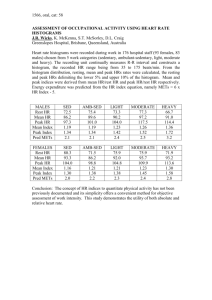
Artificial Data / Random
advertisement

D:\106732405.doc
2/13/2016
Artificial data
E x a bx (1.1)
E E 2
i
I E E Bkg ( E Ei ) ci exp
(1.2)
w
i 1
i
1/3
Changing the d12 to d6 shows a more typical
experiment. In general the constants a,b,cj,wj,Ej,dj, and
dj+1 need to be determined along with their standard
deviations.
m
2
Bkg E
d d
m
j 1,2
j
E (1.3)
3
j 1
<beginning of file> for/BKG.FOR
IMPLICIT REAL*8 (A-H,O-Z)
DIMENSION D(2)
PARAMETER (N=5000,M=2)
DATA D/1D0,511D0/
OPEN(1,FILE='BKG.OUT')
H=600D0/N
DO I=1,N
E=(I-.5D0)*H
BKG=0
DO J=1,M,2
IF(E.LT.D(J+1))THEN
SP=(D(J+1)-E)**3
BKG=BKG+E**2*SP
ENDIF
ENDDO
WRITE(1,'(2G15.6)')E,BKG
ENDDO
END
<end of file>
bkg.for - Lines transferred = 18
RUN
<hold>
<beginning of file>for\PEAK.FOR
IMPLICIT REAL*8 (A-H,O-Z)
PARAMETER (N=5000)
DATA CJ/1D12/,EJ/511D0/WJ/10D0/
OPEN(1,FILE='PEAK.OUT')
H=600D0/N
DO I=1,N
E=(I-.5D0)*H
ARG=(E-EJ)/WJ
PEAK=CJ*EXP(-ARG*ARG)
WRITE(1,'(2G15.6)')E,PEAK
ENDDO
END
The standard deviation is the difference between the
value determined in a single experiment, and that that
would be determined by repeating the experiment an
infinite number of times. It is not the difference
between the correct answer and that given by the
experiment.
The data observed is not the number given by
the two codes above, but differs by a “random amount”.
In many cases it differs by a Gaussian centered at the
data value so that
2
1 M
I m E I E I E (1.4)
M m 1
D:\public_html\class2K\Progdet\sorting\Random.htm
Psuedo Random numbers
Random numbers are not wanted. What is
desired is a set of completely reproducible numbers that
are the same on all computers and in both C and
Fortran. In addition, it must be true that the numbers
give all averages the same as would be given by actual
random numbers. In practice the numbers should be reinitialized with the numbers needed to recreate the
desired set written out as
17894561 3678991
18345899 234567899
...
D:\106732405.doc
2/13/2016
In this way, when the code bombs after 23 hours or
running, the situation just before the bomb can be
recreated by simply entering these numbers.
With this many random numbers, the
"randomness" of the set can be a problem for some
calculations1. The method used here, first suggested by
MacLaren and Marsaglia2, is to insert numbers into a
table with a multiplicative congruential method with
one multiplier and seed and to extract them from the
table with a multiplicative congruential method with a
different multiplier and seed. random.for contains the
common
COMMON/RAN/IX,IY,ITAB(128)
RANDOM.CPP RANDOM.H
The file random.h contains
struct {int ix,iy,itab[128];} ran;
int rseed(int ix,int iy);
double rndmf();
2/3
b gzf (a bb agx)dx
1
f b a
0
now select x positions uniformly and randomly between
0 and 1 and average them so that
xi Rand (1.)
f
bb agL 1 f (a bb agx )
N
N N
i
i 1
"obvious" error analysis
The expected error in f N can be estimated by
considering each random selection as an independent
estimator of f N and then averaging the squares of
the differences to yield
2
1 N
2N f (b b a xi ) f N
N i 1
c b g
1
f (a b
b ag
x)
N
h
N
2
i
i 1
The seeds are ix and iy. The random number set is
initialized by calling rseed(ix,iy). This call causes 128
numbers to be fed into the table itab[128] with one
random number generator. The call x=rndmf() gives a
random number base on ix,iy and itab, between 0 and 1.
It selects this by advancing ix and iy, pulling a value
from a randomly selected table entry and replacing that
with a new value.
This can be re-initialized by printing out ix and
iy and then calling rseed. This wastes 128 random
numbers, but gives a completely determined new set of
random numbers.
Simple Monte Carlo Integration
z
2 f N
N
f ( x)dx
a
Change variables such that x=a+(b-a)*x'. dx = (b-a)dx'
1
R. L. Coldwell, "Correlational Defects in the Standard
IBM 360 Random Number Generator and the Classical
Ideal Gas Correlation Function", J. Computational
Phys. 14, 223 (1974).
2
M. D. MacLaren and G. Marsaglia, J. Assoc. Comput. Mach. 12
(1965),83
b g
f (a b a xi )
i 1
h N 2 f f
2
2
N
f 2N
N
N
1
i 1
2
N
h 2 N h 2N
as the rms difference between h and any single
estimator. The expectation value of the sum is then N
times N so that the deviation in the sum is
2sum N 2N
and the expected error in the sum is
sum N N
while the expected error in the average is
N
b
f
N
sum
N
N
N
so that
f 2 f 2
N
cpp\trandom.c cpp\random.c cpp\random.h
f f N
#include <stdio.h>
#include <math.h>
#include "random.h"
void main(void)
{int n,ir,ix=37,iy=72;
double sum,sum2,err,xtemp;
rseed(ix,iy);
D:\106732405.doc
2/13/2016
for (ir=0;ir<10;++ir)
{printf(" rseeds %10d %10d
",ran.ix,ran.iy);
rseed(ran.ix,ran.iy);
sum=0;
sum2=0;
for (n = 0; n <= 99; ++n)
{xtemp=rndmf();
sum+=xtemp;
sum2+=xtemp*xtemp;}
sum=.01*sum;
sum2=.01*sum2;
err=.01*(sum2-sum*sum);
err=sqrt(err);
printf("<f> %6f +- %6f <f^2>
%6f\n",sum,err,sum2);}
return;}
3/3
GRAN=GRAN+RNDMF()
ENDDO
ERR=SQRT(PEAK)*GRAN
PEAK=PEAK+SQRT(PEAK)*GRAN
WRITE(1,'(3G15.6)')E,PEAK,ERR
ENDDO
END
C$INCLUDE RANDOM
Gaussian distribution3
Rgauss=-6;
For(i=0;i<12;++i){Rgauss+=rndmf();}
1
1
f xdx
0
2
1
1
f 2 x 2 dx
0
3
Thus
1 1 1
2
2 f 2 f
3 4 12
or
z
z
12
12 f 6 rndmf
i 1
bg 6 1
This means that the above sum is 0 +- 1. To
produce a peak of height P = 36 +- 6 with a Gaussian
distribution on the six. I simply take
R
S
T
12
P 36 6 * 6 rndmf
i 1
bgU
V
W
More specifically in for\peakerr.for
IMPLICIT REAL*8 (A-H,O-Z)
PARAMETER (N=5000)
DATA CJ/1D6/,EJ/511D0/WJ/10D0/
OPEN(1,FILE='PEAK.OUT')
H=600D0/N
CALL RSEED(1377957,235789931)
DO I=1,N
E=(I-.5D0)*H
ARG=(E-EJ)/WJ
PEAK=CJ*EXP(-ARG*ARG)
GRAN=-6
DO J=1,12
3
J. M Hammersley and D. C. Handscomb, Monte Carlo
Methods, John Wiley (1964) p.39
Replacing the points
The fit to the data has an error equal to the (Err
in each data points)/(dat/M) where M is the number
constants fitted . In addition the error in each data point
can be estimated from the final value of 2. The
constants w = f(dat1,…,datN) is a function of all of the
data points. New data points can be generated by
adding Gaussian random numbers to the fit.
Thus it is possible to directly estimate
2
1 M
2f f x1 , x2 ,..., xN f xˆ1 .xˆ2 ,..., xˆ N (2.1)
M i 1
This is done by selecting all N x's as the expected
values + a random number with a Gaussian distribution
with the standard deviation of the point xi. It requires
at least M=10 to cover the odd chances and most
references recommend 25 to 30. Note that in this case
the values are averaged.