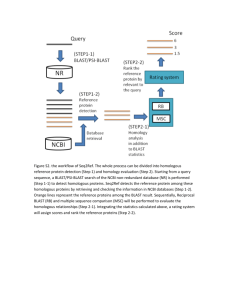
Protein sequence comparisons typically double the evolutionary
advertisement

MMG 433 Microbial Genomics Lab Exercise #7: BLAST Due Date: March 2. Name: _______________________________ Searching Nucleic Acids and Protein Databases for Homologs Goals: To gain an understanding of strategies for searching sequence databases, and to develop expertise in the interpretation of results from database searches. There is an excellent tutorial on database searching provided by NCBI. To access this tutorial, go to the NCBI homepage, select "Education" from the menu along the left margin of the page, and click on the BLAST/PSI_BLAST information and tutorial icon. Complete the Query tutorial first (this is probably worthwhile even if you use BLAST regularly) and proceed through the BLAST and PSI_BLAST tutorials. It is also instructive to read the BLAST Guide. The tutorials rely in part on an understanding of the following terms in bold. Homologous genes are those that share a common evolutionary ancestry. Homologous genes can be either paralogous i.e. genes resulting from duplication and evolution within a population, or orthologous, i.e. homologous genes that differ because they are found in different species. You do not need to provide written answers to the following questions, but keep them in mind while you are working through the tutorials. What can be learned from a BLAST search? Why is it advantageous to search with a protein sequence rather than the corresponding DNA sequence? If either DNA or protein sequences are compared to a database, why are there 6 different variations of BLAST programs? Would you consider an E value of 0.1 to be biologically meaningful? Why run BLAST using an organism-specific database if all of the organism-specific databases are included within the non-redundant (nr) database? If BLAST does not find a significant match, how could PSI-BLAST find anything of significance? What is a "profile" that is the heart of PSI-BLAST? How does one decide which additional sequences to add during iterations of PSI-BLAST? What are "low complexity" regions of a sequence and what advantage can be gained by filtering out these regions 1. Use Entrez to find the sequence for the uncharacterized MJ0414 ORF of Methanococcus jannaschi. How many proteins do you find? Why is there more than one? 2. Perform a PSI Blast search for three iterations using 0.005 as an E-value. What is the likely function of this protein? Is the similarity found over the entire protein? If not which part of the protein shows similarity? What would happen if you chose an E-value of 5 for performing the next PSI-BLAST?