Client/Server Computing: Architecture, Types, and Clients
advertisement

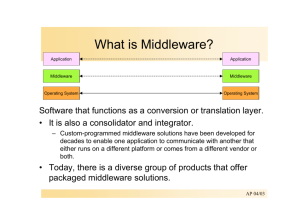
Client / Server Computing What is Client/Server? Client/Server (referred to as C/S for brevity) is a logical progression from from modular processing, where different program modules are responsible for different tasks. Client/server is a computational architecture that involves client processes requesting service from server processes. In the client/server model, these processes are generally maintained on different pieces of hardware. But it is important to remember that the client and server are both SOFTWARE processes!! Although many generally call hardware boxes 'servers' or 'clients', the clients or servers are actually the software processes these computers are running. Even thought the client and server processes are separated, a C/S application should seem like it operates as a single application to the user. The CLIENT: The client is a process (program) that sends a message to a server process (program), requesting that the server perform a task (service). Client programs usually manage the user-interface portion of the application, validate data entered by the user, dispatch requests to server programs, and sometimes execute business logic. The client-based process is the user's point of interaction with the application. The client process contains solution-specific logic and provides the interface between the user and the rest of the application system. The client process also manages the local resources that the user interacts with such as the monitor, keyboard, workstation CPU and peripherals. One of the key elements of a client workstation is the graphical user interface (GUI). Normally a part of operating system i.e. the window manager detects user actions, manages the windows on the display and displays the data in the windows. The SERVER: A server process (program) fulfills the client request by performing the task requested. Server programs generally receive requests from client programs, execute database retrieval and updates, manage data integrity and dispatch responses to client requests. Sometimes server programs execute common or complex business logic. The server-based process "may" run on another machine on the network. This server could be the host operating system or network file server; the server is then provided both file system services and application services. Or in some cases, another desktop machine provides the application services. The server process acts as a software engine that manages shared resources such as databases, printers, communication links, or high powered-processors. The server process performs the back-end tasks that are common to similar applications. Categories of Component Processes in the Client/Server Model Three categories: The User Interface (UI): how the application is presented to the user; The Business Logic (BL): the processing rules that are used in the C/S application; a payroll application will have different business rules than a trading floor application, for example; Data Management (DM): the storage of the data used by the application- which implements the information model These three components can be divided among the client and server processes in several ways-See the table below: Types of Client/Server Computing The Gartner Group came out with the five ways of describing the different c/s styles based on how they split the three components of any application: user interface, business or application logic, data management. The five styles are distributed presentation, remote presentation, distributed function, remote data management, and distributed data management. (Note: This is an arbitary classification and others may do it differently). Types of Client/Server Computing C/S Type Distributed Presentation Remote Presentation Distributed Logic Data Mgt. Data Mgt. Data Mgt. Functions on Business Logic Business Logic Business Logic Server Side User Interface Remote Data Management Distributed Database Data Mgt. Data Mgt. Network over which the processes communicate Functions on Client Side Data Mgt. Business Logic Business Logic Business Logic User Interface User Interface User Interface User Interface User Interface 'Thinnest' Client ---------------------------------------------------------- 'Fattest' Client Datamation, 4/1/95 Distributed and Remote Presentation -- For people whose roots are embedded in the mainframe IBM world, client-server is essentially distributed or remote presentation. This style maps a workstation Graphical User Interface (GUI) front end onto an existing application's textbased screen. In Distributed Presentation, we are generally looking at a system which uses a dumb terminal at the client side. This is the extreme of the 'thin' client model (see below). Distributed Logic -- Here the split occurs in the application functionality, one part going to the client, other to the server. Distributed Logic applications are the most complex of the three basic typologies since two separately compiled application programs must be developed. Developers must analyze where each function should reside and what type of dialog must occur between the two programs. The underlying communications facilities may implement either a message-based or remote procedure call (RPC) mechanism for transfer of dialog and data. Remote Data Management -- In remote data management, the entire application resides on the client and the data managment is located on a remote server/host. Remote Data Management is relatively easily to program for because there is just one application program. Distributed Database -- This is when data management and application functions occur at both the client and server. In this instance, data management at the client would include referential, read-only data. Data frequently updated or accessed by many users would reside on the server. This is the extreme of the 'fat' client model. Fat Clients vs. Thin Clients Fat Clients -- These are fully loaded PC's - desktops or laptops - containing a full suite of PC operating system, Windows, PC applications and network connectivity software. This is a misnomer, because clients are actually processes, not machines. These systems are ready to run all types of processes--user interface, business logic, and data management. Machines that are capable of running all these level of processes are costly and are complex to manage. Thin Clients -- These are machines that will download what they need to run from a network. They attach to a server and provide a graphical interface on a terminal that is optimized for network-centric computing. Thin clients cost a fraction of the price of a fat client. Thin clients can readily access the internet, network based application and other host based systems. These devices are designed to take the complexity out of managing them. They will be managed like dumb terminals--there will be no local data storage and no disk drives to worry about, yet users will be able to select applications from various operating systems connected to the network simultaneously. Fat Client -- Pros (+) and Cons (-) (+) More flexibility for the user; (+) Since the client does more processing, the server does not have to be very powerful; (-) Because the server has to deliver more data for the client to process, there are large data sets going through the network, leading to greater network congestion; (-) Machines capable of running fat client processes are more expensive, because they require more processing power, more RAM, and more secondary storage; (-) Fat clients increase managerial costs; changes to business logic have to be distributed to all of the individual clients; there is much more user training involved; fat clients have a variety of software that must be supported; (-) The annual cost of ownership of each fat client has been estimated at $12K to $16K per year; this includes all the real costs of the hardware and software, plus all the hidden costs of software upgrades, managing the machines, and training the users for all the different client processes they are using. Thin Client -- Pros (+) and Cons (-) (-) Less flexibility for the user; (-) Because the server processes handle more of the processing, the machine running the server processes has to be very powerful; (+) The server only delivers the results of client queries, not entire data sets. Because of these, the server is sending much less data through the network. Because of this, there is generally less congestion on the network; (+) Machines that run only thin client processes do not need as much processing power, RAM, or secondary storage. Because of this, these thin client machines are less expensive (+) Thin clients minimize some managerial costs; most changes can be made at the server level, eliminating the need to distribute changes to each client machine. Two-Tier and Three-Tier Architectures Two-Tier Architecture The three components of an application (user interface, business logic, and data management) are split into only tow tiers--the client and the server. In a two-tier architecture, a client talks directly to a server, with no intervening server. It is typically used in small environments (less than 50 users). A common error in client/server development is to prototype an application in a small, two-tier environment, and then scale up by simply adding more users to the server. This approach will usually result in an ineffective system, as the server becomes overwhelmed. To properly scale to hundreds or thousands of users, it is usually necessary to move to a three-tier architecture. Three-Tier Architecture A three-tier architecture splits three parts into three tiers, and introduces a server (or an "agent") between the client and the server. The role of the agent is manyfold. It can provide translation services (as in adapting a legacy application on a mainframe to a client/server environment), metering services (as in acting as a transaction monitor to limit the number of simultaneous requests to a given server), or intellegent agent services (as in mapping a request to a number of different servers, collating the results, and returning a single response to the client. The goal of the three-tier architecture is to provide a middle-tier process, called middleware, that focuses as an intermediary between the server and the client. This allows the client process to emphasize the user interface, and the server side to emphasize data management. Type of Middleware Database middleware is used on database-specific environments. It provides the link between client and server when the client application that accesses data in the server's database is designed to use only one database type. Remote procedure calls (RPC) middleware is a more general-purpose solution to client/server computing than database middleware. RPCs are used to access a wide variety of data resources for use in a single application. Messaging middleware takes the RPC philosophy one step further by addressing the problem of failure in the client/server system. It provides synchronous or asynchronous connectivity between client and server, so that messages can be either delivered instantly or stored and forwarded as needed. Object middleware delivers the benefits of object-oriented technology to distributed computing in the form of object request brokers. ORBs package and manage distributed objects, which can contain much more complex information about a distributed request than an RPC or most messages and can be used specifically for unstructured or nonrelational data. Transaction-processing (TP) monitors have evolved into a middleware technology that can provide a single API for writing distributed applications. TP monitors generally come with a robust set of management tools that add mainframelike controls to open distributed environments. Proprietary middleware is a part of many client/server development tools and large client/server applications. It generally runs well with the specific tool or application environment it is a part of, but it doesn't generally adapt well to existing client/server environments, tools, and other applications. Business Drivers for Client / Server Computing Downsizing from 'big iron' (mainframe) environments; Movement from vertical 'stovepipe' applications to enterprise-wide systems; Organizations have changed from steep hierarchies to flattened hierarchies Network management is replacing vertical management There is a change to team based management The user will perform as much processing as possible during customer contact time Multi-skilled and multi-function teams need access to multiple applications The development and implementation of client/server computing is more complex, more difficult and more expensive than traditional, single process applications. The only answer to the question "why build client/server applications?" is "because the business demands the increased benefits. Send questions about this outline to Bill Ferns Download an MS-Word 6.0 version of this file. Return to the Bill Ferns' CIS9000 page.