A sentence similarity measure using verbs, nouns and adjuncts
advertisement

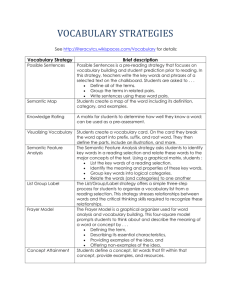
A sentence similarity measure using verbs, nouns and adjuncts Author: David M. Pearce Supervisors: Dr Zuhair Bandar, Dr. David McLean Introduction There have been many projects trying to give a computer understanding of a language such as English1-3. The solution has proved elusive despite large investments of time and money. The complexity of the problem is a result of the English language containing much ambiguity, which a reader copes with through making assumptions. People’s assumptions of what they read are influenced by their vocabulary, idiolect and even their experiences. It is impractical to try and mimic human interpretation of a sentence with a computer as there are a vast number of rules and exceptions that can be specific to the individual reader. A similarity measure is simply a number within a range that represents how alike the objects being compared are to one another. An accurate sentence similarity measure would be a very powerful device greatly enhancing the computers interaction with humans. The measure could be used to determine whether a previously unseen sentence can mean the same as a sentence that the computer knows how to deal with. Two of the most prominent tasks that a model could be plugged in to are automatic e-mail response and chat room monitoring. Both of which are very time consuming and can be invasive of personal privacy when performed by people. When asked to compare these two sentences a human will most likely treat both sentences as meaning the same thing. However, using rare definitions for the last word of each sentence a valid sentence is still formed. Using The Chambers Dictionary8 rail can mean a small flightless bird and train can have the meaning whale-oil. Both of these definitions function with the verb clause travelled by. Fig. 2 illustrates this idea graphically where the small human understanding can give a lower match than the maximum possible match that the possible meanings could yield. Aim There have already been some simple models that attempt to make a written sentence comparison. These are tasks such as LSA4 and the noun based sentence similarity model detailed by Li, Bandar et al5. The purpose of this research is to expand the ideas contained within the Li, Bandar et al. model to deal with the additional linguistic complexities that arise from the result of Figure 2: Visual representation of the meanings of a pair of sentences including verbs, adjectives and adverbs so as to yield a more powerful and The aim of this research is to have a model that can be gradually refined so accurate similarity algorithm and tool. that each of the meanings of words becomes closer to those understood by humans with each evolution of the program. This is done by combining the Approach vocabulary and semantic information contained in WordNet with the rules of To compare sentences semantically first there needs to be a semantic map of Grammar and structure. When the vocabulary is expanded so as to include words. A word in English does not have to have a unique meaning. To make adjuncts and verbs a greater ambiguity can exist between words this can be the comparison between a pair of words from the respected and widely used reduced by using the structural information contained from words which semantic database WordNet6 developed in Princeton University is used. The carry little or no semantic information the simplest example of this is the database is split into synsets (groups of words that have the same meaning or definite article (the) which indicates that the next phrase is a noun clause. would appear in the same place in the thesaurus). Each synset has a single This is a necessary step as the word comparison method will always look for parent this forms a tree structure that allows the proximity of any two nodes the nearest definitions within the semantic tree structure. If the word cat in a to be found as a function of the subsumer (the deepest common parent node) sentence was clearly referring to the cat ‘o nine tails rather than the animal (mammal in the case of cat and dog in figure 1) and the distance to the root and the word dog to the verb to pursue then an artificially high similarity node. This allows for Li, McLean & Bandar’s word similarity7 measure to be would be obtained without the use of better disambiguation from using the used. information contained within the sentence. Future Work The continual development of the model to allow for the disambiguation of the different parts of the sentence so that the clauses that represent the same thing in the sentence are only compared against each other. Future work will include domain testing of the algorithm for the task of automated e-mail response allowing the computer to decide what the incoming e-mail is about and then what action should be taken as a result. References: 1 Figure 1: Lexical semantic tree structure as found in WordNet6 With words the highest similarity score between the meaning is taken as the overall score. A problem can be illustrated by only selecting a single meaning using the following two sentences. 1 - Tim travelled by rail. 2 - Tim travelled by train. H. Maynard, K. McTait, D. Mostefa, L. Devillers, S. Rosset, P. Paroubek, C. Bousquet, K. Choukri, J. Goulian, J. Antoine, F. Béchet, O. Bontron, L. Charnay, L. Romary, M. Vergnes, & N. Vigouroux, 2004, ‘Constitution d'un corpus de dialogue oral pour l'évaluation automatique de la compréhension hors et en contexte du dialogue.’ JEP, Fez 2 F. Ciravegna, S. Harabagiu, 2003, ‘Recent advances in Natural Language Processing’, IEEE Intelligent Systems, Jan / Feb, pp 12 – 13 3 J. Allen, 1994, Natural Language Understanding, Bejamin Cummings, 2nd Ed. 4 T.K. Landauer, P. W. Foltz & D. Laham, 1998, ‘Introduction to Latent Semantic Analysis’, Discourse Processes, V25, pp 259-284 5 Y. Li, Z. Bandar, D. McLean, J. O’Shea & K. Crockett, 2006, ‘Sentence Similarity Based on Semantic Nets and Corpus Statistics’, IEEE Knowledge and Data Engineering, Vol 18 No 8, pp 1138-1150 6 C. Fellbaum (ed.), 1998, WordNet An Electronic Lexical Database, The MIT Press 7 Y. Li, D. McLean & Z. Bandar, 2003, ‘An Approach for Measuring Semantic Similarity between Words Using Multiple Information Sources’, IEEE Transactions on Knowledge and Data Engineering, Vol 15 No 4, pp 871-882 8 I. Brookes (ed.), 2005, The Chambers Dictionary, Chambers Harrap Publishers Ltd, Edinburgh, pp 1252&1610