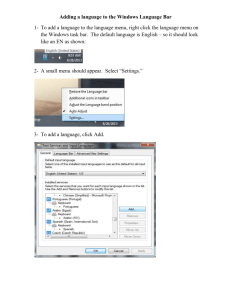
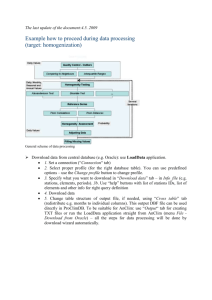
Example how to proceed during data processing:
advertisement

The last update of the document:23.9. 2009 Brief description of the software package (AnClim, ProClimDB, LoadData) AnClim software o Input format: TXT files o Working with one station at a time, but automated processing of many stations is enabled as well o Menu is ordered in a sequence (steps) to be taken during data processing: viewing data, adjusting (transformation), testing distribution, finding outliers, homogeneity testing (both absolute and relative homogeneity tests), times series analysis, filtering output data o Other tools: filling missing values, creating reference series, automation o Managing the software: Series Controler (form in the right bottom corner: info about period, length of series, number of missing values, option for switching between monthly data or seasonal and annual averages/sums/extremes) o Settings the software: in menu Options / Settings, documentation can be found under menu Help / Documentation. o Working with series: plotting graphs, finding outliers, calculating statistical characteristics, various tests (the most commonly used during time series analysis) o Working with two series: merging two series (using differences, ratios/log ratios) LoadData – application for loading data from database (e.g. Oracle) o Creating connection into database (via ODBC) o Specification what to download (stations, elements, periods), various profiles for individual database tables, help buttons for display info about stations, elements, o Tools for importing data from TXT, … files o Adjusting output (cross tables) o Output to TXT files, Excel, AnClim Running LoadData application from the AnClim o Download wizard – guides through all the steps o Transformation to files suitable for AnClim automatically ProClimDB software: o Used for processing whole datasets (all stations at a time) o There are two main input files in the software: Data file (dbf file with all stations data) and Data_info file (list of stations with their geography etc., needed in case you need to compare a station with its neighbours) o How to proceed: select a function, specify files (use right click to select various functions from context menu), set options, run the function for a whole dataset. You can drag and drop the files from Explorer (or any file manager). o User has full control over the processing all the time, a lot of auxiliary output is created o First step of processing is getting information about all available stations (menu Get Info – Create Info File), their period etc., the other step is importing geography (menu Get Info – Import geography), then you can calculate statistical characteristics , correlations, reference series, outliers, etc. A lot of tools for managing dataset is available as well. Click the header to Sort/Unsort, Right click to mark the column for Find/Replace function, etc. Right click to launch context menu with further functions and hints. Functionality available during Viewing a file Two modes of data processing: monthly or daily data (in AnClim and ProClimDB). Homogeneity testing in AnClim: after we export candidate and its reference series to TXT files (using ProClimDB), we can use automation in AnClim – running homogeneity tests for differences (ratios) between candidate and its reference series for a whole dataset. o It is recommended to use several tests: e.g. t-test (on differences), Man-WhitneyPettit test (non-parametric test), SNHT (several modifications), Bivariate test, Vincent test (two-phase linear regression). o Further it is useful to run the tests for several types of reference series: based on correlations, distances, regional average (good for temperature but in case of precipitations we can get only one meaningful type of reference series) o Testing monthly, seasonal and monthly averages Remark: in the later version, it possible to launch AnClim from 8-4 function in ProClimDB software and to run the tests automatically Results from homogeneity testing are imported back to ProClimDB (imported to DBF files) and further processed. o Numbers of inhomogeneities detections per individual years or groups of years are calculated (summed). o Where the inhomogeneity detection using various tests, various reference series etc. coincides, we can regard such cases as very probable to be inhomogeneous, then to go to metadata and verify them etc. o After we decide inhomogeneites, we can adjust them, and in the end to fill missing values Usual scheme of data processing during data quality control and homogenization (preparing data for time series analysis) Individual software and tasks that it can solve: Download data from database (e.g. Oracle) Quality control Homogenization (ProClimDB) (ProClimDB/AnClim) (LoadData) 1 0 .0 0 .8 8 .0 0 .6 6 .0 0 .4 4 .0 0 .2 2 .0 0 .0 0 .0 - 0 .2 - 0 .4 - 2 .0 - 0 .6 - 4 .0 1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000 - 0 .8 - 1 .0 1911 1915 1919 1923 „Technical“ series and grid points calculation (ProClimDB) ProClimDB: Statistical analysis SPI, … Extreme value analysis Spatial analysis (connection ProClimDB - ArcView) Further tools: (connection ProClimDB - R) Validation of RCM outputs Correction of RCM outputs 1927 1931 1935 1939 1943 1947