Physicians` Health Study – Regular Aspirin Intake v
advertisement

1
Logistic Regression, with an Example from Educational Testing
Our model has a single dichotomous response variable, which we will code as either 1 =
{Success} or 0 = {Failure}. It has one or more explanatory variables, X1, X2, …, Xk. Some of
these variables are continuous, and some may be categorical. Since the response variable has a
Bernoulli distribution, the mean is EY x , the probability of success, considered to be a
function of the explanatory variables. Since 0 1 , the identity link function for the model
cannot be used if the model has continuous explanatory variables (having possible values
between - and +). We may find the appropriate link function by translating the Bernoulli
probability mass function of Y into exponential form:
1 y
1
p y y 1 , for y = 0, 1 becomes p y 1 exp y ln
, for y = 0, 1.
1
The natural parameter of the distribution is thus w ln
, the logit function of the
1
success probability. For 0 1 , we have w . We may then write our logistic
regression model as:
x
0 1 x ,
(1)
g x ln
1 x
expressing the logit of the success probability as a linear function of the explanatory variable (in
the case of a model with a single explanatory variable). The interpretation of the above equation
is that the log of the odds of success is a linear function of the explanatory variable.
We may also write the model in the form:
exp 0 1 x
(2)
,
x
1 exp 0 1 x
the logistic regression function of x. The graph of this function is an ogive curve, with the
following characteristics:
0
0.5 , so that the odds of success are even when x 0 ,
i)
1
1
ii) lim x 0 ,
x
iii) lim x 1 ,
x
iv)
The slope of the function is given by
x
1 x 1 x . Thus the
x
maximum slope (rate of increase of success probability occurs at x
the slope is
1
.
4
The odds function corresponding to the logistic regression function is
x
(3)
x
exp 0 1 x .
1 x
0
, where
1
2
Example: Assume that we have administered a standardized test in mathematics, consisting of a
number of multiple-choice questions, to all 6th-grade students in Florida. As a result of analyzing
the test scores (we will not get into how this is done), we have an estimate of the abililty, x, of
each student in the population. We now have written another multiple-choice test question,
which is to be considered for future inclusion on a form of the standardized test. We want to
examine the characteristics of this test question. As with all of the other test items, the question
has four possible responses, only one of which is correct. Given that we know a randomly
chosen student’s ability, x, we may relate the student response variable, Y, coded as
1 = {correct} or 0 = {incorrect} to the student’s ability by using a logistic regression model. The
model has the form given in either equation (1) or equation (2). A “good” test item would be one
with fairly high discrimination at ability level x0
0
, which may be interpreted as the
1
difficulty level of the item. High discrimination means that the slope of the logistic regression
function is large at this value of x, so that students with ability greater than x0
0
have a
1
relatively high probability of answering the item correctly, while students with ability less than
0
have a relatively low probability of answering the item correctly. Let us assume that
1
the maximum discrimination of the item occurs at x0 1.5 , with 0 24 , and 1 16 . The
x0
discrimination power of the item is the maximum slope of the item characteristic curve (ICC),
equation (2). This maximum slope is
1
4
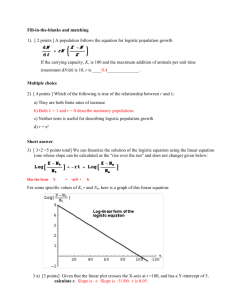
4 . A graph of the ICC is shown below.
3
We will now look at several students at several different ability levels. For student 1, with
ability level x1 1.8 , the probability that this student will answer the item correctly is found
from equation (2) to be
exp 0 1 x
e 4.8
x
0.9918 .
1 exp 0 1 x 1 e 4.8
This student is highly likely to answer the item correctly. The odds that this student will answer
the item correctly are 1.8 exp 24 161.8 121.5104 .
For student 2, with ability level x2 1.3 , we find
exp 0 1 x
e 3.2
x
0.0392 .
1 exp 0 1 x 1 e 3.2
This student has a very low probability of answering the item correctly. The odds that this
student will answer the item correctly are 1.3 exp 24 161.3 0.0408 .
For student 2, with ability level x3 1.5 , we find
exp 0 1 x
e0
0.5 .
1 exp 0 1 x 1 e 0
This student, with ability level equal to the difficulty of the item, has even odds of answering the
item correctly: 1.5 exp 24 161.5 1.
x
Note: The characteristics of the item, it’s difficulty and discrimination power, are characteristics
of the item in relation to the population of students to whom the item will be administered, and
have no meaning independent of this population.