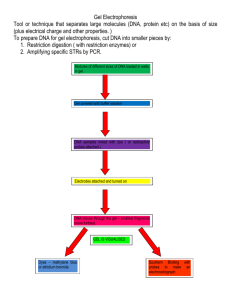
BIO 310 lab kurs
advertisement

Compendium autumn 2000 BI 315 lab. course Methods in population genetics Department of Botany & Trondhjem Biological Station (Inst. of Natural History, VM, NTNU) J. Mork (Ed.) co-workers: M. Heun, B. I. Honne, S. Karlsson, T. Ryan, S. Såstad, M.-A. Østensen 2 CONTENTS (T = theory, X = experiment) Page --------------------------------------------------------------------------Lecturers ............................................................ 3 (T) Protein electrophoresis (J. Mork)................................ 4 (T) Genetic interpretation of banding patterns on gels (J. Mork)..... 9 (X) Isoelectric focusing of LDH in gadoids (J. Mork) ................ 13 (T) Analysis of genetic differentiation and structure (J. Mork)...... 14 (X) Starch gel electrophoresis of fish tissue enzymes (M-A. Østensen) 18 (T/X) Bruk av isozyner for å studere hybridsoner (diploid-tetraploid hybridsone hos orkidéer) (S. Såstad) ...... (T/X) RFLP markers (the cDNA RFLP SypI*) (T/X) DNA markers (mini/micro-satellites,PCR reaction) (T. Ryan) .... APPENDICES (S. Karlsson) .............. 23 28 32 .......................................................... 40 (T) Hints on software for statistical tests and genetics (J. Mork).... 41 (T) Measurements of similarities and distances (B.I. Honne) .......... 45 (T) Analysis of data from Avena sterilis RAPDs (B.I. Honne) .......... 47 (T) DNA analysis techniques (P. Galvin)............................... 56 (T) Plant DNA markers (M. Heun)....................................... 78 2 3 BI 315 POPULATION GENETICS METHODOLOGY COURSE AT TBS AUTUMN 2000 (WEEK 47 & 48) Prof. Mork and Prof. Fenster are responsible for the course. Personnel involved: Name Telephone Telefax E-mail Prof. Jarle Mork, TBS Prof. Charles Fenster, Bot.Inst., KB-Fak. Prof. Manfred Heun, NLH Ås Prof. Bjørn Ivar Honne, Planteforsk Dr. Tony Ryan, Max Planck, Leipzig Dr. Sigurd Såstad, Bot. Avd. VM Cand. Scient. Sten Karlsson, TBS Leading Eng. Mari-Ann Østensen, TBS 47 73 59 15 89 47 73 55 0337 47 64 94 76 91 47 74 82 62 11 49 341 9952 593 47 73 59 22 51 47 73 59 15 80 47 73 59 67 99 47 73 59 15 97 47 73 59 61 00 47 64 94 76 79 47 74 82 88 11 49 341 9952 555 47 73 59 22 49 47 73 59 15 97 47 73 59 15 97 Jarle.Mork@vm.ntnu.no Charles.fenster@chembio.ntnu.no manfred.heun@ikb.nlh.no Bjorn.Ivar.Honne@neplanteforsk.nlh.no Ryan@eva.mpg.de Sigurd.Sastad@vm.ntnu.no Stenka@stud.ntnu.no Mari-Ann.Ostensen@vm.ntnu.no Web address for course information: http://www.ntnu.no/~jmork/jmork/courses/315H00/AGEN00.html 3 4 Lecture PROTEIN ELECTROPHORESIS (J. Mork, TBS) Principle In an electric field (DC), charged particles like molecules in aquous solution migrate towards the electrode of opposite charge. Amphotheric molecules (e.g., proteins and peptides) may have a large number of charged groups, and their net charge will depend on the pK value (the dissociation constant) of their charged groups which depends on the pH of the aquous medium. Due to differences in charge, different molecules in a mixture will migrate with different velocities and thereby be separated in single fractions. In addition to pI (the isoelectric point) of a protein/peptide, its electrophoretic migration velocity is influenced by the type, concentration and pH of the buffer, by the temperature and field strength (the voltage between the electrodes), as well as of type and pore size of the stabilizing medium (paper, agar, starch etc). Allelic variation (substitution of amino acids) in proteins usually does not affect molecular size appreciably. However many such substitutions result in a change of net charge which alters the electrophoretic mobility and makes the different genotypes detectable by electrophoresis. Of special value for population genetics is that such ’biochemical’ variation is co-dominant and allows the scoring of both allels at a locus (i.e. no dominance or recessivity). Electrophoretic separations can take place in free solution (e.g. in capillars) or in stabilizing media such as silica plates, variuos paper types, or gels. The development of stabilizing media during the last 50 years has been from paper via agar, cellolose-acetat, agarose, starch and to synthetic polymers of acrylamid. At the same time there has been a development of new techniques from the ‘continuous’ separation based on charge, via separation based on molecule size, to disc electrophoresis, immuno-electrophoresis and isoelectric focusing. No other biochemical technique has shown such a rich diversification and played such a central role in modern biochemistry. By electrophoresis it is possible to obtain very efficient separations with relatively simple equipment. Application areas range from biological and biochemical research to protein chemistry, pharmacology, forensic medicin, veterinary science, food quality control, molecular biology and genetics. Samples may be as diverse as whole cells or particles, proteins, peptides, amino acids , organic acids and bases, nucleic acid, drugs, and pesticides - in short, all substances that can carry electric charges. In biological research it will probably become increasingly important to choose the most adequate separation technique for a specific purpose, and to be able to carry out the practical procedures involved in electrophoresis. An thorough guide to the techniques is Westermeier (1993). Basically, there are three different principles for electrophoretic separation: a) common zone electrophoresis b) isotachophoresis (ITP) c) Isoelectric focusing (IEF) Similarities and differences between these three is shown in the following figure (mr = relative mobility (to a standard), pK = the dissociation constant, T = trailing ion, L = leading ion, and pI = isoelectric point (i.e., the pH where the amphoteric compound has no net charge). 4 5 a) In electrophoresis we use a buffer system that is homogeneous over the entire separation area to ensure equal pH. This is valid also for disc electrophoresis, although there the buffer system is discontinuous in the start of the experiment in order to concentrate the substances in a very narrow start band (i.e., utilizing the isotachophoresis effect). b) In isotachophoresis (ITP) the separation takes place in a discontinuous buffer system. The ionized compound migrates trapped between a front ‘leading electrolute’ and a tail ‘trailing electrolyte’ which migrates with the same velocity. The various components of the sample distribute themselves according to their respective electrophoretic mobilities and form a ‘stack’ with the front bands closely behind the ‘leading ion’ and the tail bands just in front of the ‘trailing ion’. Isotachophoresis is mostly used in quantitative separations (and as a ‘stacking and concentration’ step in disc electrophoresis). c) In isoelectric focusing the separation takes place in a pH gradient created by several hundred different ampholytes with different isoelectric points and with buffer capacity at their isoelectric points. As anolyte and catholyte are used e.g. 1 M phosporic acid and 1 M sodium hydroxide. The function of these is to keep the gradient ‘in place’ between the electrodes. IEF is very sensitive to electro-osmosis (see below), and the supporting medium should thus be as electrically inert (usual media are polyacrylamide and specifically pure agarose). IEF is suitable for amphoteric substances in which the net charge depends on pH, e.g. proteins and peptides. The molecules migrate to the position in the pH gradient where their net charge is zero (i.e., their isoelectric point) and the mobility is zero. Should they diffuse away from this position, the buffer effect of the nearby ampholytes will induce a charge which will force them back in position between ampholytes with slightly lower and slightly higher pI. The higher the field strength (voltage drop) is, the more concentrated the bands will be, thereof the name ‘focusing’. IEF is mostly used for qualitative characterization of substances or mixtures of substances and purity control, but also for preparative purposes. The pH gradient gels can easily be made inhouse, but are also commersially available as ready-made gels with different gradients (e.g., 2-10, 3-9, 4-9, 4-6, 5-7, 5-8 etc). Ampholyte mixtures are marketed by many firms (e.g., Pharmacia’s «Pharmalytes» , Serva’ «Serva-Lytes», Bio-Rad’s «Biolytes» (the two latter are identical). Ready-made gels cost much more than home-made (~600 kr vs ~80 kr per gel of size 24,5x12,5x0,1 cm). Both home-made and ready-made gels have fridge shelf lives of up to one year. The chemical composition (ampholyte type etc) as well as the linearity of the pH gradient vary considerably between brands. There is also some variation in prices. The buffer system in electrophoresis Common electrophoresis takes place in a buffer with accurate pH and constant ionic strength. The ionic strength should be as low as practically possible in order to achieve high field strength (voltage drop) and thereby rapid migration/separation, but not so low that the proteins are not pH-buffered by the medium, or the buffer capacity is used up before the separation is completed. During electrophoresis, the buffer ions migrate through the gel in the same manner as the sample molecules; anions towards the anode and cations towards the cathode (in vertical 5 6 electrophoresis the buffer pH is set so that all molecules of interest migrates towards the same electrode; in practice from the upper to the lower part of the gel). The buffer ions are responsible for most of the conductivity in the supporting medium. The lower the conductivity (i.e. the ionic strength) , the less Joule heat is produced, and the higher field strength can be employed without overloading the cooling capacity of the system. The cooling is usually achieved by a cooling plate connected to a circulating thermostat. The buffer capacity must be large enough to ensure constant pH during the entire experiment. The capacity is regulated by the amount of buffer and/or its concentration. The problem of electro-osmosis If the gel support (glass plate, plastic film etc) or the separating medium itself have electrical charges, a phenomenon called electro-osmosis occurs. If the charges are negative, water in the buffer will migrate towards the cathode and carry sample molecules with them (socalled cathodic drfit). This can either counteract or increase the ordinary electrophoretic mobility. The high voltages employed makes IEF particularly sensitive for electro-osmosis, not least by the use of media which are not totally electrically inert (like some brands of «IEFgrade» agaroses). However, the pheomenon is also common in ordinary electrophoresis in agar, paper and cellulose-acetat. Gels made from starch and polyacrylamide have no electro-osmosis. Joule heat and the cooling system After separation, the bands should be as distinct and concentrated as possible. Prolonged analysis time will usually lead to unwanted band diffusion. One way to shorten the analysis time (i.e., diffusion time) is to increase the field strength (i.e the applied voltage) over the gel. However, this will also increase the Joule heat produced (cf figure below), and this may lead to problems like protein denaturation, gel artifacts (melting agarose), «smearing» of bands, etc. It is therefore very important to design the experiment so that the separation takes place as quickly as possible, but with no more Joule heat produced than can be carried away by the cooling system. Very basic knowledge about the aparatus and to the relations between voltage, current, conductivity, affect and Joule heat makes it relatively easy to avoid problems of this kind. It is the total applied effect (measured in Watts) that determines the heat production in the system that must be matched by the cooling plate capacity. The current is necessarily the same at any point between the electrodes. In places where the resistence is large (conductivity low), either because the cross-section of the circuit «lead» is small or because there are few ions present, the system will «use up» most of the voltage to «force» the current through. With constant current and high field strength these circuit parts will use more of the available wattage and therefore produce more Joule heat than other parts. Typically, this is in the gel, which often has both a smaller cross-section and a lower conductivity than the buffer chamber. Therefore, the cooling plate is placed under the gel. Cooling plates made of metal (NB! must be electrically insulated!) or ceramics are much more efficient than those of glass, and will allow higher effect and hence shorter analysis time. As a rule of thumb, a 1 mm thick gel on a metall or ceramic cooling plates can tolerate an applied wattage of 0.2 W/cm2 gel without substantial temperature increase (i.e., not more than 2-3 degrees centigrade higher in the gel than in the coolant). This Joule heat produced is directly dependent on the effect applied to the electrophoresis system. The effect obeys the following simple equiation: Effect (watt) = Voltage (volt) x current (ampere) 6 7 Tissue samples; properties and treatment of proteins An important criterion for the choise of electrophoretic method is the type of sample which is to be analysed. One line can be drawn between denaturing methods (e.g. SDS electrophoresis) and methods where the biological activity of the protein must be preserved. Another line is between amphoteric compounds (proteins, peptides) and non-amphoteric substances. Common to them all is that the sample should not contain particles, oil drops etc because these may block the pores of the medium. Protein extracts are usually prepared by homogenization in aquous solutions (aqua. dest. or buffer). Since e.g. enzyme loci may be differently manifested in different tissue types, it can often be useful and efficient to homogenize several tissue types together (e.g. muscle and liver) in the same vial in order to have more loci represented. Usually, a few seconds of forceful mincing of the tissue samples (1 ccm in double amount liquid) with a glass rod is sufficient tot break the cell walls and release the proteins in animal tissues (plant tissues may need more labour). It is usually desirable to centrifuge the homogenates (e.g. 10.000 G for 10 minutes) to avoid cell debris in the extracts which may block the pores of the medium. Some proteins are very tough and can stand rough treatment in the field as well as in the laboratotium, while others are extremely sensitive for factors like elevated temperatures, oxydation, low ionic strength, too high or too low pH (low pH is usually worse than high). The properties of different proteins must be learned by experience in each organism and each organ. However, there are a few general rules. For example, proteins (e.g. enzymes) which usually perform their function at relatively high temperatures will better tolerate high temperature and storage in the laboratory. Thus, mammalian proteins are usually more stable at room temperature than proteins from e.g. fish. In any case, the best results are usually obtained when using fresh (not frozen) samples. Bacterial degradation can be a serious problem. It is adviceable to strive for as sterile treatment as possible during all stages of sample preparation, to keep the samples chilled, and to avoid drying-out as well as to much sample dilution. In some cases, the use of a bacteriostat like Na-azid can be necessary to avoid bacterial growth. In addition, the pH of the extraction buffer should not be too far from the natural milieu of the protein since physiological conditions will usually increase its life-time. If samples are to be stored for prolonged periods (e.g. more than 1-2 weeks) this should take place at ultra-low temperatures (e.g., at -70 degrees C or lower) in a «biofreezer», on dry ice, or in liquid nitrogen, and packed in a way which avoids drying-out and exposure to air oxygen. One should be aware, however, that some proteins will not tolerate the freezing/thawing process. In such cases freeze-drying may be an alternative. 7 8 Detection of inherited variation in proteins Mutations are the main source of inherited protein variation. By point mutations the DNA polymerase have performed an erroneous reading which results in the incorporation of the «wrong» amino acid in the protein. Between one third and one fourth of the possible amino acid substitutions will lead to a difference in charge bewteen the original protein and the mutation, so that they can be detected by differences in electrophoretic mobility. Proetin electrophoresis is therefore a technically simple and suitable method for detecting inherited variation, although not all amino acid substitutions can be detected. Most proteins are colourless and will not be visible in the gel without specific histochemical colouring procedures. For general protein staining there are several more or less sensitive methods. Many of the stains were originally developed by the textile industry (e.g. the wideliy used Coomassie Brilliant Blue). In recent years more sensitive techniques (e.g., «silver staining») have been developed. Commercial kits are available for silver staining, but the technique is also thoroughly described and can easily be adopted from Westermeier (1993). Except for some procedures for the detection of e.g. lipo-proteins and gluco-proteins, general protein stains are unspecific. Enzyme stainings, on the other hand, can be made very specific by basing the staining procedures on reactions that only can take place in the presence of a specific enzyme. The principle is to incubate the gel in a solution (or covering the gel with an agar/agarose overlay) containing the enzymes’ substrate as well as the necessary co-factors (like NAD, NADP etc) for the reaction, plus reagents which result in the precipitation of a coloured product (e.g. formazan) at the site of enzyme activity. Documentation of results, preservation of gels The colour reaction is stopped when the banding patterns are scorable, usually by incubating the gel in fixing solution. Widely used fixing solutions are, e.g., 20% TCA, 10% picric acid, and 1:4:5 mixture of acetic acid/water/ethanol. By fixing the protein unfolds, gets trapped in the gel matrix, and looses its biological/enzymatic activity (note that formazan-bands from MTT are soluble in ethanol, so that when alcoholic fixatives are used, NBT rather than MTT should be used). In large pore gels, small molecules may not be adequately trapped by the fixing and may diffuse out of the gel. One solution to this can be to reduce the pore size quickly after separation by drying the gel. Gels of starch and cellulose-acetat can be frozen and will keep their integrity on thawing. A frozen agar or agarose, gel, however, will collapse on thawing. Both agarose and polyacrylamide gels may loosen from plastic support films upon thawing. Recommended preservation methods for the different types of gels are (note that photodocumentation or digitizing with a scanner is an option in all cases): Cellulose-acetat: Drying. Agar/agarose: Drying-in onto the polypropylene support film (drying can be speeded up with a hair-dryer). Starch: Freezing, or drying-in onto filter paper in a «gel-dryer». Polyacrylamide: drying in on the polypropylene support film, and covering with an extra plastic film. 8 9 Lecture: GENETIC INTERPREPATION OF BANDING PATTERNS ON GELS (J. Mork, TBS) There will usually be individual variation in the banding patterns after staining. The variation may be phenotypic or genotypic. The phenotypic variation can be caused by post-transcriptional changes to the protein like partial degradation, glucosilation, polymerization etc, and is usually of limited value for the purpose of studying genetic variation. For the variation in banding patterns to be decribed as genetic, certain assumptions must be fulfilled which are based on the Mendelian laws of inheritance, the Hardy-Weinberg theorem, plus combinatorics and knowledge on the quarternary structure of each protein (for protein substructure see e.g. Darnall & Klotz 1975). Ideally, the heritability of protein variants should be checked in offspring groups from controlled crossings of parents with known ‘genotype’. In lack of or in anticipation of such data, the observed ‘genotypic’ distribution in an adequately large number of individuals may be tested against Hardy-Weinberg expectations. For this purpose one should of course use samples which from other (e.g. biological) criteria appear to be representing one single, panmictic population. (See section on ”The Hardy-Weinberg theorem...” below). The test procedure applied for this purpose is the chi-square goodness-of-fit test, which is carried out as in the following hypothetical example: Suppose that by visual inspection of banding patterns among 100 diploid individuals, three different patterns are found; either one or the other of two dense bands with different positions on the gel, or both those bands but with only half the density in each band. The three types occur with the numbers 34, 15, and 51, respectively. We hypothesize that the bands are caused by a two-allele (A and B) polymorphism at one locus, and assign the genotypes AA, BB, and AB to these three banding patterns. The protein thus appears to be a monomer (see chapter ”Banding patterns...” below), with one gene product (gel band) in the homozygotes and two in the heterozygote. We want to test whether the observed distribution of our ‘genotypes’ is in accordance with this interpretation, and carry out the chi-square ”Goodness-of-fit” test: H0: The sample is taken from a population where AA, AB, og BB are distributed according to Hardy-Weinberg equilibrium proportions. H1: The sample proportions of AA, AB, og BB deviates too much from H-W equilibrium that H0 can be correct. AA AB BB N qA Oberved 34 52 14 100 .6 Expected (HW) 36 48 16 chi-square (34-36)2/36 (52-48)2/48 (14-16)2/16 Pooled chi-square = 0.11 + 0.33 + 0.25 = 0.69. Degrees of freedom (DF) = 3 -2 = 1 P (probability of worse fit) = 0.406 Conclusion: H0 is not rejected. qB .4 That the distribution of AA, AB, og BB is in accordance with the Hardy-Weinberg expectations can be taken as substantial support for a hypothesis that the variation is heritable and is caused by allelic variation at one locus. (Of course, the ultimate test would have to be based on controlled crossing of parents with known genotype). Banding patterns caused by different quarternary structures of the protein The example above concerned the simplest possible situation - a monomeric protein where the homozygote pattern is one-banded and the heterozygote is two-banded. In cases where the alleles code for sub-units of composite proteins (dimers, trimers, tetramers etc), more complex heterozygote patterns will be seen on the gel. 9 10 Dimeric proteins: Three combinations of sub-units X and Y are possible (XX, XY, and YY). The heterozygote will show one Xband, one intermediate XY-band, and one Y-band. The relative amounts (and staining intensity) of the three types will, according to simple combinatorics, be 1:2:1. Trimeric proteins: Four possible combinations: XXX, XXY, XYY, YYY with expected intensity 1:3:3:1. Tetrameric proteins: Five possible combinations: XXXX, XXXY, XXYY, XYYY, YYYY with expected intensities 1:4:6:4:1. Interlocus hybrid bands When several loci code for sub-units of composite proteins one will often (but not always) find molecules which are composed of sub-units from different loci. In the simplest case; two monomorphic loci for a dimeric protein, this may be manifested as one hybrid zone in the middle between the two homodimeric bands of the two loci. The banding pattern will be substantially more complex when looking at multiple loci coding for sub-units of tetrametic proteins. In general I, the theoretically expected number of bands will be (Harris & Hopkinson 1977): I = (L + h + n -1)! / n!(L + h -1)! Where L=number of loci, h=number of heterozygous loci per individual, and n=number of sub-units per protein. For example, a double heterozygote for LDH-2* og LDH-3* in cod will be expected to show: I = [(2+2+4-1)!/ (4!(2+2-1)!)] = 35 bands. For a triple heterozygote the number would be 126. Inter-specific hybrid patterns Species hybrids usually show the protein bands from both parent species. Since even closely related species rarely have the same alleles at a locus, electrophoresis is a very efficient method both for the identification of species and the detecting species hybrids. Particularly, this applies to the younger stages in species where species 10 11 characteristics develop at more advanced stages of development, and for species which in general are difficult to identify morphologically. The method has, e.g., been applied with success on eggs and adults of salmon/trout and various mosses and their hybrids. Patterns in lower and higher levels of ploidy In haploid species, only one allele is manifested and therefore only one band is seen at each locus. The existence of ‘heterozygous’ banding patterns in such species must therefore be due to inter-locus hybrid bands. Some species (e.g. salmon, several grass species etc) are natural popyloids and may have double, triple etc sets of genes at their loci. Polymorphisms in such species may show patterns and staining intensities which deviate from those shown in the figure above, mainly with respect to the symmetry in band intensities of the heterozygotes. The reason for this is that proteins synthesized at several loci may have the same electrophoretic mobility (lying ‘on top’ of each other in the gel). If, for example, an individual is heterozygous for a dimeric protein on a duplicated locus, one of the homodimers will be more intensively staining than the other, because the homodimers from the other (monomorphic) locus have the same electrophoretic mobility. Testing the zymograms with gel-scanners has shown good correlation between observed and expected staining intensity in cases where the individuals were scored as heterozygotes on a duplicated locus. Thus in practice the genotype scoring needs not be a problem at higher levels of ploidy. The Hardy-Weinberg theorem, and tests for genetic equilibrium The so-called Hardy-Weinberg principle was formulated simultaneously by the English matematician G.H. Hardy and the German Phycisist W. Weiberg, and can be expressed like this: «Single locus genotype frequencies after one generation of random mating can be expressed by the binomial (if 2 alleles) or multinomial (if >2 alleles) function of the allele frequencies» Under certain assumptions, the allele- and genotypic proportions will be constant over generations and may serve as population characteristics. These assumptions are: 1. 2. 3. 4. 5. Panmixia (random mating) No mutations Very (infinitely) large population size No immigration No selection Even if no natural population fulfills all these assumptions completely, the effect of deviations from them is usually not considered large enough to make the test of Hardy-Weinberg proportions meaningless. Such a test is already shown above. Here follows a brief scetch of the procedure: First, the number of the different genotypes in a sample is counted: for example AA:51, AB:38, and BB:11 among N=100 diploid individuals.To calculate the expected numbers (under H-W equilibrium) of the three genotypes we first calculate the frequency of each of the alleles, and insert these frequencies into the binomial formula. We found 51 individuals with genotype AA (which means double dose A) and 38 heterozygotes AB which has single dose A. Altogether we have (51+38+11)*2 = 200 alleles in our sample, of which (51*2) + 38 = 140 are A-alleles, giving the frequency 140/200=0.7 for the A-allele. The frequency of the B-allele must then be 1-0.7 = 0.3. The binomial formula: (p + q)2 = p2 + 2pq + q2, will, when we insert p=0.7 and q=0.3, give the proportions 0.49, 0.42, and 0.09 as H-W expectations for the three genotypes AA, AB, and BB. To find the expected absolute number of each genotype, these proportions are multiplied by the sample size (N=100). The expected number of the three genotypes under Hardy-Weinberg equilibrium are thus: AA:49, AB: 42, and BB: 9, which are somewhat different from the observed numbers. Whether the deviation is too large to be coincidental can be tested by a chi-square goodness-of-fit test as shown in the table above. The principle for calculating chi-square is, for each genotype, to square the difference between observed and expected number, and to divide the result with the expected number. The numbers thus obtained are summed to yield the total chi-square which can be looked up in a table of critical values. In goodness-of-fit tests (but not in chi-square contingency tables), the degrees of freedom (abbreviated DF) needed when looking up in a chi-square table are calculated as the number of genotypes minus the number of alleles. In the present case this is (3-2)=1 DF. A chi-square table will tell us the probability that a deviation (represented by the chi-square) of a 11 12 certain size may be due to coincident, or if it is statistically significant and thus probably represents a real deviation from Hardy-Weinberg proportions. Nomenclature for loci and alleles While the name of the protein (enzyme) is spelled out in normal types or as an abbreviation (e.g., lactate dehydrogenase, LDH), the locus which codes for the protein is by convention written in italics and with and asterisc (*) after it. If more than one locus code for the same protein, the loci are numbered 1,2 etc starting with the most cathodic one (e.g. LDH-1*, LDH-2*, LDH-3*) if historic priority doesn’t tell otherwise for the locus under study. The alleles at a locus are named by their mobility relative to the most common allele in the total material (pooled samples from many locations), which is assigned the value 100. A band which migrates half the distance of this 100 band would be called 50. If the migration is in the opposite direction (i.e. towards the cathode), a negative sign (-) is added to the allele name. Thus a band which migrates half the distance of the 100 band but in the opposite direction would be called -50. The alleles behind the bands are written in italics . A heterozygote would thus be called LDH-3* 100/-50. In reports from protein electrophoresis, it has become a convention to present gel pictures and diagrams with the anode at the top. References for chapter «Protein electrophoresis» Darnall, D. W. & Klotz, I.M. 1975. Subunit constitution of proteins - A Table. Arch. Biochem. Biophys. 166: 651- 682. Harris, H. & Hopkinson, D.A. 1977. Handbook of enzyme electrophoresis in human genetics. Elsevier/Noth Holland Biomedical Press. Westermeier, R. 1993. Electrophoresis in practice. VCH Publishers Inc., NY. 277 pp. ISBN 1-56081-705-4. ooooooooooooooOOOOOOOOOOOOooooooooooooooooo 12 13 Lab. experiment: ISOELECTRIC FOCUSING IN POLYACRYLAMIDE GEL (IFPAG) AND HISTOCHEMICAL STAINING OF LDH ALLOZYMES IN TISSUE EXTRACTS FROM MARINE GADOIDS (J. Mork, TBS) Background: The heart form (LDH-B) of the tissues enzyme LDH (lactate dehydrogenase; E.C. 1.1.1.27) is polymorphic in Atlantic cod. Two common and several rare alleles have been demonstrated in cod along the Norwegian coast. This experiment uses cod LDH to demonstrate robust techniques for IFPAG, histochemical staining of enzymes, interpretation of gel patterns, genotyping, and and estimation of allele frequencies. IFPAG: The analytic method will be Isoelectric Focusing in Polyacrylamide Gels (IFPAG). A broad pH gradient gel (Serva-Lyte 4-9 technical grade) will be used, and the final ampholyte concentration will be 2%. The gel will have a total acrylamide concentration (T) of 5%, and the degree of crosslinking ( C ) will be 3%. I M of phosphoric and sodium hydroxide, respectively are used for the anode and cathode electrode wicks. Photopolymerization (Riboflavin-5-P) is used. Procedures for mounting gel cassettes and moulding gels are demonstrated. Instrumentation: Bio-Rad «Biophoresis» electrophoresis apparatus equipped for IFPAG. Power Supply is a LKB 2103, and the cooling circulator is a Desaga Frigostat thermostated at 4C. The analysis: Homogenization of tissues and extraction of proteins are demonstrated. The steps in the analysis are: 1 - Mounting of gel on the cooling plate of the apparatus (5 min) 2 - Prefocusing (5 min) 3 - Cathodic applic. of ~50 paper pieces (incl. standards) soaked in tissue extracts (10 min) 4 - Focusing for 10 min and then removal of sample paper pieces 5 - Completing the focusing during another 60-75 min Towards the end of the focusing the LDH staining solution is made ready (80 ml 0.5 M Tris-HCl pH 10.0, 1 gram Na-lactate, 10 mg each of NAD, NBT and PES). 6 - After completing the focusing, the electrode wicks are removed, and the gel is incubated in the staining solution (dark, 40 C) until the blue formazan bands formed at the sites of activity are strong enough to allow genotyping (5-15 min). 7 - The enzyme reaction is stopped by placing the gel in 20% TCA (10 min). 8 - Gels are then washed in generous amounts of acetic acid:ethanol:water (1:5:4) containing 10% glycerol (60 min). 9 - The gel is mounted (paper clips) on a glass plate and allowed to dry in until its surface is sticky (due to the glycerol). 10 - The gel is then covered by another plastic sheet which is rolled onto the sticky surface. 11 - The plastic covered gel can be filed as a permanent record of the experiment. Literature describing the methods: Mork, J. & Haug, T: 1983. Genetic variation in halibut (Hippoglossus hippoglossus (L.) from Norwegian waters. Hereditas 98: 167-174. 13 14 Lecture: ANALYSIS OF GENETIC DIFFERENTIATION AND STRUCTURE (J. Mork, TBS) Evolution can be defined as any change in population gene frequency. Given sufficient time and degree of isolation, the evolutionary forces (mutation, genetic drift, gene flow and selection) will eventually result in different gene frequencies in different populations («time» may mean anything from a few, to hundreds of thousands of generations, depending on population size). There are many models for describing genetic differentiation. One of the best known and most frequently used is Sewall Wright’s «Mainland-Island model». It is based on a situation where a start population («Mainland») is split into many isolated subpopulations («Islands»), and describes the genetic differentiation between these over generations using formulae which includes e.g. population size, migration rates, and the number of generations since population splitting (and thereby reproductive isolation). Wright utilized a specific statistic - the Fst - as a measure of the degree of differentiation. The Fst value tells what proportion of the total genetic variability in the material is caused by genetic differences between populations (the rest is of course due to differences between individuals, i.e. within populations). For example, an Fst value of 0.10 would mean that 10% of the total variation can be attributed to differences between samples. It is worthwhile to mention that because Fst is a relative measure (between/within), its value is not expected to be affected by the type of genetic marker used (i.e., markers with different evolutionary rates, like e.g. isozymes and microsatellites, would be expected to yield similar Fst estimates when applied on the same material). Measures of absolute genetic differences, on the other hand (like Nei’s genetic distance D), are expected to give different results depending on the evolutionary rate (mutation rate) of the actual marker. For example, mini- and micro-satellites are expected to give larger D-values than isozymes, and this has been shown to be the case also in practice. WRIGHT’S FST , (A RELATIVE MEASURE OF DIFFERENTIATION) To understand the nature of Fst it is useful to have some knowledge of the Hardy-Weinberg theorem and the socalled Wahlund-effect. The latter tells that in a physical mixture (i.e., not an interbred group) of individuals from two or more populations with different gene frequencies, the mixture will show a deficit of heterozygotes compared to the expected (Hardy-Weinberg) proportion calculated from the joint gene frequency in the mixture. This effect is easy to understand if looking at the extreme situation where two populations with gene frequencies of 1.0 and 0.0, respectively, provide one half each of a mixed sample. The joint gene frequency in the mixed group will necessarily be 0.5, and from this we would expect a proportion of heterozygotes of (0.5*0.5*2=) 0.5 from the Hardy-Weinberg theorem, while the mixed group actually have no heterozygotes! Smaller differences in allele frequencies, or skewed proportions between the groups involved will of course create correspondingly smaller deficits of heterozygotes, but whenever observed, a significant deficit of heterozygotes is an indication that our sample consists of a mixture of two or more populations with different gene frequencies. Observed heterozygosity is simply the proportion of heterozygotes in a sample Expected heterozygosity (H) on a locus, however, is calculated from the observed allele frequencies: H = 1- xi2 where xi is the frequency of the ith allele. Mean expected H is written with a ‘bar’ above it and is the arithmetic average H at all the investigated loci (usually both monomorphic and polymorphic loci are included). Relevant software: Hetzyg.exe (J. Mork) The rationale behind Fst is that by the ‘start’ of differentiation (i,.e., when reproductive isolation occurs), all the (sub)populations have the same allele frequencies and genotype frequencies at all loci. Assume that the allele frequency at a 2-allel polymorphic locus is 0.5. Over generations, the allele frequencies and thereby the genotype frequencies will diverge between populations. The amount of divergence due to genetic drift will depend on population sizes and the number of generations. If, at one point in time, all the genotypes in all the populations are pooled in one large table, the proportion constituted by of heterozygotes will be a lesser number than that calculated (the H-W expectation) from the the ‘joint’ allele frequencies of that mixed group. The deficit will increase with time (generations), until eventually all the (sub)populations are fixed for one or the other allele, and 14 15 no heterozygotes are observed at all. (The expected proportion, which is based on joint allele frequencies, is however constant and hence the same as in the undivided start population). One way to look at this process is that the genetic variability, which at the start was entirely located within populations, is more and more transformed to be between populations. Fst is actually a measure of the fraction of the total genetic variation which can be attributed to differences between populations (the so-called ‘between’ component). The formula for Fst is: Fst = 1 - Hmean / Htotal where Hmean is the arithmetic mean of the heterozygosities in all the subpopulations, while Htotal is the expected heterozygosity based on the joint allele frequency in pooled subpopulations. It is evident from the formula that Fst equals 0 when the subpopulations are identical in allele frequencies, and 1 when they are fixed for different alleles. Wright’s Fst is basically a measure for single loci. Masatoshi Nei has suggested another statistic which utilizes information from several loci simultaneously. The statistic is analogous to Wright’s Fst , but is called Gst and calculated from allele frequencies rather than genotype frequencies (assuming Hardy-Weinberg equilibria in all subpopulations). Nei’s statistic is called Gst. Relevant software: GSA.exe (J. Mork) NEI’S I OG D (ABSOLUTE MEASURES OF DIFFERENTIATION) Masatoshi Nei has also suggested another measure, called D (genetic distance) which provides an estimate of the absolute genetic differences between populations. («.. mean number of amino acid substitutions per locus»). This statistic utilizes allele frequencies at multiple loci, and is calculated for each locus via the statistic I («genetic Identity»). The formula is: I = xiyi / SQR[(xi2)(yi2)] where xi og yi are frequencies of the i-th allele in population X og Y, respectively (SQR means square root). Furthermore, D = - ln(I). It is common to calculate the arithmetic mean D when dealing with more than one locus. Relevant software: DG25.exe, DG50.exe, DG100.exe (J. Mork), BIOSYS (D. Swofford) CLUSTER ANALYSIS AND DENDROGRAM CONSTRUCTION In studies of intraspecific genetic structure it is recommendable to have information on allele frequencies at many polymorphic loci. An efficient way of illustrating the calculated similarities and differences between groups is to perform cluster analysis. The method outlined below is the UPGMA (Unweighted Paired Group Method of Arithmetic Average), which is one way to present complex matrix data graphically. There are many others. First, the mean I or D between all pairwise combinations are calculated as explained above. The result can, e.g., be arranged in a matrix with the OTUs (Operational Taxonomic Units) along both axes. The two OTUs with the smallest D (or largest I) between them are then fused into one OTU, and the I or D value (the mean of the values of the two original OTUs) for this new OTU towards all the others is recalculated in a new matrix. Then again the two OTUs with the smallest distance are fused, followed by a new re-calculation. This procedure is repeated in a cyclical way until all the OTUs are parts of the same cluster. The dendrogram which can be constructed from this gives a graphical presentation of the similarities between OTUs in the total material. Example (UPGMA cluster analysis of Nei’s genetic distances, and dendrogram construction): Consider samples from 3 populations (OTUs). In each sample, genotypes at 3 loci (called HbI*, LDH-3* and IDHP-1*) with 2 alleles at each are scored by electrophoresis, giving the following values (for sake of simplicity, 15 16 the alleles are called S and F, and the genotypes thus SS, SF, and FF at all loci. qF and qS are the calculated allele frequencies of F and S): Population 1: Locus HbI* LDH-3* IDHP-1* genotype SS 25 81 36 genotype SF 50 18 48 genotype FF 25 1 16 N 100 100 100 qF 0.5 0.1 0.6 qS 0.5 0.9 0.4 Population 2: Locus HbI* LDH-3* IDHP-1* genotype SS 81 25 25 genotype SF 18 50 50 genotype FF 1 25 25 N 100 100 100 qF 0.9 0.5 0.5 qS 0.1 0.5 0.5 Population 3: Locus HbI* LDH-3* IDHP-1* genotype SS 64 36 49 genotype SF 32 48 42 genotype FF 4 16 9 N 100 100 100 qF 0.8 0.6 0.7 qS 0.2 0.4 0.3 Calculation of genetic distances: Formulae: I = xiyi / SQR[ (xi2)(yi2)], and D = - ln(I) Calculation of I-values and D-values from observed allele frequencies: Population 1 versus population 2: HbI*: I = (0.5*0.9) / SQR[(0.25+0.81)*(0.25+0.01)] = 0.7810 LDH-3*: I = (0.9+0.5) / SQR[(0.81+0.25)*(0.01+0.25)] = 0.7810 IDHP-1*: I = (0.6+0.5)*(0.4+0.5) / SQR [(0.36+0.16)*(0.25+0.25)] = 0.9803 Mean I = (0.7810+0.7810+0.9803) / 3 = 0.8474 Mean D = -ln(0.8474) = 0.1656 Population 1 versus population 3: HbI*: I = 0.8575 LDH-3*: I = 0.8274 IDHP-1*: I = 0.9820 Mean I = 0.8890 Mean D = 0.1180 Population 2 versus population 3: HbI*: I = 0.9906 LDH-3*: I = 0.9803 IDGP-1*: I = 0.9285 Mean I = 0.9665 Mean D = 0.034 Presenting the results of calculations in the first cycle in matrix form: 16 17 Matrix 1 Population 1 Population 2 Population 3 Population 1 -0.1656 0.1180 Standard Genetic Distances (Nei 1972) Population 2 Population 3 -0.034 -- The smallest value of pairwise genetic distance in this matrix is between populations 2 and 3. Therefore, these two populations are combined into one (and will be connected by the lowest level bifurcation in the dendrogram). The genetic distance between this ‘combined’ population and population 1 is then calculated as the arithmetic mean of the two distances that population 2 and population 3 originally had towards population 1, i.e. mean D=(0.1656+0.1160)/2 = 0.1408, and a new matrix can be filled in: Matrix 2 Population 1 Population (2+3) Standard Genetic Distances (Nei 1972) Population 1 Population (2 + 3) -0.1408 -- This procedure of joining the nodes with the smallest D-value in each cycle and then recalculating the matrix proceeds until all populations have been joined. In the current example with three population there will be two nodes (population 1 and the combined population 2/3) in the dendrogram which can be drawn on basis of the values in matrices 1 and 2: Among relevant software for cluster analysis and dendrogram construction are e.g.: DG25.exe, DG50.exe, DG100.exe (J. Mork), BIOSYS (D. Swofford), GNKDST (M. Nei) oooooooooooooOOOOOOOOOooooooooooooo 17 18 Lab. experiment: STARCH GEL ELECTROPHORESIS OF FISH TISSUE ENZYMES (J. Stien, J. K. B. Forthun & M-A. Østensen, TBS) (Figures 1 and 2 should not be reproduced without permission from the authors) Preparing biological material Tissues to be used in electrophoresis are preferably cut out and extracted as soon as possible after death of the animal, although storage in a frozen condition may give satisfactory results as well if the temperature is sufficiently low. Storage Use e.g. sealed plastic bags (avoid air pockets), adequately marked with species name, locality, date, total number of individuals, individual numbers, tissue types, etc.. Tissues and enzymes may vary dramatically in their storing capacities. Fatty tissues (and their enzymes) like liver are generally less suited for prolonged storage. The following storage times apply to liver tissues of codfishes (approximate values): Roomtemperature Refrigerator (0 til 4 °C) Freezer (ca. 18 °C) Biofreezer (-65 til -85 °C) a few hours < a week a few months many years Extraction When extracts of enzymes are to be stored refrigerated for more than one day, bacterial and mucoid growth inhibitors may preferably be added to the extraction liquid. If storage is not necessary, extraction can be made in distilled water. Equal amounts (volume) of tissue and solution are suitable for most practical work on fish. Homogenization Repeated freezing and thawing breaks the cell walls, and releases cytosol to the extraction liquid. Manual shaking increases mixing efficiency. Cell walls may also be broken by ultrasound treatment. Such treatment generates heat which can damage the enzymes, and should be performed with efficient cooling. Efficient homogenization is obtained by manually crushing the cell walls, e.g. with a glass rod in an Eppendorf tube. Best effect is achieved with partly frozen tissue (0 °C). If many samples are to be treated, cooling in ice bath may be neccesary. Centrifugation At TBS the Eppendorf tubes are centrifuged (here in a Sorvall Instruments RC5C, Rotor code 12, 10 000 rpm (~10 000 g) for 10 minutes at 2-4 °C). An ordinary table top centrifuge with > 2000 rpm and somewhat longer runs may serve well if the temperature is kept low. Preparering of medium / the starch gel Use hydrolyzed potato starch of analytical quality. The concentration of starch in the buffer solution depends on the batch from the producer. At TBS starch from Sigma Chemicals is used. This gives adequate gels at 10-11% (w/v) concentration. 18 19 Boil with constant agitation over gas-flame in e.g. an Erlen-Meyer flask (double the volume of the gel). Too little agitation may result in burned starch at the bottom of the flask.. The air content in the solution is removed by vacuum suction before the gel is poured. Due to the danger of implosion, only completely intact flasks must be used for this! When only big gas bubbles are formed by suction, the gel is ready for pouring. Pour the the solution directly onto the (pre-heated to approx. 50C for this purpose) thermostated plate. Bubbles induced during transfer should be removed e.g. with a pipette (they can make trouble when the power is applied). Set the temperature of the thermostated plate to approx. 4°C to let the gel solidify. If not used immediately after cooling, the gel should be covered with a plastic wrapping to avoid evaporation and drying. When covered and cool, the gel may be stored over night. Before use, any condensation on the gel surface should be wiped off. Application on the gel One or more slots are cut in the gel, depending on the width of the gel and on what type of buffer system is used. In continous systems (i.e. Clayton & Tretiak 1972) two or even three slots can be used, while discontinous systems (i.e. Ridgway et al. 1970) allow only one slot. Allow 2 cm of the gel on the anodal and cathodal side for electrode contact, and allow sufficient space for fast migrating enzymes in the anodal part. Absorb the protein extracts in pieces of filter paper and load them side by side into the slot cut in the gel. In routine analyses, the paper pieces may be as narrow as 1 mm. Allow sufficient space between pieces to avoid contact between them. Subsequent scoring of the indivudual isozyme genotypes is eased by applying e.g. groups of ten individuals, separated by a paper piece with a marker dye. Figure 1. The figure shows how to prepare and set up for SGE. The gel is resting on a cooling plate (2-3 °C) and connected to a power supply using two electrodes. The electrodes are connected to the gel via two buffer vessels. (+) = anode, (-) = cathode. The figure shows a gel with three lines of slots. 19 20 Electrophoresis If cooling is only from the bottom of the gel, a plastic wrapping should cover the surface of the gel during the run to avoid evaporation and drying. The application pieces should be removed after 10-15 minutes. The applied power/voltage is reduced during sample application.The total duration of the run depends on type of buffer system, the individual enzymes and pH in the gel. Suitable time for good separation are learned through experience. Gel slicing Cut the gel into slices of suitable size for staining. Many types of apparatus has been developed for this. At TBS a simple gear made of a dental string, glass plates and weights are used (Figure 2). The thickness of the slices depends on how many enzymes are to be stained for, and on the shear strength of the gel. Figure 2. “Gel-slicer”. Prior to specific histochemical staining, the gel is cut into 1 mm thick slices using a device such as that indicated by the drawing. Histochemical staining Staining occur normally at the highest rate between 30-35 °C. Because of different transcription rates in cells, different enzymes exhibit large variation in staining intensity. Substrate and staining solution are mixed while the gel is running. Light sensitive reactants (i.e. Nitro blue tetrazolium salt (NBT) and Phenazine ethosulphate (PES)) is however added as late as possible to reduce nonspecific staining caused by ambient light. 20 21 LDH: Tris-HCl, 0,2 M, pH=9,0 DL-Na-Lactate NAD NBT PES 50 ml 700 mg 5 mg 10 mg 5 mg (0,5 ml) (1,0 ml) (0,5 ml) PGM: Tris-HCl, 0,4 M, pH=9,0 12,5 ml a-D-Glucose-1-phosphate 150 mg G-6-PDH 40 u MgCl2 20 mg NADP 5 mg NBT 10 mg PES 5 mg ----------------------------------------------------------Agar 375 mg dest. vann 12,5 ml PGI: Tris-HCl, 0,4 M, pH=9,0 12,5 ml a-D-Fructose-6-phosphate 30 mg G-6-PDH 30 u MgCl2 20 mg NADP 5 mg NBT 10 mg PES 5 mg ----------------------------------------------------------Agar 375 mg dest. vann 12,5 ml (2,0 ml) (0,5 ml) (1,0 ml) (0,5 ml) (2,0 ml) (0,5 ml) (1,0 ml) (0,5 ml) Agar/agarose overlay To reduce diffusion of intermediate products in the gel during staining, the staining reagents can be mixed in a liquid agar solution which solidifies after pouring onto the gel. The most useful agaroses are those that with a solidifying temperature slightly above the incubation temperature (40 °C in a heated locker or 30 °C in room tempreature). Due to the smaller volume, a higher concentration of the staining reagents can then be used with no increase in cost. Gel pattern recording Read the gel slices while the bands ar clear and distinct, and before fixation of the bands. To read weak bands, some degree of overstaing is often necessary. Make sure that all sufficiently clear bands are read before overstaing the gel. Data for individual genotypes are written on suitable forms. On these forms other data of the individuals are also included, like species, length, weight, age, sex, gonad maturation stage, etc. Of course, sample data like locality, date, depth etc should follow the sample. 21 22 Fixation and preservation of gels The gel structure hardens and the staining bands are fixed in a solution containing ethanol, water and acetic acid (5:4:1). DO NOT TOUCH THE GEL WITHOUT GLOVES AFTER STAINING! It will allways contain traces of the staining solution. Storing Freezing. Wrap the gel into clear plastic, to prevent air contact. Add a note with a number or short description to each slice to connect the slices to the forms for station- and individual data. Store the slices in an ordinary freezer (-18 °C). Drying. After fixation the slices can be placed on filter paper sheets and put onto a gel dryer. Be careful not to destroy the slices with too high temperature. Stop the drying process before the paper wrinkles. Write the ID of the slice on the paper. Photography. Use ordinary equipment for repro photography. Uneven heat removal in the gel might have influenced the migrating rate in different sections. Light through the gel can therefore give a more diffuse impression than light from above. Remember to photograph the ID together with the slice. Cleaning of equipment Some of the chemicals used are mutagenes/poisonous. RINS ALL GLASS FROM THE STAINING PROCEEDURE WITH COLD WATER BEFORE WASHING! This is to avoid breathing of toxic damps. OoooooooooooooOOOOOOOOOOOOOoooooooooooooo 22 23 Lab eksperiment BRUK AV ISOZYMER FOR Å STUDERE HYBRIDSONER diploid-tetraploid hybridsone hos orkideer Sigurd Såstad Bot. Avd., Institutt for Naturhistorie, Vitenskapsmuseet, NTNU Interessen for hybridsoner har vært økende de senere år fordi man antar at krysninger mellom genetisk divergente individer har hatt avgjørende betydning for evolusjon i en rekke plante og dyregrupper (Arnold 1997). Hybridisering og introgresjon kan føre til økt genetisk diversitet innen arter, overføring av genetiske adapsjoner mellom arter, oppbygging eller nedbrytning av reproduktive barrierer mellom nært beslektede grupper og dannelse av nye økotyper eller arter (Barton & Hewitt 1989). Hybridsoner som består av cytotyper med forskjellige ploidnivå har spesiell interesse fordi de gir mulighet til å studere hvilke mekanismer som er involvert i tidlige stadier av polyploid artsdannelse, og hvordan reproduktive isolasjons-mekanismer påvirker etablering av polyploider i diploide populasjoner (Thompson & Lumaret 1992, Petit et al.1999). Fordi nydannede polyploider finnes i sterkt mindretall i diploide populasjoner, vil disse omtrent alltid forsvinne med mindre de har egenskaper som gjør dem i stand til å etableres i populasjonen, eller til å kolonisere nye områder (’minority cytotype exclusion principle’; Levin 1975). Cytotypen som er i mindretall vil oftere pollineres av den dominerende cytotypen og slik produsere ikke spiredyktig avkom (’triploid block’) eller evt. stort sett sterilt triploid avkom (Petit et al. 1999). Modeller for en neopolyploids etableringssuksess avhenger av faktorer som 2n-gametproduksjon hos diploider, relativ fitness hos polyploider kontra diploider, og grad av fertilitet av triploide individer (Felber 1991, Felber & Bever 1997). Dersom høyere konkurranseevne hos polyploiden kombineres med høyere fekunditet, selvbefruktning og/eller habitatsegregering mellom cytotypene, øker dette sannsynligheten for polyploid etablering (Rodriguez 1996). 23 24 Undersøkelsesarter: Dactylorhiza incarnata ssp. cruenta x Dactylorhiza lapponica Slekten Dactylorhiza inkluderer flere taxa som er endemiske for Nordvest Europa. Mange medlemmer av slekten har svært variabel morfologi, og da enkelte taxa ofte har en sympatrisk utbredelse, er hybrider relativt vanlige (Hedrén 1996, Malmgren 1992). Dactylorhiza er følgelig innad en taksonomisk dårlig definert / avgrenset gruppe. Noen populasjoner antas å bestå kun av hybridogene individer, mens andre regnes å ha sitt opphav i hybridogene stamformer. Både morfologiske og cytologiske data indikerer at evolusjonen i Dactylorhiza i høy grad er retikulat (Hedrén 1996). En hybridsone mellom den diploide Dactylorhiza incarnata ssp. cruenta (blodmarihand, 2n = 40), og den tetraploide D. lapponica (lappmarihand, 2n = 80) er utgangspunktet for dette prosjektet. Sikker hybridisering mellom disse artene er bare kjent fra Røros, Sør-Trøndelag (Lid & Lid 1994), i et gammelt kulturlandskapsområde (Sølendet naturreservat; Moen 1990). I dette området er imidlertid hybriden svært vanlig og til dels dominerende i områder som tradisjonelt har vært påvirket av slått. Disse områdene skjøttes i dag for å forhindre gjengroing etter at den tradisjonelle utmarksslåtten opphørte. Dactylorhiza incarnata ssp. cruenta finnes primært på mykmatter i rikmyrsområder, mens D. lapponica har sine primærområder ved kalkkilder og i ekstremrike fastmatter på myr. En antar at rydding av slått ved å forhindre gjengroing, har åpnet mange nye potensielle habitater for begge artene, noe som også har gitt etableringsmuligheter for hybriden mellom dem. D. lapponica er en av mange allotetraploide arter som er resultatet av en krysning mellom tidlige varianter av Dactylorhiza incarnata og Dactylorhiza fuchsii (skogmarihand, 2n=40; Hedrén 1996). Sekundære hybridsoner mellom allopolyploider og deres diploide foreldrearter er etter hva vi vet ikke tidligere rapportert (cf. Petit et al. 1999). Formål med øvingen: Gjøre en isoelektrisk fokusering av enzymene PGI (dimert enzym) og PGM (monomert enzym). Materialet er en tetraploid orkide (Dactylorhiza lapponica), og dennes potensielle foreldrearter (D. incarnata ssp. cruenta og D. fuchsii), samt av hybriden mellom lapponica og D. incarnata ssp. cruenta. Utfra resultatene skal vi: Vurdere elektroforetiske mønster hos tetraploiden, og forsøke å finne ut om dette er en allo eller autopolyploid. En allotetraploid vil oppvise disomisk nedarving med fiksert heterozygoti (dvs. homologe kromosomer nedarvet fra divergente linjer sjelden eller aldri vil pares i meiosen; Weeden & Wendel 1989; Figur 1). En autotetraploid vil ha tetrasomisk nedarving, med distinkt segregering i forventede ratioer (homo og heterozygoter). 24 25 Vurdere om diploidene er sannsynlige foreldrearter til tetraploiden Vurdere de elektroforetiske mønstrene hos hybridene, og finne ut om disse stemmer overens med hva vi skulle forvente i en første-generasjons triploid hybrid mellom diploiden og tetraploiden, evt. om den synes å utgjøre en tilbakekrysning med foreldreartene. 25 26 Fig. 1. Forventede nedarvingsmønstre hos allo- og auto-tetraploider. 26 27 Ekstraksjon og Elektroforese Ekstraksjon: for isozym-analyse av plantemateriale er ekstraksjon et kritiske trinn. Planter inneholder generelt en god del kjemiske forbindelser som kan virke nedbrytende når de kommer i kontakt med enzymene ved homogenisering av materialet. Oversikt over tilsetningsstoffer i homogeniseringsbufferen og deres antatte virkemåte: Skadelige vevs- reaksjon med protein reaksjonsforhold substanser Phenoler H-bindinger til O-atomer i surt/nøytralt proteinenes peptid bindinger Quinoner Reagerer med NH2 og SH grupper (sees som bruning av vev) Phenoloxidaser Tilsetningsstoff Virkemåte PVP Caffein H-bindinger til phenoler danner uløselige forbindelser under sure/nøytrale forhold. PVP kan inhibere glutamin synthetase Dannes fra phenoler v.h.a. phenol Natriumascorbat reduserende agenter (reduserer oxidaser ved basiske betingelser Natriummetabisulfit quinoner?). Kan inhibere enkelte (mercaptoetanol?) dehydrogenasesystemer basisk Natriumborat inhiberer O-diphenol oxidase Mercaptoetanol?) DIECA inhiberer phenol-oxidaser ved å virke på det kobberholdige aktive senter. Kan inhibere SOD DMSO Stabilisering av ekstrakt Ekstraksjonen foregår ved knusing av materiale med pistill på is. Ekstrakt suges opp på filtrerpapir og fryses ned til -80 grader (kan oppbevares i flere måneder). Elektoforese: Ved kjøring av testmateriale viser det seg at de aktuelle orkide-enzymene har et svært lav isoelektrisk punkt (pI). Ved IEF med pH gradient 4-9 forsvinner de aktuelle enzymene ut i anoden ved full fokusering. Dermed må kjøringen avbrytes etter fra 5-20 min for deretter å farge umiddelbart Fargemekanisme (PGI): (stoffer merket med * tilsettes fargeløsning) Fructose-6-fosfat* PGI Glukose-6-fosfat G6PD*, Mg++* NADP* 6PGA NADPH/PES*/NBT* Farging skjer ved bruk av agar overlay teknikken. Gelen plasseres ved 37 grader i mørket i 10-30 min, før fiksering. Litteratur: Arnold ML. 1997. Natural hybridization and evolution (Oxford Series in Ecology and Evolution). New York: Oxford University Press. Barton NH, Hewitt GM. 1989. Adaptation, speciation and hybrid zones. Nature 341: 497-503. Bretagnolle F, Thompson JD. 1995. Gametes with somatic chromosome number: mechanisms of their formation and role in the evolution of autopolyploid plants. New Phytologist 129: 1-22. Felber F. 1991. Establishment of a tetraploid cytotype in a diploid population: effect of relative fitness of the cytotypes. Journal of Evolutionary Biology 4: 195-207. Felber F, Bever JD. 1997. Effect of triploid fitness on the coexistence of diploids and tetraploids. Biological Journal of the Linnean Society 66: 95-106. Hedrén M. 1996. Genetic differentiation, polyploidization and hybridization in northern European 27 28 Dactylorhiza (Orchidaceae): evidence from allozyme markers. Plant Systematics and Evolution 201: 31-55. Levin DA. 1975. Minority cytotype exclusion in local plant populations. Taxon 24: 35-43. Lid J, Lid DT. 1994. Norsk flora. Oslo: Det norske Samlaget. Malmgren S. 1992. Hybridisering bland svenska orkideer - korsnings - och odlingsforsök. Svensk Botanisk Tidskrift 86: 337 - 346. Moen A. 1990. The plant cover of the boreal uplands of central Norway. I. Vegetation ecology of Sørlendet nature reserve; haymaking fens and birch woodlands. Gunneria 63: Petit C, Bretagnolle F, Felber F. 1999. Evolutionary consequences of diploid - polyploid hybrid zones in wild species. Trends in Ecology and Evolution 14: 306-311. Thompson JD, Lumaret R. 1992. The evolutionary dynamics of polyploid plants: origins, establishment and persistence. Trends in Ecology and Evolution 7: 302-307. Weeden, N.F. & Wendel, J.F. 1989 Visualization and interpretation of plant isozymes. In Soltis DE & Soltis PS (eds.). Isozymes in plant biology. Dioscorides, Portland. pp 46-63. oooooooooo00000000000000000oooooooooo 28 29 RFLP MARKERS The cDNA RFLP SypI Sten Karlsson TBS, Inst. for Naturhistorie, Vitenskapsmuseet, NTNU Synaptophysin (SypI) is a population genetic marker for cod, belonging to the class of markers called RFLP (Restriction Fragment Length Polymorphism). This locus is coding for an integral membrane protein of synaptic vesicles. Primers have been constructed for this gene. The forward primer (B) is situated in the third exon of the gene and the reverse primer 52 bp beyond the termination codon. In short: the polymorphism is due to presence or absence of restriction site. The uncut PCR product is 1051 bp in length. When this fragment is exposed for a six base pair restriction enzyme (Dra I) all the genotypes are cut into two 773 bp fragment and two 278 bp fragment. If there are no other fragment, the individual is homozygous AA. If there is a restriction site for the restriction enzyme Dra I the 773bp fragments will be cut into two 495bp fragment and two 278bp fragment. In this case the individual is homozygous BB. If there is a restriction site in only one of the homologous genes the individual is heterozygous AB. This individual will produce one 773bp fragment, one 495bp fragment and three 278 bp fragments. All these fragment are separated and visualized on an agarose gel (Figure below). 773 bp 278 bp 495 bp 29 30 The procedure for genotyping The procedure for genotyping can be divided into four steps. The first step include isolation of DNA, the second step PCR amplication of the gene, the third step cuting of the gene by the restriction enzyme DraI and the final step, electrophoretic separation on an agarose gel. DNA isolation In this lab course, DNA will be isolated from liver. * A small piece of liver (approx. 70mg) is cruched with a glass rod in a 2 ml plastic tube. * 700l of proteinase-K buffer is added and 4l of proteinas-K * The tubes are placed in heat-cupboard, adjusted to 50C and incubated over night. * To each tube add 400l of Tris saturated phenol and 600l of isoamylalcohol-chloroform (1:24) * Rotate tubes for 30 minutes, followed by centrifuging in 5000g for 15 minutes *Maximum 500l of the upper aquos phase is carefully sucked out with a pipette and transferred to new sterilized tubes. * The DNA is precipitated in 2 times the volume of ice cold 96% ethanol. * The DNA pellet is rinsed in 70% ethanol by carefull rotation for 30 minutes. * The ethanol is discarded and the DNA pellet is allowed to dry. * The DNA pellet is resuspended in 100l of TE-buffer or sterilized water. Proteinase-K buffer: 1ml 1M Trisbuffer, 0.1ml 0.5M EDTA, 0.5ml 10% SDS, 8.4ml dH2O Proteinase-K stocksolution: Add 5ml of 50% glycerol/ water mixture to 100mg Proteinas-K PCR Mastermix l dH2O PCR reaction buffer (1X) MgCl2 (3.75M) dNTP (0.25mM) Primer (SYN 7) reverse (0.072M) Primer (B) forward (0.0705M) *Taq 7.9 2 3 4 0.6 0.6 1 * Taq is diluted 1:5 30 31 Normaly Taq is excluded from the mastermix. Instead the Taq is added to each tube when everything else is added. Before the tubes are placed in the PCR apparateus 30 l of mineral oil is added to prevent the liquid to evaporate. The following program is run on the PCR: Start: 5 min. 94C denaturation 30 cycles: denaturation (94C 30 seconds), annealing (55C 30 seconds), extension (72C 30 seconds) Stop: 7 min. 72C Cutting with restriction enzyme (DraI) Mastermix l RE-buffer dH2O *DraI 2 4 2 * DraI is diluted 1:4 The mastermix is added to each tube and 10 l of the PCR product. Incubation for 90 minutes in 37C. The digestion stops by adding 1 l of 0.2M EDTA and 4l of loading dye. Electrophoretic separation The fragments are separated and visualized on an agarose gel. A 50ml agarose gel is prepared by adding 1g of agarose to 50ml of 1X TBE buffer and 1.5l of ethidium bromide. 10 l of the product, obtained from the restriction enzyme digestion is loaded into each well of the gel, which is submerged in 1X TBE buffer. The gel is run for approximately 20 minutes, with a maximum voltage of 120. The fragments are visualized on a UV-light board and photographed with a polaroid camera. 31 32 Literature Carvalho, G. R. & T. J. Pitcher (red.). 1995. Molecular genetics in fisheries. Chapman & Hall. London. 141 pages. Hillis, D. M., C. Moritz & B. K. Mable. Second edition. 1996. Molecular Systematics. Sinauer Associates, Inc. Publisher Sunderland, Massachusetts. 655 pages. Fevolden, S. E & G. H. Pogson. 1997. Genetic divergence of Atlantic cod at the synaptophysin (SypI) locus among Norwegian coastal and north-east Arctic populations of Atlantic cod. Journal of fish biology 51: 895-908. Pogson, G. H., K. A. Mesa & R. G. Boutilier. 1995. Genetic population structure and Geneflow in the Atlantic Cod Gadus morhua: A comparison of Allozyme and Nuclear RFLP loci. Genetics 139: 375385. ooooooooooooooooOOOOOOOOOOOOOOoooooooooooooooo 32 33 DNA MARKERS (MINI- AND MICROSATELLITES, PCR) Anthony Ryan Max Planck Institute for Evolutionary Anthropology, Inselstraße 22, 04103 Leipzig, Germany. The following discussion is a general outline of laboratory techniques. A more detailed description of these is given in the “Core Reading” listed in the references section. Tissue preservation Several methods exist for storing tissue samples prior to DNA extraction. If possible, it is better to freeze the tissue samples, so that both protein and nucleic acid components (DNA, RNA etc.) may be analysed. However, this can be impractical in situations where samples must be collected in the field or transported without freezing, for example by airmail. One alternative is to store and transport tissue samples, such as gill or muscle from fish, in several volumes of absolute alcohol (“several volumes” means that the volume of ethanol must be two to three times the volume of the tissue sample). Under these conditions, the degradation of the sample by bacteria or fungi is inhibited by alcohol. Alternatively, tissues may be transported frozen, for example in dry ice. However, the cost is often prohibitive. For the extraction of DNA from fish samples, gill tissue stored and transported in ethanol give high quality DNA extracts which are sufficient for most laboratory applications. DNA Extraction In order to isolate nucleic acids from tissue samples, it is first necessary to disrupt the cell membranes and remove the proteins which are present. Routine DNA extraction protocols usually begin by digesting the tissue samples for several hours using a protein-degrading enzyme, such as Proteinase K. After this stage, it is often desirable to degrade the RNA which is present in the samples. This is achieved using an enzyme called RNAse. Afterwards, the degraded protein samples must be separated from the nucleic acids. Here, two common protocols are used. In the first, called Phenol/Chloroform Extraction, the samples are extracted with phenol and chloroform. These solvents remove the protein fraction from the sample, and DNA can be precipitated from the resulting solution. Alternatively, the proteins can be precipitated from the solution by adding a concentrated salt solution, in a process called Salting-Out. After salting out or phenol-chloroform extracting the samples, the DNA must be concentrated to a considerably smaller volume in order to be useful in laboratory analyses. This is usually achieved by precipitation in either two volumes of Ethanol or one volume of Iso-propanol, and centrifugation to collect the resulting pellet, which is then re-suspended in sterile water or an appropriate storage buffer such as Tris-EDTA (TE). Both phenol-chloroform and salting out procedures give DNA extracts of sufficient quality for most laboratory requirements. However, although the phenol-chloroform procedure is longer and requires the use of corrosive solvents, it does yield a higher level of DNA purity. 33 34 DNA quality control The molecular weight of the extracted DNA can be determined by electrophoresing the sample on a 0.5% agarose gel. A high molecular weight DNA ladder should be included in order to determine the approximate molecular weight of the extracted DNA. Where possible, the molecular weight should be as high as possible, as some types of laboratory analyses require high molecular weight DNA. The concentration of the DNA in each individual sample is best determined by measuring the absorbance at 260nm. By measuring the absorbance at 280 nm, and calculating the ratio of the absorbances at 260/280 nm, it is possible to determine the degree of purity of the extraction. A good quality DNA extraction should have a ratio of Abs260/Abs280 = 1.8. Lower ratios may be indicative of protein contamination, but in practice Abs260/Abs280 > 1.6 is usually sufficient. Minisatellites and Microsatellites These types of molecular markers are composed of core sequences (also called mini- or microsatellite motifs) which are repeated tandemly. The differences between different alleles at any locus are due to the number of times the core sequence is repeated. For a microsatellite, the core sequence is 2 – 6 b.p. (base pairs) long. For example, the human microsatellite HumF13b contains the core sequence (TTTA)n repeated several times. The core sequence for a minisatellite, on the other hand, is usually much longer (20 – 30 b.p.), and is often not perfectly repeated. Initially, minisatellite loci were used in multi-locus profiles which could be used to determine individual specific DNA fingerprints from Southern blots. However, while this technique was applied for individual identification purposes, it is not possible to determine which fragments on a Southern blot belong to which locus, and so little about population structure (heterozygosity, random mating, etc) can be determined. This problem was overcome by designing Southern blot probes which contain the minisatellite motif plus some of the flanking sequence. Thus, a single locus minisatellite profile is obtained, and existing statistical methods can be used to gain information about the populations under study. The major difficulty with Southern blot techniques is that they require large amounts (>1 g) of high molecular weight (<20 kb) DNA. This problem is solved by using PCR based methods, for which 20 ng (0.02 g) DNA are often sufficient. The DNA used need not be of high molecular weight for PCR assays. In the PCR assay, primers which are specific for the region of DNA at either side of the mini- or microsatellite locus are used to obtain PCR products, the sizes of which can be determined by electrophoresis. The isolation and characterisation of new mini- and microsatellite DNA loci is time consuming. Several methods have been described for this (see “Core Reading”). Mitochondrial DNA mtDNA, a maternally inherited closed circular molecule, was among the earliest DNA markers used in the study of wild populations. Initially, purified mtDNA was subjected to digestion by restriction enzymes, and the resulting restriction fragments were converted to restriction maps after 34 35 electrophoresis (RFLP). With the advent of PCR, it became possible to amplify mitochondrial segments from total cellular DNA, and subject these PCR products to restriction digestion or to direct sequencing. Several new approaches, such as mismatch distribution analysis, have allowed researchers to gain information on population history. Core reading Avise, J.C. (1994) Molecular markers, Natural History and Evolution. Chapman and Hall, New York. (Chapter 3, Molecular Tools, and Chapter 4, Interpretive tools.) O’ Connell, M. and Wright, J.M. (1997) Microsatellite DNA in fishes. Reviews in fish biology and fisheries, 7: 331 – 367. Additional references Avise, J.C. (1994) Molecular markers, Natural History and Evolution. Chapman and Hall, New York. (Chapter 9, Conservation Genetics). Allendorf F.W. and Seeb, L.W. (2000) Concordance of genetic divergence among sockeye salmon populations at allozyme, nuclear DNA and mitochondrial DNA markers. Evolution 54: 640 – 651. Carvalho G.R. and Pitcher A.J. Eds. (1995) Molecular genetics in fisheries. Chapman and Hall, London. De Woody, J.A. and Avise, J.C. (2000) Microsatellite variation in marine, freshwater and anadromous fishes compared with other animals. Journal of Fish Biology 56: 461 – 473. Hewitt, G. (2000) The genetic legacy of the Quaternary Ice Ages. Nature 405: 907 – 913. Keller, L. and Ross, K.G. (1998) Selfish genes: a green beard in the red fire ant. Nature 394: 573 – 575. Poinar, H.N. (1999) DNA from fossils: the past and the future. Acta Pædiatr Suppl 433: 133 - 140. Schneider P.M., Seo, Y. And Rittner, C. (1999) Forensic mtDNA hair analysis excludes a dog from having caused a traffic accident. International Journal of Legal Medicine 112: 315 – 316. Stoneking, M. (1994) Mitochondrial DNA and Human Evolution. Journal of Bioenergetics and Biomembranes 26: 251 - 259. 35 36 DNA Extraction Protocol I. Tissue digestion Proteinase K Buffer: 0.5M EDTA (ph 8.0) Sodium sarcosyl [10%] 1M Trisma Base.HCl Distilled deionized H2O 10ml 2.5ml 0.5ml up to 50ml 1. Label a 2ml sterile tube and add 0.8ml Proteinase K buffer. 2. Cut approximately 0.5cm3 of tissue (gill tissue in ethanol) and eliminate the ethanol by compressing the piece of tissue between two pieces of absorbent papers. Put the dry tissue into the labelled tube with the buffer. 3. Add 4l of proteinase K (20mg/ml) and incubate at 50C over night. 4. Check if the tissue is well dissolved. If not add 2l of proteinase K (20mg/ml) and incubate for 1h at 50C. 5. Add 10l of RNAse (10mg/ml) and incubate at 37C for 1-2h. II. Phenol-chloroform extraction 1. Add 0.4ml of phenol and 0.4 ml of chloroform/isoamyl alcohol (24:1). Mix gently and place on a rotating platform for 15min to 1 hour. 2. Centrifuge the sample for 15 min. at maximum speed. 3. Transfer approximately 0.6ml of aqueous phase into new labelled sterilised tube, taking care not to disturb the inter-phase. 4. Add 2-2.5 volumes of pure ethanol (-20C) and shake gently so that the DNA precipitates and falls to the bottom as a “stringy” pellet. 5. Replace the solution with 70% ethanol and place on a rotating platform over night to remove salts from the DNA preparations. 6. Remove the ethanol and allow the pellet to dry, as ethanol can interfere with the following analysis (i.e. PCR). 7. Re-suspend the DNA in 50l of TE buffer (10Mm Tris, 0.1Mm EDTA). Gently agitate the tube to aid re-suspension of the pellet. Allow the DNA to re-suspend at +4C for at least 24 hours before assessing its quality and concentration. Agarose minigel electrophoresis (check molecular weight of DNA) Check the quality of DNA running 1l of re-suspended DNA solution, 1l of 6x Loading Dye (stock solution 10X Loading Dye: 30% ficoll, 100mM EDTA 0.4% Bromophenol Blue, 0.4% Xylene Cyanol) and 4L sterile water on a 0.5% agarose gel in 0.5x TBE buffer containing 5l of ethidium bromide (10mg/ml) per 100ml. TBE buffer 5x Trisma Base 54g Boric Acid 0.5M EDTA (pH8.0) 27.5g 20ml 36 37 Apply a constant voltage of 40V for 20 minutes. The DNA should appear as a concentrated band close to the origin, indicating that only high molecular weight DNA is present. Spectrophotometric determination of DNA concentration The DNA concentration is calculated by its optical-density (O.D) at 260nm. Dilute 10l of resuspended DNA in 1ml of distilled water. Make sure the solution is well mixed, add it to a quartz cuvette and insert the cuvette into the spectrophotometer. An O.D. value of A260 = 1 corresponds to a DNA concentration of 50g/ml. The absorbance value at 260nm (which is the absorbance maximum of DNA) is then used in the following formula to estimate the concentration of DNA in the original tube: Concentration DNA= A260 x 50 x 100 = g/l 1000 which is equal to A260 x 5 = Concentration (g/l) POLYMERASE CHAIN REACTION PROTOCOL 1. Thaw the PCR reagents (which are kept frozen at -20C) and the DNA template. Stock solution PCR Ingredients Reaction buffer IV (Advanced BiotechnologiesTM) Magnesium Chloride (MgCl2) (Advanced BiotechnologiesTM) Deoxynucleotide Triphosphates (dNTPs)(Pharmacia) Forward Primer Reverse Primer Distilled deionized H2O 10X 25 mM 1.25 mM 20M 20M - 2. Prepare a solution of mastermix: Ingredients Buffer MgCl2 dNTP Primer F. Primer B. Distilled H2O TOTAL Volume X1 sample Final concentration 2l 1.6l 4.0l 1l 1l 9.2l ____ 19l 1X 2 mM 0.25 mM 1M 1M - 3. Store the Mastermix solution at +4C. 4. Add 1l of DNA (200g/l) to each tube. 5. Add 1unit of Taq Polymerase per sample (stock solution 5U/l, 1U=0.2l) to the mastermix. 37 38 6. Add the correct amount of mastermix to each tube (in this case 19l to bring the total volume to 20l). Be very careful not to cross contaminate the samples. Make sure that the DNA template and the mastermix are properly mixed. 7. Add 20l of mineral oil to each tube to prevent evaporation during the reaction. 8. Insert the tubes into the PCR thermo cycler and start the program with an initial denaturation step of 5 minutes at 95C followed by 30 cycles of 95C for 1 minute, 60C for one minute and 72C for 2 minutes. Finally a single cycle of 72C for 5 minutes ensures that all fragments are fully elongated. Analysis of PCR Products on Agarose Gel (minisatellites) Gel moulding 1. Make up 300 ml of 1% Agarose Gel. Dissolve the agarose in 1XTBE buffer by heating the solution. When the agarose is completely dissolved, to avoid distorting the casting tray, allow the solution to cool for 15-20 minutes at room temperature. 2. Before pouring the gel solution into a 20x30x0.6cm casting tray, add 5l of Ethidium Bromide, mix thoroughly and then pour it into the tray. 3. Make sure that there are no bubbles and insert the comb which forms the wells. Let the gel solidify for 1 hour. CAUTION: Ethidium bromide is mutagenic and should always be handled with care. Wear gloves. Electrophoresis 1. Remove the comb from the gel. Put the gel into the electrophoretic apparatus and cover it with 2L of 1 x TBE Buffer. 2. Add 2l of 6x Loading Dye to 10l of PCR products and apply the samples to the gel. Load 8l of molecular weight ladder to allow determination of allele sizes. 3. Apply a constant voltage of 70V for 14 hours 4. When the electrophoresis is complete, place the gel on a UV transluminator and photograph it. Analysis of PCR Products (microsatellite) on an Automatic DNA Sequencer (Li-Cor). For this system, it is necessary that one of the primers is labelled with a fluorescent dye, which is detected by a laser. The DNA is denatured by heating and kept denatured by the addition of formamide to the loading dye. Preparation of gel plates 1. Clean the two gel plates very carefully both with distilled water and ethanol to remove all dust particles which might cause air bubbles. 38 39 2. Insert a 0.25mm spacer on each side between the two plates and bind them with the clamps (leave the top clamp open to insert the top spacer). 3. Position the gel plates at a shallow angle, approximately 35 to help to pour the gel. 4. Make up the polyacrylamide gel solution in a 50ml beaker : Ultrapure Urea distilled water 5X TBE Buffer RapidGelTM-XL-40% Concentrate 10.5g 10ml 5ml 2.8ml Place parafilm over the mouth of the container and mix thoroughly until all urea has dissolved. 5. Add 25l TEMED and 175l of Ammonium Persulphate solution. Mix thoroughly. Draw the mixture (approx. 20ml of solution) into a pipette or a syringe. 6. Pour the solution between the two plates. Check that no bubbles are present, and if so remove them with a thin wire. 7. Apply the top spacer (to leave the space for the comb) and insert the casting plate, tighten the top clamps and leave the gel to polymerise for at least 1 hour (not more than 2 hours because it will dry out). Preparation of the gel for loading 1 When the gel has solidified, remove the casting plate and the top spacer. Remove the excess polyacrylamide with distilled water and a piece of paper. 2. Place the gel plates onto the DNA sequencer. Insert the buffer chamber and tighten the clamps. 3 Pour 500ml of 1XTBE Buffer into each buffer tray. Clear the loading edge of excess polyacrylamide by rinsing it with a Pasteur pipette. (to see the loading edge more easily, place a silver surface between the gel plates and the sequencer). 4. Put the lids on each buffer tray and connect the circuit from the gel plates to the automatic sequencer. Close the interlock. 5. Create a new file for the data on the hard drive of the automatic sequencer. Open the program (data collection). Create a new directory (file, new, create). Set the voltage to 1200V, the current to 50A and the power to 50W. Turn on the scanner. Click enter and check that the circuit is closed. 6. Pre-run the gel for at least 20 min to ensure that it is adequately heated and prepared before loading the samples. Preparation of the samples and gel loading 1. Pipette 1l of each PCR product into an individual 0.5ml sterile microcentrifuge tube. 2. Add 2l of Loading Dye - Formamide ACS Reagent solution (Loading Dye with Formamide) to each tube. Centrifuge at low speed for 4 seconds to make sure that the PCR products and the Formamide solutions mix together . 3 Heat each tube to 85C for 60 seconds on a PCR thermal cycler denature the PCR products. 4. Turn the machine off, open the interlock. Remove the top buffer trays lid. 39 40 5. Gently insert a 48- or 64- well shark-tooth comb (depending on the number of samples) between the two plates until the tips of the comb are approximately 1 millimetre into the gel. Tighten the top clamps. 6. Load 0.5l of PCR products-Formamide solution into each well of the loading comb. Load 0.5l fluorescently labelled size ladder to provide a consistent identification of the molecular weight of the alleles separated on the gel. 8. Replace the lid. Close the interlock. Set the auto gain (options, auto gain, auto). Focus the gel (scanner control, options, focalising, auto) (check that the curve is approx. like a normal distribution). Set auto gain again. Start electrophoresis. Electrophoresis and detection of PCR products of up to 400 b.p. should take approximately 2 – 3 hours. Stuttering. This is an artifact of PCR, where DNA fragments which are one or two repeat units shorter than the true allelic fragment are produced. This is thought to be due to replicative slippage during the PCR reaction. Stuttering is particularly pronounced in di-nucleotide microsatellites. a. b. A. Li-Cor gel showing amplification products of the di-nucleotide microsatellite locus BW7, which exhibits some stuttering. B. Li-Cor gel showing amplification products of the di-nucleotide microsatellite locus BW9, showing considerably more stuttering. Di-nucleotides, particularly when the core sequence is repeated very many times, are particularly prone to stuttering. oooooooooooooOOOOOOOOOOOOOoooooooooooooo 40 41 APPENDICES 41 42 HINTS ON SOFTWARE FOR STATISTICAL TESTS AND GENETIC VARIABILITY (J. Mork, TBS) NB! Be aware of the ADDITIVE properties of the chi-square statistic (chi-square and degrees of freedom from several tests may be pooled for a stronger, overall test). Also remember that in all types of chi-square tests, the expected value in a cell should not be less than 5, at least not in more than 20% of the cells of a test. If this assumption is not fullfilled, one remedy is to pool cells or alleles, or to use Monte Carlo based so-called exact tests (see «Zaykin-tests» below.) Two type of chi-square tests are very commonly used in population genetics. The first type is the «Goodness-offit» test, which is used to test if the observed genotypic proportions at a locus is in correspondence with the expected values assuming Hardy-Weinberg equilibrium (the expected values are thus calculated by means of the sample allele frequencies using the binomial (or multinomial) formula (p+q...) 2. The second type is the chi-square contingency table test (abbreviated RxC (Rows by Columns) test of homogeneity (homogeneity is more correct to say than heterogeneity because the null hypothesis is that the samples are drawn from the same population and thus expected to be homogeneous). Test for Goodness-of-fit to Hardy-Weinberg expectations [ Programmes: HWEQ2.EXE (Chi-square, two-allel loci) ] [ ZHIHW.EXE, exact test; multi-allel loci ] Chi-square test (HWEQ2.EXE): Assume a sample of 100 diploid individuals. Electrophoretic analysis of an enzyme has revealed 3 different patterns which is interpreted as genotypes formed by the combination of two alleles called 100 and 70 based on the electrophoretic mobilities of their products. Thus the genotypes are: 100/100, 100/70, and 70/70. The number of the different genotypes are tabulated, and the allele frequencies are calculated by summing their numbers in homo-and heterozygotes. The following table can be set up (the letter q mean «frequency of»): Observed Expected (H-W) chi-square 100/100 38 (36) Genotypes 100/70 44 (48) 70/70 18 (16) N q*100 q*70 100 0.60 0.40 Expected (H-W) values are calculated from the binomial formula (a+b)(a+b)=a 2 + 2ab + b2 Genotype 100/100 = (0.6)2 * 100 = 36. Genotype 100/70: = (2*0.6*0.4) * 100 = 48, etc chi-square = Sum of [ (Observed - Expected)2 / Expected] from each cell. In this case chi-square = [(38-36)2 / 36] + [(44-48)2 / 48] + [8(18-16)2 / 16] = 0.694. Degrees of freedom = [Number of different genotypes minus no. of different alleles ] = 3-2 = 1. The significance level P corresponding to the calculated chi-square and degrees of freedom is looked up in a chisquare table (e.g. in Sokal & Rohlf: Biometry), or checked with a suitable computer program. In this example, P=0.405. which is much higher than the P=0.05 rejection level which is commonly used in biology. We therefore do not reject the nullhypothesis, which is that the sample can have been drawn from a population in Hardy-Weinberg equilibrium for the locus under study. 42 43 P gives the probability that one may encounter, by chance alone, a deviation between estimated and observed genotypic proportion as large or larger than the one actually observed in the sample, if the sample came from a population in Hardy-Weinberg equilibrium. A chi-square value corresponding to P=0.05 is expected to be encountered in one out of 20 cases when sampling from one and the same H-W population. Wahlund-effect: A deviation from expected values is in form of a deficiency of heterozygotes relative to expectations is indicative of population mixing (i.e. the sample contains a physical mixture from two or more populations with different allele frequencies at the locus under study). The nature of this phenomenon is easily seen by joining two equally sized subsamples where one has only the 100/100 genotype and the other only the 70/70 genotype. Their joint allele frequency would be 0.5 and we would therefore expect half of the individuals to be heterozygotes whereas none will be present in the mixed sample. «Zaykin-test» for Hardy-Weinberg proprtions (programme ZHIHW.EXE): If the assumption of >5 as expected value in cells is not met, so-called exact test may be used (e.g. Zaykin & Pudovkin’s ZHIHW:EXE). Such tests are based on Monte Carlo simulations. For the software provided on BI 315, on-screen documentation will appear by typing the programme’s name. Data can be loaded from a text file or typed in during programme execution. Tests for inter-sample homogeneity (RxC contingency table tests) [ Programmes: CHIRXC.EXE (Chi-square) ] [ ZHRXC.EXE (exact test)] 1. CHIRXC.EXE (Chi-square): This test is used to test if the proportion of genotypes (or alleles ) is similar in different sub-groups of the materials. «Sub-groups» can be e.g. samples from different locations, sex groups, age groups etc. The chi-square value is, as always, calculated by squaring the difference between observed and expected value and dividing the result with the expected value. The result from this process in each cell is summed into a total chi-square. The number of degrees of freedom is generally calculated as (R-1)(C-1). The «expected» number in a cell is calculated based on the following line of reasoning: The null hypothesis is that we have a number of samples taken from the same population. If so, the best estimate we can have of the true distribution in the population is given by the largest sample we have, and that is the sum of all the samples. We therefore use the proportions of «types» in the «Total» as a template for calculating the expected values for each «Location» in the table below. Thereafter, we test if the difference between observed and expected proportions is too large to be caused by chance alone (e.g. at the 5% significance level). RxC test of genotypic proportions: Location 1 Location 2 Total 100/100 38 (24) 34 (48) 72 Genotypes 100/70 44 (45.3) 92 (90.7) 136 70/70 18 (30.6) 74 (61.4) 92 N 100 200 300 Example: expected value in cell «100/100 for Location 1»: (72/300*100) = 24 Chi-square = 20.157, DF = (2-1)(3-1) = 2, P = 0.00004, i.e. we reject the null hypothesis. The two samples are so different in genotypic proportions that it is very unlikely that they are drawn from the same population. Usually, we can make a more powerful test by converting the genotypic proportions to allelic proportions (counting two alleles of the same kind in homozygotes and one allele of each type in the heterozygote). The higher power is because the degrees of freedom is lower for alleles than for genotypes. The genotype proportions in the table above will give the following allelic proportions (table below): RxC test of allelic proportions (allele counts from the genotypic numbers in the table above): Allele 43 44 100 70 Location 1 120 (112) 80 (128) Location 2 160 (168) 240 (192) Total 280 320 Chi-square = 21.429, DF = (2-1)(2-1) = 1, P = 0.000004, i.e. the null hypothesis is rejected. N 200 400 600 2. Exact test «Zaykin-test» for RxC tables (programme ZHIRXC.EXE): If the assumption of >5 is not met in the cells of the RxC table, the Monte Carlo type exact test provided by the computer program ZHIRXC.EXE can remedy the problem. Instruction for the use of the program is given onscreen by typing in the programme name on the computer. Nomenclature conventions: Loci, genotypes and alleles are written in italics. Recommended abbreviations for enzymes and enzyme loci can be found in Shacklee et al. (1990). For example, the gene coding for the enzyme LDH-3 is called LDH-3*, the most common allele is called LDH-3*100, and the homozygote for this allele is called LDH-3*100/100. Reference: Shacklee, J.B., F.W. Allendorf, D.C. Morizot, and G.S. Whitt. 1990. Gene nomenclature for proteincoding loci in fish. Transactions of the American Fisheries Society 119: 2-15. Software for calculation of Nei’s I (genetic Identity) and D (genetic Distance) (J. Mork, TBS) The following allele frequencies at two loci in samples from two locations have been calculated from observed genotypic proportions in the samples: LDH-3* Location 1 Location 2 100 0.60 0.70 HbI* 70 0.40 0.30 100 0.90 1.00 80 0.10 0.00 Since we have only two samples here, we may use the program GSA.EXE for calculating Genetic Distance. (The genetic Identity can be found from the relation D = -ln(I)). When more than two samples, the temporary (*.TMP) files generated by the program DG25B.EXE can be used to find all pairwise genetic distances. Both these programs use an infile (DOS text file) with the following format (NB! the cursivated comment are not part of file): 2 2 0 2 (no. of samples - no. of polymorphic loci - no. of monomorphic loci - largest no. of alleles at any locus) 22 (no. of alleles at loci in succession from left to right in tablethe infile) «A1» 0.60 0.40 0.90 0.10 (Name of sample (alphanumeric and in brackets. Use codes A1-A9, B1-B9 etc)- allele frequencies) «B2» 0.70 0.30 1.00 0.00 We may call this file e.g. Bih97.txt, and call it during execution of GSA.EXE. The output from GSA.EXE will look like this: 44 45 Output includes the calculated Gst (= the average Fst for two loci), which tells that ca 1.8% (fraction 0.0182) of the total genetic variation in the material is due to genetic differences between samples.. Further,GSA.EXE provides values for Genetic Distance. Since we have only two samples here, the minimum and the maximum D-value will be the same (namely 0.0104). In an UPGMA dendrogram this will be the distance from D=0 to the point where the two legs of the bifurcation join on the Distance axix. It is not meaningful to do cluster-analysis and dendrogram drawing with only two samples, but if we do that anyhow (using Bih97.txt as infile for DG25B.EXE), the dendrogram will look like this: oooooooooOOOOOoooooooooo 45 46 MEASUREMENTS OF SIMILARITIES AND DISTANCES (Bjørn Ivar Honne, Planteforsk) Genetic distance according to EDWARDS (1971): Measurement of distance with allele frequencies p1 ,q1 and p2 ,q2 in two populations: Any locus with two alleles in any population may be pictured on a quarter-circle with radius 1, and coordinates sqroot of p and q, respectively. The angle between the two radii is and the distance 2d is measured along the secant connecting the two points (populations), where: d 1 cos( ) and d 2 1 p1 p2 q1 q 2 Further, if the allele frequencies are not too different: 2d 2 FST According to NEI (1972, -75, -77): Designate the frequencies of multiple alleles at one locus in a population X as pi , and the frequencies of the allelomorphs in another population Y as qi . Then let Jxx = pi2 , and JYY = qi2 . These are the probabilities that two alleles taken at random in population X and Y respectively, are identical in function (not necessarily identical by descent). Now, when one allele is randomly chosen from population X and the other from Y, the probability that they are identical (by function) is JXY = pi qi (summed over all identical pairs at that locus) Then Nei’s normalized identity, I, for this locus in X and Y is: I J XY J XX J YY , and the standard genetic distance, D, is: D = - ln(I) For multiple loci the respective J’s are arithmetic means over loci. (NB! monomorphic loci, if encountered, are included in the analysis). If the alleles considered are selcetively neutral, then Nei’s normalized identity, I, change linearly with time. 46 47 The genotypic identity and distance according to HEDRICK (1971) Given that populations deviate from H-W proportions, the genotype frequencies may be an interesting alternative to allele frequencies to measure identities/distances. Hedrick uses a parallel development to Nei’s reasoning but based on genotype frequencies. The standardized identity according to Hedrick, i.e. based on genotype frequencies, is: I 2I XY , I X IY where n I XY Pij , X Pij ,Y , i j n I X Pij2, X , and i j n I Y Pij2,Y i j Pij,X and Pij,Y are the frequencies of genotype ij in population X and Y , respectively; and the summations are over all genotypes. The genetic distance is the complement of I, or: D=1-I. Extension to multiple loci may be done by averaging I and D over loci. The probability of a unique genotype according to HEDRICK (1971) Important in species comparisons and other situations is the presence or absence of particular genotypes or - alleles. To focus on this aspect, the probability of a unique genotype is introduced. This measure has two components: n U x y Pijx , where Pij.y = 0 i j and n U yx Pij y , where Pij.x = 0 i j the first component is the probability of a genotype occuring in population X and not in Y; the second is the probability of a genotype occuring in Y and not in X. U ranges from 0 to 1. Extension to multilocus situations is done by calculationg the arithmetic average over all loci. 47 48 SIMILARITIES AND DISTANCES FOR RAPD BAND PATTERNS USING JACCARD’S DICHOTOMY COEFFICIENTS: Analysis of data from Avena sterilis RAPDs. Bjørn Ivar Honne, Planteforsk Data provided by Prof. dr. Manfred Heun. The data are from 177 RAPD bands generated with 20 primers in 24 genotypes of Avena sterilis. The raw data are scores of presence and intensity of bands. Scores 1, 2, 3 = band present and with icreasing intensity, score 0 = no band where at least one of the other genotypes has produced a band. (The raw data are given at the end of this chapter). From these data we want to measure similarities or dissimilarities among the 24 genotypes (lines), and so use these measures to construct a form of tree where those genotypes which are similar cluster closely together, and those less similar join up at increasing distances as the dissimilarities increases. We will return to the tree construction later, let us first decide how to measure similarities. We could use the raw data directly and measure similarities by Goodman-Kruskal’s gamma coefficient among the genotypes. (The gamma coefficient is suited for discontinuous/discrete data). However, this is not quite suitable here. First, with this measure, a score of 0 in two genotypes would contribute to similarity among those two genotypes, whereas the mutual lack of band where other genotypes have a band is no positive confirmation that the two ceros are similar. They may fail to produce the band for completely different reasons (DNA base compositions). The intensity of bands is another difficulty. We don’t know the reproducibility here, and if not highly reproducible, genotypes with same bands present but with different intensities would be assumed/measured less similar than those with same intensity. So the only hard evidence we have got is presence or absence of bands. Thus the data should be dichotomized, i.e. represented by 0 or 1 only, (or any other pair of digits). This can be achieved by retaining all 0 (cero) as 0, and replacing all values greater than 0 with 1. When our raw data are dichotomized, we may compare all possible pairs of genotypes (i,j) by presence (1) or absence (0) of each of the 177 possible bands (x), and compute a matrix of similarity coefficients. As mentioned above, we would count as similarity when two genotypes produce the same band, as dissimilarity when the one genotype produces a band and the other not, and exclude as not informative the cases where both genotypes lack a possible band. Referring to the table below, xi and xj represent the possible bands in two genotypes/lines. For each band position, (bands identified by primer used and fragment length), there is either a 0 or 1 in each genotype; a is the number of cases with same band in both, b is band in j not in i , c is band in i not in j, and d is no band in either where at least one fo the other genotypes investigated has produced a band. The latter is the number of non informative cases when similarity is considered. So the total number of bands in the two genotypes is a + b + c, of which a are similar bands. 48 49 xi 1 a c a+c 1 0 xj 0 b d b+d a+b c+d So the similarity coefficient, Si,j , would be: Si , j Mi , j a , a bc Ti Tj Mi , j also called Jaccard´s dichotomy coefficients, (varying from 0 to 1). Above is also shown a notation with Mi,j for the number of common bands, Ti for the total number of bands in i, and Tj for the total number of bands in j. A mesure of distance between the two genotypes, di,j , would be: di,j = 1- Si,j , leading to distance = 0 for similarity 1 (all band similar, i.e. b = c = 0; Mi,j = Ti = Tj ), and distance = 1 for similarity 0 (i.e. a = Ti,j = 0 and b and/or c > 0). The similarity matrix for all pairs among the 24 genotypes are at the end of this chapter. The distances as defined above, may the be used to cluster the genotypes in a tree structure. However, trees can be constructed in several ways with one and same measure of distances between pairs of genotypes, and different methods doesn´t (usually) produce similar trees. Here we shall show two methods, the average method, (also called the UPGMA= the unweighted pair group method with arithmetic mean), and the additive tree method. The UPGMA method and others are briefly described in Hartl & Clark p. 378 etc. The reason for also showing the result of the additive method, is that UPGMA and other hierarchial tree methods imply that all within cluster distances are smaller than all between cluster distances and that within cluster distances are equal. This («ultrametric») condition seldom applies to real similarity data. In an additive tree distances between objects/genotypes are represented by the lengths of the branches connecting them. Starting with the raw data file at the end of this chapter, dichotomizing the data, calculating similarities and distances and constructing a tree, can be achieved with the following commands from inside the program packet ‘SYSTAT’ (v. 6.0),( > marks the program prompt): >corr (evokes the module which calculates correlations,similarities etc.) >use avenak (name of the file with raw data) >save avenas3 (naming the file where we save the similarity matrix) >let (A1..D6) = @ <> 0 (dichotomizing the raw data) >s3 A1..D6 (calculates similarities as Jaccard’s dichotomy coeff.) >cluster (swithces to the module for cluster analyses) >use avenas3 (use the similarity matrix) >join A1..D6 /linkage=average(,polar) (the program recognises the file as a similarity matrix, uses 1-Si,j to calculate distances, constructs the tree according to the ‘average’/UPGMA method and produces a polar plot if the option within parenthesis is used). Other statistical packages like SAS can also produce the same results (different commands). 49 50 Clusteranalysis of data from Avena sterilis. Distance used is 1-Jaccard’s dichotomy coefficients, linkage=‘average’; upper graph cartesian plot, lower graph polar plot. 50 51 Additive tree using Jaccard’s dichotomy coefficients on data from Avena sterilis RAPD’s. NB! As given here the tree is unrooted. 51 52 Raw data from scoring 177 RAPD bands generated with 20 primers (A-01, A-02, ....., B-08) applied to 24 genotypes (A1, A2, ....., D6). Presence of bands are designated 1, 2 or 3 according to band intensity, absence of band where at least one other genotype has produced a band is designated 0. ____________ Genotypes __________________ PRIM. A A A A A A B B B B B B C C C C C C D D D D D D 1 23 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 A-01 A-01 A-01 A-01 A-02 A-02 A-02 A-03 A-03 A-03 A-03 A-03 A-03 A-03 A-04 A-04 A-04 A-04 A-04 A-04 A-04 A-04 A-04 A-04 A-04 A-04 A-09 A-09 A-12 A-12 A-12 A-12 A-12 A-12 A-12 A-12 A-12 A-13 A-13 A-13 A-13 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 1. 1. 1. 1. 1. 1. 0. 0. 0. 2. 0. 2. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 1. 2. 0. 2. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 0. 1. 2. 2. 2. 2. 0. 2. 1. 0. 0. 1. 0. 0. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 0. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 0. 2. 2. 2. 2. 2. 2. 0. 0. 1. 1. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 2. 2. 2. 2. 2. 2. 1. 1. 1. 1. 1. 1. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 1. 0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 1. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 1. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 2. 0. 2. 0. 0. 0. 2. 2. 0. 0. 0. 0. 0. 0. 2. 2. 0. 0. 0. 2. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 2. 0. 3. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 2. 2. 1. 0. 2. 0. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 2. 0. 2. 1. 0. 2. 2. 2. 2. 2. 2. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 2. 1. 1. 0. 0. 1. 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 0. 0. 1. 1. 1. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 2. 2. 2. 2. 2. 2. 0. 0. 2. 2. 0. 2. 2. 2. 2. 1. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 2. 2. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 2. 2. 2. 2. 2. 1. 1. 2. 2. 2. 2. 2. 2. 2. 1. 2. 2. 2. 2. 2. 2. 2. 2. 0. 1. 2. 0. 2. 2. 0. 0. 0. 2. 0. 0. 0. 2. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 2. 2. 2. 3. 2. 2. 2. 2. 52 53 PRIM. A A A A A A B B B B B B C C C C C C D D D D D D 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 A-14 2. 2. 2. 2. 2. 2. 1. 1. 1. 1. 1. 1. 2. 2. 1. 1. 1. 2. 1. 2. 1. 1. 2. 2. A-14 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. A-14 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-14 2. 1. 1. 0. 1. 1. 2. 2. 2. 2. 2. 2. 1. 1. 1. 0. 2. 2. 2. 2. 2. 2. 2. 2. A-16 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 1. 0. 0. 0. 1. 1. 0. 0. 0. 1. A-16 2. 0. 2. 2. 2. 0. 2. 2. 0. 2. 0. 2. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. A-16 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-16 0. 0. 2. 2. 0. 2. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. A-16 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-16 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 2. 0. 2. 0. 2. A-16 1. 1. 0. 0. 0. 0. 1. 0. 0. 0. 0. 1. 0. 0. 1. 2. 0. 0. 0. 0. 2. 0. 2. 0. A-16 2. 2. 2. 2. 2. 2. 1. 2. 2. 1. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. A-16 2. 2. 2. 0. 2. 2. 1. 1. 0. 0. 0. 1. 2. 2. 2. 2. 2. 2. 1. 2. 2. 1. 2. 2. A-16 0. 0. 0. 2. 0. 0. 2. 0. 1. 2. 0. 1. 0. 0. 0. 0. 1. 0. 2. 0. 0. 0. 0. 2. A-16 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-16 0. 0. 0. 0. 0. 0. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 3. 3. 0. 3. 0. 3. A-16 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-17 2. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 1. 2. 2. 2. 2. 2. 2. 2. A-17 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-17 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. A-17 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 0. 0. 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. A-17 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. A-17 1. 1. 1. 1. 0. 0. 2. 1. 0. 2. 0. 2. 2. 2. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. A-17 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-17 0. 0. 0. 0. 0. 0. 2. 2. 0. 1. 2. 2. 2. 0. 2. 2. 1. 1. 1. 1. 1. 1. 1. 1. A-17 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-18 0. 0. 0. 0. 0. 0. 2. 2. 1. 0. 2. 0. 0. 2. 2. 2. 0. 2. 2. 0. 2. 2. 2. 1. A-18 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 2. 2. 0. 2. A-18 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 2. 0. 0. 0. A-18 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-18 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 2. 2. 2. 0. 2. A-18 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 1. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. A-18 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-18 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-18 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. A-18 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 1. 2. 2. 2. 2. 2. 2. 2. A-19 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-19 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 1. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 2. 2. A-19 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-19 0. 0. 0. 0. 0. 0. 0. 0. 3. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. A-19 2. 2. 0. 2. 2. 2. 2. 0. 2. 2. 2. 2. 0. 2. 0. 0. 1. 0. 2. 2. 2. 2. 2. 2. A-19 2. 2. 0. 2. 0. 2. 0. 0. 0. 0. 0. 2. 2. 0. 2. 2. 1. 2. 2. 2. 2. 0. 2. 2. A-19 2. 2. 2. 2. 2. 2. 1. 1. 1. 1. 1. 1. 2. 2. 2. 2. 1. 2. 2. 1. 1. 2. 2. 2. A-19 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 0. 0. 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 0. 0. A-19 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 2. 0. 2. 2. A-19 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-19 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 53 54 PRIM. A A A A A A B B B B B B C C C C C C D D D D D D 1 23 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 A-20 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-20 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. A-20 0. 0. 0. 0. 0. 0. 2. 2. 2. 2. 2. 2. 0. 1. 1. 1. 1. 1. 2. 0. 0. 0. 2. 1. A-20 0. 0. 0. 1. 0. 0. 2. 0. 2. 2. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. A-20 2. 2. 0. 2. 2. 2. 0. 1. 0. 0. 0. 2. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. A-20 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. A-20 0. 0. 0. 0. 0. 0. 2. 2. 0. 2. 2. 2. 0. 1. 2. 0. 2. 2. 0. 0. 0. 0. 0. 0. A-20 0. 0. 0. 2. 0. 0. 2. 2. 2. 2. 2. 2. 0. 0. 2. 2. 2. 2. 2. 0. 0. 2. 0. 2. A-20 1. 1. 1. 0. 0. 1. 0. 0. 2. 0. 0. 0. 2. 0. 0. 0. 0. 1. 1. 2. 2. 1. 1. 1. A-20 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. A-20 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 0. 0. 0. 2. 2. 2. 2. 2. 2. 2. 2. 0. 0. 2. A-20 0. 0. 0. 0. 0. 0. 2. 2. 2. 2. 1. 1. 2. 0. 0. 0. 0. 0. 0. 0. 0. 2. 2. 0. A-20 0. 0. 2. 0. 0. 2. 2. 2. 2. 2. 2. 2. 2. 1. 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. A-20 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 2. 2. 2. 2. 0. A-20 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-01 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-01 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 2. 0. 0. 0. 0. 2. B-01 0. 0. 0. 0. 0. 0. 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. B-01 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-01 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. B-01 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-01 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. B-01 2. 2. 2. 0. 2. 2. 1. 1. 1. 1. 2. 2. 2. 0. 2. 2. 1. 2. 1. 0. 0. 1. 1. 2. B-01 0. 0. 0. 0. 1. 1. 0. 0. 0. 0. 0. 0. 2. 2. 0. 0. 1. 2. 1. 1. 2. 1. 2. 1. B-01 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-01 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 2. 0. 0. 0. B-02 0. 0. 0. 0. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. B-02 0. 1. 1. 0. 0. 0. 0. 0. 2. 2. 1. 2. 1. 1. 0. 1. 1. 0. 1. 0. 0. 2. 0. 2. B-02 2. 2. 3. 3. 2. 2. 3. 3. 3. 2. 3. 2. 3. 2. 2. 3. 2. 2. 3. 2. 2. 3. 2. 3. B-02 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. B-02 3. 3. 1. 0. 3. 3. 0. 0. 0. 0. 2. 2. 0. 0. 3. 0. 3. 0. 2. 1. 1. 2. 1. 2. B-02 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 3. 0. 0. 0. 0. 0. 0. B-02 0. 0. 0. 0. 0. 0. 3. 2. 2. 2. 1. 2. 0. 0. 0. 0. 2. 0. 2. 2. 2. 2. 2. 2. B-02 0. 0. 2. 2. 0. 0. 0. 2. 2. 1. 2. 2. 0. 0. 0. 2. 0. 0. 2. 2. 2. 2. 2. 2. B-02 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 3. 0. 0. 0. 0. 0. 3. 3. 0. 3. 0. B-02 1. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 2. 0. 0. 0. 0. 0. 0. 0. 0. B-02 2. 0. 0. 0. 0. 0. 2. 2. 2. 2. 0. 2. 0. 2. 0. 0. 1. 0. 2. 2. 2. 2. 2. 2. B-03 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. B-03 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 2. 3. 3. 3. 3. 3. B-03 0. 0. 2. 0. 0. 0. 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 0. 0. 2. 0. 0. 2. 0. 0. B-03 0. 2. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. B-03 2. 2. 2. 1. 2. 2. 0. 0. 2. 0. 2. 0. 2. 2. 2. 1. 2. 2. 2. 2. 2. 2. 2. 2. B-03 0. 0. 0. 0. 0. 0. 0. 3. 3. 0. 3. 0. 0. 0. 0. 2. 0. 0. 0. 2. 0. 0. 0. 2. B-03 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. B-03 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. B-03 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 54 55 PRIM. A A A A A A B B B B B B C C C C C C D D D D D D 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 B-04 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-04 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. B-04 2. 2. 2. 2. 2. 2. 2. 2. 1. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. B-04 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-04 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. B-04 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 2. 0. 0. 0. 0. 0. 2. 2. 2. 0. 0. 1. 0. 2. B-04 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-04 0. 0. 0. 0. 0. 0. 2. 0. 0. 2. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. B-05 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-05 0. 2. 2. 0. 2. 2. 0. 0. 0. 0. 0. 0. 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 0. 0. B-05 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-05 0. 2. 0. 0. 0. 2. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. B-05 2. 2. 2. 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. B-05 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-05 0. 0. 0. 0. 2. 0. 2. 2. 2. 0. 2. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. B-06 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-06 0. 0. 0. 0. 0. 0. 2. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. B-06 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 0. 2. 0. 0. 2. 0. B-06 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 0. 2. 2. 2. 2. B-06 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 2. 0. 0. B-06 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-06 0. 0. 0. 0. 0. 0. 2. 2. 2. 2. 2. 2. 0. 0. 0. 2. 0. 2. 0. 0. 0. 2. 2. 0. B-06 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. B-07 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 2. 0. B-07 0. 0. 1. 1. 0. 0. 2. 2. 0. 0. 0. 0. 0. 2. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. B-07 2. 2. 2. 3. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. B-07 0. 0. 0. 0. 0. 0. 2. 2. 0. 2. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 1. B-07 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-07 0. 0. 0. 3. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 3. 3. 3. 3. 3. 0. B-07 1. 2. 3. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 3. 2. 2. 2. 3. 2. 2. 2. 2. 2. 2. B-07 0. 0. 2. 2. 2. 2. 2. 2. 0. 2. 0. 0. 2. 2. 0. 1. 1. 0. 0. 2. 2. 0. 2. 2. B-08 2. 0. 2. 0. 2. 3. 0. 2. 2. 0. 2. 2. 3. 2. 3. 0. 0. 3. 2. 0. 0. 0. 2. 0. B-08 2. 0. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 0. 0. 2. 2. 2. 2. 2. 0. 3. 2. 3. 3. B-08 0. 2. 2. 2. 2. 2. 0. 0. 0. 0. 1. 0. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. B-08 2. 0. 2. 0. 0. 2. 0. 0. 2. 0. 2. 0. 0. 2. 0. 0. 0. 0. 0. 1. 1. 0. 0. 0. B-08 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 1. 2. 2. 2. 2. 2. 2. 2. 1. 0. 2. 2. 2. 2. B-08 0. 0. 0. 0. 2. 0. 2. 2. 2. 2. 0. 0. 0. 2. 0. 2. 2. 0. 0. 0. 0. 0. 0. 0. B-08 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. B-08 2. 0. 2. 2. 2. 0. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 0. B-08 0. 3. 0. 3. 0. 0. 3. 3. 3. 3. 3. 0. 0. 0. 0. 3. 0. 3. 3. 0. 0. 3. 0. 0. B-08 2. 2. 2. 2. 2. 2. 0. 0. 0. 0. 0. 0. 1. 2. 2. 2. 2. 2. 2. 2. 0. 2. 2. 2. B-08 0. 2. 2. 2. 2. 2. 0. 0. 0. 0. 2. 0. 2. 2. 2. 1. 2. 2. 2. 2. 2. 2. 2. 2. B-08 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 1. 0. 1. 1. 0. 0. 55 56 Similarity matrix with Jaccard’s dichotomy coefficient for the Avena data A1 A2 A3 A4 A5 A6 B1 B2 B3 B4 B5 B6 C1 C2 C3 C4 C5 C6 D1 D2 D3 D4 D5 D6 C1 C2 C3 C4 C5 C6 D1 D2 D3 D4 D5 D6 A1 A2 A3 A4 A5 A6 B1 B2 1.0000 0.8250 0.8065 0.7200 0.8099 0.8049 0.6667 0.6818 0.6815 0.6593 0.6692 0.7068 0.7705 0.7559 0.8250 0.7231 0.7463 0.7742 0.6884 0.7099 0.7442 0.6765 0.7578 0.7090 1.0000 0.7840 0.7541 0.8167 0.8729 0.6350 0.6370 0.6377 0.6397 0.6870 0.6741 0.8067 0.7760 0.8017 0.7559 0.7786 0.7520 0.6934 0.7287 0.7500 0.6815 0.7638 0.7273 1.0000 0.7381 0.8279 0.8226 0.6357 0.6741 0.6619 0.6642 0.6866 0.6619 0.7886 0.7874 0.7840 0.7273 0.7630 0.7364 0.6573 0.6642 0.6838 0.6454 0.6963 0.6763 1.0000 0.7541 0.7360 0.6541 0.6565 0.6204 0.6591 0.6692 0.6324 0.7438 0.7440 0.7258 0.7520 0.7348 0.7063 0.6642 0.6718 0.6667 0.6277 0.6667 0.6716 1.0000 0.8729 0.6593 0.6870 0.6618 0.6642 0.6870 0.6496 0.8067 0.8049 0.8017 0.7559 0.8203 0.7951 0.6571 0.6767 0.6970 0.6569 0.7231 0.6889 1.0000 0.6214 0.6471 0.6475 0.6259 0.6970 0.6594 0.8167 0.8000 0.7967 0.7385 0.7879 0.7619 0.6786 0.7252 0.7462 0.6547 0.7597 0.7239 1.0000 0.8760 0.7846 0.8770 0.7597 0.7846 0.6493 0.6889 0.6842 0.6715 0.6950 0.6544 0.6528 0.5903 0.6312 0.6525 0.6788 0.6714 1.0000 0.7891 0.8080 0.7920 0.7891 0.6899 0.7045 0.7132 0.7121 0.6978 0.6947 0.6906 0.6377 0.6569 0.7037 0.7197 0.7111 C1 C2 C4 C5 1.0000 0.7951 0.8534 0.7600 0.7692 0.8000 0.7090 0.7323 0.7266 0.6970 0.7823 0.7442 1.0000 0.8049 0.7462 0.8372 0.7559 0.6738 0.7068 0.7273 0.6500 0.7405 0.7059 C3 1.0000 0.8279 0.8062 0.8559 0.7313 0.7023 0.7364 0.6815 0.7778 0.7538 1.0000. 0.7630 1.0000 0.7778 0.7727 0.6929 0.7273 0.6642 0.7000 0.6963 0.7194 0.6691 0.7042 0.7348 0.7445 0.7388 0.7737 C6 D1 1.0000 0.7259 0.6593 0.7045 0.7015 0.7442 0.7348 D2 1.0000 0.7687 0.7895 0.8397 0.7895 0.8615 56 1.0000 0.8926 0.7313 0.8320 0.8346 B3 B4 1.0000 0.8047 0.8320 0.7463 0.6642 0.6912 0.6618 0.6861 0.6853 0.6815 0.6901 0.6154 0.6454 0.6786 0.6934 0.6978 D3 B5 1.0000 0.7656 0.8047 0.6541 0.6940 0.6642 0.6765 0.7122 0.6593 0.6573 0.5944 0.6241 0.6691 0.6715 0.6643 D4 B6 1.0000 0.7348 0.7031 0.7045 0.7266 0.7121 0.6978 0.7209 0.7029 0.6377 0.6569 0.6912 0.7068 0.6985 D5 1.0000 0.6767 0.6788 0.7252 0.6861 0.6972 0.6691 0.7021 0.6383 0.6934 0.6786 0.7444 0.6978 D6 1.0000 0.7652 1.0000 0.8699 0.7652 1.0000 0.8281 0.7955 0.8140 1.0000 57 DNA ANALYSIS TECHNIQUES (Paul Galvin 1998) Aquaculture Development Centre, Department of Zoology and Animal Ecology, University College Cork, Ireland Tel: +353 21 904053 Fax: +353 21 277922 E-mail: P.Galvin@UCC.IE 1. Electrophoresis of DNA Unlike proteins, where at least part of the separation is the result of different charges (due to amino acid substitutions), all DNA is negatively charged, so the DNA fragments migrate towards the positive electrode. The distance that the fragments migrate is therefore primarily related to the size of the fragments (smaller fragments move more quickly), although the secondary structure of the DNA can also be important (as utilised in single stranded conformational polymorphism (SSCP) analysis) (Hillis et al. 1996). The degree of "sieving" that is effected by the gel matrix is therefore of the utmost importance. Two types of gel matrix are commonly used: polyacrylamide and agarose (Maniatis et al. 1982). Polyacrylamide gel electrophoresis is usually carried out on a vertical gel apparatus, with concentrations of acrylamide ranging from 4 to 8%, depending on the range of fragment sizes that need to be separated. The lower the percentage of acrylamide, the easier it is for the DNA to pass through the gel matrix. Therefore, lower percentage acrylamide concentrations tend to be used to separate larger fragments, while higher percentage concentrations reduce the speed of migration for the smaller fragments, thus concentrating the fragments into sharp bands. Similarly agarose gels can range from 0.5% to 5% w/v where the highest concentrations are used only for fragments of < 300bp. While polyacrylamide gels tend to provide optimal resolution for smaller fragments, improvements in the quality of available agarose (although high quality agarose tends to be expensive), have enabled the use of agarose gels for separating microsatellite alleles. One important factor influencing the choice is the characteristic neurotoxicity of acrylamide in its unpolymerised state. 57 58 2. Visualisation of DNA Following the separation of the fragments, visualisation of the fragments can be achieved in a number of ways. Probably the simplest method (if sufficient quantity of the required type of DNA is present), is to stain with ethidium bromide and view over a UV transilluminator. The simplicity of this method makes it popular especially for routine assessment. However, ethidium bromide intercalates with the DNA, making it a highly mutagenic substance, presenting a hazard in the laboratory. Its sensitivity is also limited to approximately 10ng of DNA. DNA bands on a gel can also be revealed by silver staining, and this is a valid alternative especially for polyacrylamide gels. Where the DNA of interest occurs in very low concentrations, some form of tagging either with a radioactive or chemiluminescent label is required for detection. When radioactive labels are used (e.g. 32 P), the DNA is transferred from the gel to a nylon membrane (e.g. by Southern blotting) and a labelled probe is hybridised to the membrane, which is then exposed to X-ray film. Automated DNA sequencers combine laser technology, fluorescence detection and carefully regulated polyacrylamide gel electrophoresis to enable automated sequence analysis and genotype characterisation. This relatively expensive technology is fast becoming the method of choice for detecting genetic variability within and among species (i.e. genotyping of microsatellite loci and sequencing of mtDNA or transcribed sequences respectively) (Ziegle et al. 1992; Tully et al. 1993). Not only does this approach avoid the need to use radio-active isotopes, it also lends itself to automation and hence provides the possibility for a high throughput, enabling screening of larger numbers of loci and populations than has been possible with manual methods. In addition, through the use of image analysis software to characterise the genotypes, based on the mobility of the bands relative to reference bands, genotype characterisation can be standardised among different researchers within and between laboratories. 3. Restriction digestion of DNA Restriction enzymes cut DNA at specific recognition sequences. Different restriction enzymes have characteristic recognition sequences (restriction sites) of four, five or six base pairs, the length of which affects the number of times that a fragment will be cut. That is, generally six-base cutters will have fewer recognition sites in any given sequence and so will result in fewer fragments. Restriction fragment length polymorphisms (RFLPs) result when a mutation changes a sequence such that it either generates a new restriction site where there wasn't any previously, or results in the loss of an existing restriction site. RFLPs are detected by digestion with a restriction enzyme, followed by separation of the fragments of DNA (on an electrophoresis gel). This enables interpretation of the pattern to determine where the restriction sites have occurred, revealing differences among chromosomes due to the gain or loss of a restriction site. 58 59 4. The Polymerase Chain Reaction (PCR) The PCR technique has revolutionised molecular biology (Saiki et al. 1988). It is now possible to isolate sections of DNA by designing primers complimentary to the sequences at either side, and to amplify up such sections of DNA to facilitate different forms of manipulation. The sensitivity of the technique means that careful attention to the practice is required. Contamination with foreign DNA of any of the solutions or materials connected to the reactions can result in the failure to amplify the correct product, or the presence of artefact products. As a general rule, the results of any reaction should be 100% reproducible and for any locus, the products should segregate according to Mendelian expectations. By following these criteria, the risk of artefact bands being misinterpreted resulting in inaccurate genotype characterisation can be minimised. 5 Sampling considerations DNA fragments tend to be broken down rapidly by endonucleases once the cell dies. While certain techniques that are based on small fragments of DNA (e.g. microsatellite analysis) are tolerant of high levels of degradation, and have enabled the use of ancient DNA in some applications (Paabo 1989), a good sampling programme should aim to ensure that the quality of DNA available for analysis is as high as possible. This is achieved by ensuring that the endonucleases that cause the degradation are prevented from becoming active. One option is to freeze the tissue immediately post-mortem, and avoid any defrosting of the tissue before the DNA extraction. Alternatively, some of the tissue can be placed in 99% ethanol (in at least three times the volume of the tissue), and given a quick shake to ensure that the tissue is well immersed. Other alternatives may be available depending on the species of interest and the tissue type: in the case of blood and small insects, smearing of the tissues (or blood) on a glass slide and air drying (especially appropriate for warm countries where freezing is impractical and ethanol is difficult to acquire) is known to yield good quality DNA. As tissues for different species can differ substantially, a pilot study is required prior to any large sampling programme, to ensure that the proposed method of storage will provide DNA of sufficient quality to apply the relevant analysis technique. The two criteria which are important to DNA analysis are the quality of the DNA in terms of the degree to which it is degraded and its purity. While DNA of maximum quality (i.e. DNA that has not been broken down into small fragments) is always desirable, it is not always possible to obtain DNA which has not already been degraded by endonucleases and for some applications which involve analysis of relatively small DNA fragments, it is not essential. For other applications, particularly those involving restriction analysis of non-amplified DNA, high quality DNA is a prerequisite. 59 60 Therefore, the final application should be considered when choosing the type of method for DNA extraction. The second variable to consider is the purity of the DNA. While phenol-chloroform based extraction protocols are designed to remove impurities from the DNA, other approaches simply release the DNA into solution. The latter can be adequate for many PCR based applications, while some impurities can inhibit restriction enzymes, which affects applications that involve digestion of the total DNA. Therefore, as with DNA quality, the time and resources invested in DNA purification should match the application for which the DNA is required. Unlike DNA quality, which is dependent on the condition of the DNA when it is received, it should always be possible to obtain pure DNA if required. One of the most important considerations when undertaking a population study, is to determine how many individuals need to be sampled. However, for any given study, there will be limiting resources (e.g. labour, consumables, etc.). Therefore, it is necessary to balance the need collect as large a sample size as possible, against the need to screen as many populations as possible, and the need to get allele frequencies from as many loci as possible. Whether the aim is to describe genetic variation in populations or species, it will be necessary to get an adequate picture of the variation within the taxonomic unit (population or species), in order to be able to determine the degree of differentiation among taxonomic units. Similarly, the choice of the number of loci is a form of genetic sampling, where one or a few may provide a gene phylogeny (which may not necessarily be representative of the whole genome), so that what is ideally required is an organismal phylogeny, based on as many loci as possible (Weir 1990b). These considerations mean that there is no simple recommendation for the "ideal" sample size, number of samples, or number of loci. Each situation will be case specific, so that it is necessary to weigh up the above three constraints taking the type of marker into consideration. Some taxonomic groups show considerable genetic variation among locations. Therefore, in order to be able to determine genetic differentiation between two populations from different areas for example, it would be necessary to get a reliable estimate of within population genetic diversity. 6. Molecular Markers 6.1 Mitochondrial DNA analysis One of the first parts of the gene to be studied was the mitochondrial DNA (see Avise et al. (1987)), since it was a manageable size (approximately 16,000bp) and could be isolated from the rest of the DNA by caesium chloride gradient centrifugation. This enabled RFLP analysis of the total mitochondrial genome by silver-staining following electrophoresis. Since the isolation of mtDNA involved caesium chloride gradient centrifugation (a hazardous and time consuming procedure), together with its requirement for fresh tissue, many researchers 60 61 switched to using mtDNA as a probe (Hynes et al. 1989), so that there was no longer any need to separate mtDNA from nuclear DNA prior to electrophoresis. Instead, total DNA was digested with a restriction enzyme and then separated by agarose gel electrophoresis. Due to the fragile nature of the agarose gels, the DNA was transferred and fixed to a nitrocellulose membrane, so that it was possible to probe the membrane. The probe, consisting of the mtDNA fragment (together with a marker to enable sizing of the bands), was labelled with a radioactive isotope (e.g. 32P) and hybridised to the DNA bound to the membrane. Following autoradiography, an X-ray film revealed the banding pattern, from which it was possible to determine the presence or absence of restriction sites. While the technique was quite expensive, due to the need to repeat the procedure for each enzyme, it did avoid the requirement for direct isolation of mitochondrial DNA (which required fresh liver tissue), and provided analysis of restriction sites over the whole mtDNA genome. It was also quite demanding with respect to the DNA requirements, such that in order to be able to screen a number of enzymes, several micrograms of high quality DNA were required. Following the development of the PCR approach, comparisons between mtDNA sequences from a wide range of vertebrate species revealed that certain parts of the mtDNA genome were highly conserved among species. This enabled the development of "universal" primers (Kocher et al. 1989), that were capable of amplifying segments of the mtDNA from most vertebrates. This has resulted in the cytochrome b (cyt b) region being studied intensively across a wide range of species, initially by RFLP analysis and subsequently by direct sequence analysis (Meyer 1993). 6.2 DNA Fingerprinting Transfer of DNA from an agarose gel to a nylon membrane (or nitro-cellulose) was also a feature of multi-locus minisatellite DNA analysis (Jeffreys et al. 1985a). Again, total genomic DNA was isolated, a few micrograms of which were cut with a four base restriction enzyme and separated by electrophoresis on an agarose gel. The DNA was then transferred to a membrane by Southern blotting as for the previous technique. While the results of probing with an mtDNA probe and for a multilocus probe (such as that of Jeffreys 33.15/33.6) yield completely different banding patterns, the procedure is essentially the same, progressing from probing, hybridisation through to autoradiography. This approach continues to be used in single locus minisatellite DNA analysis (Jeffreys et al. 1985b), and anonymous cDNA analysis (e.g. Pogson et al 1995). With respect to these techniques, the main progress over the last decade has been the improvement of chemiluminescent (non-radioactive) staining procedures and the ability to PCR amplify the probes; this not only removes the necessity to grow up the inserts by cloning, but also enables labelling of the probes during PCR. Minisatellite regions consist of multiple tandem repeats of a core sequence of 9-100 bp in length (Tautz, 1993). The technique of single locus minisatellite DNA analysis provided the first real alternative to screening for genetic variability at protein coding loci by isozyme analysis, since it 61 62 enabled a high throughput of samples using an assumed non-coding (selectively neutral) region of DNA to reveal high levels of genetic variability. A multi-locus minisatellite DNA probe consists of a sequence of several minisatellite repeat units. Many minisatellite regions share repeat units of similar sequence. If a sequence consisting of a series of such repeat units is used as a probe, it will therefore hybridise to many different loci. While this method can thus detect many different highly variable loci, it is usually not possible to determine which alleles belong to which loci and therefore, to determine the allele frequencies for each locus (Burke et al. 1991). In order to circumvent this problem, it is possible to isolate single locus minisatellite DNA probes, which have in addition to the minisatellite repeat sequence, a unique sequence flanking the minisatellite region that occurs only once in the genome, and thereby prevents the "probe" from hybridising with more than one minisatellite locus. Screening of minisatellite DNA variation with single-locus probes involves digesting genomic DNA with a restriction enzyme (e.g. HaeIII), separating the fragments by agarose electrophoresis, transfer of the DNA to a nylon membrane by Southern blotting and hybridisation of the membranebound DNA to the single locus probe (where one of the nucleotides has been labelled with 32P) under stringent hybridisation conditions (Taggart and Ferguson 1990b). Allelic variation can then be revealed by autoradiography. Different alleles can occur due to differences in the number of repeat units that make up the allele, or due to mutations at the restriction sites. An alternative means of screening for minisatellite variation involves designing PCR (polymerase chain reaction) primers complementary to the flanking sequences (Jeffreys et al. 1988b), enabling amplification of that minisatellite region in any individual. The amplified product will then contain two alleles, whose length will depend on the number of minisatellite repeat units between the primers. Since the size of the flanking region can be determined from the sequence and the size of each repeat unit can be similarly determined, it is possible by separating the fragments by electrophoresis to determine the number of repeat units in each allele. This enables a large number of alleles to be resolved (n > 30) even on an agarose gel. While the minisatellite core sequences (sequences consisting of the repeat units only) are believed to be non-coding, there is usually little information on the function of the flanking sequences. It is therefore possible to have a locus under the influence of selection in the flanking sequence, tightly linked to a minisatellite locus, resulting in "hitchhiking selection". In such a situation, the minisatellite locus may be positioned adjacent to a locus which is subject to selection. Due to proximity, there is little opportunity for recombination, and so segregation at the two loci can be linked. In this way, alleles from the neutral minisatellite locus may segregate together with the alleles from the adjacent locus under selection. As the behaviour of the minisatellite is the same as if it was directly under the influence of selection, this is termed hitchhiking selection. It is also possible 62 63 that minisatellite regions may be in some way involved in the control of transcription, which could place these loci under the influence of selection. (Krontiris et al. 1993) have described an association between mutations at the HRAS1 minisatellite locus in humans and the risk of breast cancer which may be an example of this phenomenon. The aforementioned methods of mtDNA, multi-locus and single locus minisatellite DNA analysis (excluding PCR-amplified minisatellites) and anonymous cDNA markers have in common the need to first cut the DNA with a restriction enzyme, transfer it to a nylon membrane and then probe the membrane by hybridising a labelled (usually radio-isotope) probe to the membrane-bound DNA. There are a number of limitations imposed by this approach. (1) High quality DNA is required to ensure that the cuts in the DNA are those of the restriction enzyme and not due to degradation. (2) The DNA needs to be sufficiently pure that the restriction enzyme is not inhibited. (3) Several micrograms of DNA are required to ensure a strong signal in the X-ray film (4) Labelling of the DNA has traditionally involved the use of radio-active isotopes which are both hazardous and expensive (although chemiluminescent labelling is now becoming more common) (5) The membranes are very expensive (6) Band sharpness is lost due to the combined effects of Southern blotting and autoradiography 6.3 Microsatellite DNA analysis Microsatellite loci are similar to the minisatellite loci described above, except that the repeat units are di- tri- or tetra-nucleotide lengths (Wright and Bentzen 1994). They are much more common in the genome than minisatellite loci, enabling these loci to be isolated much more easily. Screening of allelic variability at these loci using automated DNA sequencers is becoming the standard when the resources are available (Tully et al. 1993). There is considerable debate in the literature at present regarding the mode of mutation for microsatellite loci (i.e. infinite allele model versus stepwise mutation model) (Valdes et al. 1993), the possibility of selection influencing allele / genotype frequencies and the dangers associated with interpretation of data with a high incidence of null alleles for some loci. As the number of studies using microsatellite loci increases, some of these issues should be resolved in the near future. Tri- and tetra-nucleotide loci are preferred due to their tendency to have a lower incidence of stutter bands relative to di-nucleotide repeats (O'Reilly et al. 1996). This simplifies determination of which bands should be used to define the genotype of a particular individual; this is especially important when automated genotype characterisation is being undertaken by image analysis. By combining two to four microsatellite loci with non-overlapping allele size ranges, it is possible to 63 64 multiplex different loci, and hence greatly increase the efficiency of genotype characterisation. Therefore, while the technical aspects of microsatellite analysis have progressed enormously, the understanding of the underlying assumptions for this class of marker requires further research. In the interim, caution should be exercised when interpreting microsatellite data. 6.4 Transcribed Sequences Transcribed sequences refer to the conventional definition of the gene, in which the segment of the genome was known to code for a particular protein . There has been a renewed interest in these loci from a number of respects. (a) Some of the loci have been studied extensively by allozyme electrophoresis and analysis at the DNA level can provide an improved understanding of the information collected from earlier studies. (b) Many of the loci contain highly conserved regions which code for proteins (exons) and non-coding regions (introns) which are not involved in coding. While the former enable the design of PCR primers that can be effective for a range of species, the latter can be highly variable, and enable the development of rapid methods of screening for genetic variability (e.g. RFLP analysis). (c) While it would be inappropriate to assume that allelic variability detected at these loci should be selectively neutral, the genetic diversity can be used to differentiate among populations, where it can be shown that the strength of selection is weak (i.e. observed differences cannot be attributable to one generation of selection), and allele frequencies are temporally stable. 7. Statistical analysis 7.1 "Standardised approach" There are two primary considerations when choosing between the various software packages for analysis of genetic data: (1) What are the relevant evolutionary models to the data and which of the packages base their analysis on those models? (2) Which packages are the most "user friendly"? It is clear from many reports and publications produced in the past that the latter consideration ranked highest. BIOSYS-1 (Swofford and Selander 1981) facilitated a relatively easy but comprehensive analysis of data generated from allozymes, and it is evident from the literature that an "acceptable standard analysis" of such data was present during the 1980s as follows: (a) calculation of levels of polymorphism and allele frequencies for each locus, 64 65 (b) 2 test for conformance of each of the taxonomic units at each locus with Hardy-Weinberg expected proportions, (c) heterogeneity 2 analysis to test for significant differences between allele frequencies in different taxonomic units, (d) analysis of F-statistics (Wright 1978) to determine the proportion of genetic diversity within and among sub-units (FST), to estimate the rate of gene flow (from FST), and to determine if instances of non-conformance with HW expectations were due to excesses or deficiencies of heterozygotes (F IS), (e) calculation of Nei's 1972 or 1978 genetic distances, and (f) generation of a UPGMA dendrogram from the genetic distances. While this approach does address many aspects relating to genetic variability in populations, it acceptance as a "standard" analysis, which could be applied to all situations, and the related presumption that the use of this kind of analysis enabled results from different studies to be easily compared, was, to say the least, an over simplification the issues involved. It is important at this point to outline the issues that need to be considered. 65 66 7.2 Statistical problems With the development of DNA techniques, and particularly the isolation of mini- and microsatellite DNA loci, many difficulties that had been noted with analysis of allozyme data, became obstacles to analysis of the data resulting from studies involving these highly variable loci. These can be described as follows. (a) Low frequency alleles, and particularly genotypes became more common as the number of detectable alleles increased. This resulted in an increased risk of sampling error and hence, difficulties associated with implementation of the various tests, due to the inappropriateness of the conventional contingency 2 test. Also, contrary to suggestions in some of the early literature on mtDNA analysis , the increased resolving power of the DNA methods increases the potential for sampling error and thus larger sample sizes are required (Moritz et al. 1987). (b) Although the mutation rate of allozyme loci is generally regarded as being low (e.g. 10 -6), the rate of mutation of DNA loci can vary considerably (i.e. from 10-1 for some minisatellite loci to <10-6 for some coding sequences). Also, the mode of mutation varies among different DNA loci, and to date the mechanism by which mutations arise in VNTR loci is not clearly defined (Henke et al. 1993) and thus it is impossible to determine which model of evolution can be applied to the interpretations of the data. (c) While FST analysis can be used to determine hierarchical structuring of genetic diversity within a species, in most cases the statistical significance of this structuring is left untested. The importance of such structuring is generally accepted as critical to management and conservation considerations, and thus it would seem imperative that appropriate testing of this aspect should be undertaken. (d) Where the object of the study is to determine the genetic relationships between different taxonomic units, or to describe population structure, great caution is required. Many studies, due to limited resources or availability of polymorphic loci are restricted in this respect. In studies where only a small number of loci are screened, there is a high risk of any single locus being under the influence of either balancing or directional selection (i.e. non neutral), and biasing the conclusions as a consequence (Nei 1987). What is therefore required is that as many loci as possible are screened and only a consensus-type dendrogram should be used for interpretation, where the data has been subjected to numerical resampling to highlight unreliable associations of taxonomic groups. The genetic distance calculated together with algorithm used to generate the dendrogram, are also of great importance, as these reflect the assumptions that are being made regarding the evolutionary processes that have resulted in the phylogeny at the time of analysis (Felsenstein 1985). (e) The basic aims of the study need to be defined at an early stage, in order to determine the most appropriate analyses to undertake. Discrimination between taxonomic units can be carried out using loci which are under the influence of selection, provided that the allele frequencies are stable 66 67 over time. Separation of taxonomic units can be defined by significant results from a heterogeneity 2 analysis, or principle component analysis. Studies aiming to describe population structure need to be based on selectively neutral loci, where there is at least some impression of the mutation rate: high mutation rates result in homoplasies and thus tend to underestimate differentiation. It is beyond the scope of this discussion to attempt to review the many software packages available. With respect to their "user friendliness", such a discussion might invariably be biased by the experience of this author. Different analysts will have different backgrounds and for example, while those familiar with MS DOS may have little difficulty negotiating around MS DOS based programs, others whose experience has been largely focused on the MS Windows / Apple Macintosh environment would prefer to avail of software with a Graphical User Interface (GUI). Therefore, it is not the actual software package that requires consideration, but, as with any general statistical packages, it is the particular tests implemented that are important. While the composition of some software packages tend to reflect the author(s) opinions on which components are most appropriate, by inclusion of only those components, many of the recently developed packages have included a whole range of possible options for undertaking each aspect of the analysis. This again puts the onus on the user to choose the most appropriate analysis, in which the following should be considered. 7.3 Recommended approaches for analysis of genetic diversity i) Number of loci tested and the level of polymorphism. Even if some of the loci are later excluded from the analysis due to lack of variability or technical difficulties, it is important for studies describing the relationships among populations to include information on all of the loci initially tested. Selection of loci (e.g. based on their levels of polymorphism) can sometimes be biased by choosing the loci that show the greatest differences, which may be influenced by factors such as directional or balancing selection. ii): Allele and genotype frequencies: Allele frequencies are the normal means of citing the "raw data". However, this is only of value when there is no deviation from Hardy-Weinberg expected proportions. When the genotypic frequencies do not conform with HW equilibrium, then allele frequencies are inadequate to describe the raw data, since the genotypic frequencies do not have a normal distribution and cannot therefore be approximated based on HW expectations (Weir 1990a). iii) Homozygosity and heterozygosity: These have taken on added importance with VNTR loci due to problems with "null alleles". Reporting of excesses or deficits of homozygotes / heterozygotes should be accompanied by data detailing how many (if any) of the samples were not scored for a particular locus. Failure to get data from an individual sample may reflect the presence of a "null homozygote". iv) Conformance with Hardy-Weinberg expected proportions: As stated earlier, the conventional 2 test is not appropriate for most VNTR data, due to the problems with very small expected numbers in 67 68 many of the categories. The preferred alternative is based on Fisher's exact test (Guo and Thompson 1992). Computational difficulties associated with the implementation of the exact test with a large number of alleles has been overcome using a pseudo-random method of testing subsets of the data as described by Guo and Thompson (1992). HW assumes that genes are distributed independently into genotypes. Therefore, this test for HW conformance involves simulation that assume independent distribution of the genotypes, using the same allele frequencies as in the original sample. By repeating the process several times (permutations), it is possible to build up a distribution of the genotype frequencies that would be expected based on HW expectations. The original genotypic frequencies can then be compared with the permutation results to determine the probability of the observed frequencies conforming with HW expected proportions. This overcomes the difficulty associated with small expected numbers for individual classes. 7.4 Recommended approaches for analysis of genetic differentiation i) Heterogeneity test: The conventional heterogeneity 2 test of allele frequencies is also of limited value with respect to VNTR loci, due to difficulties with large numbers of alleles with low expected numbers in many of the classes. This problem can be overcome by either permutation tests or numerical resampling techniques. The null hypothesis is that the samples are simply random subsets of a larger population. The permutation tests therefore determine if the allele frequencies reflect alleles distributed independently into two samples. This is done by pooling the data, and randomly sampling the alleles equivalent to those of original population sizes from the pooled data set. Permutations of this procedure generate a distribution of the allele frequencies expected based on this random model. Comparison of the observed data with this distribution (i.e. is it within the 95% confidence intervals) can be used to test the null hypothesis. Numerical resampling such as bootstrapping or jackknifing operates on a slightly different basis (Weir 1990b). [Bootstrapping involves randomly resampling subsets of the original data to provide new samples of equivalent size as the original (sampling with replacement); jackknifing eliminates one observation of the data (e.g. individual / locus) at a time, so that the number of new data sets is equal to the number of observations]. By calculating the variance within each data set (95% CIs from bootstrapping; SDs from jackknifing), it is possible to determine if different populations do not significantly overlap (e.g. their 95% CI's do not overlap). ii) Population structuring: There is an ever increasing range of algorithms for calculating F-statistics. Wright (1978) defined the differentiation between subpopulations relative to the total as a parameter called FST. Analogous parameters have now been defined by several authors based on alternative assumptions about the evolutionary model and consequent modifications to the algorithm. The two most commonly used algorithms until recently were those of , and G ST, however while the latter has the advantage of not showing negative values when sub-populations appear similar, it is also biased in 68 69 those circumstances and results in an overestimate of the degree of sub-structuring. Over the last two years, many of the newer software packages have included calculations of R ST, which assumes that microsatellite evolution is primarily driven by the stepwise mutation model. Due to the difficulties involved in testing the mutation process of microsatellites, because of the fact that repeat units do not usually vary across a repeat region, this assumption appears to be flawed. While early models assumed that mutations at microsatellite loci took the form of the gain or loss of a single repeat unit (conforming to a strict stepwise mutation model), available empirical evidence has demonstrated that this is certainly not the case (some of the latest models are therefore not based on a strict one-step mutation model). In fact, while recent studies by Jeffreys and co-workers have shown that a completely different mutation process (gene conversion type) dominates in minisatellite loci, there is no evidence to suggest that the same process is not also dominant in microsatellite loci. Therefore, any models which assume that there is a relationship between the number of repeat units and the divergence time of any two VNTR alleles, need to be interpreted with great caution. Such analysis should only be conducted alongside analysis based on alternative models, where any differences between the results can be noted. iii) Genetic distance: Until recently much of the literature concerning population studies was based on Nei's 1972 and 1978 genetic distance measures. For situations where the population(s) have been stable over a long time, these are appropriate measures. However, in the case of many aquatic species, the extent of founder effects and genetic drift can be considerable, and therefore the genetic distance measures used should be appropriate to this. An alternative measure which is more appropriate to situations where genetic drift is an important factor is (Reynolds et al. 1983) coancestry coefficient. This is based on FST values, where the relationship between genetic distance and time is approximately linear in instances of recent divergence. The major difference between the genetic distances of Nei (including the more recent DA measure ) and the FST based measures is that the former weights intermediate frequency differences highly and differences between extreme frequencies much less (i.e. a much greater genetic distance would appear from differences between 0.55 and 0.45 than from 0.00 and 0.10). While the same occurs in the case of the FST based measures, the "problem" appears to be much less. Therefore, further research is required to determine the "optimal" genetic distance measure. It should also be noted that where the genetic distances measured are very low (e.g. < 0.005), there is likely to be a large error associated with the distance (unless it has been derived from a very large number of loci). iv) Dendrograms: UPGMA dendrograms have tended to predominate in past literature. While this method of phylogeny reconstruction has some favourable attributes, its underlying assumptions are rarely met. There are several "additive" type dendrograms that can be used which should be preferred. An example of one of these is the Neighbour-Joining method of (Saitou and Nei 1987). 69 70 Whatever algorithm is used for generating the dendrogram, bootstrapping of the allele frequencies (followed by calculation of genetic distances, etc.) should be used to build a consensus dendrogram to enable the reliability of the nodes to be assessed. This involves bootstrapping over loci, which assumes that each of the loci represent independent data sources (independent "samples" from the genome). As with all measures of genetic relatedness, generation of a dendrogram relies on the data that has been collected. Therefore, it is essential to have as many loci as possible included in the study, to enable the dendrogram to be interpreted as an "organism tree" rather than a "gene tree" (in the case of single locus data) (Nei 1987). 9. Sampling considerations DNA fragments tend to be broken down rapidly by endonucleases once the cell dies. While certain techniques that are based on small fragments of DNA (e.g. microsatellite analysis) are tolerant of high levels of degradation, and have enabled the use of ancient DNA in some applications (Paabo 1989), a good sampling programme should aim to ensure that the quality of DNA available for analysis is as high as possible. This is achieved by ensuring that the endonucleases that cause the degradation are prevented from becoming active. One option is to freeze the tissue immediately post-mortem, and avoid any defrosting of the tissue before the DNA extraction. Alternatively, some of the tissue can be placed in 99% ethanol (in at least three times the volume of the tissue), and given a quick shake to ensure that the tissue is well immersed. Other alternatives may be available depending on the species of interest and the tissue type: in the case of blood and small insects, smearing of the tissues (or blood) on a glass slide and air drying (especially appropriate for warm countries where freezing is impractical and ethanol is difficult to acquire) is known to yield good quality DNA. As tissues for different species can differ substantially, a pilot study is required prior to any large sampling programme, to ensure that the proposed method of storage will provide DNA of sufficient quality to apply the relevant analysis technique. The two criteria which are important to DNA analysis are the quality of the DNA in terms of the degree to which it is degraded and its purity. While DNA of maximum quality (i.e. DNA that has not been broken down into small fragments) is always desirable, it is not always possible to obtain DNA which has not already been degraded by endonucleases and for some applications which involve analysis of relatively small DNA fragments, it is not essential. For other applications, particularly those involving restriction analysis of non-amplified DNA, high quality DNA is a prerequisite. Therefore, the final application should be considered when choosing the type of method for DNA extraction. The second variable to consider is the purity of the DNA. While phenol-chloroform based extraction protocols are designed to remove impurities from the DNA, other approaches simply release the DNA into solution. The latter can be adequate for many PCR based applications, while 70 71 some impurities can inhibit restriction enzymes, which affects applications that involve digestion of the total DNA. Therefore, as with DNA quality, the time and resources invested in DNA purification should match the application for which the DNA is required. Unlike DNA quality, which is dependent on the condition of the DNA when it is received, it should always be possible to obtain pure DNA if required. One of the most important considerations when undertaking a population study, is to determine how many individuals need to be sampled. However, for any given study, there will be limiting resources (e.g. labour, consumables, etc.). Therefore, it is necessary to balance the need collect as large a sample size as possible, against the need to screen as many populations as possible, and the need to get allele frequencies from as many loci as possible. Whether the aim is to describe genetic variation in populations or species, it will be necessary to get an adequate picture of the variation within the taxonomic unit (population or species), in order to be able to determine the degree of differentiation among taxonomic units. Similarly, the choice of the number of loci is a form of genetic sampling, where one or a few may provide a gene phylogeny (which may not necessarily be representative of the whole genome), so that what is ideally required is an organismal phylogeny, based on as many loci as possible (Weir 1990b). These considerations mean that there is no simple recommendation for the "ideal" sample size, number of samples, or number of loci. Each situation will be case specific, so that it is necessary to weigh up the above three constraints taking the type of marker into consideration. Some taxonomic groups show considerable genetic variation among locations. Therefore, in order to be able to determine genetic differentiation between two populations from different areas for example, it would be necessary to get a reliable estimate of within population genetic diversity. 71 72 8. Protocols 8.1 DNA Extraction by Phenol-Chloroform method 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. Prepare PK Buffer (proteinase K buffer) as follows EDTA (0.5M) SDS (10%) Tris (10mM) pH 8.0 with HCl H2O 10.0ml 2.5ml 0.5ml 37.0ml Label one tube for each extraction and add 400L PK buffer and 4L proteinase K (20mg/ml) to each tube Add approximately 60mg tissue to each tube Incubate at 50C for at least 3 hours (or overnight) Add 10L RNAase (10mg/ml), mix and incubate for 90 min at 37C Add 400L phenol (hydrolised) to each tube, mix by vortexing. [CAUTION! Both phenol and chloroform are highly corrosive and volatile. It is essential to wear protective glasses, gloves and lab-coat when handling these substances. All work should be carried out in a fume cubbord.] Add 400L chloroform-isoamyl alcohol (24:1) to each tube, mix by vortexing. Centrifuge at 13,000g for 10 minutes. Label a new tube for each sample. Remove 300L from the aqueous phase (top layer) and transfer to a new tube. Add 600L 99% EtOH, and shake the tube to precipitate the DNA. Remove the supernatant and allow the pellet to dry out for 5-10 min. Re-suspend the DNA pellets in 50-100L TE buffer (Tris-EDTA). Test the DNA quality, by running out a 1L aliquot (mixed with 5L 1x loading dye) on a 1% 1X TBE agarose gel alongside a size marker. High molecular weight DNA appears as a sharp band close to the origin, while degraded DNA appears as a smear along the lane. [Recipe for 2 liters 5X TBE Buffer: 108g Trisma Base (IRRITANT)(Sigma Chemical Company) 55g Boric Acid (X)(Sigma Chemical Company) 40ml 0.5M EDTA (pH8.0) (X)(Sigma Chemical Company) Add distilled water up to a volume of 2 litres.] 72 73 8.2 PCR Amplification a Minisatellite DNA locus (1) Label sterile 0.5 ml tubes. (2) Defrost on ice H2O, x10 Buffer, MgCl2, dNTPs and both primers (3) Add 100ng (1L) of DNA template (e.g. cod) to the base of each tube (4) Create a master mix from the rest of the solutions adding 10% of each to allow for pipetting error X10 Reaction Buffer dNTP (1.25mM stock) MgCl2 (25mM stock) Primer 1 (20uM stock) Primer 2 (20uM stock) H2O Thermoprime plus polymerase Volume per tube 2.0L 4.0L 1.6L 0.5L 0.5L 11.3L 0.1L Final concentration x1 0.25mM 15mM 0.5M 0.5M 1U (5) Dispense stock solution from (4) into each tube and overlay with 30L mineral oil (9) Seal the tube and start the main PCR programme cycle. [950C for 2min] x 1 cycle [940C for 1 min; 600C for 1 min and 720C for 1 min] x 30 cycles. (10) Following PCR amplification, quality of products should be assessed on a 0.5% TBE gel by running out 5L of the reaction (with 1L 6x loading dye). If one or two sharp bands appear (may be faint), proceed. (11) Separate products by loading 12L on a large (20x30cm) agarose gel apparatus, to enable alleles to be clearly separated, even when they are only differentiated by a single repeat unit. 8.3 Preparation of an Agarose gel 1. Determine the volume required. Measure the internal dimensions of the gel casting tray and calculate the volume required to make a gel of 5mm in thickness (e.g. gel size of 200 x 300mm requires 20 x 30 x 0.5 ml agarose solution = 300ml). 2. Determine the gel concentration required. For larger fragments (> 1kb), use less agarose (i.e. 0.7 – 1.0%) to enable these fragments to pass through the matrix during electrophoresis and be separated. In the case of smaller fragments, higher concentrations are necessary (i.e. 1-3%), to prevent the bands from becoming diffuse. A 1% concentration provides reasonable results over a wide range of fragment sizes 3. For a 300ml gel, add 3.0g agarose to 300ml 1x TBE buffer in a conical flask, and heat to boiling point with a microwave oven. [CAUTION! When removing the flask from the microwave, the melted agarose can sometimes contain trapped air, causing it to overflow once disturbed]. Add 15L of ethidium bromide (i.e. 5L /100ml of a 20mg/ml stock), and swirl the fask gently to mix. [CAUTION! Ethidium bromide is highly mutagenic, hence, any of the equipment which come in contact with the gels should not be handled without gloves]. Cover the top of the flask with foil to prevent evaporation. 4. Seal the ends of the gel casting tray with masking tape and place on a level surface. Insert the combs in the appropriate slots on the casting tray to form the wells for applying the samples. 5. Cool the melted agarose to approximately 50C prior to pouring (for approx. 40 minutes with occassional swirling), to avoid warping the casting tray. Pour the gel, removing any air bubbles with a Pasteur pipette. Allow the gel to set. 6. When the gel has set, gently remove the combs and place the tray in the electrophoresis tank. Add 1x TBE buffer until the gel has been submerged by approximately 5mm. The gel is then ready for sample application to the wells. 73 74 8.4 Preparation of an acrylamide gel for the Li-Cor Automatic DNA Sequencer. a) Preparation of gel plates 1. Clean the two gel plates very carefully both with distilled water and ethanol to remove all dust particles that might cause air bubbles. 2. Insert 0.25mm spacers, on each side between the two plates and tie them with the clamps (leave the top clamps open until the gel has been poured and the top spacer has been inserted). 3. Position the gel plates at a shallow angle, approximately 30C to help to pour the gel. b) Recipe for 33cm gel (increase volumes by 50% for a 41cm sequencing gel) 1. Weight out 10.5g Ultrapure Urea (IRRITANT)(Amersham Life Science). 2. Add: 10ml distilled water 3. 5ml 5X TBE Buffer 4. 2.8ml RapidGelTM-XL-40% Concentrate (TOXIC) )(Amersham Life Science). 5. Place parafilm over the mouth of the container and mix thoroughly until all urea has dissolved. 6. Add 25l Temed (CORROSIVE)(Sigma Chemical Company). 7. Add 175l of Ammonium Persulphate solution (1mg/10l) (CORROSIVE)(Sigma Chemical Company). 8. Mix thoroughly. Suck the mixture (approx. 20ml of solution) into a pipette. 9. Pour the solution into the two plates starting from one side towards the other and then back to the middle keeping the same pressure. 10. Check if any bubble is present and if so remove them. 11. Apply the top spacer (to leave the space for the comb) and insert the casting plate, tie the top clamps and leave the gel to polymerise for at least 1 hour (not more than 2-3 hours because it will dry out). 12. Wash immediately the container and the pipette to prevent acrylamide from polymerising in them. c) Prepare the gel to be loaded 1. When the gel has solidified, remove the top spacer and clean the excess polyacrylamide 2. Place the gel plates inside the DNA sequencer, insert the buffer chamber and tighten the clamps (hand tight only) 3. Pour 500ml of 1X TBE Buffer into each buffer tray. Clear the loading edge of excess polyacrylamide by flushing it with a Pasteur pipette. 4. Place the lids on each buffer tray and connect the circuit from the gel plates to the automatic sequencer. Close the cover. 5. Create a new file for the data on the hard drive of the automatic sequencer as follows. a) open the program (data collection); b) create a new directory (file, new, create), c) open / edit the configuration file as appropriate for the gel in use, d) turn on the scanner, e) click ENTER and check that the circuit is closed. 6. Pre-run the gel for 15 - 20 min. to ensure that it is adequately heated and prepared before loading the samples. d) Preparation of the samples 74 75 1. Pipette 2l of Loading Dye - Formamide ACS Reagent (TOXIC)(Sigma Chemical Company) solution into 0.5ml sterilised microcentrifuge tubes. 2. Add 1l of PCR product to each and mix by pipetting a few times. 3. Heat each tubes to 85C for 60 seconds on a PCR thermal cycler or water bath to denature the DNA (to single stranded DNA). e) Loading the gel 1. Turn the machine off and open the cover. 2. Remove the lid from the top buffer tray. 3. Insert gently a 48- or 64-well comb (depending on the number of samples) between the two plates until the tips of the comb are approx. 1mm into it. 4. Load 0.5l of PCR products-Formamide solution into each well (ie between the teeth of the comb). Also load 0.5l of a standard DNA size ladder every 10-20 wells to measure the molecular weight of the DNA fragments on the gel. 5. Replace the lid and close the cover. 6. Set the auto gain (options, auto gain, auto). 7. Focus the gel (scanner control, options, focusing, auto) (check that the curve is approx. like a normal distribution). 8. Set auto gain again. 9. Turn on voltage and laser. The auto gain and the focusing are set after the samples are loaded in case the gel plates get disturbed while loading. 75 76 8.5 Cycle Sequencing (Amersham kit) 1. Label 0.5ml microcentrifuge tubes (a) one tube labelled per plasmid-primer combination for master mix solutions detailed in (2) below (b) four tubes per plasmid-primer combination for the ddG, ddA, ddT and ddC nucleotide mixes (i.e. for (a) labels tubes 1-10, so that for (b), label 1G, 1A, 1T, 1C, 2G, 2A, etc.) 2. (a) Add 1g of plasmid DNA to each tube from step 1(a) (i.e. tubes 1-10) and add H2O to bring the total volume to 20L (b) Then add: 2.0 L primer (2M), 3.0 L DMSO, 0.5 L 5M Betaine 3. Add 2L from each of ddG, ddA, ddT and ddC mixes to appropriate tubes labelled from step 1(b). 4. Dispense 6 L of master mix from step 2 to each tube from step 3. 5. Seal the tubes, place on the PCR block and run the following program: (95C – 2.5 min.) x 1 cycle (95C – 20 sec., 56C – 20 sec., 72C – 20 sec.) x 30 cycles 6. Pre-run the sequencing gel to ensure that it has reached 50C before applying the sequencing reactions 7. On completion of the program, add 4 L formamide loading dye to each tube and heat to 850C for 1 min (i.e. on a PCR block). 8. Load 0.5-1.0L (depending on comb size) from each tube on to the gel in the LiCor 4200 automated DNA sequencer 9. (a)Run “Auto Gain” on the computer to calibrate the dynamic range of the fluorescence detection (b) Run “Focus” to ensure that the laser is focussed on the centre of the gel (c) Re-run Auto Gain to refine calibration based on the correct focus 10. Start the electrophoresis by switching the laser and voltage on. 76 77 Appendix 1. Evaluation of the relative merits of the main techniques where the evaluation is based on criteria related to the implementation of these techniques (NB! This page to be read in landscape format) Gene Type Analysis Technique Tissue Preservation Minimum Tissue Quantity DNA Quality Cost Isozymes Starch Gel -80C Medium Not applicable Low MtDNA CsCl + RFLP Fresh liver only High Very High High RE + Probing of filter -20C / 95% EtOH Medium High High Low Medium Low Low Medium High Medium High Medium Low Low - Medium Low - Medium PCR + RFLP -20C / 95% EtOH PCR + Direct Sequencing -20C / 95% EtOH Minisatellites RE + Probing of filter -20C / 95% EtOH PCR amplified -20C / 95% EtOH Microsatellites PCR amplified -20C / 95% EtOH Low Low Low - Medium Anonymous cDNA RE + Probing of filter -20C / 95% EtOH Medium High Medium - High Single Copy Sequence PCR + RFLP -20C / 95% EtOH Low Low - Medium Low Low Low - Medium High Low Low - Medium Medium PCR + Direct Sequencing -20C / 95% EtOH PCR + SSCP -20C / 95% EtOH 77 78 Appendix 2. Practical evaluation of the main techniques for differentiating betweeen species, populations and individuals (NB! This page to be read in landscape format). Gene Type Analysis Technique Phylogenetics at Species Level Population Genet Isozymes Starch Gel Fair Good but lack of p can be limiting in s CsCl + RFLP Good - but too many bands can be a problem; also very slow etc. MtDNA RE + Probing of filter PCR + RFLP Good - but too many bands can be a problem Fair (Very Slow) Fair (Very Slow) Very Good Good (if enough R available) PCR + Direct Sequencing Excellent Very Slow but new sequencing may he RE + Probing of filter Not suitable Very good PCR amplified Not suitable Very Good Microsatellites PCR amplified Not suitable Very Good Anonymous cDNA RE + Probing of filter Not suitable Good Single Copy Sequence PCR + RFLP Good Good (if enough va detected) PCR + Direct Sequencing Excellent Fair (too slow and PCR + SSCP Not suitable Potentially Good f populations Minisatellites OoooooooooooooOOOOOOOOOOooooooooooooooo 78 79 PLANT DNA MARKERS M. Heun, NLH-Ås Electronic version not available. Please refer to handouts from prof. Heun during the course. ooooooo OOOOOO oooooooo 79