Structure of the Genome
advertisement

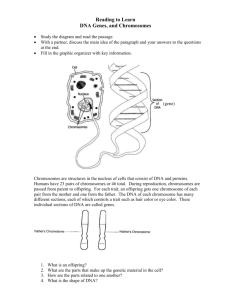
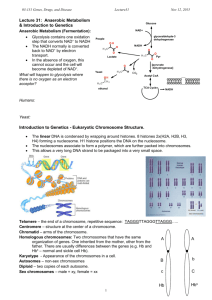
PHAR2811 Dale’s lecture3 page 1 Structure of the Genome Lecture Synopsis: Review DNA structure. What does the DNA look like in a cell? Chromosome length, diversity and packaging e.g. histones . Heterochromatin and euchromatin and their relationship to transcription. Review of DNA structure DNA is a biopolymer made up of nucleotides; the sugar; deoxyribose, the phosphate, the base: adenine, thymine, guanine or cytosine. The nucleotides are able to base pair; Adenine to Thymine and Guanine to Cytosine. They are known as complementary or forming Watson and Crick canonical base pairs. The nucleotides are joined via a phosphodiester bond, forming a polymer which has a 5’ phosphate (PO4) “head” and a 3’hydroxyl (OH) “tail”. DNA exists in the cell as a double stranded structure; the base sequence of each strand is complementary to the other; one strand in the 5’ to 3’ orientation and the other in the 3’ to 5’ orientation. The strands base pair throughout the full length of the structure. DNA is a specialised structure that functions as the genetic store of the cell; the template. The absence of the OH at position 2’ of the ribose is a modification unique to DNA which enhances the stability of the backbone to base attack (RNA, which retains the OH at position 2’ is much more susceptible to base attack). The thymine (methylated uracil) ensures that corruptions to the code brought about by spontaneous deamination of cytosine can be corrected. Thymine also only exists in DNA. Other structural features which contribute to DNA’s role as genetic storehouse are: The double stranded structure provides protection to the information containing face of the bases, an extra copy of the information and a template for repair. The outside of the DNA, with its predominating phosphate groups and sugar is very hydrophilic. The bases, buried in the interior, are much more hydrophobic and the information in the very heart of the molecule is polar. The exterior properties make it very difficult for potential mutagenic compounds to penetrate the hydrophilic outer shell, move through the hydrophobic interior to the polar information centre. PHAR2811 Dale’s lecture3 page 2 DNA Packaging The genome of any organism, be it a eukaryote or a prokaryote contains a lot of information so the DNA becomes extremely long. Some useless statistics to drive home the point: E. coli has one single circular chromosome containing one long DNA molecule 1.3 mm in length. The bacterium it has to fit in is a cylinder of diameter ~1 m and length 3 m. In other words the bacterial dimensions seem to be 1/1000 th of the length of the DNA (mm m). The DNA is packaged as loops that are then supercoiled and associate with proteins forming a dense structure termed the scaffold. The full human genome contains 2 metres of DNA (this is all 46 chromosomes worth!) in each cell. There are about 1013 cells in your average human (some have more, some less). Therefore there must be 2 X 1013 m of DNA. Another useless fact: the distance from the earth to the sun is 1.5 X 1011 m. This means there is enough DNA in the average human to stretch from the earth to the sun and back about 50 times!! The 2 metres of DNA has to be packaged into a nucleus with a diameter of ~6 m. This makes packing the family station wagon to go camping look like a breeze!! How is this amazing packaging achieved? Geneticists for years have predicted the existence of chromosomes; both from microscopy and from the observation that certain genes did not inherit in the standard Mendelian pattern. Up until now you have had this view that genes are sections of double stranded, double helical DNA that code for one polypeptide chain. This is a very precise and accurate definition but gives no idea of how it exists in the cell. You have been taught that the hereditary material is DNA yet it appears as chromosomes. Prokaryotes: The genome of prokaryotes is extremely efficient. Survival depends on the ability to divide rapidly when nutrients are available so there is no room for extra non-coding stretches of sequence. Using the quintessential prokaryote example, Eschericha coli, affectionately known by all as E. coli, this organism contains 4.6 million nucleotide pairs or base pairs (bp). Consider your average E. coli bacterium: each protein on average has a molecular weight of ~35 000, thus requiring ~350 amino acid residues (assuming the average molecular weight of an amino acid residue is 100). This in turn will need 1 050 base pairs which after including intergenic sections, promoter regions and termination sections will give a final “gene” of 1 500 bp. If the bacterial genome contains ~4.6 million bp then the bacterium can code for ~ 3 000 proteins. This is within the “ball-park” estimate of the number of total number of proteins produced by E. coli. PHAR2811 Dale’s lecture3 page 3 Despite this efficiency the DNA even for E. coli is quite long and as mentioned earlier requires scaffold proteins to package it into the cell. The drawings I usually do of a neat little circle sitting happily inside a cell may be a tad simplistic! BUT as mentioned earlier this is nothing compared to eukaryotic DNA. For a start eukaryotes are not as efficient with their code. Evolutionary imperatives for multicellular organisms are not driven by the ability to colonise when ever and where ever they can. The multicellular organism will be successful if it can adapt to its environment; if its organisation responds quickly etc. In fact to have uncontrolled proliferation, such as that seen with bacteria, in a multicellular organism is termed cancer!! Because dividing rapidly is not a top priority eukaryotes, particularly higher forms, can afford redundancy in the code. E. coli double every 20 min under optimal conditions, human cells take 18 - 24 h to complete one round of the cell cycle. This redundancy is seen as extra non-coding sequence. In fact it is estimated that only ~2 % of the human genome is actually coding i.e is transcribed and translated into protein. We will discuss the rest in the next lecture. Chromosome characteristics: Chromosomes vary in number between species. The chromosome number is a combination of the haploid number (n) X the number of sets. Algae and fungi are haploid; most animals and plants are diploid. The number of pairs of chromosomes in different species genomes is bizarre. Humans have 23 pairs, cows have 39, carp have 52 yet alligators (who no doubt eat the carp) have only 16 pairs! Your position in the food chain does not have much bearing on the amount of genetic material contained in your genome!! The award for the largest number of chromosomes falls to a flowering plant Chromosomes vary in size within a species. Within the human genome there is a four fold difference in the size of the chromosomes. The ps and qs of chromosomes. Centromere: the region of the chromosome where the spindle fibres attach. This is mediated by the kinetochore. Repetitive satellite DNA is often found around the centromere. The relative position of the centromere is constant, which means that the ratio of the lengths of the two arms is constant for each chromosome. This ratio is an important parameter for chromosome identification, and also, the ratio of lengths of the two arms allows classification of chromosomes into several basic morphologic types: PHAR2811 Dale’s lecture3 page 4 Telomere: ends of the chromosome, containing a distinct repeating sequence, which enables the ends of the chromosome to replicate. Special telemerases perform this task. They are very important in the aging process. We will cover this in more detail in a further lecture. Chromatids: During cell division each chromosome is duplicated by replication. At metaphase the pairs line up. Each chromosome consists of two sister chromatids, attached at the centromere. The arms: The short arm of the chromosome is the p or petit and the long arm is denoted by q (queue). Chromosome banding Chromosomes can be stained with special dyes which give a consistent and unique pattern like a barcode for each chromosome; so much so that the bands have been numbered. The most common stain used is a Giesma stain. This stain, when applied after mild proteolytic treatment (trypsin) gives light (G-light) and dark (G-dark) bands. When viewed at the lowest resolution only a few bands appear. These are numbered p1, p2, p3 etc counting from the centromere. If the stained chromosomes are viewed at higher resolution many sub-bands are revealed. So the labelling then goes p11, p12, p13. So if your DNA marker may be given a position on the chromosome with a set of numbers like 17p23. This means the locus is on chromosome 17 on the short p arm in sub-band 23. Some more terms: The general material which makes up the chromosomes is called chromatin by cytogeneticists. This is composed of DNA and protein. When stained with DNA-reactive stains there appears to be two different regions; one which stains well and one which doesn’t. The densely stained region is known as heterochromatin; the poorly stained region is euchromatin. The densely stained heterochromatin contains DNA which is more tightly packaged or condensed and probably is not being actively transcribed. Most of the active genes are located in the euchromatin. PHAR2811 Dale’s lecture3 page 5 Chromosome packing at the molecular level. So how does the DNA fit? The DNA is wound around a series of very basic (positive) proteins called histones. These proteins are small with lots of lysine and arginine residues, giving them a high pI (~12) and lots of positive charges at pH 7. There are 5 separate histone species: Histone H1, H2A, H2B, H3 and H4. Histones 2A, 2B, 3 and 4 assemble as dimers to form an octamer (2*2A+2*2B+3+4=8 subunits). The DNA then wraps 1.75 turns around this octamer, forming a solenoid. Histone H1 acts as a linker between the octamer wraps. This packaging looks like a string of beads under the electron microscope; the beads being the octamer with the DNA wrapped around and the linker in between being the H1 bound to DNA. This packing is known as nucleosomes. The major force in the association between histones and DNA is electrostatic, although some hydrogen bonds also form. Most of the hydrogen bonds form between the histones and the O of phosphate. A few form with the bases but in a non-base sequence manner. Histones are a great example of a non-base sequence specific interaction with DNA. To overcome these interactions and dissociate the histones from the DNA we subject the chromatin to high salt solutions. The high ionic strength reduces the ionic interactions and frees the components. This was used in your lab last year to isolate DNA (1 M perchlorate). At some stages in the cell cycle, interphase (a collective term referring to G1, S and G2) the chromosomes are dispersed throughout the whole nucleus. The chromosomes look more like a plate of spaghetti then. At M phase, however they disentangle themselves and line up in a compact form ready for cell division. This process is called condensation. If I have time in a later lecture we will review mitosis in the light of the cell cycle and replication. The higher order packaging is more speculative. Show slide from G&G The roles of histones Packing: The tight packaging around the histones can only be achieved because the histones shield the negative phosphates from each other. Otherwise the DNA would repel itself and could not bend. The tight packing can make the DNA more inaccessible to transcription. Transcription factors which need to gain access via the major groove normally so they can read and interact with a particular base sequence often do this better in histone-free DNA. The interaction between the DNA and the histones is dynamic and somewhat transient. Like most non-covalent interactions there is a continual release and rebinding. These fluctuations do allow some protein binding. PHAR2811 Dale’s lecture3 page 6 Histone remodeling. Nucleosome remodeling complexes, large protein complexes that allow movement between the histones and the DNA, influences the accessibility of the DNA to transcription. Sometimes nucleosomes are positioned in certain sites. This can have the effect of giving greater access or restricting access. The N-terminal of the core histones are not part of the tight DNA packing assembly and can be accessed even when the DNA is tightly wound around the octamer. Protease digestion of the nucleosome will not touch the histones protected by DNA but the tails are digested. These N-terminal tails can be modified by methylation, phosphorylation or acetylation of lysines and serines. These modifications are important for chromatin remodelling. Acetylation of lysines neutralises the positive charge on the side chain. Phosphorylation gives a negative charge. Both have the effect of weakening the ionic attraction and loosening the packaging. The N-terminal tails are also necessary for higher order packing formations and these may be prevented with these modifications. These modifications are effected by enzymes. Histone acetylase transferases (HATs) and histone deacetylases (HDAs) add and remove acetyl groups from the lysines of histone tails. Likewise there are methyl transferases also. The histone modifying enzymes work together with the histone remodelers to change the accessibility of the DNA to transcription. This is often the first step in switching on the transcription of a group of genes. Techniques are now being developed which can measure the DNA access. OH O C CH H2 C H2 C H2 C H2 C +NH3 NH 2 OH O C CH O H2 C H2 C H2 C H2 C H N C CH 3 NH 2 Acetyl groups are transferred to the amino side chain of lysine. What effect does this modification have on DNA packing? Histone remodeling is often the first event to occur when a set of genes are switched on.