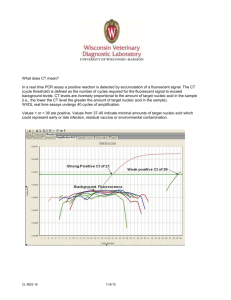
computational1
advertisement

Biology 475 - Molecular Biology Lab Computational Fingerprinting Analysis Objectives To learn about how data is stored, annotated, and accessed on NCBI/GenBank To learn how to load and analyze DNA information on Biology Workbench To "solve" your mystery DNA map and check your work PART ONE – NCBI GENBANK Which you will also use next week when you BLAST your original sequences About the National Center for Biotechnology Information (NCBI) Federally funded on-line database and analytical tools, supported by NIH/NLM since 1988 MANY databases: Nucleotide (GenBank), Protein, Genome, Structure… Each sequence on NCBI is annotated; some information includes: LOCUS = name, length, molecule, date ACCESSION = unique assigned identifier (assigned by NCBI at the time of acceptance) VERSION = accession version plus GI:number (submission number; e.g. 1 = first submitted) SOURCE = organism of origin, common ORGANISM = whole organism, classification AUTHORS = submitting scientists TITLE = publication, manuscript, and/or project title, links to abstract (minimally), possibly article FEATURES = biological markers including… Source = origins of sequence (e.g. soil sample, hot spring sample…) Promoter(s) = base pair location of promoters Misc. Feature = e.g. transcription start site, structural motifs Procedures Go to NCBI and note the “menu bar” items at the top; set the search bar to nucleotide (i.e. GenBank). Enter M77789, the accession number for your mystery DNA. One “hit” will come up; click on the accession number - this will take you to the annotated flatfile. Read the annotations and record all relevant annotations in your analysis for the mystery DNA lab. Edit/Copy the entire raw sequence (ORIGIN 1-end) – this will be needed for the next step. PART TWO – ABOUT AND USING BW About the Biology Workbench (BW) Supported by San Diego Supercomputer Center (SDSC), with external federal funding (e.g. NSF) Free since 1996,150,000 sessions available per month (each person creates/uses own account) Provide programs and, in many cases, contain interfaces to link to databases (NCBI) We will only be using TWO of tool bars today: • • • • • Sessions: begin and choose projects, will need today Protein: protein analysis, not in this lab Nucleic: software for uploading data, will need today Alignment: software for aligning data, next lab Structure: will not use any Within each - MANY pieces of software that do many things. We will only use a few of these options. If you want to learn more, download and read the available on-line BW turotial. Some Useful BW Nucleic Tools Add New Nucleic Sequence – allows cutting/pasting of data – will need today Ndjinn/engine: link/search other databases ClustalW: multiple alignment TACG: map restriction sites for sequences - will need today SIXFFRAME: interpret all codon frames NASTATS: determine things like %GC - will need today PRIMER: assist with primer design Procedures – Session Tools Open the BW site, http://workbench.sdsc.edu/, and set up an account. Using your account, select and open SESSION TOOLS From the SESSION TOOLS box, click on “”Start New Session” and hit the RUN button. A new window should open, asking for a description. Type “Mapping” and hit START NEW SESSION. A new window should open showing Mapping has been created and is selected Procedures – Nucleic Tools/Ndjnn Now select and open NUCLEIC TOOLS. A new window with a new box of different tools will appear – these are the MANY software options available on BW for just analyzing nucleic acids. Select Add New Nucleic Sequence - Multiple Database Search and hit RUN button (Ndjinn = Engine, as in search engine). In the Label box, type Mystery. Paste your copied sequence (from NCBI) into the Sequence box and then click the SAVE button. You will be taken back to the main NUCLEIC TOOLS Session page, and you should see that your Mapping Session now has the sequence you just imported. For each of the following programs, make sure your Mapping session is open and your Mystery DNA is selected before proceeding. Procedures – Nucleic Tools/ NASTATS With your Mystery sequence selected, scroll down NUCLEIC TOOLS until you find NASTATS and click on the RUN button. A new data output window will come up with information about your mystery sequence. Describe these data in your lab analysis section. What does this information say about the predictive math should consider performing/practicing in terms of how many times each of the enzymes SHOULD cut your mystery DNA? When done, click the RETURN button and proceed to the final problem. Procedures – Nucleic Tools/ TACG With your Mystery sequence selected, scroll down NUCLEIC TOOLS until you find TACG (Analyze for a Restriction Site) and click on the RUN button. DO NOT BE TEMPTED TO HIT SUBMIT… there are some things below to complete: - First, you should know what to do with the “substrate parameters section” Skip down to the “User Specified Enzymes” area (with 15 boxes) Type in the enzymes you used (use proper format – HaeIII, last 3 = roman numerals) Leave everything else default and scroll to bottom – hitting SUBMIT Review new window output, which should allow you to grade your mapping problem Record the ACTUAL numbers of times each enzyme cut, and the predicted sizes in your analysis. Reserve describing problems (i.e. if things didn’t match) for your Discussion section.