Word - WMO
advertisement

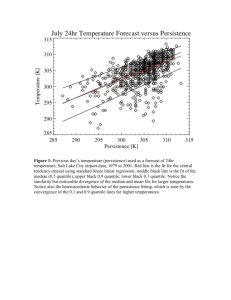
WORLD METEOROLOGICAL ORGANIZATION _______________ COMMISSION FOR BASIC SYSTEMS EXPERT TEAM MEETING ON ENSEMBLE PREDICTION SYSTEMS TOKYO, JAPAN, 15-19 OCTOBER 2001 CBS ET/EPS/Doc 8(2) (9.X.2001) ITEM: 8 ______ Original: ENGLISH DEVELOPMENT OF STANDARD VERIFICATION MEASURES FOR EPS (Submitted by L. Lefaivre, Canada) ____________________________________________________ Summary and purpose of document The various types of verifications which have been proposed for the Ensemble Prediction System (EPS). _____________________________________________________ Action proposed The expert team is invited to consider the document and to make proposals based on this information. CBS ET/EPS/Doc. 8(2) 1. INTRODUCTION Many types of verifications have been proposed for the Ensemble Prediction System (EPS). Verifications must however follow basic principles in order for measures to be proposed and exchanged. First, they ought to be limited and focused. In effect, it is necessary to keep the verification data as simple as possible and limited to a few scores on specific fields so that exchange procedures can be successfully established. As a consequence, verification scores should be focused to the most representative ones. Second, EPS forecasts ought to show an improvement with respect to the deterministic ones. Scores should thus include also a comparison with the deterministic forecasts. Finally, by the very nature of EPS, scores should also verify the probabilistic approaches and assess the spread/skill relationship. 2. VERIFICATION MEASURES 2.1 Root Mean Square (RMS) Errors RMS scores have the advantage of being commonly used. Scores at selected levels (250, 500 and 850 hPa) for specific variables (geopotential heights, temperatures) are verified and exchanged between several centres for the deterministic forecasts. This would thus be very natural to calculate the RMS of the ensemble mean and verify it against the high resolution deterministic forecast. An example of the RMS error ensemble mean forecast at 500 hPa compared to the deterministic one is shown for June 2001 on Figure 1. Definition of the RMS can be found at Appendix A. 2.2 Relative Operating Characteristics (ROC) Relative Operating Characteristics (ROC), derived from signal detection theory, is intended to provide information on the characteristics of systems upon which management decisions can be taken. In the case of weather/climate forecasts, the decision might relate to the most appropriate manner in which to use a forecast system for a given purpose. ROC is applicable to both deterministic and probabilistic categorical forecasts and is useful in contrasting characteristics of deterministic and probabilistic systems. The derivation of ROC is based on contingency tables giving the number of observed occurrences and nonoccurrences of an event as a function of the forecast occurrences and non-occurrences of that event (deterministic or probabilistic). The events are defined as binary, which means that only two outcomes are possible, an occurrence or a non-occurrence. The binary event can be defined as follows: the occurrence of threshold precipitation; the occurrence of temperature at 850 mb to fall beyond a threshold value; any other occurrences. CBS ET/EPS/Doc. 8(2) Hit rate (HR) and false alarm rate (FAR) are calculated for each probability intervals (bins), giving N points on a graph of HR (vertical axis) against FAR (horizontal axis) to form the ROC curve. This curve, by definition, must pass through the points (0,0) and (1,1) (for events being predicted only with 100% probabilities and for all probabilities exceeding 0% respectively). The further the curve lies towards the upper left-hand corner (where HR=1 and FAR=0) the better; no-skill forecasts are indicated by a diagonal line (where HR=FAR). For deterministic forecasts, only one point on the ROC graph is possible. Evolution of the ROC verifications for the 5 mm precipitation threshold over Canadian stations is shown at Figure 2 for the CMC Ensemble Prediction System for summers 1999, 2000 and 2001. The area under the ROC curve is a commonly used summary statistics to assess the skill (Hanssen and Kuipers 1965; Stanski et al 1989) of the forecast system (see Figure 3 as an example of two systems being verified using ROC score). The area is standardized against the total area of the figure such that a perfect forecast system has an area of one and a curve lying along the diagonal (no information) has an area of 0.5. The normalized ROC area has become known as the ROC score. Not only can the areas be used to contrast different curves, but they are also a basis for Monte Carlo significance tests. Monte Carlo testing should be done within the forecast data set itself. The area under the ROC curve can be calculated using the Trapezium rule, but it has the disadvantage of being dependent on the number of points on the ROC curve, or the number of probability intervals (bins). It is thus highly recommended to calculate the area based on a normal-normal model and a least square estimate of the ROC curve (Mason 1982). Definition of the ROC can be found at Appendix B (for deterministic forecasts) and Appendix C (for probabilistic forecasts). 2.3 Spread/skill verification There does not seem to be a consensus on the best approach to measure the spread/skill relationship. ECMWF compares ensemble spread and ensemble error to the control (Buizza and Palmer 1998), while NCEP looks at the spread in conjunction with the uncertainty of the synoptic flow and lead time (Toth et al 2001). At CMC, we have privileged a first order score of spread versus skill that was developed by Houtekamer (personal communication, Lefaivre et al, 1997). Definition is given in Appendix D. Results for August 2001 for 500 hPa heights over Northern Hemisphere (Figure 4) indicate that, for all lead times, the ensemble method is showing some success. The upper and lower bounds of the method, defined in Appendix D, are also shown on the figure. CBS ET/EPS/Doc. 8(2) 2.4 Talagrand diagrams To verify if the spread of the ensemble encompasses the verifying analysis, Olivier Talagrand proposed a statistical method of displaying bias and dispersion within the ensemble (Talagrand et al 1997). Talagrand diagrams are obtained by checking where the verifying analysis usually falls with respect to the ensemble forecast data (arranged in increasing order at each grid point). Note that the first (last) bin is selected if the analyzed value is lower (higher) than any of the values in the ensemble. An example of the 500 hPa Talagrand distribution for the CMC EPS in August 2001 is shown on Figure 5. Definition of the Talagrand diagrams is given at Appendix E. The disadvantage of this method is that images have to be exchanged, rather than numbers. It is also dependent on the number of members within the ensemble. 3. RECOMMENDATION It is recommended to exchange the following verification scores: Monthly 500 hPa RMS errors both for the ensemble mean and the deterministic model, as verified against its own analysis. It is essential that these fields be verified using the same definition of domains as the one defined in the already existing NWP verification exchange protocol1. They are defined as the following: Northern Hemisphere (90N 20N) all latitude inclusive, Southern Hemisphere (90S - 20S) all latitude inclusive and Tropics (20N - 20S); Monthly spread/skill relationship over the same domains as for the RMS using the method described in Appendix D; Monthly Talagrand diagrams are not recommended; Monthly ROC of precipitation at the following thresholds: 2,5 and 10 mm. Since these have to be verified against stations, rather than analyses, common data sets over specific regions have to be defined (e.g. like the SHEF data set over continental USA). 1 Manual on the Global Data-Processing System (GDPS) Table F, Attachment II.7, pp. 36-42 CBS ET/EPS/Doc. 8(2) 4. REFERENCES Buizza, R. and T. N. Palmer, 1998: Impact of Ensemble Size on Ensemble Prediction, Mon. Wea. Rev., 126, 2503-2518 Hanssen A. J. and W. J. Kuipers, 1965: On the relationship between the frequency of rain and various meteorological parameters. Koninklijk Nederlands Meteorologist Institua Meded. Verhand, 81-2-15 Lefaivre, L., P. L. Houtekamer, A. Bergeron and R. Verret, 1997: The CMC Ensemble Prediction System. Proc. ECMWF 6th Workshop on Meteorological Operational Systems, Reading, U.K., ECMWF, 31-44. Mason, I., 1982: A model for the assessment of weather forecasts. Aust. Meteor. Mag., 30, 291-303 Stanski H. R., L. J. Wilson and W. R. Burrows, 1989: Survey of common verification methods in meteorology. World Weather Watch Technical Report No. 8, WMO/TD 358, 114 pp. Talagrand, O., R. Vautard et B. Strauss, 1997: Evaluation of probabilistic prediction systems. Proceedings, ECMWF Workshop on Predictability, 1997 Toth, Z., Y. Zhu and T. Marchok, 2001: The Use of Ensembles to Identify Forecasts with Small and Large Uncertainty, Wea. Forecasting, 16, 463-477. CBS ET/EPS/Doc. 8(2) Validation of ensemble forecasts (500 hPa) over NH JUNE 2001 10 9 RMS errors against analyses (dam) 8 7 6 5 4 3 2 1 2 3 4 5 6 7 8 9 10 Lead Time (days) Figure 1: Verification (Root mean square score) of 500 hPa over northern extratropics (north of 20N) for the ensemble (dashed line) as compared to the deterministic model (solid line); spread in the ensemble is indicated by the dotted line CBS ET/EPS/Doc. 8(2) ROC pcpn verification for JJA 1999, 2000 and 2001 JJA 1999 8 members (192X96) JJA 2000 16 members (192X96) JJA 2001 16 members (300X150) 5 mm threshold Over Canadian stations Figure 2: Evolution of the ROC scores for Canadian stations in summer (June, July and August) of 5 mm threshold probabilistic QPF using the CMC EPS. The improvement in the ROC score followed increase in the number of members (2000) and in resolution (2001) Relative Operating Characteristics (5mm) DJF00/01 Area 0.95 0.9 0.85 0.8 T150 T95 0.75 0.7 1 2 3 4 5 6 7 8 9 10 Lead time (days) Figure 3: Evolution of the ROC area for QPF verification over Canadian stations for different lead times in winter (December, January and February) 2000/2001 for two different EPS configurations CBS ET/EPS/Doc. 8(2) Figure 4. Example of spread/skill verification at 500 hPa over Northern Extratropics for August 2001 CBS ET/EPS/Doc. 8(2) Figure 5. Example of Talagrand diagram at 500 hPa over Northern Extratropics for August 2001 CBS ET/EPS/Doc. 8(2) APPENDIX A Definition of the Root Mean Square (RMS): The RMS error is defined as: RMS f i Oi W i 1 N 2 i W i 1 where: N i f forecast value or value of the standard at grid point i or at station i. O analyzed value at grid point i or observed anomaly value at station i. W 1 for all stations, when verification is done at stations. W cos at grid point i, when verification is done on a grid, with: i i i i N i i the latitude at grid point i. total number of grid points or stations where verification is carried. CBS ET/EPS/Doc. 8(2) APPENDIX B Definition of the Relative Operating Characteristics (ROC) - Deterministic forecasts Table 1 shows a contingency table for deterministic forecasts: observations forecasts occurrences non-occurrences occurrences O1 NO1 non-occurrences O2 NO2 O1+ O2 NO1+ NO2 O1+ NO1 O2+ NO2 T Table 1:contingency table for the calculation of ROC, applied to deterministic forecasts. O W OF 1 i (OF) being 1 when the event occurrence is observed and forecast; 0 otherwise. The summation is over all grid points i or stations i. O1 is the weighted number of correct forecasts or hits. i O W ONF (ONF) being 1 when the event occurrence is observed but not forecast; 0 otherwise. The summation is over all grid points i or stations i. O2 is the weighted number of misses. being 1 when the event occurrence is not NO1 W i NOF i (NOF) observed but was forecast; 0 otherwise. The summation is over all grid points I or stations i. NO1 is the weighted number of false alarms. being 1 when the event occurrence is not NO2 W i NONF i (NONF) observed and not forecast; 0 otherwise. The summation is over all grid points I or stations i. NO2 is the weighted number of correct rejections. W i 1 for all stations, when verification is done at stations. 2 i i W i i cos i at grid point i, when verification is done on a grid. the latitude at grid point i. T is the grand sum of all the proper weights applied on each occurrences and nonoccurrences of the events. When verification is done at stations, the weighting factor is one. Consequently, the number of occurrences and non-occurrences of the event are entered in the contingency table of Table 1. CBS ET/EPS/Doc. 8(2) However, when verification is done on a grid, the weighting factor is cos(i), where i is the latitude at grid point i. Consequently, each number entered in the contingency table of Table 1, is, in fact, a summation of the weights properly assigned. Using stratification by observed (rather than by forecast), the hit rate (HR) is thus defined as (referring to Table 1): HR O1 O O 1 2 The range of values for HR goes from 0 to 1, the latter value being for perfect forecasts. The false alarm rate (FAR) is defined as: FAR NO 1 NO NO 1 2 The range of values for FAR goes from 0 to 1, zero corresponding to perfect forecasts. The Hanssen and Kuipers score (KS), calculated for deterministic forecasts, is defined as: KS HR FAR O NO O NO O O NO NO 1 1 2 2 2 1 1 2 The range of KS goes from -1 to +1, the latter value corresponding to perfect forecasts (HR being 1 and FAR being 0). KS can be scaled so that the range of possible values goes from 0 to 1 (1 being for perfect forecasts): KS 1 KS scaled 2 The advantage of scaling KS is that it becomes comparable to an area on the ROC diagram where a perfect forecast system has a score of one and a forecast system with no information has a score of 0.5 (HR being equal to FAR). CBS ET/EPS/Doc. 8(2) APPENDIX C Definition of the Relative Operating Characteristics (ROC) - Probabilistic forecasts Table 2 shows a contingency table (similar to Table 1) that can be built for probabilistic forecasts: bin number 1 2 3 n N forecast probabilities 0-P1 (%) P1-P2 (%) P2-P3 (%) Pn-1-Pn (%) PN-1-100 (%) observations occurrences nonoccurrences O1 NO1 O2 NO2 O3 NO3 On Non ON NON Table 2: contingency table for the calculation of ROC, applied to probabilistic forecasts. Where: n = number of the nth probability interval or bin n; n goes from 1 to N. Pn-1 = lower probability limit for bin n. Pn = upper probability limit for bin n. N = number of probability intervals or bins. O W O n i (O) being 1 when an event corresponding to a forecast in bin n, is observed as an occurrence; 0 otherwise. The summation is over all forecasts in bin n, at all grid points i or stations i. i NO W NO n i i (NO) being 1 when an event corresponding to a forecast in bin n, is not observed; 0 otherwise. The summation is over all forecasts in bin n, at all grid points i or stations I W i 1 for all stations, when verification is done at stations. W i cos i at grid point i, when verification is done on a grid. the latitude at grid point i. i When verification is done at stations, the weighting factor is one. Consequently, the summation of occurrences and non-occurrences of the event, stratified according to forecast probability intervals, are entered in the contingency table of Table 2. CBS ET/EPS/Doc. 8(2) However, when verification is done on a grid, the weighting factor is cos(i), where i is the latitude at grid point i. Consequently, each number entered in the contingency table of Table 2 is, in fact, a summation of weights, properly assigned. To build the contingency table in Table 2, probability forecasts of the binary event are grouped in categories or bins in ascending order, from 1 to N, with probabilities in bin n1 lower than those in bin n (n goes from 1 to N). The lower probability limit for bin n is Pn-1 and the upper limit is Pn. The lower probability limit for bin 1 is 0%, while the upper limit in bin N is 100%. The summation of the weights on the observed occurrences and non-occurrences of the event corresponding to each forecast in a given probability interval (bin n for example) is entered in the contingency table. Hit rate and false alarm rate are calculated for each forecast probability interval (bin). The hit rate for bin n (HRn) is defined as (referring to Table 2): N HRn O i n i N O i 1 i and the false alarm rate for bin n (FARn) is defined as: N FAR n NO i n i N NO i 1 i where n goes from 1 to N. The range of values for HRn goes from 0 to 1, the latter value being for perfect forecasts. The range of values for FARn goes from 0 to 1, zero corresponding to perfect forecasts. Frequent practice is for probability intervals of 10% (10 bins, or N=10) to be used. However the number of bins (N) must be consistent with the number of members in the ensemble prediction system (EPS) used to calculate the forecast probabilities. CBS ET/EPS/Doc. 8(2) APPENDIX D Definition of the spread/skill relationship For each grid point, for each verification period, for the month of verification, forecast errors are listed from small to large errors (small error forecasts are arbitrarily set as the lower half of the monthly series). The same is done for the spread, each grid point being ranked from small to large spread. A 2 X 2 contingency table can thus be constructed (see Table 3). FORECASTS SPREAD Good Bad Small N1 N2 Large N4 N3 Table 3. Contingency table for spread and score relationship One would like the total number of occurrences with a combination of good forecasts/small spread (N1) and of bad forecasts/large spread (N3) be greater than the other combination (N2 + N4). In the case that the skill of the forecast is of no value, all the entries in the table will be approximately equal, and thus (N1+N3) will be about equal to (N2+N4). The lower bound, defined as «unavoidable failures», cannot be zero because of the very nature of the probabilistic nature of the problem: if a probability distribution is very broad, a specific realisation may still happen to have a small error; if a distribution is narrow, a realisation has non-zero probability of being somewhere in the tail. The upper bound of the method, defined as «maximum obtainable success» is obtained by listing all predicted variances; assume that the actual variances are distributed the same way; for each variance, simulate a realisation using a random number generator. Finally, one produces a contingency table from the variances of the simulated error. CBS ET/EPS/Doc. 8(2) APPENDIX E Definition of the Talagrand Diagrams A Talagrand diagram checks where the verifying analysis usually falls with respect to the ensemble forecast data (arranged in increasing order at each grid point). It is an excellent means to detect systematic flaws of an ensemble prediction system. To construct a Talagrand diagram one proceeds as follows: First one takes the forecasts for some variable by all members of the ensemble. This may give a list of say: (1.5, 2.3, 0.8, 4.1, 0.3) (for a 5 member ensemble). One then puts these values in order. So this gives: (0.3, 0.8, 1.5, 2.3, 4.1). With this list we define 6 bins as follows: l bin 1: values below the lowest value (0.3), l bin 2: values between 0.3 and 0.8, l bin 3: values between 0.8 and 1.5, l bin 4: values between 1.5 and 2.3, l bin 5: values between 2.3 and 4.1, l bin 6: values above 4.1. We now place the analyzed value (say 2.95) in the appropriate bin (bin 5). This process is repeated for a large number of analyzed values (summing over different verifying days and locations). Eventually the total number of cases per bin in a histogram are plotted. Since all perturbations are intended to represent equally likely scenarios, this distribution should be flat. Several common "problems" can be diagnosed from the diagrams. If the spread in the ensemble is too small, the analyzed value will often fall outside the range of values sampled by the ensemble. The first and the last bin will be overpopulated and the diagram will have a "U-shape". A "U-shape" is typically obtained for the validation of medium-range (say day 510) results. One did not capture all sources of error properly and finds that the spread in the ensemble is too small. If the spread in the ensemble is too big, the analyzed value will almost never be outside the range of the sampled values. The first and the last bin will contain very few analyzed values and consequently one obtains an "n-shape" (highest in the middle). An "n-shape" is typically obtained for the validation of short-range (day 1) results. If the diagram is asymmetric the model has a bias to one side. An "L-shape" would correspond to a warm bias for the model. Conversely, an "Inverse L-shape" would correspond to a cold bias. It is important to note that a flat Talagrand diagram only indicates that the probability distribution has been sampled well. It does not indicate that the ensemble will be of any practical use. For long-range forecasts, when all predictability is lost, one will obtain a flat Talagrand diagram (if the model has no bias). ____________________________