seems to be the only cytosolic factor required, since AP-1 adaptors can be enriched onto isolated TGN membrane fractions by adding myristoylated ARF-1 and AP-1 (Seaman et al., 1996). The other adaptor complex identified, AP-3, is organised with four subunits, as the AP-1 and the AP-2 (endocytotic adaptor) complexes (Simpson et al., 1996; Simpson et al., 1997). AP-3 is associated with the trans-Golgi region of the cell as well as with more pheriperal structures (Simpson et al., 1997). The adaptor protein was first described as independent of clathrin formation for vesicle budding, since it did not co-localise with clathrin at the light- or electron microscopy level, and was not enriched in purified clathrin coat vesicles (Simpson et al., 1996; Simpson et al., 1997). However, it has later been shown that AP-3 associates with clathrin in an in vitro study. In the same study, it was also found that AP-3 colocalised with clathrin by 13 1 Introduction immunofluorescence and immunoelectron microscopy techniques (Dell'Angelica et al., 1998). A conserved segment in the 3A subunit of the AP-3 complex was found to be involved in the binding to clathrin. This sequence, LLDLD, was also found in the 1 and 2 subunits, as well as in other clathrin binding proteins. These results highly favour that the AP-3 adaptor also is dependent on clathrin coat vesicle formation (Dell'Angelica et al., 1998). The different basolateral sorting signals (the tyrosine-motif, the di-leucine-motif and may also the third signal, which is neither of the two others) are recognised by the AP-1 and AP-3 adaptors, but with preferred affinity. Both adaptors bind to the tyrosine signal (YxxØ), but the AP-3 adaptor seems to prefer an acidic residue after the tyrosine (Ohno et al., 1998). This signal is characteristic for proteins targeted to lysosomes or lysosome-related organelles, and is in accordance with the idea that proper targeting of the lysosomal membrane glycoprotein LAMP I to lysosomes requires AP-3 adaptor complex formation (Le Borgne et al., 1998). It has also been shown that the AP-3 complex plays a major role in the selective transport of alkaline phosphatase (Vowels and Payne, 1998) and LIMP II (Le Borgne et al., 1998), which both use a di-leucine signal in the cytoplasmic tail for targeting to the yeast vacuole or the lysosome, respectively. Thus the AP-3 complex also shows a preference for di-leucine signals. AP-3 adaptor formation, however, is not a universal signal for lysosomal transport, since MPR traffic relies on the AP-1 adaptor complex (Ohno et al., 1998)1. The selection and discrimination of the different signalmotifs by the two adaptors, depends on their ability to bind the short signal peptides. The crystal structure of the endocytic adaptor (AP-2), showed that the two bulky hydrophobic residues in the YxxØ-peptide were positioned in two hydrophobic pockets (Owen and Evans, 1998). The binding of a signal-peptide to the two other adaptors is thus probably also dependent on the signal-peptides ability to fill different pockets in the binding site. Several non-clathrin coat proteins identified on the TGN surface, p62 (Jones et al., 1993), p200 (Narula and Stow, 1995) and p230 (Gleeson et al., 1996), which might be involved in generation of basolateral vesicles (Keller and Simons, 1997). Whether these other carriers are coat proteins functioning similarly to clathrin to encapsulate transport vesicles destined for the cell surface, is still unclear. However, a hybrid consisting of a mutant cytoplasmic domain of the cationdependent MPR and the luminal domain in the influenza virus HA, was shown to contain basolateral sorting determinants unrelated to motifs used for clathrin coated pit localisation (tyrosine or di-leucine motifs) (Distel et al., 1998). Neither AP-1 nor AP-2 adaptor complex formation was required for basolateral targeting and recycling of the hybrid molecule, and it is thus interesting to know if the AP-3 adaptor complex is involved. If not, this indicates the existence of three different vesicle machineries for lysosomal and basolateral transport. The mechanism for delivery In epithelial cells, the basolateral cargo is delivered with the direct transport route. Meanwhile, apical transport goes both via the direct route and/or the indirect transport route. Studies of the apically localised aminopeptidase N and dipeptidylpeptidase IV in MDCK, CaCo-2 (colon cell line) and hepatocytes, showed that the proteins were transported with the direct transport route (MDCK II), transcytosed (hepatocytes) and both routes (CaCo2), respectively (Mostov et al., 1992). 1 Note, however, that while alkaline phosphatase and LIMP II are localised in the lysosomes, the MPRs never reach the lysosomes, but are re-directed from the late endosomes to the TGN. 14 1 Introduction There is considerable evidence that apical transport is facilitated by cytoskeletal elements, in particular microtubules and their associated motor proteins (Cole and Lippincott-Schwartz, 1995; Lafont et al., 1994). Generally, apical transport is inhibited by treatment with either nocodazole or colchicine, two microtubule-disrupting agents. Experiments with the actin-depolymerising agent cytochalasin D (CytoD), indicate that actin also may favour apical sorting. CytoD partly inhibits basolateral to apical transcytosis of IgA in MDCK II cells, but has little effect on the basolateral recycling of transferrin (Maples et al., 1997). The involvement of actin and microtubule is not fully determined, however, since apical targeting without functionally microtubule- or actin-filament is also observed. Saunders and Limbird (1997) showed that the sorting of different localised G-protein-coupled receptors, was differently affected by the presence of microtubule- or actin-disrupting agents. Normally, the A1 adenosine receptor (A1AdoR) is apically enriched, and the adrenergic receptor (2BAR) subtype is randomly delivered to both domains, but selectively retained basolaterally. During treatments with microtubule-disrupting agents, the A1AdoR was enriched on the basolateral surface, while the 2BAR subtype was delivered both apical and basolateral. This experiment indicates that there exists two different transport routs for apical sorting, where only the specific apical delivery is dependent of microtubule (Saunders and Limbird, 1997). In addition to microtubules, there are mechanisms that direct specific docking and fusion of vesicles with the target membrane. For several years, it has been postulated that SNAREs (soluble N-ethyl maleimide-sensitive factor attachment protein receptors) direct the specificity, and are required for membrane fusion reactions in basolateral delivery (Hay and Scheller, 1997). The SNARE family is divided in two, according to membrane localisation. SNAREs on vesicles are termed v-SNAREs, and SNAREs on target membranes, t-SNAREs. The different SNAREs are usually localised to distinct membranes or transport vesicles, and pairing of the proper v- and t-SNAREs lead to fusion of vesicles with target membranes. Other soluble proteins, such as the ATPase N-ethyl maleimide-sensitive factor (NSF) and soluble NSF attachment protein (SNAP), interact with the v- and t-SNAREs, and are thought to be general factors involved at some stages in the fusion processes (Low et al., 1998). It has been found that apical to basolateral transcytosis of IgA in MDCK cells requires NSF (Apodaca et al., 1996), and thus transcytosis is suspected to use the SNAP-SNARE mechanism. However, if cognate v- and t-SNAREs could pair at all times, all the organelles in the cytoplasm might be stuck together. Thus, there has to be an additional level of specificity that prevents uncontrolled fusion. It has been proposed that the t-SNAREs are protected by SNARE-protectors and thus are not available for v-SNARE interaction, unless this protector is removed. This regulatory role may be controlled by Rab proteins. The cells produce at least 30 different Rab GTPases, and like SNAREs, most of them are localised on distinct classes of transport vesicles or membrane compartments (Schimmoller et al., 1998). Most Rabs are doubly geranylgeranylated at, or near, their C-termini, which leads to their membrane association. They cycle between an active, GTP-bound form and an inactive, GDP-bound form. Transport vesicles carry Rab proteins with bound GTP, and after membrane fusion, GTPhydrolysis converts them into their GDP-bound form. Rabs, in their GTP-bound conformation, thus seem to recruit the required transport-step-specific docking factors from the cytosol to facilitate v- and t-SNARE paring (Schimmoller et al., 1998). This is shown for basolateral delivery of VSV G in MDCK cells, as well as the route to the dendrites in the neurones, which is dependent of Rab-8 and the NSF-SNAP-SNARE machinery for docking and fusion (Ikonen et al., 1995). 15 1 Introduction It is still not fully determined if these factors are required for apical delivery, since no indication for the involvement of Rabs, NSF, SNAP and SNAREs was found for apical transport of influenza virus hemagglutinin (HA) in the same cells (Ikonen et al., 1995; Yoshimori et al., 1996). The transport vesicles involved in this step were enriched in annexin XIIIb, and antibodies against annexin XIIIb inhibited the reconstituted TGN to apical transport (Fiedler et al., 1995). Keller and Simons (1997), thus suggested that apical and basolateral delivery involves fundamentally different transport mechanism, but a later study has raised doubt about this. Certain t-SNARE isoforms are found localised on the apical plasma membrane in MDCK cells (Low et al., 1996), and even though evidence for a role of NSF has not been found, overexpression of the apical plasma membrane SNARE, syntaxin 3, caused a specific inhibition of the transport from TGN to the apical membrane (Low et al., 1998). Overexpression of a particular SNARE affects, for unknown reasons, most severely the transport step that originally involves this SNARE. This result indicates that all membrane traffic pathways to the plasma membrane in MDCK cells, and probably all other cells, use some of the elements in the SNARE machinery for fusion and docking. However, it is thus still unclear if the SNARE machinery is involved in all vesicles targeting fusion events. 16 1 Introduction Apical domain Lysosome Basolateral domain LE EE 1 2 TGN 1 Apical delivery Luminal signal Microtubule dependent Annexin XIIIb? SNAP-SNARE-Rab? 2 ERGIC ER Basolateral delivery Cytoplasmic signals Recognised by adaptor proteins (AP-1 and AP-3) SNAP-SNARE-Rab Microtubule dependent? Figure 1-4: Intracellular transport routs to the cell surface. Direct transport routs, targeting signals and sorting determinants for transport to the apical (1) and basolateral (2) cell surface in polarised MDCK II cells. The transcytosis, endocytosis and recycling routs, which involve several types of different intracellular compartments, are not shown. Abbreviations: ER; endoplasmic reticulum, ERGIC; ER-Golgi intermediate compartment, TGN; trans-Golginetwork, EE; early endosome, LE; late endosome. 17 1 Introduction 1.2 Proteoglycans 1.2.1 Structure and classification Proteoglycans (PGs) constitute a diverse group of large macromolecules composed of glycosaminoglycan (GAG) chains covalently bound to a core protein (Kjellen and Lindahl, 1991). A glycoprotein is by definition classified as a proteoglycan, when one or more sugar chains is a GAG chain. GAGs consist of long unbranched heteropolysaccharides arranged in a regular pattern of repeating disaccharide units that carry sulphate substitutions in various positions. The repeating unit consists of a hexosamine [N-acetyl-D-glucosamine (GlcNAc) or Nacetyl-D-galactosamine (GalNAc)] and either a hexuronic acid [D-glucuronic acid (GlcA) or Liduronic acid (IdoA)] or a galactose (Gal). The common GAGs include the galactosaminoglycans [chondroitin sulphate (CS) and dermatan sulphate (DS)] and the glucosaminoglycans [heparan sulphate (HS), heparin and keratan sulphate (KS)]. DS, HS and heparin contain both GlcA and IdoA, whereas CS has GlcA as the only hexuronic acid constituent (Figure 1-5). An additional GAG, which is not protein bound, is hyaluronic acid. A hyaluronic acid molecule is composted of 250 to 25000 GlcA and GlcNAc disaccharide units, and is the simplest of the GAG chains, as it does not contain sulphated sugars. Hyaluronic acid is though to represent the earliest evolutionary form of GAG, because of its simplicity (Evered and Whelan, 1989). Except for hyaluronic acid, all other GAGs are potentially sulphated at distinct positions in the repeating disaccharide, either by deacetylation followed by sulphation of the hexosamine, and/or an exchange of a hydroxyl group with sulphate. Imperfect processing gives varying degree of sulphation along the GAG chain. Due to the variability in sulphation, all GAGs, and particularly the GlcA/IdoA co-polymers, display considerable sequence heterogeneity, both within and between GAGs chains. The variation in sulphation and GlcAIdoA epimerisation, results in unique sequences that are important for the biological function of the GAG. Another important function of the sulphation is to increase the negative charge of the GAG chains. The extensive sulphation of heparin makes it the most negatively charged polysaccharide known (Kolset et al., 1994). The dashed lines in Figure 1-5 mark the potential sulphation sites in each GAG. The glycosaminoglycan chains, except for hyaluronic acid, are as mentioned above attached to a core protein. Three different amino acid residues in the core protein function as anchoring sites serine, threonine and asparagine. CS, DS, HS and heparin are O-linked to serine, while keratan sulphate is O-linked to either serine or threonine, or N-linked to asparagine. The alternating disaccharide unit of the GAG is not attached directly to the core protein, but are connected through distinct short linkage regions. CS, DS, HS and heparin are coupled to the core protein through a distinct Xyl-Gal-Gal-GlcA bridge. Keratan sulphate, on the other hand, is connected to more complex oligosaccharide units (Keller et al., 1981; Stein et al., 1982). Corneal KS is Nlinked to asparagine units in the core protein via mannose and GlcNAc residues (Baker et al., 1975; Keller et al., 1981), whereas skeletal KS is O-linked to serine/threonine units via a GlcNAc residue (Dickenson et al., 1990; Nieduszynski et al., 1990). The anchoring of the GAGs to the core protein is schematised in Figure 1-6. 18 1 Introduction GAG Hexuronic or Iduronic acid Galactose Hexosamine Disaccharide composition COO H _ CH2OH O H OH O H H H OH H H NHCOCH3 O H O H Heparan sulphate/ Heparin D-glucuronic acid (GlcA) L-iduronic acid (IdoA) D-glucosamine (GlcNAc) H OH GlcA (14) GlcNAc ( (14) - H H CH2OH O _ O H H COO OH H H OH O H O H H H OH NHCOCH3 IdoA (14) GlcNAc (14) CH2OH CH2OH Keratan sulphate - Galactose (Gal) D-glucosamine (GlcNAc) H H OH O H H O HO O HO H O H H H H OH NHCOCH 3 Gal (14) GlcNAc (13) COO- Chondroitin sulphate D-glucuronic acid (GlcA) - D-galactosamine (GalNAc) H CH2OH O H OH H O H O H H H O HO H H OH H NHCOCH 3 GlcA (13) GalNAc (14) H Dermatan sulphate D-glucuronic acid (GlcA) L-iduronic acid (IdoA) - D-galactosamine (GalNAc) H CH2OH O COOOH H H O D-glucuronic acid (GlcA) H H OH H NHCOCH 3 IdoA (13) GalNAc (14) COO- Hyaluronic acid O H H H O HO - D-glucosamine (GlcNAc) H CH2OH O H OH H OH H O O H H H O H H HO H NHCOCH 3 GlcA (13) GlcNAc (14) Figure 1-5: Structure of the different glycosaminoglycan chains. The structure of the repeating disaccharides in the different types of glycosaminoglycan chains is drawn without sulphation. The different sulphation positions in each GAG are marked by encircling by the dashed line ( ). Different proteoglycans can be classified according to their glycosaminoglycan chain composition, as described above. However, several hybrid proteoglycans carry more than one type of GAG chains. Examples include the large aggregating proteoglycan of cartilage (aggrecan), which has both CS and KS, the cell surface proteoglycan syndecan-1, which contains both CS and HS (Zhang et al., 1995), and betaglycan, which also contains CS and HS (Templeton, 1992). Furthermore, removal of the GAG chain from a PGs does not always affect the most important known function(s) of a proteoglycan, which illustrates that the core protein 19 1 Introduction may be more important for the function. Classification of proteoglycans is thus more instructive if based on protein structure or function, rather than the GAG composition (Kjellen and Lindahl, 1991). Core protein Ser OXylGalGalGlcA Ser/Thr OGalNAc Chondroitin sulphate Dermatan sulphate Heparan sulphate (Heparin) GalNeuNAc GalNAcGal Keratan sulphate Asn NGlcNAcGlcNAcMan ManGalNAc Keratan sulphate ManGalNAc Keratan sulphate Figure 1-6: The functional linkage regions for anchoring of glycosaminoglycans to core proteins Proteoglycans can be classified into five families (Table 1-1). This classification is based on the basic structure of the core proteins and the functional characteristics of the proteoglycans. The function of some proteoglycans will be described later. However, the table illustrates the variation among the different PGs. For instance, the number of GAG chains varies from 1 to more than 100, and the core protein size varies from short to huge polypeptides. Moreover, the overall sizes of the entire proteoglycans varies from as small as about 70 kDa to as large as 3500 kDa (Doege et al., 1990; Sawhney et al., 1991). Source Name and examples Family A Large extracellular proteoglycans Aggrecan Versican Family B Glycosaminoglycan chains 220 265 >100 CS, > 10 KS 12-15 CS 36 38 41 1 DS 2 DS 1 KS 450 2-3 HS 31 110 1-2 CS, 1-2 HS CS, HS 17-19 CS, DS, Heparin, HS Small connective tissue proteoglycans Decorin Biglycan Fibromodlulin Family C Core protein size (kDa) Basement membrane proteoglycans Perlecan Family D Cell surface proteoglycans Syndecan Betaglycan Family E Intracellular proteoglycans Serglycin Table 1-1: Classification of proteoglycans. Classification of proteoglycans after their core proteins and functional characteristic (Kjellen and Lindahl, 1991; Templeton, 1992). 20 1 Introduction The core proteins of most PGs can be subdivided into various domains, which indicate that many PGs have arisen from gene splicing from other genes. Examples of common subdomains are immunoglobulin domains and leucine-rich repeats (Ayad et al., 1994). The core protein also usually carries O-linked, and in some cases N-linked oligosaccharides in a similar fashion to other glycoproteins (Lohmander et al., 1980; Nilsson et al., 1982). 1.2.2 Biosynthesis of xyl-linked proteoglycans Translational and co-translational processes of proteoglycans take place in the rough ER, as for other secretory or transmembrane proteins. Formation and elongation of the GAG chain is then catalysed by several enzymes, which transfer saccharides one by one onto the growing chain. Formation of CS, DS, HS and heparin type GAGs, starts with the transfer of a xylose to a consensus serine residue in the core protein (Kearns et al., 1991; Schwartz, 1977). (The KS-GAG chain is not considered further in this thesis.) This reaction is initiated in the ER or early in the Golgi apparatus (Kearns et al., 1993; Vertel et al., 1993), and catalysed by xylosyl transferase (XT) which transfers a uridine diphosphate-xylose (UDP-D-xylose) to the serine residue (Figure 1-7). The consensus serine residues for GAG attachment was first found to be S-G (Roden and Armand, 1966), and later extended to Ser-Gly-X-Gly, with some acidic acids preceding in the Nterminal direction (Bourdon et al., 1987). However, this sequence is not universal. The "parttime" proteoglycan type IX collagen, with a single CS chain present in 70 % of the secreted molecules, contains a Val-Glu-Gly-Ser-Ala-Asp sequence as GAG substitution region (Huber et al., 1988). This implies that also the protein conformation is important for xylosylation, which has also been postulated by others (Brinkmann et al., 1997). In addition, not all Ser-Gly sequences are substituted with GAG, which further indicates that the protein sequence around the attachment site may be important (Zhang et al., 1995). The next step in the formation of the linkage region is the attachment of two galactose (Gal) residues from UDP-Gal catalysed by to transferases, Gal transferase I and Gal transferase II (Curenton et al., 1991), both residing in the cis or medial Golgi (Sugumaran et al., 1992; Sugumaran and Silbert, 1991). The last saccharide in the linkage region, GlcA, is transferred form UDP-GlcA by GlcA transferase I (Kitagawa et al., 1998). GlcA transferase I has a distribution in both medial and trans-Golgi (Sugumaran et al., 1998) (Figure 1-7). Addition of the next saccharide distinguishes HS/heparin proteoglycans from CS/DS proteoglycans. The growing chain starts with attachment of a GlcNAc for the formation of HS/heparin and a GalNAc for the formation of CS/DS. This reaction is catalysed by specific enzymes, distinct from those used in the following elongation of the disaccharide units in the GAG chain (Fritz et al., 1994; Rohrmann et al., 1985). Either a GlcNAc is transferred from UDPGlcNAc to the linkage region by GlcNAc transferase I (Fritz et al., 1997), or a GalNAc is transferred from UDP-GalNAc by GalNAc transferase I (Kitagawa et al., 1995) localised in the medial and trans-Golgi (Sugumaran et al., 1998). The following elongation of the GAG chain is enzymatic addition of alternating GlcA and GalNAc (CS/DS) or GlcA and GlcNAc (HS/heparin). These reactions are catalysed by UDP-GlcNAc transferase II, UDP-GalNAc transferase II and two different UDP-GlcA transferases (Sugumaran et al., 1997). The site for polymerisation of CS/DS and HS/heparin it thought to be a late Golgi event. Experiments with BFA, indicate that enzymes involved in the biosynthesis of chondroitin sulphate are located in the trans-Golgi network (Spiro et al., 1991) whereas the enzymes involved in the synthesis of heparan sulphate are located in more proximal parts of the Golgi apparatus (Uhlin-Hansen and Yanagishita, 1993). This organisation may be cell specific, since studies of the hybrid molecule 21 1 Introduction serglycin, which contains both chondroitin sulphate and heparin chains when expressed in mastocytoma cells, synthesised both types of chains in the presence of BFA (Uhlin-Hansen et al., 1997). Thus these cells seem to have co-localisation of the GAG synthesising enzymes. transGolgi cisGolgi medialGolgi ERGIC ER COO- CH2OH H H O HO O H H O H H HO H OH O OH H O H O H OH H OH NH H O CH2 CH H H H H H CH2OH HO H O UDP-Xyl transferase UDP-Gal transferase I UDP-GlcA transferase I UDP-Gal transferase II trans-Golginetwork H OH C O GlcA (13) Gal (13) Gal (14) Xyl O Serine Figure 1-7: The UDP transferases involved in formation of the Xyl-linkage region. The distribution of UDP-Xyl transferase (Kearns et al., 1991), UDP-Gal transferase I (Quentin et al., 1990), UDP-Gal transferase II (Curenton et al., 1991) and UDP-GlcA transferase I (Kitagawa et al., 1998) in the ER and the Golgi apparatus. The distribution of the four transferases is determined in cells of different origin, which vary in size, and number of stacks in the Golgi apparatus. The exact positions of the different transferases in the epithelial cell line, MDCK II, may thus not be directly comparable to the positions shown above. Along with the addition of saccharides, the growing chain is modified in various positions. The modifications are (a) sulphation (all), (b) epimerisation of GlcA to IdoA (DS, HS and heparin), (c) deacetylation/N-sulphation (HS and heparin). The sulphation reactions require transfer of sulphate from adenosine 3'-phosphate 5'-phosphosulphate (PAPS), catalysed in the trans-Golgi (Uhlin-Hansen et al., 1997). PAPS is synthesised in the cytosol and transferred to the Golgi lumen by the PAPS transporter (Mandon et al., 1994), and then used as substrate by various sulphotransferases in the Golgi lumen. Presumable, there exists at least one sulfotransferase responsible for sulphation in each position. For instance, three different N-deacetylase/Nsulphotransferases (NDSTs) have been cloned (Aikawa and Esko, 1999), which only deacetylate GlcNAc in the formation of HS and heparin. Other sulphotransferases show less specificity for their target. The 6-O-sulphotransferase that sulphates the Gal residue in keratan sulphate is also able to utilise chondroitin sulphate galactosamine as an acceptor in vitro (Sugumaran et al., 1995). The different modifications on each type of GAG chain are shown beneath (Figure 1-8). 22 1 Introduction GlcAGalGalXyl- GalNAc (GlcAGalNAc)n 4Osulphation/ 6Osulphation GlcAIdoA epimerisation 4Osulphation (6Osulphation) CS DS GlcNAc (GlcAGlcNAc)n Some Deacetylation N-sulphation Some GlcAIdoA epimerisation Extensive Deacetylation N-sulphation Extensive GlcAIdoA epimerisation 2Osulphation/ 3Osulphation/ 6Osulphation 2Osulphation/ 3Osulphation/ 6Osulphation HS Heparin Figure 1-8: The different steps determining the synthesis of CS, DS, HS and heparin glycosaminoglycan chains on the GlcA-Gal-Gal-Xyl-linkage region. Many of the enzymatic reactions modifying the HS/heparin chains are catalysed by multifunctional proteins, such as the NDSTs (Wei et al., 1993), facilitating multiple catalytic events along a single polymer, which increases the polymerisation rate. It is estimated that the HS/heparin polymerisation in the trans-Golgi and trans-Golgi network is carried out at a rate of 80 monosaccharide units/minute (Lidholt et al., 1988). The presence of multifunctional enzymes in the chondroitin sulphate biosynthesis has not yet been investigated, due to the lack of purified enzymes (Sugumaran et al., 1997). The fine structure of chondroitin sulphate appears to be controlled by membrane topography at the site of synthesis, together with the concerted action of different glycosyltransferases and sulphotransferases in juxtaposition to the membrane bound nascent proteoglycan (Silbert and Sugumaran, 1995). 23 1 Introduction Factors determining the type of GAG species to be synthesised It is not known how the cell selects for elongation of the linkage region with either CS, DS, HS or heparin, but the most essential step is probably the attachment of the fifth saccharide (Figure 1-8). This attachment, determines if the produced GAG chain becomes CS/DS or HS/heparin. Note that CS and DS are structurally nearly identical, and only differ in the epimerisation of GlcA to IdoA and a lower 6-O sulphation in DS (see Figure 1-5). The difference between HS and heparin GAGs is the more extensive modification of heparin compared to HS. Until now, several factors have been postulated to influence what type of GAG that is elongated on the linkage region. These include (a) the amino acid sequence flanking the serine residue, (b) the access of UDP-sugars and the presence of GAG synthesising enzymes in the Golgi apparatus, (c) phosphorylation or sulphation of the linkage region. (a) The amino acid sequence flanking the serine residue Some differences in the consensus amino acid sequences for attachment of CS and HS have been found. Most heparan sulphate proteoglycans contain repetitive (S-G)n segments (where n 2) and a nearby cluster of acidic residues (Zhang et al., 1995), while the chondroitin sulphate proteoglycans contain the recognition sequence G-S-G flanked by acidic residues (Brinkmann et al., 1997). However, experiments indicate that the consensus sequence for elongation of CSGAG, may only be required for the synthesis of the linkage region. Normally, cells assemble GAG chains on proteoglycan core proteins, but they can also use -xylosides as primers for GAG formation (Kolset et al., 1990). These compounds bypass the need for xylosylated core proteins and stimulate GAG synthesis beyond the level that occurs on endogenous proteoglycans. In most cells, xylosides prime chondroitin sulphate synthesis effectively, but heparan sulphate synthesis weakly or not at all. It is found that the structure of the alglycones on -xylosides is important for the synthesis of heparan sulphate on the xyloside (Fritz et al., 1994; Fritz et al., 1997). These findings suggest that the UDP-GlcNAc transferases I involved in heparan sulphate synthesis, might requires binding to both the core protein and the linkage region in order to form HS-GAG chain, whereas the UPD-GalNAc transferase I, which primes the chondroitin sulphate synthesis, functions independently of the core protein (Lugemwa et al., 1996). (b) The access of UDP-sugar and the presence of GAG synthesising enzymes in the Golgi apparatus Formation of CS, DS, HS and heparin requires presence of UDP-Xyl in the ER, and UDP-Gal, UDP-GlcA, UDP-GlcNAc and UDP-GalNAc in the Golgi lumen. The active UDP-saccharides are synthesised in the cytosol and are translocated by specialised transporters into the Golgi lumen (Hirschberg and Snider, 1987). Until now, the human UDP-Gal translocator (Ishida et al., 1996; Miura et al., 1996) and the UDP-GlcNAc translocator in MDCK cells (Guillen et al., 1998) have been characterised. The rat liver UDP-GalNAc transporter is characterised but not cloned (Puglielli et al., 1999). Mammalian studies suggest that the translocators are antiporters with the corresponding nucleoside monophosphates (Hirschberg et al., 1998). Uridine monophosphate (UMP) is a competitive inhibitor of the UDP-GlcNAc and the UDP-Gal transporters, and is translocated out of the Golgi lumen as the UDP-saccharides are translocated into the Golgi lumen (Waldman and Rudnick, 1990). During transport of nucleotide sugars, ATP and PAPS into the Golgi vesicles of mammals and yeast, these solutes are concentrated between 50 and 100-fold in the lumen of the Golgi relative to the incubation medium, which suggest that they are actively transported (Hirschberg and Snider, 1987). 24 1 Introduction In a MDCK cell line deficient in transfer of UDP-galactose into the Golgi lumen, the biosynthesis of keratan sulphate is highly reduced, and the modification of glycoproteins and glycolipids are altered, while chondroitin sulphate and heparan sulphate synthesis are virtually intact (Toma et al., 1996). This, together with other studies (Brandli et al., 1988; Deutscher and Hirschberg, 1986), indicates that with limited availability of UDP-galactose in the Golgi lumen, the UDP-Gal is used for formation of the linkage region in CS-GAG and HS-GAG. One likely explanation for this is a lower Km for galactosyl transferases involved in the biosynthesis of the linkage region of proteoglycans (Toma et al., 1996). However, it is also possible that the cell transports UDP-Gal into a pre-Golgi compartment, where the transported UDP-Gal is used to synthesise the linkage region. Nevertheless, the concentration ratio of UDP-GalNAc and UDP-GlcNAc in the Golgi lumen may dictate CS/DS or HS/heparin synthesis. Normally UDP-GalNAc is formed by epimerisation of UDP-GlcNAc, a reaction catalysed by UDP-GlcNAc 4-epimerase in the cytosol, which also catalyses epimerisation of UDP-glucose to UDP-galactose (Piller et al., 1983). A cell line deficient in this gene has defects in the synthesis of glycolipids, and the N-linked and O-linked carbohydrate chains of glycoproteins. The defect can be fully corrected by exogenous Gal and GalNAc, showing that there exist salvage pathways for UDP-Gal and UDP-GalNAc formation (Kingsley et al., 1986). Interestingly, a UDP-GlcNAc pyrophosphorylase isolated from kidney is able to utilise GalNAc-1-P and UTP to catalyse the formation of UDP-GalNAc (Szumilo et al., 1996). Thus, there seems to exist different alternative cell specific pathways for formation of UDP-Gal and UDP-GlcNAc. Both the enzymatic system producing the different UDPsaccharides and the translocators are thus likely to dictate the presence of the UDP-saccharides in the Golgi lumen. (c) Phosphorylation or sulphation of the linkage region. Signals in the linkage region may also dictate the attachment of CS/DS versus HS/heparin. Until now, two different modifications of the linkage region have been discovered - phosphorylation of C-2 of xylose or sulphation in various positions. The C-2 of xylose in the linkage region is a major site for phosphorylation in both chondroitin sulphate (Oegema et al., 1984; Sugahara et al., 1992) and heparan sulphate proteoglycans (Fransson et al., 1985) in cell rich tissues. However, xylose is generally non-phosphorylated in proteoglycans derived from tissues with an abundant extracellular matrix (Cheng et al., 1996; Sugahara et al., 1995a). It is shown that the phosphorylation of C-2 in xylose increases during the attachment of the two Gal residues, while addition of the GlcA residue is followed by rapid dephosphorylation during the biosynthesis of decorin (Moses et al., 1997). In proteoglycans produced by melanoma cells this dephosphorylation is complete, since phosphate is not found even on the intracellular PG (Spiro et al., 1991). In contrast, aggrecan made by chondrosarcoma cells contains phosphate even in the secreted product (Oegema et al., 1984). It may be that dephosphorylation is ineffective in some tumour cells, and in some way may be responsible for the altered proteoglycan synthesis in these cells. The function of phosphorylation is not known, but it may provide a signal for transport of proteoglycans along the secretory pathway and/or for modifications of the growing glycan chain (Moses et al., 1997). The linkage region is also sulphated in various positions in both chondroitin sulphate and dermatan sulphate, but such sulphation has never been detected in heparan sulphate (Kitagawa et al., 1997). Structural studies have revealed that sulphation of C-6 of both Gal residues and C-4 of Gal adjacent to GlcA were characteristic for chondroitin sulphate (de Waard P. et al., 1992; Sugahara et al., 1988; Sugahara et al., 1991; Sugahara et al., 1992). Sulphation of the C-4 of the 25 1 Introduction second Gal residue was also demonstrated in the linkage region of bovine aorta dermatan sulphate (Sugahara et al., 1995a). Heparan sulphate and heparin from several sources have also been analysed, but no sulphate was found on the two Gal residues (Sugahara et al., 1992; Sugahara et al., 1994; Sugahara et al., 1995b). Interestingly, when 2-O phosphate on Xyl was found in the linkage region, the two Gals were non-sulphated (Sugahara et al., 1992). Thus, phosphorylation seems to prevent sulphation, but since phosphate is present in the linkage region of all GAGs, the biological function of this is unclear. Of all possible signals discovered, sulphation seems to be the only signal that could discriminate between CS/DS and HS/heparin synthesis. However, sulphate could also be present in the linkage region during synthesis of all GAGs, and later be removed before secretion. Probably, several of the factors mentioned above influence on the synthesis of CS/DS or HS/heparin type of GAG chain. In contrast, the synthesis of either CS or DS, or the synthesis of either HS or heparin is likely to be controlled by the different GAG synthesising enzymes in the Golgi apparatus. The discrimination between heparan sulphate and heparin is complex and probably set by the composition of the different sulphotransferases and epimerase(s) (Aikawa and Esko, 1999). CS and DS are discriminated by the critical C5 epimerisation of GlcA to IdoA in the biosynthesis of dermatan sulphate. Once one IdoA is formed, the C5 epimerase seems to continue to make more IdoA, which indicate that the formation of the very first IdoA is a critical step (Malmstroem et al., 1993). This epimerisation is found to start with the GlcA in the linkage region in some proteoglycans isolated from bovine aorta (Sugahara et al., 1995a), but never in the first GlcA in heparan sulphate or heparin (Sugahara et al., 1992). Thus, the first epimerisation reaction of GlcA to IdoA could be a trigger for DS synthesis in some cells, and simultaneously prevent the synthesis of HS and CS. 1.2.3 Function of proteoglycans The biological functions of proteoglycans are diverse, and vary from simple mechanical support to more specific and complex effects on cellular processes, such as cell adhesion, proliferation and differentiation. Most of these effects depend on binding of proteins to the GAG chains. This association varies from charge interactions of relatively low affinity and specificity, to highly specific high affinity binding mediated by a particular saccharide structure (Kjellen and Lindahl, 1991). One of the most studied interactions with high affinity and specificity, is the interaction of antithrombin III and a heparin. This binding is mediated by a unique pentasaccharide sequence in the heparin chain (Pejler et al., 1987). Antithrombin is a unique inhibitor of the clotting system and neutralises most of the enzymes generated during activation of the clotting cascade, especially thrombin, factors Xa and IXa. The interaction between antithrombin and the activated clotting factors is at least 1,000-fold increased in the presence of heparin (Mammen, 1998). Interactions with low affinity and specificity are due to the presence of many sulphate- and carboxyl-groups along the GAG chain, which give it a high negative charge at physiological pH. These charges attract basic proteins or basic domains in proteins. Since heparin is the most highly sulphated glycosaminoglycan, it usually binds to ligands more strongly than the other types of GAG chains. CS-GAG has the lowest level of sulphation, and, with the exception of some binding to collagen (Obrink et al., 1975), free chondroitin sulphate fails to interact with common heparin binding ligands. However, when the chondroitin sulphate is in multivalent arrangement, as part of a PG, they can interact with ligands such as fibronectin (Oldberg and Ruoslahti, 1982), collagen (Smith et al., 1985) or vitronectin (Suzuki et al., 1984). This indicates that the accumulation of negative charges is very important for low affinity binding. 26 1 Introduction In the extracellular matrix, the high negative charge of the GAG chains functions to maintain the matrix hydrated. The glycosaminoglycan chains attract cations that are osmotically active, and create a swelling pressure that enables matrix to withstand compressive forces (Roughley and Lee, 1994). In addition, most, if not all, proteoglycans in the extracellular matrix bind to other components (Ruoslahti, 1988). The usual mode of binding is through interaction of the GAG chain with a binding site in the matrix protein, but some proteoglycans also bind through their core proteins. For instance, decorin can bind to collagen (Vogel et al., 1986) and fibronectin (Schmidt et al., 1987). The binding site in collagen is quite specific, and important, since decorin regulates the thickness of collagen fibrils in the matrix (Vogel and Trotter, 1987). Due to their structural diversity, PGs in the extracellular matrix can also form selective barriers to regulate the traffic of cells and molecules according to size, charge or both. This role has been suggested for perlecan, a HS proteoglycan in the basal lamina of the kidney glomerulus (Kasinath et al., 1996). The sulphation of the GAG chains is important, since reduced sulphation often leads to dysfunctional filtration in the kidney, as observed in diabetes (Kolset et al., 1994). It is shown that the matrix HS synthesis and sulphation is down-regulated in glomerular epithelial cells when cultured in high glucose (Kasinath et al., 1994), and that this effect is not caused by insulin deficiency (Kasinath, 1995). The mechanism giving this effect is however not known, but increased glucose, or D-glucosamine levels, is shown to induce transforming growth factor 1 (TGF-1) expression in porcine glomerular mesangial cells (Kolm-Litty et al., 1998). Via an autocrine pathway, the increased TGF- production is though to induce the synthesis and accumulation of matrix components, and to inhibit mesangial cell proliferation. TGF- is also shown to promote chondroitin sulphate attachment, and lower heparan sulphate attachment on cell surface proteoglycans in mouse mammary epithelial cells (Rapraeger, 1989). High glucose in the blood, may thus be one of the factors that alters the basal lamina and induces diabetic nephropathy in some diabetic patients (Kasinath et al., 1996). 1.2.4 Serglycin The proteoglycan serglycin was first isolated form rat yolk sac tumour cells (Oldberg et al., 1981) and later renamed from PG19 to serglycin, due to the long alternating sequence of serine and glycine in the core protein (Ruoslahti, 1988). The human serglycin gene has been cloned and sequenced (Humphries et al., 1992) and found to be localised on chromosome 10 (Stevens et al., 1988). The functional gene consists of three exons. Exon one codes for the 5'-nontranslated end and the hydrophobic signal peptide (29 amino acid). Exon 2 codes for 49 amino acids, which makes the N-terminal end after removal of the signal peptide in the ER lumen. Exon 3 codes for 17 amino acids, and the 18 amino acid repeating Ser-Gly sequence, followed by the 47 amino acids, which makes the C-terminal end (Humphries et al., 1992). The biological functions of serglycin are poorly understood, but several studies of interactions between serglycin and other components indicate some of its biological functions. Studies have shown that serglycin is localised intracellularly in hematopoietic cells (Kolset and Gallagher, 1990), where the core protein is substituted with chondroitin sulphate, with the exception of mast cells where the core protein contains a mix of chondroitin sulphate and heparin (Lidholt et al., 1995). Serglycin may in fact be the only natural source of heparin. Serglycin has been shown to be a carrier of proteases (Masson et al., 1990) and to bind chemokines (Kolset et al., 1996), where it probably functions in packaging and stabilisation of the secretory proteins in the vesicles. The enzymes are concentrated in an osmotic inactive form, and probably prevented from self-degradation or degradation by other proteins (Kolset and Gallagher, 1990). Serglycin 27 1 Introduction has also been found to be a novel ligand for the surface bound CD44 (Toyama-Sorimachi et al., 1995). Serglycin expression seems to be closely associated with the hematopoietic cell differentiation pathway (Maillet et al., 1992). It is not even constitutively expressed in non-stimulated proliferating monocytic U937 cells (Kulseth et al., 1998). Stimulation of endothelial cells with chemokines like TNF- and IL-1, which are normally produced during inflammatory reactions, increases the mRNA expression level of serglycin (Kulseth et al., submitted). This, and the other experiments, highly indicates that serglycin has several functions, which may also be different in different cell types. 1.2.5 CD44 The CD44 family belongs to a larger group of hyaluronic acid binding proteins (Toole, 1990). In humans, the CD44 family consists of 16 exons derived from a single gene located on the short arm of chromosome 11 (Dougherty et al., 1991; Goldstein et al., 1989). Through alternative splicing of the newly synthesised RNA, the CD44 gene can give rise to many different isoforms of CD44 (Underhill, 1992). The isoform diversity is generated by incorporation of amino acid stretches encoded by exon 6 to exon 14 (Henke et al., 1996). Transcripts with these variant exons spliced out, encode the most common and widely expressed 85 kDa isoform (CD44s). The expression of CD44 isoforms containing sequences encoded by the variant exons (CD44v), however, is tightly regulated. Expression of these isoforms can be tissue specific, developmental regulated and/or regulated by cell activation (Sleeman et al., 1997). All of the isoforms are glycosylated, and they contain both O- and N-linked carbohydrate side chains (Underhill, 1992). They do also contain a CS attachment region (E5 region), while only the isoform containing the V6 region contains a HS attachment region (Greenfield et al., 1999). Both functionally and physically, the CD44 molecule can be divided into three major domains, the cytoplasmic domain, which mediates interactions with the cytoskeleton, the middle domain, which is responsible for the lymphocyte homing, and the amino terminal domain, which binds to hyaluronic acid. The most important isoforms are CD44H (a CD44s), which is associated with meshencymal cells, and CD44E (R1) (a CD44v), which is associated with actively dividing epithelial cells. The functions of the variably spliced isoforms containing inserts (CD44v) are largely unexplored. It has been shown in a rat model of tumour metastasis, that a previously non-metastasising cell line can be altered to aggressively metastatic by the overexpression of CD44 variants containing exon V6 (Gunthert et al., 1991). The V6-epitope is also required for lymphocyte activation (Arch et al., 1992). Introduction of the V6 and V7 epitopes in CD44 permits the N-terminal hyaluronic acid motif to bind to several types of GAG, in addition to hyaluronic acid (Sleeman et al., 1997). Another study has shown that CD44 is capable of binding to fibrinogen/fibrin, and thereby able to mediate endothelial cell migration and invasion into the fibrin matrix during wound repair (Henke et al., 1996). Both xylosides and anti-CD44 antibodies blocked cell migration, which indicates that chondroitin sulphate present on either the CD44, or another proteoglycan, was essential for migration. These wound microvascular endothelial cells express both the CD44H isoform and an isoform containing the variably spliced exon V3. This last variant is the only isoform that may be attached with both heparan sulphate and chondroitin sulphate (Brown et al., 1991). 28 1 Introduction Interactions of serglycin and CD44 Although no specific ligands have been identified for CD44v isoforms, several ligands have been ascribed to CD44s isoforms, including mucosal addressin, collagen type I, fibronectin, MIP-1, the chondroitin sulphate form of invariant chain, osteoponin and serglycin (Sleeman et al., 1997). At least for serglycin, the binding by CD44 is dependent on the presence of chondroitin sulphate on the serglycin core protein (Toyama-Sorimachi et al., 1995). The interaction of serglycin and CD44 is mediated by chondroitin 4-sulphate, chondroitin 6-sulphate or a mixture of both (Toyama-Sorimachi et al., 1997). Toyama-Sorimachi et al., thus postulated that serglycin serves as a major ligand for CD44 in various events in the lymphohematopoietic system. Most T-lymphocytes express CD44, but do not bind hyaluronate or serglycin unless they are activated (Toyama-Sorimachi et al., 1995). This indicates that, although hyaluronate or serglycin may be found frequently in the hematopoietic milieu, ligation with CD44 occurs only when an appropriate activation stimulus is present. This is interesting, since CD44 was initially identified as a lymphocyte homing receptor in mucosal lymphoid tissues (Jalkanen et al., 1987). This CD44-mediated lymphocyte binding to mucosal high endothelial venules is independent of hyaluronic acid binding (Culty et al., 1990). Thus, CD44 has at least two distinct functional domains, one for binding of hyaluronate, and another involved in interactions with mucosal high endothelial venules. The interaction between rapidly moving leukocytes with the endothelium is mediated by several steps. The first step involves the members of the selectin family, which slow down the flow of leukocytes through postcapillary venules, and promote transient adhesiveness to the endothelium (also called rolling). The second step involves integrins, which convert the transient interaction to a strong adhesion. The initial stage involves a number of chemokines (Kincade, 1993). The chemokine MIP-1 binds to lymph node endothelium, and induces binding of T-cells to VCAM, in the presence of CD44 or heparin, in vitro. This demonstrates that the presence of a glycosaminoglycan was essential for binding. However, it has not yet been demonstrated that CD44 alone is the essential proteoglycan. Thus, it is interesting that both serglycin and CD44 is up-regulated in inflammatory endothelia, which indicates that they are tightly regulated, and probably function together in the recruitment of leukocytes through the endothelium (Kulseth et al., submitted). This was also postulated by Toyama-Sorimachi (1997), but since they failed to detect serglycin in endothelial cells, with the use of antibodies, they excluded this possibility. There are several possibilities for the involvement of serglycin in the lymphocyte homing process. With an activated serglycin binding form of CD44 on both the circulating lymphocyte and the endothelia, serglycin can simply mediate cell adhesion by connecting the two cells. However, the mechanism is likely to be another, because the circulating lymphocytes do not normally contain the serglycin binding form of CD44 before they are activated (ToyamaSorimachi et al., 1995). Thus, it is more likely that when the endothelium is stimulated to induce lymphocyte adhesion, they induce the synthesis of the serglycin binding form of CD44, which binds the secreted serglycin in complex with the chemokines. This complex holds the chemokine at the activated endothelium only, and functions to recruit a lymphocyte, which becomes tightly bound, and then activated to migrate through the endothelium (Figure 1-9). 29 1 Introduction Circulating leukocyte MIP-1 receptor CD44 CD44 In the presence of MIP1, the leukocyte adheres to the endothelium, and starts to migrate through the endothelium. Integrin (ICAM / VCAM) Stimulation of endothelium during inflammation Mucin Selectin Activated LFA-1 or VLA-4 Vesicle containing serglycin with bound chemokine Figure 1-9: The involvement of serglycin in leukocyte recruitment through the endothelial cell layer. The figure is modified after (Tanaka and Aso, 1998). Another important interaction between CD44 and serglycin is probably also present during cytotoxic T-cell activation. The interaction between serglycin and CD44 was originally found when it was discovered that the mouse cytotoxic T cell line CTLL2, transfected with CD44, was self-adhesive, and formed large aggregates (Toyama-Sorimachi and Miyasaka, 1994). In further analysis, a 600 kDa proteoglycan was co-immunoprecipitated together with the transfected CD44. This proteoglycan was found to contain CS-GAG chains, and to consist of a 18-22 kDa core protein. The specific binding was determined to be mediated through the CS-GAG chains attached to the serglycin core protein (Toyama-Sorimachi et al., 1995), and the binding site was found to overlap with, or was close to, the hyaluronic acid binding domain. The attachment of the chondroitin chains to the serglycin core protein is important, because free CS-GAG is not able to bind to CD44. In addition, the binding is only mediated when the cell line expresses the active form of CD44 on the surface. Interestingly, a 600 kDa proteoglycan is also required for secretion of granzyme A and different chemokines (RANTES, MIP-1 and MIP-1) in HIV-1 specific CTLL cells (Wagner et al., 1998). The granzyme A and the chemokines, facilitate both lysis of virus-infected cells and inhibit the action of free virus. They are stored in complex with this proteoglycan in intracellular granules until stimulation, which results in its secretion. Even though this proteoglycan is not yet identified, there is likely that the proteoglycan can be serglycin. Serglycin is shown to bind MIP1 in macrophage-stimulated U937 cells (Kolset et al., 1996), and RANTES is able to bind to a 30 1 Introduction CS containing artificial proteoglycan (Wolff et al., 1999). Thus, serglycin may have a fundamental importance in the defence against HIV, and is probably also involved in other immunological reactions. Once secreted, serglycin may function to concentrate the chemokines at the appropriate position, and prevents them from being washed away by the circulating blood. If the virus-infected cells express the serglycin-binding form of CD44, the serglycin/chemokine complex is thus likely to bind to target cells only. Infection MHC CD3 TCR MHC LFA-3 CD2 LFA-3 CD44 CD44 Cytotoxic T cell Infected cell Activation Serglycin with bound chemokines MHC: Major histocompatibility complex LFA-3: Lymphocyte functionassociated antigen-3 TCR: T cell receptor MHC LFA-3 CD3 TCR CD2 CD44 Figure 1-10: Recognition of an infected cell by a cytotoxic T cell. The figure is modified after (Wolff et al., 1999). A model showing how serglycin may be involved in the lysis of virus-infected T-cells. Serglycin is secreted with bound granzyme A and/or chemokines (RANTES, MIP-1 and MIP-1) after activation of the cytotoxic T-cell. 31 1 Introduction 1.3 Aim of study The topic of this diploma thesis was to construct a recombinant serglycin-His-flag, which could enable simple purification and detection of the secreted molecule, and then to study the secretion of this recombinant serglycin-his-flag in both epithelial and endothelial cells. It has been shown that polarised cultured MDCK II cells synthesise both chondroitin sulphate (CS) and heparan sulphate (HS) proteoglycans, but that the CS proteoglycans are secreted to the apical compartment exclusively (Vuong, 1998). Treatment of the cells with heksyl--xyloside, which primes CS glycosaminoglycan (CS-GAG) chain synthesis in these cells, results in apical secretion of the CS-GAG chains (Kolset et al., 1999). This apical secretion, whether the CSGAG chain is attached to a core protein or not, may be due to a signal for apical sorting in the CS-GAG chain. We thus wanted to study the secretion of the recombinant serglycin-His-flag, often found to be a CS proteoglycan, in MDCK II cells. The proteoglycan serglycin has previously been considered as a hematopoietic expressed gene (Toyama-Sorimachi et al., 1995), but other cells, including endothelial cells, have recently been shown to express serglycin mRNA (Kulseth et al, 1999). The expression in non-hematopoietic cells, highly indicates that the molecule has multiple functions. One of the most interesting properties is the interaction with CD44, which may have cell specific functions. However, detection of the synthesised serglycin has been difficult, which has complicated the study of its biological function. A way to overcome this problem, would be to transfect endothelial cells with a vector encoding the recombinant serglycin-His-flag, and then purify the recombinant molecule to analyse the biological function of serglycin. Both of these projects require splitting into several minor projects, which could be defined as: 32 Cloning of the serglycin-His-flag vector. Transfection of endothelial and epithelial cells. Selection of stable transfected cells, and determination of recombinant mRNA expression- and recombinant PG secretion levels in the obtained subclones. Optimisation of a metal chelating chromatography system for isolation of the recombinant serglycin-His-flag. Purification of the secreted serglycin-His-flag. Determination of the GAG chains attached to the recombinant serglycin-His-flag. Study the secretion of recombinant serglycin-His-flag in MDCK II cells.