DFAs
advertisement

Deterministic Finite Automata (DFAs)
This material covers section 1.3 and the beginning of chapter 2.
We begin with the general description of an automaton, a machine that can recognize strings
in the language for which is was built. Additional features of the specific types of automata
will be discussed when they are encountered. We assume the machine can read input so the
string we test will reside in an input (file) which is divided into cells and is read only. The input
is read left to right one symbol at a time. In most cases, to accept a string the machine must
read all of the input. That is, it will not stop unless the last symbol of the input is read. Some
automata are designed to produce output. In some cases there is a temporary storage device
which can be written to. The types of automata differ mainly in how the storage is handled.
An automaton also has a control unit which can be in any of a finite number of internal states.
The control unit knows the legal moves of the automaton and will make those moves as input
is read.
At any point in time, the control unit is in some internal state, and a particular symbol on the
input tape is being scanned. The internal state is determined by the transition function () i.e.
the moves of the machine. The transition function looks at the current state and the input
symbol and sometimes the information in storage to decide its move. We use the term
configuration to refer to the particular state of the control unit, the input symbol being read and
the storage. The transition from one configuration to another is called a move.
In the most general sense, we can think of the machine as the following:
We need to make a distinction between deterministic and nondeterministic automata. An
automaton is deterministic if there is a unique move from every configuration. In a
nondeterministic automaton, there may be more than one move from a given configuration.
We will look at the difference in accepting power of the deterministic and nondeterministic
versions of the automata we study.
An automaton whose only response is “yes” or “no” is called an acceptor. This is often
accomplished by looking at the state in which the machine ends up and a “yes” corresponds
to ending in a final state. If an automaton is capable of producing strings of symbols as output
it is a transducer. Our primary interest is in acceptors.
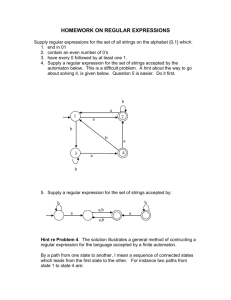
Section 1.3 exercise 4
Suppose a certain programming language permits only identifiers that begin with a letter,
contain at least on but no more than three digits and can have any number of letters. Give a
grammar and an acceptor for such a set of identifiers.
We introduce variables corresponding to when each digit has been added. For example,
<firstdigit> may produce as many letters as desired until the first digit is placed. Since we
may have up to two more digits, we introduce two other variables <nextdigit> and <lastdigit>.
Notice that for both of these variables one of the rules is a -rule allowing us to stop the
derivation. After the third digit has been placed in the identifier we use <rest> to allow us to
produce as many letters as desired following the third digit.
Grammar:
<letter> a | b | … | z
<digit> 0 | 1 | … | 9
<id> <letter> <firstdigit>
<firstdigit> <letter> <firstdigit> | <digit> <nextdigit>
<nextdigit> <letter> <nextdigit> | <digit> <lastdigit> |
<lastdigit> <letter> <lastdigit> | <digit> <rest> |
<rest> <letter> <rest> |
Here’s an automaton that will accept legal identifiers according to the conditions above.
Note the use of a trap state. If, while reading a string, the machine detects that the input
string cannot be in the language then it moves to a nonaccepting state where it can read the
remainder of the input before stopping.
Chapter 2
Now we turn to the formal definitions of automata. We begin with deterministic finite
automata, DFAs.
A deterministic finite automaton or DFA is defined by the 5-tuple
M = (Q, , , q0, F) where
Q is a finite set of internal states
is a finite set of symbols called the input alphabet
: Q Q is a total function called the transition function
q0 Q the start or initial state
F Q is a set of final states
Typical Notational conventions that I use are
(1) states are designated by p's and q's usually with subscripts
(2) the alphabet consists of lower-case letters near the front of the alphabet (usually a, b
and/or c) or digits
(3) lower case letters near the end of the alphabet usually u, v, w, x, y, and z with or without
subscripts are strings of input symbols
A DFA operates as follows, It begins in the initial state with the input head reading the first
symbol on the input tape. During each move, the input head moves one position to the right.
When the last symbol has been read and the machine stops, the automaton accepts the string
if it is in one of its final states and otherwise the string is rejected. Note that this implies the
machine does not stop until all input has been processed. Transitions from one state to
another are determined by the transition function. For example, a typical move might be
(q0, a) = q1 which means if the DFA is in state q0 and the input head is reading an a then the
machine moves to state q1.
In our pictorial representation called a transition graph, the circles represent states and the
edges are the transitions. The start state (usually q0) will have an unlabeled arrow (or a
triangle) coming into it. The book has a more formal definition on page 38 but we’ll skip that.
Let’s look at an automaton and write out the transition function.
Q = {q0, q1, q2, q3}, = {a, b}, F = {q2}
Write out the transition function for this machine to the right of the machine.
What is the language accepted by the automaton?
Important: A DFA must be completely specified. That is, for every state and for every input
symbol there must be a move. For example, if = {a, b} then each state in the diagram of
the machine must have an edge with a as a label and an edge with b as a label (both labels
may be on the same edge).
Sometimes we want to label edges with strings rather than single alphabet symbols. For
example, in the automaton above (q0, ab) = q2. Note that this extension to strings is done in
the natural way which is basically composition of functions. Let * denote the extended
transition function, *: Q * Q. (Notice that the in the definition of has been replaced
by * to indicate strings. To get *( q0, ab) we must first get to q1 i.e. (q0, a) = q1 and then
use again to get to q2 i.e. (q1, b) = q2. Formally,
*: Q * Q is defined (recursively) by
1) *(q, ) = q for every q Q
2) for string w and input symbol a, *(q, wa) = (*(q, w), a)
Now that we have the extended transition function we can formally define the language
accepted by a DFA:
If M = (Q, , , q0, F) is a DFA, then, the language accepted by M denoted L(M) is defined as
follows: L(M) = {w * | *(q0, w) F}. In other words beginning in q0, M accepts all strings
which lead to a final state
Note that both and * must be total functions. A DFA processes every string in * and
either accepts it or determines it is not in the language. Then the set of strings not accepted
by M is just the complement of L(M) or
____
L(M) = {w * | *(q0, w) F}.
____
Given an automaton M, how do you think we could construct an automaton for L(M)?
The answer is probably what you predicted--just change all accepting or final states to
nonaccepting and vice versa. Thus, the machine to accept the complement of the language
accepted by the automaton M is obtained by replacing F by Q – F in the definition of M.
Consider the following DFA, M. Draw yourself a picture of the machine to try to figure out
what language it accepts.
M = ({q0, q1, q2, q3}, {0, 1}, , q0, {q3} ) where is defined by
0
1
q0
q1
q2
q1
q3
q2
q2
q1
q3
q3
q1
q2
Language--all strings that end in 00 or 11 (or end in an even number of 0's or an even number
of 1's). Which description is more accurate?
Example 2. The machine below which we’ve seen before accepts all strings of odd length
ending in b. More formally,
M = ({q0,q1,q2}, {a, b}, , q0, {q2})
Note that this is an NFA. Later, we will construct a DFA to accept this language.
In order to justify the use of graphs in proving arguments the author has proven Theorem 2.1:
Let M = (Q, , , q0, F) be a DFA and let GM be the associated transition graph. Then, for every
qj Q and w +, *(qi, w) = qj if and only if there is in GM a walk with label w from qi to qj.
This basically says the graph is a good model for the automaton.
Definition: A language L is regular if and only if there exists some DFA M such that L = L(M).
At this point to prove regularity we will need to find a DFA that accepts it and generally prove
that the DFA in fact does what we claim. Later we will have other methods such as closure
properties, grammars and regular expressions to prove a language is regular.
Example 3: Consider the set of all strings over {a, b} with begin with b and have exactly two
a’s. Call this language L. Let’s construct a DFA for L and then show how it can be used to
construct a DFA for L2. Clearly, any string that begins with a leads to a trap state. If we
move from q0 to q1 on a b, then there must be at least two more states q2 and q3 in order to
ensure we get exactly two a’s. Since the a’s do not have to be consecutive, we put loops
labeled by b on q1, q2, and q3. After we have read the two a’s we’re in q3 so that should be
our accept state. If, in q3, another a appears in the input, the machine should move to the
trap state.
A DFA for L is shown below.
One way we can characterize these strings is bb*ab*ab* where b* means 0 or more b’s. This
is called a regular expression and will be discussed later. (The bb* may be replaced by b+ if
you wish.)
Now, suppose we want to concatenate L with itself. What must we do to construct a DFA for
L2. L2 will contain strings of the form bb*ab*abb*ab*ab*. What we will basically do is to glue
two copies of this automaton together. Let’s label the states in the second copy with p’s. We
must effectively merge q3 and p0 and change the transitions leading to the trap state in the
second copy so that they lead to the trap state in the first copy. Although it’s not technically
wrong to have two trap states, it’s a good idea to eliminate any unnecessary states in the
machine.
The final result is