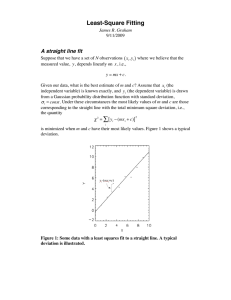
What Do We Mean by the “Best” Line?

What Do We Mean by the “Best” Line?
To answer that question, first we have to agree on what we mean by the “best fit” of a line to a set of points. Why do we say that the line on the left fits the points better than the line on the right? And can we say that some other line might fit them better still?
Intuitively, we think of a close fit as a good fit. We look for a line with little space between the line and the points it’s supposed to fit. We would say that the best fitting line is the one that has the least space between itself and the data points , which represent actual measurements.
Okay, what do we mean by “least space”? There are three ways to measure the space between a point and a line: vertically in the y direction, horizontally in the x direction, and on a perpendicular to the line. We choose to measure the space vertically . Why? Because our whole purpose in making a regression line is to use it to predict the y value for a given x, and the vertical distances are how far off the predictions would be for the points we actually measured.
If we know we want the line that has the smallest vertical distance between itself and the points, how do we compute that vertical distance? If the line is y=3x+2 and we have a point (2,9), the the predicted value is 3×2+2=8 and subtract the actual measured value 9.
We say that the deviation is –1, negative because the predicted value is less than the actual value. In general, the deviation (vertical gap) between any given point (x,y) and the line y=mx+b will be mx+b–y.
But each deviation could be positive or negative, depending on whether the line fall above or below that point. We can’t simply add up deviations, because then a line would be considered good if it fell way below some points as long as it fell way above others. To prevent that, we square each deviation , and add up the squares. (This also has the desirable effect that a few small deviations are more tolerable than one or two big ones.)
And at long last we can say exactly what we mean by the line of best fit. If we compute the deviations in the y direction, square each one, and add up the squares, we say the line of best fit is the line for which that sum is the least. Since it’s a sum of squares, the method is called the method of least squares .
Question:
Consider the three points (4, 33), (5, 27), and (6, 15). Given any straight line, we can calculate the sum of the squares of three vertical distances from these points to the line.
What is the smallest possible value this sum can be?
This is the question that we did it in our class. After entering L1, L2 do stat calculate, option 4 to get your regression line( y hat = -9x + 70. Plug the x values to get your y-hat values(plug 4, 5, 6 ) to get (34, …). Square each residual(y – hat) and add them up
Suppose that x is dial settings in your freezer, and y is the resulting temperature in °F.
Here’s the full calculation: n=5 x y x² xy
0 6 0 0
2 –1 4 –2
3 –3 9 –9
5 –10 25 –50
6 –16 36 –96
∑ 16 –24 74 –157
Now compute m and b:
5(−157) − (16)(−24) −401
m = ------------------- = ---- = −3.5175
5(74) − 16² 114
−24 − (−3.5175)(16)
b = --------------------= 6.456
5
Use the regression equation calculated by a TI-83 for the same data.
Alternative Formulas
Some authors give a different form of the solutions for m and b, such as: where x̅ and y̅ are the average of all x’s and average of all y’s.
These formulas are equivalent to the ones we derived earlier. (Can you prove that?
Remember that n x̅ is ∑ x, and similarly for y.) While the m formula looks simpler, it requires you to compute mean x and mean y first. If you do that, here’s how the numbers work out: n=5 x y
x– x̅ y– y̅ (x– x̅ )² (x– x̅ )(y– y̅ )
0 6 –3.2 10.8 10.24 –34.56
2 –1 –1.2 3.8 1.44 –4.56
3 –3 –0.2 1.8 –0.04 –0.36
5 –10 1.8 –5.2 3.24 –9.36
6 –16 2.8 –11.2 7.84 –31.36
∑ 16 –24 0 0 22.8 –80.2 mean 3.2 –4.8
Whew! Once you’ve got through that, m and b are only a little more work: m = −80.2 / 22.8 = −3.5175 b = −4.8 − (−3.5175)(3.2) = 6.456