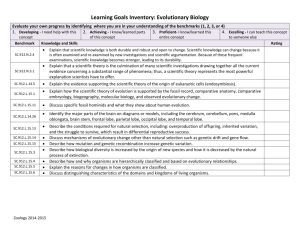
Session - Genetic Algorithms Research and Applications Group
advertisement

CEC99 SPECIAL SESSIONS Session: Theory and Foundation of Evolutionary Computation – 5 Sessions Organizer: David Fogel Natural Selection Inc., La Jolla, CA 92037 fogel@ece.ucsd.edu 1. "Characterizations of Trajectory Structure of Fitness Landscapes Based on Pairwise Transition Probabilities of Solutions" Mark Jelasity, Boglarka Toth, and Tamas Vinko Characterization of trajectory structure of fitness landscapes is a major problem of EC theory. In this paper a hardness measure of fitness landscapes will be introduced which is based on statistical properties of trajectories. These properties are approximated with the help of a heuristic based on the transition probabilities between the elements of the search space. This makes it possible to compute the measure for some well known function: a ridge function, a long path function, a fully deceptive function, and a combinatorial problem: the subset sum problem. Using the same transition probabilities the expected number of evaluations needed to reach the global optimum from any point in the space is approximated and examined for the above problems. 2. "Aggregating Models of Evolutionary Algorithms" William M. Spears The standard difficulty in modeling evolutionary algorithms (EAs) is in finding the correct level of granularity. If the granularity is too coarse the model has poor predictive ability. If the granularity is too find, the model is generally intractable. A solution to this dilemma is to find methods for aggregating finegrained models of EAs -- the aggregation removes unnecessary detail from models, producing simpler models with good predictive accuracy. This paper summarizes two useful aggregation techniques for EA models that introduce little or no error in accuracy. 3. "Some Observations on the Interaction of Recombination and Self-Adaptation in Evolution Strategies" Lothar Grunz and Hans-Georg Beyer The performance of the multirecombinant (mu/mu,lambda)-ES with sigma-self-adaptation (sSA) is investigated on the sphere model. The investigation includes the computation of the maximal performance of an ES using recombination can reach when the mutation strength is optimally adjusted during the whole evolution. The comparison between the strategies with and without sSA shows that selfadaptation is not always able to drive the ES in its optimal working regime, although it still guarantees linear convergence order. The static and dynamic aspects of self-adaptation are discussed and it is shown that the learning parameter has a sensible influence on the progress rate. 4. "Self-Adaptation and Global Convergence: A Counter-Example" Guenter Rudolph The self-adaptation of the mutation distribution is a distinguishing feature of evolutionary algorithms that optimize over continuous variables. It is widely recognized that self-adaptation accelerates the search for optima and enhances the ability to locate optima accurately, but it is generally unclear whether these optima are global or not. Here, it is proven that the probability of convergence to the global optimum is less than one in general -- even if the objective function is continuous. 5. "Emphasizing Extinction in Evolutionary Programming" Garrison Greenwood, Gary B. Fogel, and Manuel Ciobanu Evolutionary programming uses tournament selection to choose parents for reproduction. Tournaments naturally emphasize survival. However, a natural opposite of survival is extinction, and a study of the fossil record shows extinction plays a key role in the evolutionary process. This paper presents a new evolutionary algorithm that emphasizes extinction to conduct search operations over a fitness landscape. 6. "A Performance Analysis of Evolutionary Pattern Search with Generalized Mutation Steps" William Hart and Keith Hunter Evolutionary pattern search algorithms (EPSAs) are a class of evolutionary algorithms (EAs) that have convergence guarantees on a broad class of nonconvex continuous problems. In previous work we have analyzed the empirical performance of EPSAs. This paper revisits that analysis and extends it to a more general model of mutation. We experimentally evaluate how the choice of the set of mutation offsets affects optimization performance for EPSAs. Additionally, we compare EPSAs to self-adaptive Eas with respect to robustness and rate of optimization. All experiments employ a suite of test functions representing a range of modality and number of multiple minima. 7. "On the Real Arity of Multiparent Recombination" I. G. Sprinkhuizen-Kuyper, C. A. Schippers, and A .E. Eiben In the last years several papers reported experimental results for multi-parent recombination operators, looking at the effects of using more parents. Tacitly, these studies assume that the number of parents (the arity of the given recombination operator) tells how many old individuals contribute to a new one by passing their genetic information to it. In this article we point out that this assumption is not valid for a number of well-known recombination operators and distinguish parents and donors, the latter ones being those parents that really deliver information to the offspring. We perform a mainly theoretical analysis on the number of donors. Experimental results are provided to support theoretical estimates and predictions. 8. "Learning Landscapes: Regression on Discrete Spaces" William G. Macready and Bennett S. Levitan It is often useful to be able to reconstruct landscapes from a set of data points sampled from the landscape. Neural networks and other supervised learning techniques can accomplish this task but typically do not exploit the metric structure of discrete input spaces. In this paper we propose a new method based on Gaussian processes which reconstructs landscapes over discrete spaces from data sampled from the landscape and the optional prior beliefs about the correlation structure of the landscape. In addition to speeding up costly fitness evaluations, the methods can be used to characterize landscapes in terms of a small set of easily interpretable quantities. 9. "The Deterministic Genetic Algorithm: Implementation Details and Some Results" Ralf Salomon Recent literature on genetic algorithms provides a controversial discussion on the efficiency of this particular class of randomized optimization procedures; despite several encouraging empirical results, recent theoretical analyses have argued that in most cases, the runtime behavior of genetic algorithms is increased by at least a factor of ln(n) with n denoting the number of parameters to be optimized. It has been argued that these inefficiencies are due to intrinsic resampling effects. As a result of these theoretical considerations, a deterministic genetic algorithm has been suggested as a theoretical concept. Since its proposition, information discussions have been raised concerning some implementation details as well as efficacy issues. Since some implementation details are a bit tricky, this paper discusses some of them in a pseudo programming language similar to PASCAL or C. In addition, this paper presents two possible variants in detail and compares their runtime behavior with another fairly-established procedure, the breeder genetic algorithm. It turns out that on widely-used test functions, the deterministic variants scale strictly better. Furthermore, this paper discusses some specific fitness functions on which random algorithms yield better worst-case expectations than deterministic algorithms; but both types require constant time on average, i.e., one function evaluation. 10. "Effective Fitness Landscapes for Evolutionary Systems" Chris Stephens In evolution theory the concept of a fitness landscape has played an important role, evolution itself being portrayed as a hill-climbing process on a rugged landscape. In this article it is shown that in general, in the presence of other genetic operators such as mutation and recombination, hill-climbing is the exception rather than the rule. This discrepancy can be traced to the different ways that the concept of fitness appears -- as a measure of the number of fit offspring, or as a measure of the probability to reach reproductive age. Effective fitness models the former not the latter and gives an intuitive way to understand population dynamics as flows on an effective fitness landscape when genetic operators other than selection play an important role. The efficacy of the concept is shown using several simple analytic examples and also some more complicated cases illustrated by simulations. 11. "An Examination of Building Block Dynamics in Different Representations" Annie S. Wu and Kenneth A. De Jong We compare the traditional, fixed genetic algorithm (GA) representation scheme with a floating representation scheme and examine the differences in building block dynamics and how these differences affect a GA's ability to balance exploration and exploitation of building blocks. This study examines both the overall performance of a GA and the detailed events that contribute to overall behavior. Results indicate that the floating representation allows a GA to maintain a higher level of construction which results in a more diverse population from which to build solutions. 12. "The Futility of Programming Computers by Means of Natural Selection" Terry Fogarty Abstract Forthcoming 13. "The Time Complexity of Maximum Matching by Evolutionary Programming" Xin Yao Abstract Forthcoming 14. "Adaptive Genetic Algorithms -- Modeling and Convergence" Alexandru Agapie Head of Computational Intelligence Laboratory Institute of Microtechnology Bucharest, 72225, P.O. Box 38-160, Romania e-mail: agapie@oblio.imt.pub.ro agapie_a@hotmail.com http://www.imt.ro/ The paper presents a new mathematical analysis of GAs; we propose the use of random systems with complete connections (RSCC), a non-trivial extension of the Markovian dependence, accounting for the complete, rather than recent, history of a stochastic evolution. As far as we know, this is the first theoretical modeling of an adaptive GA. First we introduce the RSCC model of an p(m)-adaptive GA, then we prove that a "classification of states" is still valid for our model, and finally we derive a convergence condition for the algorithm. 15. Colin Reeves, Title, Abstract, Forthcoming 16. "Problem Perturbation: Implications on Fitness Landscapes" Worthy Martin Abstract Forthcoming 17. "FDA - An Evolutionary Algorithm for Additively Decomposed Functions" Heinz Muehlenbein and Thilo Mahnig FDA - the Factorized Distribution Algorithm - is an evolutionary algorithm which combines mutation and recombination by using a distribution instead. First the distribution is estimated from a set of selected points. It is then used to generate new points for the next generation. In general a distribution defined for n binary variables has 2^n parameters. Therefore it is too expensive to compute. For additively decomposed discrete function (ADFs) there exists an algorithm which factors the distribution into conditional and marginal distributions, each of which can be computed in polynomial time. The scaling of FDA is investigated theoretically and numerically. The scaling depends on the ADF structure and the specific assignment of function values. Difficult functions on a chain or a tree structure are optimized in about O(n*sqrt(n)) function evaluations. More standard genetic algorithms are not able to optimize these functions. FDA is not restricted to exact factorizations. It also works for approximate factorizations. 18. Emanuel Falkenauer, Title, Abstract, Forthcoming. 19. "On Some Difficulties in Local Evolutionary Search" Hans-Michael Voigt In this paper we consider the very simple problem of optimizing a stationary unimodal function over R^n without using analytical gradient information. There exist numerous algorithms from mathematical programming to evolutionary algorithms for this problem. Here we have a closer look at advanced evolution strategies (GSA, CMA), the evolutionary gradient search algorithm (EGS), local search enhancement by random memorizing (LSERM), and the simple (1+1)-evolution strategy. These approaches show different problem solving capabilities for different test functions. We introduce different measures which reflect certain aspects of what might be seen as the problem difficulty. Based on these measures it is possible to characterize the weak and strong points of the mentioned approaches which may lead to even more advanced algorithms. 20. Some Information Theoretic Results on Evolutionary Optimization Thomas M. English Tom English Computing Innovations 2401 45th Street, Apt. 30 Lubbock, Texas 79412 USA The body of theoretical results regarding conservation of information ("no free lunch") in optimization has not related directly to evolutionary computation. Prior work has assumed that an optimizer traverses a sequence of points in the domain of a function without revisiting points. The present work reduces the difference between theory and practice by a) allowing points to be revisited, b) reasoning about the set of visited points instead of the sequence, and c) considering the impact of bounded memory and revisited points upon optimizer performance. Fortuitously, this leads to clarification of the fundamental results in conservation of information. Although most work in this area emphasizes the futility of attempting to design a generally superior optimizer, the present work highlights possible constructive use of the theory in restricted problem domains. Session: Time Series Prediction – 3 Sessions Organizer: Byoung - Tak Zhang Artificial Intelligence Lab (SCAI) Department of Computer Engineering Seoul National University Seoul 151-742, Korea Phone: +82-2-880-1833; fax: +82-2-883-3595 btzhang@scai.snu.ac.kr http://scai.snu.ac.kr/~btzhang http://scai.snu.ac.kr/~btzhang/conferences/cec99/index.html 1. Shu-Heng Chen and Chun-Fen Lu: Would Evolutionary Computation Help in Designs of Artificial Neural Nets in Forecasting Financial Time Series? 2. Adelino R. Ferreira da Silva: Evolving Best-Basis Representations 3. E. Gomez-Ramirez, A. Gonzalez-Yunes, and M. Avila-Alvarez: Adaptive Architecture of Polynomial Artificial Neural Network to Forecast Nonlinear Time Series 4. Ch. Hafner and J. Froehlich: Generalized Function Analysis Using Hybrid Evolutionary Algorithms 5. Hitoshi Iba: Using Genetic Programming to Prediction Financial Data 6. Je-Gun Joung and Boung-Tak Zhang: Time Series Prediction Using Committee Machines of Evolutionary Neural Trees 7. Jung-Jip Kim and Boung-Tak Zhang: Heritability of Selection Schemes in GB-Based Time Series Analysis 8. Dong-Wook Lee and Kwee-Bo Sim: Evolving Chaotic Neural Systems for Time Series Prediction 9. Helmut A. Mayer and Roland Schwaiger: Evolutionary and Coevolutionary Approaches to Time Series Prediction Using Generalized Muti-Layer Perceptrons 10. Sathyanarayan S. Rao, Hemanth K. Birru, and Kumar H. Chellapilla: Evolving Nonlinear Time-Series Models Using Evolutionary Programming 11. Bernhard Sendhoff and Martin Kreutz: Variable Encoding of Modular Neural Networks for Time Series Prediction 12. Alaa F. Sheta: Nonlinear Channel Equalization Using Evolutionary Strategy 13. Ikuo Yoshihara, M. Numata, K. Sugawara, S. Yamada, and K. Abe: Time Series Prediction Model Building with BP-like Parameter Optimization Session: Dynamically Changing Fitness Landscapes – 1 Session Organizers: Kenneth DeJong George Mason University Fairfax, VA kdejong@cs.gmu.edu Ron Morrison George Mason University Fairfax, VA rmorrison@grci.com Ron Morrison 1. Experience With A Problem Generator For Changing Landscapes John Grefenstette 2. On Evolution Strategy Optimization In Dynamic Environments Karsten & Nicole Weicker 3. A Test Problem Generator for Non-stationary Environments Ron Morrison and Kenneth DeJong 4. The Usefulness Of Tag Bits In Changing Environments William Liles and Kenneth DeJong Session: Coevolution – 1 Session Organizer: Brian Mayoh Aarhus University Computer Science Department NyMunkegade Bldg. 504 DK-8000 Aarhus C, Denmark Phone: +45 8942 3373; Fax: +45 8942 3255 brian@daimi.aau.dk www.daimi.au.dk/~brian/cec99.html 1. "On a Coevolutionary Genetic Algorithm for Constrained Optimization" Helio Barbosa (LNCC.Petropolis,Brazil) hcbm@fluidyn.lncc.br 2. "Curiosity through cooperating/competing algorithmic predictors" Jurgen Schmidhuber(IDSIA,Lugano,Switzerland) juergen@idsia.ch 3. "Learning Nash Equilibria by Coevolving Distributed Classifier Systems" F. Seredynski (IPIPAN,Warsaw,Poland) sered@ipipan.waw.pl Cezary Z. Janikow 4. On preliminary studies of learning variable interdependencies in coevolutionary optimizers" Karsten & Nicole Weicker (Un.Tubingen,Un.Stuttgart,Germany) weicker@Informatik.Uni-Tuebingen.De 5. "Multinational evolutionary algorithms" Rasmus K. Ursem Since practical problems often are very complex with a large number of objectives it can be difficult or impossible to create an objective function expressing all the criterias of good solutions. Sometimes a simpler function can be used where local optimas could be both valid and interesting. Because evolutionary algorithms are population-based they have the best potential for finding more of the best solutions among the possible solutions. However, standard EAs often converge to one solution and leave therefore only this single option for a final human selection. So far at least two methods, sharing and tagging, have been proposed to solve the problem. This paper presents a new method for finding more quality solutions, not only global optimas but local as well. The method tries to adapt it's search strategy to the problem by taking the topology of the fitness landscape into account. The idea is to use the topology of the fitness landscape to group the individuals into sub-populations each covering a part of the fitness landscape. Session: Evolutionary Programming and Neural Networks Applied to Breast Cancer Research – 1 Session Organizers: Walker Land Binghamton University Computer Science Department wland@binghamton.edu Dr. Barbara Croft Diagnostic Imaging Program National Cancer Institute Breast Cancer is second only to lung cancer as a tumor-related cause of death in women. More that 180,000 new cases are reported annually in the US alone and, of these, 43,900 women and 290 men died last year. Furthermore, the American Cancer Society estimates that at least 25% of these deaths could be prevented if all women in the appropriate age groups were regularly screened. Although there exists reasonable agreement on the criteria for benign/malignant diagnoses using fine needle aspirate (FNA) and mammogram data, the application of these criteria are often quite subjective. Additionally, proper evaluation of FNA and mammogram sensor data is a time consuming task for the physician. Inter-and-inter-observer disagreement and/or inconsistencies in the FNA and mammogram interpretation further exacerbate the problem. Consequently, Computer Aided Diagnostics (CAD) in the form of Evolutionary Programming derived neural networks, neural network hybrids and neural networks operationg alone (utilized for pattern recognition and classification) offer significant potential to provide an accurate and early automated diagnostic technology. This automated technology may well be useful in further assisting with other problems resulting from physical fatigue, poor mammogram image quality, inconsistent FNA discriminator numerical assignments, as well as other possible sensor interpretation problems. The purpose of this proposed session is to present current and ongoing research in the CAD of breast carcinoma. Specifically, this session has the following objectives: To show the advantages of using Evolutionary Programming and Neural Networks as an aid in the breast cancer diagnostic process To demonstrate the application of EP and neural network hybrid systems in solving the InterObservability problem. To establish that CAD tools are simple and economical to implement in the clinical setting To demonstrate that CAD tools can provide the cytophathogists, radiologists and neurosurgeons with an early diagnosis of breast cancer that is accurate, consistent and efficient as well as accessible. Some practical results of CAD of breast cancer sensor data using neural networks are expected to be: Operational software which will aid the physician in making the diagnosis, quite possibly in real time, and once formulated and tested, they are always consistent, not prone to human fatigue or bias. Providing diagnostic assistance for the intra-and-inter-observability problems by ultimately minimizing the subjective component of the diagnostic process Providing an initial detection and/or classification process in the absence of a qualified physician Providing possible (and probably currently unknown) relationships between sensor environment discriminators and a correct diagnosis. This session is comprised of the following five invited papers: 1. A Status Report on Identifying Important Features for Mammogram Classification D.B. Fogel, (Natural Selection, Inc.) E.C. Wasson (Maui Memorial Hospital) E.M. Boughton, (Hawaii Industrial Laboratories) V.W. Porto and P.J. Angeline (Natural Selection, Inc.) Disagreement or inconsistencies in mammographic interpretation motivates utilizing computerized pattern recognition algorithms to aid the assessment of radiographic features. We have studied the potential for using artificial neural networks (ANNs) to analyze interpreted radiographic features from film screen mammograms. Attention was given to 216 cases (mammogram series) that presented suspicious characteristics. The domain expert (Wasson) quantified up to 12 radiographic features for each case based on guidelines from previous literature. Patient age was also included. The existence or absence of malignancy was confirmed in each case via open surgical biopsy. The ANNs were trained using evolutionary algorithms in a leave-one-out cross validation procedure. Results indicate the ability for small linear models to also provide reasonable discrimination. Sensitivity analysis also indicates the potential for understanding the networks’ response to various input features. 2. Application of Artificial Neural Networks for Diagnosis of Breast Cancer J.Y. Lo and C.E. Floyd (Digital Imaging Research Division, Dept. of Radiology, Duke Univ. Medical Center, and Dept. of Biomedical Engineering, Duke Univ.) We will present several current projects pertaining to artificial neural networks (ANN) computer models that merge radiologist-extracted findings to perform computer-aided diagnostics (CADx) of breast cancer. These projects include (1) the prediction of breast lesion malignancy using mammographic and patient history findings, (2) the further classification of malignant lesions as in situ carcinoma vs. invasive cancer, (3) the prediction of breast cancer utilizing ultrasound findings, and (4) the customization and evaluation of CADx models in a multi-institution study. Methods: These projects share in common the use of feedforward, error backpropagation ANNs. Inputs to the ANNs are medical findings such as mammographic or ultrasound lesion descriptors and patient history data. The output to the ANN is the biopsy outcome (benign vs. malignant, or in situ vs. invasive cancer) which is being predicted. All ANNs undergo supervised training using actual patient data. Performance is evaluated by ROC area, specificity for a given high sensitivity, and/or positive predictive value (PPV). Results: We have developed ANNs, which have the ability to predict the outcome of breast biopsy at a level comparable or better than expert radiologists. For example, using only 10 mammographic findings and patient age, the ANN predicted malignancy with a ROC area of 0.86 = B1 0.02, a specificity of 42% at a given sensitivity of 98%, and a 43% PPV. onclusion: These ANN decision models may assist in the management of patients with breast lesions. By providing information which was previously available only through biopsy, these ANNs may help to reduce the number of unnecessary surgical procedures and their associated cost. Contributions made by this abstract: This abstract describes the application of simple backprop ANNs to a wide range of predictive modeling tasks in the diagnosis of breast cancer. The group is one of the most authoritative in the field of computer-aided diagnosis, with a tract record that encompasses many radiological imaging modalities and engineering disciplines. 3. Optimizing the Effective Number of Parameters in Neural Network Ensembles: Application to Breast Cancer Diagnosis Y. Lin and X. Yao, ( Dept of Computer Science, Australian Defense Force Academy, Canberra) The idea of negative correlation learning is to encourage different individual networks in an ensemble to learn different parts or aspects of the training data so that the ensemble can learn the whole training data better. This paper develops a technique of optimizing the effective number of parameters in a neural network ensemble by negative correlation learning. The technique has been applied to the problem of breast cancer diagnosis. 4. Artificial Neural Networks in Breast Cancer Diagnosis: Merging of Computer-Extracted Features from Breast Images Maryellen L. Giger Kurt Rossmann Laboratories for Radiologic Image Research The University of Chicago Department of Radiology MC2026 5841 S. Maryland Ave. Chicago, IL 60637 m-giger@uchicago.edu Phone: 773-702-6778 Fax: 773-702-0371 Computer-aided diagnosis (CAD) can be defined as a diagnosis made by a radiologist who takes into consideration the results of a computerized analysis of radiographic images and uses them as a "second opinion" in detecting lesions, assessing disease, and/or in making diagnostic decisions. The final decision regarding diagnosis and patient management would be made by the radiologist. CAD is analogous to a spell checker. In mammography, computerized methods for the detection and characterization of lesions are being developed to aid in the early detection of breast cancer. Since mammography is becoming a high volume x-ray procedure routinely interpreted by radiologists and since radiologists do not detect all cancers that are visible on images in retrospect, it is expected that the efficiency and effectiveness of screening could be increased by CAD. In addition, computerized methods are being developed to aid in the characterization of lesions in order to potentially reduce the number of benign cases sent to biopsy. Once a lesion is detected, the radiologist's decision concerns patient management -- that is, return to routine screening, perform follow-up mammograms, or send to biopsy? This differs from a purely benign versus malignant determination. Many breast cancers are detected and referred for surgical biopsy on the basis of a radiographically detected mass lesion or cluster of microcalcifications. Although general rules for the differentiation between benign and malignant mammographically identified breast lesions exist, considerable misclassification of lesions can occur. On average, less than 30% of masses referred for surgical breast biopsy are actually malignant. We have been developing computerized analysis schemes to aid in distinguishing between malignant and benign lesions. Such methods can use features extracted either by computer or by radiologists. These features are then merged by classifiers, such as linear discriminant functions or artificial neural networks, to yield estimate of the likelihood of malignancy. These computerized methods for the characterization of breast lesions are being developed for mammography, sonography, and magnetic resonance imaging. 5. Investigation of and Preliminary Results for the Solution of the Inter-Observability Problem using Fine Needle Aspirate (FNA) Data W. H. Land, JR and L. Loren (Computer Science Dept., Binghamton Univ. and T. Masters (TMAIC, Vestal, NY) This paper provides a preliminary evaluation of the accuracy of Computer Aided Diagnostics (CAD) in addressing the inconsistencies of Inter-Observability scoring. The Inter-Observability problem generally relates to different cytopathologists and radiologists, etc. at seperate locations scoring the same type of samples differently using the same methodologies and environment discriminates. Two different approaches are currently being investigated: (1) a recently developed Evolutionary Programming (EP) / Probabilistic Neural Network (PNN) hybrid, and (2) a classification model based on the thresholding of means of all predictors called the “mean of predictors” model. Method: Two distinctly different FNA data sets were used. The first was the data set collected at the Univ. of Wisconsin (Wolberg data set) while the other was a completely independent one defined and processed at the Breast Care Center, Syracuse University (Syracuse dataset). Results of several experiments performed using the EP/PNN hybrid (which provided several unique network configurations) are first summarized. The EP/PNN hybrid was trained on the Wolberg dataset and the resultant models evaluated on the Syracuse dataset. For comparative purposes, these same hybrid architectures which were trained on the Wolberg set were also evaluated on the Wolberg validation set. The “mean of predictors” method first trained the thresholds using the original Wolberg training set. This model was then tested on the Wolberg test and validation sets, and on the Syracuse set. All three Wolberg datasets (train, test, validate) were then used to train the threshold, and this model was applied to the Syracuse data Results: Initial results using the EP/PNN hybrid showed a 85.2% correct classification accuracy with a 2.6% Type II (classifying malignant as benign) error averaged over five experiments when trained on the Wolberg data set and validated on the Syracuse data set. Training and validating on the Wolberg data set resulted in a 97% correct classification accuracy and a < 0.2% Type II error. These results are preliminary in that no attempt has been made to optimize the threshold setting. The paper will include several additional EP/PNN hybrid experimental results as well as optimum threshold settings and an ROC analysis. The “mean of predictors method” analysis produced the following preliminary results. Training the thresholds on the first 349 Wolberg samples resulted in a CAD model which provided: (1) a 98.8% classification accuracy and a 0% Type II error, (2) a 96% classification accuracy with a 1.7% Type II error when using the Wolberg test and validation sets respectively which confirms the EP/PNN preliminary results. Using the Syracuse validation set yielded a 96% classification accuracy and a 1% Type II error which is improved performance when compared with the EP/PNN results. Training the “mean of predictors” model on all 699 Wolberg samples and validating on the Syracuse dataset resulted in a 86% classification accuracy and a 1% Type II error. Again, these results match well with the EP/PNN results. We again emphasize these results are preliminary but very promising. Conclusions: Preliminary results using both the newly developed EP/PNN hybrid and the “mean of predictors” methods are very encouraging. We believe that both of these CAD tools will, with additional research and development effort, be useful additions to our growing group of CAD tools being developed at Binghamton University. Session: Engineering Design – 2 Sessions Organizers: Ian Parmee Plymouth Engineering Design Centre Reader in Evolutionary/Adaptive Computing in Design and Manufacture School of Computing University of Plymouth Drakes Circus Plymouth PL4 8AA Devon, UK Phone: 01752 233509; Fax: 01752 233529 I.parmee@plymouth.ac.uk Prabhat Hajela RPI hajela@rpi.edu Mark Jakiela Hunter Professor of Mechanical Design Washington University in St. Louis mjj@mecf.wustl.edu 1. Marc Schoenauear Ecole Polytechnique, Paris 2. Eric Goodman Michigan State 3. Ian Parmee EDC, Plymouth 4. Chris Bonham EDC, Plymouth 6. communications 7. antenna design 8. building structures 9. 10. Session: Data Mining – 2 Sessions Organizer: Jan Zytkow zytkow@uncc.edu 1. Clustering TV Prefererences Using Genetic Algorithms Teresa Goncalves & Fernando Moura-Pires tcg@di.fct.unl.pt 2. A Comparison of Two Feature Selection Algorithms Kan Chen & Huan Liu liuh@comp.nus.edu.sg 3. A Survey of Genetic Feature Selection in Mining Issues Maria Jose Martin-Bautista and Maria-Amparo Vila mbautis@decsai.ugr.es 4. Discovering interesting prediction rules with genetic algorithms Edgar Noda, Alex Freitas & Heitor Lopes alex@dainf.cefetpr.br 5. Learning Classifications using Evolutionary Programming Michael Cavaretta & Kumar Chellapilla mcavaret@ford.com 6. Evolution of Logic Programs: Part-of-Speech Tagging Philip G. K. Reiser & Patricia Riddle philip@cs.auckland.ac.nz 7. GA-based Hierarchical Rule Learning Jukka Hekanaho hekanaho@ra.abo.fi Session: Scheduling – 2 Sessions Organizers: Jeff Herrmann University of Maryland jwh2@glue.umd.edu Edmund Burke University of Nottingham ekb@cs.nott.ac.uk Bryan Norman University of Pittsburgh banorman@engrng.pitt.edu 1. Jeff Herrmann 2. Bryan Norman 3. Edmund Burke 4. Jeff Joines 5. X. Q. Cai 6. D. Montana Session: Teaching of Evolutionary Computation – 1 Session Organizer: Xin Yao Department of Computer Science Australian Defense Force Academy Canberra xin@cs.adfa.oz.au 1. Sung-Bae Cho (Korea) 2. Riccardo Poli (UK) 3. Alice E. Smith (USA) 4. Xin Yao (Australia) 5. Zbigniew Michalewicz (USA) Session: DNA Computing – 2 Sessions Organizer: Jan Mulawka Institute of Electronics Fundamentals Warsaw University of Technology ul. Nowowiejska 15/19 00-665 Warsaw, Poland Phone: (+48 22) 660 53 19; Fax: (+48 22) 825 23 00 jml@ipe.pw.edu.pl http://www.ipe.pw.edu.pl/~gair 1. Towards a System for Simulating DNA Computing Using Secondary Structure Akio Nishikawa, Masami Hagiya University of Tokyo, Japan nisikawa@is.s.u-tokyo.ac.jp Whiplash PCR is a useful method for analyzing DNA. For example, state transitions can be implemented by this method. In normal PCR, extension is guided by the annealed complementary DNA sequence. Whiplash PCR is a modification of normal PCR in which the 3'-end of the target single-stranded DNA molecule is extended by polymerase when it anneals to a complementary sequence in the target DNA molecule, so that the secondary structure of the target single-stranded DNA forms the guiding sequence. When the annealed sequences are extended by PCR, the guiding sequence and the composition of the PCR reaction buffer control termination. If the PCR buffer lacks T and the guiding sequence contains an AAA sequence, the PCR extension will stop at the sequence AAA. In Whiplash PCR, like normal PCR, the molecule is subsequently denatured by high temperature, the guiding sequence re-anneals when the temperature is lowered for the next extension step and the cycle repeats. Whiplash PCR is a very powerful technique for solving certain types of problems, but the feasibility of using it in a specific instance should be carefully considered. The target molecule must form a secondary structure by annealing to itself, and it must be capable of melting and reforming a similar secondary structure. To implement this, the sequences must be carefully designed. The simulation system we are constructing checks whether the sequences can form such secondary structures by examining the nucleotide sequence. It also simulates sequence extension by ligation, PCR and whiplash PCR, mishybridization, affinity separation, and restriction enzyme digests. By combining all these types of reaction simulations, it can simulate a series of DNA computing processes, which will aid the designers of DNA computing reactions. We are now constructing such simulation software based on sequence comparison, and will report our current stage of development. In addition to developing the simulation methods based on sequence comparison, we have investigated possible enhancements of our system. Simply using a method based on sequence comparison to examine the feasibility of DNA computing using secondary structures is inadequate. We plan to enhance our system in two ways. First, it will check the conditions for each reaction step with reaction parameters such as the PH, temperature, and makeup of the PCR reaction buffer. Second, it will calculate and examine the physico-chemical parameters affecting the secondary structure necessary for whiplash PCR. In other words, the sequences can form such secondary structures by examining the nucleotide sequence. It also simulates sequence extension by ligation, PCR and whiplash PCR, mishybridization, affinity separation, and restriction enzyme digests. By combining all these types of reaction simulations, it can simulate a series of DNA computing processes, which will aid the designers of DNA computing reactions. We are now constructing such simulation software based on sequence comparison, and will report our current stage of development. In addition to developing the simulation methods based on sequence comparison, we have investigated possible enhancements of our system. Simply using a method based on sequence comparison to examine the feasibility of DNA computing using secondary structures is inadequate. We plan to enhance our system in two ways. First, it will check the conditions for each reaction step with reaction parameters such as the PH, temperature, and makeup of the PCR reaction buffer. Second, it will calculate and examine the physico-chemical parameters affecting the secondary structure necessary for whiplash PCR. In other words, it will check the feasibility from a physico-chemical perspective. We would like to discuss these enhancements and the feasibility of our simulation system. Furthermore, if possible, we would like to compare the results of our simulation system with in vitro experiments. 2. PNA-enhanced DNA Computing J. Miro-Julia, F. Rossello UIB University, Spain joe@ipc4.uib.es Since Adleman's seminal paper, DNA computing is emerging as a very promising alternative to electronic computing. It s massive parallelism, its low energy needs, even its possible ability of breaking the NP barrier make its study irresistible. But for all its promise DNA computing has few results to show. This is in because there are many biochemical problems in handling DNA that are still to be solved. Peptyde Nucleic Acid (PNA) is a new class of informational biomolecule, a nucleic acid analogue with a backbone consisting of a peptide-like chain formed of glycine units to which the usual nucleobases are attached. DNA molecules have some properties, relevant to the area of computation with biomolecules, unique among nucleic acids: among others, they hybridize to both complementary DNA and RNA with higher affinity that DNA itself. They can be used to enhance PCR amplification, and they can be used to restrict the action of restriction enzymes on DNA strands. The goal of this paper is to introduce PNA in the area of computation with biomolecules, and to discuss its possible role in overcoming some of the drawbacks that appear with DNA. 3. Efficient DNA Computation of Spanning Trees Martyn Amos, Shinichiro Yoshii, Paul E. Dunne and Alan Gibbons University of Liverpool, UK martyn@csc.liv.ac.uk In this paper we demonstrate the translation of a high-level algorithm down to the level of molecular operations on DNA. For DNA computation to be a viable and competitive paradigm, we need algorithms that require viable resources (time and volume). We describe a translation of a parallel algorithm for the computation of spanning trees on graphs that is resource-efficient. 4. The Analysis of a Simple Programmed Mutagenesis System. Julia Khodor and David K. Gifford Laboratory for Computer Science, MIT, USA Jkhodor@MIT.EDU We present the experimental results of the advanced cycles of string rewrite system based on programmed mutagenesis, a technique for rewriting DNA strands according to programmed rules. We have previously shown that formation of the second-cycle product depends on successful completion of the first cycle, and demonstrated that two oligonucleotides annealing to the template next to each other can ligate and extend to form the correct product. We now report our findings on the behavior of the advanced cycles of the system. We discuss several factors influencing the behavior of the system, such as the choice of enzymes, temperatures, and concentrations. The efficiency of the system and the potential significance of the results to the field of DNA-computing are also discussed. 5. Executing Parallel Logical Operations with DNA Mitsunori Ogihara and Animesh Ray University of Rochester, USA ogihara@cs.rochester.edu DNA computation investigates the potential of DNA as a massively parallel computing device. Research is focused on designing parallel computation models executable by DNA-based chemical processes and on developing algorithms in the models. In 1994 Leonard Adleman initiated this area of research by presenting a DNA-based method for solving the Hamilton Path Problem. That contribution raised the hope that parallel computation by DNA could be used to tackle NP-complete problems which are thought of as intractable. The current realization, however, is that NP-complete problems may not be best suited for DNA-based (more generally, molecule-based) computing. A better subject for DNA computing could be large-scale simulation of parallel computation models. Several proposals have been made in this direction. We overview those methods, discuss technical and theoretical issues involved, and present some possible applications of those methods. 6. Aspects of Evolutionary DNA Computing Thomas Baeck , Joost Kok, and Grzegorz Rozenberg Leiden University, The Netherlandes baeck@icd.de Evolutionary Computation focuses on probabilistic search and optimization methods gleaned from the model of organic evolution. Genetic algorithms, evolution strategies and evolutionary programming are three independently developed representatives of this class of algorithms, with genetic programming and classifier systems as additional paradigms in the field. After giving a general introduction to evolutionary algorithms and demonstrating their practical usefulness as heuristics for finding good solutions in combinatorial and continuous problem domains with a few application examples, the presentation emphasizes on certain features of genetic algorithms and evolution strategies: Namely, the mutation and recombination operators from genetic algorithms and the selection operator from evolution strategies are discussed in more detail. Furthermore, some theoretical results concerning the convergence velocity of certain variants of genetic algorithms are presented, and in particular the question for optimal mutation rates in genetic algorithms is discussed. Based on this detailed background information about evolutionary algorithms, it is then outlined how these algorithms relate to DNA based computing. 7. The Inference via DNA Computing J. Mulawka, P. Wasiewicz, and A. Plucienniczak Warsaw University of Technology, Poland jml@ipe.pw.edu.pl Most of research on DNA computing concerns solving NP-complete problems, programming in logic as well as purely mathematical consideration of splicing theory. There is no doubt that these works have given new impetus to find another areas for DNA computing. In proposed paper we show that selfassembly of DNA strands may be applied to implement the inference process. The ability of such an application was provided for the first time by J.J. Mulawka et al. At the International Conference on Evolutionary Computation in Anchorage, 1998. In this paper we would like to report another achievements in this field. The inference process can be implemented either by backward or forward chaining. We have developed new methods of inference based on another concept of genetic engineering. The primary objective of our paper is to describe these methods and procedures. After short introduction to the subject an overview of the problem will be provided. It will be shown how knowledge can be structured, and stored by means of DNA strands. Next, we describe an implementation of DNA inference engine. Such system can store knowledge for a narrowly defined subject area and solve problems by making logical deductions. The inference mechanism performs these tasks by manipulating on DNA strands. It provides the problem-solving methods by which the rules are processed. Our approach uses standard operations of genetic engineering. To check correctness of our method a number of laboratory tests have been carried out. The results of these experiments as well as concluding remarks will be provided in final version of the paper. 8. Byoun-Tak Zhang from Korea 9. H. Rubin rubinh@mail.med.upenn.edu 10. T. Head tom@math.binghamton.edu Session: Ant Colony Methods – 1 Session Organizer: Marco Dorigo Chercheur Qualifie' du FNRS IRIDIA CP 194/6 Universite' Libre de Bruxelles Avenue Franklin Roosevelt 50 1050 Bruxelles Belgium Phone: +32-2-6503169; Fax: +32-2-6502715 mdorigo@ulb.ac.be http://iridia.ulb.ac.be/dorigo/dorigo.html 1. An Ant Colony Optimization Approach for the Single Machine Total Tardiness Problem Bauer A., Bullnheimer B., Hartl R.F., Strauss C. Machine Scheduling is a central task in production planning. In general it consists of the problem of scheduling job operations on a given number of available machines. In this paper we consider a machine scheduling problem with one machine, the Single Machine Total Tardiness Problem. As this problem is NP-hard, we apply the ant colony optimization metaphor, a recently developed meta-heuristic that has proven its potential for various other combinatorial optimization problems, and present computational results. Keywords Ant Colony Optimization, Machine Scheduling, Meta-Heuristics, Single Machine Total Tardiness Machine Scheduling using ACO 2. A Cooperative Ant Algorithm for Dynamic Routing and Load Balancing Martin Heusse and Dominique Snyers ENST de Bretagne, Brest, France snyers@ieee.org This talk presents a new family of completely distributed algorithms for routing in dynamic communication networks inspired by insect collective behaviors. These algorithms are compared with others on simulated networks under various traffic loads. Early results using the realistic Opnet simulator will also be presented. The connection between these ``ant algorithms'' and dynamic programming is discussed. These new ``ant algorithms'' can be described as an online asynchronous version of dynamic programming combined with reinforcement learning. Estimates of the current load and link costs are measured by sending routing agents (or artificial ants) in the network that mix with the regular information packets and keep track of the costs encountered during their journey. The routing tables are then regularly updated based on that information without any central control nor complete knowledge of the network topology. Two new algorithms are proposed here. The first one is based on round trip routing agents that update the routing tables by backtracking their way after having reached the destination. The second one relies on forward agents that update the routing tables directly as they move toward their destination. An efficient co-operative scheme is proposed to deal with asymmetric network connections. 3. A New Version of Ant System for Subset Problems Guillermo Leguizamon Interest Group on Computer Systems Universidad Nacional de San Luis Argentina legui@unsl.edu.ar Zbigniew Michalewicz Department of Computer Science University of North Carolina at Charlotte USA zbyszek@uncc.edu Ant Colony Optimization (ACO) is a relatively new meta-heuristic for hard combinatorial optimization problems. This meta-heuristic belongs to the class of heuristics derived from nature, which includes Evolutionary Algorithms, Neural Networks, Simulated Annealing, Tabu Search. An ACO algorithm is based on the result of low-level interaction among many cooperating simple agents that are not explicitly aware of their cooperative behavior. Each simple agent is called ant and the ACO algorithm (a distributed algorithm) is based on a set of ants working independently and cooperating sporadically in a common problem solving activity. Since the design of Ant System, the first example of ACO algorithm, plenty of work has been done in this area with applications to problems such as the Traveling Salesman Problem, the Bin Packing Problem, and the Quadratic Assignment Problem. In this paper we present the original Ant System as well as a new version applied to three subset problems: the Multiple Knapsack Problem (MKP), the Set Covering Problem (SCP), and the Maximum Independent Set Problem (MISP). The results show the potential power of the ACO approach for solving subset problems. 4. Hamiltonian(t) – An Ant-Inspired Heuristic for Recognizing Hamiltonian Graphs Israel A. Wagner (1,2) Alfred M. Bruckstein (2) (1) IBM Haifa Research Lab, Matam, Haifa 31905, Israel (2) Department of Computer Science, Technion City, Haifa 32000, Israel israelw@vnet.ibm.com, freddy@cs.technion.ac.il Given a graph G(V,E), we consider the problem of deciding whether G is Hamiltonian, i.e., whether or not there is a simple cycle in E spanning all vertices in V. This problem is known to be NP-complete, hence cannot be solved in time polynomial in |V| unless P=NP. The problem is a special case of the Travelling Salesperson Problem (TSP), that was extensively studied in the literature, and has recently been attacked by various ant-colony methods. We address the Hamiltonian cycle problem using a new antinspired approach, based on repeated covering of the graph. Our method is based on a process in which an ant traverses the graph by moving from vertex to vertex along the edges, occasionally leaving traces in the vertices, and deciding on the next step according to the level of traces in the surrounding neighborhood. We show that Hamiltonian cycles are limit cycles of the process, and investigate the average time needed by our ant process to recognize a Hamiltonian graph, on the basis of simulations made over large samples of random graphs with varying structure and density. 5. Adapted versions of the ABC algorithm in network control L.J.M. Rothkrantz, J. Wojdel, A. Wojdel roth@kgs.twi.tudelft.nl University of Delft, The Netherlands Recently agents algorithms based on the natural behavior of ants were successfully applied to route data in telecommunication networks. Mobile agents created the routing tables in the simulated network with behaviors modeled on the trail-laying abilities of agents. This paper describes some adapted versions of the Ant Based Control algorithm. To test the algorithms in different network topologies, a simulation environment was designed and implemented. The simulation software, algorithms and results of experiments will be presented in this paper. Session: Evolutionary Computation and Biological Modeling – 2 Sessions Organizers: Kumar Chellapilla H. Dept. of ECE, Univ. of California, San Diego 9500 Gilman Drive La Jolla, CA 92093-4007 Ph: (619) 534-5935; Fax: (619) 534-1004 kchellap@ece.ucsd.edu http://vision.ucsd.edu/~kchellap Gary Fogel Natural Selection Inc., La Jolla, CA 92037 1. Computer Experiments on the Development of Niche Specialization in an Artificial Ecosystem Jon Brewster and Michael Conrad Dept. of Computer Science Wayne State University Detroit, MI 48202 Evolve IV is the most recent of the EVOLVE series of evolutionary ecosystem models. The key new feature is all interactions among organisms are mediated by metabolic transformations. The model is thus well suited to the study of niche proliferation since evolutionary pressures lead to specialization and mutually stimulatory relationships in a natural way. 2. Multiple RNA Sequence Alignment Using Evolutionary Programming Kumar Chellapilla and Gary Fogel Multiple sequence alignment and comparison are popularly used techniques for the identification of common structure among ordered strings of nucleotides (as is the case with DNA or RNA) or amino acids (as is the case with proteins). Current multiple sequence alignment algorithms are characterized by great computational complexity. The focus of this paper is to use evolutionary programming as the basis for developing an efficient multiple sequence alignment algorithm for RNA sequences. An evolutionary programming (EP) based multiple sequence alignment algorithm is presented. Variants on the basic algorithm are also presented and their trade-offs are discussed. The appropriate weights associated with matches, mismatches and gaps are critical for the success of any algorithm. Simulation results on the canonical version indicate that the proposed EP method is not only viable but offers a much more robust alternative to conventional methods as the differences in the structure increase. 3. When Metaphors Collide: Biological Underpinnings To Genetic Programming Theory Jason Daida University of Michigan, Artificial Intelligence Lab & Space Physics Research Lab, 2455 Hayward Ave, Ann Arbor, MI 48109-2143 USA, (734) 647-4581 (wk), (734) 764-5137 (fax), daida@eecs.umich.edu (email), http://www.sprl.umich.edu/acers/ (www) Current theoretical research in genetic programming (GP) owes part of its heritage to the use of biological metaphor. Indeed, one could go even further by stating that biological metaphors have significantly shaped the direction of theoretical development in GP. Whether in the particulars of what in GP maps to genotype and to phenotype, or in the wholes of what in GP maps to a set of dynamics that is reflective of some biological phenomena, the use of biology in framing GP theory has been pervasive. However, current research also shows that descriptions of GP dynamics can deviate significantly from what one would expect in biology. Therefore, our investigations have lead us to rethink how the biology maps to processes and artifacts in GP. Consequently, this paper discusses how the use of biological metaphor can over constrain critical portions in the development of GP theory. 4. Simulated Sequencing by Hybridization Using Evolutionary Programming Gary Fogel and Kumar Chellapilla Sequencing of DNA is among the most important tasks in molecular biology. DNA chips are considered to be a more rapid alternative to more common gel-based methods for sequencing. Previously, we demonstrated the reconstruction of DNA sequence information from a simulated DNA chip using evolutionary programming. The research presented here extends this work by relaxing several assumptions required in our initial investigation. We also examine the relationship between base composition of the target sequence and the useful set of probes required to decipher the target on a DNA chip. Comments regarding the nature of the optimal ratio for the target and probe lengths are offered. Our results go further to suggest that evolutionary computation is well suited for the sequence reconstruction problem. 5. A Survey of Recent Work on Evolutionary Approaches to the Protein Folding Problem. Garrison Greenwood* , Byungkook Lee**, Jae-Min Shin**, and Gary Fogel*** *Dept. of Electrical & Computer Engineering, Western Michigan University, Kalamazoo, MI 49008 ** Laboratory of Molecular Biology, National Cancer Institute, Bethesda, MD 20892 *** Natural Selection Inc., La Jolla, CA 92037 A problem of immense importance in computational biology is the determination of the function conformations of protein molecules. With the advent of faster computers, it is now possible to use heuristic algorithms to search conformation space for protein structures that have minimal free-energy. Surveys work done in the last five years using evolutionary search algorithms to find low energy protein conformations. In particular, a detailed description is included of some work recently started at the National Cancer Institute, which uses evolution strategies. 6. Creation Of A Biomimetic Dolphin Hearing Model Through The Use Of Evolutionary Computation D. S. Houser1, D. A. Helweg, and P. W. B. Moore 1SPAWARSYSCEN-San Diego, Code D351, 49620 Beluga Road, San Diego, CA 92152-5435 Niche exploitation by an organism cumulatively results from its existing adaptations and phylogenetic history. The biological sonar of dolphins is an adaptation for object (e.g. prey or obstacle) detection and classification in visually limited environments. The unparalleled echo discrimination capability of the dolphin provides an excellent model for investigating similar synthetic systems. Current biomimetic modeling of dolphin echo discrimination emphasizes the mechanical and neurological filtering of the peripheral auditory system prior to central nervous system processing of echoes. Psychoacoustic, anatomical, and neurophysiological data collected from the bottlenose dolphin (Tursiops truncatus) indicate the structure of some auditory tuning curves. However, an optimal filter set has yet to be developed that demonstrates comparable frequency-dependent sensitivity. Evolutionary computation techniques have been employed to optimize the sensitivity of filters to that observed in the bottlenose dolphin by seeding the population with known filter parameters and evolving the number, frequency distribution, and shape of individual filters. Comparisons of evolved and known biological tuning curves will be discussed. 7. Evolutionary Computation Enhancement of Olfactory System Model Mary Lou Padgett and Gerry V. Dozier, Auburn University Recent electron microscopy work on the anatomy of the olfactory system in the rat has suggested a structural basis for grouping input stimuli before processing to classify odors. In the construction of a simulated nose, the appropriate number of inputs per group is a design parameter which can be finetuned using evolutionary computation. Previous results indicate that improvements to classification accuracy can be made by grouping inputs. On the other hand, the cost of such grouping can potentially increase the number of samples required for each "sniff". This increase can be expensive in terms of hardware and processing time. This paper suggests a methodology for selecting a size range based on improvement in accuracy and cost of grouping inputs. Session: Fitness Distributions: Tools for Designing Intelligent Operators and Efficient Evolutionary Computations – 1 Session Organizer: Kumar Chellapilla Dept. of ECE, Univ. of California, San Diego 9500 Gilman Drive La Jolla, CA 92093-4007 Ph: (619) 534-5935; Fax: (619) 534-1004 kchellap@ece.ucsd.edu http://vision.ucsd.edu/~kchellap 1. Fitness Distributions in Evolutionary Computation: Analysis of Local Extrema in the Continuous Domain Kumar Chellapilla and David B. Fogel The design of evolutionary computations based on schema processing, minimizing expected losses, and emphasizing certain genetic operators has failed to provide robust optimization performance. Recently, fitness distribution analysis have been proposed as an alternative tool for exploring operator behavior and designing efficient evolutionary computations. For example, the step size of a single parent variation operator determines the corresponding probability of finding better solutions and the expected improvement that will be obtained. This paper analyses the utility of Gaussian, Cauchy, and Mean mutation operators when a parent is located on a local extrema of a continuous objective function that is to be optimized. 2. Towards Evolution of Modular Finite State Machines using Fitness Distributions David Czarnecki For a given representations in an evolutionary computation, there are a number of variation operators that can be applied to existing solutions to create new solutions. These variation operators can be classified into two broad categories, exploratory and exploitative operators. Exploratory operators allow for the traversal of a given search space. Exploitative operators may induce behavior that uses the current location in the fitness landscape to move a solution towards a more optimal region in the neighboring search space. Fitness Distributions is a recent technique to assess the viability and quality of such variation operators. This technique is applied to the evolution of modular and non-modular finite state machines. Experiments are conducted on a number of tracking and control problems. Discussion is directed towards assessing the overall effectiveness of operators for such machines. 3. Using Fitness Distributions to Improve the Evolution of Learning Structures Christian Igel, Martin Kreutz, and Peter Stagge The analysis of features of the fitness distribution (FD) [3,4] is used to improve the performance of three different structure optimization algorithms by guiding the choice and design of the used variation operators. All three algorithms employ hybrid approaches where an evolutionary algorithm (EA) is used for structure optimization in conjunction with gradient based learning strategies for parameter adaptation. 4. On Functions With A Given Fitness--Distance Relation Leila Kallel, Bart Naudts and Marc Schoenauer Recent work stresses the limitations of fitness distance correlation (FDC) as an indicator of landscape difficulty for genetic algorithms (GAs). Realizing that the fitness distance correlation (FDC) value cannot be reliably related to landscape difficulty, this paper investigates whether an interpretation of the correlation plot can yield reliable information about the behavior of the GA. Our approach is as follows: A generic method for constructing fitness functions which share the same fitness versus distance-tooptimum relation (FD relation) is presented. Special attention is given to FD relations which show no local optimum in the correlation plot, as is the case for the relation induced by Horn's longpath. A tentative taxonomy is proposed for he different types of GA behavior found within a class of fitness functions with a common correlation plot. Finally, the behavior of the GA is shown to be very sensitive to small modifications of the fitness--distance relation. 5. Empirical Study Of Two Classes Of Bit Mutation Operators In Evolutionary Computation Hemanth Birru Bit mutation operators are widely used in evolutionary computations (EC) that adopt a binary representation. Most commonly, one or more randomly selected bits are flipped with some probability. The success of such a variation operator invariably depends on the location and number of bits being varied in the chromosome. Given an objective function and a candidate parent, bit mutations in some locations will provide an improvement in fitness whereas no improvement will result when mutations are applied to other locations. Two classes of bit mutation operators are defined and the relationship between the probability of improvement in fitness and the expected improvement obtained is studied. Such a study would help in designing better mutation operators to obtain faster convergence in EC methods using a binary representation. Session: Knowledge - Based Approaches to Evolutionary Computation Using Cultural Algorithms, Case - Injected Genetic Algorithms, and Related Techniques for Real World Engineering Applications – 2 Sessions Organizer: Robert G. Reynolds Department of Computer Science 431 State Hall Wayne State University Detroit, MI 48202 reynolds@CS.Wayne.EDU 1. Using Cultural Algorithms to Improve Performance in Semantic Networks Nestor Rychtyckyj Manufacturing and Engineering Development AI and Expert Systems Group Ford Motor Company Detroit Evolutionary computation has been successfully applied in a variety of problem domains and applications. In this paper we describe the use of a specific form of evolutionary computation known as cultural algorithms to improve the efficiency of the subsumption algorithm in semantic networks. Subsumption is the process that determines if one node in the network is a child of another node. As such, it is utilized as part of the node classification algorithm within semantic network-based applications. One method of improving subsumption efficiency is to reduce the number of attributes that need to be compared for every node without impacting the results. We suggest that a cultural algorithm approach can be used to identify these defining attributes that are most significant for node retrieval. These results can then be utilized within an existing vehicle assembly process planning application that utilizes a semantic network based knowledge base to improve the performance and reduce complexity of the network. 2. Performing Fault detection within a Complex Engineering Environment through the utilization of Chained Cultural Algorithms. David Ostrowski Science Laboratories Ford Motor Company Detroit Software testing is extremely difficult in the context of engineering applications. Biezer made a distinction between a functional approach to testing software as opposed to a structural approach. The functional approach is considered Black Box testing and the structural White Box testing. We feel that these methods are difficult to apply since they represent deterministic approaches to complex problems which have been known to be evaluated to NP-hard. Since constantly changing environments are heuristical in nature, we suggest that the application of the White and Black Box testing methods within a Cultural Algorithm environment will present a successful approach to fault detection. In order to utilize both a functional and structural approach, two Cultural Algorithms will be applied within this tool. The first algorithm will utilize the Black Box testing by establishing an equivalence class of data through the means of maintaining a belief space over a number of populations. the equivalence class will then be passed over to the second Cultural Algorithm that will apply program slicing techniques to determine program slices from the data established within the first algorithm. The goal will be to pinpoint faults within the program design. Through the searching of the program code this approach can be considered behavioral mining of a program. 3. Learning to Assess the Quality of Genetic Programs Using Cultural Algorithms George Cowan Park Davis Laboratories Michigan The total program length of Genetic Programming (GP) solution programs can be partitioned into effective program length and several types of excess code length for which, following Angeline, we use the term "bloat". Local Bloat is the excess code length attributable to local introns, sections of code in the solution program that do not affect the results for any training input. If the training data is highly representative of the problem domain, then it is likely that local intron removal does not affect the results for any possible input. Considering code after the removal of introns, we define Global Bloat to be the excess length of code which can be represented more succinctly while using the same operators that were allowed during evolution. Finally we distinguish Representational Bloat, the excess length, after the removal of Global Bloat, of code which can be represented more succinctly using operators from an expanded set. The remaining code is the Effective Program. We explore the relationships found between these types of code length and three GP process modifications purported to reduce bloat. 4. A Cultural Algorithm Application Robert G. Reynolds 5. Solving High Dimensional Real-valued Function Optimization Problems With Cultural Algorithms Chan – Jin Chung Lawrence Technological University Department of Math and Computer Science Southfield, Michigan 6. Learning to Identify Objects with Case-Injected Genetic Algorithms Sushil J. Louis Department of Computer Science University of Nevada Reno Reno, Nevada 89557-0148 Session: Particle Swarm Optimization – 1 Session Organizer: Russ Eberhart Director of the Advanced Vehicle Technology Institute Purdue School of Engineering and Technology at IUPUI 799 West Michigan Street Indianapolis, IN 46202, USA Phone: (317) 278-0255; Fax: (317) 274-4567 eberhart@engr.iupui.edu 1. Russ Eberhart 2. Jim Kennedy 3. Yuhui Shi 4. Pete Angeline Session: Multi - Objective Optimization With Evolutionary Algorithms – 2 Sessions Organizer: El - Ghazali Talbi University of Lille Laboratoire d'Informatique Fondamentale de Lille Bat. M3 59655 Villeneuve d'Aseq Cedex France Phone: 03 20 43 45 13; Fax: 03 20 43 65 66 talbi@lifl.fr http://www.lifl.fr/~talbi/cec99.html 1. An Updated Survey Of Evolutionary Multiobjective Optimization Techniques: State Of The Art And Future Trends Carlos A. Coello Coello Laboratorio Nacional de Informatica Avanzada (LANIA) P.O. Box 60326-394 Houston, Texas 77205 USA e-mail: ccoello@xalapa.lania.mx After using evolutionary techniques for single-objective optimization during more than two decades, the incorporation of more than one objective in the fitness function has finally become a popular area of research. As a consequence, many new evolutionary-based approaches and variations of existing techniques have been recently published in the technical literature. The purpose of this paper is to provide a critical review of the existing approaches, their limitations, advantages, and degree of applicability. Finally, the future trends in this discipline and some of the most promising areas of future research will be described. 2. Multicriteria Optimization and Decision Engineering of an Extrusion Process Aided by a Diploid Genetic Algorithm S. Massbeuf, C. Fonteix (1), L.N. Kiss (2), I. Marc, F. Pla and K. Zaras (1) Laboratoire des Sciences du Genie Chimique - UPR CNRS 6811 ENSAIA, 2 avenue de la foret de Haye, BP 172, 54505 Vandoeuvre-les-Nancy Cedex, France (2) Universite Laval - Faculte des Sciences de l'Administration Bureau 3202A/PAP, Sainte Foy G1K 7P4, Quebec, Canada 03 83 59 58 42, fax 03 83 59 58 04, perso 03 83 96 37 04 In many, if not most, optimization problems, industrials are often confronted with multiobjective decision problems. For example, in manufacturing processes, it can be necessary to optimize several criteria to take into account all the market constraints. So, the aim is to choose the best tradeoffs among all the defined and conflicting objectives. In multicriteria optimization, after the decision maker has chosen all his objectives, he has to determine the multicriteria optimal zone by using the concept of domination criterion called Pareto domination. Two points, in the research domain, are compared. If one is better for all attributes, it is a non dominated solution. All the non dominated points form the Pareto's region. Two multiobjective optimization algorithms are used to obtain the Pareto's zone. These methods are based on a diploid genetic algorithm and are compared on an industrial application : food's granulation. Some constraints are applicated to reduce the zone if some points are not interesting for the maker. In the remaining zone, the decision maker has to choose the best solution after he has made a ranking with all potential solutions. 3. Distributed Multi-Objective Optimisation for Complex Aerospace Engineering problems using Genetic Algorithms and Game Theory B. Mantel (Dassault-Aviation), J. Periaux (Dassault-Aviation) and M. Sefrioui (Univ. Paris 6, LIP6). Direction de la Prospective Computational Applied Mathematics periaux@rascasse.inria.fr 4. Multi-objective Genetic Programming For Dynamic Systems Modelling Katya Rodríguez-Vázquez and Peter J. Fleming Dept. of Automatic Control and Systems Engineering University of Sheffield, Mappin Street S1 3JD, U.K. e-mail: katya@acse.shef.ac.uk, P. Fleming@sheffield.ac.uk This work presents an investigation into the use of Genetic Programming (GP) applied to chaotic systems modelling. A difference equation model representation, the NARMAX (Non-Linear AutoRegressive Moving Average with eXtra inputs) model is proposed for being the basis of the hierarchical tree encoding in GP. Based upon this difference equation model representation and formulating the identification as a multiobjective optimisation problem, the well-known benchmark problem, the Chua's circuit, is studied. The formulation of the GP fitness function, multicriteria cost function based upon the definition of Paretooptimality, generated a set of non-dominated chaotic models. This approach considered criteria related to the complexity, performance and also statistical validation of the models in the fitness evaluation. The final set of non-dominated model solutions are able to capture the dynamic characteristics of the system and reproduce the chaotic motion of the double scroll attractor. 5. Assessing the Performance of Multiobjective Genetic Algorithms for Optimisation of a Batch Process Scheduling Problem K. J. Shaw, C. M. Fonseca [1], A. L. Nortcliffe, M. Thompson, J. Love, and P. J. Fleming. Department of Automatic Control & Systems Engineering, University of Sheffield, Mappin Street, S1 3JD, UK. Fax: +44 (0) 114 273 1729 Email: shaw@acse.shef.ac.uk [1] ADEEC/UCEH, Universidade do Algarve, Campus de Gambelas, 8000 Faro, Portugal Email: cmfonsec@ualg.pt Scheduling provides a source of many problems suitable for solution by genetic algorithms (Davis, 1985; Bagchi et, al, 1991; Cleveland and Smith, 1993; Lee et al., 1993; Shaw and Fleming, 1996; Löhl et al., 1998). The complexities, constraints and practicalities involved in the field motivate the development of genetic algorithm techniques to allow innovative and flexible scheduling solutions. Multiobjective genetic algorithms (MOGAs) extend the standard evolutionary-based optimisation genetic algorithm optimisation technique to allow individual treatment of several objectives simultaneously (Schaffer, 1985; Goldberg, 1989, Fonseca and Fleming, 1993, 1998, Horn, Nafpliotis, and Goldberg, 1994, Srivinas and Deb, 1995). This allows the user to attempt to optimise several conflicting objectives, and to explore the trade-offs, conflicts and constraints inherent in this process. The area of MOGA performance assessment and comparison is a relatively new field, as much research concentrates on applications rather than the theory behind MOGA capabilities (e.g., Fonseca and Fleming, 1996; Van Veldhuizen and Lamont, 1998; Zitzler and Thiele, 1998). However, the theoretical exploration of these issues can have tangible effects on the development of highly practical applications, such as the process plant scheduling system under development in this work (Shaw, et. al., 1999). By assessing and comparing their strengths, variations and limitations with a quantitative method, the user can develop a highly efficient MOGA to suit the application, and gain insight into behaviour the application itself. In this work, two MOGAs are implemented to solve a process scheduling optimisation problem. A quantitative comparison of their performances is conducted, and the results and implications of this comparison are then examined within the context of the problem. Finally, a discussion of how this work may be applied beyond this field, to many other types of multiobjective optimisation techniques and applications is provided. This demonstrates the utility of this study to many other MOGA users. 6. A Genetic Algorithm Approach to Multi-Objective Scheduling Problems with Earliness and Tardiness Penalties Hisashi Tamaki, Etsuo Nishino and Shigeo Abe. Dept. of Electrical and Electronics Engr. Kobe University Rokko-dai, Nada-ku, Kobe 657-8501, Japan Tel/Fax: +81-78-803-1063 tamaki@chevrolet.eedept.kobe-u.ac.jp This paper deals with identical parallel machine scheduling problems with two kinds of objective functions, i.e., both regular and non-regular objective functions, and proposes a genetic algorithm approach in which (a) the sequence of jobs on each machine as well as the assignment of jobs to machines are determined directly by referring to a string (genotype), and then (b) the start time of each job is fixed by solving the linear programming problem. As for (b), we newly introduce a method of representing the problem to determine the start time of each job as a linear programming problem whose objective function is formed as a weighted sum of the original multiple objective functions. This method enables to generate a lot of potential schedules. Moreover, through computational experiments by using our genetic algorithm approach, the effectiveness for generating a variety of Pareto-optimal schedules is investigated. 7. Cooperative Strategies for Solving the Bicriteria Sparse MultipleKnapsack Problem F. S. Salman, GSIA, CMU, Pittsburgh, PA 15213, fs2c@andrew.cmu.edu J. Kalagnanam, S. Murthy, IBM T.J. Watson Research Center, PO Box 218, Yorktown Hts, NY 10591 jayant@us.ibm.com, 914 945 1039 speaker: Jayant Kalagnanam The problem of assigning a given set of orders to the production units in the inventory arises frequently in production planning and scheduling. Typically, this problem can be formulated as a variation of the multiple knapsack problem where items (orders) are packed into knapsacks (production units). In our model we consider variations such as multiple objectives and additional assignment restrictions. We consider the objectives of both maximizing total amount of assignment and minimizing total waste due to unused knapsack capacity, as well as assignment restrictions which can be represented by sparse bipartite graphs. The focus of this paper is on obtaining non-dominated solutions in reasonably short computational time. This paper studies real instances from the steel industry which proved very hard to solve using conventional integer programming techniques. A cooperative organization of heuristics was used to solve these instances with surprising effectiveness. Such an approach can generalized for use for other hard optimization problems. 8. Multi-objective design of finite word-length controllers R.S.H. Istepanian Dept of Electrical and Computer Engineering, Ryerson Polytechnic University, 350 Victoria St, Toronto M5B 2K3, Canada. istepanr@ee.port.ac.uk J.F. Whidborne Division of Engineering, Kings College London, Strand, London WC2R 2LS, U.K. james.whidborne@kcl.ac.uk Feedback controller implementations with fixed-point arithmetic offer advantages of speed, memory space, cost and simplicity compared to floating-point arithmetic. Thus, to date, fixed-point processors dedicated for digital controller implementations are still the dominant architecture in many modern digital control engineering applications, particularly for automotive, consumer, military and medical applications. However, most control design methodologies assume that the designed controller will be implemented with infinite precision. Thus, when the controller is implemented, rounding errors in the controller parameters can cause a performance degradation and even instability. However, to directly design the controller with finite-precision control parameters can result in lower performance and stability robustness. Hence, there is a trade-off between the cost of the controller (in terms of word-length and memory requirements) and the performance of the system. This paper will present an approach to designing finite word-length feedback controllers by means of a multi-objective genetic algorithm. The approach provides a set of solutions that are (near) Pareto-optimal with respect to minimal word-length and memory requirements and to closed loop performance. The method is applied to the design of a finite word-length controller for the IFAC93 benchmark problem. Session: Quantum Computing – 2 Sessions Organizer: Ajit Narayanan Department of Computer Science University of Exeter Exeter EX4 4PT, UK ajit@dcs.exeter.ac.uk 1. Introduction to Quantum Mechanics Ajit Narayanan University of Exeter UK This talk will briefly introduce the basic concepts of quantum computing, such as superpositions and quantum Turing Machines, before describing Shor's quantum cryptanalysis algorithm. 2. Quantum Computing Richard Hughes Los Alamos National Laboratory NM This talk will bring the audience up-to-date on the most recent developments in quantum computing and will describe current interest and research at LANL, which included the use of trapped ions for undertaking quantum computation. 3. Quantum Genetic Programming Lee Spector Hampshire College Amherst, MA Methods for discovering algorithms for quantum computers are described where such methods are more efficient than any classical computer algorithms for the same problems. 4. Quantum Cryptography Anders Karlsson Royal Institute of Technology Sweden Current research in quantum information theory and cryptography will by described. 5. Quantum Algorithms for Search Lov Grover Bell Labs NJ Grover's algorithm for database search will be described. 6. Quantum Search For NP - Complete Problems Colin P. Williams Jet Propulsion Laboratory California Institute of Technology CA Current work based on Grover's algorithm for solving NP - complete problems through quantum search will be described. Session: Advanced Adaptive Algorithms for IE/OR Problems– 2 Sessions Organizers: Mitsuo Gen Intelligent Systems Engg. Lab. Dept. of Indust. & Inform. Systems Engg. Graduate School of Engineering Ashikaga Inst. of Technology Ashikaga, 326-8558 Japan Phone: +81(284)62-0605 ext. 376 or +81(284)62-2985 direct Fax: +81(284)64-1071 Email: gen@ashitech.ac.jp or gen@genlab.ashitech.ac.jp Gursel A. Suer Univ. of Puerto Rico - Mayaguez, P.R. a_suer@rumac.upr.clu.edu 1. Spanning Tree-based Genetic Algorithm for Bicriteria Fixed Charge Transportation Problem Mitsuo Gen, Yinzen Li, and Jong Ryul Kim Dept. of Indust. & Inform. Systems Engg. Ashikaga Inst. of Tech. Ashikaga 326-8558, Japan 2. Genetic Algorithm for Solving Bicriteria Network Topology Design Problem Jong Ryul Kim and Mitsuo Gen Dept. of Indust. & Inform. Systems Engg. Ashikaga Inst. of Tech. Ashikaga 326-8558, Japan 3. Genetic Algorithms in Lot Sizing Decisions William Hernandez and Gursel A. Suer Dept. of Industrial Engg. University of Puerto Rico Mayaguez, PR 00681, USA The work presented in this paper focuses on the application of genetic algorithms to obtain the order quantities for an uncapacitated, no shortages allowed, single-item, single-level lot sizing problem. The problem is tested under various conditions with different lot sizing and genetic algorithm parameters. The impact of scaling on the fitness function is also explored. The results indicate that genetic algorithms are promising for this area as well and more complex lot sizing problems can be tackled. 4. A Hybrid Approach of Genetic Algorithms and Local Optimizers in Cell Loading Gursel A. Suer *, Ramon Vazquez +, and Miguel Cortes ++ * Dept. of Industrial Engg. + Depts. of Electrical Engg. & Civil Engg. University of Puerto Rico-Mayaguez Mayaguez, PR 00681, USA and ++ Dept. of Science and Technology Interamerican University-Aguadilla Aguadilla, PR 00605, USA In this paper, we explore the potential application of evolutionary programming to cell loading problem. The objective is to minimize the number of tardy jobs. The proposed approach is a hybrid three phase approach; 1) Evolutionary programming is used to generate a job sequence, 2) Minimum load rule is applied to assign jobs to cells and 3) Moore's Algorithm is applied to each cell independently. The experimentation results show that the inclusion of the local optimizing procedure mentioned in step 3 accelarates reaching a good solution. 5. Adaptive Penalty Methods for Reliability Optimization of Series-Parallel Systems Using an Ant System Approach Yun-Chia Liang and Alice E. Smith Department of Industrial Engineering, University of Pittsburgh, Pittsburgh, PA 15261 aesmith@engrng.pitt.edu This paper solves the redundancy allocation problem of a series-parallel system by developing and demonstrating a problem-specific Ant System. The problem is to select components and redundancylevels to optimize some objective function, given system-level constraints on reliability, cost, and/or weight. The Ant System algorithm presented in this paper is combined with adaptive penalty methods to deal with the highly constrained problem. Experiments on well-known problems from the literature were used to test this approach. 6. A Hybrid Genetic Algorithm Approach for Backbone Design of Communication Networks Abdullah Konak and Alice E. Smith Department of Industrial Engineering, University of Pittsburgh, Pittsburgh, PA 15261 aesmith@engrng.pitt.edu This paper presents a hybrid approach of a genetic algorithm (GA) and local search algorithms for the backbone design of communication networks. The backbone network design problem is defined as finding the network topology minimizing the design/operating cost of a network under performance and survivability considerations. This problem is known to be NP-hard. In the hybrid approach, the local search algorithm efficiently improves the solutions in the population by using domain-specific information while the GA recombines good solutions in order to investigate different regions of the solution space. The results of the test problems show that the hybrid methodology improves on previous approaches.