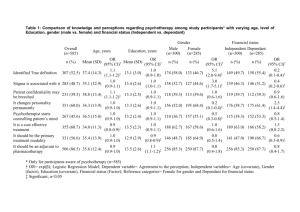
Chapter 2 Binary Data
advertisement

1 Chapter 2 Binary Data 2.1 Introduction Motivating example: Z 1 : recoverd; Z 0 : Not recoverd. x1 1 : hospital A; x1 2 : hospital B. x2 1: surgical procedure I; x2 2 : surgical procedure II. The data are: Table (a) Data subject 1 2 3 4 5 6 7 Let Covariate (1,1) (1,2) (1,2) (2,1) (2,2) (1,2) (1,1) Response 0 1 0 0 1 1 1 Z i , i 1, 2, , 7, be the response indicating whether the patients are recovered or not and let xi xi1 , xi 2 , i 1, 2, , 7, be the hospitals and surgical procedures for the patients. Suppose PZi 1 xi i , PZi 0 1 xi 1 i . Objective: We want to investigate the relationship between the response probability i and the explanatory variable xi . That is, whether the recovery of the patient is correlated to the hospital he chose or the 2 surgical procedure conducted. The original ungrouped data can be organized to the grouped data in the following table: Table (b) Covariate (1,1) (1,2) (2,1) (2,1) Class size 2 3 1 1 Response 1 2 0 1 The responses in table (b) are Yi , 0 Yi mi , i 1, 2, 3, 4; m1 2, m2 3, m3 1, m4 1. Note: 1. The table (a) can not be reconstructed from table (a) since information concerning the serial order of the subject is not known. 2. Serial order of patients is considered irrelevant when the data are grouped by covariate class. 3. An effect might be detectable as a serial trend in the analysis, but can not be detected from an analysis of the grouped data in table (b). 4. Some methods are appropriate to grouped data, particularly those involving Normal approximation. 5. For ungrouped data, only one asymptotic approximation can be developed ( N , where N is the sample size). For grouped data, two asymptotic approximations can be developed, one for that the sample size N tends to infinity and the other for that the class size m tends to infinity). 3 6. The contingency tables for the original ungrouped data are As x1 1 Y=0 Y=1 1 1 1 2 Y=0 Y=1 1 0 0 1 x2 1 x2 2 and As x1 2 x2 1 x2 2 7. Z i , i 1, 2, , 7, are distributed as Bernoulli random variable with parameter i while Yi , i 1, 2, 3, 4. are distributed as binomial random variable with parameters mi and i . 2.2 Models for binary responses (a) Modeling In practice, the formal model usually embodies assumptions such as zero correlation or independence, lack of interaction or additivity, linearity and so on. These assumptions can not be taken for granted and should, if possible, be checked. For binary data, to express as the linear combination p jxj j 1 would be inconsistent with the law of probability. A simple and effective way of avoiding this difficulty is to use a transformation g onto the whole real line , . That is, that maps the unit interval 0,1 4 p g j x j j 1 . Several functions (link functions) commonly used in practice are: 1. The logit or logistic function g 1 log . 1 2. The probit or inverse normal function g 2 1 . 3. The complementary log-log function g 3 log log 1 . 4. The log-log function g 4 log log . Note: g1 g1 1 , g 3 g 3 1 . Note: The required inverse functions are 1. The logit or logistic function e 1 . 1 e 2. The probit or inverse normal function 2 . 3. The complementary log-log function 3 1 e e . 4. The log-log function 4 e e . 5 Note: The logistic function is most commonly used link function. Note: For the data in the motivating example, suppose the logistic link function is used. Then, log 0 1 x1 2 x2 1 exp 0 1 x1 2 x2 1 exp 0 1 x1 2 x2 1 j , j 1, 2. x j The last equation implies that a larger change in change of xj as is near 0.5 than due to the is near 0 or 1. (b) Estimation Suppose Yi ~ bmi , i , i 1, 2, , n, i g log with link function i i 1 i p j xij . Note that j 1 E Yi i mi i . The likelihood function is mi yi m y f | y i 1 i i i i 1 yi n and the log-likelihood function is 6 n l log f | y li i 1 m log i yi log i mi yi log 1 i i 1 yi n n mi i yi log m log 1 log i i i 1 1 i yi i 1 n Thus, n y mi i l n li i i U r i i 1 i xir r 1 i 1 i 1 i i r i i n yi mi i xir i 1 since 1 i mi 2 1 i 1 i 1 i 1 i mi 1 yi 2 1i i 1 i yi mi i 1 i 1 i 1 i li yi i i yi mi i i 1 i and i 1 1 1 i i 1 i 1 i log i i 1 i i 1 i 1 i 2 i 1 i 1 i 1 i 1 2 i 1 i 7 On the other hand, n n yi mi i xir i 2l mi xir s r i 1 s s i 1 n i i mi xir mi i 1 i xis xir i s i 1 i 1 n Therefore, n 2 l 2 l I sr E mi i 1 i xis xir i 1 s r s r Denote x1 p 1 m1 1 m x2 p , 2 2 2 , xnp m n n n 0 0 m2 2 1 2 0 0 mn n 1 n x11 x12 x x22 21 X xn1 xn 2 m1 1 1 1 0 W 0 Then, in matrix form, U X t y , I X tW X The Fisher’s scoring method is X W ˆ Xˆ X W ˆ z ˆ X W ˆ X X W ˆ z I ˆt ˆt 1 I ˆt ˆt U ˆt , t 0, 1, 2, X tW ˆt Xˆt 1 X tW ˆt Xˆt X t y ˆt X tW ˆ Xˆ X tW ˆ Xˆ W 1 ˆ y ˆ t t 1 t t 1 t t 1 where t t t t 1 t t t t t t t t 8 z t1 z z t t 2 Xˆ t W 1 ˆ t y ˆ t z tn and yi i ˆ zti xij tj . m 1 j 1 i ˆt i i p Note: A good choice of starting value usually reduced the number of cycles by about one or perhaps two. Note: After a few cycles of the weighted estimating equation, the fitted mi i ˆ values t are normally quite accurate but the parameter estimates and their standard error may not be. There are two criteria tested to detect abnormal convergence of this type. The primary criterion is based on the change in the fitted probabilities, for instance by using the deviance. The other is based on the change in ˆt or in the linear predictor xi ̂ t . Note: Let 0 m1 1 1 1 0 m2 2 1 2 W W ˆ 0 0 1 ˆ E On 0 mn n 1 n ˆ 0 9 Cov ˆ X tWX 1 On 1 1 Note: The above results are also true for the alternative limit in which n is fixed and m . Chapter 3 Log-linear Models 3.1 Introduction Motivating example: Ship type Year of construction Period of operation 1960-74 1975-79 1960-74 1975-79 1960-74 1975-79 1960-74 1975-79 Aggregate months service 127 63 1095 1095 1512 3353 0 2244 Number of damage incidents 0 0 3 4 6 18 A A A A A A A A 1960-64 1960-64 1965-69 1965-69 1970-74 1970-74 1975-79 1975-79 E E E E E E E E 1960-64 1960-64 1965-69 1965-69 1970-74 1970-74 1975-79 1975-79 1960-74 1975-79 1960-74 1975-79 1960-74 1975-79 1960-74 1975-79 45 0 789 437 1157 2161 0 542 0 Response: the number of damage incidents, yi , i 1, 2, ,40. 0 11 0 7 7 5 12 0 1 10 Covariates: Ship type: A-E. Year of construction: 1960-64, 1965-69, 1970-74, 1975-79. Period of operation: 1960-74, 1975-79. In addition, it is reasonable to suppose that the number of damage incidents is directly proportional to the other variable, the aggregate month service or total period of risk. Objective: W are concerned with the effects of the above factors (covariates) on the risk of damage. That is, the relationship between the number of damage incidents and these factors. A natural model is as follows: Log(expected number of damage incidents) = 0 + log(aggregate months service) + (effect due to ship type) + (effect due to year of construction) + (effect due to service period). Note: It is quite reasonable to assume the number of damage incident is Poisson distributed. Thus, the above model is associated with canonical link for Poisson data. In this chapter, we are concerned mainly with counted data not in the form of proportions. Typical examples involve counts of events in a Poisson or Poisson-like process, where the upper limit to the number is infinite or effectively so. However, departures from the idealized Poisson model are to be expected, for example, over-dispersion. Therefore, we avoid the assumption of Poisson variation and assume only that Var Yi 2 E Yi . 11 The dependence of to be i E Yi on the covariate log i i xi xi is assumed . The term log-linear models are referred to the above log-linear relationship. 3.2 Likelihood Functions The Poisson log-likelihood function for Y1 , Y2 ,, Yn is n l 1 , 2 ,, n yi log i i , i 1 where E Yi i . The deviance function is D y1 , , yn , ˆ1 , , ˆ n 2l y1 , , yn 2ˆ1 , , ˆ n y 2 yi log i yi ˆ i i 1 ˆ i n n yi 2 yi log 2 yi ˆ i i 1 i 1 ˆ i n where ̂ i E Yi i is the estimate of Note: If a constant term is included in the model, it can be shown that n y i 1 i ˆ i 0 . 12 Thus, the deviance function can be reduced to yi D y1 , , yn , ˆ1 , , ˆ n 2 yi log . i 1 ˆ i n