Developing Literacy in Quantitative Methods
advertisement

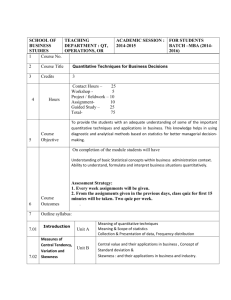
DEVELOPING LITERACY IN QUANTITATIVE RESEARCH METHODS Dr Christina Hughes University of Warwick C.L.Hughes@warwick.ac.uk These materials have two inter-related aims. The primary aim is to develop students' literacy in the use and reading of research that uses quantitative data. The second is to enhance students' confidence in their understandings of such approaches. To achieve these aims the package will introduce students to a number of basic statistical techniques that are used in social research. In addition the materials will explore some common concepts that underpin quantitative social research. The specific objectives are: · To develop understandings of the relationship between different types of quantitative data and their implications for descriptive and inferential statistical techniques; · To develop understandings of the statistical techniques of: measures of central tendency, measures of dispersion; · To explore the meanings of correlation and causality in relation to quantitative social research; · To explore uses, and misuses, of official statistics. Quantitative techniques are most commonly associated with survey and experimental research designs. As the name suggests, quantitative research is concerned with the collection and analysis of data in numeric form. It tends to emphasize relatively large-scale and representative sets of data, and is often (problematically) presented or perceived as being about the gathering of `facts'. Because of strong associations that are made between statistics as social facts and dominant ideas of science as objective and detached, quantitative strategies are often viewed as more valid. Many small-scale research studies that use questionnaires as a form of data collection will not need to go beyond the use of descriptive statistics and the exploration of the interrelationships between pairs of variables. It will be adequate to say that so many respondents (either the number or the proportion of the total) answered given questions in a certain way; and that the answers given to particular questions appear to be related. Such an analysis will make wide use of proportions and percentages, and of the various measures of central tendency (averages) and of dispersion (ranges). You may, however, wish or need to go beyond this level of analysis, and make use of inferential statistics or multivariate methods of analysis. There are dozens of inferential statistics available: three commonly used examples are Chi-square; Kolmogorov-Smirnov and Student's t-test. The functions of these statistics vary but they are typically used to compare the measurements you have collected from your sample for a particular variable with another sample or a population in order that a judgement may be made on how similar or dissimilar they are. It is important to note that all of these inferential statistics make certain assumptions about both the nature of your data and how it was collected. This means that you have to be clear whether your data is, for example, nominal, ordinal, interval or ratio. If these assumptions do not hold these measures should not be used. Multivariate methods of analysis may be used to explore the interrelationships among three or more variables simultaneously. Commonly used examples include multiple regression, cluster analysis and factor analysis. While you do not need to have an extensive mathematical knowledge to apply these techniques, as they are all available as part of computer software packages, you should at least have an understanding of their principles and purposes. One key point to be aware of when carrying out quantitative analysis is the question of causality. One of the purposes of analysis is to seek explanation and understanding. We would like to be able to say that something is so because of something else. However, just because two variables of which you have measurements appear to be related, this does not mean that they are. Statistical associations between two variables may be a matter of chance, or due to the effect of some third variable. In order to demonstrate causality, you also have to find, or at least suggest, a mechanism linking the variables together. [Extracted from Blaxter, Hughes and Tight, 1996] Bibliography This bibliography includes texts that are useful for students new to quantitative techniques and those that are useful for the more advanced. The asterisk (*) indicates those that are introductory. The key publishers of methodology texts are Sage, Routledge and Open University Press. If you wish to extend your reading or keep up to date with developments you should put your name on these publishers' catalogue mailing lists. There are also a number of journals that are primarily concerned with developments in methodology. These include: The International Journal of Social Research Methodology and Social Research Online ( http://www.socresonline.org.uk). In addition, secondary sources produced by the Office for National Statistics for the Government Statistical Service can be obtained from The Office for National Statistics, 1 Drummond Gate, London, SW1V 2QQ or through the STATBASE on-line directory. Black, T (1999) Doing Quantitative Research in the Social Sciences: An Integrated Approach to Research Design, Measurement and Statistics, London, Sage Blaxter, L, Hughes, C and Tight, M (1996) How to Research, Buckingham, Open University Press* Bowling, A (1997) Research Methods in Health: Investigating Health and Health Services, Buckingham, Open University Press* Bryman, A and Cramer, D (1990) Quantitative Data Analysis for Social Scientists, London, Routledge Calder, J (1996) Statistical Techniques, in R Sapsford and V Jupp (Eds) Data Collection and Analysis, London, Sage, pp 225-261 Cramer, D (1994) Introducing Statistics for Social Research: Step-by-step calculations and computer techniques using SPSS, London, Routledge Denscombe, M (1998) The Good Research Guide: For small scale social research projects, Buckingham, Open University Press* De Vaus, D (1991) Surveys in Social Research, Sydney, NSW, Allen and Unwin Hek, G, Judd, M and Moule, P (1996) Making Sense of Research: An Introduction for Nurses, London, Cassell* Hinton, P (1995) Statistics Explained: A guide for social science students, London, Routledge* Leary, M (1991) Introduction to Behavioural Research Methods, Belmont, Calif, Wadsworth Publishing Levitas, R and Guy, W (1996) Interpreting Official Statistics, London, Routledge Persell, C and Maisel, R (1995) How Sampling Works, Newbury Park, Calif, Pine Forge Pilcher, D (1990) Data Analysis for the Helping Professions: A Practical Guide, Newbury Park, Calif, Sage Sapsford, R (1996) Extracting and Presenting Statistics, in R Sapsford and V Jupp (Eds) Data Collection and Analysis, London, Sage, pp 184-224 Solomon, R and Winch, C (1994) Calculating and Computing for Social Science and Arts Students, Buckingham, Open University Press* Stanley, L (Ed) (1990) Feminist Praxis, London, Routledge Townsend, P (1996) The Struggle for Independent Statistics on Poverty, in R Levitas and W Guy (Eds) Interpreting Official Statistics, London, Routledge, pp 26-44 Traub, R (1994) Reliability for the Social Sciences: Theory and Application, Thousand Oaks, Calif, Sage Wright, D (1997) Understanding Statistics: An introduction for the social sciences, London, Sage* TYPES OF QUANTITATIVE DATA Nominal data Nominal data come from counting things and placing them in a category. They are the lowest level of quantitative data in the sense that they allow little by way of statistical manipulation compared with the other types. Typically there is a head count of members of a particular category, such as female/male or African Caribbean/South Asian. These categories are based simply on names; there is no underlying order to the names. Used for the following descriptive statistics: proportions, percentages, ratios. Ordinal data Like nominal data, ordinal data are based on counts of things assigned to specific categories but in this case the categories stand in some clear, ordered, ranked relationship. The categories are `in order'. This means that the data in each category can be compared with the data in the other categories as being higher or lower than, more or less than, etc. those in other categories. The most obvious examples of ordinal data come from the use of questionnaires in which respondents are asked to respond to a five-point Likert scale. It is worth stressing that rank order is all that can be inferred. With ordinal data we do not know the cause of the order or by how much they differ. Used for the following descriptive statistics: proportions, percentages, ratios. Interval data Interval data are like ordinal data but the categories are ranked on a scale. This means that the `distance' between the categories is a known factor and can be pulled into the analysis. The researcher can not only deal with the data in terms of `more than' or `less than' but also say how much more or how much less. The ranking of the categories is proportionate and this allows for direct contrast and comparison. Calendar years are one example. This allows the researcher to use addition and subtraction (but not multiplication and division) to contrast the difference between various periods. Used for the following descriptive statistics: measures of central tendency (mode, median, mean) Ratio data Ratio data are like interval data except that the categories exist on a scale which has a `true zero' or an absolute reference point. When the categories concern things like incomes, distances and weights they give rise to ratio data because the scales have a zero point. Calendar years, in the previous example, do not exist on such a scale because the year 0 does not denote the beginning of all time and history. The important thing about the scale having a true zero is that the researcher can compare and contrast the data for each category in terms of ratios, using multiplication and division, rather than being restricted to the use of addition and subtraction as is the case with interval data. Ratio data are the highest level of data in terms of how amenable they are to mathematical manipulation. Used for the following descriptive statistics: measures of central tendency (mode, median, mean) [adapted from Blaxter, Hughes and Tight, 1996 and Denscombe, 1998] TYPES OF QUANTITATIVE DATA EXAMPLES Are the following nominal, ordinal, ratio or interval data? · The income levels of social workers; · The examination scores of members of this course; · The sex of your research participants; · The birth position of members of a family; · Exam grades received at school; · Number of exam passes; · The temperatures of different geographical zones; · The size of families in the UK; · IQ scores; Illustrative Issue A Likert scale is written to convey equidistant points along an axis: *-----------------*---------------- *---------------- *---------------- * Very Fairly Important Not very Not at all Important Important Important Important Are the meanings ascribed by research respondents similarly equidistant? Is such data interval or nominal? TYPES OF QUANTITATIVE DATA A CAUTIONARY COMMENT Very important 1 Fairly important 2 Not very important 3 Not at all important 4 The problem is that the `real' distance between the ratings numbered 3 and 4 for a respondent may be much greater than the distance they perceive between the items numbered 1 and 2. The `real' distances between each of the ratings may also vary from person to person. In theory, therefore, such data should be treated as ordinal data. Most researchers take a pragmatic approach, however, and continue with the practice of treating ratings and psychological tests as interval data. One way of dealing with data that are difficult to `type' correctly is through the use of models. Scientists use models of weather systems to study the relationships between different factors in order to understand better what the contributory factors are. In the same way, statisticians produce statistical models based on their current understanding of the problem. When they do not quite work as expected, they modify some of their assumptions. If the assumption of an interval scale does not work, then further analyses can be carried out on the assumption of an ordinal scale. Over the years, reviews of the statistical evidence suggested that the assumption of equality of equal intervals within rating scales is justified. But where such assumptions are made, there is always the possibility of misinterpretation of the data. The important point is to be clear always that there are different types of data, and that this will affect the type of analyses that can be used on them. (Calder, 1996: 229) MEASURES OF CENTRAL TENDENCY OR MID-POINTS AND AVERAGES There are three types of average and these are collectively called `measures of central tendency'. These are the mean, the median and the mode. The mean (or arithmetic average) This is the most common meaning of `average'. It includes the total spread and finds the mid-point. To calculate the mean: 1. Add together the total of all the values for the category 2. Divide this total by the number of cases · The mean cannot be used with nominal data. For example, you cannot `average' names, sexes, nationalities and occupations. · The mean is affected by extreme values, or outliers. Because the mean includes all values the average can be pulled toward the value of the outlier or toward the more extreme values. · The mean can lead to strange descriptions, such as 2.4 person households. Example: Calculate the mean from the following: • 1 4 7 11 12 17 17 47 The median or mid-point The median is the mid-point of the range. To calculate: 1. Place the values in ascending/descending rank order 2. Find the mid-point number 3. With even numbers of values the mid-point is half-way between the two middle values · The median can be used with ordinal data as well as interval and ratio data. · The median is not affected by extreme values or outliers. · The median works well with a low number of values. · The main disadvantage is that you can do no further calculations with the median. Example: Calculate the median from the following: • 1 4 7 11 12 17 17 47 The Mode The mode is the value that is most common. To calculate: 1. Arrange the data in ascending/descending order; 2. Identify the value that occurs more frequently than any other. · The mode can be used with nominal, ordinal, interval and ratio data. It has the widest possible scope therefore. · It is unaffected by outliers or extreme values. · It does not allow any further mathematical calculations. · There may not be any `most common' values or there may be more than one. Example: Calculate the mode of the following: 1 1 4 4 7 11 12 17 17 17 47 MEASURES OF DISPERSION Given some of the problems in the accuracy of conveying meaning with measures of central tendency, measures of dispersion are an important adjunct in any description of the data. Measures of dispersion are used to indicate how widely the data is spread and how evenly the data is spread. In other words, how far from the central point is the data dispersed? There are three main measures of dispersion: the range, fractiles and standard deviation. The range This is the simplest, and a very effective, way of describing the spread of the data. To calculate the range: · Substract the minimum value in the distribution from the maximum value. Although effective, the range can still be affected by the value of any outliers. In consequence it can give a misleading impression of the spread of the data. This is why is it important to include a note of the highest and lowest score in your written presentation of data. Example: Calculate the range from the following: 3 4 7 11 12 17 17 47 Fractiles To take account of the spread of values across the whole range, fractiles (eg quartiles/quarters, deciles/tenths, percentiles/hundredths) are used. These divide the range into smaller, equidistant ranges. Fractiles are used with median values. To calculate: 1. Subdivide the range into equal parts (eg quartiles, deciles, percentiles) 2. Find the median (mid point) value; 3. Working from the median point divide your data into the relevant fractiles. Fractiles can eliminate the high and low values that affect measures of central tendency. For example, by focusing on the cases that fall between the second and third quartile reasearchers know that they are dealing with the half of the values that fall in the middle. In addition it allows the comparison of values between fractiles. For example, the top ten percent of earners can be compared with the bottom. Example: The following is income data of social workers. Divide the data into quartiles. Find the median that occurs in each quartile. Find the median that occurs between the second and third quartile. How would you present this data? What would you say about the validity of these data? Income per annum (thousands): 15 16 17 21 22 27 27 47 Standard Deviation (SD) The standard deviation is used with the arithmetic mean. The standard deviation uses all the values in the range to calculate the spread of the data. It is a measure of the distance of the scores from your mean. The larger the standard deviation the more spread out the range is. To calculate: 1. Find the mean 2. Subtract the mean from all your values 3. Square all the results (to turn your minuses into pluses) 4. Add all these `squared numbers' together 5. Divide this by the number of your values minus one 6. Find the square root of this · The standard deviation can be used for further statistical analysis · Because of this standard deviation is an immensely important aspect of social research · The standard deviation can only be used with interval and ratio data. It is meaningless when used with nominal and even ordinal data. Exercise: Find the standard deviation of the following: • 1 4 7 11 12 17 17 47 CORRELATION Correlation How closely are two variables connected? This question is answered in statistical terms with correlation. For example, do the students who spend the most time studying achieve the highest marks? Do those who spend least time studying get the lowest marks? These question are asking us to compare two variables: study time and examination performance. We are asking to what extent is there a relationship between these two variables. If the answer was that that those who spend most time studying do achieve the highest marks we would say that there is a positive correlation between the two variables. In other words we would be saying that as the score increases on one variable it also increases on the other variable. In addition, if those who study least achieve the lowest marks, we would also say that there is a positive correlation between the two variables. However, if we found that the more students spent studying the lower their marks, this would be described as a negative correlation. There is, for example, a negative correlation between the variables of smoking and health. The more a person smokes the less healthy that person is likely to be. If there is no relation between two variables then we would say that the variables are uncorrelated. For example, if the hypothesis was that wearing jeans improved exam scores and the results suggested that some students who wore jeans had high scores and some who wore jeans had low scores, some students who did not wear jeans had high scores and some who did not wear jeans had low scores the results are likely to show no correlation. To calculate correlation one plots the scores on a scatter diagram. This requires you to plot the scores of the two variables along the axes of a graph and mark the results. If a straight line can be drawn there is a correlation. The direction of the lines indicates whether this is a positive (up) correlation or a negative (down) correlation. The two most commonly used correlation statistics are Spearman's rank correlation coefficient that works for ordinal data and Pearsons's product moment correlation coefficient that works for interval and ratio data. When reading statistical research you are likely to find the following signs: · +1 this equals a perfect positive correlation (as one variable goes up so does the other) · 0 this means there is no relationship between the variables · -1 this equals a perfect negative correlation (as one variable goes up the other goes down) · In practice any correlation coefficient between 0.3 (weak) and 0.7 (strong) suggests a reasonable correlation. Example: Do the following data indicate a correlation? Student Study Time Examination Mark 1 40 58 2 43 73 3 18 56 4 10 47 5 25 58 6 33 54 7 27 45 8 17 32 9 30 68 10 47 69 (from Hinton, 1995) CORRELATION AND CAUSATION CORRELATION DOES NOT MEAN CAUSATION If two things go together it is easy to assume that they are causally related in some way. Is this the case? Even if the thickness of a caterpillar's coat correlates closely with the severity of the winter weather, can we conclude that caterpillars cause bad weather? Three criteria are required to achieve causality in statistical research: · Covariation · Directionality · Elimination of extraneous variables Covariation To conclude that two variables are causally related they need to covary or correlate. If one variable causes the other then changes in the values of one variable should be associated with changes in the values of the other. This is, of course, the definition of correlation. Directionality To infer that two variables are causally related we much show that the presumed cause precedes the presumed effect in time. However in most correlational research both variables are measured at the same time. There is therefore no way to determine the direction of causality. Has X causes Y or Y caused X? Elimination of Extraneous variables The third criterion for inferring causality is that all extraneous factors that might influence the relationship between the two variables are eliminated. Correlational research never satisfies this requirement completed. Two variables may be correlated not because they are causally related to one another but because they are both related to a third variables. For example, does loneliness cause depression? Maybe but a third variable - the quality of a person's social network - may reduce both loneliness and depression. Example: Does smoking cause cancer? There is a wealth of research that suggests a strong correlation between smoking and cancer. Does smoking cause cancer? [adapted from Leary, 1991] USING OFFICIAL DATA SETS There are a number of important, and useful, data sets collected by government and which can be used for secondary analyses. These include: · Census of Employment · Census of Population · Labour Force Survey · General Household Survey · Family Expenditure Survey The annual publication Social Trends is a useful source for those who are seeking some simple statistics. Social Trends compiles its analyses from these data sets. In addition, the ESRC keeps data archives of both quantitative and qualitative research that can be consulted. Care should be taken in the use of statistics however. For example, in a discussion of poverty statistics, Townsend notes how successive governments in the UK have chosen to avoid using the term `poverty'. As he further notes (1996: 26): Statistics don't fall out of the skies. Like words - of which they are of course an extension - they are constructed by human beings influenced by culture and the predispositions and governing ideas of the organisations and groups within which people work. Statistical methodologies are not timeless creations. They are the current expression of society's attempts to interpret, represent and analyse information about economic and social (and other) conditions. As the years pass they change - not just because there may be technical advances but because professional, cultural, political and technical conventions change in terms of retreat as well as advance ... [Thus] Every student of social science ... needs to be grounded in how information about social conditions is acquired. Statistics form a substantial part of such information. Acquiring information is much more than looking up handbooks of statistics. We have to become self-conscious about the process of selection. Levitas and Guy (1996) contextualise these concerns in terms of the following: There are developments which may make official data more easily accessible to academic experts [on-line access]. They do not make data more easily available to the public in the interests of informed political debate. Moreover, the (relative) ease of conducting secondary analysis carries the danger of forgetting that the concepts used in any research derive from the questions and interests of its original intentions. The extent to which secondary analysis can bend data sets to the service of sometimes quite different agendas is necessarily limited. (p 3) ...The debates ... show that the insistence on the neutrality and objectivity of facts still dominates discussion of official statistics and their production. The presentation of statistics in particular ways for political ends, and the abolition of inconvenient measures, continue. It is understandable that professional statisticians should try to counter this by appeals to objectivity. But it is also abundantly clear that the definitions used in official statistics still produce measures which embody the interests of the state rather than of citizens. It is therefore only with the utmost care that such data can be interpreted for democratic purposes. (p 6) The edited text by Levitas and Guy (1996) outlines the kinds of data sets that are available. It also contains discussions of the use, and misuse, of government statistics in the following areas: poverty, unemployment, social class, health, safety at work, working women, ethnicity, disability and crime. Another useful text is that of Stanley L (Ed) (1990) Feminist Praxis, London, Routledge. Amongst the range of issues discussed, this contains discussions on the ways in which statistics collected on the homeless are `compromised' by the processes of turning raw data into statistical information. A chapter by Liz Stanley (A Referral Was Made) discusses the politics of objectivity influences the presentation of a social service's case. USING OFFICIAL DATA SETS EXERCISE 1. How would you interpret the following statement? "Statistics on patterns of household disposable income are provided in Households below Average Income reports ... The best response to low household income is to sustain economic recovery and to assist those in greatest need" (Reported in Townsend, 1996: 27-28) 2. How would you interpret the following conversation? Ms Corston: Is the Prime Minister aware that Social Trends 1994, a Government publication, reveals that as a direct consequence of Tory Government policy since 1979 the average disposable income of the richest 20 per cent of households has increased by £6,000 a year while the 20 per cent of households at the bottom of the income scale have had their average disposable income cut by £3,000 a year? Does that reveal the hypocrisy of the Prime Minister's professed commitment to creating a nation at ease with itself? The Prime Minister: The hon. Lady [Ms Corston] was being selective in what she said - [Interruption]. She was selective from the report. The net disposable income of people at all ranges of income has increased and the proportion of total tax paid by those on top incomes has increased, not been reduced. (Reported in Townsend, 1996: 40)