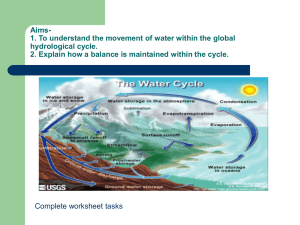
The potential and limitations of Shuffle complex and multi
advertisement

Shuffled complex evolution and multi-linear approaches to flow prediction in the equatorial Nile basin. Jean-Marie Kileshye Onema a, b, Zacharia Katambara a, Akpofure Taigbenu a (a)Water Research Group, School of Civil and Environmental Engineering, University of Witwatersrand, Private Bag 3, WITS 2050, South Africa (b) Ecole Supérieure des Ingénieurs, Université de Lubumbashi, PO Box 1825, République Démocratique du Congo Corresponding author email : jmkilo3@yahoo.co.uk Abstract Continuous development and investigation in flow prediction is of interest in watershed hydrology especially where watercourses are poorly gauged and data are scarce like in most parts of Africa. Thus, this paper reports on the potential and limitations of two approaches in forecasting discharges for the Semliki River. The Semliki River is part of the upper drainage of the Albert Nile. With an average annual local runoff of 4.622km3, the Semliki watershed contributes up to 20% of the flows of the White Nile. The watershed was sub-divided in 21 subcatchments (S3 to S23); eight physiographic attributes for each subcatchment were generated and used to forecast flows. Multi linear and shuffled complex evolution approaches were used to predict the discharges. The predictions were validated and calibrated using the limited historical flows records on the river. The statistics of prediction performance, namely the Nash-Sutcliffe efficiency (NSE), the percent bias (PBIAS) and the RMSEobservations standard deviation ratio (RSR) were performed. The linearity assumption proved to be adequate in capturing the interactions between catchments descriptors and the discharges. Subsequently the flows predicted were more accurate. The shuffled complex evolution embedded in a Delphi programme provided a less precise combination of parameters for flow prediction. Additionally, no physical meaning could be linked to those parameters due to the black box approach associated with the shuffled complex evolution. Key words: flow prediction, Nile, Semliki, shuffled complex evolution 1. Introduction Numerous approaches exist for flow prediction in natural river reaches. Flow forecasting has significant interest both from research as well as from an operational point of view. The choice of methods depends on data availability and the type of application. While continuous developments strive at enhancing our predictive capability for streamflow, we are often facing the problem of predictions in ungauged basin (Sivapalan et al., 2003). Reliable and accurate estimates of hydrologic components are not only important for water resources planning and management but are also increasingly relevant to environmental studies (Schröder, 2006). Several studies have reported on the use of catchment descriptors and regionalization of parameters for flow prediction in ungauged basins. Among the most recent studies Sefton and Howard (1998), Mwakalila (2003), Xu (2003), Merz and Blöschl (2004), McIntyre et al., (2005), Sanborn and Bledsoe (2006), Yadav et al.,(2007), Sharda et al., (2008) Kwon et al., (2009) and Shao et al., (2009) have dealt with the subject. In their comparison of linear regression with artificial neural network, Heuvelmans et al., (2006) indicated the need of well-informed choice of physical catchment descriptors as a first condition for a successful parameter regionalization. Cheng et al., (2006) reported on the importance and usefulness of parsimonious models for runoff prediction in data-poor environment as these models are characterized by small number of parameters. Reducing uncertainty associated with predictions in ungauged basin is critical as reported by Uhlenbrook and Siebert (2003) Koutsoyiannis, (2005a, 2005b) as well as Zhang et al., (2008). Lately, Koutsoyiannis et al., (2008) indicated that analogue modeling techniques for simulation are also used for prediction with impressive performance due to the advances achieved on non linear dynamical systems (chaotic systems). The major drawback is the fact that these approaches are data intensive and work as black box, thus no process insight is provided. Relevant spatial and temporal scale to flow prediction continues to be a subject of discussions and investigations in watershed hydrology (Kundzewicz, 2007). Thus, this paper reports on the potential and limitations of multi-regression and shuffled complex optimizations when it comes to flow prediction in a medium size and data-scarce watershed of the equatorial Nile region. 2 2. Study area These analyses are conducted within the Semliki watershed of the equatorial Nile region (Fig1.). The catchment covers an estimated area of 23,621.0 km2. Figure 1: Semliki watershed The Semliki drains the basins of lakes Edwards and George, and a contributing area downstream that includes the western slopes of the Ruwenzori range. The watershed receives an average rainfall of 1245mm per annum, with peaks occurring in May (95mm) and October (205mm). An average annual local runoff of 4.622km3 has been estimated from records at Bweramule (Sutcliffe and Parks, 1999). The elevations comprise flat areas and ice-caped mounts climbing up to 4862m above the sea level. The flora and the fauna of the watershed constitute one of the unique and distinct ecosystem of the Albertine Rift ecosystem. The vegetation predominantly comprises medium altitude moist evergreen to semi deciduous forest. Five distinct vegetation zones have been documented under the mount Ruwenzori and they occur with changes in altitude. Detailed information on landscape physiographic attributes is reported in Kileshye Onema and Taigbenu (2009). 3. Methods and materials The landscape on any catchment is made up of several combinations of physiographic attributes. These combinations are usually variable among catchment, giving rise to different hydrological responses. Table 1 presents the eight physiographic attributes extracted from the 21 subcatchments that form the Semliki watershed (S3 - S23) (Fig 2). Table 1: Physiographic attributes generated for subcatchments (S3-S23) 3 Physiographic attribute Stream Length Drainage density unit m km.km-2 Abbreviation Strm_len Drainage Mean Stream slope % avg_slope Max elevation of the subcatchment m Max_elev Min elevation of the subcatchment Weighted average elevation of the area Mean monthly precipitation m Min_elev m avg_elev mm/month monthly__prec Mean monthly NDVI - monthly_NDVI Figure 2: Semliki Subcatchments (S3 to S23). The Principal component analysis (PCA) as Indirect Gradient Analysis was used as the exploratory technique to study the structure of the data. Multi-regression was performed on the eight physiographic selected to derive the model as illustrated in figure 3. 4 Descriptive Statistics Section Predicted Values with Confidence Limits of Means Normality Tests Section Residual Report Analysis of Variance Regression Equation Section Estimated Model Figure 3: Multiple regression analysis The shuffled complex evolution embedded in a Delphi programme was used on the other hand for the purpose of determining the optimum parameters of the predictive equation. The method combines the strength of the downhill simplex procedure with the concepts of controlled random search competitive evolution and complex shuffling. The optimization approach used is further documented in Katambara and Ndiritu (2009). The performance rating for prediction accuracy used was the following dimensionless evaluation statistics: The Nash-Sutcliffe efficiency (NSE), the Percent bias (PBIAS) and the RMSE-observations standard deviation ratio (RSR). They were computed respectively as shown in equations (1) (2) and (3) (Moriasi et al., 2007). n obs sim 2 (Yi Yi ) NSE 1 in1 obs mean 2 (Yi Y ) i 1 Equation 1 n obs sim (Yi Yi ) *100 PBIAS i 1 n obs (Yi ) i 1 Equation 2 5 RSR RMSE STDEVobs n obs sim 2 (Yi Yi ) i 1 n obs mean 2 ) (Yi Y i 1 Equation 3 4. Results and discussions 4.1. Principal Components Analysis (PCA) The descriptive statistics below (Table 2) show that the variables included in the PCA are measured at significantly varying scales, however this does not affect the results of the analysis as the matrix analyzed is the scale invariant correlation matrix of the variables (as opposed to the covariance matrix). Table 2: Descriptive statistics of variables Variables Stream Length Drainage Average Slope Maximum elevation Minimum elevation Average elevation Monthly precipitation Monthly NDVI Count Mean Standard Deviation 21 21 21 21 21 21 29.46 7.85E-02 0.2 2577.9 733.18 1164.82 20.66 3.52E-02 0.23 1273.84 99.78 392.54 21 21 101.72 0.6 6.97 7.52E-02 The correlations between the variables are summarized in table 3. There are some high correlations (greater than 0.5), implying that there is a correlation structure that can potentially be modeled or further explored using PCA. If all the correlations were low there would be no need to try to model the correlation structure using principal components analysis. The value of phi for this data (0.4) (Table 4), suggests that there is considerable redundancy or complexity in the group of variables which warrants further examination using PCA. Bartlett’s sphericity test is used to test the null hypothesis that the correlation matrix of the group of variables is a zero identity matrix i.e. none of the variables are correlated. If we obtain a p-value for the Bartlett’s test which is greater than 0.05 we should not carry out PCA. The p-value obtained is very low indicating that we can carry out the PCA (Table 4). Table 3: Coefficients of correlations between variables Stream Drainage Average Maximum Minimum Average Monthly Monthly 6 Length Stream Length Drainage Average Slope Maximum elevation Minimum elevation Average elevation Monthly precipitation Monthly NDVI Slope elevation elevation elevation precipitation NDVI 1 0.344 -0.2 -0.05 -0.29 -0.29 -0.08 0.07 0.34 1 -0.19 -0.46 -0.24 -0.45 0.07 0.16 -0.2 -0.19 1 0.37 0.13 0.54 0.08 -0.15 -0.05 0.47 0.36 1 0.23 0.87 -0.5 -0.63 -0.28 -0.24 0.13 0.226 1 0.46 -0.25 -0.23 -0.28 -0.45 0.54 0.87 0.46 1 -0.45 -0.64 -0.09 0.07 0.08 -0.5 -0.25 -0.45 1 0.78 -0.07 0.16 -0.15 -0.63 -0.23 -0.64 0.78 1 Table 4: Bartlett test and Glaeson – Staelin (Phi) Bartlett DF P-Value Glaeson –Staelin Test (Phi) 81.98 28 0.00000 0.395415 According to the Kaiser criterion when the principal components have been calculated using correlation coefficients is to retain the principal components with an eigenvalue greater than 1. Therefore in this case we would retain the first 3 principal components. These 3 principal components account for 76% of the variation in the data (table 5). Table 5: Eigenvalues of components No. Eigenvalue 1 2 3 4 5 6 7 8 3.49 1.56 1.02 0.78 0.64 0.30 0.17 0.05 Individual Percent 43.59 19.46 12.71 9.80 7.97 3.74 2.13 0.62 Cumulative Percent 43.59 63.04 75.75 85.55 93.51 97.25 99.38 100.00 Scree Plot ||||||||| |||| ||| || || | | | The Eigenvectors are the coefficients that relate the scaled original variables to the derived factors. The scaled original variables are defined as follows: xi X i i i Equation 4 where; xi = the scaled variable; X i = the original variable; i = the mean of the original variable and 7 i = the standard deviation of the original variable For instance, the first principal component is: Factor1 = -0.157886(Strm_len) -0.283358(Drainage) + 0.241135(avg_slope) + 0.468021(Max_elev) + 0.268251(Min_elev)+ 0.505941(avg_elev) 0.339627(monthly__prec) - 0.417503(monthly_NDVI) - Equation 5 The italics are there to emphasise that we are referring to the scaled original variables and not their original values. Inspection of the eigenvectors shows that the first factor is a contrast of avg_slope, max_elev, min_elev and avg_elev to strm_len, drainage, monthly__prec and monthly_NDVI. This factor explains 44% of the variation in the data. The eigenvectors of the three factors that have been retained are shown in table 6 below: Table 6: Eigenvectors of principal components Variables Factor1 Factor2 Factor3 Strm_len -0.16 -0.52 -0.42 Drainage -0.28 -0.36 -0.10 avg_slope 0.24 0.37 -0.60 Max_elev 0.47 -0.08 -0.27 Min_elev 0.27 0.17 0.56 avg_elev 0.51 0.10 -0.14 monthly__prec -0.34 0.52 -0.22 monthly_NDVI -0.42 0.37 -0.05 The factor loadings are the correlations between the variables and the factors. Factor 1 is most highly correlated to the maximum elevation and the average elevation; whereas factor 3 is most highly correlated to the average slope and the minimum elevation (Table 7). Table 7: Factor loadings of principal components Variables Factor1 Factor2 Factor3 Strm_len -0.29 -0.65 -0.42 Drainage -0.53 -0.45 -0.10 avg_slope 0.45 0.46 -0.60 Max_elev 0.87 -0.10 -0.27 Min_elev 0.50 0.21 0.56 avg_elev 0.94 0.12 -0.14 monthly__prec -0.63 0.65 -0.22 monthly_NDVI -0.78 0.46 -0.05 4.2. Multi-regression and shuffled complex evolution Multi-regression and shuffled complex evolution were the optimization approaches used for the determination of runoff predicting equations. Several normality tests were performed, results are reported in table 8, the Anderson Darling test was the only one that rejected the null hypothesis at 20%. 8 Table 8: Normality test Reject H0 Test name Test value Prob level At Alpha = 20% Shapiro Wilk 0.96 0.44 No Anderson Darling 0.53 0.18 Yes D'Agostino Skewness 0.64 0.52 No D'Agostino Kurtosis 0.35 0.73 No D'Agostino Omnibus 0.54 0.76 No The estimated model generated from the multiple regression is represented in equations (4). The optimum parameters established with the shuffled complex evolution are illustrated in equation (5). Table 9 and figure 4 a-b indicate that the multi-regression outperformed the shuffled complex evolution in the optimization of parameters. While shuffled complex evolution has been documented to provide optimum parameters this study illustrates the fact the approach is data-driven and limited performance can be achieved from it in data-poor environment. Table 9: Performances statistics Method Multi-regression Shuffled complex 45 Flow (Mm3 month-1) Flow (Mm3 month-1) evolution Multi Regression 40 Observed Simulated 35 30 NSE 0.90 PBIAS -2.8E-15 RSR 0.31 -0.50 42.43 1.22 45 Shuffled Complex 40 30 25 25 20 20 15 15 10 10 5 5 0 Observed Simulated 35 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 Subbasin 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 (a) Subbasin (b) Figure 4. Predicted vs observed: (a) multi-regression, (b) shuffled complex evolution Q=10349036.065+ 1663.615*avg_elev-276576.251*avg_slope42571909.54*Drainage-556.309*Max_elev+ 293.425*Min_elev+ 7178929.965*monthly_NDVI-100711.884*monthly__prec+ 168414.558*Strm_len Equation 4 Q=0.2*Strm_len1.12Drainage0.3Max_el0.6Min_el0.1avg_el0.4monthly_Prec0.2NDVI0.1 Equation 5 9 5. Conclusions This study undertaken in the data-scarce Semliki watershed of the equatorial Nile reported on the use of two optimisation approaches for the prediction of flows. The principal Component analysis performed identified variables that explained most of the variability in the dataset investigated. The dimensionless statistics on the predictions indicated that the multi-regression approach outperformed the shuffled complex evolution approach. While the later approach has been documented as one of the germane approach in the determination of optimum parameters, this study illustrated the fact the shuffled complex approach is data-driven and limited performance can be achieved from it in datapoor environments. References Cheng, Q., Ko, C., Yuan,Y., Ge, Y., Zhang, S., 2006. GIS modeling for predicting river runoff volume in ungauged drainages in the greater Toronto area, Canada. Computers and Geosciences 32, 1108-1119. Heuvelmans, G., Muys, B., Feyen, J., 2006. Regionalization of the parameters of a hydrological model: comparison of linear regression models with artificial nets. Journal of hydrology 319, 245-265 Katambara, Z., Ndiritu, J., 2009. A fuzzy inference system for modeling streamflow: Case of Letaba River, South Africa. Physics and Chemistry of the Earth 34, 688–700 Kileshye Onema, J-M., Taigbenu, A. E., 2009. NDVI–rainfall relationship in the Semliki watershed of the equatorial Nile. Physics and Chemistry of the Earth doi:10.1016/j.pce.2009.06.004. Koutsoyiannis, D., 2005a. Uncertainty, entropy, scaling and hydrological stochastics.1Marginal distributional properties of hydrological processes and state scaling Hydrological sciences Journal 50, 381-404 Koutsoyiannis, D., 2005b Uncertainty, entropy, scaling and hydrological stochastics. 2Time dependence of hydrological processes and time scaling Hydrological sciences Journal 50, 405-426 Koutsoyiannis, D., Yao, H., Georgakakos, A., 2008 Medium-range flow prediction for the Nile: a comparison of stochastic and deterministic methods. Hydrological sciences Journal 53,405426 Kundzewicz, Z.W., 2007. Prediction in ungauged basins-a systemic perspective. IAHS publication no. 309. Kwon, H-H., Brown, C., Xu, K., Lall, U., 2009. seasonal and annual maximum streamflow forecasting using climate information: application to the Three Gorges dam in the Yangtze river basin, China. Hydrological sciences Journal 54, 606-622. McIntyre, N., Lee, H., Wheater, H., Young, A., Wagener, T., 2005. Ensemble predictions of runoff in ungauged catchments. Water Resources Research, 41,W12434, doi:10.1029/2005WR004289. 10 Merz, R., Blöschl, G., 2004. regionalization of catchment model parameters. Journal of hydrology 287, 95-123. Moriasi, D.N., Arnold, J.G., Van Liew, M.W., Bingner, R.L., Hardmel, R.D., Veith, T.L. 2007. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. American Society of Agricultural and Biological Engineers, 50(3):885-900. Mwakalila, S., 2003. Estimation of stream flows of ungauged catchments for river basin management. Physics and Chemistry of the Earth 28, 935-942. Sanborn, S. C., Bledsoe, B. P., 2006. Predicting streamflow regime metrics for ungauged streams in Colorado, Washington and Oregon. Journal of hydrology 325, 241-261. Shao, Q., Zhang, L., Chen, Y. D., Singh, V. P., 2009. A new method for modeling flow duration curves and predicting streamflow regimes under altered land-use conditions. Hydrological sciences Journal 54, 582-595. Schröder, B., 2006. Pattern, process, and function in landscape ecology and catchment hydrology-how can quantitative landscape ecology support predictions in ungauged basins? Hydrol. Earth Syst. Sci. 10, 967-979. Sefton, C. E. M., Howard, S. M., 1998. Relationship between dynamic response characteristics and physical descriptors of catchments in England and Wales. Journal of hydrology 211, 1-16 . Sharda, V. N., Prasher, S. O., Patel, R. M., Ojasvi, P. R., Prakash, C., 2008. Performance of Multivariate Adaptive Regression Splines (MARS) in predicting runoff in mid-Himalayan micro-watersheds with limited data. Hydrological sciences Journal 53(6), 1165-1175. Sivapalan, M., Takeuchi, K., Franks, S. W., Gupta, V. K., Karambiri, H., Lakshmi, V., Liang, X., Mcdonnell, J. J., Mendiondo, E. M., O’connell, P. E., Oki, T., Pomeroy, J. W., Schertzer, D., Uhlenbrook, S. and Zehe, E., 2003. IAHS Decade on Predictions in Ungauged Basins(PUB), 2003–2012: Shaping an exciting future for the hydrological sciences. Hydrological sciences Journal 48(6), 857-880. Sutcliffe, J.V and Parks, Y.P. 1999.The hydrology of the Nile, IAHS special publication no.5 Uhlenbrook, S., Siebert, A., 2003. On the value of experimental data to reduce the prediction uncertainty of process-oriented catchment model. Environmental modeling and software 20, 19-3. Xu, C-Y., 2003. Testing the transferability of regression equations derived from small sub-catchments to a large area in central Sweden. Hydrol. Earth Syst. Sci. 7 (3), 317-324. Yadav, M., Wagener., T., Gupta, H., 2007. Regionalization of constraints on expected watershed response behavior for improved predictions in ungauged basins. Advance in Water Resources 30, 1756-1774. Zhang, Z., Wagener, T., Reed, P., Bhushan, R., 2008. Reducing uncertainty in prediction in ungauged basins by combining hydrologic indices regionalization and multiobjective optimization. Water Resources Research, 44, W00B04, doi:10.1029/2008WR006833. 11



![Job description [DOC 33.50 KB]](http://s3.studylib.net/store/data/007278717_1-f5bcb99f9911acc3aaa12b5630c16859-300x300.png)