value arbitrarily
advertisement

Question 1.
(1)
Agent Type
Robot soccer
player
Internet
book-shopping
agent
Performance
Measure
Winning game,
goals
for/against
Environment
Actuators
Sensors
Field, ball,
own team,
other team,
own body
Devices (e.g.,
legs) for
locomotion
and kicking
Camera, touch
sensors,
accelerometers,
orientation
sensors,
wheel/joint
encoders
Web pages,
user requests
Obtain
Internet
Follow link,
requested/
enter/submit
Interesting
data in fields,
books,
display to user
minimize
expenditure
Agent types and their PEAS descriptions
(2)
Environment properties are given in the following figure. Suitable agent types:
a. A model-based reflex agent would suffice for most aspects; for tactical play, a
utility-based agent with lookahead would be useful.
b. A goal-based agent would be appropriate for specific book requests. For more
open-ended tasks—e.g., “Find me something interesting to read”—tradeoffs are
involved and the agent must compare utilities for various possible purchases.
Task
Observable Deterministic Episodic
Static
Discrete
Agents
Environment
Robot
Partially
Stochastic
Sequential Dynamic Continuous Multi
soccer
Internet
Partially Deterministic Sequential
Static
Discrete
Single
bookshopping
Environment properties
Question 2.
a. The algorithm expands nodes in order of increasing path cost; therefore the first
goal it encounters will be the goal with the cheapest cost.
b. It will be the same as iterative deepening, d iterations, in which O(bd)nodes are
generated.
c. d/
Question 3.
A heuristic is consistent iff, for every node n and every successor n‘of n generated by
any action a,
h(n) ≤ c(n, a, n’) + h(n’)
One simple proof is by induction on the number k of nodes on the shortest path to any
goal from n. For k = 1, let n‘ be the goal node; then h(n) ≤ c(n, a, n’). For the
inductive case, assume n‘ is on the shortest path k steps from the goal and that h(n’) is
admissible by hypothesis; then
h(n) ≤ c(n, a, n’) + h(n’) ≤ c(n, a, n’) + h*(n’) = h*(n)
so h(n) at k+1steps from the goal is also admissible.
Question 4.
The exact steps depend on certain choices you are free to make.
a. Choose the X3 variable. Its domain is {0, 1}.
b. Choose the value 1 for X3. (We can’t choose 0; it wouldn’t survive forward
checking, because it would force F to be 0, and the leading digit of the sum must be
non-zero.)
c. Choose F, because it has only one remaining value.
d. Choose the value 1 for F.
e. Now X2 and X1 are tied for minimum remaining values at 2; let’s choose X2.
f. Either value survives forward checking, let’s choose 0 for X2.
g. Now X1 has the minimum remaining values.
h. Again, arbitrarily choose 0 for the value of X1.
i. The variable O must be an even number (because it is the sum of T + T less than 5
(because O + O = R +10 0). That makes it most constrained.
j. Arbitrarily choose 4 as the value of O.
k. R now has only 1 remaining value.
l. Choose the value 8 for R.
m. T now has only 1 remaining value.
n. Choose the value 7 for T.
o. U must be an even number less than 9; choose U.
p. The only value for U that survives forward checking is 6.
q. The only variable left is W.
r. The only value left for W is 3.
s. This is a solution.
This is a rather easy (under-constrained) puzzle, so it is not surprising that we arrive at
a solution with no backtracking (given that we are allowed to use forward checking).
Question 5.
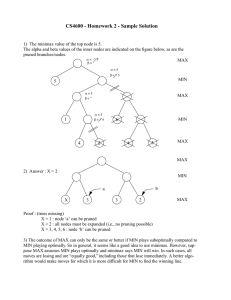
a. The game tree, complete with annotations of all minimax values, is shown in the
following figure. The “?” values are handled by assuming that an agent with a choice
between winning the game and entering a “?” state will always choose the win. That
is, min(–1,?) is –1 and max(+1,?) is +1. If all successors are “?”, the backed-up value
is “?”.
A game tree for the four-square game. Terminal states are in single boxes, loop states
in double boxes. Each state is annotated with its minimax value in a circle.
b. Standard minimax is depth-first and would go into an infinite loop. It can be fixed
by comparing the current state against the stack; and if the state is repeated, then
return a “?” value. Propagation of “?” values is handled as above. Although it works
in this case, it does not always work because it is not clear how to compare “?” with a
drawn position; nor is it clear how to handle the comparison when there are wins of
different degrees (as in backgammon). Finally, in games with chance nodes, it is
unclear how to compute the average of a number and a “?”. Note that it is not correct
to treat repeated states automatically as drawn positions; in this example, both (1,4)
and (2,4) repeat in the tree but they are won positions.
What is really happening is that each state has a well-defined but initially unknown
value. These unknown values are related by the minimax equation at the bottom of
page 163. If the game tree is acyclic, then the minimax algorithm solves these
equations by propagating from the leaves. If the game tree has cycles, then a dynamic
programming method must be used, as explained in Chapter 17. (Exercise 17.8
studies this problem in particular.) These algorithms can determine whether each node
has a well-determined value (as in this example) or is really an infinite loop in that
both players prefer to stay in the loop (or have no choice). In such a case, the rules of
the game will need to define the value (otherwise the game will never end). In chess,
for example, a state that occurs 3 times (and hence is assumed to be desirable for both
players) is a draw.