Central Dogma and Endomembrane System Getting Glucose
advertisement

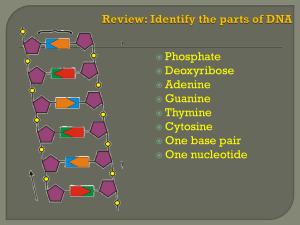
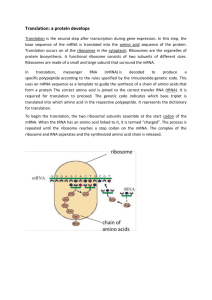
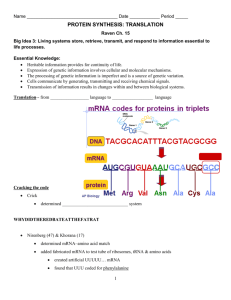
Central Dogma and Endomembrane System Getting Glucose Transporter out to the membrane – eukaryotic When insulin binds to the insulin receptor on a liver cell a signal is sent in to the nucleus and the response is to activate the two genes for glucose transporter protein, a membrane protein that will allow glucose to then diffuse into the cell. Within the nucleus of the eukaryotic cell exists the chromatin, which is a collection of all the chromosomes (46 in humans). A eukaryotic chromosome is a linear piece of DNA plus all of the proteins associated with it including the histones, which serve to organize the chromosomes. Chromosomes are analogous to books as they contain instructions to build every RNA and polypeptide/protein molecule in the cell. This would make the nucleus like the library of the cell. The short sections of the chromosomes that contain this information are known as genes and they make up approximately one percent of the genetic material. Genes might be thought of as individual pages of the book. All genes contain instructions to first build RNA. There are three main types of genes – mRNA, rRNA and tRNA genes. The enzyme that is able to read the genes and build the complementary RNA molecules is called RNA polymerase. This process is known as transcription because the genes are being essentially rewritten in the same “language” since RNA is very similar to DNA as they are both nucleic acids. The rRNA genes are located in the nucleolus of the nucleus, which is where ribosomes are formed. The rRNA or ribosomal RNA made by RNA polymerase in this region will fold up and form 65% of the ribosome with the other 35% being a number of proteins imported from the cytosol. The ribosome is actually made in two distinct parts known as the small and large subunits. The tRNA genes, which code for tRNA, will also fold upon formation and serve to bring amino acids to the ribosome later in the story. The mRNA genes, on the other hand, code for messenger RNA, which serve as instructions that dictate the amino acid sequence of a particular polypeptide. In this case, the mRNA gene is the glucose transporter gene. Before leaving the nucleus, but after transcription, the mRNA gets modified. A 5’ cap is added as well as a tail of 50 or more A nucleotides (poly-A tail) on the 3’ end both by distinct enzymes. The ribosomal subunits, tRNAs and mRNAs will be exported from the nucleus through the nuclear pore. The process of translation, which is the reading of the mRNA and subsequent building of the polypeptide begins when the small subunit of the ribosome randomly collides with the 5’ cap of the mRNA and specifically binds to it. All collisions of molecules the size of proteins and smaller are random. However, the binding is very specific and is based on shape and charge of the two molecules. The small subunit will scan along the mRNA until it reaches the start codon. Codons can be thought of as the words of the nucleic acid language or the words of the books (DNA). All the codons are only three-letters and since there are only four letters (A,T,C,G) there are only 64 possible words. The first codon or start codon is almost always AUG. Next, a tRNA, called the initiator tRNA, containing a very specific complementary sequence of nucleotides to the start codon (3’-UAC-5’) known as the anticodon will collide and bond via complementary base-pairs to the start codon. This particular tRNA with the 3UAC5 anticodon always carries with it the amino acid methionine. Therefore, the first amino acid of most proteins is methionine. The large subunit binds next to the small subunit and mRNA placing the initiator tRNA into what is called the p-site. There is a second site over the next codon called the a-site. The next tRNA will collide with the codon in the a-site and it complementary will bind bringing the next very specific amino acid according the mRNA instructions. The ribosome will then catalyze formation of the peptide bond between the two amino acids. The carboxyl side of the methionine will be attached to the amino side of the second amino acid. Therefore the polypeptide is being made from the N- toward the Cterminus. The ribosome will now translocate one codon. This will slide the a-site over to the third codon and the p-site over the second codon. The initiator tRNA, bound to the start codon, will now be out of the ribosome and will fall off the mRNA. The tRNA with the dipeptide will be in the p-site, and the a-site will be open to receive the next tRNA. This will continue and the nascent polypeptide will emerge from the ribosome. Since this is a membrane protein, the first 20 or so amino acids will have a very specific sequence known as the ER localization sequence or ERLS. There is a ribonucleoprotein (RNA-protein complex) known as the signal recognition particle (SRP), which will collide with this nascent polypeptide and bind to it. This entire complex containing the SRP, mRNA, ribosome and tRNAs will collide with the translocon of the rough ER. The translocon has a ribosome receptor and an SRP receptor. It also contains pore proteins that will allow the growing polypeptide to cross the membrane and enter the ER. The SRP will hand off the polypeptide to the pore proteins and the ribosome/tRNA will continue translation as the polypeptide is thread through the translocon. As the polypeptide enters, it will be simultaneously glycosylated by a number of ER resident enzymes called glycosyltransferases. To be glycosylated means to have oligosaccharides added on at very specific locations, which will turn the polypeptide into what is called a glycoprotein. The oligos are part of the structure and therefore critical in terms of function. Glucose transporter protein is a membrane protein and therefore has a very special amino acid sequence within the polypeptide that will signal the translocon to slide this section of the polypeptide into the membrane. This is where the protein becomes a membrane protein. Eventually the ribosome will reach the stop codon for which there is no complementary tRNA. Instead there is a protein called release factor that will bind to the stop codon and cause the ribosome to dissociate from the mRNA. The membrane protein is now completed. In order to get it out to the actual cell membrane, protein of the ER will pinch off a membranous transport vesicle that will contain various membrane and soluble proteins for delivery to the golgi. Kinesin, a motor protein found in the cytosol, will bind to specific proteins in the membranes of the vesicles and walk the vesicles along mictotubules using ATP as a source of energy as these structure are too large and move to slowly to simply allow random motion for proper delivery. Once many vesicles arrive at the Golgi they will fuse forming was is called the ‘cis’ or receiving cisterna. Within the Golgi, oligosaccharides are modified by Golgi resident enzymes and proteins are sorted so that they go to their proper final destination. New cis cisternae will form behind the old one moving the old one forward in line. It is now a medial cisternae. The Golgi is in fact composed of many of these membranous pancake-like stacks. Eventually the medials will continue being moved forward until becoming a trans cisterna, which is last in line. This model where the cis eventually matures into the trans is known as the cis maturation model. The trans cisterna will break up into a number of different types of vesicles. The glucose transporter will be in the membrane of a secretory vesicle destined for the cell membrane. Kinesin will again walk it out there. Upon arrival a number of proteins will serve to fuse the vesicle with the cell membrane. The secretory vesicle membrane will now become part of the cell membrane, all the proteins inside the vesicle will be secreted outside the cell, and glucose transporter will finally be where it needs to be and serve to transport glucose into the cell (facilitated diffusion).