Genetic engineering - E
advertisement

NEHRU ARTS AND SCIENCE COLLEGE
DEPARTMENT OF BIOTECHNOLOGY
GENETIC ENGINEERING
Unit I
Guidelines for Genetic Engineering Research:Basic techniques-Isolation and purification of nucleic acids, Agarose gel electrophoresis,
Southern, Northern and Western blotting, Enzymology of recombinant DNA, DNA and DNA
markers
Unit II
Gene cloning vectors: Bacteriophages-Lambda and M13, Phagemids, Cosmids, Yeast
vectors, Plant and animal vectors, Restriction mapping of DNA fragments and Map
construction, DNA sequencing. Vector engineering and codon optimization.
Unit III
Cloning in E.coli,Cloning in organisms other than E.coli,Expression vectors, Fusion vectors,
Genomic library, cDNA library-types and screening, RFLP and RAPD.
Unit IV
Site-directed mutagenesis, SSCP and Hetroduplex analysis, Protein engineering: Processing
and stabilization of recombinant proteins. Applications of protein engineering.
Unit V
Gene therapy : Different types and applications, Salient features of Human genome project ;
Chromosome jumping & Chromosome walking. PCR: Types and applications,
Patenting of life forms, ethical issues in genetic engineering
GENETIC ENGINEERING
***************************************************************************
***
Unit I
Guidelines for Genetic Engineering Research:Basic techniques-Isolation and purification of nucleic acids, Agarose gel electrophoresis,
Southern, Northern and Western blotting, Enzymology of recombinant DNA, DNA and DNA
markers
ISOLATION AND PURIFICATION OF NUCLEIC ACIDS
To isolate genomic DNA
Remove tissue from organism
Homogenise in lysis buffer containing guanidine thiocyanate (denatures proteins)
Mix with phenol/chloroform - removes proteins
Keep aqueous phase (contains DNA)
Add alcohol (ethanol or isopropanol) to precipitate DNA from solution
Collect DNA pellet by centrifugation
Dry DNA pellet and resuspend in buffer
Store at 4°C
Each cell (with a few exceptions) carries a copy of the DNA sequences which make up
the organism's genome. However, many genomes are large and complex (for instance the
human genome is made up of ~3000 x 106 base pairs). A particular DNA sequence (for
instance the allele of a gene) can be very small in comparison. And it probably occurs only
once or twice within the genome (ie only one or two copies per cell). This means that a
particular DNA sequence will be present as only a (very) small part within the complex
mixture of DNA sequences that make up the genomic DNA of that organism.
It is often necessary to 'break up' large DNA molecules into smaller, more manageable
fragments - often to sizes ranging from 100 bp to 2 kb (bear in mind that each resulting DNA
fragment is an individual molecule). These smaller fragments can then be manipulated more
easily - to isolate particular DNA fragments, to characterise their molecular sequence, to
determine their function, to determine their position in relation to other sequences within the
genome, to use them to express proteins, etc.
Manipulation of the DNA
It used to be difficult to isolate enough of a particular DNA sequence to carry out
further manipulation and/or characterisation of its molecular sequence. DNA is a
macromolecule - it is made up of a sequence of lots and lots of deoxyribonucleotides. Large
DNA molecules can be fragmented using 'shearing' forces, in other words mechanical stress
to 'shred it', thus creating smaller fragments. However, the resulting fragmentation is not
reproducible - the breakage points can occur anywhere within the molecule, thus each DNA
molecule will be randomly broken down and various different-sized fragments can be
generated, any of which can have the DNA sequence of interest. A further difficulty in
isolating a particular DNA fragment is that standard chemical/biochemical methods are not
sufficient to distinguish any part of the genome from another (after all one DNA molecule is
chemically similar to another).
Progress in understanding genetic mechanisms at the molecular level was slow. Then
came the discovery of various bacterial and viral enzymes which modify and synthesise
nucleic acids (DNA and RNA), along with the means to produce more outwith the organism
from which they were originally isolated. The application of these enzymes for manipulating
DNA (no matter what the source) led to the creation of Recombinant DNA Technology
which has enabled great scientific advances in the field of biology, has created new scientific
disciplines and has revolutionised our world.
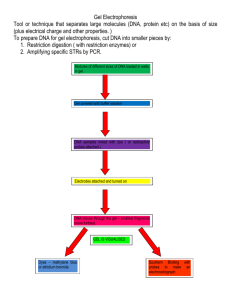
AGAROSE GEL ELECTROPHORESIS
DNA fractionation
Separation of DNA fragments in order to isolate and analyse DNA cut by restriction enzymes
Electrophoresis
Linear DNA fragments of different sizes are resolved according to their size through gels
made of polymeric materials such as polyacrylamide and agarose. For instance, agarose is a
polysaccharide derived from seaweed - and gels formed from between 0.5% to 2%
(mass/volume i.e. 0.5 to 2.0g agarose/100 ml of aqueous buffer) can be used to separate
(resolve) most sizes of DNA
DNA is electrophoresed through the agarose gel from the cathode (negative) to the anode
(positive) when a voltage is applied, due to the net negative charge carried on DNA
When the DNA has been electrophoresed, the gel is stained in a solution containing the
chemical ethidium bromide. This compound binds tightly to DNA (DNA chelator) and
fluoresces strongly under UV light - allowing the visualisation and detection of the DNA.
Like any molecule that binds to DNA, ethidium bromide is hazardous. It is a mutagen.
Gel Electrophoresis
o
Electrophoresis is the movement of molecules by an electric current.
o
Nucleic acid moves from a negative to a positive pole.
o
Nucleic acid has a net negative charge, they RUN TO RED
Electrophoresis of Nucleic Acids
Nucleic acids are separated based on size and charge.
DNA molecules migrate in an electrical field at a rate that is inversely
proportional to the log10 of molecular size (number of base pairs).
Employs a sieve-like matrix (agarose or polyacrylamide) and an
electrical field.
DNA possesses a net negative charge and migrates towards the
positively charged anode.
Applications of Electrophoretic Techniques in the Molecular Diagnostics Laboratory
Sizing of Nucleic Acid Molecules
DNA fragments for Southern transfer analysis
RNA molecules for Northern transfer analysis
Analytical separation of PCR products
Detection of Mutations or Sequence Variations
Principles of Gel Electrophoresis
o
Electrophoresis is a technique used to separate and sometimes purify
macromolecules
o
Proteins and nucleic acids that differ in size, charge or conformation
o
Charged molecules placed in an electric field migrate toward either the positive
(anode) or negative (cathode) pole according to their charge
o
Proteins and nucleic acids are electrophoresed within a matrix or "gel"
ELECTROPHORESIS
The gel itself is composed of either agarose or polyacrylamide.
Agarose is a polysaccharide extracted from seaweed.
Polyacrylamide is a cross-linked polymer of acrylamide.
Acrylamide is a potent neurotoxin and should be handled with care!
Polyacrylamide gel electrophoresis (PAGE)
Non-denaturing (Special applications in research)
Denaturing contain 6-7 M Urea (Most common)
Agarose Gel Electrophoresis
Separates fragments based on mass, charge
Agarose acts as a sieve
Typically resolve 200 bp-20 kbp
fragments <200 bp, polyacrylamide gels
fragments> 20 kbp, pulse field gels
Include DNA size standards
Factors That Effect Mobility Of DNA Fragments In Agarose Gels
Agarose Concentration
Higher concentrations of agarose facilitate separation of small DNAs, while low
agarose concentrations allow resolution of larger DNAs (Remember-inversely
proportional!)
Voltage
As the voltage applied to a gel is increased, larger fragments migrate
proportionally faster that small fragments
Charge is evenly spread (uniform) so the larger fragments will have more
charged groups
Factors That Effect Mobility Of DNA Fragments In Agarose Gels
Electrophoresis Buffer
The most commonly used for double stranded (duplex) DNA are TAE (Trisacetate-EDTA) and TBE (Tris-borate-EDTA).
Effects of Ethidium Bromide
Staining dye that inserts (intercalates) into the DNA between the nitrogenous
bases (“rungs of the ladder”) and glows when exposed to UV light
Binding of ethidium bromide to DNA alters its mass and rigidity, and therefore
its mobility
Comparison of Agarose Concentrations
Fragment Resolution: Agarose Gel Electrophoresis
Gel Electrophoresis: The Basics
The movement of molecules is impeded in the gel so that molecules will collect or form a
band according to their speed of migration.
The concentration of gel/buffer will affect the resolution of fragments of different size
ranges.
Genomic DNAs usually run as a “smear” due to the large number of fragments with only
small differences in mass
Agarose Electrophoresis of Restriction Enzyme Digested Genomic DNA
PULSE FIELD GEL ELECTROPHORESIS APPARATUS
Used to resolve DNA molecules larger than 25 kbp
Periodically change the direction of the electric field
Several types of pulsed field gel protocols
FIGE: Field inversion gel electrophoresis
TAFE: Transverse alternating field electrophoresis
RGE: Crossed field electrophoresis
CHEF: Contour-clamped homogeneous electric field
ENZYMOLOGY OF RECOMBINANT DNA
Enzymes that can cut (hydrolyse) DNA duplex at specific sites. Current DNA technology is
totally dependent on restriction enzymes.
Restriction enzymes are endonucleases
Bacterial enzymes
Different bacterial strains express different restriction enzymes
The names of restriction enzymes are derived from the name of the bacterial
strain they are isolated from
Cut (hydrolyse) DNA into defined and REPRODUCIBLE fragments
Basic tools of gene cloning
Names of restriction endonucleases
Titles of restriction enzymes are derived from the first letter of the genus +
the first two letters of the species of organism from which they were isolated.
EcoRI
BamHI
-
HindIII
PstI
Sau3AI
from
from
-
AvaI - from Anabaena variabilis
from
Escherichia
Bacillus
Haemophilus
coli
amyloliquefaciens
influenzae
from
Providencia
stuartii
from
Staphylococcus
aureus
Restriction enzymes recognise a specific short nucleotide sequence
This is known as a Restriction Site
The phosphodiester bond is cleaved between specific bases, one on each DNA
strand
The product of each reaction is two double stranded DNA fragments
Restriction enzymes do not discriminate between DNA from different organisms
Most restriction enzymes will cut DNA which contains their recognition sequence, no
matter the source of the DNA
Restriction endonucleases are a natural part of the bacterial defence system
Part of the restriction/modification system found in many bacteria
These enzymes RESTRICT the ability of foreign DNA (such as bacteriophage
DNA) to infect/invade the host bacterial cell by cutting it up (degrading it)
The host DNA is MODIFIED by METHYLATION of the sequences these
enzymes recognise
o
Methyl groups are added to C or A nucleotides in order to protect the
bacterial host DNA from degradation by its own enzymes
Fig 7-5b, Lodish et al (4th ed)
Types of restriction enzymes
Type I Recognise specific sequences·but then track along DNA (~1000-5000
bases) before cutting one of the strands and releasing a number of nucleotides
(~75) where the cut is made. A second molecule of the endonuclease is required
to cut the 2nd strand of the DNA
o
e.g. EcoK.
o
Require Mg2+, ATP and SAM (S-adenosyl methionine) cofactors for
function
Type II Recognise a specific target sequence in DNA, and then break the DNA
(both strands), within or close to, the recognition site
o
e.g. EcoRI
o
Usually require Mg2+
Type III Intermediate properties between type I and type II. Break both DNA
strands at a defined distance from a recognition site
o
e.g. HgaI
o
Require Mg2+ and ATP
Hundreds of restriction enzymes have been isolated and characterised
Enables DNA to be cut into discrete, manageable fragments
Type II enzymes are those used in the vast majority of molecular biology
techniques
Many are now commercially available
Each restriction enzyme will recognise its own particular site
Some recognise very short sequences consisting of only 4 base pairs. These tend
to cut DNA more frequently (generating smaller fragments) as the likelihood that
any stretch of DNA sequence will contain these minimal recognition sites is high.
approximately 1 site per 256 bases ([1/4]4)
Some require longer recognition sequences (up to 8 bp). The longer the
recognition sequence the less frequently these sites are likely to occur in any
particular DNA sequence. Enzymes which cut DNA very infrequently are known
as RARE cutters.
an 8 bp recognition site will occur approximately 1 per 65,536 bases
([1/4]8)
The sites occur more randomly than predicted, so that digestion by any one enzyme will
generate DNA fragments of different lengths
Some recognise more than one sequence
There are restriction enzymes which allow substitutions in one or more positions
of their recognition sequences.
Most common substitutions
o
purines (A or G), designated R
o
pyrimidines (C or T), designated Y
o
any nucleotide, designated N
For example HincII will allow two substitutions in each of two sites. It recognises and
cuts 4 different sequences.
5'-G T C GA C-3'
5'-G T T G A C-3'
3'-C A G C T G-5'
3'-C A A C T G-5'
5'-G T C A A C-3'
3'-C A G T T G-5'
5'-G T T A A C-3'
3'-C A A T T G-5'
The consensus HincII recognition site is designated 5'-G T Y R A C-3'
Many Type II restriction endonucleases recognise PALINDROMIC sequences
Symmetrical sequences which read in the same order of nucleotide bases on each
strand of DNA (always read 5'
For example, EcoRI recognises the sequence
5'-G A A T T C-3'
3'-C T T A A G-5'
The high specificity for their recognition site means that DNA will be cut reproducibly
into defined fragments
Generate restriction maps
Isolate and clone specific DNA fragments
Different enzymes cut at different positions and can create single stranded ends
('sticky ends')
Some generate 5' overhangs - eg: EcoRI
Some generate 3' overhangs - eg: PstI
Some generate blunt ends - eg: SmaI
Examples of restriction enzymes and the sequences they cleave
Source microorganism
Enzyme
Recognition Site
Ends produced
Arthrobacter luteus
Alu I
AG*CT
Blunt
Bacillus amyloiquefaciens H
Bam HI
G*GATCC
Sticky
Escherichia coli
Eco RI
G*AATTC
Sticky
Haemophilus gallinarum
Hga I
GACGC(N)5*
Sticky
Haemophilus infulenzae
Hind III
A*AGCTT
Sticky
Providencia stuartii 164
Pst I
CTGCA*G
Sticky
Nocardia otitiscaviaruns
Not I
GC*GGCCGC
Sticky
Staphylococcus aureus 3A
Sau 3A
*GATC
Sticky
Serratia marcesans
Sma I
CCC*GGG
Blunt
Thermus aquaticus
Taq I
T*CGA
Sticky
The 'sticky' overhangs are known as COHESIVE ENDS
The single stranded termini (or ends) can base pair (ANNEAL) with any
complementary single stranded termini
This is the basis for RECOMBINANT DNA TECHNOLOGY
Inserting foreign DNA into a cloning vector
Restriction enzymes are a useful tool for analysing Recombinant DNA
After ligating a particular DNA sequence into a cloning vector, it is necessary to check
that the correct fragment has been taken up. Sometimes it is also necessary to ensure that
the foreign DNA sequence is in a certain orientation relative to sequences present in the
cloning vector.
Checking the size of the insert
Checking the orientation of the insert
Determining pattern of restriction sites within insert DNA
DNA MARKERS
DNA markers are easily recognizable pieces of DNA that flag the location of particular
genes.
DNA markers are a gene technology that can help speed up the breeding of conventional
(not genetically modified) plant varieties.
DNA markers make incorporating desirable genes into new plant varieties more accurate.
DNA markers are a gene technology tool that helps breeders conventionally breed new plant
varieties. The resultant new plant varieties are not genetically modified (GM).
Breeding plants
DNA markers
Breeding plants
When developing new plant varieties, plant breeders typically want to combine the best genes and
associated traits of two parents into a singular new plant variety.
To conventionally breed a new plant variety two closely related plants are ‘sexually crossed’. The
aim is to combine the favourable traits from both parent plants and exclude their unwanted traits
in a singular new and better plant variety.
However, the progeny of sexual crosses inherit a mix of genes from both parent plants and so
both positive and negative traits may be inherited. Breeders have to look at all the progeny and
select the ones with the most positive traits and least negative traits. They then cross this selected
progeny back to one of the original parent plants to try and transfer more of its positive traits into
the following generation. This process called ‘back-crossing’ takes place over a number of
generations, which usually means a number of years, until the progeny has all the desirable traits
and none of the negative ones of the original two parent plants.
DNA markers
DNA markers help breeders speed up the breeding process significantly and they are also used to
improve breeding accuracy.
A DNA marker is like an easily recognisable flag that identifies the presence of a useful or
desirable gene. With anywhere between 25 000 and 50 000 genes in plants, finding if a desirable
gene is present can be very hard. In the past often the only way to work out if a gene was present
in the progeny of a cross was to grow the plant and see if it displayed the trait of interest.
For example, if breeders were trying to breed a gene for disease resistance into a new wheat
variety they would have to grow the new wheat plants then expose them to the disease and
observe which ones displayed resistance. This growing process can take many months, adding to
the length of time it takes to develop a new plant variety. It is also possible that other factors may
be helping the wheat variety to display resistance and the disease-resistance gene may not even be
present in those plants that appear to be coping well.
With DNA markers, breeders can simply take a DNA sample from the seed or seedling and
almost immediately determine if the desirable gene is present by checking for the DNA marker.
So not only can the process of breeding be sped up but also there is no confusion that the gene is
actually present and therefore its associated trait will be present too.
Identifying DNA markers in the first place can also take some time as most DNA markers are
unique to a particular gene, but it is their specificity that makes them so helpful.
Linked DNA Markers
All of the DNA (RFLP or PCR) markers that we have discussed so far have been targeted to a
specific gene. For many important traits, the actual gene of interest is not known. Therefore,
probing for the presence of the normal or mutated allele is not possible. Instead the probe
recognizes a sequence that is close to the actual gene of interest. The only drawback to screening
with a probe that is near, but not actually in the gene, is that an error in diagnosis can occur if a
recombination event occurs between the marker and the actual gene of interest. The error is
directly proportional to the distance that the marker is from the gene.
The following illustration shows the relationship between two markers and a gene.
Marker 1
1 cM
Gene Marker 1
|
|
___________________________________________
Marker 2
5 cM
Gene
|
Marker 2
|
___________________________________________
Recombination is less likely to occur between marker 1 and the gene than between marker 2 and
the gene. Actually there is only a 1% chance the linkage between marker 1 and the gene will be
broken. For diagnostic purposes 99% of the time the individual with marker 1 will have the
specific allele of the gene of interest. Marker 2 is 95% accurate in diagnosing the specific allele at
the gene of interest. Obviously, the closer the marker is to the gene the more accurate the testing
procedure. But the best probe still is one that actually hybridizes to the particular gene that is in
question.