1 - CENG464
advertisement

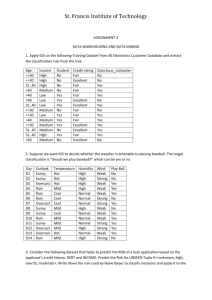
Classification Training and Test set are randomly sampled Tid Attrib1 Attrib2 Attrib3 1 Yes Large 125K No 2 No Medium 100K No 3 No Small 70K No 4 Yes Medium 120K No 5 No Large 95K Yes 6 No Medium 60K No 7 Yes Large 220K No 8 No Small 85K Yes 9 No Medium 75K No 10 No Small 90K Yes Learning algorithm Class Induction supervised Learn Model Model 10 Training Set Apply Model accuracy 1 Tid Attrib1 11 No Small Attrib2 55K Attrib3 ? Class 12 Yes Medium 80K ? 13 Yes Large 110K ? 14 No Small 95K ? 15 No Large 67K ? Deduction 10 Test Set Find a mapping OR function that can predict class label of given tuple X Decision Tree - more than 1 DT can be induced from the same training data (Because of different the DT algorithm and attribute selection measure) - structure of DT affects the performance of classification model o speed of classification is related to the # of the levels in the tree o aim is to construct a DT that has minimal # of levels such that it classifies as many examples as early at the highest levels of the tree as possible - Accuracy of classification by DT is critical - Not every attribute is needed in decision making - More branches in a DT means more complexity more memory resources required more tests needed DT is more likely to overfit makes errors in prediction Information Gain ID3 algorithm uses Information gain measure. Probability of event Ek=P(Ek)=Nk/M where Nk # of samples conveying event Ek M whole sample size Self-Information of Ek= I(Ek)= -log P(Ek) Entropy of whole system= P(Ek) log P(Ek)=H(S) Conditional self-Information of event Ek given that Fj occurred: I(Ek| Fj)= log ( P(Ek and Fj ) / P(Ek) ) Expected information of system=H( S1|S2)= (Ek|Fj)log(P(Ek|Fj)/ P(Ek) ) A DT can be considered as a 2 Information Systems based on Attributes and class H(class) average info of class system before attribute A is considered as the root of the DT H(class|A) expected info of class system after A is chosen as root Information Gain = G (A)= H(class)- H(class|A) The attribute that has the highest information gain is the one that reduces the degree of uncertainty the most ID3 algorithm selects the attribute whose values influence the outcome of the class the most, ensuring the classification of as many examples as close to the root of the tree as possible. Example: weather data Find H(class) Find H(class|Outlook) Find Information Gain = G (Outlook) 1. Initial data set no 1 2 3 4 5 6 7 8 9 10 11 12 13 14 outlook temperature humidity sunny hot high sunny hot high overcast hot high rain mild high rain cool normal rain cool normal overcast cool normal sunny mild high sunny cool normal rain mild normal sunny mild normal overcast mild high overcast hot normal rain mild high windy FALSE TRUE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE TRUE TRUE FALSE TRUE class N N P P P N P N P P P P P N 2. Information Gain measure results in- outlook to be the highest gain attribute Partition the training set into three subsets being Outlook the root: Outlook Sunny Overcast Rain Outlook=overcast outlook temperature humidity overcast hot high overcast cool normal overcast mild high overcast hot normal overcast cool normal windy FALSE TRUE TRUE FALSE TRUE class P P P P P windy FALSE TRUE FALSE FALSE TRUE class N N N P P Outlook=sunny outlook temperature humidity sunny hot high sunny hot high sunny mild high sunny cool normal sunny mild normal Outlook=rain outlook temperature humidity rain mild high rain cool normal rain cool normal rain mild normal rain mild high windy FALSE FALSE TRUE FALSE TRUE class P P N P N windy FALSE TRUE FALSE FALSE TRUE class N N N P P 3. Analyze each subset Outlook=sunny outlook temperature humidity sunny hot high sunny hot high sunny mild high sunny cool normal sunny mild normal Apply Information gain measure- Humidity has the highest gain value - select Humidity as the root of the subtree, create two subsets: outlook temperature humidity sunny hot high sunny hot high sunny mild high windy FALSE TRUE FALSE class N N N outlook temperature humidity sunny cool normal sunny mild normal windy FALSE TRUE class P P Each subset contains only the samples with only one class label (N or P) - Two leaf nodes labeled by P and N are created Outlook Sunny Humidity high N normal P Overcast Rain 4. analyze subset Outlook=Overcast Outlook=overcast outlook temperature humidity overcast hot high overcast cool normal overcast mild high overcast hot normal overcast cool normal windy FALSE TRUE TRUE FALSE TRUE class P P P P P All the samples have the same class label P create leaf node with P Outlook Sunny Overcast Rain Humidity P high normal N P 5. analyze subset Outlook=rain Outlook=rain outlook temperature humidity rain mild high rain cool normal rain cool normal rain mild normal rain mild high windy FALSE FALSE TRUE FALSE TRUE class P P N P N Calculate information gain for each attribute Windy attribute has the highest gain partition over Windy Windy=False outlook temperature humidity rain mild high rain cool normal rain mild normal windy FALSE FALSE FALSE class P P P windy TRUE TRUE class N N Windy=True outlook temperature humidity rain cool normal rain mild high In each subset, we have the same class label create leaf nodes with the class labels Outlook Sunny Overcast Rain Windy Humidity P high N normal True P False N P Gain Ratio C4.5 and C5 algorithms uses Gain Ratio. Normalizes uncertaintyinformation gain across different attributes in order to avoid bias towards attributes with more distinct values Gain Ratio (A)= Gain(A)/ H(A) H (Outlook)= -5/14log 5/14 – 4/14log 4/14 -5/14 log 5/14 = 1.577 Gain Ratio (Outlook)=0.246/ 1.577 = 0.156 Information Gain Ratio has a better performance than the information gain in terms of classification accuracy of the resulting tree Gini Index CART,SPRINT,SLIQ algorithms uses Gini Index Assume class has w labels c1, c2, c3…cw Gini impurity function measures level of impurity of the data set Gini (t)=1- P(Ci\ t)2 OR Gini (class)= 1- P(Ci)2 Where P(Ci\ t) is the fraction of specific class under condition t When Dt is constructed, it searches for an attribute whose values split an impure set into partitions Choose an attribute that reduces the impurity the most Gini Index (A) =Gini (class)- P(aj) Gini (A=aj) where P(aj) is the probability of A=aj Example: Weather data X2 Statistics Used in CHAID algorithm. It is a measure for the degree of association or dependence between two variables. For classification, it can be used to measure the degree of dependence between a given attribute and the class variable. Problem of overfitting -the classification problem built from a limited set of training examples is too representative of the training examples themselves rather than the general characteristics of data more complex tree is built, too many branches, some may reflect anomalies due to noise or outliers less accurate predictions -cause of overfitting o presence of noise records in the training set, o lack of representative examples in the training set, o the repeated attribute selection process of a model construction algorithm Prunning: approaches to avoid overfitting replace a subtree by a leaf node, making the tree smaller, more robust and less prone to error Prepruning: Halt tree construction early do not split a node if this would result in the goodness measure falling below a threshold Difficult to choose an appropriate threshold Postpruning: Remove branches from a “fully grown” tree Use a set of data different from the training data to decide which is the “best pruned tree” Other issues related to DT CART method: produces 2 way splitbinary tree Internal nodesBoolean test on an attribute value->T/F Simpler in representation but more levels then multi-way splits Tree shape is important: DT that classifies most data records with a few tests (few levels) and uses more tests for a few records with a particular set of attribute values is more desirable How to performs attribute selection for continuous attributes? Use a threshold value to split the values into to partition, use relational condition for the testfind calculate attribute selection measure Advantages of DT Explains why the decision is made through a classification rule Classifies unseen records efficiently. Classification time depends on the 3 of levels of the tree Can handle categorical and continuous attributes Weaknesses of DT Have high error rates Computationally difficult to build as recursive functions used