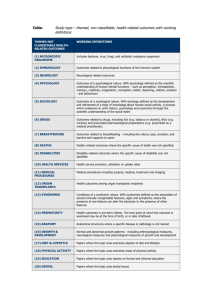
Pattern Analysis: Concatenated Observations
advertisement

OOM Software Manual
Contents
Introduction………………………………………… 3
Define Ordered Observations……………………… 6
Ordered Observations List Options……… 11
Auto Generate Options………………….. 13
Instructions/Distribution………………… 16
Build / Test Model…………………………………. 18
Observation Oriented Modeling
Software Manual
Overview and Initial Example………….. 18
Build Models……………………………. 22
Options………………………………….. 23
Randomization Test…………………….. 32
Output…………………………………... 34
Frequency or Proportional Models……... 41
Pairwise Rotation…………………………….……. 45
Options…………………………………. 46
James W. Grice, Ph.D.
Oklahoma State University
Version 2
Software Release Date: November 12th, 2013
Updated: August 13th, 2015
Copyright © 2015
Matching Analysis………………………................ 51
Options………………………………….. 52
Descriptive Statistics………………………………. 56
Pattern Analysis: Crossed Orderings…………… 58
Options………………………………….. 65
Randomization Test…………………….. 66
Output…………………………………... 67
Pattern Analysis: Concatenated Orderings……..
69
Options………………………………….. 79
Randomization Test…………………….. 84
Output…………………………………... 85
Ordinal Analysis: Crossed Orderings……………… 86
Options………………………………….. 89
Randomization Test……………………. 91
Output…………………………………... 93
Ordinal Analysis: Concatenated Orderings………… 98
Options………………………………….. 108
Randomization Test…………………….. 113
1
OOM Software Manual
Output…………………………………... 115
Efficient Cause Analysis…………………………… 118
Options………………………………….. 127
Randomization Test…………………….. 133
Output…………………………………... 135
Logical Ordered Observations…………………….. 136
Operators……………………………….. 140
Combine Units of Observations…………………… 142
Create Combination Orderings……………………. 145
Ordering/Case Combinations………….. 145
Group Combinations …………………... 147
2
OOM Software Manual
1
3
Introduction
The purpose of this manual is to provide a brief
overview of the different features and analysis routines in the
Observation Oriented Modeling (OOM) software. In this
regard it is meant to introduce the reader to various options in
the software and to explain the output generated by these
options. It also explains in plain language the logic of different
analyses and the computations involved in generating different
output. This manual is not meant to serve as a guide for
building and testing integrated models nor is it meant to offer a
complete guide for interpreting results generated by the
different analyses. Still, careful study of this guide, along with
viewing the instructional videos at http://www.idiogrid.com/OOM,
should give the user a high level of comfort and confidence
when using the OOM software.
The reader is encouraged to work through the examples
included in this manual and in the videos. The data sets are
included in the installation of the OOM software. Moreover,
the reader is encouraged to experiment with his or her own data
or with data constructed to have certain properties. Working
with non-genuine or simulated observations is a good way to
test the reader’s understanding of the software as well as the
software’s capabilities. For example, the reader could generate
pairs of ordered observations with a non-linear pattern of
relationship and examine how the binary Procrustes rotation
recovers the relationship.
The OOM software is constructed in a standard
Windows format with a parent window and three child
windows nested within: the Data Edit, Text Output, and
Graphics Output windows. These windows are layered in
Figure 1.1, and a Main Menu can also be seen across the top of
the parent window. The Data Edit window is currently active,
or visible, in Figure 1.1.
Figure 1.1 OOM Parent and Child Windows
OOM Software Manual
As a quick run through the program and an analysis,
consider the following observations regarding smoking and
lung cancer:
person
person
person
person
person
person
person
person
person
person
1
2
3
4
5
6
7
8
9
10
smoking
No
No
No
No
No
Yes
Yes
Yes
Yes
Yes
Figure 1.2 Data Edit Window (snipped)
cancer
No
No
No
No
Yes
No
No
Yes
Yes
Yes
File: SmokingCancerExample.oom
In OOM all observations must be represented with a number
that can be entered into the Data Edit window. Clearly,
observing whether or not a person smokes cigarettes or has
developed lung cancer does not require the conceptualization
of continuously structured quantitative qualities. The reliance
on numbers for all ordered observations should not therefore be
interpreted as assuming continuous quantitative structure in
OOM; but instead, should be viewed as a clerical necessity in
the software. For this example, 0 is used to represent “no” and
1 is used to represent “yes.” The observations as entered in the
Data Edit window are shown in Figure 1.2. As can be seen, the
ten persons form the rows of the observation matrix, and the
two orderings form the columns. Zeros and ones are entered
into the matrix to represent the observations.
The units of observations must next be defined. This is
done in the Define Ordered Observations window which can be
opened by selecting Edit: Define Ordered Observations from
Figure 1.3 Define Ordered Observations Window
4
OOM Software Manual
the Main Menu or by selecting the corresponding button from
the toolbar (see Figure 1.1). Pausing the mouse over the
buttons on the toolbar will briefly display their labels. Figure
1.3 shows the window with the smoking units of observation
defined as:
Figure 1.4 Build / Test Model Window
{0} No
{1} Yes
The Cancer ordered observations are defined in the same way,
and it should be pointed out that defining the units of
observations correctly is critical in OOM. An entire chapter
(Chapter 2) is therefore devoted to the Define Ordered
Observations window.
Now that units of observation have been defined,
analyses may be conducted. The standard analysis window in
OOM is the Build / Test Model window listed under the
Analysis Main Menu option. Figure 1.4 shows the window with
the following expression being tested,
Smoking Cancer.
Selecting the [OK] button to run the analysis sends the text
portion of the results to the Text Output window and the
graphics portion of the analysis to the Graphics Output window.
Figure 1.5 shows the multigram generated from the analysis as
it appears in the Graphics Output window.
Figure 1.5 Graphics Output Window with Multigram
5
OOM Software Manual
2 Define Ordered Observations
Perhaps the most important window in OOM is the
Define Ordered Observations window shown in Figure 2.1. It
is in this window the user defines the units of observation that
are the basis for the deep structures utilized by most of OOM’s
procedures. Unlike other statistical programs, defining and
labeling the units of observation is not simply a matter of
convenience; rather, it is a necessity.
It can be seen that the window is separated into two
sub-windows: the Ordered Observations list and Unit
Definitions. The list of ordered observations is used to name
the different orderings, define the numeric value that indicates
missing observations, and set the decimal precision for which
values are displayed in the Data Edit window. Several other
options (viz., Min, Max, and Units) may be used in the process
of defining units of observation. The unit definition subwindow is where the units of observation are actually defined
and labeled, and several options are available to simplify this
process. Because of the importance of defining the units of
observation in OOM, the unit definitions sub-window also
contains an edit box that reports simple instructions on how to
define the units. These instructions can also be toggled to show
a distribution (i.e., frequency histogram) of the observations as
they are being defined. The distribution is important for
insuring that all of the observations have been properly defined.
As with most of the chapters in this technical manual,
the most expedient route for explaining the Define Ordered
Observation window is via example. Consequently, we will
consider 10 observations ordered according to 2 units of
6
Figure 2.1 Define Ordered Observations Window
Gender (Male/Female), 3 units of a subjective Rating of the U.
S. President’s foreign policy (Disapprove, Neither Approve nor
Disapprove, Approve), and 11 units of body (Temperature
(98.0 to 99.0 with a single decimal of precision):
person_1
person_2
person_3
person_4
person_5
person_6
person_7
person_8
person_9
person_10
Gender
Male
Male
Male
Male
Male
Female
Female
Female
Female
Female
Rating
Approve
Disapprove
Disapprove
Disapprove
Neither
Approve
Approve
Neither
Approve
Approve
Temp
98.9
98.6
98.9
98.1
98.4
98.7
98.5
98.6
98.6
98.9
OOM Software Manual
Clearly, the Gender observations are made through a discrete
judgment of determining if a person is male or female.
Nonetheless, in OOM numbers must be used to represent the
units of observation. Given the nature of Gender, the choice of
numbers to represent the observations is completely arbitrary;
for example, 0 could just as easily be used as 100 or 70 to
indicate a male. For the present purposes, 1 will be used to
indicate a male and 2 will be used to indicate a female. The
Rating observations are similarly discrete countable units and
can be indicated by any numbers. Here, -1, 0, and 1 will be
used to indicate the Disapprove, Neither, and Approve
observations, respectively. The negative to positive values will
serve a nice reminder of the apparent valence of the rating
judgments (negative to positive). Lastly, body temperature is
known as a continuous quantity and the values shown above
can be entered “as is” in the OOM software and defined
accordingly. The observations as they are entered into the Data
Edit window thus appear as follows:
person_1
person_2
person_3
person_4
person_5
person_6
person_7
person_8
person_9
person_10
Gender
1
1
1
1
1
2
2
2
2
2
Rating
1
-1
-1
-1
0
1
1
0
1
1
Temp
98.9
98.6
98.9
98.1
98.4
98.7
98.5
98.6
98.6
98.9
File: DefineObservationsExample.oom
Turning now to the Define Ordered Observations
window, Figure 2.2 shows the window as it will appear when
7
all of the units of observation have been defined, when the
Gender ordering has been selected, and the distribution has
been toggled on.
Figure 2.2 Define Ordered Observations Window, Gender Defined
It can be seen that the following text appears in the Unit
Definitions edit window:
{1} Male
{2} Female
This text defines the units of observations, NOT the Min and
Max values in the observation list. The Min and Max values are
only used in the Auto Generate options described below. It is
the text in the Unit Definitions window that defines the
OOM Software Manual
observations upon which deep structure data matrices are
constructed in OOM. The text “{1} Male” shows that the
number 1 will be used to indicate a male. The brackets
therefore enclose the number or numbers used to indicate a
particular unit of observation, and the label appears to the right
of the brackets. Similarly, the text “{2} Female” shows that
the number 2 is defined and labeled as the indicator for a
female.
The frequency distribution on the right side of Figure
2.2 shows that all 10 observations have been successfully
defined as males or females. There are 5 males and 5 females
in the data set. The text,
Male : [ 5]*****
Female : [ 5]*****
Total Number of Observations
Number of Missing Observations
Number of Units
: 10
: 0
: 2
Observations to Categorize
Categorized Observations
Uncategorized Observations
: 10
: 10
: 0
informs the user that all 10 of the observations have been
accounted for in the definitions. If, for instance, the user were
to mistakenly type the following text as the unit definitions,
{1} Male
{3} Female
then the following would appear in the distribution window:
8
Male : [ 5]*****
Female : [ 0]
Total Number of Observations
Number of Missing Observations
Number of Units
: 10
: 0
: 2
Observations to Categorize
Categorized Observations
Uncategorized Observations
: 10
: 5
: 5
Clearly, the 5 females in the data set have not been accounted
for in the definitions. Their values were entered as 2’s and here
miss-defined as 3’s. As mentioned above, it is in this way the
distribution (frequency histogram) plays an important role in
insuring the user has defined all of the units of observation
properly.
Figure 2.3 shows a close-up of the ordered observations
list in Figure 2.2. The Label for each ordering is determined
and entered by the user and can be of any width and can
include any characters. If the list of ordered observations is
lengthy, they can be entered or changed in an edit box by
selecting the [Edit Labels] button below the list (see Figure
2.2). Lists of labels can also quickly be copied from other
programs (e.g., word processing, spreadsheet, or statistics
programs) using the [Edit Labels] option.
Figure 2.3
Ordered
Observations
List
OOM Software Manual
It can also be seen in Figure 2.3 that the Min, Max, and
Units values for Gender are 1, 2, and 1, respectively. These
values have no direct bearing on the actual unit definitions of
the Gender ordered observations. They can be used, however,
as aids in the automatic generation of units of observations.
Specifically, these values can first be set and then the [Single]
button in the Auto Generate section of Figure 2.2 can be
selected to automatically generate the units of observation with
number labels based on the Prefix setting (in this case,
“Unit=”). Doing so for Gender would yield the following
default, automatically generated units of observation:
{1} Unit=1
{2} Unit=2
The [Single] automatic routine begins by creating a unit of
observation from the Min value and labels it with the value
affixed to the Prefix, in this case “Unit=1.” The routine then
increments by one unit as defined in Units, in this case 1 and
generates a second unit of observation with the label “Unit=2.”
This process is incrementally repeated until the Max value is
reached in the unit-generation process. For Gender, the process
begins with 1 and increments by 1 to 2 at which point it stops,
generating the text shown above.
While this process is convenient for generating units for
orderings with numerous units of observation, in this example
the number of units is only 2; moreover, the labels “Unit=1”
and “Unit=2” are clearly not informative, so they can easily be
edited to read “Male” and “Female” as originally shown above.
To reiterate, the purpose of the Min, Max, and Units
values in the ordered observations list is to assist with the
automatic generation of the units of observation in the Unit
9
Definitions sub-window. The text in the Unit Definitions subwindow overrides these values. In other words, given the text
in Figure 2.2; namely,
{1} Male
{2} Female,
the Min, Max, and Units values have no direct relevance to the
ordered observations.
The Missing and Decimals settings for each ordering of
observations, by contrast, do impact different analyses and
features in OOM. The Missing setting assigns a particular
number to be the missing value for the selected ordering. As
can be seen in Figure 2.3, all three orderings are set with -99 as
the missing value. Consequently, in all of the analyses in OOM
for these observations, any entered value of -99 will be treated
as missing. OOM also utilizes a system-wide missing value
that can be set by selecting Options: Set System Missing Value
from the Main Menu. The default value is -99999, and the
system missing value is used to replace illegitimate values (e.g.,
when attempting to divide by zero) that might be generated
during different analyses. The Decimals setting in Figure 2.3
indicates the number of decimals that will be displayed in the
Data Edit window for the ordered observations. In this instance
the Gender and Rating ordered observations are whole numbers
(Decimals = 0), and Temp is observed to a tenth of a degree of
precision (Decimals = 1).
The Rating ordered observations are defined in the Unit
Definitions edit window as,
{-1} Disapprove
{0} Neither
{1} Approve
OOM Software Manual
and the distribution shows that all 10 people have been
accounted for in the definitions, with 3, 2, and 5 people
observed in the disapprove, neither, and approve units,
respectively;
Disapprove : [ 3]***
Neither : [ 2]**
Approve : [ 5]*****
Total Number of Observations
Number of Missing Observations
Number of Units
: 10
: 0
: 3
Observations to Categorize
Categorized Observations
Uncategorized Observations
: 10
: 10
: 0
It is instructive to walk through the process of defining
the Temp units of observations. Body temperature is a
continuously structured quantity in nature that can be measured
using highly precise methods. Here, the observations are
recorded to 1/10th of a degree, Fahrenheit. While OOM’s
strength is with discrete countable qualities, or qualities that
can be predicated as more or less, truly continuous qualities
can also be analyzed. To define the temperatures for the current
10 people, the observations are first examined for minimum
and maximum values. The values fall between the convenient
range 98.0 to 99.0 degrees Fahrenheit. The Min and Max
values are therefore set to these numbers (see Figure 2.3). The
Units option is then set to 0.1 to indicate the precision for the
units of observation. Next, the Prefix edit box is edited to be
blank, and finally the [Single] button is selected, generating the
definitions:
{98.0}
{98.1}
{98.2}
{98.3}
{98.4}
{98.5}
{98.6}
{98.7}
{98.8}
{98.9}
{99.0}
10
98.0
98.1
98.2
98.3
98.4
98.5
98.6
98.7
98.8
98.9
99.0
As mentioned above, the [Single] button counts from the Min
to the Max value in increments indicated by Units. Each
counted unit of observation is labeled with the value without a
prefix attached. The distribution appears as follows:
98.0
98.1
98.2
98.3
98.4
98.5
98.6
98.7
98.8
98.9
99.0
:
:
:
:
:
:
:
:
:
:
:
[
[
[
[
[
[
[
[
[
[
[
0]
1]*
0]
0]
1]*
1]*
3]***
1]*
0]
3]***
0]
Total Number of Observations
Number of Missing Observations
Observations to Categorize
Number of Units
:
:
:
:
10
0
10
11
Categorized Observations
Uncategorized Observations
: 10
: 0
A number of units are empty, and 4 units record only one
observation. As an important general rule, two or more
observations should be recorded per unit, so in this instance
more observations should be made (viz., more people should
OOM Software Manual
be included in the study), or the observations should be
grouped into less precise units (e.g., 98.0 – 98.5, 98.6 – 99.0).
One way of grouping units of observation is by use of
the [Range] auto generate button. With the same settings for
Temp shown in Figure 2.3 the [Range] button will generate
each unit of observation as a range of values determined by the
Units setting. As can be seen in the following definitions, the
range feature begins with the Min value as the lower bound for
a range of values spanning a width of observations determined
by Units; here, 98.0 to 98.1:
{98.0:
{98.2:
{98.4:
{98.6:
{98.8:
{99.0:
98.1}
98.3}
98.5}
98.7}
98.9}
99.1}
98.0:
98.2:
98.4:
98.6:
98.8:
99.0:
98.1
98.3
98.5
98.7
98.9
99.1
98.1
98.3
98.5
98.7
98.9
99.1
:
:
:
:
:
:
[
[
[
[
[
[
1]*
0]
2]**
4]****
3]***
0]
Total Number of Observations
Number of Missing Observations
Number of Units
: 10
: 10
: 0
With the units of observation now defined as ranges, only one
populated unit records 1 observation. The other units record 2
or more observations, and 2 units are still empty. Because there
are fewer units with only 1 observation, these definitions would
be more suitable for the current observations gathered from 10
people.
Ordered Observations List Options
The next unit of observation begins with the next highest value
and again creates a range of values according to Units; here,
98.2 to 98.3. The process is iterated until a final unit of
observation is created that includes the Max value. Based on
these new units of observations as small ranges, the distribution
now appears as follows:
98.0:
98.2:
98.4:
98.6:
98.8:
99.0:
Observations to Categorize
Categorized Observations
Uncategorized Observations
11
: 10
: 0
: 6
[Edit Labels]
For the current example, the Gender, Rating, and Temp
labels can be entered individually in their respective rows in
the ordered observations list (see Figure 2.3). Alternatively,
they can be entered in an edit window that opens when the
[Edit Labels] button is selected. The window is shown in
Figure 2.4, and it can be seen that each label is entered on its
own line. The labels can be edited here and they can be copied
to and pasted from other programs. Recall in Windows that
“ctrl c” copies selected text from any edit box, and “ctrl v”
pastes the copied text. This Edit Labels window is particularly
useful when a large number of labels need to be entered or
copied from another program; for example, when labeling 100
items from a personality questionnaire.
OOM Software Manual
Figure 2.4
Edit Labels
Window
[Copy Information]
Imagine a personality questionnaire with 100 items. A
person responds to each self-descriptive item using a 7-point
rating scale anchored by “disagree strongly” and “agree
strongly.” Obviously, entering the unit definitions for the 100
items will be time-consuming and tedious. The [Copy
Information] option alleviates most of this work and provides
the tools for quickly generating the unit definitions for all 100
items. The process begins with defining the unit definitions for
the first of the 100 items, labeled as “Item 1”, as shown in
Figure 2.5.
12
Figure 2.5 Ordered Observations Window, First Item Defined
It can be seen that the Min, Max, etc. values have all been set,
and the unit definitions have been edited as:
{1}
{2}
{3}
{4}
{5}
{6}
{7}
Disagree Strongly
R2
R3
R4
R5
R6
Agree Strongly
It can also be seen that the other 99 items (ord_5 to ord_103)
have not yet been defined and are set to the default values. The
next step is to select the [Copy Information] button, which
OOM Software Manual
13
opens the window shown in Figure 2.6, and change the options
as shown. It can be seen in the figure that “Item 1” has been
moved to the “Copy From:” edit box and that the remaining
items, labeled “ord_5” to “ord_103”, have been moved into the
“Copy To:” edit box.
above will also be copied. As stated numerous times above, it
is these definitions that are most important because they
determine the deep structure of the observations. With the click
of the [OK] button, the unit definitions for all 99 items will be
completely and instantly set up!
Figure 2.6
Copy
Information
Window
Auto Generate Options
The Auto Generate options are used to quickly generate
and manipulate the unit definitions appearing in the edit box
(see Figure 2.1). The [Single] and [Range] buttons utilize the
Min, Max, and Units values in the Ordered Observations list, so
these values must be set prior to using these options.
Prefix
The Prefix is the text label applied to each unit of
observation when the [Single] or [Range] buttons are pressed.
For instance, if the prefix is “Gender_”, then the labels for
Gender would appear as,
{1} Gender_1
{2} Gender_2
when the [Single] auto generate button is selected. Any text
can be entered into the edit box as the prefix.
Under Information to Copy everything has been selected, and
the Label Prefix has been set to “Item” starting with “2”; thus
the label for “ord_5” will be changed to “Item 2”, “ord_6” will
be changed to “Item 3”, etc. It can be seen that the Min, Max,
etc. values will all be copied from the first defined item to the
remaining items, and that the observation definitions shown
Include Proportions
This option includes proportions in square brackets
after the numerical portion of each unit definition. These
proportions are not necessary when defining observations, but
they are used in some models in OOM. For instance, with this
OOM Software Manual
option selected, “Gender_” as the prefix, and selecting the
[Single] auto generate button for Gender, the following unit
definitions are generated:
{1}[0.50] Gender_1
{2}[0.50] Gender_2
The “[0.50]” represents an expected proportion that may be
used in model testing. The value, .50, is determined by the
number of units, in this case 2, so that the proportions sum to
1.0. If three units were generated, then the proportions would
all equal .33, and if four units were generated, then the
proportions would all equal 0.25. The user can manipulate
these proportions after they have been generated, but any such
changes should still restrict their sum to be equal to 1.0; for
example,
{1}[0.75] Gender_1
{2}[0.25] Gender_2
Here, “Gender_1”, males, are expected to outnumber
“Gender_2” by a margin of 3-to-1. Examining proportions of
units of observations is similar to the binomial and chi-square
goodness-of-fit tests in the traditional Pearsonian-Fisherian
approach. How accurate are the above proportions in
comparison to the actual proportions of males and females?
This question can be answered by testing the following
expression in the Build / Test Model window,
Gender Gender.
With the current example (DefineObservationsExample.oom
data set) 50% of the persons are observed as males, and
consequently the expected proportions of .75 and .25 are not
14
accurate representations of the actual observations. Additional
example models employing proportions are presented at the
end of Chapter 3 (see Frequency or Proportional Models).
[Single]
As described above the single button uses the Min, Max,
Units and Prefix settings to generate the units of observation.
The units will range from Min to Max, incrementing by a value
equal to Units. The label for each unit of observation will be
the Prefix followed by the number used to designate the unit of
observation. This option is best for observations with a small
number of units. If a large number of units is defined by the
settings (e.g., > 1000 units), then a message will appear before
the units are created. This message will ask the user to confirm
the creation of the large numbers of units, because such
observations will likely be unwieldy in the OOM software and
may cause it to freeze or crash for certain analyses.
[Range]
Also as described above the range button uses the Min,
Max, Units and Prefix settings to generate the units of
observation. The units will range from Min to Max, but for this
option each unit will be comprised of a range of values whose
difference is equal to Units. The label for each range unit will
be the Prefix followed by the numbers used to designate the
range of observations. This option is best for observations that
are considered to represent a quality that is a continuously
structured quantity or for observations with a large number of
units that need to be reduced to a smaller, more manageable
number. This option can also be used to group units with only
one observation into units with at least two observations. As a
OOM Software Manual
15
general suggestion in OOM, at least 2 observations should be
recorded for each unit. This is not a mathematical or statistical
requirement, but a conceptual suggestion based on the idea that
a researcher would wish to make a minimum of two
observations for any unit while attempting to evaluate a model.
Of course, more observations than 2 would be desirable.
This option is available largely for organizational or even
aesthetic reasons. For instance, in the Pattern Analysis /
Crossed Observations option switching the order for the ratings
produces the two patterns shown in Figures 2.7 and 2.8, and the
user may find one pattern easier to work with than the other for
some esoteric reason.
[Delete Empty Units]
Selecting this button will delete any unit for which no
observations have been recorded. Because most of the analyses
in OOM are not predicated on assuming continuous
quantitative structure, the deletion of empty units will not
impact the results. Deleting empty units can, however, greatly
facilitate the interpretation of complex output or graphs. The
size of a multigram with numerous empty units, for instance,
can be greatly reduced to fit on a computer screen or single
sheet of paper for ease of interpretation.
Figure 2.7
Crossed
Pattern
for First
Order
[Reverse Units]
Selecting this button simply reverses the order of the
unit definitions as they appear in the edit window. For instance,
the Rating units were defined above as,
{-1} Disapprove
{0} Neither
{1} Approve
Selecting the [Reverse Units] button changes the definitions to,
{1} Approve
{0} Neither
{-1} Disapprove
Figure 2.8
Crossed
Pattern
for Reversed
Order
OOM Software Manual
[Undo]
This option will undo the most recent change made to
the unit definitions in the edit window. It is not active until a
change is made, at which point it will become active. Only the
single most recent change can be undone.
Instructions / Distribution
The instructions/distribution edit box in the Define
Ordered Observations window (see Figure 2.1) serves two
functions. First, it presents a brief set of instructions on how to
define the units of observations both manually and by using the
auto generate options. These instructions are included in this
particular window given its centrality to OOM. Second, it can
be used to examine the distribution of observations across the
various units, thus permitting the user to examine the impact of
the unit definitions and to insure that all of the observations are
accounted for in the definitions.
Each * = x Observations
The value for x can be changed to modify the
appearance of the distribution. The default value is 1, therefore
each asterisk in the frequency distribution (histogram) is equal
to one observation. For example, the distribution for Gender is,
Male : [ 5]*****
Female : [ 5]*****
16
and each asterisk represents one observation, with five in each
unit. Changing x to 2 for this option, yields the following
distribution,
Male : [ 5]**
Female : [ 5]**
As can be seen, the width of the histogram is reduced, and each
asterisk now represents 2 observations. No special symbol is
added to the histogram to indicate a single observation; rather,
the actual number of observations for each unit is listed in
square brackets ([5], note how the asterisks indicate only 4
observations per unit). Setting the value of x to a higher
number will thus be useful for very large data sets with large
numbers of observations in at least some of the units. This
option permits the user to shorten the histogram so that it does
not extend too far off of the screen.
[Instructions / Distribution]
Selecting this button toggles the instructions in the edit
box and the distribution.
[Uncategorized]
This button provides a list of the observations that are
not included in the defined units of observation. Such a list will
help to identify errors in the definitions. For the observations
above, for example, imagine if Gender were defined as,
{1} Male
{3} Female
OOM Software Manual
but the value 2 was still used to denote a female unit of
observation in the Data Edit window. In this instance, selecting
the [Uncategorized] button will list the following observations:
Uncategorized Observations:
person_6
Value = 2
person_7
Value = 2
person_8
Value = 2
person_9
Value = 2
person_10 Value = 2
Each of the five observations, person_6, person_7, etc. is listed
along with its value from the Data Edit window. Here the
definitional error is made obvious since the female units of
observation were defined as 3 rather than 2. Missing values
will also be included in the uncategorized list with their
numeric value (e.g., -99).
[Update]
Selecting this button will update the distribution in the
edit window after changes are made to the unit definitions.
With many changes, however, the distribution will
automatically be updated. Toggling back and forth between the
instructions and the distribution will also update the
distribution.
17
OOM Software Manual
3
Build / Test Model
Overview and Initial Example
The Build / Test Model option is the tool originally
programmed into the OOM software for building and testing
expressions derived from integrated models. Additional tools
have since been added, which are described in chapters to
follow. This option uses binary Procrustes rotation, and in brief,
it attempts to conform the deep structure units of one set of
observations to the deep structure units of a second set of
observations. The two sets of observations are referred to as the
conforming and target observations, respectively. Consider the
following ordered observations of 18 different people:
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
case_13
case_14
case_15
case_16
case_17
case_18
Condition
1
1
1
1
1
1
1
1
1
2
2
2
2
2
2
2
2
2
Items
7
8
5
7
8
7
9
6
7
5
6
4
5
7
6
4
5
5
File: BuildModelExample_1.oom
18
The first column of observations represents the conditions from
a randomized controlled experiment in which participants
listened to recordings of Beethoven’s 9th symphony (Condition
= 1) or static (Condition = 2) while attempting to hold in
memory as many words as possible from a list of 10 words
provided by the researcher. The Items observations indicates
the number of words successfully held in memory.
Ideally, we would work from an integrated model that
might lead us to expect the number of items recalled by the
participants who listened to Beethoven to exceed the number of
items recalled by the participants listening to static. The model
might even predict an exact number of items for each group.
Without such a model, however, we can more generically ask if
the Items observations can be brought into conformity with the
Condition observations. In other words, can the conforming
observations (Items) be brought into conformity with the target
observations (Condition)? This question does not require that
a particular function (e.g., a linear or curvilinear function) be
posited to relate the two sets of observations; rather, the binary
Procrustes rotation algorithm will simply rotate the Items units
of observations to maximum conformity with the Condition
units of observation. The analysis is conducted by selecting the
Build / Test Model option from the Analyses menu option of
the Main Menu of the OOM software.
Figure 3.1 shows the Build / Test Model window and
the chosen options for an initial analysis of the following
expression in the Models edit box:
Condition Items
The operator connects the two sets of observations and
represents how they are causally ordered in the integrated
OOM Software Manual
model. The Condition observations are considered as the cause
and the Items observations are considered as the effect.
Figure 3.1
Build/Test
Model
In the language of OOM the Condition represents the target
observations and Items represents the conforming observations.
The analysis proceeds by attempting to conform the
observations on the right side of the operator to those on the
left side of the operator. Figure 3.1 shows that the
Randomization Test, Multigram and Ordering Summaries
options are chosen for this initial analysis. The Number of
Trials for the randomization test is set to 1000. There is likely
no common agreement among statisticians on the number of
trials that should be conducted for such a test, but 1000 is a
reasonable number. For those with little experience with OOM,
19
it is recommended to first set a small number (e.g., 100) simply
to gauge the amount of time involved in conducting the
randomization test. A higher number of trials can later be set to
obtain a better estimate of the c-value (see below). Large data
sets with large numbers of units of observations may require a
great deal of time to complete 1000 or more trials.
Figure 3.2 shows the output from the analysis with
annotation (in red print), and the results indicate the rotation
classified 83% (15 of 18) of the observations correctly. How
did the analysis arrive at this result? To answer this question,
let’s begin with the deep structure of the target observations
(Condition) :
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
Clearly, the target observations are comprised of two units. The
conforming observations, by comparison, are comprised of 11
units indicating that the participants could correctly recall 0, 1,
2, 3…10 words. The deep structure for the 18 conforming
observations is therefore:
OOM Software Manual
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
1
0
0
0
0
1
0
0
0
0
0
0
1
0
0
1
0
0
0
1
1
0
0
0
0
0
0
0
1
0
0
1
0
0
0
1
0
0
0
1
0
0
1
0
1
0
0
1
0
0
0
0
1
0
0
0
0
0
1
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
The analysis worked by transforming the 11-unit deep structure
of the conforming observations into the 2-unit deep structure of
the target observations, yielding a set of classified observations
with the following deep structure:
1
1
0
1
1
1
1
0
1
0
0
0
0
1
0
0
0
0
0
0
1
0
0
0
0
1
0
1
1
1
1
0
1
1
1
1
20
The analysis then compared the classified observations to the
original target observations (see above) and tallied the number
of matches. In this example 15 of the 18 observations matched,
yielding the 83.33% Percent Correct Classification (PCC)
index. Comparing the classified and target observations, it can
be seen that observations 3 and 8 were originally observed to
belong to the Beethoven group but, on the basis of their items
recalled, were classified to belong to the static group.
Observation 14 originally belonged to the Static group, but was
classified as belonging to the Beethoven group. All other
observations were correctly classified; therefore, the overall
pattern of Items observations could be accurately transformed
to the pattern of Condition observations.
The randomization test works by randomizing the deep
structure rows of only the conforming observations (Items).
This has the effect of randomly pairing the conforming
observations with the target observations. The Procrustes
rotation is then applied to these random pairings and the PCC
index computed. This process is repeated 1000 times, as
chosen in the options, and the number of PCC values equaling
or exceeding 83.33% (the PCC index for the actual
observations) is tallied and converted to a proportion: 82 / 1000
for this example, or .082, the c-value.
The red frequency bars in the multigram in Figure 3.3
show the three people who were misclassified. It can also be
seen that 7 people in the Beethoven group memorized more
items (7 or more) than 8 of the people in the Static group. Such
clear separation in the Items units of observations accounts for
the impressive overall results of the Observation Oriented
analysis.
OOM Software Manual
21
Figure 3.2
Annotated Output for Observation Oriented Model
Build / Test Model for Build/Test Model Example 1
Classification Imprecision value = 0
Missing Values = Listwise Deletion
Normalization = Target/Conforming
The settings/options requested by the user are reported here. These options
are described in the pages that follow. Options and settings selected by the
user are routinely printed in blue font.
Ordering Frequency Summaries
This table summarizes features and counts for the different orderings
included in the model being tested. “Obs” has here been abbreviated from
“Observations.” There were no missing observations in this example, and
all of the observations were defined and included in the analysis. As
indicated above, Condition is comprised of 2 units, and Items is comprised
of 11 units.
Condition
Items
Totals
Units: 2
Units: 11
Units: 13
Missing: 0
Missing: 0
Missing: 0
Undefined: 0
Undefined: 0
Undefined: 0
Obs: 18
Obs: 18
Obs: 36
Model Tested :
Condition
-->
Items
The expression (model) tested is repeated here in blue font.
Classification Results
Conforming (Effect) Observations Classified to Target
(Cause) Observations
Classifiable Observations
Ambiguous Classifications
Correct Classifications
Percent Correct Classifications
:
:
:
:
The number of classifiable observations is listed first. As the summary table
above indicates, 18 observations were classifiable. Fifteen of 18
observations (83.33%) were classified correctly, which is a very impressive
result. None of the observations resulted in an ambiguous classification.
18
0
15
83.33
Randomization Results
Observed Percent Correct Classifications : 83.33
Number of Randomized Trials
Minimum Random Percent Correct
Maximum Random Percent Correct
Values >= Observed Percent Correct
Model c-value
{New graph created: See Graphics Window}
The conforming and target orderings are identified and labeled.
:
:
:
:
:
1000
61.11
94.44
82
0.08
The Percent Correct Classification (83.33%) is repeated here. For the 1000
trials, the lowest PCC was 61.11% and the highest was 94.44%, and 82 of
the trials yielded a PCC value equal to or greater than 83.33%. The chancevalue (c-value) is thus .08, or .082 to be more precise (82 / 1000). This is an
impressively low value, indicating an unusual pattern in the observations
compared to chance pairings of the target and conforming observations.
A note in green font is generated indicating that a multigram has been
generated.
OOM Software Manual
Figure 3.3
Multigram
cross the units of observations much like is done in a factorial
ANOVA in the Pearsonian-Fisherian tradition. In order to
demonstrate these features a more complex set of observations
is needed. Two additional orderings of observations are thus
added to the original 18 observations above:
Condition
case_1
1
case_2
1
case_3
1
case_4
1
case_5
1
case_6
1
case_7
1
case_8
1
case_9
1
case_10
2
case_11
2
case_12
2
case_13
2
case_14
2
case_15
2
case_16
2
case_17
2
case_18
2
Build Models
Figure 3.1 shows the expression in the Models edit box
that was tested above; namely;
Condition Items
Multiple expressions and more complex expressions may be
entered into the Models edit box. If multiple expressions are to
be evaluated, each must be entered on a separate line. More
complex expressions can be constructed and tested using the
various Operators buttons (+, -, ^) shown in Figure 3.1. The +
and – buttons are used to perform deep structure addition or
subtraction on the observations, and the ^ button is used to
22
Items Items_two Gender
7
6
1
8
7
2
5
5
2
7
6
1
8
8
2
7
5
1
9
7
1
6
5
1
7
7
2
5
3
1
6
4
1
4
3
1
5
5
2
7
5
2
6
3
2
4
3
2
5
3
2
5
2
1
File: BuildModelExample_2.oom
The Items_two observations are comprised of 11 units and
represent the participants’ attempt to recall the items three
hours after the first attempted recall. Gender represents male (1)
and female (2) units of observation.
Figure 3.4 shows how two models can be entered into
the Models edit box. Each expression must be entered on a
separate line and must be a legal expression. A legal expression
is one that, at a minimum, connects target and conforming
observations with the connector operator (). No more than
one connector operator is permitted in each expression,
OOM Software Manual
whereas multiple +, -, and ^ operators are permitted on both the
left- and right-hand sides of the connector operator. For
example,
Condition ^ Gender Items + Items_two
is a legal expression.
The first expression in Figure 3.4 is the same as tested
above, and the second demonstrates how units of observations
can be crossed; namely,
Condition ^ Gender Items
In this expression every Condition unit of observation will be
crossed with every Gender unit of observation, thus yielding
four units of observation: Beethoven/Male, Beethoven/Female,
Static/Male, and Static/Female. These are the target
observations and Items are the conforming observations.
Results of the analysis (output not shown) indicate a reduction
in the Percent Correct Classification (PCC= 55.56%, c-value
= .40) compared to the first expression above. The multigram
in Figure 3.5 shows the 10 of 18 observations that were
correctly classified. The figure also clearly shows how the
Condition and Gender orderings were crossed to form the 4
units of the target observations.
Options
The Build / Test Model window provides a number of
options when creating and testing expressions. These options
can be seen in the lower left hand corner of Figures 3.1 and 3.4
in the Options section of the window.
Figure 3.4
Multiple
Expressions
Tested
Figure 3.5
Multigram
23
OOM Software Manual
Model Observation Separation
Model Observation Separation permits the user to
separate two orderings of observations into two units. The
extent to which the observations overlap can then be evaluated.
For example, the Items_two observations could be conformed
to the Items observations using the following expression:
Items Items_two.
It might be expected that persons who recalled many items on
the first trial recalled the same number of items on the second
trial. This expression would permit the test of such an idea and
would be akin to Pearson’s correlation coefficient, although of
course the analysis is not based on any a priori function. The
expression would also not test if the people typically recalled
more items on the first occasion compared to the second. The
Model Observation Separation option provides the test of this
second question (akin to a dependent samples t-test).
What literally happens in the OOM software when the
Model Observation Separation option is chosen for this
example is that the Items and Items_two observations for the
18 people are concatenated into one column of 36 (18 + 18)
observations (let’s call it Items_concat) and a new ordering is
created with two units (let’s call it Group). The implicit
expression tested is therefore,
Group Items_concat.
For the concatenation process to be legitimate, the two sets of
observations (Items and Items_two) must have the same
number of units of observations. In this case, they both have 11
units of observations representing the number of items recalled.
If the numbers of units are not equal, OOM will generate an
error message and test the original expression, Items
Items_two.
24
Figure 3.6 shows the expression tested and shows that
the Model Observation Separation option has been selected.
Figure 3.6
Model
Observation
Separation
Figure 3.7 shows the multigram and output generated from the
Model Observation Separation option. It can be seen that the
Items and Items_two observations were not clearly separated.
Twelve of 18 people recalled 4 or more items on the second
occasion and all of the people recalled at least 4 items on the
first occasion. The analysis revealed that while 66.67% (24 of
36) of the observations were classified correctly, a result this
extreme was not very distinct (c-value = .63). The generated
output follows a standard format like that shown in Figure 3.2,
but a note is included to indicate that a Separation of
Observations expression was tested.
OOM Software Manual
Figure 3.7 Observation Separation Multigram and Output
Build / Test Model for Build/Test Model Example 2
Classification Imprecision value = 0
Missing Values = Listwise Deletion
Normalization = Target/Conforming
Ordering Frequency Summaries
Items
Items_two
Totals
Units: 11
Units: 11
Units: 22
Missing: 0
Missing: 0
Missing: 0
Undefined: 0
Undefined: 0
Undefined: 0
Obs: 18
Obs: 18
Obs: 36
Model Tested :
Items
-->
Items_two
:
Separation of Observations
Classification Results
Conforming (Effect) and Target (Cause) Observations
Separated and Classified to Groups
Classifiable Observations
Ambiguous Classifications
Correct Classifications
Percent Correct Classifications
:
:
:
:
36
0
24
66.67
Randomization Results
Observed Percent Correct Classifications : 66.67
Number of Randomized Trials
Minimum Random Percent Correct
Maximum Random Percent Correct
Values >= Observed Percent Correct
Model c-value
{New graph created: See Graphics Window}
:
:
:
:
:
1000
33.33
86.11
632
0.63
25
OOM Software Manual
In summary, the Model Observation Separation option
is similar to a dependent samples t-test from the traditional
Pearsonian-Fisherian tradition. With a dependent samples t-test
two hypotheses are actually involved. The first examines the
linear association between pairs of observations and the second
examines the mean separation between the pairs of
observations. The Model Observation Separation option is
similar to this second hypothesis, although as with any analysis
in OOM it is not based on means or other aggregate statistics
but rather patterns in the observations.
Classification Imprecision
In the language of observation oriented modeling, the
effect is considered to conform to the cause. The effect thus
corresponds to the conforming observations and the cause
corresponds to the target observations. In instances in which
the effect is considered to be comprised of ordered categories,
counted units, or measured units of a continuously structured
attribute in nature (e.g., temperature), then the Classification
Imprecision option may be legitimately used. As its name
implies this option allows the user to consider a range of units
when judging the observations to be correctly or incorrectly
classified by the rotation algorithm.
Consider an expression in which the number of items
recalled on the second occasion is brought into conformity with
the items recalled initially (without Observation Separation),
Items Items_two.
Figure 3.8 shows the multigram for the analysis of this
expression. While the pattern of observations shows a
somewhat consistent and monotonic pairing between units of
observation for the Items and Items_two orderings, the PCC
26
Figure 3.8 Multigram for Items Items_two
index is not very high, 44.44%, and the c-value (1000 trials) is
high, .79. It can also be seen in Figure 3.8 that the analysis
yielded 5 ambiguously classified observations for unit 5 of the
Items_two ordering.
Because the target observations are counted words
recalled in this example, we could ask if the results could be
improved by “loosening up” the criterion for an accurate
classification. Much as is done when considering measurement
error, this would be like asking if, for instance, given +/- 1 unit,
can the conforming observations be brought into conformity
with the target observations? This adjustment for imprecision
can be made by setting the Classification Imprecision value.
Figure 3.9 shows the same expression now being tested with an
imprecision setting of +/- 1 unit of observation.
OOM Software Manual
27
Figure 3.9
Model
Classification
Imprecision
again, no values of 10 were observed). It should be clear, given
these observations and multigrams, that setting the imprecision
value to +/- 2 would result in the final two red bars in Figure
3.10 turning green (indicating correct classification).
It can also be seen in the two multigrams that the
Classification Imprecision option does not affect the
observations that are classified as ambiguous (yellow bars). As
a general statement, then, increasing the classification
imprecision creates a wider horizontal band in the multigram
for correct classifications, thus turning red bars green that are
horizontal to one another in the multigram. Ambiguously
classified observations will not be affected. Lastly, it should be
pointed out that the c-value will likely increase with less
precision or remain unsatisfactorily high. For +/- 1 unit of
imprecision, 3 more observations were classified correctly, but
the c-value remained disappointingly high, .66.
Figure 3.10 shows the multigram resulting from the analysis.
Comparing this figure with Figure 3.8 shows that 3 more
observations were correctly classified. Specifically, the
Items_two unit 3 (3 items recalled, see Figure 3.8) observations
were only considered correctly classified when paired with unit
4 of the Items observations. Now, with an imprecision value of
+/- 1, the Items_two unit 3 observations are considered
correctly classified if they correspond to Items observations of
3, 4, or 5 (see Figure 3.10, although no values of 3 Items were
observed). Similarly, Items_two unit 8 observations were only
considered correctly classified when paired with unit 9 of the
Items observations (see Figure 3.8). Now the Items_two unit 8
observations are considered correctly classified if they
correspond to Items observations of 8, 9, or 10 (see Figure 3.10;
Figure 3.10 Multigram adjusted for imprecision (+/- 1 unit)
OOM Software Manual
Missing Values
The Build / Test Model window offers two methods for
handling missing values. The first method is well known in the
Pearsonian-Fisherian tradition as Listwise Deletion of
observations. With listwise deletion, any case with a missing
value on any ordering included in an expression will be
removed entirely from the analysis. Consider the observations
from above, now with some missing observations,
Condition
case_1
1
case_2
1
case_3
1
case_4
1
case_5
1
case_6
1
case_7
1
case_8
1
case_9
1
case_10
2
case_11
2
case_12
2
case_13
2
case_14
2
case_15
2
case_16
2
case_17
2
case_18
2
Items Items_two Gender
7
6
1
8
.
2
.
5
2
7
6
1
8
8
2
7
5
.
9
.
1
6
5
1
7
7
2
5
3
.
6
4
1
4
3
1
.
5
2
7
5
2
6
3
2
4
3
2
.
3
2
5
2
1
File: BuildModelMissing.oom
If the following expression is tested,
Condition ^ Gender Items
then 5 cases will be completely removed from the analysis. In
other words, rather than 18 total observations, only 13 will be
available for analysis. Note that 2 persons are missing
Items_two observations, but these people will be included in
the analysis because Items_two is not included in the
28
expression. The Frequency Summaries in the OOM output
below reports the missing 5 observations. The 13 classifiable
observations are indicated in the Classification Results; of
which, 5 were ambiguously classified and 6 were correctly
classified.
Build / Test Model for Build/Test Model Missing
Classification Imprecision value = 0
Missing Values = Listwise Deletion
Normalization = Target/Conforming
Ordering Frequency Summaries
Condition
Items
Gender
Totals
Units:
Units:
Units:
Units:
2
11
2
15
Missing:
Missing:
Missing:
Missing:
0
3
2
5
Undefined:
Undefined:
Undefined:
Undefined:
0
0
0
0
Obs:
Obs:
Obs:
Obs:
18
15
16
49
Model Tested :
Condition { ^ } Gender
-->
Items
Classification Results
Conforming (Effect) Observations Classified to Target
(Cause) Observations
Classifiable Observations
Ambiguous Classifications
Correct Classifications
Percent Correct Classifications
:
:
:
:
13
5
6
46.15
Clearly, listwise deletion can result in the loss of a great many
cases, particularly with many instances of missing observations
in complex expressions that include several orderings. It is not
generally recommended as a strategy for treating missing data
OOM Software Manual
in the Pearsonian-Fisherian tradition, and that recommendation
is echoed in observation oriented modeling.
The second method for treating missing observations is
the Add Units option (see Figure 3.9). Because most of the
analyses in observation oriented modeling do not assume
ordered categories or quantitative structure of attributes, an
additional unit of observation is added to each ordering by this
option for the missing values. Testing the following expression
with this option,
Condition Items
produces the multigram shown in Figure 3.12. It can be seen
that an additional unit of observation has been created for the
Items ordering, and in this example the missing observations
are not clearly associated with either Condition (2 in the Static
condition and 1 in the Beethoven condition).
Figure 3.11
Missing
Observations
Add Units
29
The output from the analysis indicates that the missing values
have been “Classified” and therefore 18 observations are
classifiable:
Build / Test Model for Build/Test Model Missing
Classification Imprecision value = 0
Missing Values = Listwise Deletion
Normalization = Target/Conforming
Ordering Frequency Summaries
Condition
Items
Totals
Units: 2
Units: 11
Units: 13
Missing: 0
Missing: 3
Missing: 3
Undefined : 0
Undefined : 0
Undefined : 0
Obs: 18
Obs: 15
Obs: 33
Model Tested :
Condition
-->
Items
Classification Results
Conforming (Effect) Observations Classified to Target
(Cause) Observations
Classifiable Observations
Ambiguous Classifications
Correct Classifications
Percent Correct Classifications
:
:
:
:
18
0
15
83.33
In this example, 15 of the 18 observations are classified
correctly (83.33%) in the analysis, 2 of which are the missing
values classified in the Static group (see Figure 3.11). However,
another missing value is observed in the Beethoven group, so
the missing values are nearly evenly split between the two
groups, thus failing to reveal a clear pattern themselves. It is in
this manner, nonetheless, that missing values can be explored
OOM Software Manual
for systematic patterns, a key endeavor recognized even in the
Pearsonian-Fisherian tradition.
As another example of adding units of observations for
missing values, consider the same data set and the following
expression,
Gender Items.
Note that both orderings reveal missing values; hence, units of
observations are added to both in the analysis. It can be seen in
Figure 3.12 that all of the Items missing values were for
females, showing a clear pattern. The two missing Gender
observations were for the 5 and 7 units of Items observations,
and both were considered as classified correctly; still, no clear
pattern is revealed. Again, the point here is that by using the
Add Units option, potential systematic patterns in the missing
observations can be explored.
Figure 3.12
Missing
Observations
Add Multiple
Units
30
Normalization
The multigram in Figure 3.12 shows an interesting fact
about the normalization options in OOM. Specifically, note the
7 unit Items observations (the row labeled 7 in the multigram).
Two males, two females, and one person who did not report
gender recalled 7 items. Even though the one person who did
not report gender was outnumbered 2-to-1 by both males and
females, being classified as Missing was considered correct
(note the green bar in Figure 3.12 in row “7”) from the binary
Procrustes rotation. How can this be so? When examining a
multigram, the user might be inclined to assume that for each
of the row units (the conforming observations), the largest
frequency bar will be colored green and therefore represent a
correct classification, and that ties will always result in
ambiguous classifications. Figure 3.12 clearly shows, however,
that these assumptions are not necessarily true. If they were
correct, Items units 4, 5, and 7 would yield yellow frequency
bars in Figure 3.12 due to their equal frequencies. The reason
the assumptions are not true in this example is because the
Normalization: Target / Conforming default option (see Figure
3.9 above) was chosen.
Normalization is a generic rescaling technique and it is
commonly used for two reasons. First, it can be used to convert
numbers to a scale with a known property; for example, the
sum of the squared values equaling one. Interpreting the
relative magnitudes of normalized numbers is often easier than
interpreting the original values because of this known property.
Second, normalized numbers from different variables (in
traditional parlance) or orderings (in OOM parlance) are
equivalent with respect to the known property. This
equivalence is often of mathematical and conceptual value
OOM Software Manual
when combining, comparing, or further transforming the
normalized values. In OOM the Normalization: Target /
Conforming default option is used to offset the impact of large
differences in frequencies in the crossed units of observations
shown in any multigram. In other words, this normalization is
used to permit units with smaller numbers of observations but
with distinct patterns of association to be classified as correct
even in the context of units of observation with larger
frequencies. Again, in reference to a multigram (e.g., Figure
3.12), normalization permits smaller frequency bars to be
classified as correct if they are involved in distinct patterns.
In the course of developing an integrated model,
however, it may be desirable to in fact allow the largest
frequency in each row of a multigram (that is, each unit of the
conforming observations) to be considered as the correct
classification. In such an instance the Normalization:
Conforming Only option should be chosen. Doing so for the
expression
Gender Items
yields the multigram in Figure 3.13. As can be seen, this
example led to a large number of ambiguous classifications
because the algorithm stressed only the differences between
columns for each row of the multigram. For three units of the
Items conforming observations (4, 5, and 7) there were ties
with regard to the frequencies for Gender units.
The choice between the two normalization options will
be driven by at least two factors. First, the dictates of an
integrated model and the frequencies of units of observation it
is expected to yield. Second, a practical, case-by-case
examination of the observed frequencies in the multigram. If
small frequencies are yielding dramatically different results
31
between the two types of normalization, the user must attempt
to explain these effects in the context of generating a set of
results that is meaningful and repeatable.
Figure 3.13
Conforming Only
Normalization
One last thing can be said about normalization;
specifically, selecting the Transformation Matrix checkbox
under Output options in the Build / Test Model window (see
Figure 3.9) will print a transformation matrix in the Text
Output window of OOM. This matrix represents that values
that are multiplied, via matrix multiplication, to the conforming
deep structure observations in order to transform them into the
target deep structure observations. The transformation matrix
OOM Software Manual
resulting in the multigram in Figure 3.12 follows
(Normalization: Target / Conforming):
Transformation Matrix
Row_1
Row_2
Row_3
Row_4
Row_5
Row_6
Row_7
Row_8
Row_9
Row_10
Row_11
Col_1
|
|
0.0000
0.0000
0.0000
0.0000
0.6901
1.0000
0.8856
0.6901
0.0000
1.0000
0.0000
Col_2
|
0.0000
0.0000
0.0000
0.0000
0.7237
0.0000
0.4644
0.7237
1.0000
0.0000
0.0000
32
transformation matrices depends on how the original
transformation matrix, eTc, was normalized (e equals the
number of units in the conforming, effect, observations; c
equals the number of units in the target, cause, observations). T
is the crux of the Procrustes rotation and is computed from the
conforming and target deep structure matrices as,
’
eTc = eE n nCc
For the first transformation matrix shown above the columns
and then the rows of eTc were normalized. For the second
transformation matrix only the rows were normalized. The
final conformed observations are computed from the
conforming deep structure observations and normalized
transformation matrix (see Chapters 3 and 4 of the Observation
Oriented Modeling book).
The transformation matrix resulting in Figure 3.13 follows
(Normalization: Conforming Only):
Randomization Test
Transformation Matrix
Row_1
Row_2
Row_3
Row_4
Row_5
Row_6
Row_7
Row_8
Row_9
Row_10
Row_11
Col_1
|
|
0.0000
0.0000
0.0000
0.0000
0.7071
1.0000
0.8944
0.7071
0.0000
1.0000
0.0000
Col_2
|
0.0000
0.0000
0.0000
0.0000
0.7071
0.0000
0.4472
0.7071
1.0000
0.0000
0.0000
The two multigrams were generated from the two different
types of normalization. The difference between the two
As described above the randomization test works by
randomly pairing the conforming and target observations and
then rotating the novel arrangement to conformity. For the sake
of simplicity, only the conforming observations are randomized
in the process, as it is not necessary to randomize both the
conforming and target observations to achieve the goal.
OOM Software Manual
In order to make this explicit, again consider the target
deep structure for the original 18 observations above:
1
1
1
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
1
1
The deep structure for the 18 conforming observations is:
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
1
0
0
0
0
1
0
0
0
0
0
0
1
0
0
1
0
0
0
1
1
0
0
0
0
0
0
0
1
0
0
1
0
0
0
1
0
0
0
1
0
0
1
0
1
0
0
1
0
0
0
0
1
0
0
0
0
0
1
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
33
Recall from above the binary Procrustes rotation yielded a PCC
index of 83.33. When the Randomization Test option is
selected, and the Number of Trials set to some value, like 1000
shown in Figure 3.1, then OOM will repeatedly randomize the
conforming observations, perform the binary Procrustes
rotation, compute the PCC index for the randomized
observations, and record the results. For instance, the 1st of
1000 trials of randomized conforming observations may appear
as follows:
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
1
1
1
0
0
0
0
0
0
0
0
1
1
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
1
0
0
0
1
0
0
0
0
1
1
0
1
0
1
0
0
0
0
1
0
1
0
0
0
0
1
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
Note this deep structure matrix differs from the original only
with regard to the rows. The columns have not been
randomized. The PCC index resulting from conforming these
observations to the original target observations is 72.22, lower
than the 83.33% for the actual pairings of observations.
This randomization process is repeated 1000 times and
the results summarized in the Text Output window as shown in
Figure 3.2 (the annotated output) above. The number of
OOM Software Manual
instances in which the PCC index from the randomized
observations equals or exceeds the original value (in this case,
82) is particularly important and is used to compute the chance
value, or c-value. Specifically, the number of PCC values
equaling or exceeding the original value is simply divided by
the number of trials. In Figure 3.2 above, the c-value was .08,
or 82 / 1000.
In traditional Null Hypothesis Significance Testing, the
goal is to estimate a population parameter and determine
statistical significance. This typically requires an observed test
statistic to be evaluated on the basis of a sampling distribution,
the properties of which (e.g. it is a normal curve) depend upon
a number of assumptions (e.g., the observations are
independent).
By comparison, randomization tests – as they are
commonly employed in OOM – are free of assumptions. A
distribution of PCC outcomes is constructed ad hoc from
randomized orderings of the observations themselves. The
observed PCC value can then be evaluated in this distribution.
The typical assumptions of population normality and
homogeneous variances are not required, nor are the
assumptions of independence of observations or random
sampling (or assignment). The assumption-free nature of
randomization tests is widely recognized as one of their most
attractive features (see Manly, B. F., 1997, 2nd Ed.,
Randomization, Bootstrap, and Monte Carlo Methods in
Biology, Chapman & Hall).
The Save Randomized Results option (see Figure 3.1)
can be selected to save the results from the randomization test
to a new data set in OOM. These new observations can then be
examined, edited, saved, summarized, or used for different
purposes. For instance, the frequency histogram for the 1000
PCC values shows a skewed shape:
61.11
66.67
72.22
77.78
83.33
88.89
94.44
:
:
:
:
:
:
:
[255]**************************
[194]*******************
[341]**********************************
[128]*************
[ 61]******
[ 17]**
[ 4]*
Total Number of Observations
Number of Missing Observations
Number of Units
: 1000
: 0
: 7
Observations to Categorize
Categorized Observations
Uncategorized Observations
: 1000
: 1000
: 0
Output
The Output options are largely self-explanatory, and
some have been described above. Nonetheless, a few words
will at least be said about each output option. Figure 3.14
shows the Output options all selected.
34
OOM Software Manual
Figure 3.14
Output
Options
Chosen
35
toggled (see Figure 3.15), the frequency values can be toggled,
the vertical lines can be removed from the graph, and the width
and height of the columns can be adjusted.
Figure 3.15
Black and White
Multigram
Multigram
The multigram in OOM is a novel method for graphing
results that has been exemplified above. The multigram is
simply a series of frequency histograms for the conforming
units of observation concatenated horizontally for each unit of
target observation (see Figure 3.13). The results of the binary
Procrustes rotation are incorporated in the multigram via a
coloring scheme: green indicates correctly classified
observations, red indicates incorrectly classified observations,
and yellow indicates ambiguously classified observations. It
should be noted that when a multigram is visible in the
Graphics Output window, the right mouse button can be
clicked to open a popup menu of options that permit the user to
alter visual features of the graph; specifically, the colors can be
The multigam cannot otherwise be edited, although it can be
saved in its default form as a Windows metafile. Such files can
be copied into Powerpoint or Word and edited. The multigram
can also be exported as a bitmap file that can be edited with
any standard image editing program.
Ordering Summaries
This option is selected by default and is available for
most analyses in OOM. The output generated by this option
helps the researcher to insure that the observations being
OOM Software Manual
analyzed have been defined and that most observations are
non-missing. Example output follows:
Ordering Frequency Summaries
Items
Gender
Totals
Units: 11
Units: 2
Units: 13
Missing: 0
Missing: 0
Missing: 0
Undefined : 0
Undefined : 0
Undefined : 0
Obs: 18
Obs: 18
Obs: 36
Here “Observations” has been abbreviated to “Obs.” The
ordering labels are listed first, followed by the number of units
constituting each. The number of missing values is then
reported and followed by the number of observations that were
undefined. Recall that undefined observations are those with
values that have not been defined by the user in the Define
Ordered Observations window (see Chapter 2; for instance, a
Gender value entered incorrectly as “3” would be undefined).
The number of defined, non-missing observations for each
ordering are presented in the last column. In this example, all
eighteen cases are defined and non-missing. A row of totals is
presented last in the Ordering Frequency Summaries.
Classification Summaries
This output option reports a unit breakdown of the
classified observations from the binary Procrustes rotation. It
can also be thought of as a numerical/tabular presentation of
the information in the multigram. For the expression,
Gender Items
the annotated output is presented in Figure 3.16. It can be seen
that the number of correct, incorrect, and ambiguous
classifications is presented first according to the target units of
36
observations (Condition), and then according to the conforming
units of observation (Gender).
Individual Classifications
This output option is highly useful for identifying those
particular individuals/observations who are classified correctly,
incorrectly, or ambiguously by the binary Procrustes rotation.
The annotated output in Figure 3.17, for instance, shows that
observations 14 and 16 (case_14, case_16) were the individuals
ambiguously classified in the current example analysis. The
Classification Strength Indices can also be found in this option.
Counts for Multigram
This option again reports a summary table of the
classified and mis-classified observations. Here they are broken
down by whether or not they were correctly, incorrectly, or
ambiguously classified. Again, these results can be compared
to the multigram for which they are a tabulated summary (see
Figure 3.18).
OOM Software Manual
37
Figure 3.16 Classification Summaries Output
Classification Summary by Gender
Male
Female
Correct
|
Incorrect
|
|
Ambiguous
|
|
|
6
2
1
5
3
1
Note. Values represent totals. 18 observations
classified.
Classification Summary by
0
1
2
3
4
5
6
7
8
9
10
Classified observations are first reported according to the target
observations, Gender in this example, with two units of observation: Male
and Female.
About an equal number of observations (6 and 5) were classified correctly
for the two units. Similarly, 2 and 3 observations were incorrectly classified
for the Male and Female units, respectively. Two observations resulted in
Ambiguous classifications for this expression.
Items
Correct
|
Incorrect
|
|
Ambiguous
|
|
|
0
0
0
0
0
0
0
0
0
0
0
0
0
0
2
3
2
0
2
1
0
3
2
0
2
0
0
1
0
0
0
0
0
Note. Values represent totals. 18
observations classified.
There were 11 (0 – 10) units for the Items observations, and this table
reports the correct, incorrect, and ambiguous classified observations
accordingly. The five incorrectly classified observations were “spread out”
across the 5, 6, and 7 Items units. The two ambiguous classifications were
both found in the 4 Items unit.
OOM Software Manual
Figure 3.17 Individual Classifications Output
Individual Classification Results
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
case_13
case_14
case_15
case_16
case_17
case_18
Classification Result
|
Classification Strength
|
|
Target Deep Structure
|
|
|
Classified Deep Structure
|
|
|
|
Conforming Deep Structure
|
|
|
|
|
C 0.83
Male
Male
7
C 1.00
Female
Female
8
C 0.83
Female
Female
5
C 0.83
Male
Male
7
C 1.00
Female
Female
8
C 0.83
Male
Male
7
C 1.00
Male
Male
9
C 0.89
Male
Male
6
I 0.83
Female
Male
7
I 0.83
Male
Female
5
C 0.89
Male
Male
6
A 0.71
Male
Amb
4
C 0.83
Female
Female
5
I 0.83
Female
Male
7
I 0.89
Female
Male
6
A 0.71
Female
Amb
4
C 0.83
Female
Female
5
I 0.83
Male
Female
5
Note. C = Correctly Classified, I = Incorrect, A = Ambiguous.
38
Here the individual observations are summarized with regard to the binary
Procrustes rotation. Each row represents an observation, and 18
observations are included in this example. As can be seen in the first
column presents the case labels.
The second column reports the classification result, and the note to the table
indicates: C = Correctly Classified, I = Incorrect, A = Ambiguous. It can be
seen that observations 12 and 16, for instance, are ambiguously classified.
These two observations are found in the yellow bars in the multigram in
Figure 3.15.
The third column reports the Classification Strength Indices which can
range in value from 0 to 1. Generally speaking, the ambiguous
classifications will result in lower CSI values due to the “competition”
between observations to be classified into one of the target units of
observation. case_12 is a Male and case_16 is a Female, for instance, and
both recalled 4 items (see the last column). The algorithm was therefore
“torn” between classifying the 4 units of Items observations as males or
females, resulting in the relatively low CSI values (.71). The CSI values can
be examined for particular values or patterns of values that might indicate
weaknesses in the results. Here, no systematic differences in the CSI values
are present; for instance, the males and females do not appear to differ and
no individual correctly or incorrectly classified observations stands out.
The Target Deep structure reports the actual target units of observation
(Gender in this example), and the Classified Deep Structure reports the
observations as classified by the binary Procrustes rotation. The units in
these two columns match for the correctly classified observations and do
not match for the incorrectly classified observations. For instance, case_9 is
a female who was, based on her items recalled, classified incorrectly as a
male. The ambiguously classified observations are listed as “Amb” in the
Classified Deep Structure column.
The Conforming Deep Structure column reports the actual conforming units
of observation, Items in this example.
OOM Software Manual
39
Figure 3.18 Counts for Multigram Output
Multigram Summary: Correctly Classified Observations
0
1
2
3
4
5
6
7
8
9
10
Male
|
|
0
0
0
0
0
0
2
3
0
1
0
Female
|
0
0
0
0
0
3
0
0
2
0
0
Multigram Summary: Ambiguously Classified Observations
0
1
2
3
4
5
6
7
8
9
10
Male
|
|
0
0
0
0
1
0
0
0
0
0
0
Female
|
0
0
0
0
1
0
0
0
0
0
0
Multigram Summary: Incorrectly Classified Observations
0
1
2
3
4
5
6
7
8
9
10
Male
|
|
0
0
0
0
0
2
0
0
0
0
0
Female
|
0
0
0
0
0
0
1
2
0
0
0
This tabulated output is a direct reflection of the multigram shown in Figure
3.15. It can be seen, for instance, that the two ambiguously classified
individuals both recalled 4 items, and one of the persons is a male and one
is female. It can also be seen that the two incorrectly classified males
recalled 5 items whereas the 3 incorrectly classified females recalled 6 or 7
items. Again, these tables provide a numeric representation of the
multigram.
OOM Software Manual
Transformation Matrix
The transformation matrix is discussed above. It is the
central matrix for the binary Procrustes rotation. It can be
examined to gain insight into how clearly the algorithm
separated units of observation. For instance, a row in the
transformation matrix populated by zeros and a single value of
1 shows the clearest possible separation that will result in the
strongest CSI values. Otherwise, the transformation matrix is
of little practical value and is mainly reported so that users may
check the algorithm if they desire.
Save Deep Structure Matrices
Selecting this option will create new data sets in the
Data Edit window in OOM. Each ordering in the expression
will be converted to its deep structure, and the deep structure
will be set up in the Data Edit window where it can be
manipulated, edited, saved, etc. For instance, the expression,
Condition ^ Gender Items
will generate three deep structure data sets in the Data Edit
window.
Save Classification Results [Button]
Selecting this button will open the options window
shown in Figure 3.19. It can be seen that the individual
classification results shown above can be saved to a data set in
the Data Edit window in OOM. The classification results can
be appended to the original observational data set, or a separate
data set can be created. Once saved, different operations can be
performed. For instance, the individuals who are correctly
classified can be selected and compared to those who are
incorrectly classified, or different orderings (e.g., ethnicity or
40
Figure 3.19
Save Classification
Results Options
some other observations) not yet included in an expression can
be examined relative to the different results. As can be seen
below, the classification result (correct, incorrect, or
ambiguous), the CSI values, the original target observations,
the classified units of observation, and the original conforming
observations can all be appended to the original data set or
saved into their own data set.
case_1
case_2
case_3
case_4
case_5
case_6
...
case_13
case_14
case_15
case_16
case_17
case_18
Classif
CSI
Target
Class
Conf
Correct
Correct
Correct
Correct
Correct
Correct
0.83
1
0.83
0.83
1
0.83
Male
Female
Female
Male
Female
Male
Male
Female
Female
Male
Female
Male
7
8
5
7
8
7
Correct
Incorrect
Incorrect
Ambiguous
Correct
Incorrect
0.83
0.83
0.89
0.71
0.83
0.83
Female
Female
Female
Female
Female
Male
Female
Male
Male
Male
Female
Female
5
7
6
4
5
5
OOM Software Manual
Frequency or Proportional Models
The expressions and models discussed above included
two sets of ordered observations, target and conforming, that
were brought into conformity with one another. In some
integrated models, the investigator may have only one set of
ordered observations for which the proportions of units are of
interest. For example, consider a comparative psychologist
who studies one dozen rats on three different occasions.
Suppose, based on his integrated model, he expects 80% of the
rats to learn to successfully navigate a complex maze for each
of the trials. His observations are thus ordered into two units,
Failure (0) and Success (1), as follows:
rat_1
rat_2
rat_3
rat_4
rat_5
rat_6
rat_7
rat_8
rat_9
rat_10
rat_11
rat_12
Trial1
0
1
0
0
0
1
0
0
0
0
0
1
Trial2
1
0
1
1
1
0
0
1
0
0
0
1
41
In order to test a proportional model, the expected
proportions must first be designated in the Define Ordered
Observations window. Figure 3.20 shows the window with
Figure 3.20 Define Ordered Observations for Trial1
Trial3
1
1
1
1
0
0
1
1
1
1
1
1
File: RatTrainingExample.oom
Again, the goal here is not to bring the trials into conformity,
but rather to investigate the distribution of observations across
the two units for each of the three trials, similar to what might
be done in a oneway chi-square analysis. In OOM such models
are referred to as frequency (or proportional) models, and they
are tested in the Build / Test Model window.
Trial1 selected in the ordered observations list. The following
text can be seen in the unit definitions edit box:
{0} [0.20] Fail
{1} [0.80] Success
The 0 and 1 in the brackets indicate the values in the Data Edit
window that represent the failure and success observations.
The 0.20 and 0.80 in the square brackets represent the expected
OOM Software Manual
proportions from the integrated model. If the proportions were
omitted,
{0} Fail
{1} Success
the proportional model could still be tested, but OOM will
assume the proportions are equal (0.50 in this example) across
the units of observation.
Now that the expected proportions under the presumed
integrated model have been defined for the units of
observation, the expression can be constructed and tested in the
Build / Test Model window, as shown in Figure 3.21.
Figure 3.21
Proportional
Model
42
It can be seen that the expression is simply Trial1 Trial1.
This format, in which the conforming and target observations
are the same, indicates to OOM that a proportional expression
is being tested. The annotated output is reported in Figure 3.22
and shows clearly that the observed pattern of failures and
successes (9 failures, 3 successes) did not match the expected
pattern of frequencies at all. In fact, the proportions were
almost exactly opposite of what was expected, and the chance
value reflects this fact, c-value = .98.
The randomization test in OOM for proportional
models does not merely shuffle the deep structure of the
observations; rather, based on the deep structure, it randomly
determines the unit for each observation. For instance, a
randomized deep structure for Trial1 may appear as:
rat_1
rat_2
rat_3
rat_4
rat_5
rat_6
rat_7
rat_8
rat_9
rat_10
rat_11
rat_12
Failure Success
1
0
1
0
0
1
0
1
0
1
1
0
0
1
0
1
1
0
1
0
1
0
1
0
Here the number of failures is 7 and the number of successes is
5, yielding a Total Matched Frequencies value equal to 7.40,
which is greater than the observed value of 5.40 (see Figure
3.22). The randomization test therefore generates random
proportions for the observations on the basis of their deep
structure and compares the results to the original observations.
OOM Software Manual
43
Figure 3.22 Output for Proportional Model
Build / Test Model for Rat Training Example
Classification Imprecision value = 0
Missing Values = Listwise Deletion
Normalization = Target/Conforming
Model Tested :
Trial1
-->
Trial1
[Proportional Analysis]
Expected and Observed Results
Fail
Success
Expected Proportions
|
Observed Proportions
|
|
Expected Frequencies
|
|
|
Observed Frequencies
|
|
|
|
0.20
0.75
2.40
9.00
0.80
0.25
9.60
3.00
Total Matched Frequencies
Proportion of Matched Frequencies
:
:
5.40
0.45
Randomization Results
Total Matched Frequencies
Number of Randomized Trials
Minimum Matched Frequencies
Maximum Matched Frequencies
Values >= Total Matched Frequencies
Model c-value
: 5.40
:
:
:
:
:
1000.00
2.40
11.60
985.00
0.98
The expected proportions of .20 and .80 are repeated here and paired with
the observed proportions. In this case the match between the two is terrible,
so the integrated model appears to predict the exact opposite of what is
observed. The proportions are converted to frequencies as well and reported.
Again, the expected and observed frequencies are nearly opposite. Ideally,
the expected proportions will result in whole numbers for the expected
frequencies since, in this instance, there is no .4 or .6 failure or
success…either the rats learn or they do not. OOM, however, does not
prevent fractions for this analysis, and it is up to the user to justify the
expected proportions and frequencies.
The Total Matched Frequencies is computed as follows: The model
expected 2.40 failures, and at least this many were in fact observed (2.40
matches). The model also expected 9.60 successes, but only 3.00 were
observed (3 matches). The sum of 2.40 and 3.00 is computed to yield the
Total Matched Frequencies, 5.40. Twelve rats were observed, yielding the
Proportion of Matched Frequencies, .45 (5.40 / 12).
The c-value is extremely high, indicating that the pattern of expected
proportions (or frequencies) did not match the observed proportions at all;
in fact, they were nearly opposite.
The multigram rounds the expected frequencies to whole numbers, and it
can be seen that 2 failures and 10 successes were expected, whereas 9
failures and 3 successes were observed. Only 5 units in the multigram
therefore overlap, the 2 expected failures are matched by at least 2 observed
failures, and 3 expected successes are matched by 3 observed successes. For
proportional models the multigram does not use a color-coded scheme (e.g.,
red for mis-classifications, yellow for ambiguous classifications) and
instead reports all frequencies in green.
OOM Software Manual
Using the same expected proportions (.20 failures, .80
successes) for the other two sets of ordered observations, it is
instructive to briefly examine the results for such disparate
observed proportions. For the expression,
Trail2 Trial2
the observed proportion of failures (.50) and successes (.50)
were closer to expectation. The multigram in Figure 3.23
shows the overlap between the expected and observed
frequencies is greater than for Trial1. The c-value is also much
improved, .62 (N = 1000 randomized trials), but is still
unimpressive. For the expression,
Trail3 Trial3
the observed proportion of failures (.17) and successes (.83)
were almost identical to expectation. The multigram in Figure
3.24 shows the correspondence between the expected and
observed frequencies, and the c-value is impressively low (.02),
indicating that the degree of correspondence between the
expected and observed frequencies is unusual compared to
randomly generated proportions.
Figure 3.23
Proportional
Model
Moderate Fit
44
Figure 3.24
Proportional
Model
Excellent Fit
Finally, given the nature of the proportional analysis,
which does not employ a binary Procrustes rotation, many of
the options in the Build/Test Model window will not apply or
generate output. Most output options will also fail to yield
output, such as the Classification Summaries and Counts for
Multigrams options. If these options are nonetheless chosen, a
note will be printed in the Text Output window.
OOM Software Manual
4
Pairwise Rotation
The Pairwise Rotation option is found under the
Analyses Main Menu option of OOM. It can be used to perform
binary Procrustes rotations on multiple pairs of ordered
observations, similar to building a correlation matrix for
multiple variables in the Pearsonian-Fisherian tradition.
Consider, for instance, the following:
student_1
student_2
student_3
student_4
student_5
student_6
student_7
student_8
student_9
student_10
student_11
student_12
student_13
student_14
student_15
student_16
student_17
student_18
student_19
student_20
student_21
student_22
student_23
student_24
student_25
student_26
student_27
R1
10
6
5
8
9
9
7
9
7
10
2
5
4
1
5
3
3
2
8
7
9
10
8
8
10
10
1
R2
10
2
3
4
9
3
3
9
5
10
1
2
1
1
3
1
1
1
7
9
4
10
4
6
10
10
1
File: ScienceRatings.oom
R3
10
10
4
9
8
10
7
8
7
9
2
4
7
1
7
7
1
1
7
9
8
10
8
8
9
9
3
R4
10
9
3
6
.
9
5
6
6
9
1
2
6
1
8
5
1
1
5
3
3
10
6
5
10
6
1
R5
9
10
7
10
9
8
6
7
6
9
8
5
8
3
3
6
7
4
4
9
9
7
6
7
9
5
3
R6
8
9
7
9
9
5
6
8
6
7
7
7
8
3
3
6
5
4
4
6
4
5
4
5
8
6
3
45
These observations are from 6 teachers who rated the
likelihood of each of 27 high school students to pursue a career
in science. Each rater used a 10-point scale anchored from 1,
not at all likely, to 10, highly likely. In the language of OOM,
one question might regard how well pairs of raters conform to
one another in their observed ratings of the 27 students. The
Build / Test Model analysis option could be used to answer this
question, but 15 models would need to be constructed
comparing each unique pair of raters. Moreover, since binary
Procrustes rotation is not generally symmetrical, different
results would be found, for instance, when rotating R1 to
conformity with R2 compared to rotating R2 to conformity
with R1. A total of 30 pairwise models would therefore be
needed. The Pairwise Rotation option essentially provides a
shortcut for testing models for these pairs of ordered
observations.
As can be seen in Figure 4.1 the Pairwise Rotation
window lists the orderings of observations in the data set; in
this example, R1, R2, R3, etc., from the science ratings data set.
It can also be seen that for this example all 6 raters are selected
so that all 30 pairwise combinations or orders of pairs of raters
will be analyzed. Caution should be used when selecting the
number of orderings to include because the analysis could take
a long time to complete. Binary Procrustes rotation with large
numbers of observations and the computation of c-values is
computationally intensive. It is therefore recommended that
only two or three orderings (e.g., R1, R2, and R3 only) be
selected first, the options chosen, and the analysis conducted,
before running the analysis on all of the orderings. The user
can in this way get a feel for how long the complete analysis
may take.
OOM Software Manual
Figure 4.1
Pairwise
Rotation
Analysis
Window
The analysis will work systematically through pairs of
orderings, and the pair under analysis will be listed in the
Rotating box at the bottom of Figure 4.1. As the analysis
proceeds through each pair of orderings, each will in turn be
listed in the Rotating box.
46
Options
Model Observation Separation
Selecting this option will, for the current example,
compare pairs of raters in terms of their separation on the
rating scale. For example, if R1 rates all of the students from 1
to 5, and R2 rates all of the students from 6 to 10, then their
observed ratings are clearly separated. This is a different
question from asking if their two sets of ratings can be brought
into conformity with one another. Because OOM does not
assume continuous quantitative structure, another example of
separation would entail R1 rating all of the students using even
numbers (2, 4, 6, 8, 10) with R2 rating all students using odd
numbers (1, 3, 5, 7, 9). Again, this indicates clear separation
between the two raters. More information about this option can
be found under the Options of Build / Test Model analyses in
Chapter 3 above.
Classification Imprecision
This option allows the user to treat a range of scores as
correct classifications. This option is also described in greater
detail in Chapter 3 (Build / Test Model chapter), but for the
current example it can be considered to permit the raters to be
“off” by several units of observation and still be considered as
conforming to one another. For example, consider setting the
Classification Imprecision value to 1. Once two raters’
observations are rotated to conformity, a correct classification
would be tallied if a given conformed observation was within
+/- 1 unit of the target observation. If the patterns of
observations for two raters are similar overall but consistently
differ in this manner by one unit (e.g., R1 rates the first student
OOM Software Manual
as 5 and R2 rates the same student as 6), then they will be
considered as rotated to conformity. It is as if the raters agree,
but are “off” by +/- 1 unit of observation. As noted in the Build
/ Test Model chapter, this option does assume that the units of
observation represent ranked orders or equal interval quantities.
Missing Values and Normalization
These options are described in detail in Chapter 3 above
(the Build / Test Model chapter) and need not be repeated. It
should only be noted that for Pairwise Deletion binary
Procrustes rotation will not include any pair of observations
where at least one is missing. It can be seen in the data set
above, for example, that R4 (the 4th rater) did not rate
student_5, the 5th student. Any comparison between R4 and
another rater will therefore exclude the 5th student. For other
complete pairs, this student will be included. This is the
standard technique of pairwise deletion used in statistical
programs within the Pearsonian-Fisherian tradition. It is
different from Listwise deletion which would exclude the 5th
student in this example from all comparisons in the analysis.
Output
The Ordering Summaries option is described in Chapter
3. The other options (Percent Correct Classified, Average
Percent Classified Correct, Asymmetries between
Classifications) generate matrices of values printed to the Text
Output window of OOM. The annotated output in Figure 4.2
provides descriptions of the different matrices and how they
are interpreted.
47
Randomization Test
The randomization test is identical to that used in the
Build / Test Model analysis (see Chapter 3). The randomization
test is conducted on each unique pairwise rotation, and the
results are reported in a matrix in the Text Output window.
OOM Software Manual
48
Figure 4.2 Pairwise Rotation Annotated Output
Pairwise Rotations for Science Ratings
Classification Imprecision value = 0
Missing Values = Pairwise Deletion
Normalization = Target/Conforming
Ordering Frequency Summaries
R1
R2
R3
R4
R5
R6
Totals
Units:
Units:
Units:
Units:
Units:
Units:
Units:
10
10
10
10
10
10
60
Missing:
Missing:
Missing:
Missing:
Missing:
Missing:
Missing:
0
0
0
1
0
0
1
Undefined:
Undefined:
Undefined:
Undefined:
Undefined:
Undefined:
Undefined:
Classifiable Observations
R1
R2
R3
R4
R5
R6
R1
|
.
27
27
26
27
27
R2
|
27
.
27
26
27
27
R3
|
27
27
.
26
27
27
R4
|
26
26
26
.
26
26
R5
|
27
27
27
26
.
27
R6
|
27
27
27
26
27
.
Ambiguous Classifications
R1
R2
R3
R4
R5
R6
R1
|
.
4
0
6
4
2
R2
|
7
.
7
0
9
4
R3
|
3
6
.
13
0
0
R4
|
12
4
5
.
10
9
R5
|
0
0
0
10
.
0
R6
|
0
0
4
0
0
.
0
0
0
0
0
0
0
Obs:
Obs:
Obs:
Obs:
Obs:
Obs:
Obs:
27
27
27
26
27
27
161
The observation summary shows the single missing rating for the fourth
item (R4). Complete ratings were obtained for all other orderings. Recall
each ordering is comprised of 10 units (ratings from 1 to 10). All of the
observations were defined and entered correctly.
The number of Classifiable Observations are reported in this matrix. The
maximum for any pair of orderings will be the minimum number of
observations (“Obs”) for either ordering in the Ordering Frequency
Summaries table. Recall that binary Procrustes rotation is not symmetrical,
so for each pair of raters two expressions must be tested; R1 R2 and R2
R1, for instance. Values above the main diagonal, here printed in blue
font, represent expressions in which the ordered observations forming the
column of the matrix are rotated to conformity with the row observations.
The value 27, for instance, represents the number of classifiable
observations from the R2 R1 expression. It can be seen that any rotation
involving R4 will include only 26 classifiable observations.
This matrix reports the number of ambiguous classifications from the
Procrustes rotations. Again, values above the main diagonal refer to
columns orderings rotated to row orderings. Rotating R4 R1, for instance,
yielded 12 ambiguous classifications; whereas rotating R1 R4 yielded
only 6 ambiguous classifications. R4’s ratings seem to result in more
ambiguous classifications than the others. His/her ratings might warrant
closer attention.
OOM Software Manual
49
Figure 4.2 Pairwise Rotation Annotated Output (Continued)
Correct Classifications
R1
R2
R3
R4
R5
R6
R1
|
.
18
17
13
13
15
R2
|
15
.
12
16
10
11
R3
|
12
11
.
7
13
13
R4
|
7
13
12
.
9
9
R5
|
12
12
12
7
.
17
The number of Correct Classifications from the Procrustes rotations are
reported in this matrix.
R6
|
12
9
10
9
16
.
Percent Correct Classifications
R1
R2
R3
R4
R5
R6
R1
|
100.00
66.67
62.96
50.00
48.15
55.56
R2
|
55.56
100.00
44.44
61.54
37.04
40.74
R3
|
44.44
40.74
100.00
26.92
48.15
48.15
R4
|
26.92
50.00
46.15
100.00
34.62
34.62
R5
|
44.44
44.44
44.44
26.92
100.00
62.96
R6
|
44.44
33.33
37.04
34.62
59.26
100.00
Note. Column observations are rotated to conformity with row
observations above the main diagonal. The opposite direction of
rotation results are presented below the main diagonal.
Average Percent Correct Classifications
R1
R2
R3
R4
R5
R6
R1
|
100.00
61.11
53.70
38.46
46.30
50.00
R2
|
R3
|
R4
|
R5
|
R6
|
100.00
42.59
55.77
40.74
37.04
100.00
36.54
46.30
42.59
100.00
30.77
34.62
100.00
61.11
100.00
Note. Values represent averaged Percent Correct Classification
values from deep structure rotations.
The Percent Correct Classification indices are reported in the next matrix.
The “100.00” values in the main diagonal are superfluous since, for instance,
R1’s ratings can be rotated to perfect conformity with his/her own ratings.
With non-matching orderings, recall that binary Procrustes rotation is not
symmetrical, so for each pair of raters two expressions must be tested; R1
R2 and R2 R1, for R1 and R2, for instance. The note to the table
indicates that values above the main diagonal (here printed in blue font)
represent expressions in which the ordered observations forming the column
of the matrix are rotated to conformity with the row observations. The value
55.56, for instance, represents the PCC result from the R2 R1 expression.
The values below the main diagonal (here printed in purple font) represent
results from the opposite expressions; for instance, the value 66.67 is
computed from the R1 R2 expression.
The magnitudes of these values indicate poor to modest similarity between
pairs of raters regarding the students’ likelihood to pursue careers in science.
The lowest value is 26.92% for several pairs of raters, and the highest value
is 66.67%. Of course the minimum and maximum possible values would be
0% and 100%, respectively.
This next matrix reports the averages of the blue and purple values reported
in the first matrix above; for instance, the mean of 55.56 and 66.67 is equal
to 61.11. Given the asymmetrical nature of the binary Procrustes rotation,
these averages permit the user to work with only 15 unique numbers rather
than 30 when interpreting the results. As with any averaging process,
information is lost. Based on these averages, it can be seen that pairs R1/R2
and R5/R6 yielded the greatest conformity between ratings, ignoring the
direction of rotation. Overall, the results indicate modest similarity between
raters.
OOM Software Manual
50
Figure 4.2 Pairwise Rotation Annotated Output (Continued)
Asymmetries between pairwise rotations
R1
R2
R3
R4
R5
R6
R1
|
.00
-11.11
-18.52
-23.08
-3.70
-11.11
R2
|
.
0.00
-3.70
-11.54
7.41
-7.41
R3
|
.
.
0.00
19.23
-3.70
-11.11
R4
|
.
.
.
0.00
-7.69
0.00
R5
|
.
.
.
.
0.00
-3.70
R6
|
.
.
.
.
.
0.00
Note. Values represent differences between Percent Correct
Classification values.
c-values for Percent Correct Classifications
R1
R2
R3
R4
R5
R6
R1
|
.
0.00
0.00
0.29
0.26
0.03
R2
|
0.00
.
0.44
0.00
0.64
0.65
R3
|
0.07
0.27
.
0.93
0.10
0.20
R4
|
0.81
0.01
0.19
.
0.83
0.84
R5
|
0.07
0.12
0.23
0.88
.
0.00
R6
|
0.03
0.40
0.33
0.65
0.00
.
Note. Values represent averaged c-values.
Average c-values for Percent Correct Classifications
R1
R2
R3
R4
R5
R6
R1
|
R2
|
R3
|
R4
|
R5
|
.
0.00
0.04
0.55
0.17
0.03
.
0.35
0.01
0.38
0.52
.
0.56
0.17
0.27
.
0.85
0.74
.
0.00
Note. Values represent averaged c-values.
R6
|
.
These values represent the simple differences between the PCC values
printed in the first matrix above. Each value therefore indicates the
difference between the rotations for each pair of ordered observations. For
instance, the R2 R1 and R1 R2 expressions yielded PCC values of
55.56 and 66.67, respectively, for a difference equal to -11.11.
It can be seen that the expressions R1 R4 and R4 R1 revealed the
greatest asymmetry, with a difference in PCC values equal to 23.08
percentage points. Most of the other pairs of expressions yielded similar
PCC values. Individual comparisons can always be investigated further in
the Build / Test Model analysis.
This matrix reports the c-values from the Randomization Test. They can
range in value from 0 to 1, and small values indicate that chance pairings of
the actual observations failed to yield PCC values as high as those obtained
from the actual observation pairs. The rotations are not symmetrical, so
values are again reported above and below the main diagonal to conserve
space and provide a format for quick comparison.
While many of the values are low (e.g., < .15), many are also high
(e.g., > .50) indicating that the rater’s judgments of the students were not
conformable beyond chance levels. Raters 1 and 2 yielded a low c-value as
did raters 5 and 6; whereas raters 4 and 5 and 4 and 6 yielded high c-values.
The two c-values from the asymmetric rotations are averaged and reported
in this matrix. Again, this simply reduces the amount of information that
must be processed when interpreting the results. Highly discrepant c-values
from pairs of orderings should be investigated using the Build / Test Model
analysis since averaging results in a loss of potentially important
information. The overarching goal with this example is to assess the extent
to which the raters ordered the 27 students in a similar fashion, and the low
PCC values and mediocre c-values indicates their observations were not in
high agreement.
OOM Software Manual
5
Matching Analysis
The Matching Analysis option is found under the
Analyses Main Menu option of OOM and is a simple algorithm
for examining the degree of similitude between pairs of
ordered observations. It is based on a simple method of directly
comparing the unrotated, original deep structures of two
orderings. Consider the science rating observations from the
Pairwise Rotation chapter:
student_1
student_2
student_3
student_4
student_5
student_6
student_7
student_8
student_9
student_10
student_11
student_12
student_13
student_14
student_15
student_16
student_17
student_18
student_19
student_20
student_21
student_22
student_23
student_24
student_25
student_26
student_27
R1
10
6
5
8
9
9
7
9
7
10
2
5
4
1
5
3
3
2
8
7
9
10
8
8
10
10
1
R2
10
2
3
4
9
3
3
9
5
10
1
2
1
1
3
1
1
1
7
9
4
10
4
6
10
10
1
File: ScienceRatings.oom
R3
10
10
4
9
8
10
7
8
7
9
2
4
7
1
7
7
1
1
7
9
8
10
8
8
9
9
3
R4
10
9
3
6
.
9
5
6
6
9
1
2
6
1
8
5
1
1
5
3
3
10
6
5
10
6
1
R5
9
10
7
10
9
8
6
7
6
9
8
5
8
3
3
6
7
4
4
9
9
7
6
7
9
5
3
R6
8
9
7
9
9
5
6
8
6
7
7
7
8
3
3
6
5
4
4
6
4
5
4
5
8
6
3
51
Six teachers rated the likelihood of each of 27 high school
students to pursue a career in science using a 10-point scale.
The options window for the Matching Analysis in
Figure 5.1 shows that multiple pairs of ordered observations
can be examined simultaneously. All 6 of the raters are
selected in the figure, and the analysis proceeds by converting
each ordering to its deep structure and then simply tallying the
number of matches. Examining the raw observations (data), for
instance, it can be seen that R1 and R2 match with regard to
stu_1, stu_5, stu_8, stu_10, stu_14, stu_22, stu_25, stu_26, and
stu_27, for a total of 9 matches of 27 possible (33.33%). Each
rater is compared in similar fashion to every other rater.
Figure 5.1
Matching Analysis
Window
OOM Software Manual
Because this analyses is based on deep structures, a generic
randomization test can also be used to evaluate the
probabilistic nature of agreement between each pair of raters. It
should be obvious that this analysis is only legitimate if the
units of observation for each ordering are all identical. In this
example, every rater used the same 10-point scale, so they can
all be meaningfully compared with regard to their frequency of
matches across the 27 students.
Options
Classification Imprecision
If the units of observation are assumed to represent an
ordered quality or a quality with a continuous quantitative
structure, then the Classification Imprecision option can be
used. It is by default set to 0, which means that for any two
ratings -- in this example -- to be tallied as a match, they must
be exactly the same unit of observation (e.g., a student is rated
7 by both raters). Setting the Classification Imprecision value
to a number other than 0 allows for a range of units of
observation to be considered as matches. For example, if the
value is set to 1 and R1 rates the first student as 5 and R2 rates
the first student as 4, then these two ratings would be
considered as a match because they are within +/- 1 unit of
observation of each other. As an extreme example, setting the
Classification Imprecision value to 9 in this example would
result in every rater matching on every student since the largest
difference between raters is 9 units (10 – 1 = 9). Of course such
a result is trivial, and the c-value for each pair of raters would
equal 1.0, but this extreme example helps to explain how the
imprecision value works.
52
Missing Values
Missing values can be handled in one of two ways.
Pairwise Deletion or Add Units. If the first (and default) option
is chosen, then the tallying process described above will ignore
any pair of observations where at least one is missing. It can be
seen in the data set above, for example, that R4 did not rate
stu_5, the 5th student. Any comparison between R4 and another
rater will therefore have a maximum number of 26 matches.
This is the standard technique of pairwise deletion used in
statistical programs within the Pearsonian-Fisherian tradition.
When Add Units is selected, another unit of observation
is created to represent the missing values. This is tantamount in
the Matching Analysis to counting the missing values as
observations that can be matched. For instance, in the current
example if two raters failed to rate stu_3, these missing values
would be tallied as a match, and the total number of possible
matches would be 27.
Output
The Ordering Summaries option is described in Chapter
3. The other options (Number of Matches, Proportion of
Matches, Average Absolute Difference) generate matrices of
values printed to the Text Output window of OOM. The
annotated output in Figure 5.2 provides descriptions of the
different matrices and how they are interpreted.
OOM Software Manual
Randomization Test
The randomization test in the Matching Analysis works
in similar fashion to the same test for binary Procrustes rotation
(see Chapter 3, Build / Test Model). The ordered observations
for each pair are converted to their deep structure, and the
second is randomized according to its rows. In this example,
this means that the ratings for the second rater in a given pair
are randomly shuffled. The number of matches is then tallied
for the randomized data. This process is repeated a determined
number of times (the Number of Trials set by the user, see
Figure 5.1) and the number of matches tallied for each
randomized trial. The number of values which equal or exceed
the observed number of matches for the original observations is
then determined and converted to a proportion. The proportion
is the chance value, or c-value, and it indicates the relative
frequency which randomized versions of the data yielded a
number of matches equal to or greater than the observed value.
The c-value ranges in value, then, from 0 to 1 and, in a sense, it
indicates the unusualness of the observed number of matches
between a pair of ordered observations. A low c-value near
zero indicates an unusual number of matches.
53
OOM Software Manual
54
Figure 5.2 Matching Analysis Annotated Output
Matching Analysis for Science Ratings
Classification Imprecision value = 0
Missing Values = Pairwise Deletion
The overall percent of matches is computed from all of the pairs of
observations in combination. Here the result is not very impressive at
20.75%, but the overall c-value (0.05) indicates that randomized orderings
of the data did not often generate an overall percentage this high.
Overall Results
Overall Number of Matches : 83
Overall Number of Possible Matches : 400
Overall Percent Matches : 20.75
Overall c-value
: 0.05
Number of Matches
R1
R2
R3
R4
R5
R6
R1
27
9
8
6
3
1
R2
R3
R4
R5
R6
27
7
10
3
4
27
6
5
3
26
3
4
27
11
27
The number of matches are reported in this matrix. The main diagonal
entries indicate the number of non-missing observations for each rater. Note
that if the Add Units option for missing values was chosen, all of the main
diagonal entries would equal 27. The other numbers in the matrix indicate
the number of matches between each pair of raters. It can be seen that
Raters 5 and 6 revealed the greatest agreement (11) while raters 1 and 6
were almost completely discrepant (1).
Percent Matches
R1
R2
R3
R4
R5
R6
R1
100.00
33.33
29.63
23.08
11.11
3.70
R2
100.00
25.93
38.46
11.11
14.81
R3
100.00
23.08
18.52
11.11
R4
100.00
11.54
15.38
R5
100.00
40.74
R6
The Number of Matches are converted to percentages in this matrix based
on the minimum number of non-missing observations for each pair. Again,
it can be seen that raters 5 and 6 matched on 40.74% of the students (11 /
27). Because the Imprecision value was set to 0, these percentages reflect
exact matches between the raters with regard to the students. Still, they
don’t reflect impressive agreement between pairs of raters.
100.00
Note. Imprecision = 0
Average Absolute Differences
R1
R2
R3
R4
R5
R6
R1
0.00
1.85
1.15
1.92
2.15
2.59
R2
R3
R4
R5
R6
0.00
2.33
2.00
3.19
2.96
0.00
1.62
1.81
2.41
0.00
2.46
2.38
0.00
1.11
0.00
As another index of similitude between pairs of observations the average
absolute differences in deep structure units are reported in this matrix. The
values for this example indicate that many of the observations were within
+/- 2 units on the 10-point scale, which suggests that by setting the
Classification Imprecision value to 2, much higher matching scores can be
obtained. In fact, with an imprecision of 2, the Overall Percent Matches is
equal to 65.75% compared to the 20.75% above.
OOM Software Manual
55
Figure 5.2 Matching Analysis Annotated Output (continued)
Pairwise c-values
R1
R2
R3
R4
R5
R6
R1
.
0.00
0.02
0.04
0.59
0.94
R2
R3
R4
R5
R6
.
0.01
0.00
0.36
0.08
.
0.00
0.23
0.50
.
0.48
0.22
.
0.00
R2
R3
R4
R5
R6
.
0.02
0.00
0.50
0.27
.
0.02
0.13
0.50
.
0.35
0.17
.
0.00
.
.
Overall c-values
R1
R2
R3
R4
R5
R6
R1
.
0.00
0.00
0.02
0.50
0.94
The chance value from the randomization test is reported here for each pair
of ordered observations. Not surprisingly, the pairs of raters with the highest
numbers of matches tend to have the lowest c-values, although this will not
always be the case because these pairwise c-values are more sensitive to the
distributions of the units of observations. For example, two raters in the
current example may achieve a high number of matches simply by rating
most of the students as 10. The c-value for such observations would be high
given the high number of matches even in randomized versions of the same
observations. Because of this sensitivity, the Overall c-values are reported
as well in a separate matrix. These chance values are computed on the basis
of all of the pairs of randomized observations, not just those for a particular
pair.
Consider R2 and R6. Their Number and Percent of Matches are 4 and 14.81,
respectively (see matrices above). When randomizing only these two pairs
of ordered observations, the c-value is .08. Specifically, of 1000 trials only
in approximately 80 instances did the randomized number of matches equal
or exceed 4. When a distribution of Number of Matches is constructed from
the randomization results for all 6 raters, however, the c-value is .27. In the
context of all pairs of ordered observations, then, the 4 matches was not as
unusual.
OOM Software Manual
6
56
Descriptive Statistics
The Descriptive Statistics analysis option (see Figure
6.1) is one of a few routines in OOM that is not based on the
deep structures of ordered observations. Instead, the
computations for the various statistics are based upon the
numbers entered into the Data Edit window. The numbers are
taken “as is” in the analyses. Descriptive statistics certainly
take a back seat in OOM to the other techniques in the program,
but they may still be useful for summarizing, for instance, a
distribution of PCC values or CSI values. Because it is
assumed the user of OOM is familiar with basic statistics and
because these statistics are secondary, only the formulas will be
presented here without examples. Perhaps the most important
issue to be aware of is that in OOM the variance and standard
deviation are computed via the population formulas.
Consequently, the variance and standard deviation values
obtained from OOM are not likely to match those obtained by
default from other statistical programs.
As can be seen in Figure 6.1, a note appears at the
bottom of the Descriptive Statistics window to remind the
reader that the analyses are based on the numbers as they are
recorded in the Data Edit window, not as they are defined in
the Define Ordered Observations window (see Chapter 2). It
can also be seen that the various descriptive statistics can be
reported separately for units of one set of ordered observations
by using the “Break Down by…” option. For example, the
statistics (mean, median, etc.) can be reported separately for
males and females if such orderings are recorded in the
observations.
Figure 6.1
Descriptive
Statistics
Option Window
As stated above, standard methods and formulas for
descriptive statistics are used in OOM, and their descriptions
follow. The user need only select the statistics in Figure 6.1 to
compute.
Number of Observations reports the number of nonmissing observations for each selected ordered
observations
Minimum and Maximum reports the minimum and
maximum values, as recorded in the Data Edit window,
for the selected ordered observations
OOM Software Manual
Median reports the value that stands at the 50th
percentile of the distribution of numbers. The values are
simply rank-ordered from least to greatest, and the
middle value located. If the number of observations is
odd, then the mean of the two middle values is
computed and reported as the median.
Mode reports the most frequently occurring value. The
number of modes is also reported in the output.
Mean reports the arithmetic average computed via the
standard formula,
x
x
.
n
Mean Absolute Deviation reports the mean deviation
from the arithmetic mean; namely,
MAD
x
i
x
i 1
.
n
Absolute Median Deviation reports the mean deviation
from the median; namely,
n
AMD
i
i 1
n
x
i 1
i
n
SS ( xi x ) 2 ,
i 1
n
Mdn
.
n
Sum of Squares (SS), Variance (S2), and Standard
Deviation (S) report the traditional measures of
dispersion using the population (or “biased”) formulas;
specifically,
57
S2
SS
,
n
S
SS
.
n
Sum reports the simple arithmetic sum of all of the
numbers for the ordered observations as they appear in
the Data Edit window.
OOM Software Manual
7
Pattern Analysis: Crossed Observations
The crossed observations pattern analysis can be used
to evaluate the relationship between any two sets of ordered
observations. The pattern of the relationship may be linear,
non-linear, circular, or any other form permitted by the units of
observation.
Consider the following ordered observations of 15
different people:
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
case_13
case_14
case_15
JobSat JobMorale
10
9
9
4
7
7
9
8
1
9
1
1
4
4
7
3
8
3
6
6
2
8
7
4
6
5
6
4
7
4
Gender
1
2
1
1
2
1
1
2
2
1
2
2
1
2
2
File: PatternCrossedExample.oom
The first column of observations represents the self-reported
level of satisfaction with one’s current job using a 10-point
scale anchored by 1, “extremely dissatisfied”, and 10,
“extremely satisfied.” The second column represents perceived
company morale, again using a 10-point scale anchored by 1,
“extremely low”, and 10, “extremely high.” The third column
represents biological sex ordered as 1 (male) and 2 (female).
58
Based upon an integrated model, we might expect the
units of JobSat and JobMorale observations to be related in a
strict one-to-one fashion. In other words, each unit of JobSat
should be paired with the corresponding unit of JobMorale
(e.g., 1 corresponds with 1, 2 corresponds with 2, etc.). In
traditional variable-based language, the expectation is that the
two variables should be positively, linearly related according to
a specific function.
Figure 7.1 shows the Pattern Analysis: Crossed
Observations window in which JobSat has been defined as the
First Ordering and JobMorale has been defined as the Second
Ordering. These two sets of observations will therefore be
crossed to form a two-dimensional grid on which an expected
pattern can be defined.
Figure 7.1
Pattern Analysis
for Crossed
Observations
OOM Software Manual
The selection of JobSat as the First Ordering rather than the
second is completely arbitrary. The pattern is defined by
selecting the Define Pattern button shown in Figure 7.1. It can
also be seen the Randomization Test is chosen.
Figure 7.2 shows the Define Crossed Pattern window
in which the expected pattern of results has been determined.
The pattern is defined by simply clicking, with the left mouse
button, each square in which the observations are expected to
be present. A square, or crossed unit, can be de-selected by
clicking the right mouse button. As can be seen in the figure,
each unit of JobSat is expected to be observed with each
corresponding unit of JobMorale, thus creating a linear pattern.
This pattern can be saved as a Windows Bitmap file or printed
by selecting the [Save] or [Print] Image Options buttons,
respectively. The pattern, as defined in the window in Figure
7.2, can be saved by selecting the [Save] button under Pattern
Options. Saving the pattern permits it to be reloaded on a future
occasion which can save valuable time when working with and
defining complex patterns with numerous crossed units of
observation.
By selecting the All Observations radio button the 15
observations can be examined in the grid, as shown in Figure
7.3. Only 4 of the 15 observations (27%) conform to the
expected pattern, and an alternative pattern will thus be
necessary. Nonetheless, given this pattern is assumed to be
based on an integrated model, the [OK] button is selected and
the analysis conducted by selecting the [OK] button on the
Pattern Analysis window in Figure 7.1. The annotated output in
Figure 7.4 reports the 4 conforming observations, and the
accompanying c-value from the randomization test perhaps
surprisingly shows that the 27% conforming observations is
Figure 7.2
Define
Expected
Pattern
of Results
Window
Figure 7.3
Observations
Shown
59
OOM Software Manual
60
Figure 7. 4 Annotated Output for Crossed Pattern Analysis
Pattern Analysis (Crossed Observations) for Pattern Crossed
Example Data Set
Missing Values = Omitted from Totals
Randomization Method = Randomize Observations
The user-selected options are reported here.
Ordering Frequency Summaries
JobSat
Units: 10
Missing: 0
JobMorale
Units: 10
Missing: 0
Totals
Units: 20
Missing: 0
The summary shows that no observations were missing or coded incorrectly.
Both JobSat and JobMorale have the same number of units (i.e., the 1-10
scale)
Undefined: 0
Undefined: 0
Undefined: 0
Obs: 15
Obs: 15
Obs: 30
Defined Pattern
Ext
| 2
+ O
O +
O O
O O
O O
O O
O O
O O
O O
O O
Low
3 4
O O
O O
+ O
O +
O O
O O
O O
O O
O O
O O
5
O
O
O
O
+
O
O
O
O
O
6
O
O
O
O
O
+
O
O
O
O
7
O
O
O
O
O
O
+
O
O
O
8
O
O
O
O
O
O
O
+
O
O
9
O
O
O
O
O
O
O
O
+
O
The pattern defined by the user to be tested is shown here. This option
should routinely be chosen to help insure the pattern was defined as
intended. It is selected by default.
Ext High
O Ext Dissatisfied
O 2
O 3
O 4
O 5
O 6
O 7
O 8
O 9
+ Ext Satisfied
Classification Results
Pairs of Observations Classified According to the Defined
Pattern(s)
Classifiable Pairs of Observations : 15
Correct Classifications : 4
Percent Correct Classifications : 26.67
Randomization Results
Observed Percent Correct Classified : 26.67
Number of Randomized Trials
Minimum Random Percent Correct
Maximum Random Percent Correct
Values >= Observed Percent Correct
Model c-value
:
:
:
:
:
1000
0.00
26.67
28
0.03
The 4 conforming observations shown in Figure 7.3 are tallied here and
converted to a PCC index (26.67; 4 / 15). With nearly 3/4 of the
observations unaccounted for, this result is not impressive.
Given the small proportion, it is perhaps surprising the c-value is
impressively low. Of 1000 trials, only 28 yielded PCC values equal to or
greater than 26.67. The maximum number of matches (conforming
observations) in the randomized trials was 26.67 (4/15) and the minimum
was 0. As always in OOM, the c-value is to be treated as entirely secondary.
The low observed PCC index of 26.67 is sufficient for concluding the
expected pattern fails to explain the observations.
OOM Software Manual
unusual compared to random patterns of observations (c-value
= .03). The low c-value can be partly explained by the large
numbers of crossed units of observations (its computation will
be described below). Crossing JobSat with JobMorale produces
a matrix of 100 units, only ten of which are defined in the
expected pattern (see Figure 7.3). Matching even three
observations in such a large matrix and scant pattern is
improbable. Regardless, the low PCC index (27%), which is
primary in OOM, likely disqualifies the pattern as scientifically
useful.
The crossed pattern analysis can include a Third
Ordering, yielding essentially a 3-dimensional cube
constructed from the units of observations. Figure 7.5 shows
Gender (ordered as 1=male, 2=female) included in the analysis
as the Third Ordering. The Randomization Test is again
selected, and the Individual Matching Results options are also
chosen.
Figure 7.5
Pattern Analysis
for Crossed
Observations
with Gender
Included
61
The anticipated pattern is defined by selecting the Define
Pattern button. Figure 7.6 shows the Define Pattern window in
which the First Ordering and Second Ordering observations
are again crossed to form a grid. As can be seen in the edit box
immediately above the image, the grid is now layered
according to the units of observation for the Third Ordering.
Figure 7.6
Male
Observations
Figure 7.7
Female
Observations
OOM Software Manual
The results for the males are currently shown in Figure 7.6.
Figure 7.7 shows the results for the females which are shown
by selecting the double-headed arrow button next to the edit
box displaying either “male” or “female” in the figures. The
overall pattern is thus defined by working within the different
units of observation for the Third Ordering. The sub-patterns
of expected observations therefore may differ. In a purely post
hoc fashion, for instance, Figures 7.6 and 7.7 show clearly
distinct sub-patterns of observations, crossing JobSat and
JobMorale, for males and females. The males’ pattern indicates
a unit-to-unit matching between JobSat and JobMorale, while
the females’ pattern appears exactly opposite. However, for
both sexes the unit-to-unit or opposite pattern is not exact.
At this point it is useful to utilize the Imprecision and
Diagonal fill options of the Define Crossed Pattern window
shown in Figures 7.6 and 7.7. If it can be assumed that the units
of observation for the crossed First and Second Orderings
represent ordered categories or equal interval units of
observation, then the Imprecision option can be reasonably
used to define a less precise pattern that includes a range of
possible systematically matched observations. Figure 7.8, for
instance, shows the consequence of selecting the grid cell
representing the intersection of the “5” unit of JobSat and
JobMorale observations after the Imprecision value was set to
1. As can be seen, the expected pattern includes the matched
“5” units of observation, but also observations that deviate by
one unit in either direction for both JobSat and JobMorale. A
cross is therefore formed when a cell of the grid is selected.
Setting the Imprecision value to 2 would generate a larger cross
entailing deviations of +/- 2 units of observations. Selecting the
Diagonal fill option will furthermore create a pattern that
appears as a box, essentially filling in the space generated by
the arms of the cross. For instance, Figure 7.9 shows the
consequence of selecting the crossed “5” units of JobSat and
JobMorale after the Imprecision value was set to 1 and the
Diagonal fill option was selected.
Figure 7.8
Imprecision
set to 1, and
Include
Diagonal
Not Selected
Figure 7.9
Include
Diagonal
Selected
62
OOM Software Manual
It is naturally up to the user to determine if the diagonal
elements in the imprecision area are to be included in the
pattern.
Examination of Figures 7.6 and 7.7 suggest on a purely
post hoc basis that the crossed JobSat and JobMorale
observations for both males and females are matched in a unitto-unit fashion give-or-take 1 unit. Setting the Imprecision
value to 1 and defining the patterns, it can be seen in Figures
7.10 and 7.11 that indeed nearly all of the observations can be
accounted by such descriptions. Again, the pattern is opposite
for the two sexes. The overall pattern, which is 3-dimensional,
can be saved by selecting the [Save File] button and reloaded at
a later date to conduct the analysis again. After selecting [OK]
to accept the defined pattern, the [OK] button on the Pattern
Analysis window in Figure 7.5 is selected to conduct the
analysis. Figure 7.12 shows the annotated output which
summarizes the impressive results. All but one of the 15
observations were accurately modeled with the defined pattern,
PCC = 93%, and the c-value was extremely low (c < .001). The
individual results show the single female who did not conform
to the pattern. The individual results can be saved to a new set
of observations for further analysis, manipulation, or storing
for future uses.
Figure 7.10
Pattern for
Males
Figure 7.11
Pattern for
Females
63
OOM Software Manual
64
Figure 7.12
Annotated Output for Crossed Pattern Analysis, Gender as Third Order
Pattern Analysis (Crossed Observations) for Pattern Crossed
Example Data Set
Missing Values = Omitted from Totals
Randomization Method = Randomize Observations
Defined Pattern :
Ext
| 2
| |
| |
| |
| |
| |
| |
| |
| |
+ +
+ +
O +
O O
O O
O O
O O
O O
O O
O O
The options selected by the user are reported here.
Male
Low
3
|
|
|
|
|
|
|
O
+
+
+
O
O
O
O
O
O
4
|
|
|
|
|
|
O
O
+
+
+
O
O
O
O
O
5
|
|
|
|
|
O
O
O
+
+
+
O
O
O
O
6
|
|
|
|
O
O
O
O
+
+
+
O
O
O
7
|
|
|
O
O
O
O
O
+
+
+
O
O
8
|
|
O
O
O
O
O
O
+
+
+
O
9
|
O
O
O
O
O
O
O
+
+
+
Ext High
O Ext Dissatisfied
O 2
O 3
O 4
O 5
O 6
O 7
O 8
+ 9
+ Ext Satisfied
The pattern defined for the males is reported. The pattern for the females is
also shown in the OOM output, but has been deleted here for brevity.
Defined Pattern : Female (Not Shown Here)
Classification Results
Pairs of Observations Classified According to the Defined
Pattern(s)
Classifiable Pairs of Observations : 15
Correct Classifications : 14
Percent Correct Classifications : 93.33
Fourteen of the 15 observations conformed to the expected pattern of results
shown in Figures 7.10 and 7.11. The PCC index is therefore 93.33 (14/15),
an impressive result by any standard of judgment.
OOM Software Manual
65
Figure 7.12 (Continued)
Randomization Results
Observed Percent Correct Classified : 93.33
Number of Randomized Trials : 1000
Minimum Random Percent Correct : 0.00
Maximum Random Percent Correct : 73.33
Values >= Observed Percent Correct : 0
Model c-value : less than ( 1 / 1000;
that is, < 0.001
The PCC index value of 93.33 is repeated here and the number of requested
randomized trials (1000) reported. The minimum percentage of correct
classifications for the 1000 randomized trials was 0 and the maximum was
73.33; therefore, not for a single trial did a PCC value from the randomized
observations equal or exceed 93.33. The c-value is thus less than 1/1000, or
less than .001, which is not surprising given the high observed PCC index,
the number of observations (15), and the high number of crossed units (100,
or 10 x 10).
Individual Classification Results
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
case_13
case_14
case_15
Classification Result
|
JobSat
|
|
JobMorale
|
|
|
Gender
|
|
|
|
1
10
9
1
0
9
4
2
1
7
7
1
1
9
8
1
1
1
9
2
1
1
1
1
1
4
4
1
1
7
3
2
1
8
3
2
1
6
6
1
1
2
8
2
1
7
4
2
1
6
5
1
1
6
4
2
1
7
4
2
Note. Classification Result: 1 = Correct; 0
= Incorrect.
The individual results report whether or not each observation conformed to
the expected pattern (1 = match, 0 = no match), and the original units of
observations for the First, Second, and Third orderings are reported for
convenient reference as well. It can be seen that the single mis-classified
person was “case_2”, a female. Her crossed JobSat and JobMorale
observations can be seen in Figure 7.11. This table of results can be saved
to a new data set that can be manipulated, analyzed, and stored by selecting
the Save Individual Results option in seen in Figure 7.1 or 7.5.
OOM Software Manual
Options
Define Pattern
Selecting the [Define Pattern] button opens the Define
Pattern window first shown in Figure 7.6 above. As has been
described, it is in this window the user defines the expected
pattern of observations, ideally based on an integrated model.
Missing Values
There are two options for missing values: Omit from
Totals and Include in Totals. As it is easiest to describe these
two options via example, consider the following ordered
observations for 15 people:
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
case_13
case_14
case_15
JobSat JobMorale
10
9
9
4
7
7
.
8
1
.
1
1
4
4
7
3
8
3
6
6
2
8
7
4
6
5
6
4
7
4
Gender
.
2
1
1
2
1
1
2
2
1
2
2
1
2
2
File: PatternCrossedMissing.oom
This is the same set of observations used above, but note how
three observations have been deleted, one each for the JobSat,
JobMorale, and Gender orderings. Using the patterns for males
and females in Figures 7.10 and 7.11, a three dimensional
66
expected pattern can again be tested. Choosing either Omit
from Totals or Include in Totals option, the summary appears
as follows:
Ordering Frequency Summaries
JobSat
JobMorale
Gender
Totals
Units:
Units:
Units:
Units:
10
10
2
22
Missing:
Missing:
Missing:
Missing:
1
1
1
3
Undefined
Undefined
Undefined
Undefined
:
:
:
:
0
0
0
0
Obs:
Obs:
Obs:
Obs:
14
14
14
42
The three missing values, one for each ordering, are noted. The
total number of cases is 15, and only 12 of those have a
complete set of observations. The first person, “case_1”,
excludes a gender observation, and therefore cannot be
classified because a pattern from 7.10 or 7.11 cannot be chosen.
In other words, which pattern should be used for “case_1”?
The other two cases with missing observations (case_4, case_5)
cannot be classified correctly on the basis of either pattern
because they are missing at least one observation for the
crossed orderings. To omit these three cases (persons) from the
analysis, the Omit from Totals options should be chosen. The
resulting output for the PCC index will appear as:
Classification Results
Pairs of Observations Classified According to
the Defined Pattern(s)
Classifiable Pairs of Observations : 12
Correct Classifications : 11
Percent Correct Classifications : 91.67
Note how the “Classifiable Pairs of Observations” is equal to
12, and the resulting PCC index is 91.67 (11/12).
OOM Software Manual
To include the three cases (persons) in the analysis, the
Include in Totals option should be chosen. Doing so yields the
following output for the same expected pattern:
Classification Results
Pairs of Observations Classified According to
the Defined Pattern(s)
Classifiable Pairs of Observations : 15
Correct Classifications : 11
Percent Correct Classifications : 73.33
Note that all 15 cases (persons) are now included in the
“Classifiable Pairs of Observations”, resulting in a lower PCC
index of 73.33 (11/15).
The Randomization Test will employ the PCC index for
the observed results in accord with the missing value option
chosen. No other output or results will differ for the two
options.
Randomization Test
As with other analyses in OOM, selecting the
Randomization Test will result in a c-value being computed
and reported in the Text Output window. There are two ways to
randomize in the Pattern Analysis: Crossed Observations
analysis: Randomize All Observations or Randomize Deep
Structures.
The default option (see Figure 7.1) is Randomize All
Observations. With this option, the actual observations for the
Second Ordering chosen by the user are randomly shuffled. If
a Third Ordering is chosen, such as Gender in this example,
67
then the Third Ordering observations are randomly shuffled as
well. The First Ordering observations could be shuffled as well,
but randomizing the Second and Third orderings is sufficient
and more efficient.
If a two-dimensional pattern is created and tested (as
when the user selects only a First and Second Ordering to
analyze), the goal is simply to create random pairs of the actual
observations. Consider the following observations:
case_1
case_2
case_3
case_4
JobSat JobMorale
10
9
9
4
7
7
9
8
Gender
1
2
1
1
A randomized version of the observations would be as follows:
case_1
case_2
case_3
case_4
JobSat JobMorale
10
4
9
7
7
9
9
8
Gender
1
2
1
1
If Gender is included as the Third Ordering for a threedimensional pattern, then a randomized version of the
observations would be as follows:
case_1
case_2
case_3
case_4
JobSat JobMorale
10
8
9
4
7
7
9
9
Gender
1
1
2
1
Notice how both the JobMorale and Gender observations have
now been randomly shuffled.
OOM Software Manual
A given number of such randomized versions of the
data, set by the user as Number of Trials, are created, and in
every case a PCC index is computed. The PCC index for the
actual data is then compared to the PCC indices from the
randomized versions of the data, and the c-value computed.
Choosing the Randomize Deep Structure option will not
randomize the actual observations. Instead the test works by
randomly determining the deep structures of each of the three
orderings chosen for the pattern. Consider the deep structure of
the JobSat observation for the first person above (case_1) with
a value of 10:
0
0
0
0
0
0
0
0
0
1
A randomized version of this observation is based on a random
determination for the column location of the 1; for example,
0
1
0
0
0
0
0
0
0
0
or
0
0
0
0
0
0
0
0
1
0.
Each row of the deep structure matrix (i.e., each person in this
example) is similarly randomly determined. The deep
structures for this person’s JobMorale and Gender observations
will also be randomly determined. The deep structures of all
three orderings are therefore randomly determined with the
Randomize Deep Structure option. By selecting this option for
the Randomization Test, then, the user is essentially asking,
“how often can I obtain a PCC index as high or higher than the
observed PCC index, if the observations are randomly created
within the context of the given deep structures (e.g., two 10-
68
unit structures and one 2-unit structure)?” This is distinct from
the question asked when choosing the Randomize Observations
option: “If I randomly pair the First, Second Order, and Third
Order observations in the pattern, how frequently can I obtain a
PCC index as high or higher than the observed PCC index?”
Because OOM places a premium on the observations obtained
through careful work, the Randomize Observations option is
set as the default and may generally be preferred.
Output
The defined patterns, ordering summaries, and
individual classification results can all be printed to the Text
Output window by selecting these options. In addition, the
individual classification results can be saved to a new data
spreadsheet by selecting the Save Individual Results option.
The annotated output in Figure 7.12 provides descriptions of
the output generated by these options.
OOM Software Manual
8
Pattern Analysis: Concatenated
Observations
69
agreeableness/disagreeableness and are ordered according to a
five-point Likert-type scale anchored with values of -2 and +2;
for example,
I am a person who is generally easy to get along with.
This analysis can be used to evaluate patterns of
observations made upon the same people, events, animals, etc.,
simultaneously or over time. The observations may be
considered as entirely distinct (e.g., personality traits, hair color,
biological sex) or of the same class of qualities (e.g.,
extraversion, agreeable, and conscientious personality traits).
They may also be repeated observations of the same quality
over time, such as observations of individuals’ body
temperatures over the course of several days.
Consider the following ordered observations of 14
different people:
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
case_13
case_14
Ext/Int Agr/Dis Hand
2
2
1
1
1
1
1
-2
2
2
-1
2
0
1
3
-1
2
3
-2
0
3
-1
2
3
-1
2
3
-2
2
3
-2
-1
3
0
1
3
1
2
3
-1
2
1
Gender
1
1
1
1
1
1
1
2
2
2
2
2
2
2
File: PatternConcatExample.oom
The first and second columns of observations regard selfassessments of extraversion/introversion and
Highly
Agree
2
Agree
1
Neither
0
Disagree
-1
Highly
Disagree
-2
The third column of observations regards handedness ordered
as 1=left, 2=ambidextrous, and 3=right. The final column of
observations regards biological sex ordered as 1=male and
2=female.
As an initial example analysis, the pattern of
extraversion and agreeableness observations can be examined.
As shown in Figure 8.1 the Ext/Int and Agr/Dis orderings have
been moved into the Concatenated Observations box. The
Randomization Test and Individual Classifications options
have also been selected. The expected pattern of observations
is defined by selecting the Define Pattern(s) button, which
opens the window shown in Figure 8.2. The figure shows the 2 to +2 rating scale which in this case is common to the two
sets of concatenated observations, Ext/Int and Agr/Dis. The
expected pattern of observations is created/defined by clicking
the units with the left mouse button. A clicked unit will turn
green. Clicking a unit with the right mouse button will deselect
the unit and turn it back to white. Figure 8.2 shows the units of
1 and 2 representing extraversion and agreeableness have been
selected; in other words, the 14 people are expected to endorse
the 1 or 2 points on the two personality questions. The image
representing the expected pattern can be saved or printed by
selecting the [Save] or [Print] Image Options. The image will
OOM Software Manual
Figure 8.1 Pattern Analysis for Concatenated Observations Window
Figure 8.2 Define Concatenated Pattern Window
Figure 8.3 Define Concatenated Pattern: Observations Shown
be saved as a Windows Bitmap image file. Selecting the All
Observations radio button (see Figure 8.2) includes the actual
observations in the image. Figure 8.3 shows the observations
and reveals that 10 of the 14 people were observed to endorse
the 1 or 2 scale points for Agr/Dis, but only 5 people endorsed
the 1 or 2 scale points for Ext/Int. Despite the observations not
lining up exactly as expected, the [OK] button is selected to
accept this definition which is presumably driven by an
integrated model. The [OK] button on the Pattern Analysis
window in Figure 8.1 is then selected to conduct the analyses.
The annotated output is shown in Figure 8.4.
70
OOM Software Manual
71
Figure 8.4 Annotated Output for Concatenated Pattern Analysis
Pattern Analysis (Observation Concatenation) for Concatenated
Pattern Example
The Missing Values option chosen is reported here.
Missing Values = Omitted from Totals
Ordering Frequency Summaries
Ext/Int
Agr/Dis
Totals
Units: 5
Units: 5
Units: 10
Missing: 0
Missing: 0
Missing: 0
Undefined: 0
Undefined: 0
Undefined: 0
Obs: 14
Obs: 14
Obs: 28
The summary shows that all observations have been defined and accounted
for. No missing observations are reported. The Ext/Int and Agr/Dis
orderings each have five units corresponding to the five points on the
Likert-type scale.
Defined Pattern : All Observations
Ext/Int
| Agr/Dis
O O -2
O O -1
O O
0
+ +
1
+ +
2
Classification Results : All Observations
Observations Classified According to the Defined
Pattern(s)
Classifiable Observations : 28
Correct Classifications : 15
Percent Correct Classifications : 53.57
Classifiable Complete Cases : 14
Correctly Classified Complete Cases : 3
Percent Correct Classified Cases : 21.43
The pattern of expected observations is reported and shows that each person
(case) is expected to have endorsed the “agree” (1) or “highly agree” (2)
scale options.
As noted in the text above, 10 people endorsed the Agr/Dis question as
expected, and only 5 endorsed the Ext/Int item as expected, yielding a total
of 15 Correct Classifications. Because there are no missing observations, a
total of 28 (14 people x 2 orderings) correct classifications is possible. The
Percent Correct Classifications is therefore 53.57 (15/28), and does not
indicate impressive accuracy. A “complete case” is one for which both the
Ext/Int and Agr/Dis observations are consistent with the expected pattern.
In other words, a complete case is tallied in this example when the person
endorses either 1 or 2 on the scale for both the Ext/Int and Agr/Dis items.
As shown, only 3 people matched the expected pattern completely, yielding
a dismal PCC of only 21.43 (3/14).
OOM Software Manual
72
Figure 8.4 (Continued)
Randomization Results : All Observations
Observed Percent Correct Classifications : 53.57
Number of Randomized Trials
Minimum Random Percent Correct
Maximum Random Percent Correct
Values >= Observed Percent Correct
Model c-value
:
:
:
:
:
1000
14.29
71.43
107
0.11
Observed Percent Correct Classified Cases : 21.43
Number of Randomized Trials
Minimum Random Percent Correct Cases
Maximum Random Percent Correct Cases
Values >= Observed Percent Correct Cases
Model c-value
:
:
:
:
:
1000
0.00
50.00
382
0.38
Individual Classification Results
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
case_13
case_14
Result:Ext/Int
|
Result:Agr/Dis
|
|
Classifiable Observations
|
|
|
Correct Classifications
|
|
|
|
PCC
|
|
|
|
|
1
1
2
2
100.00
1
1
2
2
100.00
1
0
2
1
50.00
1
0
2
1
50.00
0
1
2
1
50.00
0
1
2
1
50.00
0
0
2
0
0.00
0
1
2
1
50.00
0
1
2
1
50.00
0
1
2
1
50.00
0
0
2
0
0.00
0
1
2
1
50.00
1
1
2
2
100.00
0
1
2
1
50.00
Note. Result: 1 = Correct Classification; 0 = Incorrect
Classification.
A randomization test is conducted for both PCC values (53.57 and 21.43).
The Number of Randomized Trials was set in Figure 7.1 and is repeated in
the output. For the first PCC value, the 1000 randomized versions of the
data yielded a maximum PCC equal to 71.43 (20/28). The minimum value
was 14.29 (4/28). The results for all 1000 trials can be examined, not just
these two extreme values, by selecting the Save Randomized Results option
in Figure 7.1. One-hundred seven of the1000 randomized trials (107/1000
= .11) yielded a PCC value equal to or greater than 53.57. This is an
impressively low c-value, indicating a distinct pattern within the
observations; however, the observed PCC value is not very high (53.57%),
and most of the correct classifications are obtained from the Agr/Dis
ordering. This fact helps to explain why the c-value for the percentage of
complete cases is unimpressive at .38. Almost four-hundred of the
randomized versions of the observations (382) yielded a percentage of
complete correct classifications equal to or greater than 21.43. The
distinctiveness in the pattern of observations thus seems to be limited to the
Agr/Dis ordering under the current expectations.
Individual results for the 14 people are presented. A value of 1 in the first
two columns indicates a match (correct classification) between the expected
observation and the actual observation. The first person, “case_1”, for
instance rated himself as a 1 or 2 on both the Ext/Int and Agr/Dis items. His
Correct Classifications is therefore tallied as “2.00” and converted to a
percentage of 100. It can be seen that “case_2” and “case_13” were also
perfectly matched. “case_7” rated himself on the introverted and
disagreeable sides of the scales, and his Correct Classifications and
Percent Correct Classifications (abbreviated PCC) are therefore zero.
“case_11” also did not rate herself as expected, and the remaining
individuals were observed according to expectation on either the Ext/Int or
Agr/Dis items, but not both (Percent Correct Classifications = 50.00). It
can be clearly seen in the second column, however, that most of the matches
(correct classifications) were obtained for the Agr/Dis observations.
OOM Software Manual
The algorithm for the concatenated pattern analysis is
straightforward. Deep structures for the concatenated
observations are generated, and the numbers of observations
that are consistent with the defined, expected pattern are simply
tallied. As shown in the annotated output above, they are tallied
in terms of individual matches (Correct Classifications) and in
terms of complete case matches (Correct Case Classifications)
across all concatenated orderings.
As a second example, the handedness observations can
be added to the expected pattern and the observations can be
separated into two groups according to the gender observations.
Figure 8.5 shows the Pattern Analysis window for this example.
Again, the individual results are requested as is a
randomization test with 1000 trials.
Figure 8.5
Pattern
Analysis
Window for
Second
Example
73
Given the additional observations, suppose the expected pattern
of observations is now different; specifically, the males are
expected to be extraverted, agreeable, and left handed whereas
the females are expected to be introverted, agreeable, and right
handed. Figure 8.6 shows the defined pattern for the males
(note the “Male” label in the edit box above the left-hand
corner of the pattern image). By default, OOM uses the unit
labels for the first observations entered into the concatenation
process; hence, the -2, -1, 0, 1, and 2 labels along the left edge
of the pattern. Recall from above the handedness units are
coded as 1=left, 2=ambidextrous, and 3=right. These labels are
not shown in the pattern image, but the top-most unit is the first
defined unit and therefore represents left-handed people. The
second row under “Hand” represents ambidextrous
observations and the third row represents right-handed
observations. The black units indicate that the handedness
ordered observations are comprised of only 3 units compared
to the 5 units for the other orderings. The selected green units
in Figure 8.6 show that the males are expected to be
extraverted, agreeable, and left-handed. The pattern for the
females is defined by selecting the right arrow of the doublearrow button adjoining the edit box labeled “Male.” After
choosing the arrow and defining the pattern, Figure 8.7 shows
the expected pattern of observations for the females. The
pattern also includes the observations themselves, and again
the green units show that the females are expected to be
introverted, agreeable, and right handed. After the patterns are
defined the analysis yields the results, which are annotated, in
Figure 8.8.
OOM Software Manual
Figure 8.6
Expected Pattern of
Results for Males,
Second Example
Figure 8.7
Expected Pattern of
Results for Females,
Second Example
74
This second example shows that the observations can
be constituted of differing numbers of units. The two
personality observations above were ordered into 5 units each,
and the handedness observations were ordered into 3 units. The
observations were nonetheless concatenated as shown in
Figures 8.6 and 8.7. It must be kept in mind that the labels
defining the rows of the patterns in the Define Concatenated
Pattern window are automatically derived from the ordered
observations that make up the first column. The original labels
for the other observations may have to be referenced to recall
their order. In Figures 8.6 and 8.7, for instance, handedness
was defined as 1=left, 2=ambidextrous, and 3=right which
corresponded to the first three rows in the pattern. This
example also shows that different patterns can be defined for
different units of observation, in this case males and females.
Any number of different units could similarly be differentiated.
OOM Software Manual
75
Figure 8.8 Annotated Output for Second Example
Pattern Analysis (Observation Concatenation) for Concatenated
Pattern Example
Missing Values = Omitted from Totals
Defined Pattern :
Because the patterns were defined separately for males and females, the
results are determined and reported separately as well. Here the results for
males are shown in the same format as those in Figure 8.4 above.
Male
Ext/Int
| Agr/Dis
| | Hand
O O + -2
O O O -1
O O O
0
+ + 1
+ + 2
The expected pattern for the males is reported.
Classification Results :
Male
Observations Classified According to the Defined
Pattern(s)
Classifiable Observations :
Correct Classifications :
Percent Correct Classifications :
21
10
47.62
Classifiable Complete Cases :
Correctly Classified Complete Cases :
Percent Correct Classified Cases :
7
2
28.57
Randomization Results :
There are seven males in the data set and three orderings (Ext/Int, Agr/Dis,
Hand), resulting in 21 Classifiable Observations. Ten of the observations
matched the pattern for males. The Percent Correct Classifications is
therefore 47.62. The Percent Correct Classified Cases is only 28.57 (2
males matched the pattern completely across all three orderings). Neither
PCC index is very impressive.
Male
Observed Percent Correct Classifications : 47.62
Number of Randomized Trials
Minimum Random Percent Correct
Maximum Random Percent Correct
Values >= Observed Percent Correct
Model c-value
:
:
:
:
:
1000
4.76
71.43
235
0.24
The c-value for the individual matches (correct classifications) is not very
impressive at .24, whereas the c-value for the complete matches (next page)
is much lower and impressive at .05. Although only 2 of the 7 males were
perfectly matched (29%), the fact that three orderings were involved makes
such an outcome highly unlikely when the deep structures are randomized
as described in the Randomization Test section of this chapter.
OOM Software Manual
76
Figure 8.8 (Continued)
Observed Percent Correct Classified Cases : 28.57
Number of Randomized Trials
Minimum Random Percent Correct Cases
Maximum Random Percent Correct Cases
Values >= Observed Percent Correct Cases
Model c-value
:
:
:
:
:
1000
0.00000
42.86
49
0.05
Individual Classification Results : Male
case_1
case_2
case_3
case_4
case_5
case_6
case_7
Result:Ext/Int
|
Result:Agr/Dis
|
|
Result:Hand
|
|
|
Classifiable Observations
|
|
|
|
Correct Classifications
|
|
|
|
|
PCC
|
|
|
|
|
|
1
1
1
3
3
100.00
1
1
1
3
3
100.00
1
0
0
3
1
33.33
1
0
0
3
1
33.33
0
1
0
3
1
33.33
0
1
0
3
1
33.33
0
0
0
3
0
0.00
The individual results for the males show that “case_1” and “case_2” are
perfectly matched (100% PCC values) across all three ordered observations:
Ext/Int, Agr/Dis, and Handedness. All of the other males are matched on at
most one of the three orderings (PCC = 33.33; 1/3). Again, the results are
not impressive. The expected pattern did not accurately represent the male
observations.
Note. Result: 1 = Correct Classification; 0 = Incorrect
Classification.
Defined Pattern :
Ext/Int
| Agr/Dis
| | Hand
+ O O -2
+ O O -1
O O +
0
O + 1
O + 2
Female
The analysis now switches to the females. Their expected pattern is first
reported here.
OOM Software Manual
77
Figure 8.8 (Continued)
Classification Results :
Female
Observations Classified According to the Defined
Pattern(s)
Classifiable Observations : 21
Correct Classifications : 17
Percent Correct Classifications : 80.95
The results for the females are much more impressive, with the Percent
Correct Classifications equal to 80.95 (17/21). The Percent Correct
Classified Cases is nearly 43% (3/7 * 100), although still not very high.
Overall, the pattern fit better for the females, particularly if complete cases
are not considered.
Classifiable Complete Cases : 7
Correctly Classified Complete Cases : 3
Percent Correct Classified Cases : 42.86
Randomization Results :
Female
Observed Percent Correct Classifications : 80.95
Number of Randomized Trials : 1000
Minimum Random Percent Correct : 9.52
Maximum Random Percent Correct : 66.67
Values >= Observed Percent Correct : 0
Model c-value : less than ( 1 / 1000);
that is, < 0.001
Observed Percent Correct Classified Cases : 42.86
Number of Randomized Trials
Minimum Random Percent Correct Cases
Maximum Random Percent Correct Cases
Values >= Observed Percent Correct Cases
Model c-value
:
:
:
:
:
1000
0.00
57.14
6
0.01
The c-values are both very impressive. Not one time in one thousand trials
was a PCC value found to equal or exceed 80.95%. The c-value is therefore
less than .001. For the complete case matches, the c-value is again
impressive and equal to .01 (.006, 6/1000). Only six times in 1000
randomized trials was a PCC value of 42.86 or higher obtained.
OOM Software Manual
Figure 8.8 (Continued)
Individual Classification Results : Female
case_8
case_9
case_10
case_11
case_12
case_13
case_14
Result:Ext/Int
|
Result:Agr/Dis
|
|
Result:Hand
|
|
|
Classifiable Observations
|
|
|
|
Correct Classifications
|
|
|
|
|
PCC
|
|
|
|
|
|
1
1
1
3
3
100.00
1
1
1
3
3
100.00
1
1
1
3
3
100.00
1
0
1
3
2
66.67
0
1
1
3
2
66.67
0
1
1
3
2
66.67
1
1
0
3
2
66.67
Note. Result: 1 = Correct Classification; 0 = Incorrect
Classification.
The individual results show that the first three females are perfectly
matched across all three orderings of observations, and the other four
females are matched on at least two of the three orderings. Again, the
results are fairly impressive for the females.
78
OOM Software Manual
Options
Define Pattern
Selecting the [Define Pattern(s)] button opens the
Define Pattern window first shown in Figure 8.2 above. As has
been described, it is in this window the user defines the
expected pattern(s) of observations, ideally based on an
integrated model.
Missing Values
There are two options for missing values: Omit from
Totals and Include in Totals. The two options can most easily
be described via an example. Consider the same ordered
observations from above for 14 people and for which three
observations have been deleted:
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
case_13
case_14
Ext/Int Agr/Dis Hand
2
2
1
1
1
1
1
-2
2
2
-1
2
0
1
3
-1
2
3
-2
0
3
-1
2
3
-1
2
3
-2
2
3
.
-1
3
0
.
3
1
2
3
-1
2
1
Gender
1
1
1
.
1
1
1
2
2
2
2
2
2
2
File: PatternConcatMissing.oom
Recall for the second analysis example above that the Gender
observations were used to separate 14 people into two groups,
males and females. The other three orderings of observations
79
were concatenated and conformed to the patterns shown in
Figures 8.6 and 8.7. One of the male’s Gender observations has
been deleted, and two observations on the other three orderings
have been deleted for the 7 females.
The annotated output in Figure 8.9 shows that the
fourth person (case_4) has essentially been excluded from the
analysis because his observations could not be placed into
either the male or female group because of the missing Gender
observation. This is tantamount to what is referred to as
listwise deletion in modern parlance. Figure 8.9 also shows that
when observations are missing on the concatenated orderings,
the missing observations are automatically tallied as nonmatches; that is, as observations that do not conform to the
expected pattern. The missing observations are still included in
the overall number of actual (or potential) observations for the
concatenated orderings.
OOM Software Manual
80
Figure 8.9 Annotated Output for Missing Values Example
Pattern Analysis (Observation Concatenation) for Concatenated
Pattern Missing
The Missing Values option was set to Omitted from Totals
Missing Values = Omitted from Totals
Classification Results :
Male
Observations Classified According to the Defined
Pattern(s)
Classifiable Observations : 18
Correct Classifications : 9
Percent Correct Classifications : 50.00
Classifiable Complete Cases : 6
Correctly Classified Complete Cases : 2
Percent Correct Classified Cases : 33.33
Individual Classification Results :
case_1
case_2
case_3
case_5
case_6
case_7
Male
Result:Ext/Int
|
Result:Agr/Dis
|
|
Result:Hand
|
|
|
Classifiable Observations
|
|
|
|
Correct Classifications
|
|
|
|
|
PCC
|
|
|
|
|
|
1
1
1
3
3
100.00
1
1
1
3
3
100.00
1
0
0
3
1
33.33
0
1
0
3
1
33.33
0
1
0
3
1
33.33
0
0
0
3
0
0.00
Note. Result: 1 = Correct Classification; 0 = Incorrect
Classification.
There were 7 males in the original data set, and in this example the Gender
observation for one male was deleted. Consequently, there were 6 males
with observations on three other orderings (Ext/Int, Agr/Dis, and Hand) for
a total of 18 (3 x 6) observations. Nine of the 18 observations (50%)
conformed to the expected pattern. Only 2 of the 6 males’ (33%)
observations on the three ordering conformed perfectly to the expected
pattern.
By selecting Omitted from Totals, the missing observations are not included
in the tallies of total possible observations.
case_4 is not reported here because his Gender observation has been deleted
in this example. Note that all of the remaining six males did not have
missing observations (Classifiable Observations = 3).
OOM Software Manual
Figure 8.9 (Continued)
Classification Results :
Recall the Missing Values option was set to Omitted from Totals
Female
Observations Classified According to the Defined
Pattern(s)
Classifiable Observations : 19
Correct Classifications : 15
Percent Correct Classifications : 78.95
Classifiable Complete Cases : 5
Correctly Classified Complete Cases : 3
Percent Correct Classified Cases : 60.00
Individual Classification Results :
case_8
case_9
case_10
case_11
case_12
case_13
case_14
81
There were 7 females in the original data set with observations on three
orderings, resulting in 21 possible observations (3 x 7). However, two
observations were missing for the Ext/Int and Agr/Dis orderings, resulting
in a total of 19 Classifiable Observations. When the Omitted from Totals
option is chosen, the missing values are not included in the Classifiable
Observations total.
There were 7 women. The two missing values were for two different
women; consequently, the number of Classifiable Complete Cases is 5.
Female
Result:Ext/Int
|
Result:Agr/Dis
|
|
Result:Hand
|
|
|
Classifiable Observations
|
|
|
|
Correct Classifications
|
|
|
|
|
PCC
|
|
|
|
|
|
1
1
1
3
3
100.00
1
1
1
3
3
100.00
1
1
1
3
3
100.00
0
1
2
1
50.00
0
1
2
1
50.00
0
1
1
3
2
66.67
1
1
0
3
2
66.67
Note. Result: 1 = Correct Classification; 0 = Incorrect
Classification.
Case_11 was missing an observation for Ext/Int and case_12 was missing
an observation for Agr/Dis; consequently, the Classifiable Observations are
equal to 2 for each of these women (cases). results are reported as nonmatches (zeros) in this table. The PCC values are based on these values; for
example, for case_12, one of the two observations fit the pattern (1/2 = .50),
yielding a PCC equal to 50%.
OOM Software Manual
82
Figure 8.9 (Continued)
Pattern Analysis (Observation Concatenation) for Concatenated
Pattern Missing
Now the Missing Values option was set to Included in Totals.
Missing Values = Included in Totals
Classification Results :
Male
Observations Classified According to the Defined
Pattern(s)
Classifiable Observations : 18
Correct Classifications : 9
Percent Correct Classifications : 50.00
The results are identical for males. With Gender missing, the person’s
observations cannot be included for the simple fact that the person does not
fit into either category, male/female. The results for the females below will
be different.
Classifiable Complete Cases : 6
Correctly Classified Complete Cases : 2
Percent Correct Classified Cases : 33.33
Individual Classification Results :
case_1
case_2
case_3
case_5
case_6
case_7
Male
Result:Ext/Int
|
Result:Agr/Dis
|
|
Result:Hand
|
|
|
Classifiable Observations
|
|
|
|
Correct Classifications
|
|
|
|
|
PCC
|
|
|
|
|
|
1
1
1
3
3
100.00
1
1
1
3
3
100.00
1
0
0
3
1
33.33
0
1
0
3
1
33.33
0
1
0
3
1
33.33
0
0
0
3
0
0.00
Note. Result: 1 = Correct Classification; 0 = Incorrect
Classification.
Again, the male’s Gender observation was deleted, so he is completely
removed from the analysis. No other males had missing observations for the
three other orderings.
OOM Software Manual
83
Figure 8.9 (Continued)
Recall the Missing Values option was now set to Included in Totals
Classification Results :
Female
Observations Classified According to the Defined
Pattern(s)
Classifiable Observations : 21
Correct Classifications : 15
Percent Correct Classifications : 71.43
Classifiable Complete Cases : 7
Correctly Classified Complete Cases : 3
Percent Correct Classified Cases : 42.86
Individual Classification Results :
case_8
case_9
case_10
case_11
case_12
case_13
case_14
There were 7 females in the original data set with observations on three
orderings, resulting in 21 possible observations (3 x 7). It can be seen that
21 is now equal to the Classifiable Observations. In other words, the two
missing values for the females are now included in the total number of
observations. Moreover, each missing value will be counted as an incorrect
classification (see individual results below).
There were 7 women, and again, the two missing values are not excluded
from the total number of observations; consequently, the number of
Classifiable Complete Cases is 7.
Female
Result:Ext/Int
|
Result:Agr/Dis
|
|
Result:Hand
|
|
|
Classifiable Observations
|
|
|
|
Correct Classifications
|
|
|
|
|
PCC
|
|
|
|
|
|
1
1
1
3
3
100.00
1
1
1
3
3
100.00
1
1
1
3
3
100.00
0
0
1
3
1
33.33
0
0
1
3
1
33.33
0
1
1
3
2
66.67
1
1
0
3
2
66.67
Note. Result: 1 = Correct Classification; 0 = Incorrect
Classification.
Case_11 was missing an observation for Ext/Int and case_12 was missing
an observation for Agr/Dis. Because “Included in Totals” was selected as
the Missing Values option, these missing values are treated as incorrectly
classified (note the zeros in the first two columns). All Classifiable
Observations values are equal to 3. The PCC indices for case_11 and
case_12 are now equal to 33.33 (1/3); whereas with the “Omitted from
Totals” option, the PCC indices were equal to 50% (see above).
OOM Software Manual
84
Randomization Test
Ext/Int [Deep Structure]
Because deep structures are not being rotated to
conformity, and because the observations are being compared
to an expected pattern, the randomization test works on the
basis of the units of observation rather than upon the
observations themselves. For example, Ext/Int is ordered into 5
units of observation, designated as -2, -1, 0, 1, and 2. The deep
structure for the fourteen people above is as follows, with the
five matches printed in red,
Ext/Int [Deep Structure]
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
case_13
case_14
-2
-1
0
1
2
0
0
0
0
0
0
1
0
0
1
1
0
0
0
0
0
0
0
0
1
0
1
1
0
0
0
0
1
0
0
0
0
1
0
0
0
0
0
0
1
0
0
0
1
1
0
0
0
0
0
0
0
0
0
1
0
1
0
0
1
0
0
0
0
0
0
0
0
0
0
A randomized version of this deep structure matrix does not
shuffle the rows, as is often done in OOM, but instead shuffles
the locations of the 1’s in the different columns as, for instance,
in the following matrix,
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
case_13
case_14
-2
1
0
0
0
1
1
0
0
0
0
0
0
0
1
-1
0
0
1
0
0
0
0
0
1
0
0
0
1
0
0
0
0
0
0
0
0
1
1
0
0
0
1
0
0
1
0
0
0
0
0
0
0
0
0
1
0
0
0
0
2
0
1
0
1
0
0
0
0
0
0
1
0
0
0
Comparing this randomized deep structure with the expected
pattern in Figure 8.2 reveals only four matches, one less than
the actual observations. The deep structure for Agr/Dis is
randomized in a similar manner and the number of matches
tallied. The number of complete matches is also tallied in this
process. In the annotated output above, 1000 such
randomizations were completed and the tallies and proportions
recorded and summarized.
In some instances, then, the c-value can be computed
using well-known rules of probability. Consider, for instance,
three observations, all of which match completely,
case_1
case_2
case_3
Ext/Int Agr/Dis
1
1
1
1
2
2
Each observation is ordered into 5 units; hence, assuming
independence between units, each has an associated probability
OOM Software Manual
of .40 (2/5 given that two of the five units are counted as
matches, or correct classifications). The combined probability
of matching for both Ext/Int and Agr/Dis is therefore .402,
or .16. The probability that all three persons will be tallied as
complete matches is finally .163, or .0041. If only the three
observations are analyzed using the Pattern Analysis:
Concatenated Observations and the pattern shown in Figure
8.2, the randomization test will yield a c-value approximately
equal to .0041. For example, conducting the analysis 6
different times with 5000 randomized trials yielded the
following results: .0050, .0040, .0038, .0036, .0044, .0032 (M
= .0040). Clearly, the value is asymptotically
approaching .0041. The c-value therefore indicates the
frequency which a matching proportion at least as high as the
value tallied for the actual data is obtained when random
observations are generated under the assumption of complete
independence.
Why not randomize the rows of observations? The
reason is that it would have no effect on the PCC index for the
Correct Classifications. Again, consider the following:
Ext/Int [Deep Structure]
case_1
case_2
case_3
case_4
case_5
-2
0
0
0
0
0
-1
0
0
0
0
0
A row-randomized version of these observations may appear as:
Ext/Int [Deep Structure]
case_3
case_1
case_4
case_5
case_2
-2
0
0
0
0
0
-1
0
0
0
0
0
0
0
0
0
1
0
1
1
0
0
0
1
2
0
1
1
0
0
Using the pattern in Figure 8.2, the number of Correct
Classifications is 4 for both the original and randomized
observations. This equality would occur regardless of the
number of units or number of observations, and the c-value
would always equal 1.0. The Correct Classified Cases would,
however, differ across row-randomized versions of the data,
but since randomizing the deep structures works for both PCC
indices, it is used in the OOM software. Finally, as noted above,
if a “Separate by…” ordering is selected, then this
randomization process is performed for each unit (group) of the
ordering.
Output
0
0
0
0
0
1
1
0
1
1
0
0
2
1
0
0
1
0
85
The defined patterns, ordering summaries, and
individual classification results can all be printed to the Text
Output window by selecting these options. In addition, the
individual classification results can be saved to a new data
spreadsheet by selecting the Save Individual Results option.
The annotated output in Figures 8.4 and 8.8 provides
descriptions of the output generated by these options.
OOM Software Manual
9
Ordinal Analysis: Crossed Orderings
This analysis is used to compare two or more groups
with regard to their ordinal standings on a single ordering.
Consider the following ordered observations for 15 different
people:
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
case_13
case_14
case_15
Time(sec)
6
15
8
10
12
12
7
14
9
15
16
22
24
.
18
Type
1
1
1
1
1
2
2
2
3
3
3
3
3
3
3
Gender
1
1
2
2
2
1
2
2
1
1
1
1
1
2
2
File: OrdinalCrossedExample.oom
The first ordering represents the amount of time (in seconds) it
takes for a person to flip a Necker cube in his or her mind. The
second ordering represents the personality types (1 = extravert,
2 = introvert, 3 = ambivert), and the third ordering represents
biological sex (1 = male, 2 = female).
Previous studies have suggested that extraverts require
shorter periods of time, on average, than introverts to flip the
Necker cube in their minds. Using traditional statistics, these
data could be analyzed with a between-subjects ANOVA or a
series of independent samples t-tests. In OOM, the most
86
rigorous way to analyze these data would be to use the Pattern
Analysis: Crossed Orderings (see pp. 58-67) option which
would require the researcher to explicitly define the expected
pattern of Time observations for the different personality types.
The data could also be analyzed using the Build/Test Model
(see pp. 18-41) which would permit the researcher to identify
any form of robust pattern in the crossed Time and Type
orderings. As another approach, the data can be analyzed using
the Ordinal Analysis: Crossed Orderings option in Figure 9.1.
Figure 9.1 Ordinal Analysis: Crossed Orderings
OOM Software Manual
With this analysis the researcher addresses whether or not the
extraverts in the sample typically required less time to flip the
cube than the introverts in the sample. The analysis is thus
based on the ordinal relationships (rankings) between pairs of
extraverts and introverts. In other words, if every extravert is
paired with every introvert, how frequently are the extraverts’
Time values lower than the introverts’ Time values? A PCC
index of 100% would indicate that in every pair, the extravert’s
time was lower than the introvert’s time. Finally, in order to
make the analysis more complex, we included ambiverts in the
data set. As will be seen below, their Time values were
expected to be between the extraverts’ and introverts’ values.
As seen in Figure 9.1, because the Necker cube times
are being compared across the groups, Time is designated as
the First Ordering. The Second (Grouping) Ordering is the
personality type. Different patterns for men and women could
also be evaluated in this analysis if Gender were to be
designated as the Third (Separate by) Ordering.
With Time as the First ordering and Type as the Second
Ordering the expected ordinal pattern(s) must be defined.
Selecting the [Define Pattern] button (see Figure 9.1) opens the
Define Ordinal Pattern window shown in Figure 9.2. As can be
seen, the expected ordinal pattern has been defined so that the
times for the extraverts are expected to be fastest (i.e., lowest)
and the times for the introverts are expected to be slowest (i.e.,
highest). The ambiverts are expected to be slower than the
extraverts and faster than the introverts. It is important to
realize that the expected pattern expresses only ordinal
relations. It does not express a linear or non-linear function, nor
does it express any type of implied mathematical equation. Do
not look at the pattern in Figure 9.2, therefore, as a linear
87
Figure 9.2 Expected Ordinal Pattern
regression model or any other type of function. It expresses
expected ordinal relationships. It is also necessary when
defining the pattern to include only one green (selected) cell in
each column. The following patterns, for instance, would not
be appropriate:
OOM Software Manual
Again, only one cell can be selected in a given column, and
these three patterns clearly violate that rule. The user will be
notified with an error message if the analysis is attempted
based on such erroneous ordinal patterns and will be prompted
to correct the error before being permitted to conduct the
analysis.
The vertical position of the expected ordinal pattern is
moreover not relevant, only the ordinal relations across
columns matter. For instance, the following two patterns are
equivalent since they both show equality between the times of
extraverts and ambiverts, which are both faster (lower times)
than introverts:
The analysis proceeds by comparing pairs of
observations on the basis of the grouping ordering. For instance,
consider the following six, novel individuals:
case_1
case_2
case_3
case_4
case_5
case_6
Time(sec)
15
22
8
14
13
12
Type
Introvert
Introvert
Ambivert
Ambivert
Extravert
Extravert
The first person (case_1) can be compared to cases three
through six from the other two groups, for a total of four
88
comparisons. Given the ordinal pattern in Figure 9.2, this
person is expected to have slower times than all four of those
other individuals. As can be seen, case_1 was in fact slower
(higher times) than the two ambiverts and the two extraverts.
The four comparisons would therefore be counted as correct
classifications by the software. Similarly, pairs of comparisons
for case_2 match the expected ordinal pattern. For case_3, only
the unique comparisons need be considered, and these will
involve cases 5 and 6. For this person, neither comparison of
time (8 vs. 13 and 8 vs. 12) matches expectation since the
ambiverts were expected to be slower (higher times) than the
extraverts. These two comparisons would therefore be counted
as incorrectly classified. For the next ambivert, case_4, 14
seconds was slower (as expected) than 13 and 12 seconds for
the two extraverts. Of the twelve unique pairwise comparisons,
then, ten matched expectation. This result would be reported as
a PCC index equal to 83.33% (10 / 12) for Classifiable Pairs of
Observations.
In summary, each person is compared to every other
person, in pairwise fashion, from the other groups and the
results summarized. In this way the user can assess if values for
persons in one group tend to be higher or lower than values for
persons in other groups. ANOVA and independent samples ttests answer a similar question, but they are based on means
and variances rather than raw comparisons of observations.
OOM Software Manual
The pattern in Figure 9.2 involves three groups. It is
possible to compare observations across the entire pattern. For
the six novel cases above, all possible combinations of cases
are as follows:
case_1 vs. case_3 vs. case_5
case_1 vs. case_3 vs. case_6
case_1 vs. case_4 vs. case_5
case_1 vs. case_4 vs. case_6
case_2 vs. case_3 vs. case_5
case_2 vs. case_3 vs. case_6
case_2 vs. case_4 vs. case_5
case_2 vs. case_4 vs. case_6
The first combination is a comparison of cases 1, 3, and 5 with
regard to the ordinal pattern. The scores for this introvert,
ambivert, and extravert are 15, 8, and 13, respectively, which
do not fit the expected ordinal pattern (viz., introvert >
ambivert > extravert). The comparison of cases 1, 4, and 5, by
contrast, do fit the pattern. Their scores are 15, 14, and 13; the
introvert took longer than the ambivert who took longer than
the extravert. Of the eight complete combinations of cases, four
match expectation. This result is reported as a PCC index equal
to 50.00% (4/8) for Correctly Classified Complete
Observations.
The analysis will report results for all possible pairs of
group comparisons: introvert vs. ambivert, ambivert vs.
extravert, and introvert vs. extravert. PCC indices will be
reported, and for all of the PCC indices described above,
randomization tests can be conducted to aid their interpretation.
Annotated output for the original example set of 15
89
observations is shown in Figure 9.3 below.
Options
Define Pattern
Selecting the [Define Pattern] button (see Figure 9.1)
opens the Define Ordinal Pattern window shown in Figure 9.2
above. This button must be selected and the expected pattern(s)
defined before the analysis can be conducted. There is no
default pattern programmed into OOM. One must be defined
by the user. As shown above, the pattern represents ordinal
relations of equality (A = B) or inequality (A < B; A > B) only.
Using the data above, for instance, additional ordinal patterns
might be defined as follows:
The first shows equality between the three groups with respect
to their recorded times flipping the Necker cube. The second
pattern expects equality between the extraverts and ambiverts,
with both groups recording faster reaction times (lower values)
compared to introverts. The third pattern shows equality
between the extraverts and introverts, with both groups
performing slower (higher values) than ambiverts.
OOM Software Manual
These three examples also show that when defining the
expected ordinal pattern(s), as noted above, only one cell
should be selected per column. In other words, every column
should have one green cell with the remaining cells empty
(white). If this rule is broken, the user will receive an error
message and will be prevented from running the analysis.
Analyze
This option allows the user to base the ordinal pattern
analysis upon the numbers as they are entered into the Data
Edit window or upon the deep structures of the observations.
Most analyses in OOM are based upon deep structures, which
is one of the primary features of the software and observation
oriented approach. Ordinal relations, however, are an important
aspect of knowing the structures and processes of nature;
consequently, the ordinal pattern analyses permit the modeling
of such relations.
The values for the example above represent time and
are clearly appropriate for examining ordinal relations. In
OOM the times to flip the Necker cube are simply entered into
the Data Edit window. Defining the units of observation is not
critical if the Numbers option is chosen for Analyze (see Figure
9.1) because the numbers will be taken directly from the Data
Edit window and examined for their conformity to the expected
ordinal pattern(s).
If the Deep Structure option is chosen, then the user
must insure that the units of observation have been defined.
The user must also be ready to defend applying statements of
ordinal relation (e.g., “unit A is greater than unit B”) to the
defined units. For the example above, for instance, the units
can be defined as equal intervals of 10 seconds: 1-10, 11-20,
90
and 21-30. The output will then summarize the deep structures
as follows:
Analyze: Deep Structures Analyzed
Time(sec) Min = 1: 10
Max = 21: 30
Type Min = Extravert Max = Introvert
# Units = 3
# Units = 3
Recall that the extraverts are expected to have lower times than
the introverts (see Figure 9.2). Consider an extravert with a
time equal to 5 and an introvert with a time of 10. These actual
times fit the expected pattern; however, their deep structures
are identical because the first unit includes values 1 through 10.
In terms of deep structures, then, these two values (5 and 10)
would not fit the expected pattern. The user must therefore be
careful to attend to whether the Numbers or Deep Structures
option has been chosen as the results can appear radically
different depending upon how the units of observations are
defined.
Missing Values
Two options for missing values are available: Omit and
Include. When the Omit option is chosen, the missing values
will not be included in the total numbers of pairs of
observations or complete observations that can be classified.
With the Omit options selected, for instance, for the 15
example cases above, the output appears as:
Classifiable Pairs of Observations : 63
Correct Classifications : 50
Percent Correct Classifications : 79.37
Classifiable Complete Observations : 90
Correctly Classified Complete Observations : 41
Percent Correct Classified Observations : 45.56
OOM Software Manual
When the Include option is chose, the output appears as:
Classifiable Pairs of Observations : 71
Correct Classifications : 50
Percent Correct Classifications : 70.42
Classifiable Complete Observations : 105
Correctly Classified Complete Observations : 41
Percent Correct Classified Observations : 39.05
As can be seen, the correctly classified observation values do
not change. Only the classifiable values (highlighted) change,
which then change the PCC values. Including the missing
values in the totals will lower the PCC indices. The c-values
will be computed in similar fashion. Comparing the output
from the Omit and Include options can therefore help the user
evaluate the impact of missing values on the results.
Classification Imprecision
Normally, correct classifications are computed on the
basis of the entered values or upon the deep structure units.
With the Classification Imprecision option ranges of values are
considered when computing the matches. For instance,
consider the following three times and the expected pattern of
ordinal relationships in Figure 9.2:
Time
Ext Ambi
5
7
Int
11
Further suppose that the Numbers are being analyzed. Given
these options, it can be clearly seen that the three values fit the
pattern; namely, the extravert is fastest (lowest time), followed
by the ambivert, and then the introvert.
91
For the same three people, consider setting the
Classification Imprecision value to 5. In this instance, the
extravert and ambivert would be considered as equal and not
matching the ordinal pattern because the absolute difference
between 5 and 7 is less than (or equal to) the imprecision value
of 5. The ambivert and introvert values would also be
considered as equal and inconsistent with the ordinal pattern
(|7 – 11| = 4; 4 ≤ 5). Only the difference between the extravert
and introvert would be considered as consistent with the
pattern (|5 – 11| = 6; 6 > 5) and therefore tallied as correctly
classified.
When the Deep Structure option for Analyze is selected,
then the Classification Imprecision value will be applied to the
deep structure units. The value will constitute a range of deep
structure units rather than a range of numbers built around the
values as they are entered in the Data Edit window.
Randomization Test
Randomization Test
The Randomization Test provides a tool for evaluating
the number of correctly classified pairs of observations and
number of correctly classified complete cases from the analysis
(see the annotated output in Figure 9.3). As with all analyses in
OOM, the percent correct classifications (viz., PCC indices)
are themselves the primary results to be emphasized by the user,
ideally in the context of an integrated model.
Nonetheless, the randomization works by randomly
shuffling the observations and then computing the PCC indices
OOM Software Manual
according to the chosen options. There are two options for
randomizing the data: All Data and Deep Structures.
When All Data is selected, the observations are
randomly shuffled between groups. For example, consider the
following values for just the females:
case_9
case_10
case_11
case_12
case_13
case_14
case_15
Time(sec)
.
10
14
7
8
18
12
Type
3
1
2
2
1
3
1
A randomized version of these observations may appear as:
case_9
case_10
case_11
case_12
case_13
case_14
case_15
Time(sec)
8
12
14
.
7
10
18
Type
3
1
2
2
1
3
1
Notice how the times are randomly paired with persons across
the three personality types. The data are therefore completely
randomized, and it is possible that a random ordering will
match the actual data.
Depending on the Number of Trials selected by the user,
the data will be randomized repeatedly and the PCC indices
computed for the randomized data. These PCC indices create a
distribution, and the actual PCC index from the data can be
located in this distribution. The proportion of randomized
PCCs equaling or exceeding the actual PCC index is reported
as the c-value. The c-value is therefore a probability statistic in
92
the frequentist sense, but it is not based on an idealized
distribution, nor does it require the assumptions common to pvalues for most other statistical analyses.
When Deep Structures is selected as the randomization
method, then random values are created for the deep structures
of the observations. For example, consider units of Time
defined as three equal intervals of 10 seconds: 1-10, 11-20, and
21-30. Now consider the following observations and their deep
structure unit values:
case_11
case_12
case_13
case_6
Time(sec)
14
7
8
24
Type
2
2
1
3
Unit
2
1
1
3
A randomized version of these data may appear as:
case_11
case_12
case_13
case_6
Time(sec)
14
7
8
24
Type
2
2
1
3
Unit
3
3
1
2
The unit values can range from 1 to 3, and the randomization
routine randomly generated the unit value for each case. This
process is tantamount to moving the “1” in the deep structure
for each person to a new unit. This method also makes it
possible for an unobserved unit to be randomly generated. For
instance, if an additional unit of 31-40 were defined for the
example data above, no person in the sample reported a time
exceeding 30 seconds. Yet, with the Deep Structure
randomization routine, that unit could be randomly generated
for an individual. This is a key difference between the two
OOM Software Manual
options. With the All Data option, the data themselves are
randomly shuffled; with Deep Structure, the deep structure
units are randomly generated.
Finally, if the Deep Structure randomization option is
chosen, it is likely to make most sense to choose the Deep
Structures option for Analyze (see Figure 9.1) as well, although
this is not necessary. It is the user’s responsibility to define the
ordered observations in a way that is theoretically meaningful,
and then to choose the appropriate analysis options.
Save Randomized Results
When this option is selected and the analysis conducted,
a new data set will be created in the Data Edit window. The
number of observations in the data set will equal the number of
trials set by the user (provided the iterative process is not
interrupted by selecting the [Stop] button). A new data set will
be created for each unit of the third Separate by ordering (see
Figure 9.1). For the Necker cube data, for instance, two data
sets will be generated; one for the males and one for the
females if Gender is included as the Separate by ordering.
Each data set will be comprised of six orderings: (1) correctly
classified pairs of observations, (2) classifiable pairs of
observations, (3) percent correct classifications, PCC, (4)
correctly classified complete cases, (5) classifiable complete
cases, and (6) percent correct classified complete cases, PCC.
In addition, all PCC values for all pairs of groups will be saved.
For the data above, for example, PCC values for extraverts vs.
introverts, extraverts vs. ambiverts, and ambiverts vs. introverts
will be saved.
The cases in the generated data sets will be labeled,
rand_1, rand_2, rand_3, etc. as a reminder of their origin from
93
the randomization test. As with any data set in OOM, these
randomization results can be examined, edited, sorted, saved,
concatenated, etc.
Output
Pattern Definitions
Selecting this option will print the defined patterns in
the Text Output window. This option is selected by default so
the user can check to make certain the patterns have been
defined properly. Here is the example pattern for the Necker
cube data above:
Defined Pattern
Extravert
| Ambivert
| | Introvert
O O + Highest
O + O
+ O O Lowest
The entire grid of possible ordinal relations is printed and
labeled. The blue crosses indicate the expected ordinal
relations.
Ordering Summaries
Summaries of the orderings will be printed to the Text
Output window. The summary is described in greater detail in
Chapter 3.
OOM Software Manual
Pairwise Results
Results for comparing each pair of groups for the
second (Grouping) ordering will be reported. The complete
output for the Necker cube data has been separated and the
columns labels abbreviated for ease of presentation as follows:
Next to these frequencies, the following output is reported
(again, with abbreviated labels):
Pairwise Ordinal Results
Extravert < Ambivert
Extravert < Introvert
Ambivert < Introvert
# Obs (1st Group)
|
Miss Obs (1st Grp)
|
|
# Obs(2nd Grp)
|
|
|
Miss Obs (2nd Grp)
|
|
|
|
Classifiable Pairs
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5
0
3
0
15
5
0
7
1
30
3
0
7
1
18
As can be seen, the first pairwise comparison involves
extraverts (the 1st group) and ambiverts (the 2nd group). The
inequality (<) indicates that the extraverts are expected to have
lower Time values than the ambiverts; that is, the extraverts
will flip the cube faster than the ambiverts. The number of
observations in each group are reported along with the number
of missing values. The number of person-to-person
comparisons from the two groups is then reported based on the
number of non-missing observations. In this first comparison,
there are 15 (5 * 3) possible comparisons. For extraverts vs.
introverts, there are 30 (5 * 6) possible comparisons because of
the missing Time observation for one of the seven introverts.
94
Extra < Ambi
Extra < Intro
Ambi < Intro
Correct Classified Pairs
|
PCC
|
|
c-value
|
|
|
Min Random PCC
|
|
|
|
Max Ran PCC
|
|
|
|
|
8
53.33
0.24
0.00
100.00
26
74.29
0.00
0.00
85.71
16
76.19
0.01
0.00
85.71
As can be seen, the number of correctly classified pairs (on the
basis of the predicted ordinal pattern) is reported for each pair
of groups. The Correct Classified Pairs values are then divided
by the Classifiable Pairs values and the results multiplied by
100 to obtain the PCC indices. If the Randomization Test
option is selected (see Figure 9.1), the results of the
randomization test are reported for each pair of groups. The cvalue is reported along with the minimum and maximum cvalues observed during the trials of the randomization test.
Complete Results
When this option is selected, the results for the
complete classifications will be printed to the Text Output
window. As described above (pp. 88-89), the complete results
require the creation of every possible combination of
observations from all of the groups. These combinations are
compared to the complete predicted ordinal pattern, and the
results summarized. For the 15 Necker cube observations
above for the three personality types, the complete results are
OOM Software Manual
as follows:
Classifiable Complete Observations : 90
Correctly Classified Complete Observations : 41
Percent Correct Classified Observations : 45.56
There are 5 extraverts, 3 ambiverts, and 6 introverts with nonmissing Time observations. Consequently, there are 90 (5 * 3 *
6) unique combinations of persons from the three groups. For
example,
case_1 vs. case_6 vs. case_9
case_1 vs. case_6 vs. case_10
case_1 vs. case_6 vs. case_11
etc.
The number of triad Times, in this example, that fit the
expected ordinal pattern was tallied at 41. The PCC index is
therefore 45.56% (41/90).
When the Randomization Test is selected, the results of
a randomization test will also be printed. The results for the
Necker cube data indicate that the observed PCC index of
45.56% is unusual:
Number of Randomized Trials : 1000
Minimum Random Percent Correct : 0.00
Maximum Random Percent Correct : 66.67
Values >= Observed Percent Correct : 16
Model c-value : 0.02
When the number of groups and number of cases are
both large, the user will be issued a warning when selecting the
Complete Results option. The number of possible combinations
for in such instances can grow very, very large and
95
consequently consume a large amount of computing time and
resources. The warning indicates that the computations may be
time consuming and it provides an option for the user to skip
the Complete Results analysis.
OOM Software Manual
Figure 9.3 Annotated Output for Ordinal Pattern Analysis
Ordinal Pattern Analysis (Crossed Orderings) for Ordinal
Analysis: Crossed Orderings Example
Missing Values = Omitted from Totals
Imprecision Value = 0
Randomization Method = All Observations
Analyze: Entered Numbers Analyzed
Time(sec)
Min =
6.00
Max = 24.00
Type
Min =
1.00
Max =
3.00
Units: 3
Units: 3
Units: 6
Missing: 1
Missing: 0
Missing: 1
Undefined : 0
Undefined : 0
Undefined : 0
The Classification Imprecision Value option was set to 0 in Figure 9.1 by
the user. Text printed in blue font indicates options chosen by the user.
Missing Values was set so that they will not be included in the totals
reported below, and the Randomization Method for deriving the c-value
was set to All Observations.
Analyze was set to Numbers, and the minimum and maximum values
(numbers) for the two orderings are reported here in the output. These
values remind the user that the numbers entered into the Data Edit window
as displayed above were analyzed. Such entered numbers should represent
counts or real values for a continuously structured attribute. In this example,
they indicate time in seconds.
Ordering Frequency Summaries
Time(sec)
Type
Totals
96
Obs: 14
Obs: 15
Obs: 29
Defined Pattern
Extravert
| Ambivert
| | Introvert
O O + Highest
O + O
+ O O Lowest
Classification Results
Ordinal Relations between Pairs of Observations Classified
According to the Defined Pattern(s)
Classifiable Pairs of Observations : 63
Correct Classifications : 50
Percent Correct Classifications : 79.37
The Ordering Frequency Summaries shows four missing values. The
Units for the Time and Type orderings, which were crossed in this analysis,
are presented.
The ordinal pattern is shown here, as the blue crosses indicate the expected
ordinal relations. The Pattern Definitions Output option is selected by
default to help insure that the user did in fact define the patterns correctly.
The Classification Results present the classifiable pairs of observations
first. Recall that every person in each group is compared to every other
person in the other groups. These comparisons are the Classifiable Pairs of
Observations. Since Missing Values was set to Omitted from Totals, the
total number of pairwise comparisons across the three personality Types (5
extraverts, 3 ambiverts, and 6 introverts with non-missing Necker cube
times) is equal to 63 (i.e., [5 * 3] + [5 * 6] + [3 * 6] = 63).
The ordinal relation between the Time values for each pair of persons is
compared to the expected ordinal pattern (i.e., the Defined Pattern). If the
observed ordinal relation matches the expected ordinal relation, then that
pair of persons’ times is counted as a Correct Classification. In this
example, 50 of the 63 pairs were correctly classified. The Percent Correct
Classification (PCC) index is therefore 79.37% (50/63 * 100), and is fairly
impressive in magnitude.
OOM Software Manual
Classifiable Complete Observations : 90
Correctly Classified Complete Observations : 41
Percent Correct Classified Observations : 45.56
97
The Classifiable Complete Observations considers observations in
relation to the entire ordinal pattern. In this example there are three
personality types. The complete ordinal comparisons are:
case_1 vs. case_6 vs. case_9
case_1 vs. case_6 vs. case_10
…
case_5 vs. case_8 vs. case_15
With 5 extraverts, 3 ambiverts, and 6 introverts (with non-missing) there are
90 possible Classifiable Complete Observations (viz., 5 * 3 * 6 = 90). Of
these triads, 41 Time values matched the expected ordinal pattern, yielding
a PCC index equal to 45.56% (41/90 * 100), which is fairly low and
unimpressive. The pairwise results above are therefore impressive, but the
complete ordinal pattern is not supported.
Randomization Results
Observed Percent Correct Classified Pairs : 79.37
Number of Randomized Trials
Minimum Random Percent Correct
Maximum Random Percent Correct
Values >= Observed Percent Correct
Model c-value
:
:
:
:
:
1000
14.29
92.06
16
0.02
The randomizations results show that the two PCC indices are quite unusual
(both c-values = .02). Again, however, the PCC index for the Correctly
Classified Complete cases is not impressive in magnitude.
Observed Percent Correct Classified Complete : 45.56
Number of Randomized Trials
Minimum Random Percent Correct
Maximum Random Percent Correct
Values >= Observed Percent Correct
Model c-value
:
:
:
:
:
1000
0.00
66.67
24
0.02
Because of the width of these results, they had to be reduced to the size of a
Lilliputian flea. They show, nonetheless, that the expected ordinal relation
in time between the extraverts and ambiverts was not supported (PCC =
53.33%). The PCCs for extraverts vs. introverts (86.67%) and ambiverts vs.
introverts (88.89%) were quite high with low c-values (c-values < .03).
These personality type pairwise results therefore show why the PCC value
for the Correctly Classified Complete cases (45.56%) was not very
impressive, while the overall pairwise PCC was higher (79.37%). The
ordinal pattern did not match the extraverts/ambiverts observations very
well.
OOM Software Manual
10
Ordinal Analysis: Concatenated Orderings
This analysis can be used to evaluate the ordinal
patterns of numeric observations (frequency counts or
continuous quantities) for different groups or classes of
observations. Consider the following ordered observations for
8 experimental and 7 control rats:
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ConRat
ConRat
ConRat
ConRat
ConRat
ConRat
ConRat
1
2
3
4
5
6
7
8
1
2
3
4
5
6
7
B1
2
1
2
0
0
2
1
1
0
0
0
2
1
1
2
B2
0
1
2
1
0
1
0
0
1
0
2
0
1
0
1
T1
10
12
9
14
2
19
13
12
0
2
1
2
1
0
0
T2
7
11
6
5
0
8
5
7
0
.
2
1
2
.
5
T3
2
.
2
1
1
2
0
1
1
3
2
1
0
.
1
Group
E
E
E
E
E
E
E
E
C
C
C
C
C
C
C
File: OrdinalBarPressExample.oom
The first two baseline columns (B1, B2) represent frequencies
of bar presses in a controlled environment over a fixed period
of time. The next three columns (T1, T2, T3) report bar presses
after behavioral training in which the bar press was paired with
a reward. The reward was removed after the successful training.
The expectation here is that the frequencies of bar
presses for the control rats will remain consistent over all trials,
B1 to T3. For the experimental rats, the frequencies are
expected to be consistent across B1 and B2, but then are
98
expected to be much greater for T1, the time immediately
following the training. Since the reward has been removed,
however, the frequencies are expected to decrease from T1 to
T3 such that at T3 the frequencies will be equal to the original
frequencies for B1 and B2. The Ordinal Analysis:
Concatenated Orderings option can be used to test these
expected patterns of ordinal relations.
Figure 10.1 shows the Ordinal Analysis: Concatenated
Orderings window in which the B1, B2, T1-T3 ordered
observations are selected as the Concatenated Observations, the
patterns for which will be defined separately for the
experimental and control units of observation (Group).
Figure 10.1 Ordinal Analysis: Concatenated Orderings
OOM Software Manual
Once the Concatenated Observations have been selected (note
that “Separate by” observations do not necessarily have to be
selected), the expected pattern(s) must be defined. Selecting the
[Define Pattern] button (see Figure 10.1) opens the Define
Ordinal Pattern window shown in Figure 10.2.
Figure 10.2 Expected Ordinal Pattern, Experimental Rats
99
T2. It is important to realize that the expected pattern
expresses only ordinal relations. It does not express a linear or
non-linear function, nor does it express any type of implied
mathematical equation. Do not look at the pattern in Figure
10.2, therefore, as a spline regression model or any other type
of function. It expresses expected ordinal relationships.
Because the pattern expresses ordinal relations of
“greater than” or “less than”, the patterns in Figure 10.3 are all
equivalent. Notice that the vertical position of the overall
pattern is arbitrary as is the vertical spacing.
Figure 10.3 Equivalent Expected Ordinal Patterns
What is not arbitrary, however, is that each column in the
pattern must have one, and only one, selected (green) cell.
Figure 10.4 shows an illegitimately defined pattern. The
frequencies for T1 cannot be defined as both equal to those for
B2 and greater than B2 in the pattern (note the T1 column has
two selected cells).
As can be seen, the expected ordinal pattern has been
defined for the experimental rats: B1, B2, and T3 are expected
to be the lowest frequencies for each rat, and are expected to be
equal. T1 is expected to be the highest frequency, followed by
Figure 10.4
Incorrectly Defined
Ordinal Pattern
OOM Software Manual
Such a pattern will produce the following error message in the
Text Output window when the analysis is conducted:
“Expected rankings were not defined properly. Two or more
ranks were assigned to a unit. Redefine the ranks and run the
analysis again.”
Individual observations and the modes for all of the
observations can be examined in the Define Ordinal Pattern
window by selecting the individual scroll arrow or by selecting
the Modes radio button (see Figure 10.2). Figure 10.5 shows
the ordinal relations for three experimental rats’ observations.
The expected ordinal pattern fits the 3rd rat’s observations
perfectly, but does not fit the 1st or 2nd rats’ observations
perfectly. Notice for “ExpRat 2” four of the five observations
fit the expected pattern, even though the software did not plot
the observations exactly within the green cells. B1 is equal to
B2, and T1 is greater than T2, and T2 is greater than both B1
and B2. T3 is a missing value and is plotted below the grid.
Figure 10.5 Example Ordinal Patterns for Three Rats
As another example, the observations in Figure 10.6 fit the
expected ordinal pattern even though the observations are not
printed in the green cells. Only the relative, ordinal positions of
100
values are considered when determining if the observations
match the expected pattern.
Figure 10.6
Matching Ordinal
Pattern of Results
Figure 10.7 shows the expected ordinal pattern of
frequencies for the control rats. As can be seen, frequencies are
expected to be equal for all five trials, B1 to T3.
Figure 10.7
Expected Ordinal
Pattern for
Control Rat
Observations
This expectation is exact as a rat pressing the bar once at B1
and only twice at B2 will fail to fit this pattern. Given this
expected pattern for the control rats and the expected pattern in
Figure 10.2 for the experimental rats, the annotated output in
Figure 10.8 is produced from the ordinal analysis (note the
Individual Results option under “Output” in Figure 10.1 was
also selected).
OOM Software Manual
101
Figure 10.8 Initial Annotated Output for Ordinal Pattern Analysis
Ordinal Pattern Analysis for Ordinal Example (Rat Bar Presses)
Order Imprecision value = 0
Ordinal Classifications = Full pattern of ordinal relations
Missing Values = Omitted from Totals
Numbers were analyzed here (see Figure 10.1), which means that instead of
deep structures, the values entered into the Data Edit window as displayed
above were analyzed. Such entered numbers should represent counts or real
values for a continuously structured attribute. In this example, they indicate
simple frequencies of bar presses. The minimum and maximum values are
summarized here as well as the units for the separating observations
(Group). This summary serves as a reminder to the user that the entered
values were analyzed.
Analyze: Entered Numbers Analyzed
B1
Min =
0.00
Max =
2.00
B2
Min =
0.00
Max =
2.00
T1
Min =
0.00
Max = 19.00
T2
Min =
0.00
Max = 11.00
T3
Min =
0.00
Max =
3.00
Group
Experimental;
Control
Ordering Frequency Summaries
B1
B2
T1
T2
T3
Group
Totals
Units
Units
Units
Units
Units
Units
Units
:
:
:
:
:
:
:
5
5
5
5
5
2
27
Missing
Missing
Missing
Missing
Missing
Missing
Missing
:
:
:
:
:
:
:
0
0
0
2
2
0
4
The Order Imprecision Value option was set to 0 in Figure 10.1 by the
user. Text printed in blue font indicates options chosen by the user.
The Full option (see Figure 10.1) for Ordinal Classifications was selected.
See Options below for a detailed description of this option. Missing Values
was set so that they will not be included in the totals reported below.
Observations
Observations
Observations
Observations
Observations
Observations
Observations
:
:
:
:
:
:
:
15
15
15
13
13
15
86
The Ordering Frequency Summaries shows four missing values. The Units
for the B1 to T3 orderings are not relevant to this analysis since the entered
numbers in the Data Edit window are being analyzed rather than their deep
structures.
Defined Pattern : Experimental
B1
| B2
| | T1
| | | T2
| | | | T3
O O O O O Highest
O O O O O
O O + O O
O O O + O
+ + O O + Lowest
The defined patterns are shown here and correspond to the expectations
outlined above for both experimental and control rats. The blue crosses
indicate the expected ordinal relations. The Pattern Definitions Output
option is selected by default to help insure that the user did in fact define the
patterns correctly.
Defined Pattern : Control
O
O
+
O
O
O
O
+
O
O
O
O
+
O
O
O
O
+
O
O
O Highest
O
+
O
O Lowest
The column labels for the Control pattern have been deleted here for brevity.
OOM Software Manual
102
Figure 10.8 (continued)
Classification Results :
Experimental
Ordinal Relations between Pairs of Observations Classified
According to the Defined Pattern(s)
Classifiable Pairs of Observations : 76
Correct Classifications : 61
Percent Correct Classifications : 80.26
Classifiable Complete Cases : 7
Correctly Classified Complete Cases : 1
Percent Correct Classified Cases : 14.29
Classification Results :
Control
Ordinal Relations between Pairs of Observations Classified
According to the Defined Pattern(s)
Classifiable Pairs of Observations : 59
Correct Classifications : 15
Percent Correct Classifications : 25.42
Classifiable Complete Cases : 5
Correctly Classified Complete Cases : 0
Percent Correct Classified Cases : 0.00
Individual Classification Results :
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
1
2
3
4
5
6
7
8
Experimental
Observations
|
Missing
|
|
Classifiable Pairs of Observations
|
|
|
Correct Classifications
|
|
|
|
PCC
|
|
|
|
|
|
|
|
|
|
5
0
10
8
80.00
4
1
6
6
100.00
5
0
10
10
100.00
5
0
10
8
80.00
5
0
10
5
50.00
5
0
10
8
80.00
5
0
10
8
80.00
5
0
10
8
80.00
The general results for all 8 experimental rats are reported here. The Full
option was chosen for Ordinal Classifications (see Figure 10.1).
Consequently, a correct classification is tallied when:
B1 = B2, B1 < T1, B1 < T2, B1 = T3, B2 < T1, B2 < T2, B2 = T3,
T1 < T2, T1 < T3, or T2 < T3
In other words, for each case (rat) there are 5C2, or 10, possible correct
classifications. Given 8 experimental rats the Classifiable Pairs of
Observations would be equal to 80; however, ExpRat 2 is missing a value
for T3 reducing the total to 76 (T3 is involved in four comparisons) since
the Missing Values option was set to exclude them from the totals. For
these data, 61 of the pairwise ordinal relations (61/76 = .80) conformed to
the expected pattern for the experimental rats…an impressive result.
The Correctly Classified Complete Cases is reported next, and shows that
only one experimental rat (see below) fit the expected ordinal pattern
perfectly (1 / 8 = .14); that is, fit all 10 ordinal pairwise comparisons listed
above.
The results for the control rats were unimpressive, with only 15 of 59 (25%)
Correct Classifications. Again, 5C2 correct classifications are possible for
each control rat, or 70 total for all 7 rats. ConRat 2 and ConRat 6, however,
have missing values, so the total is reduced to 59. None of the 5 control rats
with non-missing data fit the expected ordinal pattern completely (0/5 = 0).
The individual results for the experimental rats are reported here because
the Individual Results output option was chosen (see Figure 10.1).
Observations indicates the number of non-missing observations for the B1
to T3 orderings. ExtRat 2 has one Missing observation. As described above,
since the Full option was chosen, the Classifiable Pairs of Observatiosn
are computed as 5C2, or 10, and then the missing values are subtracted. For
ExtRat 2, 4C2 = 6. The Correct Classifications are tallied as described
above, and then the PCC is computed for each rat (Correct / Classifiable).
Here, all experimental rats, except ExpRat 5, matched at 80% or
100%...very impressive results. ExpRat 5’s observations (0, 0, 2, 0, 1, 1) did
not match the expected pattern very well (PCC = 50%).
OOM Software Manual
103
Figure 10.8 (continued)
Individual Ordinal Pattern Matches :
ConRat
ConRat
ConRat
ConRat
ConRat
ConRat
ConRat
1
2
3
4
5
6
7
Control
Observations
|
Missing
|
|
Classifiable Pairs of Observations
|
|
|
Correct Classifications
|
|
|
|
PCC
|
|
|
|
|
|
|
|
|
|
5
0
10
4
40.00
4
1
6
1
16.67
5
0
10
3
30.00
5
0
10
2
20.00
5
0
10
3
30.00
3
2
3
1
33.33
5
0
10
1
10.00
The individual results for the control rats are presented here, and they stand
in stark contrast to the experimental rats. None of the seven control rats fit
the expected pattern better than 40%. Why do the control rat observations
fit so poorly? Recall the expected pattern is equality for all observed
frequencies, B1 through T3. This is a strict expectation. Examination of the
frequencies for the control rats show that many are within +/- 1 bar presses
of each other:
ConRat
ConRat
ConRat
ConRat
ConRat
ConRat
ConRat
1
2
3
4
5
6
7
B1
0
0
0
2
1
1
2
B2
1
0
2
0
1
0
1
T1
0
2
1
2
1
0
0
T2
0
.
2
1
2
.
5
T3
1
3
2
1
0
.
1
Moreover, most of the expected differences in frequencies for the
experimental rats exceed 1 bar press:
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
1
2
3
4
5
6
7
8
B1
2
1
2
0
0
2
1
1
B2
0
1
2
1
0
1
0
0
T1
10
12
9
14
2
19
13
12
T2
7
11
6
5
0
8
5
7
T3
2
.
2
1
1
2
0
1
Group
1
1
1
1
1
1
1
1
Given these results, setting the Order Imprecision option to +/- 1 (see
Figure 10.1) should improve the results. The idea behind this change is to
show that the control rats do not deviate beyond 1 bar press across all
conditions, while the experimental rats show changes in bar presses from
B2 to T1, T1 to T2, and T2 to T3 that exceed 1 bar press.
OOM Software Manual
As described in the annotated output, the results are
impressive for the experimental rats, but not for the control rats
because of the “rigid” expectation of perfect equality in
frequencies from B1 to T3. Consequently, the Order
Imprecision option was set to “2” in Figure 10.9. Frequencies
within +/- 2 bar presses will therefore be counted as equal
when determining if the frequencies match the ordinal pattern.
This option essentially provides the user with the opportunity
to ignore small differences between frequencies.
Figure 10.9 Ordinal Pattern Analysis, more options chosen
104
The output from the analysis is presented and annotated in
Figure 10.10, and the results now show impressive agreement
between the expected ordinal patterns and the observed
frequencies for both experimental and control rats.
OOM Software Manual
105
Figure 10.10 Selected Annotated Output for Ordinal Pattern Analysis
Classification Results :
Experimental
Ordinal Relations between Pairs of Observations Classified
According to the Defined Pattern(s)
Classifiable Pairs of Observations : 76
Correct Classifications : 69
Percent Correct Classifications : 90.79
The results for the Experimental rats are even more impressive with the
Order Imprecision value set to 1. Sixty-nine of the non-missing 76 pairwise
ordinal comparisons (90.79%) fit the expected pattern. Moreover, 5 of the
rats (cases) with complete data (71.43%) fit the pattern perfectly and
completely.
Classifiable Complete Cases : 7
Correctly Classified Complete Cases : 5
Percent Correct Classified Cases : 71.43
Randomization Results :
Experimental
Observed Percent Correct Classifications : 90.79
Number of Randomized Trials : 1000
Minimum Random Percent Correct : 10.53
Maximum Random Percent Correct : 60.53
Values >= Observed Percent Correct : 0
Model c-value : less than ( 1 / 1000);
that is, < 0.001
Observed Percent Correct Classified Cases : 71.43
Number of Randomized Trials : 1000
Minimum Random Percent Correct Cases : 0.00
Maximum Random Percent Correct Cases : 14.29
Values >= Observed Percent Correct Cases : 0
Model c-value : less than ( 1 / 1000);
that is, < 0.001
The Randomization Test was selected for these analyses with the
Randomize All Observations option chosen. This option works by randomly
shuffling the concatenated observations for each case (rat) and then
shuffling between the cases. In this example, for each rat the B1, B2, T1, T2,
and T3 observations are first randomized. The values between the rats are
then randomly shuffled, and the correct classifications are finally
recomputed based on these randomized observations. For instance, for
ExpRat 1 the values for B1 to T3 are: 2, 0, 10, 7, 2, which fit the expected
pattern perfectly (with the Order Imprecision value set to 2). A randomized
version of these observations might be: 0, 10, 2, 2, 7. These values are then
randomly swapped with values from other rats.
One-thousand randomized trials were requested for this example (see Figure
10.9), and not in a single instance did the Observed Percent Correct
Classifications equal or exceed 90.79. The lowest percent was 10.53 and
the highest was 60.53. The c-value is therefore less than 1 in 1000 (c < 1 /
1000 or .001). Obtaining 91% correct classifications is therefore highly
unusual.
Similarly, the Randomization Test results for the Percent Correct
Classified Cases yielded a c-value less than .001 (1 / 1000). Not one of the
1000 randomized trials yielded a value as high or higher than 71.43.
OOM Software Manual
106
Figure 10.10 (Continued)
Individual Classification Results :
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
1
2
3
4
5
6
7
8
Experimental
Observations
|
Missing
|
|
Classifiable Pairs of Observations
|
|
|
Correct Classifications
|
|
|
|
PCC
|
|
|
|
|
c-value
|
|
|
|
|
|
5
0
10
8
80.00
0.05
4
1
6
5
83.33
0.04
5
0
10
10
100.00
0.02
5
0
10
10
100.00
0.01
5
0
10
6
60.00
0.17
5
0
10
10
100.00
0.01
5
0
10
10
100.00
0.01
5
0
10
10
100.00
0.01
The individual results for the experimental rats show the improvement
afforded by setting the Order Imprecision value set to 1. Five of the eight
rats fit the pattern completely, and rats 1 and 2fit the pattern closely
(Percent Correct Classification, PCC, > 79). ExpRat 5’s frequencies were
not close to matching the expected ordinal pattern (0, 0, 2, 0, 1).
OOM Software Manual
107
Figure 10.10 (Continued)
Classification Results : Control
Ordinal Relations between Pairs of Observations Classified
According to the Defined Pattern(s)
Classifiable Pairs of Observations : 59
Correct Classifications : 44
Percent Correct Classifications : 74.58
The results for the control rats are improved drastically by setting the Order
Imprecision value to 1. Forty-four of the 59 non-missing comparisons
between observed frequencies now fit the expected pattern, for 74.58%
Percent Correct Classifications. The c-value is low, but not impressively
so, thus indicating the mild unusualness of the PCC index.
Classifiable Complete Cases : 5
Correctly Classified Complete Cases : 1
Percent Correct Classified Cases : 20.00
Randomization Results : Control
Observed Percent Correct Classifications : 74.58
Number of Randomized Trials
Minimum Random Percent Correct
Maximum Random Percent Correct
Values >= Observed Percent Correct
Model c-value
:
:
:
:
:
1000
58.62
86.21
239
0.24
Observed Percent Correct Classified Cases : 20.00
Number of Randomized Trials
Minimum Random Percent Correct Cases
Maximum Random Percent Correct Cases
Values >= Observed Percent Correct Cases
Model c-value
:
:
:
:
:
1000
0.00
80.00
619
0.62
Individual Classification Results : Control
Observations
|
Missing
|
|
Classifiable Pairs of Observations
|
|
|
Correct Classifications
|
|
|
|
PCC
|
|
|
|
|
c-value
ConRat 1
5
0
10
10
100.00
0.26
ConRat 2
4
1
6
2
33.33
0.97
ConRat 3
5
0
10
7
70.00
0.51
ConRat 4
5
0
10
8
80.00
0.48
ConRat 5
5
0
10
9
90.00
0.26
ConRat 6
5
0
10
3
100.00
0.24
ConRat 7
5
2
3
5
50.00
0.87
The Individual Classification Results show that five of the seven control
rats fit the pattern with PCC indices of 70% or higher. Two rats yielded
PCC indices of 100%. Observations for ConRat 2 and ConRat 7 did not fit
the pattern very well. ConRat 2 pressed the bar 3 times at T3, and ConRat 7
pressed the bar 5 times at T2. Overall, then, the results are much improved
for the control rats as well as for the experimental rats when setting the
imprecision value to +/- 1.
OOM Software Manual
Options
Define Pattern
Selecting the [Define Pattern] button (see Figure 10.9)
opens the Define Ordinal Pattern window shown in Figure
10.2 above. This button must be selected and the expected
pattern(s) defined before the analysis can be conducted. There
is no default pattern programmed into OOM. One must be
defined by the user. As shown above, the pattern represents
ordinal relations of equality (A = B) or inequality (A < B; A >
B) only. Using the data above, for instance, Figure 10.11 shows
additional examples.
Figure 10.11 Additional Example Ordinal Patterns
The first shows an increase in bar presses from B1 to B2, and
then decreases in presses from T1 to T3. Moreover, observed
values for B1 and B2 are expected to be greater than values for
T1, T2, and T3. The second example shows no difference
between B1 and B2, an increase in bar presses at T1, and then a
return to baseline for T2 and T3. The third example shows a
monotonic decrease in bar presses from B1 to T3.
These three examples also show that when defining the
expected ordinal pattern(s), only one cell should be selected per
column. In other words, every column should have one green
108
cell with the remaining cells empty (white). If this rule is
broken, an error message will be printed in the Text Output
window.
Analyze
This option allows the user to base the ordinal pattern
analysis upon the numbers as they are entered into the Data
Edit window or upon the deep structures of the observations.
Most analyses in OOM are based upon deep structures, which
is one of the primary features of the software and observation
oriented approach. Ordinal relations, however, are an important
aspect of knowing the structures and processes of nature;
consequently, the Ordinal Pattern Analysis permits the
modeling of such relations.
The values for the example above represent simple
frequencies of bar presses and are clearly appropriate for
examining ordinal relations. Six bar presses, for instance, can
be unambiguously judged as greater than four such presses. In
OOM the counted bar presses are simply entered into the Data
Edit window. Defining the units of observation is not critical if
the Numbers option is chosen for Analyze (see Figure 10.9).
This is because the numbers will be taken directly from the
Data Edit window and examined for their conformity to the
expected ordinal pattern(s).
If the Deep Structure option is chosen, then the user
must insure that the units of observation have been defined.
The user must also be ready to defend applying statements of
ordinal relation (e.g., “unit A is greater than unit B”) to the
defined units. For the example above, for instance, the units
can be defined as equal, ascending ranges for each of the
orderings: 0-2, 3-5, 6-8, 9-11, and 12-14. Figure 10.12 shows
OOM Software Manual
the Define Ordered Observations window with B1 defined.
The other orderings would be defined identically.
Figure 10.12 Define Ordered Observations window
109
Figure 10.13 Deep Structure Output for Ordinal Pattern Analysis
Ordinal Pattern Analysis for Ordinal Example (Rat Bar Presses)
Order Imprecision value = 0
Compute Matches = Full pattern of ordinal relations
Missing Values = Omitted from Totals
Randomization Method = All Observations
Analyze: Deep Structures Analyzed
B1
Min = 0-2
Max = 12-14
# Units
B2
Min = 0-2
Max = 12-14
# Units
T1
Min = 0-2
Max = 12-14
# Units
T2
Min = 0-2
Max = 12-14
# Units
T3
Min = 0-2
Max = 12-14
# Units
Group
Experimental;
Control
Classification Results :
=
=
=
=
=
5
5
5
5
5
Experimental
Ordinal Relations between Pairs of Observations Classified
According to the Defined Pattern(s)
Classifiable Pairs of Observations : 72
Correct Classifications : 65
Percent Correct Classifications : 90.28
Classifiable Complete Cases : 6
Correctly Classified Complete Cases : 5
Percent Correct Classified Cases : 83.33
Individual Classification Results :
Presumably, the user would have a rationale for defining the
ranges as shown. Nonetheless, the output for the experimental
rats is shown in Figure 10.13. As can be seen, the summary
information details the defined units, and the overall results
reflect the fact that the analysis is now based on the deep
structures (viz., the defined ranges) rather than on the numbers
themselves.
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
1
2
3
4
5
6
7
8
Experimental
Observations
|
Missing
|
|
Classifiable Pairs of Observations
|
|
|
Correct Classifications
|
|
|
|
PCC
|
|
|
|
|
c-value
5
0
10
10
100.00
0.03
4
1
6
6
100.00
0.03
5
0
10
10
100.00
0.03
5
0
10
10
100.00
0.02
5
0
10
3
30.00
0.59
4
0
6
6
100.00
0.03
5
0
10
10
100.00
0.02
5
0
10
10
100.00
0.03
OOM Software Manual
For the units (deep structures) defined above as ranges, it can
now be seen that ExpRat 2 fits the expected ordinal pattern
perfectly:
ExpRat 2
Unit #
B1
0-2
1
B2
0-2
1
T1
12-14
5
T2
9-11
4
T3
missing
.
Note the units for B1 and B2 are identical, as expected, and the
unit number decreases from T1 to T2, which are both greater
than the unit numbers for B1 and B2. T3 is missing.
Ordinal Classifications
There are two ways to determine if ordinal relations are
classified correctly in the Ordinal Pattern Analysis: Full and
Adjacent Only. Consider a single rat, ExpRat 1. With the Full
option, every observation for ExpRat 1 is compared to every
other observation; B1 vs. B2, B1 vs. T1, B1 vs. T2, etc. In this
way, the entirety of the ordinal pattern is taken into account,
and for each rat in this example 5C2, or 10, comparisons are
possible (generally, nC2, where n equals number of non-missing
observations). Figure 9.14 shows an expected ordinal pattern
and the actual observations for ExpRat 1. Correctly classified
observations are tallied for B1 vs. T1, B1 vs. T2, B2 vs. T1, etc.
Figure 10.14
Example Ordinal Pattern
with One Rat’s
Observations
110
The number of correct classifications for this rat using the Full
option is therefore 8, or 80% (8 / 10 * 100). The two
misclassifications are as follows: B1 is not equal to B2, and B2
is not equal to T3.
If the Adjacent Only option is chosen, then pairs of
observations are compared only if they are immediately
adjacent to one another. For this example, then, the Adjacent
Only comparisons are B1 vs. B2, B2 vs. T1, T1 vs. T2, and T2
vs. T3, for four possible correct classifications. Generally, there
will be n – 1 possible correct classifications, where n equals the
number of non-missing observations. For the rat in Figure 9.14,
3 of the 4 comparisons, or 75%, are correct classifications. The
only misclassification is for B1 vs. B2. The Adjacent Only
option is thus less restrictive than the Full option as it only
considers a subset of all possible ordinal comparisons for the
concatenated observations. The user must decide which set of
comparisons best fits his or her integrated model.
Missing Values
Two options for missing values are available: Omit and
Include. When the Omit option is chosen, the missing values
will not be included in the total numbers of pairs of
observations that can be classified. The annotated output in
Figures 10.8 and 10.10 show example results in which the
Missing Values option was set to Omit. In these results, for
example, the total number of Classifiable Pairs of
Observations for the 8 experimental rats is 76, and the
Classifiable Complete Cases is 7 because of the missing
values in the data set. If the Missing Values option is set to
Include, these two values are 80 and 8, respectively. The
missing values are thus counted in the totals. The results
OOM Software Manual
printed for the individual rats will similarly be impacted by this
option, and Figure 10.15 shows results for the experimental
rats for which the Missing Values option has been set to
Include. This output can be compared to the output in Figure
10.8.
Classification Imprecision
Normally, correct classification are tallied based on the
entered values or upon the deep structure units. With the Order
Imprecision option ranges of values are considered when
determining then classifications. For instance, consider the
following values for B1 to T3 and the expected pattern of
ordinal relationships shown:
ExpRat X
B1
1
B2
0
T1
12
T2
3
T3
1
Further suppose that the Numbers are being analyzed, and the
classifications are based on the Full option. Given these options,
it can be clearly seen that only B1 fails to fall in the proper
order (B1 should be equal to B2, but 1 > 0). If the Order
Imprecision value is set to 1, then B1 and B2 (as well as all
other comparisons) would be considered equal if their
difference is less than or equal to 1. Consequently, B1 and B2
would be considered as equal with the Order Imprecision value
set to 1 because 1 – 0 = 1. Note that T2 vs. B1 would still fit
the ordinal pattern because 3 – 1 = 2.
111
For the same example, consider setting the Order
Imprecision value to 2. In this instance, B1 would be judged as
equal to B2 (1 – 0 < 2), consistent with the expected pattern;
but, T2 would not be judged as greater than to B1 (3 – 1 = 2,
which is equal to 2), which is inconsistent with the expected
pattern. In the extreme, the largest difference is 12, or 12 – 0.
Setting the Order Imprecision value to 12 would result in each
comparison being judged as equal, contradicting most of the
expected ordinal, pairwise relations.
Using the Order Imprecision option can therefore be
tricky for patterns which represent both equalities and
inequalities, like the current bar press example. By contrast,
imagine an expected pattern like the third panel in Figure 10.11
(a monotonic decrease across all concatenated observations).
Setting the Order Imprecision value to 2, for instance, would
help the user to evaluate if each difference across the pattern is
greater than 2 (or 2 deep structure units).
Finally, when the Deep Structure option for Analyze is
selected, then the Order Imprecision value will be applied to
the deep structure units. The value will constitute a range of
deep structure units rather than a range of numbers built around
the values as they are entered in the Data Edit window.
OOM Software Manual
112
Figure 10.15 Selected Annotated Output for Ordinal Pattern Analysis:
Missing values included in totals
Ordinal Pattern Analysis for Ordinal Example (Rat Bar Presses)
Classification Imprecision value = 0
Ordinal Classifications = Full pattern of ordinal relations
Missing Values = Included in Totals
Classification Results :
Experimental
Ordinal Relations between Pairs of Observations Classified
According to the Defined Pattern(s)
Classifiable Pairs of Observations : 80
Correct Classifications : 61
Percent Correct Classifications : 76.25
Classifiable Complete Cases : 8
Correctly Classified Complete Cases : 1
Percent Correct Classified Cases : 12.50
Individual Classification Results :
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
1
2
3
4
5
6
7
8
Experimental
Observations
|
Missing
|
|
Classifiable Pairs of Observations
|
|
|
Correct Classifications
|
|
|
|
PCC
|
|
|
|
|
c-value
|
|
|
|
|
|
5
0
10
8
80.00
0.03
4
1
10
6
60.00
0.16
5
0
10
10
100.00
0.01
5
0
10
8
80.00
0.02
5
0
10
5
50.00
0.27
5
0
10
8
80.00
0.02
5
0
10
8
80.00
0.02
5
0
10
8
80.00
0.02
Here the Missing Values option has been set to Include.
The results shown here are for the experimental rats using the same pattern
in Figure 10.8.
The Full option was also chosen for Ordinal Classifications. Consequently,
a correct classification is tallied when:
B1 = B2, B1 < T1, B1 < T2, B1 = T3, B2 < T1, B2 < T2, B2 = T3,
T1 < T2, T1 < T3, or T2 < T3
In other words, for each case (rat) there are 5C2, or 10, possible correct
classifications. Given 8 experimental rats and the Include option, the
Classifiable Pairs of Observations is equal to 80. There are 8 rats in this
group, so the Classifiable Complete Cases is equal to 8.
The results for the individual rats are shown here, and the Classifiable
Pairs of Observations are all set equal to 10 (5C2) because the Full option
was also chosen for Ordinal Classifications. If the Adjacent option had
been chosen, then these values would all be equal to 4 (# orderings – 1)
rather than 10. The Classifiable Pairs of Observations would also be
computed as 32 (4 * 8 experimental rats) rather than 80.
OOM Software Manual
Cases. With this option, a randomized version of the ExpRatX
observations may be as follows:
Randomization Test
Randomization Test
The Randomization Test provides a tool for evaluating
the number of correctly classified pairs of observations and
number of correctly classified complete cases from the analysis
(see the annotated output in Figure 10.8 above). As with all
analyses in OOM, the percent correct classifications (PCCs)
are themselves the primary results upon which the user is to
place most of his or her emphasis. The best case scenario is to
interpret these values in the context of an integrated model.
The analysis works by randomly shuffling the
concatenated values and then computing the PCC indices
according to the chosen options. For instance, consider the
following observations and expected ordinal pattern:
ExpRat X
B1
1
B2
0
T1
12
113
T2
3
T3
1
Analyzing numbers, with the Full matches option, and Order
Imprecision equal to 0, 8 of the 10 pairwise ordinal
comparisons fit expectation. These observations do not,
however, constitute a completely matched case.
There are four ways to randomize the data by setting
the Randomize option. The first option is Randomize within
Rand 1
B1
12
B2
3
T1
0
T2
1
T3
1
These random observations also do not constitute a completely
matched case, and the number of correctly classified pairs of
observations is equal to 0 as the pattern or ordinal relations do
not fit the expected pattern in any way.
The user determines the number of randomized
versions (trials) of observations to be created and tallied for
correctly classified observations. For each trial, a random order
is determined independently for each case; i.e., for each rat in
the current example.
A very important issue to understand when the
Randomize within Cases option is chosen regards c-values that
will necessarily equal 1.0. This issue will occur when a) a
pattern of equality has been defined (see Figure 10.7), and b),
the Ordinal Classification option has been set to Full. Consider
the following pattern of equality:
B1
| B2
| | T1
| | | T2
| | | | T3
O O O O O Highest
O O O O O
+ + + + +
O O O O O
O O O O O Lowest
The actual observations and any randomly shuffled set of
observed frequencies (using the Randomize within Cases
OOM Software Manual
option) will fit this pattern the same way when the Full Ordinal
Classifications option has been selected. Consider the
following observations and two randomized versions thereof:
ExpRat X
Rand 1
Rand 1
B1
1
12
3
B2
0
3
1
T1
12
0
12
T2
3
1
1
T3
1
1
0
The PCC index in all three instances equals 10.00%. The
overall and individual c-values will therefore necessarily equal
1.0 with this type of expected pattern and these selected
options. To avoid c-values equal to unity under such conditions,
a different randomization option must be chosen.
Selecting the Randomize within Orderings option will
randomized the data between cases only. For instance, consider
observations for the following two rats:
ExpRat X
ExpRat Y
B1
1
5
B2
0
6
T1
12
8
T2
3
10
T3
1
11
A randomized version of these observations may appear as
follows:
ExpRat X
ExpRat Y
B1
5
1
B2
0
6
T1
12
8
T2
10
3
T3
11
1
Note how the values in each column (ordering) have been
randomized. Some of ExpRatX’s values have been traded with
ExpRatY’s values within the orderings. In other words, the
observations have been randomized between cases but within
orderings.
114
Selecting the Randomize All Observations option will
randomized the data first within and then between cases. For
instance, again consider observations for the following two rats:
ExpRat X
ExpRat Y
B1
1
5
B2
0
6
T1
12
8
T2
3
10
T3
1
11
A randomized version of these observations may appear as
follows:
ExpRat X
ExpRat Y
B1
3
0
B2
1
6
T1
12
5
T2
8
10
T3
11
1
Note how the values have been completely randomized
between cases and within orderings.
Lastly, the Randomize Deep Structures option generates
random values for the deep structures of the observations. For
example, consider units of frequencies defined as four equal
intervals of 5 seconds: 0-4, 5-9, 10-14, and 15-19. Now
consider the following observations and their deep structure
unit values:
Rat1
Rat2
Rat3
Rat4
Freq
9
1
7
17
Unit
2
1
2
4
A randomized version of these data may appear as:
Rat1
Rat2
Rat3
Rat4
Freq
9
1
7
17
Unit
1
3
3
4
OOM Software Manual
The unit values can range from 1 to 4, and the randomization
routine randomly generated the unit value for each case. This
process is tantamount to moving the “1” in the deep structure
for each rat to a new unit.
This method also makes it possible for an unobserved
unit to be randomly generated. For instance, if an additional
unit of 20-24 were defined for the example data above, no rat
in the sample recorded frequencies exceeding 19. Yet, with the
Randomize Deep Structure option, that unit could be randomly
generated for a rat. This is a key difference between this option
and the other randomization options. With the Deep Structure
option, the deep structure units are randomly generated; with
the other options, the data themselves are always randomly
shuffled.
Finally, if the Deep Structure option is chosen, it is
likely to make most sense to choose Deep Structures for the
Analyze option (see Figure 10.9) as well, although this is not
necessary. It is the user’s responsibility to define the ordered
observations in a way that is theoretically meaningful, and then
to choose the appropriate analysis options.
Save Randomized Results
When this option is selected and the analysis conducted,
a new data set will be created. The number of observations in
the data set will equal the number of trials set by the user
(provided the iterative process is not interrupted by selecting
the [Stop] button). A new data set will be created for each unit
of the Separate by ordering. For the bar pressing data, for
instance, two data sets will be generated; one for the
experimental rats and one for the control rats. Each data set
will be comprised of six orderings: (1) classifiable pairs of
115
observations, (2) correct classifications, (3) percent correct
classifications, PCC, (4) classifiable complete cases, (5)
correctly classified complete cases, (6) percent correct
classified cases, PCC, and (7) columns of PCC values for each
case when the Individual Results Output option (see below) is
chosen. All of the values for Classifiable Pairs of Observations
will be equal, and the value will be determined by the number
of concatenated observations and selected analysis options. All
values for Classifiable Complete Cases will also be equal and
similarly determined (see the annotated output in Figure 10.8
above).
The cases in the data sets will be labeled, rand_1,
rand_2, rand_3, etc. as a reminder of their origin from the
randomization test. As with any data set in OOM, these
randomization results can be examined, edited, sorted, saved,
concatenated, etc.
Output
Pattern Definitions
Selecting this option will print the defined patterns in
the Text Output window. This option is selected by default so
the user can check to make certain the patterns have been
defined properly. Here is the example pattern for the
experimental rats above:
OOM Software Manual
Defined Pattern : Experimental
B1
| B2
| | T1
| | | T2
| | | | T3
O O O O O Highest
O O O O O
O O + O O
O O O + O
+ + O O + Lowest
The entire grid of possible ordinal relations is printed and
labeled. The blue crosses indicate the expected ordinal
relations.
Ordering Summaries
Summaries of the orderings will be printed to the Text
Output window. The summary is described in greater detail in
Chapter 3.
Individual Results
Results for each case will be printed in the Text Output
window when this option is chosen. The number of
observations and missing values are reported for each case. If
the Full option is chosen for Ordinal Classifications, then the
number of classifiable pairs of observations is computed as nC2,
where n equals the number of non-missing observations. If the
Adjacent Only option is instead chosen, then the number of
classifiable pairs of observations is computed as n – 1.
The Correct Classifications are tallies based on the
comparisons between the actual observations and the expected
pattern of ordinal relations. Obviously, the Correct
Classifications will range from 0 to the Classifiable Pairs of
116
Observations in the output. Dividing the Correct Classifications
by the Classifiable Pairs of Observations, and multiplying by
100, yields the Percent Correct Classifications. When the
Randomization option is selected, c-values for each case will
also be reported based on the type of randomization method
selected. The examples of annotated output in this chapter
show these individual c-values.
Save Individual Results
When this option is selected, the individual results
described and shown above will be reported and labeled in a
new data set in the Data Edit window. As an OOM data set, it
can be edited, sorted, concatenated, saved etc.
Save Difference Scores
In longitudinal studies it is often desirable to examine
the changes in numeric values over time. Selecting this option
will create a new data set in OOM that is reported in the Data
Edit window. Difference scores for all possible pairs of
orderings will be computed and recorded. Consider the
following frequencies for ExpRat 1:
ExpRat 1
B1
2
B2
0
T1
10
T2
7
T3
2
Simple differences are computed as B2 – B1, T1 – B1, T2 – B1,
T3 - B1, T1 – B2, T2 – B2, etc., and reported. The
computations are based on the values as shown in the Data
Edit window or upon the deep structures depending upon
OOM Software Manual
which Analyze option is chosen. For ExpRat 1, based on the
Numbers analysis option, the results are as follows:
ExpRat 1
B2–B1
-2
T1–B1
8
T2–B1
5
T2-T1
-3
T3-T1
-8
T3–T2
-5
T3–B1
0
T1–B2
10
T2–B2
7
T3-B2
2
These difference scores for all cases (rats, in this example) can
be subjected to different modeling analyses. For instance, the
rate of change in frequencies from B2 to T1 between the
experimental and control rats can be compared by attempting
to conform the T1 – B2 difference ordering to the group
ordering using the Build/Test Model analysis in OOM.
If the Deep Structures analysis option is chosen, and the
deep structures are defined as described above (see Analyze
section), then the units are as follows:
ExpRat 1
Unit #
B1
0-2
1
B2
0-2
1
T1
9-11
5
T2
6-8
3
T3
0-2
1
The computed and saved differences are as follows:
ExpRat 1
B2–B1
0
T1–B1
3
T2–B1
2
T2-T1
-1
T3-T1
-3
T3–T2
-2
T3–B1
0
T1–B2
3
T2–B2
2
T3-B2
0
Note how the differences are not based upon the frequencies of
bar presses but instead upon the ordinal positions of the defined
deep structure units.
117
OOM Software Manual
11
118
Efficient Cause Analysis
This analysis can be used to evaluate whether or not
changes in orderings match each other over time. It fits with
Aristotle’s understanding of an efficient cause as one that leads
to a change in events (movement) or to the generation of some
structure. This analysis can also be used more generically to
compare the patterns of two groupings of orderings. As with
other analyses in OOM, the results are examined at the level of
individual observations rather than at the level of the aggregate.
Consider the following two sets of ordered observations:
Sleep Judgment
Person1
Person2
Person3
Person4
Person5
Sp1
2
0
2
0
2
Sp2
3
1
3
0
1
Sp3
0
2
4
0
0
Sp4
1
2
2
0
1
Sp5
4
4
3
2
0
Sp6
0
3
1
0
2
Md5
5
8
3
7
10
Md6
7
6
7
8
8
Sp7
1
3
2
0
1
Mood Judgment
Person1
Person2
Person3
Person4
Person5
Md1
8
8
6
4
8
Md2
7
10
5
3
9
Md3
10
9
4
2
10
Md4
9
.
5
8
9
File: EfficientCauseExample.oom
Md7
5
7
5
10
9
The first set reports self-reported judgments made on seven
consecutive mornings regarding the quality of sleep obtained
the night before. Each judgment is made on an 11-point scale
with units labeled 0, 1, 2…10. Selecting 0 indicates the poorest
night of sleep imaginable while 10 indicates the best night of
sleep imaginable. The second set of observations use the same
number of units with 0 indicating the worst possible mood
imaginable and 10 indicating the best possible mood
imaginable. These judgments are made on the evening of each
of the seven consecutive days.
As has been the case in this software manual, an
integrated model describing the efficient cause relationships
between sleep and mood is not available. The analyses here are
therefore conducted solely for the reason of demonstrating the
software, and an initial analysis of these observations may
investigate whether or not the five people were consistent in
their sleep and mood judgments across the seven days such that
each day’s mood judgment conformed to each day’s sleep
judgment (Sp1,Sp2..Sp7 Md1, Md2..Md7). Another model
that could be tested entails the mood judgment as the cause and
the sleep judgments as the effect. In this model, however, the
sleep judgments must be lagged so that, for instance, the sleep
judgment on the morning of day 2 follows the mood judgment
on the evening of day 1 (Md1, Md2…Md6 Sp2, Sp3…Sp7).
Analysis of each of these models will be demonstrated below,
beginning with the Sp1, Sp2…Sp7 Md1, Md2…Md7 model.
OOM Software Manual
The Efficient Cause Analysis window is shown in
Figure 11.1. As can be seen, the seven sleep orderings have
been moved into the Efficient Cause Observations edit box,
while the seven mood orderings have been moved into the
Effect Observations. The Deep Structures of the observations
will be analyzed, and neither the Cause nor Effect units of
observation have been reflected (Reflect Units/Values option)
for this analysis. If an inverse relationship between the cause
and effect units were expected, then either could be reflected in
light of this expectation. In this example, however, the sleep
and mood units are expected to conform to one another as
ordered (e.g., a mood observation of 10 will conform to a sleep
observation of 10). The Full classifications option and Omit
from Totals option have also been chosen, which will be
described in greater detail below. A randomization test and
other output options have also been selected, which will be
described in the annotated output below. The Classification
Imprecision and Efficient Cause Lag options have both been
set to zero for this analysis. The Efficient Cause Lag is
particularly relevant here as it indicates the seven cause and
seven effect orderings will be aligned as they are ordered in
Figure 11.1. Specifically, Sp1 will be aligned with Md1, Sp2
with Md2, etc. If Efficient Cause Lag is set to 1, for example,
then the efficient cause orderings would be lagged behind the
cause observations (Sp1 aligned with Md2, Sp2 aligned with
Md3, etc.). Lagging the effect behind the cause permits the
researcher to examine if the cause preceding each effect
provides the most accurate congruence between patterns of
observations. An example of lagging the effect will be shown
below. As this introductory stage, however, selecting the
[Examine Patterns] button (see Figure 11.1) is most
119
informative, as it opens a separate window in which the pattern
for each of the five persons can be examined.
Figure 11.1 Efficient Cause Analysis
OOM Software Manual
Figure 11.2 shows the Efficient Cause Patterns window
with the first person’s (Person1) observations displayed. Note
how the columns of the 2-dimensional pattern represent the
cause orderings (7 days of morning sleep reports labeled on top)
aligned with the effect observations (7 days of evening mood
reports labeled on bottom). The Units of observation along the
left side of the pattern refer to the cause, while the units on the
right refer to the effect. In this example, the units for cause and
effect are aligned, 0 – 10.
The Effect Lag edit box in Figure 11.2 displays “Cause
= Effect” which means the effect orderings have not been
lagged. For Person1 the sleep and mood observations
conformed perfectly for days 1, 2, 5, and 6. On day 1, for
instance, the person judged his/her sleep and evening mood as
7; on day 2, the observed units were both 8. On day 3, however,
the sleep (cause in red) observation was 5 compared to 6 for
the mood observation (effect in blue). For three of the seven
days, then, the effect observations did not conform to the cause
observations.
When deep structures are analyzed, each column is
considered as a possible correct classification when the cause
and effect observations are available (non-missing). For
Person1, all seven sleep and mood observations are available,
yielding a total of 7 Possible Correct (see Figure 11.2). As
indicated by the overlapping cells, four of the seven pairs of
observations were congruent, yielding a PCC equal to 57.14%,
as shown in Figure 11.2. A c-value equal to .0220 is also
reported for this PCC. Using the double-arrow to the left of the
Show Observation edit box, the user can scroll through all five
persons and examine the PCC indices.
120
Figure 11.2 Efficient Cause Analysis, Person1
Figure 11.3 shows the observations for Person2, now
with the Lines option de-selected. It can be seen that an
observation was not available for mood on day 4. The missing
observation does not prevent the PCC and c-value from being
computed. Across the five persons, missing values are similarly
treated; hence, missing values are easily accommodated in the
efficient cause analysis in OOM.
It can also be seen in Figure 11.3 that the effect
observations appear to follow the cause observations, but they
OOM Software Manual
Figure 11.4 Efficient Cause Analysis, Person2, Effect lagged one day
Figure 11.3 Efficient Cause Analysis, Person2
are lagged by one day. Using the double-arrow to the left of the
Effect Lag edit box, the effect can be lagged. Figure 11.4 shows
the observations for Person2 with the effect lagged by one day.
As can be seen, the observations now overlap perfectly
(excluding the missing mood observation on day 4). For this
person, then, lagging the effect increased the PCC value. The
effect is not lagged, however, for the other four people. The
results for the non-lagged effect are reported in the annotated
output in Figure 11.5.
121
OOM Software Manual
122
Figure 11.5 Annotated Output for Options shown in Figure 11.1
Efficient Cause Analysis for Efficient Cause Example Data Set
Classification Imprecision = 0
Effect Lag = 0
Analyze : Deep Structures
Reflect Units/Values : Neither
Ordinal Classifications : Full
Missing Values = Omitted from Totals
Randomization Method = within Effect Observations
The options chosen are reported here. The name of the option is printed in
black, and the option selected by the user is printed in blue. As noted above
the effect is not lagged for this analysis. The options will be described in
subsequent sections of this chapter and in subsequent annotated output.
Ordering Frequency Summaries
Sp1
Sp2
Sp3
Sp4
Sp5
Sp6
Sp7
Totals
Units:
Units:
Units:
Units:
Units:
Units:
Units:
Units:
11
11
11
11
11
11
11
77
Missing:
Missing:
Missing:
Missing:
Missing:
Missing:
Missing:
Missing:
0
0
0
0
0
0
0
0
Undefined:
Undefined:
Undefined:
Undefined:
Undefined:
Undefined:
Undefined:
Undefined:
0
0
0
0
0
0
0
0
Obs:
Obs:
Obs:
Obs:
Obs:
Obs:
Obs:
Obs:
5
5
5
5
5
5
5
35
0
0
0
1
0
0
0
1
Undefined:
Undefined:
Undefined:
Undefined:
Undefined:
Undefined:
Undefined:
Undefined:
0
0
0
0
0
0
0
0
Obs:
Obs:
Obs:
Obs:
Obs:
Obs:
Obs:
Obs:
5
5
5
4
5
5
5
34
All of the cause orderings and effect orderings are summarized here. As can
be seen, only one data point is missing for the Md4 ordering.
Ordering Frequency Summaries
Md1
Md2
Md3
Md4
Md5
Md6
Md7
Totals
Units:
Units:
Units:
Units:
Units:
Units:
Units:
Units:
11
11
11
11
11
11
11
77
Missing:
Missing:
Missing:
Missing:
Missing:
Missing:
Missing:
Missing:
Units of Observation (Cause | Effect) :
0 | 0
1 | 1
2 | 2
3 | 3
4 | 4
5 | 5
6 | 6
7 | 7
8 | 8
9 | 9
10 | 10
The units of observation for the cause and effect orderings are reported
here. The cause orderings (Sp) must have the same number of units, and the
effect orderings (Md) must have the same number of units. The number of
units for the cause and effect orderings should be equal as well when the
Deep Structures are Analyzed (see option selected above). They should be
equal because the goal is to match the observations across the cause and
effect orderings (see Figures 13.3 and 13.4), and if the number of units is
not equal, then some observations will be impossible to match. As can be
seen in the output, both cause and effect orderings have units labeled 0, 1, 2,
etc., and the number of units is in fact equal (11 units). When Numbers
(Ordinal) is Analyzed, then the number of cause units need not equal the
number of effect units.
OOM Software Manual
Figure 11.5 Continued
The cause and effect orderings to be analyzed are reported here and aligned
in the orders they are selected by the user. Because the effect has not been
lagged, each daily report of sleep quality is aligned with each day of judged
mood.
Efficent Cause / Effect Links :
Sp1 --> Md1
Sp2 --> Md2
Sp3 --> Md3
Sp4 --> Md4
Sp5 --> Md5
Sp6 --> Md6
Sp7 --> Md7
Classification Results :
Effect Observations Classified to Cause Observations
Classifiable Observations : 34
Correct Classifications : 12
Percent Correct Classifications : 35.29
Randomization Results :
Observed Percent Correct Classifications : 35.29
Trials
Correct
Correct
Correct
c-value
:
:
:
:
:
Because the Deep Structures were analyzed, the number of Classifiable
Observations is equal to 34. Recall there are five people with observations
that can be classified to the cause observations on seven days. This yields a
total of 35 observations (5 * 7 = 35), and deleting the 1 missing value for
Md4 yields the 34 reported in the output. If Missing Values option was set
to Include in Totals, then the Classifiable Observations would equal 35
here. Twelve of the effect observations conformed to the cause
observations, yielding an unimpressive PCC value of 35.29.
Four of the five people had observations for all 7 sleep and all 7 mood
orderings and were therefore counted as Classifiable Complete Cases. Of
these, only 1 person’s effect observations conformed completely to the
cause observations. This person will be identified below, but with 7 cause
and effect orderings, perhaps even a single complete match is noteworthy.
Classifiable Complete Cases : 4
Correctly Classified Complete Cases : 1
Percent Correct Classified Cases : 25.00
Number of Randomized
Minimum Random Percent
Maximum Random Percent
Values >= Observed Percent
Model
123
1000
3.03
39.39
10
0.01
The randomization test for the PCC value of 35.29 is also impressively low,
(.01). Only in 10 instances of 1000 randomized versions of the data, was a
PCC value of 35.29 or higher found. The highest value was 39.39. Still,
only 35.29% of the observations have been classified accurately, indicating
the effects do not match the causes at an impressively high proportion. How
the observations are randomized will be described in the chapter text.
OOM Software Manual
124
Figure 11.5 Continued
Observed Percent Correct Classified Cases : 25.00
Number of Randomized Trials : 1000
Minimum Random Percent Correct Cases : 0.00
Maximum Random Percent Correct Cases : 0.00
Values >= Observed Percent Correct Cases : 0
Model c-value : less than ( 1 / 1000);
that is, < 0.001
The randomization test for the Percent Correct Classified Cases also
yielded a very small c-value (< .001). However, Percent Correct Classified
Cases was only 25.00 (1/4). Again, only one person’s cause and effect
observations were perfectly congruent across all 7 days. The low c-value is
understandable, however, since randomizing across all 7 days would not
likely yield perfect conformity between the cause and effect observations.
Individual Summary Results :
Person1
Person2
Person3
Person4
Person5
Cause Observations
|
Effect Observations
|
|
Classifiable Observations
|
|
|
Correct Classifications
|
|
|
|
PCC
|
|
|
|
|
c-value
|
|
|
|
|
|
7
7
7
4
57.14
0.02
7
6
6
1
16.67
0.73
7
7
7
0
0.00
1.00
7
7
7
0
0.00
1.00
7
7
7
7
100.00
0.00
The individual results are shown here. As can be seen, the 5 th person’s
observations yielded a PCC value of 100. This is the person whose cause
and effect observations matched perfectly across all seven days. Person 3’s
PCC was 0, indicating a complete mismatch between his/her cause and
effect observations. The low c-values indicate that Person1 and Person5’s
PCC values were highly improbable or unusual.
Individual Classification Results :
Person1
Person2
Person3
Person4
Person5
Sp1-->Md1
|
Sp2-->Md2
|
|
Sp3-->Md3
|
|
|
Sp4-->Md4
|
|
|
|
Sp5-->Md5
|
|
|
|
|
Sp6-->Md6
|
|
|
|
|
|
Sp7-->Md7
|
|
|
|
|
|
|
1
1
0
0
1
1
0
0
0
0
.
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
1
1
1
1
1
Note. 0 = Incorrect; 1 = Correct.
The individual classification results show exactly where the cause and effect
observations overlapped. For Person1, the sleep and mood observations
matched with respect to their units on days 1, 2, 5, and 6. With 4 of 7
conforming cause/effect observations, the PCC value in the Individual
Summary Results is equal to 57.14. Person2 has a missing value for Md4,
with only one day on which the cause and effect observations matched
(PCC = 1 / 6 * 100 = 16.67). Person5’s effect observations conformed with
the cause observations on each of the 7 days.
OOM Software Manual
125
As mentioned above, another model would treat the
mood judgments as the causes and the sleep judgments as the
effects; but the sleep judgments must be lagged so that the
sleep judgment on the morning of day 2 follows the mood
judgment on the evening of day 1, the sleep judgment on the
morning of day 3 follows the mood judgment on the evening of
day 2, etc. In other words, Md1, Md2…Md6 Sp2,
Sp3…Sp7. Figure 11.6 shows the Efficient Cause window with
the orderings selected and options selected.
Figure 11.7 shows the observations for Person3 in the
Efficient Cause Pattern window. As can be seen, Md1 is
aligned with Sp2, Md2 with Sp3, etc. In other words, the effect
(sleep judgment) has been lagged a single day. Also notice that
the last column, Md7, has no associated sleep judgment given
that only seven days of observations were made. With no
missing observations and perfect conformity, the number of
correct classifications is 6 for a PCC equal to 100% and an
accompanying c-value equal to .002.
Figure 11.6 Efficient Cause Analysis: Mood Judgments as the Cause
Figure 11.7 Efficient Cause Pattern, Person3, Mood Judgments as Cause
OOM Software Manual
The remaining output for this model, however, is not
very impressive. Consider the overall classification results:
Classification Results :
Effect Observations Classified to Cause Observations
Classifiable Observations : 29
Correct Classifications : 7
Percent Correct Classifications : 24.14
however, even this low PCC value was unusual (c-value
< .001). The individual summary results show that Person3 is
the person who’s lagged effect observations conformed
perfectly to the cause observations. For persons 2, 4, and 5,
none of the lagged effect (mood) observations conformed to
the cause (sleep) observations.
Individual Summary Results :
Classifiable Complete Cases : 4
Correctly Classified Complete Cases : 1
Percent Correct Classified Cases : 25.00
Randomization Results :
Observed Percent Correct Classifications : 24.14
Number of Randomized
Minimum Random Percent
Maximum Random Percent
Values >= Observed Percent
Model
Trials
Correct
Correct
Correct
c-value
:
:
:
:
:
126
1000
0.00
37.93
265
0.27
Observed Percent Correct Classified Cases : 25.00
Number of Randomized Trials : 1000
Minimum Random Percent Correct Cases : 0.00
Maximum Random Percent Correct Cases : 0.00
Values >= Observed Percent Correct Cases : 0
Model c-value : less than ( 1 / 1000);
that is, < 0.001
Only 24.14 percent of the observations were correctly
classified, and the randomization test indicated that this was
not an unusual result. As in the original model above, one
person’s lagged effect observations could be perfectly
conformed to the cause observations, PCC = 25.00, excluding
cases with missing observations. With six days of observations,
Person1
Person2
Person3
Person4
Person5
Cause Observations
|
Effect Observations
|
|
Classifiable Observations
|
|
|
Correct Classifications
|
|
|
|
PCC
|
|
|
|
|
c-value
|
|
|
|
|
|
6
6
6
1
16.67
0.67
5
6
5
0
0.00
1.00
6
6
6
6
100.00
0.01
6
6
6
0
0.00
1.00
6
6
6
0
0.00
1.00
The individual classification results shows the details for each
cause and effect observation, and the column headings show
the lagged effect matched with the cause.
Individual Classification Results :
Person1
Person2
Person3
Person4
Person5
Md1-->Sp2
|
Md2-->Sp3
|
|
Md3-->Sp4
|
|
|
Md4-->Sp5
|
|
|
|
Md5-->Sp6
|
|
|
|
|
Md6-->Sp7
0
0
1
0
0
0
0
0
0
0
0
1
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
0
0
Note. 0 = Incorrect; 1 = Correct.
OOM Software Manual
Options
Examine Patterns
Selecting the [Examine Patterns] button will open the
window shown in Figure 11.8. This window is used to examine
the patterns of cause and effect observations for each person
(case). Person1 is shown in Figure 11.8, as can be seen in the
edit boxes next to the “Show Observation” label.
Figure 11.8 Efficient Cause Analysis, Person1
It can also be seen that the cause and effect observations are
considered to be aligned across the seven days (“Cause =
127
Effect” in the “Align Effect” edit box). The two dimensional
figure can be enlarged or shrunk using the “Font Size” arrows
or edit box, and the shown image can be saved or printed using
the respective buttons. Selecting the “Lines” option connects
the observation units with lines, as shown in Figure 11.8. The
“Color” option toggles between a colorful and black/white
presentation of the observations in the graph. The “Grid”
option toggles the grid lines on or off.
When the lines are shown, the color coding scheme
changes slightly; specifically, when the cause and effect are
matched in the same unit, the dots and lines are not colored
green. The cause is still represented by red and the effect by
blue. Notice in Figure 11.4 above how the matched units are
colored green for days 1, 2, 5, and 6 when the Show Lines
option is not chosen. When the Show Lines option is chosen, as
in Figure 11.8, the red and blue lines intersect when the effect
conforms to the cause.
The number “# Correct” is computed according to
whether or not the deep structures or numbers (see Figure 11.1
and Analyze below) are being analyzed. For Figure 11.8 the
deep structures are being analyzed, consequently the “#
Correct” represents the number of overlapping cause and effect
observations; in this case four. The “Possible Correct” is
determined on the basis of the Missing Values option (see
Figure 11.1 and Missing Values below). If the missing values
are omitted from the totals, then “Possible Correct” will not
include missing values for the cause and effect observations. If
the missing values are included in the totals, then “Possible
Correct” will always equal the number of effect orderings in
the analysis and graph; seven in Figure 11.8.
OOM Software Manual
The “c-value” is computed using the randomization
method selected and number of iterations entered in the
Efficient Cause Analysis window (see Figure 11.1). The
randomization methods are described in detail below.
Analyze
Either the Deep Structures or Numbers (Ordinal) can be
analyzed in the Efficient Cause Analysis. The annotated output
in Figure 11.5 above shows results based on the Deep
Structures option. With this option the goal of the analysis is to
determine if the cause and effect observations conform to one
another (i.e., are matched on their units). Figure 11.8 above
shows that Person1’s cause and effect deep structures are
matched on days 1, 2, 5, and 6 but not on the other days.
Although it is not necessary, the number of units for the cause
and effect should be equal when the Deep Structure Analyze
option is chosen. If, for example, the cause in Figure 11.8 was
only structured with two units (0, 1), most of the units for the
effect observations (viz., 2,3,…10) could not possibly match.
When the Numbers (Ordinal) option is chosen, values
entered into the Data Edit window are instead analyzed. Deep
structures are therefore not used; rather the ordinal relations
between the entered values are analyzed. The question is thus
not about conforming observations in terms of their deep
structures, but whether differences (ordinal relations) across the
effect orderings conform to differences across the cause
orderings. Figure 11.10 shows the patterns of sleep and mood
observations for Person3 when the Deep Structure option is
chosen. As can be seen, none of the cause and effect
observations were matched on their deep structure units. Still,
it appears that differences across the ordering are highly similar;
128
Figure 11.10 Efficient Cause Analysis, Person3
for example, from days 1 through 3 both the sleep and mood
judgments increased, and both increased from day 5 to day 6.
Selecting the Numbers (Ordinal) option permits the user to
examine the number of instances in which these changes
(increase/decrease) co-occur for the cause and effect
observations. Clearly, the Numbers (Ordinal) options should
only be chosen if the values entered into the Data Edit window
for the causes and effects represent countable instances of
some thing or event or are continuous quantities. Figure 11.11,
with “Lines” chosen, shows higher conformity (PCC = 57.14%)
between the ordinal relations of the sleep and mood judgments.
OOM Software Manual
The method used to tally the “Possible Correct” will be
described below under Ordinal Classifications.
Figure 11.11 Person3: Numbers (Ordinal) & Lines Options Selected
129
across the seven days are expected to conform to the
differences in the sleep observations. In the parlance of
traditional statistics, the two are expected to covary positively
across the seven days.
When the cause and effect observations are expected to
be inversely patterned across the seven days, then either the
Cause or Effect Reflect Units/Values option should be selected.
With regard to the PCC indices, c-values, and other results
from the analysis, the choice of reflecting the cause or effect is
arbitrary. In other words, the results for Cause reflected will be
identical to those for Effect reflected. The user should thus
reflect the observations that make the interpretation of
individual patterns most clear.
Ordinal Classifications
This option only applies when Numbers (Ordinal) has
been selected for the Analyze option and it determines how the
Correctly Classified observations are tallied. Consider the
following sleep and mood observations as they have been
entered into the Data Edit window (since numbers are being
analyzed, deep structures are not considered) for days 1
through 4:
Reflect Units/Values
The Reflect Units/Values option is set to Neither by
default. For the current example, this setting indicates that the 0
to 10 units for the mood (effect) observations are expected to
conform to the 0 to 10 units for the sleep observations (unit 0
conforming to 0, 1 to 1, etc.). If the Analyze option is set to
Numbers (Ordinal), then the differences in mood observations
Sleep Person3
Mood Person3
D1
2
4
D2
4
5
D3
5
6
D4
6
5
The pattern in Figure 11.12 shows high ordinal conformity
between the effect and cause observations.
OOM Software Manual
Figure 11.12 Ordinal Pattern
considered. For these four days, the differences are computed
as D1 – D2, D1 – D2, D1 – D3, D2 – D3, D2 – D4, and D3 –
D4:
Sleep Person3
Mood Person3
When Ordinal Classifications is set to Adjacent Only,
then the differences between adjacent cause or effect
observations will be considered. For these four days, the
adjacent differences are computed as D1 – D2, D2 – D3, D3 –
D4:
Sleep Person3
Mood Person3
D1-D2
-2
-1
130
D2-D3
-1
-1
D3-D4
-1
1
In terms of the signs of the differences, the observations
conform almost perfectly to one another, and the PCC index
for this person is equal to 66.67 (2 / 3 * 100). With the
Adjacent Only option, then, the number of possible correct
classifications will equal n – 1, where n equals the number of
effect observations. As will be described below, the
magnitudes of the differences can also be considered by using
the Classification Imprecision option.
When Ordinal Classifications is set to Full, then the
differences between all cause or effect observations will be
D1-D2
-2
-1
D1-D3
-3
-2
D1-D4
-4
-1
D2-D3
-1
-1
D2-D4
-2
0
D3-D4
-1
1
Here, four of the six comparisons show conformity in terms of
their signs. The D2 – D4 and D3-D4 differences for sleep were
negative, while the differences for mood were zero or positive.
These differences did not match, and the PCC with the Full
option selected is again, by coincidence, 66.67 (4 / 6 * 100 =
66.67) for this person.
The Adjacent Only option is less restrictive than the
Full option as it only considers a subset of all possible ordinal
comparisons across the cause and effect orderings. If the user
wants to compare every possible pair of cause orderings with
every possible pair of effect orderings, then the Full option
must be chosen. The ideal scenario is to have this choice driven
by an integrated model, but in the current example it is difficult
to imagine why the difference in sleep judgments between days
2 and 4 (D2 – D4), for instance, would be expected to match
the difference in mood judgment on those days. The Adjacent
Only option may be more interpretable for this example.
Missing Values
This option controls how the missing values are treated
when computing the different PCC indices. When this option is
set to Omit from Totals, then the missing values are ignored, as
in the annotated output from Figure 11.5:
OOM Software Manual
Classification Results :
Effect Observations Classified to Cause Observations
Classifiable Observations : 34
Correct Classifications : 12
Percent Correct Classifications : 35.29
Classifiable Complete Cases : 4
Correctly Classified Complete Cases : 1
Percent Correct Classified Cases : 25.00
Recall Person2 is missing an observation for mood judgment
on the fourth day. If the Missing Values option is set to Include
in Totals, then the same output appears as:
Classification Results :
Effect Observations Classified to Cause Observations
Classifiable Observations : 35
Correct Classifications : 12
Percent Correct Classifications : 34.29
Classifiable Complete Cases : 5
Correctly Classified Complete Cases : 1
Percent Correct Classified Cases : 20.00
Note how the Correct Classifications and Correctly Classified
Complete Cases are 12 and 1, respectively, in the two outputs.
The Classifiable Observations, however, changes from 34 to
35 since the missing values are now counted as classifiable (i.e.,
they are not ignored). The Classifiable Complete Cases
similarly goes from 4 to 5, the latter being the number of cases.
This option similarly impacts the PCC values computed for the
individual cases.
131
Classification Imprecision
This option allows the user to define a range of deep
structure units or range of values when the effect observations
are being classified according to the cause observations. When
Deep Structures has been selected under the Analyze option,
then the value entered for the Classification Imprecision
pertains to the deep structures. Consider the following
observations with equally defined units labeled from 0 to 10:
Sleep Person3
Mood Person3
D1
2
4
D2
4
5
D3
5
6
D4
6
5
None of the effect deep structure observations are conformed
to the cause deep structures (i.e., the unit values are not
identical). If the Classification Imprecision value is set to 1,
then the deep structures will be counted as “classified
correctly” for D2, D3, and D4. The absolute unit difference for
D1 (2 – 4 = -2) is greater than the Classification Imprecision
value of 1 and therefore classified incorrectly. In this way, the
user can permit causes and effects to differ by a determined
number of units and still be considered as conformed to one
another.
When Numbers (Ordinal) has been selected under the
Analyze option, then the Classification Imprecision works on
differences between ordering values. Consider the following
generic numbers across four orderings:
Cause PersonX
Effect PersonX
D1
1
1
D2
2
2
D3
3
3
D4
4
2
OOM Software Manual
If Adjacent Only is selected as the Ordinal Classifications
option, then the relevant differences are:
Cause PersonX
Effect PersonX
D1-D2
-1
-1
D2-D3
-1
-1
D3-D4
-1
1
With Classification Imprecision set to zero, the differences for
D1-D2 and D2-D3 are conforming. The differences for D3-D4
are not conforming. Setting Classification Imprecision to 1 will
impact how the differences are computed for both the cause
and effect; specifically, any difference less than or equal to 1,
will be treated as zero. Consequently, the differences would be:
PersonX
PersonX
D1-D2
0
0
D2-D3
0
0
D3-D4
0
0
Cause PersonX
Effect PersonX
D1
3
1
D2
1
3
D3
2
1
D4
5
8
With Adjacent Only selected as the Ordinal Classifications
option, the relevant differences are:
Cause PersonX
Effect PersonX
D1-D2
2
-2
D2-D3
-1
2
D3-D4
-3
-7
With regard to ordinal relations, then, only the D3-D4
difference is conforming; from D3 to D4, both the cause and
the effect values decreased. The PCC index for this person is
therefore 33.33 (1/3). Setting the Classification Imprecision
value to 1 does not change this result since the computed
differences equal:
Cause PersonX
Effect PersonX
D1-D2
2
-2
D2-D3
0
2
D3-D4
-3
-7
Note how the difference for D2-D3 is now treated as zero.
Finally, setting the Classification Imprecision value to 2
yields the following differences:
Cause PersonX
Effect PersonX
All three differences (orders) are now conforming for a PCC
value of 100 for this person.
As another example, consider the following generic
numbers:
132
D1-D2
0
0
D2-D3
0
0
D3-D4
-3
-7
Now the PCC index equals 100 for this person. D1-D2 and D2D3 match in an ordinal fashion, with no differences greater
than 2, and D3-D4 are negative for both the cause and effect.
The idea behind the Classification Imprecision option
when Numbers (Ordinal) has been selected is therefore to give
the user the ability to only treat larger numerical differences as
important across the cause and effect orderings. Small
differences can be counted as equal. Finally, it should be noted
that the Classification Imprecision value does not get carried
over into the Examine Patterns window. In other words, the
ordinal patterns shown in Figures 13.10 and 13.11 are not
impacted by the entered value. All of the output generated from
the analysis, however, will be impacted by the imprecision
value.
OOM Software Manual
Effect Lag
This option permits the user to align the cause orderings
to the effect orderings in different ways that reflect differences
in time, which is why the analysis is referred to as Efficient
Cause Analysis. For the sleep and mood observations, for
example, it might be expected that mood on day one impacts
the sleep judgment made on day two (after the first night of
sleep). The idea here is that the previous day’s mood might
impact that night’s quality of sleep. Rather than aligning Md1
with Sp1, then, Md1 is aligned with Sp2. Furthermore, Md2
would be aligned with Sp3, Md3 with SPp4, and so on. In this
instance the effect is considered lagged by one day. The left
pattern in Figure 11.13 shows the observations for Person3
with the cause and effect orderings aligned. As can be seen,
only none of the six observations are conforming. The right
pattern in Figure 11.13 shows the same observations, but with
the effect orderings lagged one day (take note of the column
labels at the top and bottom of the 2-dimensional matrix). With
this lag, the effect observations conform to the cause
observations perfectly (PCC = 100).
The Effect Lag similarly impacts the relationships
between the cause and effect orderings when values are
analyzed (i.e., when Numbers (Ordinal) is selected for
Analyze). Finally, as with most analyses in OOM, the ideal
situation is to use an integrated model to determine the amount
of time to lag the effect. The maximum value for the Effect
Lag will equal the number of effect orderings minus one (7 – 1
= 6 for the mood observations).
133
Figure 11.13 Person3 Observations Aligned and Lagged by One Day
Randomization Test
Randomization Test
Selecting this option will result in a randomization test
being conducted on the observations. The user sets the number
of randomized trials to be conducted in the Number of Trials
edit box. The default value is 1000. The Randomize drop box
permits the user to choose between four methods of
randomization: within Effect Orderings, within Cause & Effect
Orderings, All Observations, or Effect Deep Structures.
The within Effect Orderings option randomly shuffles
the order of the effect orderings for each person (case). For
OOM Software Manual
example, consider the sleep and mood observations for the first
two people:
P1
P2
D1
7
0
D2
8
1
P1
P2
D1
7
2
D2
8
0
Sleep Judgment
D3
D4
5
6
2
2
Mood Judgment
D3
D4
6
7
1
.
D5
9
4
D6
5
3
D7
6
3
D5
9
2
D6
5
4
D7
3
3
If the mood observations are considered as the effect, they will
be randomly shuffled, separately, for each person. One
randomized version of the observations may appear as:
P1
P2
D1
3
0
D2
5
1
Mood Judgment
D3
D4
9
7
.
4
D5
8
3
D6
7
2
D7
6
2
The PCC values described in the annotated output in Figure
11.5 for such case-wise randomly shuffled data are then
computed and used to create distributions. The observed PCC
values (for all pairs and for all complete cases) are then located
within these distributions, and the c-values determined.
Selecting the within Cause & Effect Orderings option
will randomize within both the cause and effect observations.
For P1 above, for example, a randomized version of the
observations may appear as:
134
Selecting the All Observations option will randomize
both within the effect and within the cause, but also between
them as well. For P1 above, for example, a randomized version
of the observations may appear as:
P1
D1
5
D2
6
P1
D1
8
D2
8
Sleep Judgment
D3
D4
6
9
Mood Judgment
D3
D4
3
5
D5
6
D6
9
D7
5
D5
7
D6
7
D7
7
Note how the 9 value for the Mood Judgment is now randomly
moved to a Sleep Judgment. With this randomization routine,
then, the cause and effect observations can be interchanged,
unlike the previous two methods.
Finally, when the Deep Structures option is chosen for
Randomize, then the deep structures are randomly determined
for the cause and the effect observations. Consider the deep
structure of the mood observation for the first person above (P1)
with a value of 4:
0
0
0
0
1
0
0
0
0
0
0
A randomized version of this observation is based on a random
determination for the column location of the 1; for example,
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0.
or
P1
D1
9
D2
8
P1
D1
5
D2
7
Sleep Judgment
D3
D4
7
5
Mood Judgment
D3
D4
3
6
D5
6
D6
6
D7
5
D5
9
D6
8
D7
7
Each person’s row of each cause and each effect deep structure
matrix is randomly determined. By randomly determining the
deep structures, the user is essentially asking, “how often can I
OOM Software Manual
obtain a PCC index as high or higher than the observed PCC
index, if the observations are randomly created within the
context of the given deep structures (e.g., 11-unit structures)?”
This question is distinct from the question asked when
choosing the randomize within the cause or effect observations:
“If the order of the observations for the orderings are randomly
shuffled for each person, how frequently can I obtain a PCC
index as high or higher than the observed PCC index?”
Because OOM places a premium on the observations obtained
through careful work, and because the cause and effect
observations are not independent within themselves, the two
within Orderings options may generally be preferred as the
randomization methods.
Save Randomized Results
When this option is selected and the analysis conducted,
a new data set will be created. The number of observations in
the data set will equal the number of trials set by the user
(provided the iterative process is not interrupted by selecting
the [Stop] button). The data set will be comprised of six
orderings: (1) classifiable cases, (2) classifiable pairs of
observations, (3) correct classifications, (4) percent correct
classifications, (5) correctly classified complete cases, and (6)
percent correct classified cases. All of the values for
Classifiable Cases and for Classifiable Pairs of Observations
will be equal, and the values will be determined by the number
of observations and selected analysis options (e.g., whether or
not missing values are included in the totals). The annotated
output in Figure 11.5 above explains how the numbers of
Classifiable Cases and for Classifiable Pairs of Observations
are computed. Finally, the cases in the data set will be labeled,
135
rand_1, rand_2, rand_3, etc. as a reminder of their origin from
the randomization test. As with any data set in OOM, these
randomization results can be examined, edited, sorted, saved,
concatenated, etc.
Output
The ordering summaries, individual results, and
individual classification results can all be printed to the Text
Output window by selecting these options. In addition, the
individual classification results can be appended to the data set
for which they were generated or saved to a new data
spreadsheet by selecting the Save Individual Results option.
The annotated output in Figure 11.5 provides descriptions of
the output generated by these options.
OOM Software Manual
12
Logical Ordered Observations
Because it does not rely on the assumption that qualities
are structured as continuous quantities, a particular strength of
OOM is its capability to handle logical expressions. Binary
Procrustes rotation can be used to examine the conformity
between two sets of ordered observations, and the Create
Logical Ordered Observations option permits the user to create
complex logical expressions from units of observation.
Combining binary Procrustes rotation in the Build / Test Model
option with logical expressions creates a process referred to as
Logical Hypothesis Testing in the realm of observation oriented
modeling. Consider the following observations in which
persons are classified as introvert/extravert (I/E),
sensing/intuitive (S/I), thinking/feeling (T/F) and nonsuccessful therapist/successful (NS/S) therapist:
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
I/E
Ext
Int
Ext
Int
Ext
Int
Ext
Int
Int
Ext
Ext
Ext
S/I
S
I
S
I
I
S
S
I
S
S
S
S
T/F
F
T
T
F
T
T
F
F
T
F
F
T
NS/S
NS
S
NS
S
S
NS
S
S
NS
S
S
NS
File: TherapistLogic.oom
Ideally, an integrated model would drive any analyses
conducted on these observations. Without such a model,
136
however, suppose the goal is to maximally conform the
successful/non-successful therapists to the personality
observations. One route would be to combine the different
personality type observations into logical expressions. Such
expressions can be constructed using the Create Logical
Ordered Observations window (see Figure 12.1) found under
the Compute Main Menu option of OOM when the Data Edit
window is visible.
Figure 12.1
Create Logical
Ordered
Observations
A logical expression is built in Figure 12.1 by selecting the unit
of observation considered a “success” and then including it in
the Expressions edit box by selecting the [Include ] button.
Logical operators can be included in the expression by
selecting one of the Operators buttons (e.g., [OR], [AND], etc.).
The constructed expression can be named by editing the Label
OOM Software Manual
box at the bottom of the window. Figure 12.2 shows the
window with the logical expression, “Introvert AND Sensing”
defined and labeled. By selecting [OK] a new binary ordering
of observations will be created. The units will be represented
with 0 (false) and 1 (true) as shown here:
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
I/E
Ext
Int
Ext
Int
Ext
Int
Ext
Int
Int
Ext
Ext
Ext
S/I
S
I
S
I
I
S
S
I
S
S
S
S
T/F
F
T
T
F
T
T
F
F
T
F
F
T
NS/S
NS
S
NS
S
S
NS
S
S
NS
S
S
NS
Figure 12.2
Create Logical
Ordered
Observations
Sensing/
Introvert
False
False
False
False
False
True
False
False
True
False
False
False
File: TherapistLogic_SI.oom
Only case_6 and case_9 were introverted sensing types; that is,
observed as Introvert and Sensing. This new ordering can now
be used in different models. For example, the
Unsuccessful/Successful Therapist observations can be rotated
to conformity with the new ordering. Using the Build / Test
Model analysis option and the expression,
Sensing/Introvert NS/S,
the multigram in Figure 12.3 results. As can be seen, while the
NS/S observations conformed reasonably well to the
Sensing/Introvert observations, more observations for the NS
units were misclassified than classified correctly. By
comparison, none of the successful therapists were introverted
sensing types.
Figure 12.3
Multigram for
Logical
Expression
137
OOM Software Manual
Additional logical statements can be created and
examined. The statement that yields the highest overall PCC
value when modeled with the Sensing/Introvert observations is:
“Intuitive OR Feeling.” This logical statement appears in
Figure 12.4. The ordered observations, Intuit_OR_Feel, are
consequently generated and added to the data set as follows:
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
I/E
Ext
Int
Ext
Int
Ext
Int
Ext
Int
Int
Ext
Ext
Ext
S/I
S
I
S
I
I
S
S
I
S
S
S
S
T/F
F
T
T
F
T
T
F
F
T
F
F
T
NS/S
NS
S
NS
S
S
NS
S
S
NS
S
S
NS
Figure 12.4
OR Logical
Statement
Intuit_
OR_Feel
True
True
False
True
True
False
True
True
False
True
True
False
File: TherapistLogic_IF.oom
It can be seen that 8 of the 12 therapists were observed as
either intuition or feeling types. Conforming the
Unsuccessful/Successful Therapist observations to this logical
expression,
Intuit_OR_Feel NS/S,
yielded near perfect accuracy, as can be seen in the multigram
in Figure 12.5 results. As shown all but one observation was
classified correctly. The successful therapists were all intuitive
or feeling types, whereas most of the non-successful therapists
were neither intuitive nor feeling types. Only 1 non-successful
therapist was an intuitive or feeling type.
Figure 12.5
Intuit_OR_Feel
Multigram
Examination of the individual classification results (and
observations above) reveals case_1 to be a feeling type who
was also an unsuccessful therapist.
138
OOM Software Manual
The logical statements are most easily constructed
using the selection features and buttons in the Create Logical
Ordered Observations window shown in Figure 12.1. The
expressions can also be manually entered into the Expression
edit box. They can also be copied and pasted into the edit box
or copied from the edit box into other programs. The
expression can be copied by first highlighting (selecting) the
entire text and then pressing “Ctrl c” (the Ctrl and letter c keys)
on the keyboard. Text can be pasted by pressing “Ctrl v” on the
keyboard. These are standard keyboard functions for copying
and pasting text across programs within the Windows operating
system. Manually entering expressions requires clear and
accurate knowledge of the names of the ordered observations
and the labels for their respective units. Consider the
expression from Figure 12.4:
{S/I} I
[OR]
{T/F} F
Each name for the ordered observations is listed in brackets
({ }), followed by the label for the unit that is to be considered
a “success” in the statement. The logical operators are included
in square brackets ([ ]). Each ordered observation and unit
must be included on a separate line, as must all of the logical
operators, except NOT (~, see below). The above statement
cannot therefore be entered as:
139
Following these simple rules, however, the logical antithesis of
the above statement can be entered as:
{S/I} S
[AND]
{T/F} T
This statement indicates a person who is both sensing and
thinking. The NOT operator (~) shown in Figure 12.4 can also
be used to generate a logically equivalent statement:
[~]{S/I} I
[AND]
[~]{T/F} F
Note how the NOT operator is included on the line with the
ordered observation, preceding its name. This statement
indicates a person who is not an intuitive type and who is not a
feeling type; in other words, a person who is a sensing and
thinking type.
More complex logical expressions can easily be
generated. For instance,
{I/E} Int
[AND]
{S/I} I
[OR]
{T/F} F
{S/I} I [OR] {T/F} F
It is extremely important to understand that such statements are
processed in a purely sequential fashion, and there is no way to
OOM Software Manual
currently override this default method in the option. Working
sequentially means that each line of the expression is treated in
order. The first three lines in this example comprise a simple
intersection statement:
{I/E} Int
[AND]
{S/I} I
Processed, this expression generates a new ordering of
observations who are introverted and intuitive types. Let us
refer to these ordered observations as Int_I. The next lines of
the complex statement are then processed and implicitly based
on these new ordered observations:
{Int_I} True
[OR]
{T/F} F
The final set of ordered observations generated are thus people
who are introverted/intuitive types or are feeling types. Again,
all logical expressions in OOM are handled in this sequential
fashion, and the inclusion of parentheses around sub-statements
cannot override this approach. If in doubt about a particular
complex expression, the user is advised to build the expression
in a step-by-step fashion (as just demonstrated), examining the
logical orderings as they are created at each step.
140
Operators
OOM currently offers a number of standard logical
operators that can be used to build countless expressions.
~
OR
AND
XOR
IFF
IMP
Negation
Disjunction
Conjunction
Excluded Middle
Biconditional
Implication
The S/I (S for sensing and I for intuitive types) and T/F (T for
thinking and F for feeling) ordered observations above will be
used to explain each of these operators via truth tables.
The ~, or NOT, operator is logical negation; hence, ~Int
is equivalent to observing an Ext (extravert).
The OR operator represents logical disjunction as seen
in the following truth table:
I OR T
S/I
S
S
I
I
T/F
T
F
T
F
Result
True
False
True
True
For a true result, only one of the two types must be observed.
OOM Software Manual
The AND operator is conjunction, which means that
both of the types must be observed for a true result; specifically,
141
Lastly, IMP is material implication, and is often written
as “if p then q.” It is logically equivalent to “~p OR q”,
yielding the following truth table for “I IMP T”:
I AND T
S/I
S
S
I
I
T/F
T
F
T
F
Result
False
False
True
False
The XOR operator is referred to as logical exclusion
and returns a true result if either type is observed, but not both,
as shown in the truth table:
I XOR T
S/I
S
S
I
I
T/F
T
F
T
F
Result
True
False
False
True
The IFF operator is a biconditional Boolean operator
which yields a true result if either both types are observed or
neither type is observed; in other words, the person is either an
intuitive/thinker or a sensing/feeler for “I IFF T”:
I IFF T
S/I
S
S
I
I
T/F
T
F
T
F
Result
False
True
True
False
I IMP T
S/I
S
S
I
I
T/F
T
F
T
F
Result
True
True
True
False
Material implication is admittedly difficult to think about in
terms of normal language. One strategy that might help in
OOM is the use of common equivalent notations “p only if q”
or “q if p.” For this example, the latter perhaps makes the most
sense. A person is a thinking type (q) if the person is also an
intuitive type (p); but if the person is a sensing type (~q), the
person could be either a thinking or feeling type (p or ~p).
OOM Software Manual
13
Combine Units of Observation
The Combine Units of Observation option under the
Compute option of the Main Menu (when the Data Edit
window is visible) permits the user to combine units of
observation both within and across orderings. In order to
demonstrate how this option functions, we’ll again consider the
following observations in which persons are classified as
introvert/extravert (I/E), sensing/intuitive, and (S/I),
thinking/feeling (T/F); but here the therapists are classified as
Cognitive-Behavioral (CB), Constructivist (C), or Jungian (J):
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
I/E
Ext
Int
Ext
Int
Ext
Int
Ext
Int
Int
Ext
Ext
Ext
S/I
S
I
S
I
I
S
S
I
S
S
S
S
T/F
F
T
T
F
T
T
F
F
T
F
F
T
142
and C units would simply be combined. They can also be
combined, however, using Combine Units of Observation.
This will be an example of combining observations within a
particular ordering, in this case the type of therapy. The
Combine Ordered Observations window is shown in Figure
13.1, without any changes made.
Figure 13.1
Combine
Observations
Original
Window
Therapy
CB
J
CB
J
C
C
CB
J
C
CB
C
CB
File: CombineExample.oom
Suppose an integrated model calls for an analysis that
combines the CB and C units of observation. How can these
observations be combined into one unit? This could be
accomplished by using the Define Ordered Observations
option found on the toolbar of the Data Edit window or under
the Edit option of the Main Menu (when the Data Edit window
is visible). In the Define Ordered Observations window the CB
It can be seen that the units to be included in the new ordering
can be selected and included in the New Ordered Observations
edit box on the right side of the window. The new ordering will
result in a new column of observations in the Data Edit
window, and these new observations can be labeled in the edit
box at the bottom of the window. The default label is
“Combined Observations.” In the middle of the window in
Figure 13.1, the Unit Labels can be automatically generated or
OOM Software Manual
the existing unit labels can be used for the new ordered
observations. These two options will be shown below.
Figure 13.2 shows how the window would appear with the
necessary changes to combine the CB and C units of the
therapy orderings.
143
[Include] button was then pressed. The label was finally
changed to “Therapy (2 Combined).” Selecting the [OK]
button yields a new set of ordered observations with 2 units, J
for Jungian therapy and CB/C for Cognitive Behavioral or
Constructivist therapy. The old and new observations follow:
Figure 13.2 Combine Observations with Changes
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
I/E
Ext
Int
Ext
Int
Ext
Int
Ext
Int
Int
Ext
Ext
Ext
S/I
S
I
S
I
I
S
S
I
S
S
S
S
T/F
F
T
T
F
T
T
F
F
T
F
F
T
Therapy
CB
J
CB
J
C
C
CB
J
C
CB
C
CB
Therapy
(2 Combined)
CB/C
J
CB/C
J
CB/C
CB/C
CB/C
J
CB/C
CB/C
CB/C
CB/C
File: CombineExample_2C.oom
As an example of combining units across ordered
observations, let’s consider creating a new ordering of
observations with 2 units: Introverted Intuitive types (IIT) and
Extraverts (E). Figure 13.3 shows how this would be done with
the following lines in the New Ordered Observations edit
window:
The New Ordered Observations were defined in the window by
first selecting the J therapy, selecting the Use Existing Labels
checkbox, and pressing the [Include] button. The CB and C
therapies, as shown in Figure 13.2, were then selected (J was
deselected) and the Unit Label was changed to “CB/C”. The
{I/E}{ Ext} --> Ext
{I/E}{ Int} --> IIT
{S/I}{ I} --> IIT
The first line simply assigns the extraverts from the I/E
ordering to extraverts in the new ordering. The next two lines
layers the intuitive types (I) from the S/I ordering over the
introverts (Int) from the I/E ordering. The observations are
OOM Software Manual
layered because the process of assigning the new units of
observation works sequentially through the three lines of text.
First, all of the I/E extraverts are assigned to a unit labeled Ext.
Second, the I/E introverts are assigned to a unit labeled IIT. At
this stage, the new ordered observations are identical to the I/E
ordered observations. Lastly, the intuitive types from the S/I
ordering are assigned to the IIT unit of observation. This
assignment overrides, or layers over, the previous two
statements.
Figure 13.3 Combining Observations across Orderings
144
The result is in this case works something like a logical
statement in which the observations are assigned to two groups,
extraverts or intuitive/introverts as can be seen with the new
ordering:
case_1
case_2
case_3
case_4
case_5
case_6
case_7
case_8
case_9
case_10
case_11
case_12
I/E
Ext
Int
Ext
Int
Ext
Int
Ext
Int
Int
Ext
Ext
Ext
S/I
S
I
S
I
I
S
S
I
S
S
S
S
T/F
F
T
T
F
T
T
F
F
T
F
F
T
Therapy
CB
C
CB
C
C
CB
C
C
CB
C
C
CB
IIT/Ext
Ext
IIT
Ext
IIT
IIT
IIT
Ext
IIT
IIT
Ext
Ext
Ext
File: CombineExample_Across.oom
Note how the extraverts are placed within the Ext unit of the
new orderings unless the person is also an intuitive type (e.g.,
case_5). This is the most important fact to remember, the
observations are combined in a layered fashion, meaning that
the statements in the New Ordered Observations edit box are
treated sequentially, with the later statements overriding the
earlier statements. In some cases, it may not be possible to
obtain the desired orderings. In such instances, the Create
Logical Ordered Observations option may prove more fruitful
for obtaining the desired result.
OOM Software Manual
14
145
Create Combination Orderings
Ordering/Cases Combinations
This option is available under Compute on the Main
Menu when the Data Edit window is visible in OOM. In many
non-parametric statistical analysis procedures, combinations of
observations are created and evaluated. A sign test, for instance,
involves creating all possible pairs of dependent real values
and determining the number of positive or negative differences
between observations. To the extent this may be useful in
testing questions derived from integrated models in
Observation Oriented Modeling, this option offers the user a
number of features.
Consider the ordered observations from Chapter 9
above:
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ExpRat
ConRat
ConRat
ConRat
ConRat
ConRat
ConRat
ConRat
1
2
3
4
5
6
7
8
1
2
3
4
5
6
7
B1
2
1
2
0
0
2
1
1
0
0
0
2
1
1
2
B2
0
1
2
1
0
1
0
0
1
0
2
0
1
0
1
T1
10
12
9
14
2
19
13
12
0
2
1
2
1
0
0
T2
7
11
6
5
0
8
5
7
0
.
2
1
2
.
5
T3
2
.
2
1
1
2
0
1
1
3
2
1
0
.
1
Group
E
E
E
E
E
E
E
E
C
C
C
C
C
C
C
File: OrdinalBarPressExample.oom
Imagine if the goal of an analysis required that every rat’s T2
observation was paired with every other rat’s T3 observation.
The user selects Compute Create Combination Orderings
Ordering/Case Combinations from the Main Menu when
the Date Edit window is visible. Figure 14.1 shows the options
window that opens. It can be seen that Orderings has been
chosen and that orderings T2 and T3 have been selected.
Figure 14.1 Ordering/Case Combinations window
OOM Software Manual
It can also be seen that 225 new cases will be created by
pairing each rat’s T2 observation with every other rat’s T3
observation. In other words, with 15 rats there are 15 * 15 =
225 combinations. These pairs of observations will be
generated and sent to a new data set. Recall, for instance, the
first three rats:
ExpRat 1
ExpRat 2
ExpRat 3
B1
2
1
2
B2
0
1
2
T1
10
12
9
T2
7
11
6
T3
2
.
2
Group
E
E
E
The new data set will be comprised of two columns labeled T2
and T3 with the following values:
Case1
Case2
Case3
Case4
Case5
Case6
Case7
Case8
Case9
T2
7
7
7
11
11
11
6
6
6
T3
2
.
2
2
.
2
2
.
2
Note how every rat’s T2 observation has been paired with its
own and every other rat’s T3 observation. These pairings can
then be subjected to different analyses; for instance, an Ordinal
Analysis can be conducted which would be similar to
conducting a sign test on these two orderings. If Delete Cases
with Missing Observations option is chosen, then any pairings
with missing observations will not be included in the new data
set.
If T1, T2, and T3 are selected in Figure 14.1, then all
possible combinations of these orderings will be generated and
146
sent to the new data set. Again, considering the first three rats,
the first seven cases in the new data set would be as follows:
Case1
Case2
Case3
Case4
Case5
Case6
Case7
T1
10
10
10
10
10
10
10
T2
7
7
7
11
11
11
6
T3
2
.
2
2
.
2
2
With 15 rats and three orderings, a total of 3375 cases (15 * 15
* 15 = 3375) will be generated. Obviously, with a large number
of cases and three or more orderings, the number of
combinations will quickly grow extremely large.
The same types of combinations can be generated for
the rows of observations as well. Figure 14.2 shows the same
window as Figure 14.1 but now with Cases selected as well as
the first two rats. Consider the first two rats:
ExpRat 1
ExpRat 2
B1
2
1
B2
0
1
T1
10
12
T2
7
11
T3
2
.
Group
E
E
Now the combinations are generated for each pair of orderings,
as follows:
Case1
Case2
Case3
…
Case35
Case36
ord_1
2
2
2
ord_2
1
1
12
E
E
.
E
OOM Software Manual
With six orderings, 36 new cases are generated (6 * 6 = 36),
and the columns are generically labeled as “ord_1”, “ord_2”,
etc. Again, these new paired observations can be used in
different analyses.
Figure 14.2 Ordering/Case Combinations window
147
Group Combinations
The other option for creating combinations of
observations for further analysis is selected as Compute
Create Combination Orderings Group Combinations from
the Main Menu when the Date Edit window is visible. Figure
14.3 shows the options window.
Figure 14.3 Group Combinations window
OOM Software Manual
As can be seen the Group ordering has been selected as the
Ordering for Grouping and B1 has been selected as the
Ordering for Combinations. Only one ordering may be
selected in each of these two boxes. In this example, there are
two units in the Group ordering, experimental and control rats.
With eight experimental rats and seven control rats, a new data
set will be created with 56 new cases (8 * 7 = 56). Consider the
fisrt two experimental and first two control rats:
ExpRat
ExpRat
ConRat
ConRat
1
2
1
2
B1
2
1
0
0
B2
0
1
1
0
T1
10
12
0
2
T2
7
11
0
.
T3
2
.
1
3
Group
E
E
C
C
B1 has been selected as the Ordering for Combinations, thus
the other ordering are ignored and each experimental rat’s
observation on B1 is paired with every control rat’s
observation on B1, as follows:
case_1
case_2
case_3
case_4
Expe
2
2
1
1
Cont
0
0
0
0
The column labels have been abbreviated here, but are
Experimental/B1 and Control/B1 for the current example.
Again, each experimental rat’s observation is paired with each
control rat’s observation for the B1 ordering. These pairings
can then be submitted to further analysis, for example using an
Ordinal Analysis, which would be akin to conducting a MannWhitney U test on the observations. When the selected
Ordering for Grouping possesses more than two units, then
148
more columns of orderings will be generated. For example,
with three groups of rats, three columns would be generated
showing every combination of observations from the selected
Ordering for Combinations.