Lab Lecture 1
advertisement

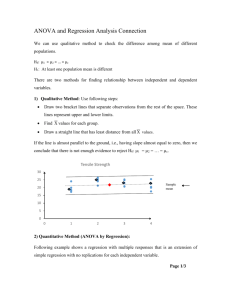
Psychology 522/622 Winter 2008 Lab Lecture #1 Multiple Regression: Dummy Coding and Regression Diagnostics The goals of this lab are to: familiarize the students with multiple regression for categorical predictors introduce some diagnostic procedures to find strange data points Oneway ANOVA and Multiple Regression DATAFILE: HEALTH.SAV The following data are from an experiment that explored the effect of health intervention type on health status. There were three health intervention types, a control, moderate, and maximum intervention. Outcomes were assessed on a health status scale where higher numbers indicate better health status. The data appear in the data set “health.sav.” We first analyze this data using the ANOVA. Here is some SPSS syntax. (All the SPSS syntax in this lab lecture is included in the syntax file “dummycodes.sps”.) ONEWAY health BY treat /STATISTICS DESCRIPTIVES HOMOGENEITY /PLOT MEANS /MISSING ANALYSIS /POSTHOC = TUKEY ALPHA(.05). Alternatively, here are the drop down menu commands that give you the same information: Analyze Compare Means Oneway ANOVA Move health to the DV box, move treat to the Factor box Click Post Hoc: select Tukey; Click Continue Click Options: select descriptives, homogeneity of variance test, and means plot; Click Continue Click OK Oneway Descriptives health N Control Moderate Intervention Maximum Intervention Total 20 20 20 60 Mean 4.2000 6.1000 7.3000 5.8667 Std. Deviation 1.47256 2.48998 2.07998 2.39680 Std. Error .32927 .55678 .46510 .30943 95% Confidence Interval for Mean Lower Bound Upper Bound 3.5108 4.8892 4.9347 7.2653 6.3265 8.2735 5.2475 6.4858 Minimum 1.00 1.00 2.00 1.00 Maximum 7.00 9.00 10.00 10.00 Descriptively by inspection of the group means, it looks like health status improved with the degree of intervention. Test of Homogeneity of Variances health Levene Statistic 2.686 df1 df2 2 Sig. .077 57 There is not strong evidence that the assumption of variance homogeneity is violated. This is good. ANOVA health Between Groups W ithin Groups Total Sum of Squares 97.733 241.200 338.933 df 2 57 59 Mean Square 48.867 4.232 F 11.548 Sig. .000 We reject the null hypothesis that all three population health status means are equal to one another. Post Hoc Tests Multiple Comparisons Dependent Variable: health Tukey HSD (I) treat Control Moderate Intervention Maximum Intervention (J) treat Moderate Intervention Maximum Intervention Control Maximum Intervention Control Moderate Intervention Mean Difference (I-J) -1.90000* -3.10000* 1.90000* -1.20000 3.10000* 1.20000 *. The mean difference is s ignificant at the .05 level. Homogeneous Subsets Std. Error .65051 .65051 .65051 .65051 .65051 .65051 Sig. .014 .000 .014 .164 .000 .164 95% Confidence Interval Lower Bound Upper Bound -3.4654 -.3346 -4.6654 -1.5346 .3346 3.4654 -2.7654 .3654 1.5346 4.6654 -.3654 2.7654 health Tukey HSD a treat Control Moderate Intervention Maximum Intervention Sig. N 20 20 20 Subset for alpha = .05 1 2 4.2000 6.1000 7.3000 1.000 .164 Means for groups in homogeneous s ubs ets are displayed. a. Us es Harmonic Mean Sample Size = 20.000. So what’s the story here? It is better to receive either the moderate or maximum intervention rather than the control intervention; however, there does not appear to be a statistically significant difference between the moderate and maximum interventions. Means Plots Mean of health 7.00 6.00 5.00 4.00 Control Moderate Intervention Maximum Intervention Treatment This graph provides a picture of the means as a function of intervention type. We now analyze this data using multiple regression. Yay! We first need to create dummy codes for our treatment levels. As there are three levels of treatment, we will need only two dummy codes. We’ll set the control group to be the “base category.” One can create these dummy codes using the SPSS menus. Another way is to use syntax. Here is what the SPSS syntax looks like for the creation of the dummy codes. RECODE treat (2=1) (ELSE=0) INTO moderate . EXECUTE . RECODE treat (3=1) (ELSE=0) INTO maximum . EXECUTE . Running this syntax creates two new variables that indicate, respectively, the moderate and maximum intervention groups. The new data set with the dummy codes is saved as “health1.sav”. Alternatively, here are the drop down commands for creating the dummy variables: TransformRecode into Different Variables Move treat into the Input VariableOutput Variable box *In the Output Variable section, type in Moderate [Maximum] in the name box Click Change Click Old and New Values *On the left side of the window in the Old Value section, type in 2 [3] in the Value box (this is because in the treat variable, moderate = 2) On the right side of the window in the New Value section, type 1 in the Value box Click Add On the left side of the window, click All Other Values On the right side of the window, type 0 in the Value box Click Add, Click Continue, Click OK. *Repeat these steps to create the dummy variable for maximum, but when you see an asterisk use the information provided in the brackets. DATAFILE: HEALTH1.SAV We now run our regression of health status on intervention type. We specify health as the outcome variable and moderate and maximum as the predictor variables. Note that we do not include the control group explicitly as a predictor variable. We see that things work out fine without it. Here is some syntax. REGRESSION /DESCRIPTIVES CORR /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT health /METHOD=ENTER moderate maximum . Alternatively, here are the drop down commands: AnalyzeRegressionLinear Move health to the DV box Move Moderate and Maximum to the IV box Click StatisticsDescriptives (estimates of effect size and model fit should already be checked) Click Continue, Click OK. Regression Correlations Pearson Correlation health 1.000 .069 .426 health moderate maximum moderate .069 1.000 -.500 maximum .426 -.500 1.000 We see that the indicator for the moderate intervention correlates weakly with the health status variable, but that the maximum intervention correlates more substantially with the health status variable. Note that there is a negative correlation (-.50) between the moderate and maximum intervention variables. This must be the case because if you are in one of the groups you cannot be in the other group. b Va riables Entere d/Re moved Model 1 Variables Entered maximum, a moderate Variables Removed . Method Enter a. All reques ted variables ent ered. b. Dependent Variable: health Model Summaryb Model 1 R .537a R Square .288 Adjusted R Square .263 Std. Error of the Estimate 2.05708 a. Predictors: (Constant), maximum, moderate b. Dependent Variable: health 28.8% of the variance in health status is attributable to the three intervention groups. ANOVAb Model 1 Regres sion Residual Total Sum of Squares 97.733 241.200 338.933 df 2 57 59 Mean Square 48.867 4.232 F 11.548 Sig. .000a a. Predic tors: (Constant), max imum, moderate b. Dependent Variable: health Note that although the terminology has changed, the numbers in this ANOVA summary table are identical to those for the ANOVA analysis. The take home message from both analyses is that intervention type is related to health status. In the ANOVA, we needed to run post-hoc tests to look for group mean differences. In regression, because we have dummy coded our predictors, two of these 1df contrasts appear automatically as regression slopes. Coeffi cientsa Model 1 (Const ant) moderate maximum Unstandardized Coeffic ients B St d. Error 4.200 .460 1.900 .651 3.100 .651 St andardiz ed Coeffic ients Beta .377 .615 t 9.131 2.921 4.766 Sig. .000 .005 .000 a. Dependent Variable: health Note the unstandardized coefficients. The constant (4.2) is the mean of the control intervention group (check this with the ANOVA results above). The regression slope for moderate intervention is the difference between the means for the moderate and control interventions (check this with the ANOVA results above). This difference is statistically significant. The regression slope for maximum intervention is the difference between the means for the maximum and control interventions (check this with the ANOVA results above). This difference, too, is statistically significant. Note that we do not get a test of whether the moderate and maximum intervention means differ. To get this using multiple regression, we would need to change one of these groups to the “base category” which is simple enough to do. Finding Strange Data Points Here we consider ways to find strange data points in the simple case where we are interested in bivariate associations (e.g., correlations and simple regression slopes). Although these methods may seem unnecessary in this case because we can find such data points simply from looking at a scatter plot, these methods are more useful when we consider multivariate associations. Thus, we seek to gain understanding of these tools in the simple case. DATAFILE: LUMBERSHORT.SAV This data contains the results of two tests of lumber stiffness on 28 planks. The data are contained in the SPSS file “lumbershort.sav”. Of interest is how the results of these two tests of lumber stiffness are related. The SPSS syntax for this section of the lab lecture are contained in the SPSS syntax file “lumber.sps”. First, we compute the correlation between test results. Can you remember how to do this via the drop down menus? The syntax is below. CORRELATIONS /VARIABLES=static1 static2 /PRINT=TWOTAIL NOSIG /MISSING=PAIRWISE . Correlations static1 static1 static2 Pearson Correlation Sig. (2-tailed) N Pearson Correlation Sig. (2-tailed) N 1 . 28 .739** .000 28 static2 .739** .000 28 1 . 28 **. Correlation is s ignificant at the 0.01 level (2-tailed). The two test scores are positively correlated and this correlation is statistically significant. Next, we explore this data looking at a simple scatter plot. (Hopefully, you would do such exploration BEFORE you conduct the preceding analysis ) GRAPH /SCATTERPLOT(BIVAR)=static2 WITH static1 /MISSING=LISTWISE . Alternatively, the drop down commands: Graphs Scatter (Note: if you’re using SPSS 14 or higher, you need to go GraphsLegacy DialogsScatter) Select Simple Scatter Move static2 to the x axis and static1 to the Y axis Click OK 2200.00 Lumber stiffness static1 test 2000.00 1800.00 1600.00 1400.00 1200.00 1000.00 1000.00 1250.00 1500.00 1750.00 2000.00 2250.00 Lumber stiffness static2 test Clearly, there is one data point that is much different than the rest. (Note: SPSS does not circle it in red for you, that’s a favor from me ) Its score is low on one of the tests and high on the other test. Inspection of the data set reveals that this in Plank #13. In newer versions of SPSS if you use the Chart Editor you can actually right click on that data point and SPSS will take you to it in the dataset if you select “Go to Case.” At this point we should decide what to do with this data point. Although this point was easy to find with bivariate data, we now examine techniques that are especially useful with multivariate data where bivariate plots are not sufficient. We’ll be interested in seeing whether these more complicated techniques identify Plank #13 as problematic. We do these analyses within SPSS Regression. (Note that these techniques are useful even if we don’t plan on conducting a regression analyses, e.g., a factor analysis.) In this case, the variable that serves as the outcome variable (DV) is arbitrary. Thus, we will regress Test 1 on Test 2 with some additional syntax. So, test 1 = DV and test 2 = IV. REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT static1 /METHOD=ENTER static2 /CASEWISE PLOT(ZRESID) ALL /SAVE MAHAL COOK LEVER . Alternatively, here are the drop down commands: Analyze Regression Linear Move static1 to the DV box, move static2 to the IV box Click Statistics; Click Casewise diagnostics, Click All Cases; Click Continue Click Save; Select Mahalanobis, Cook’s, Leverage values; Click Continue; Click OK Regression Variables Entered/Removedb Model 1 Variables Entered static2 a Variables Removed Method Enter . a. All requested variables entered. b. Dependent Variable: static1 Model Summaryb Model 1 R .739a R Square .547 Adjusted R Square .529 Std. Error of the Estimate 181.76823 a. Predictors: (Constant), s tatic2 b. Dependent Variable: static1 ANOVAb Model 1 Regres sion Residual Total Sum of Squares 1035385 859031.9 1894417 df 1 26 27 Mean Square 1035384.767 33039. 690 F 31.338 Sig. .000a a. Predic tors: (Constant), static2 b. Dependent Variable: static1 Coeffi cientsa Model 1 (Const ant) static2 Unstandardized Coeffic ients B St d. Error 353.045 208.312 .678 .121 a. Dependent Variable: static1 St andardiz ed Coeffic ients Beta .739 t 1.695 5.598 Sig. .102 .000 Ca sew ise Dia gnosticsa Case Number 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 St d. Residual .014 1.345 -.244 -1. 553 -.086 .208 -1. 182 .514 .047 .192 -.070 .339 3.686 -.693 -.816 .067 .326 -.858 -1. 305 .372 -.500 -.484 -.200 -.610 .576 -.119 1.086 -.052 static1 1561.00 2087.00 1815.00 1110.00 1614.00 1439.00 1271.00 1717.00 1384.00 1518.00 1627.00 1595.00 1901.00 1389.00 1002.00 1252.00 1602.00 1313.00 1547.00 1422.00 1290.00 1646.00 1356.00 1238.00 1701.00 1414.00 2065.00 1214.00 Predic ted Value 1558.4177 1842.4734 1859.4219 1392.3231 1629.6012 1401.1363 1485.8785 1623.4997 1375.3747 1483.1667 1639.7702 1533.3341 1230.9741 1515.0298 1150.2995 1239.7872 1542.8252 1468.9300 1784.1708 1354.3586 1380.7982 1734.0035 1392.3231 1348.9351 1596.3822 1435.7111 1867.5571 1223.5168 Residual 2.58225 244.52656 -44.42188 -282.323 -15.60115 37.86369 -214.878 93.50028 8.62531 34.83329 -12.77021 61.66593 670.02594 -126.030 -148.300 12.21275 59.17481 -155.930 -237.171 67.64136 -90.79819 -88.00349 -36.32312 -110.935 104.61777 -21.71111 197.44288 -9. 51675 a. Dependent Variable: st atic1 Note that Plank #13 has the largest residual (standardized and raw). This is consistent with the scatter plot results. The value of that observation is very different from its predicted value on the regression line. Re siduals Sta tisticsa Minimum Maximum Mean Predic ted V alue 1150.2996 1867.5571 1503.2143 St d. P redic ted Value -1. 802 1.861 .000 St andard E rror of 34.416 73.593 46.792 Predic ted V alue Adjust ed P redicted Value 1150.4421 1867.7739 1501.0418 Residual -282.323 670.02594 .00000 St d. Residual -1. 553 3.686 .000 St ud. Residual -1. 592 3.901 .006 Deleted Residual -296.431 750.55786 2.17248 St ud. Deleted Residual -1. 643 5.942 .077 Mahal. Dis tanc e .004 3.462 .964 Cook's Dis tanc e .000 .915 .058 Centered Leverage Value .000 .128 .036 St d. Deviat ion 195.82539 1.000 N 28 28 13.297 28 195.68737 178.37040 .981 1.034 198.10760 1.348 1.151 .174 .043 28 28 28 28 28 28 28 28 28 a. Dependent Variable: static1 For our purposes here we focus on the last three rows of this table. Recall that Mahalanobis’ Distance is a measure of distance of each data point from the multivariate centroid (mean) that takes into account the variances of the variables. Note that the maximum value here is 3.46. This value means nothing in and of itself, but comparing it to the mean value of .964 and the minimum value of .004 we see that the maximum is much farther above the mean than the minimum is below the mean. Think about what this would look like if you put these three points on a distribution. This suggests an asymmetric distribution and that this maximum may indicate one or more problematic data points. Cook’s Distance is another distance measure. The maximum value of this distance measure is much farther above the mean value than the minimum value is below the mean value. Again this suggests an asymmetric distribution and that this maximum may indicate one or more problematic data points. Centered leverage is an index of the influence of each data point on the regression slope. Larger values indicate a greater degree of influence on this slope. The maximum leverage value is much farther above the mean value than the minimum value is below the mean value. Again this suggests an asymmetric distribution and that this maximum may indicate one or more problematic data points. However, from the above info, we don’t know which data point (or points) are potentially problematic. You’ll notice in the SPSS data file after you run the syntax that three new variables have been added (MAH_1, COO_1, LEV_1). We can now use boxplots of these values to look for the offending case(s). Remember that although histograms will give us an idea of what the distribution of Mahalanobis, Cook’s and Leverage values look like, they don’t give us a way to identify specific cases. Boxplots, on the other hand, give us an idea of distribution and help us to identify outliers. EXAMINE VARIABLES=MAH_1 /COMPARE VARIABLE/PLOT=BOXPLOT/STATISTICS=NONE/NOTOTAL/ID=plank /MISSING=LISTWISE . Alternatively, the drop down commands: GraphsBoxplots Select Simple, Summaries of Separate Variables; Click Define Move Mahalanobis to the “Boxes Represent” box Move Plank number to the Label Cases by box; Click OK 4.00000 3.00000 2.00000 1.00000 0.00000 Mahalanobis Distance The median (heavy black bar) is less than .5, but we know the mean = .94. So what? If the median is smaller than the mean, it indicates asymmetry (more specifically, positive skew). Imagine this plot tipped to the right, on its side. We can see that the majority of the values cluster between 0 and 2, while the rest slide out to the right tail. Now let’s create a boxplot for Cook’s distance and Leverage values. We’ll put these two variables in the same graph to save time/space. EXAMINE VARIABLES=COO_1 LEV_1 /COMPARE VARIABLE/PLOT=BOXPLOT/STATISTICS=NONE/NOTOTAL/ID=plank /MISSING=LISTWISE . Drop down commands: GraphsBoxplotsSimple, Summaries of Separate Variables Define Move Cook’s and Leverage values to the “Boxes Represent” box Move Planks to the “Label Cases by” box; Click OK. 1.00000 13.00 0.80000 0.60000 0.40000 0.20000 2.00 27.00 15.00 19.00 4.00 0.00000 Cook's Distance Centered Leverage Value These boxplots illustrate the positive skew in these distributions. Cook’s distance in this case clearly identifies one observation that is much different that the others. This is Plank #13. In this case, Mahalanobis’ Distance and the leverage values appear less sensitive to the type of discrepancy that Plank #13 exhibits. Thus, in summary it is a good idea to inspect all four types of statistic (i.e., residuals, Mahalanobis’ distance, Cook’s distance, and leverage) as each can pick up on different types of discrepancy.