Software Quality Report
advertisement

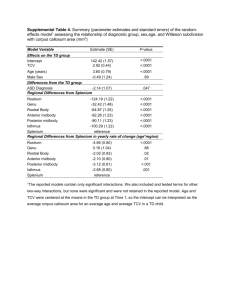
Software Quality Report Evaluating Software by Decision Coverage, Complexity, and Time to First Failure Report Overview This report provides a guide for predicting software quality from metrics obtained from the software model and testing process. Several randomly selected modules from the software portfolio will be examined. Decision coverage, the testing process metric, is the proportion of Boolean expressions in a program that have been exercised during testing. Complexity, the software module metric, is based on cyclomatic complexity or the number of independent paths in a module. The quality score is the execution time to first failure after the module has been released. Two teams determined the quality scores; thus a dummy variable may be incorporated to account for scoring bias. The data obtained is from project management records and incident reports. Model Evaluation Quality Score= 46.76 + 0.66Decision – 6.95Complexity 1. Outliers There are no outliers in our data. 2. Signs of the Coefficients The signs of the coefficients appear correct. The plot of quality score vs. complexity reveals that quality decreases as complexity increases (graph 1). The plot of quality score vs. decision coverage reveals that quality increases with decision coverage (graph 2). See graphs below. Graph 1 Graph 2 3. P-value The p-value in the Parameter Estimates section of the proc reg output tells s whether the response variable (quality score) is dependent upon the explanatory variables (decision coverage and complexity). Both p-values are <.0001, so this gives us strong evidence that quality score is dependent on both decision coverage and complexity, and therefore our regression model is accurate. 4. R squared and Correlation R squared is the measure of how well the regression line approximates the actual data points. Our equation had an r squared value of 0.9846. This value is extremely close to 1, which means our regression line approximates the data points almost perfectly. (See Appendix 2) Correlation is the measure of the strength of the linear relation between x and y, the independent and dependent variables. The correlation between the independent variable decision and the dependent variable quality is 0.64927. This figure suggests an above average positive correlation between these two variables. The correlation between the independent variable complexity and the dependent variable quality is –0.82612. This figure suggests a strong negative correlation between the two variables. (See Appendix 4) As for the correlation among variables, the correlation between the two independent variables decision and complexity is –0.12595. This suggests a very slightly negative, but almost non-existent correlation. 5. Residuals In examining the residual plots for Decision Coverage and Complexity, there are no extremely large residuals (and hence no apparent outliers), and there is no trend in the residuals to indicate that the linear model is inappropriate. The pattern of residuals in both cases indicates homogenous error variance across values of x. Recommendations: Testing on the chosen metrics reveals a well-fitting model that can be used to predict the quality of future programs. However, one must be careful in extrapolating too far, because the data for both complexity and decision coverage vs. quality score (see graphs 1 & 2 above) seem to be more widely scattered for lower values, and narrower for higher values. Further Analysis: We mentioned above the possibility of incorporating a dummy variable for Quality Team. Examination of the quality score graph reveals a normal distribution whereas splitting the quality scores by team reveals that Team 0 scores center around 54 while those of Team 1 are slightly higher at 66. See graphs below. Thus, the use of a dummy variable appears justified. In the regression that includes dummy variables (Appendix 4) the sign of the variable (+) is correct since those of the QualityTeam=1 are higher. See Appendix 3. Graph 3 Graph 4 Nevertheless, when we examine the standard errors and t-values for the intercept, Decision Coverage, and Complexity, we cannot justify the use of the dummy variable. The standard errors increase when the dummy variable is used, and the t-values decrease. Both of these factors indicate that the model is a poorer fit. Thus, we chose not to incorporate Quality Team in our model. Appendix 1 Data The SAS System Obs 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 Decision Coverage 30 30 30 35 35 35 40 40 40 45 45 45 45 45 45 50 50 50 50 50 50 55 60 60 60 60 60 65 65 70 70 75 75 75 75 75 16:42 Tuesday, May 13, 2003 Complexity 4.5 5.5 6.5 2.0 2.5 7.5 2.0 3.1 4.5 2.1 2.5 3.5 5.5 6.5 8.1 2.8 3.2 4.1 4.5 6.5 8.3 7.5 3.5 4.0 4.3 5.5 7.1 3.3 6.2 2.5 3.1 2.5 3.3 3.5 4.5 5.3 Quality 37.28 27.22 23.74 57.30 52.23 14.82 59.49 52.13 41.23 56.55 58.78 54.49 38.34 28.92 21.52 64.82 59.79 54.23 47.27 34.40 24.34 32.58 61.82 57.85 53.27 46.60 36.70 69.24 46.29 75.27 69.70 79.84 77.46 69.47 65.40 61.69 Module Name nonpar mak1 wcnt pld ls2 cp01 nnlin plst3 push ksort plart mrs1 peek parcnt ls cws cal col sortqk loc plst4 pprnt nndt1 plst2 spl pprnt2 trl lp1 mftp lws qw emac3 ttyp ltyp ping1 pingq 1 Quality Team 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Appendix 2 The REG Procedure (without dummy variables) The REG Procedure Model: MODEL1 Dependent Variable: quality Quality Analysis of Variance Source DF Sum of Squares Mean Square Model Error Corrected Total 2 33 35 9963.23896 156.54814 10120 4981.61948 4.74388 Root MSE Dependent Mean Coeff Var 2.17805 50.33528 4.32708 R-Square Adj R-Sq F Value Pr > F 1050.11 <.0001 0.9845 0.9836 Parameter Estimates Variable DF Intercept decision complexity 1 1 1 Parameter Estimate 46.76243 0.66497 -6.95206 Standard Error t Value Pr > |t| 1.77135 26.40 <.0001 0.02620 25.38 <.0001 0.20061 -34.65 <.0001 Appendix 3 The REG Procedure with dummy variables Model: MODEL1 Dependent Variable: quality Quality Analysis of Variance Source DF Sum of Squares Mean Square Model Error Corrected Total 3 32 35 9963.77522 156.01187 10120 3321.25841 4.87537 Root MSE Dependent Mean Coeff Var 2.20802 50.33528 4.38663 R-Square Adj R-Sq F Value 681.23 Pr > F <.0001 0.9846 0.9831 Parameter Estimates Variable DF Intercept decision complexity quality 1 1 1 1 Parameter Estimate 47.31145 0.65176 -6.97524 0.44446 Standard Error 2.44233 0.04788 0.21504 1.34013 t Value Pr > |t| 19.37 13.61 -32.44 0.33 <.0001 <.0001 <.0001 0.7423 Appendix 4 The CORR Procedure 3 Variables: decision complexity quality Simple Statistics Variable N decision 36 complexity 36 quality 36 Mean Std Dev 52.36111 4.49444 50.33528 14.16667 1.84993 17.00402 Sum 1885 161.80000 1812 Minimum Maximum 30.00000 2.00000 14.82000 75.00000 8.30000 79.84000 Pearson Correlation Coefficients, N = 36 Prob > |r| under H0: Rho=0 decision decision complexity quality complexity quality 1.00000 -0.12595 0.4642 0.64927 <.0001 -0.12595 0.4642 1.00000 -0.82612 <.0001 0.64927 <.0001 -0.82612 <.0001 1.00000