Today: Dummy variables.
advertisement

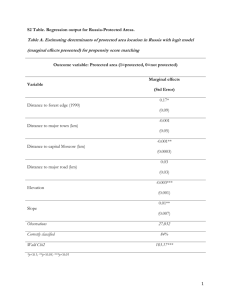
Today: Dummy variables. Dummy variables in a multiple regression, regression wrap up. Looking back in regression, we’ve looked at how an interval data response y changes as an interval data explanatory variable x. Changes. Example: Number of books read (y) as a function of television watched (x). Y = a + bX + e Last time, we expanded this idea to consider more than one explanatory / independent variable at the same time, where all the variables were interval data. This is called ______________________. Example: Wins as a function of goals for and goals against. Y = a + b1X1 + b2X2 + e This time, we’re going to drop the requirement for the independent variables to be independent data. We’re going to look at nominal data as independent data. Recall: Nominal means name. It’s data in _________with no natural _________ Example: Type of Fruit --- Kumquat, Coconut, Tomato, Dragonfruit. How do you put a type of fruit into a formula like this: = a + bX With a __________________. “Dummy” in this case just means a simple number variable (0 or 1) that we use in the place of nominal, and sometimes ordinal, data. We’ve already used dummy variables. Bearded dragon gender: 0 = Male, 1 = Female Bearded dragon colour: 0 = Green, 1 = Fancy Other possibilities: 0 = Non-Smoker, 1 = Smoker 0 = Domestic Student, 1 = International Student 0 = Eastern, 1 = Western Nominal data can have more than two categories, but we can’t do this: Favourite colour: 0 = Blue, 1 = Green, 2 = Red This would imply an order, and that having a favourite colour of green is somehow the middle ground between favouring blue and favouring red.* *If we cared about wavelength of favourite perhaps, but usually not Ordinal data can made into a 0,1,2,… scale, as long as we assume the differences between each category and the next one are about the same. 0 = Against, 1 = Neutral, 2 = For Or -1 = Against, 0 = Neutral, 1 = For Then we’re treating the ordinal data like interval data. Handling more than two categories is a for-interest topic, at the end of the lecture if time permits. It’s all just words until we get up and do something about it. Dummy variables in regression: Consider the NHL data set. Let’s see the difference in defensive skill between the Eastern and Western conferences, and by how much. Dependent variable: Goals against. (More goals against means weaker defence) Independent variable: Conference. (East or West) In our data set, we have conference listed in two different ways. ConfName: E or W. Conf: 0 or 1. 0 = Eastern Conference, 1 = Western Conference. ConfName is for when we need conference as nominal. Conf is our dummy variable for when we need interval data. We can do a regression by using Conf as our independent. (SPSS won’t even let you put Confname in) (Done under Analyze Regression Linear) We get this model summary. The conference alone explains .122 of the variance in goals against. There’s a lot to goals against that isn’t explained simply by whether you are in the Eastern or Western Conference. We get these coefficients. The prediction formula is: (Goals against) = 232.867 – 17.333(Conference) The intercept is the response (Goals against) when the explanatory variable x = 0. Here, x=0 means Eastern Conference. The intercept is the average Goals Against of teams in the Eastern Conference. The slope is the amount that (Goals Against) changes when (Conference) increases by 1. Changing x=0 to x=1 means switching for the Eastern to the Western Conference. So the slope b is the difference in mean goals against between the conferences. Here, Western Conference teams let in 17.333 fewer goals. Plugging in x=0 or 1… 232.867 – 17.333(0) = _________ goals against if East 232.867 – 17.333(1) = _________ goals against if West Since there’s only one independent variable, and it’s nominal, so we COULD do this with a two-tailed independent t-test. Analyze Compare Means Independent-Sample T Test ConfName would be the grouping variable. We would get the same results: A difference of 17.333 and a 2-tailed p-value of 0.059. So why do we bother with regression and dummy variables at all? Greenland has the fastest moving glaciers in the world. Multiple regression using a dummy variable. Let’s go back to predicting wins. Before, we modelled wins using goals for (GF) and goals against (GA). Now we can consider conference alongside everything else. Your conference (East or West) is part of what determines the teams you play against. Teams that play against weak opponents tend to win more. Will conference explain anything about wins that Goals For and Goals Against can’t? In an SPSS multiple regression, we just include the dummy variable in the list of independents like everything else. First, the model summary. Considering goals for, goals against AND conference. 82.9% of the variance in the number of wins can be explained by these three things together. Going back to last day, considering only Goals For and Goals Against, we also got an R square of 0.829. In other words, adding conference into our model told us __________________about wins than goals weren’t already covering. The R square of the model is the same with or without conference. That means just as much variance is explained by considering only goals for/against as by considering both goals for/against and the conference of the team. Conference contributes nothing extra. This is probably because the strength of your opponents is already reflected in the goals for / goals against record. It’s not like goals against weak teams count for more. The coefficient table for Wins as a function of Goals For/Against and Conference: The fact that conference isn’t improving the model any is reflected in its significance. If it’s slope were really zero, we’d still a sample like this .952 of the time. (p-value = .952) The regression equation is: (Estimated Wins) = 37.637 + 0.178(GF) – 0.167(GA) + 0.082(West Conf.) Meaning being in the west meant winning 0.082 more games. But (Estimated Wins) = 37.637 + 0.178(GF) – 0.167(GA) + 0.082(West Conf.) …is more complicated than (Estimated Wins) = 37.950 + 0.177(GF) – 0.163(GA) … which is the model from last day that ignored conference. But knowing the conference doesn’t change anything. - The r2 was .829 whether we included conference or not. - We failed to reject the null that the effect of conference was zero (__________________Goals For/Against ). In that case, we can use the simpler model that only uses goals and not lose anything. We should always opt for a simpler model when nothing is lost in doing so. This is called the __________________. "Make everything as simple as possible, but not simpler." - Nikola Tesla Comments about r2 in multiple regression. Like with single variable regression, r2 must be between 0 and 1. 0 is none of the variance is explained. 1 is all of it is explained. If you add more and more variables into your model, you will eventually reach r2 = 1, where you have enough data to model and predict the response perfectly. But each variable uses up a degree of freedom and makes the results harder to interpret. Just because you can include a variable doesn’t mean you should. (Resting heart rate) = a + b1(Age) + b2(Body Mass Index) + b3(L of Oxygen per Minute) + b4(Height) + b5(Number of Freckles) + b6(Enjoyment of Sushi) + b7(Kitchen Sinks Owned) Again, this violates the __________________. Weight of beardies as a function of age, length, and sex. What is the intercept? _________ What does it mean? A ______bearded dragon with ______________weighs negative 551 grams. (not real-world useful) How much heavier is a bearded dragon if it ages two years and doesn’t get any longer or change sex? (On average) Is there a significant difference in weight between male and female dragons of the same age and size? _________The p-value against there being no difference is _________, so we __________________that null. What does the regression equation look like? (Esimated Weight) = -551.1 + _________+ _________+ 4.9(Female) How much does the average bearded dragon weight if he’s.. - Male - 3 Years Old - 24 cm long (Esimated Weight) = -551.1 + 17.1( = ) + 34.3( ) + 4.9( ) Is there a model that likely works just as well but is simpler? _________. It’s likely that a model without considering sex would explain nearly as much of the variance. From model summaries: Model with Age, Length, Sex: r2 = .912 Model with Age, Length: r2 = .912 (Not always so exact) For interest: Nominal data of 3+ categories. Dummy variables HAVE to be 0 or 1. If not, you’re treating nominal categories as if they have some sort of order. If you have 3 categories, you need 2 dummy variables. Each of the dummy variables is 1 only when a particular category comes up, and 0 all the other times. One of the categories is considered a baseline, or starting point. All of the dummy variables will be 0 for that category. (Here: Blue is the baseline, all the dummy variables are 0 for it) Since a colour can’t be red and green at the same time, only one of the dummy variables will ever be 1 for a particular case. Doing a linear model with just these two dummy variables would look like: = a + b1(Red) + b2(Green) Which would be = a for blue cases. = a + b1 for red cases. = a + b2 for green cases. = a + b1(Red) + b2(Green) a , the intercept, the value when Red=0 and Green=0 is the average response for blue cases. b1 is the average increase/decrease in the response when the case is green instead of blue. b2 is the average increase/decrease in the response when the case is red instead of blue. Next time: Midterm 2 post-mortem. Reintroduction to contingency, Odds and Odds Ratios.