2 item-based collaborative filtering algorithm
advertisement

Experimental Study on Item-based P-Tree Collaborative Filtering Algorithm for Netflix Prize
Tingda Lu, William Perrizo, Yan Wang, Gregory Wettstein, Amal Shehan Perera
Computer Science Department
North Dakota State University
Fargo, ND 58108, USA
{tingda.lu, william.perrizo, yan.wang, g.w, amal.perera}@ndsu.edu
trustable recommendation system to help them find the
items they are mostly interested.
Abstract
Collaborative Filtering (CF) algorithm plays an
Recommendation system provides customer with
personalized recommendations by analyzing historical
transactions hence identifying the mostly possible item(s)
that will be of interest to the customer. Collaborative
Filtering (CF) algorithm plays an important role in the
recommendation
system.
Item-based
collaborative
filtering is widely employed over user-based algorithm
due to the computational complexity. Item similarity
calculation is the first but the most important step in
item-based collaborative filtering algorithm.
In this paper, we analyze and implement several item
similarity measurements in P-Tree format to Netflix Prize
data set. Our experiments suggest that adjusted cosine
based similarity provides much better RMSE than other
item-based similarity measurements. The experimental
results provide a guideline for our next step for Netflix
Prize.
1
INTRODUCTION
With the fast growth of e-commerce, more and more
online retailers realize the importance of recommendation
system, which has the goal to identify the mostly possible
item(s) that will be of interest to, or purchased later by the
user through analyzing the historical transactions [4]. The
quality of the recommendation system will not longer be a
technical issue, but also a critical business consideration.
Simultaneously, online customers need a reliable and
important role in the recommendation system. It has been
approved as a reliable and successful algorithm in
e-commerce application [1]. The user-based collaborative
filtering algorithm, one of the popular algorithms to build
recommendation system, bases on the principle that if one
buyer has purchased the same items as the other user, he
or she is likely to buy other products that might already
been purchased by the similar users. However, the
computation complexity of user-based CF algorithm is
linear to the number of users. Considering the fact that
there are tens of millions of existing customers in the
e-commerce database, most current algorithms would not
be able to capture the user similarity due to the limitation
of computational resources. The item-based filtering,
another widely employed collaborative filter algorithm,
has less scalability concerns compared to the user-based
one and gained more and more attentions.
The rest of the paper is organized as follows. The
next section provides a brief introduction of item-based
collaborative filtering algorithm we implement. In section
3 we present P-Tree algorithm, which is employed in our
experiment for efficient data processing. Section 4
provides different item-based similarity measurements
calculation. Section 5 describes the experimental results
of implementing item-based similarities to Netflix Prize
data set. Final section gives conclusions and directions for
future research work.
2
ITEM-BASED COLLABORATIVE FILTERING
// Convert the data into P-Tree data structure
ALGORITHM
PTree.load_binary();
To get the rating prediction of user u on item i, we
first load the data set into P-Tree format for efficient
// Build movie based similarity matrix for item i
processing. P-Tree will be detailed in section 3.
while i in I
{
The next step is to build the movie-based similarity
while j in I
matrix for item i. The similarity between item i and j,
{
sim[i, j ]
sim (i, j ) , can be written as,
1
aij
sim(r
uU '
ui
, ruj )
}
sim (i, j )
}
1
sim(rui , ruj )
aij uU '
// Get the top K nearest neighbors to item i
while j in I
where sim ( rui , ruj ) is the similarity between
{
rui and
if sim[i,j] is not among the top K largest value
sim[i,j] = 0.0
ruj , the rating that user u gives to item i and j respectively,
}
and a ij is a normalization factor [2][3][4]. U’ denotes
// Prediction of rating on item i by user u
the user co-support, the subset of users who rate both item
sum = 0.0, weight = 0.0;
i and j.
for (int lp=0; lp<K; ++lp)
{
Once the item similarity matrix is ready, we get the
sum += r[u,j] * sim[i,j]
top K nearest neighbors to item i, which is denoted by I’.
weight += sim[i,j]
}
The prediction of the rating for item i by user u is,
rui
r sim (i, j )
sim (i, j )
j I '
pred = sum/weight
Table 1
u, j
3
P-TREE ALGORITHM
j I '
The data in our experiment is first converted to
Table 1 briefly illustrates the algorithm to predict
how user u rates item i.
vertical Predicate-trees or P-trees format [12]. P-trees are
a lossless, compressed, and data-mining-ready vertical
data structures.
P-trees are used for fast computation of
counts and for masking specific phenomena. This vertical
data representation consists of set structures representing
the data column-by-column rather than row-by row
(horizontal relational data). Predicate-trees are one choice
of vertical data representation, which can be used for data
4
ITEM-BASED SIMILARITY
mining instead of the more common sets of relational
records. This data structure has been successfully applied
4.1 Cosine-based Similarity
in data mining applications ranging from Classification
and Clustering with K-Nearest Neighbor, to Classification
In this measurement, the items are treated as vectors
with Decision Tree Induction, to Association Rule Mining
and the similarity between two items are computed by the
[14][15][16][17]. A basic P-tree represents one attribute
cosine of the angle between corresponding vectors.
bit that is reorganized into a tree structure by recursive
sub-division, while recording the predicate true value for
Similarity of item i and j is given as,
each division. Each level of the tree contains truth-bits
that represent sub-trees and can then be used for
phenomena masking and fast computation of counts. This
sim (i, j )
construction is continued recursively down each tree path
until downward closure is reached.
r ru , j
uU ' u , i
2
uU ' u , i
r
*
2
uU ' u , j
r
E.g., if the predicate
is “purely 1 bits”, downward closure is reached when
where U’ denotes the users who rate both item i and j.
purity is reached (either purely 1 bits or purely 0 bits).
In this case, a tree branch is terminated when a
4.2 Pearson Correlation
sub-division is reached that is entirely pure (which may or
may not be at the leaf level). These basic P-trees and their
complements are combined using Boolean algebra
As the most popular similarity measurement,
Pearson correlation of item i and j is given as,
operators such as AND(&) OR(|) and NOT(`) to produce
mask P-trees for individual values, individual tuples,
value intervals, tuple rectangles, or any other attribute
sim (i, j )
provides a structure for counting patterns in an efficient,
highly scalable manner.
The current P-Tree API includes the following
uU '
uU '
pattern [13]. The root count of any P-tree will indicate the
occurrence count of that pattern. The P-tree data structure
(ru , i ri )( ru , j rj )
(ru ,i ri ) 2
uU '
(ru , j rj ) 2
where U’ denotes the users who rate both item i and j. ri
and r j is the average rating of the i-th and j-th item
respectively.
public methods of P-Tree class,
4.3 Adjusted Cosine Similarity
size()
Get size of PTree
get_count()
Get bit count of PTree
setbit()
Set a single bit of PTree
the different rating scale. For example, in a 1 to 5 star
reset()
Clear the bits of PTree
movie rating scale system, some users tend to rate movies
&
AND operation of PTree
as 5 while others might hesitate to give a rating of 5. To
|
OR operation of PTree
eliminate the user rating difference, the similarity of item
~
NOT operation of PTree
i and j is given as,
dump()
Print the binary representation of PTree
load_binary()
Load the binary representation of PTree
In the real world rating system, different users have
sim (i, j )
uU '
uU '
(ru ,i ru )( ru , j ru )
(ru ,i ru ) 2
uU '
(ru , j ru ) 2
where U’ denotes the users who rate both item i and j. ru
We evaluate the prediction quality by Root Mean
Square Deviation (RMSE).
denotes the average rating of user u for all the items.
5.2 Experimental Results
4.4 Binary-based Similarity
5.2.1 Experiment on neighborhood size
The actual rating value is discarded and the
corresponding bit in P-Tree is set to 1 [5][6]. The
similarity of item i and j is given as,
The size of the neighborhood directly affects the
prediction quality. We implement cosine, Pearson,
adjusted cosine and binary similarity algorithms with
sim (i, j )
N ij
Ni * N j
neighborhood size K=10, 20, 30, 40, 50. The results are
shown in Figure 1.
where N i and N j denote the numbers of users who
1.08
1.06
1.04
1.02
rate item i and item j respectively, N ij is the number of
RMSE
1
0.98
0.96
0.94
users who rate item i and j.
0.92
0.9
0.88
5
10
EXPERIMENTAL RESULTS
20
company, released $1,000,000 Netflix Prize competition,
which comes with the dataset of 480,189 customers,
17,770 movies and more than 100 million customer
ratings on movies [11]. The competition drew unexpected
interests from all over the world not only because of 1M
rewards, but also the substantial and challenging real data
that data miners have ever had.
Our experiment uses the training dataset in Netflix
movies and build the 50 * 17770 movie similarity matrix.
The prediction quality experiment is taken on Netflix
Prize probe set, but only those involving the selected 50
movies.
50
Adj. Cos
Binary
the best size of neighborhood ranges from 20 to 30, which
works for all similarity measurements described in
Section 4. The accuracy of the prediction improves when
the neighborhood size increases from 10 to 30 since more
similar movies are included. As the neighborhood size
continues to increase, which means more non-relevant
movies are selected, RMSE drops and the prediction
quality gets worse. The detailed RMSE is shown in table
2.
Cosine
Pearson
Adj. Cos
Binary
K=10
1.01906
1.01736
0.96452
1.05802
K=20
1.01775
1.01483
0.95144
1.03562
K=30
1.02530
1.02182
0.94408
1.03055
K=40
1.02766
1.02964
0.94549
1.02882
K=50
1.03251
1.02863
0.94466
1.02959
remove the testing data from training to avoid inflated
movie similarity matrix. Instead we randomly select 50
40
From the experimental results, we could observe that
Prize as the training and probe dataset as testing. We
accuracy. We do not build the whole 17770 * 17770
Pearson
Figure 1
5.1 Data Set and Quality Evaluation
In 2006, Netflix Inc., the biggest online DVD rental
30
K
Cos
Table 2
5.2.2 Experiment on similarity algorithms
7
ACKNOWLEGMENTS
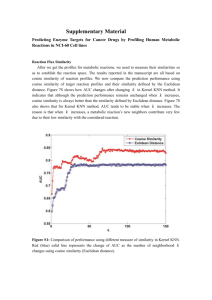
The lowest RMSE of cosine, Pearson, adjusted
We would like to thank all DataSURG members for
cosine and binary similarity algorithms are shown in
their hard work on P-Tree API. We also thank the Center
Figure 2. We observe that the adjusted cosine similarity
of High Performance Computing at North Dakota State
algorithm gets much lower RMSE than other algorithms.
University, which provides the computing facility in our
The reason lies in the fact that other algorithms do not
experiment.
exclude the user rating difference. Adjusted cosine based
algorithm discards the user variance hence gets better
8
REFERENCES
prediction accuracy.
[1]
G. Adomavicius and A. Tuzhilin, Towards the Next
Generation of Recommendation System: A Survey
of the State-of-art and Possible Extensions, IEEE
1.04
Transactions on Knowledge and Data Engineering,
1.02
pp 634-749, 2005
1
[2]
G. Karypis, Evaluation of Item-Based Top-N
Recommend Algorithms, Proceeding of the 10 th
RMSE
0.98
International
0.96
Conference on Information and
Knowledge Mangement, pp 247-254, 2001
0.94
[3]
0.92
B. Sarwar, G. Karypis, J. Konstan and J. Riedl,
Item-Based
Collaborative
Filtering
Recommendation Algorithms, Proceedings of the
0.9
Cos
Pearson
Adj. Cos
Binary
10th International Conference on World Wide Web,
Figure 2
pp 285-295, 2001
[4]
6
M. Deshpande and G. Karypis, Item-base Top-N
Recommendation Algorithms, ACM Transactions
CONCLUSION AND FUTURE WORK
on Information Systems, Vol. 22, Issue 1, pp
In this paper we show the experimental study to
item-based similarity collaborative filtering algorithm on
143-177, 2004
[5]
Netflix Prize. The experiments are taken on cosine,
M.
Bell
and
Y.
Koren,
Improved
Neighborhood-based Collaborative Filtering, KDD
Pearson, adjusted cosine and binary similarity algorithm.
Each algorithm is implemented in P-Tree with different
R.
Cup 2007, pp 7-14, 2007
[6]
neighborhood sizes. The results show adjusted cosine
R. M. Bell, Y. Koren and C. Volinsky, Scalable
Collaborative
Filtering
with
Jointly
Derived
th
similarity algorithm gets more accurate prediction than
Neighborhood Interpolation Weights, 7
other algorithms. The optimal neighborhood size ranges
International Conference on Data Mining, pp 43-52,
from 20 - 30.
2007
[7]
D.
Billsus
and
M.
J.
Pazzani,
IEEE
Learning
This paper is a preliminary one and variant forms of
Collaborative Information Filters, Proceeding of the
similarity algorithm are not included. We run the
15th International Conference on Machine Learning,
experiments on 50 randomly selected movies. It will be
pp 46-54, 1998
statistical confidence if the experiment is taken on more
movies.
[8]
D. Goldberg, D. Nichols, B. M. Oki and D. Terry,
Using Collaborative Filtering to Weave and
Information Tapestry, Communications of the ACM
35, pp 61-70, 1992
[9]
J. S. Breese, D. Heckerman and C. Kadie,
Empirical Analysis of Predictive Algorithms for
Collaborative Filtering, Proceeding of the 14th
Annual Conference on Uncertainty in Artificial
Intelligence, pp 43-52, 1998
[10] J. Wang, A. P. de Vries and M. J. T. Reinders,
Unifying User-based and Item-based Collaborative
Filtering
Approaches
by
Similarity
Fusion,
Proceedings of the 29th Annual International ACM
SIGIR Conference on Research and Development
in Information Retrieval, pp 501-508, 2006
[11] Netflix Prize, http://www.netflixprize.com
[12] DataSURG,
P-tree
Application
Programming
Interface Documentation, North Dakota State
University.
http://midas.cs.ndsu.nodak.edu/~datasurg/ptree/
[13] Q. Ding, M. Khan, A. Roy, and W. Perrizo, The
P-tree Algebra, Proceedings of the ACM Symosium
on Applied Computing, pp 426-431, 2002
[14] A. Perera and W. Perrizo, Parameter Optimized,
Vertical, Nearest Neighbor Vote and Boundary
Based Classification, CATA, 2007
[15] A. Perera, T. Abidin, G. Hamer and W. Perrizo,
Vertical Set Square Distance Based Clustering
without Prior Knowledge of K, 14th International
Conference on Intelligent and Adaptive Systems
and Software Engineering (IASSE 05), Toronto,
Canada, 2004
[16] I. Rahal and W. Perrizo, An Optimized Approach
for KNN Text Categorization using P-Tree,
Proceedings of the ACM Symposium on Applied
Computing, pp 613-617, 2004
[17] A. Perera, A. Denton, P. Kotala, W. Jockheck, W.
Valdivia and W. Perrizo, P-tree Classification of
Yeast Gene Deletion Data, SIGKDD Explorations,
Vol. 4, Issue 2, 2002