Homework 1 is assigned
advertisement

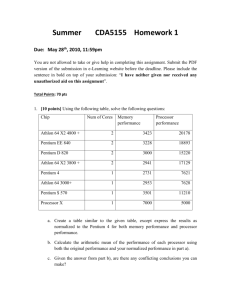
Summer 2008 CDA5155 Homework 1 Date assigned: May 21, 2008 Due date: June 2, 2008 (11:59 pm) (On-campus and EDGE students have the same deadline.) Total Points: 100 pts Exercise 1 (5/5/5/5pts=20pts) Using the following table, solve the following questions: a. Create a table similar to the given table, except express the results as normalized to the Athlon 64 X2 3800+ for each benchmark. b. Calculate the arithmetic mean of the performance of each processor. Using both the original performance and your normalized performance. c. Given the answer from part b), are there any conflicting conclusions you can make? d. Calculate the geometric mean of the normalized performance of the dual processors and the geometric mean of the normalized performance of the single performance of the single processors for the Memory benchmark. Chip Athlon 64 X2 4800 + Pentium EE 840 Pentium D 820 Athlon 64 X2 3800 + Pentium 4 Athlon 64 3000+ Pentium $ 570 Processor X Num of Cores Memory Performance Dhrystone Performance 2 2 2 3423 3228 3000 20178 18893 15220 2 1 1 1 1 2941 2731 2953 3501 7000 17129 7621 7628 11210 5000 Exercise 2 (5/5/10pts=20pts) a. You bought a new dual-core Pentium processor and you want to optimize your software for the new processor. You have two main applications. When the two application run together, the first application needs 70% resource while the second needs 30%. If 60% of the first application is parallelizable, how much speed up you would achieve with that application if run in isolation? b. You bought a new dual-core Pentium processor and you want to optimize your software for the new processor. You have two main applications. When the two application run together, the first application needs 70% resource while the second needs 30%. If 60% of the first application is parallelizable, how much overall system speedup you would observe if you parallelized it? c. Suppose a program runs in 100 seconds on an enhanced machine. The enhanced machine uses a new multiplier that is 3 times faster compared to the multiplier in the original machine. The multiplication operations take 25 seconds in the enhanced machine (i.e. 25% of the overall time in the enhanced machine). Show how Amdhal’s law (directly or indirectly) can be used to compute the execution time of the program in the original machine? Exercise 3 (5/5/5/5pts=20pts) A certain machine with a 10ns clock period can perform jumps (2 cycle), branches (3 cycles), arithmetic instructions (1 cycles), multiply instructions (4 cycles), and memory instructions (20 cycles). A certain program has 5% jumps, 20% branches, 40% arithmetic, 5% multiply, and 30% memory instructions. Answer the following questions. Show your derivation in sufficient detail. a. What is the CPI if this program on this machine. b. If the program executes 10^9 instructions, what is its execution time? c. A 4-cycle multiply-add instruction is implemented that combines an arithmetic and a multiply instruction. 25% of the multiplies can be turned into multiply-adds. What is the new CPI? d. Following (3) above, if the clock period remains the same, what is the program’s new execution time? Exercise 4 (10/5/5pts=20pts) Assume that values A, B, C and D reside in memory. Also assume that instruction operation codes are represented in 8 bits, memory addresses are 64 bits and register addresses are 8 bits. Assume all the data are 32-bits, and the instruction lengths are in the table. a. Write the code sequence for D=A+B*A+C for the following instruction set architectures: 1) Stack; 2) Accumulator; 3) Register (Register-memory); 4) Register (Load-Store). (You can refer to class slides, or Figure B.1-B.2 on page B-4 of the Appendix B ) b. Compute the total instruction number and code size for each sequence you get. c. Compute how many bytes are transferred to or from the memory in executing the code sequences, including fetching instructions, read data, write data. ISA Stack Accumulator Register-memory Load-Store Instruction Length (bits) 8 or 72 72 32 or 80 or 88 32 or 80 Exercise 5 (10/5/5pts=20pts) The value represented by the hexadecimal number FEDC BA98 7654 3210 is to be stored in an aligned 64-bit double word. a. Using the physical arrangement of the first row in Figure B.5 (Page B-8), write the value to be stored using Big Endian byte order. b. Using the same physical arrangement as in part a), write the value to be stored using Little Endian byte order. c. What are the hexadecimal values of all misaligned 4-byte words that can be read from the given 64-bit double word when stored in Big Endian byte order? d. What are the hexadecimal values of all misaligned 2-byte words that can be read from the given 64-bit double word when stored in Little Endian byte order?