Results:

Results:
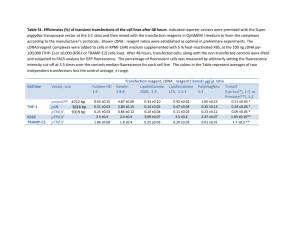
Plasmids p0789 and p… where cut using restriction enzymes EcoR I and BamH I and ran on 1% agarose gel after the completion of the miniprep. There yielded no significant bands that could be distinguished as vector DNA or inserted DNA (see figure 1) which were expected to be around the 4.5 kbp range and 1.5 kbp range respectively.
Pics of both gels with captions underneath
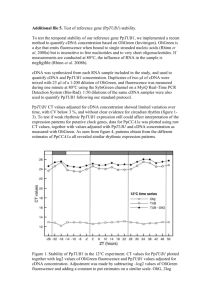
With inconclusive evidence that an insert exists within either p0789 or p…, a new plasmid was acquired from a previous years experiment. This plasmid, p5004, was sent to Ohio State University to be sequenced and a chromatogram and sequence were returned. Using the chromatogram results it was determined that nucleotides 1-30 were unacceptable and that nucleotides 648 through the end were also unable to be accounted for within our analysis. After finding the Sal I site and deleting all vector DNA prior to this site, our cDNA sequence (figure 2) was 618 base pairs.
ATACGCCTAGCTCTAATACNCTCACTATAGGGAAAGCTGGTACGCCTGCAGG
TACCGGTCCGGAATTCCCGGGTCGACCCACGCGTCCGGATTCAAAAGAGTTC
TTTCTCTCTATCTTATTCTCCGATCATCATGNTTGCAGCAGCCACCACCCGGA
GGTATCCTTCCACATCACGCTCCTCCTCCTTCTGCGCAACAACAGTACGGTTA
CCAACAACCTTACGGGATTGCNTGGAGCTGCTCCACCACCACCACAGATGTG
GAATCCTCAAGCGGCGGCGCCGCCATCAGTTCAGCCTACGACCGCTGACGAG
ATCCGGACTCTTTGGATCGGGGACTTACAGTATTGGATGGATGAGAATTTCCT
CTACGGTTGCTTTGCTCATACCGGAGAGATGGTTTCTntATAAAGTGATTCGTA
ACAAGCAAACCGGTCAAGTTGAAGGATACGGTTTCATTGAATTCGCATCTCA
TGCTGCTGCTGAAAGAGTTCTACAAACATTCAACAACGCTCCTATCCCGAGCT
TTCCTGATCAGCTCTTTAGACTGAACTGGGCATCATTGANTTCANGAGAATAA
AACGAGACGATTCACCGGGACTACAACGATAATTTGTCG
Figure 2. DNA sequence after extraction of vector DNA.
With the cDNA sequence, a BLAST search was performed to determine the possible proteins our sequence encoded. The top five matches are given below. The first match was decided to be the best fit for out sequence because of it high likelihood (e-154) and because it matched a previously sequenced Arabidopsis thaliana chromosome 1 BAC
F25C20 sequence.
Score E
Sequences producing significant alignments: (bits) Value gi|4760411|gb|AC007296.2|F25C20 Arabidopsis thaliana chromo... 553 e-154 gi|28465834|dbj|AU301107.1| Cyprinus carpio cDNA clone: 3-0... 151 1e-33 gi|28465835|dbj|AU301108.1| Cyprinus carpio cDNA clone: 3-0... 149 6e-33 gi|17939848|emb|AJ271468.1|ATH271468 Arabidopsis thaliana m... 147 2e-32 gi|28465839|dbj|AU301112.1| Cyprinus carpio cDNA clone: 3-0... 141 1e-30
When our cDNA sequence was compared to the Arabidopsis thaliana chromosome 1
BAC F25C20 sequence discovered in the blast search we identified our cDNA to encode for a protein similar to gb|U90212 DNA binding protein ACBF from Nicotiana tabacum and contains 3 PF|00076 RNA recognition motif domains. The alignments can be seen in figure 3.
Alignments
Our cDNA contained sequence from the fifth and sixth exons of the gene discovered on chromosome 1 of the Arabidopsis thaliana genome. The gene contained a total of six exons. It stretched from basepairs 75831-76009 on exon five and for the entire length of exon six (figure 4). The open reading frame for our sequence was then determined through comparison with that of the protein that to our DNA sequence and can be shown in figure 5. c DNAtoEXON.jpg
MMQQPPPGGILPHHAPPPSAQQQYGYQQPYGIAGAAPPPPQMWNPQAAAPPSV
QPTTADEIRTLWIGDLQYWMDENFLYGCFAHTGEMVSAKVIRNKQTGQVEGYG
FIEFASHAAAERVLQTFNNAPIPSFPDQLFRLNWASLSSGDKRDDSPDYTIFVGDL
AADVTDYILLETFRASYPSVKGAKVVIDRVTGRTKGYGFVRFSDESEQIRAMTEN
GVPCSTRPMRIGPAASKKGVTGQRDSYQSSAAGVTTDNDPNNTTVFVGGLDASV
TDDHLKNVFSQYGEIVHVKIPAGKRCGFVQFSEKSCAEEALRMLNGVQLGGTTV
RLSWGRSPSNKQSGDPSQFYYGGYGQGQEQYGYTMPQDPNAYYGGYSGGGYS
GGYQQTPQAGQQPPQQPPQQQQVGFSY
Figure 5. The open reading frame for our sequence.