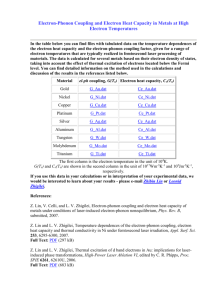
Appendix Figures
advertisement

Supplementary Appendix to:
The complex role of the prescribing physician for confounder adjustment in comparative
effectiveness research methods
May 20, 2014
Methods
Simulation study
We simulated data based on the causal diagram shown in Figure 1. This simulation was designed to
investigate the impact of causal structure on the relative performance of approaches utilizing the
prescriber. Thus, we attempted to create a simple and easily interpretable data-generation mechanism,
and we chose simulation scenarios to evaluate methods when specific associations were present or
absent. The primary association of interest is the causal effect of drug exposure on patient outcomes,
which is confounded by patient characteristics and, potentially, by prescriber characteristics. In each
simulation, we generated prescribers, 𝑖 = 1, … , 𝑚, and patients, 𝑗 = 1, … , 𝑛𝑖 , such that the distribution
of the number of patients per prescriber (𝑛𝑖 ) was right skewed, as commonly observed in comparative
effectiveness studies, with a minimum of 1 and the total number of patients (𝑛 = ∑𝑚
𝑖=1 𝑛𝑖 ) fixed. We
then generated one binary prescriber characteristic, 𝑍, designating, for example, a specialist versus
family practitioner, a continuous measure of prescriber preference, 𝑃, 2 continuous patient
characteristics, 𝑪 = (𝐶1 , 𝐶2 ), a binary treatment indicator, 𝑋, and outcome, 𝑌, as follows:
𝑍𝑖 ~𝐵𝑒𝑟𝑛𝑜𝑢𝑙𝑙𝑖(. 4)
𝑃𝑖 ~𝑁(𝜃𝑍𝑖 ,
𝜎2)
𝛾𝑍
𝑪𝑖𝑗 ~𝑁2 (( 𝑖 ) ,
𝛾𝑍𝑖
𝐼)
𝑋𝑖𝑗 ~𝐵𝑒𝑟𝑛𝑜𝑢𝑙𝑙𝑖(𝑝𝑋𝑖𝑗 )
𝑌𝑖𝑗 ~𝑃𝑜𝑖𝑠𝑠𝑜𝑛(𝑝𝑌𝑖𝑗 )
where logit(𝑝𝑋𝑖𝑗 ) = 𝛼0 + 𝛼1 𝐶1𝑖𝑗 + 𝛼2 𝐶2𝑖𝑗 + 𝑃𝑖 , log(𝑝𝑌𝑖𝑗 ) = 𝛽0 + 𝛽1 𝐶1𝑖𝑗 + 𝛽2 𝐶2𝑖𝑗 + 𝛽𝑋 𝑋𝑖𝑗 + 𝛽𝑍 𝑍𝑖 , 𝐼 is
the identity matrix (𝐶1 , 𝐶2 are independent with variance 1), and 𝑁 and 𝑁2 represent the univariate and
bivariate normal distributions, respectively. We used a Poisson log-linear model for generation of the
outcome because the Poisson distribution is closely related to the Bernoulli distribution when the event
rate is low, but it allows for direct specification of the risk ratio (RR), which is a more interpretable
parameter than the odds ratio and does not suffer from the ‘noncollapsability’ issue associated with the
odds ratio. Because we specified a homogeneous RR treatment effect (𝑒 𝛽𝑋 ), the estimand is the same
for all analytic approaches.
We considered a total of 13 simulation scenarios within this framework, summarized in Table 1.
The scenarios were chosen in order to vary the presence of associations between prescriber
characteristics and other factors, which we hypothesized, would determine the relative performance of
analytic approaches. These scenarios also varied the strength of the correlation in treatment choice
within prescribers, determined by 𝜎 2 , the number of patients per prescriber, and the overall study size.
Across all scenarios, we used 𝛼0 = −1 so that the prevalence of exposure was approximately 27%, 𝛽0 =
−3 so that the outcome risk was approximately 5%, and 𝛼1 = 𝛼2 = 𝛽1 = 𝛽2 = 0.5. Within each
scenario, we reran the simulation 4 times in a 2x2 factorial design, varying the true effect of exposure on
outcome (𝛽𝑋 = −1 or 0, corresponding to a true RR of 0.37 or 1.0, respectively) and varying the
presence of unmeasured confounding (𝐶1 was always measured, but in some scenarios 𝐶2 was set aside
to be “unmeasured” so it was not used in analyses) for a total of 52 unique simulation settings. In each
setting, we generated 1000 datasets, except scenarios 10 and 13, where we generated 5000 datasets to
account for the increased Monte Carlo error in those scenarios.
Definition of prescriber preference
In each simulated dataset, we measured prescriber preference as the “last prescription” within
prescriber, defined as a binary variable that indicated the treatment for the most recent prior patient
within prescriber (𝐼𝑉𝑖𝑗 = 𝑋𝑖𝑗−1 ). This variable is undefined for the first patient within each prescriber;
therefore, all analyses that utilize the IV were performed in the subset of patients with a defined IV.
Treatment effect analyses
We estimated treatment effects using five potential analysis approaches. In general, we focused on
simple approaches that are appropriate for estimating a RR treatment effect. For simplicity, we utilize 1to-1 PS matching, but in practice, investigators may prefer variable ratio matching or other PS methods
that retain more patients in the analysis. The first approach was a simple unadjusted RR. In the second
approach, we adjusted for measured patient-level characteristics, but we did not use prescriber
information. We estimated an ordinary PS (𝑃𝑆1 ) as the predicted probability of the indicated treatment
from the logistic regression model including all measured covariates. Based on this PS, we used 1-to-1
nearest-neighbor matching (27) with a caliper of 0.1 standard deviations of the PS and estimated the
crude RR in the matched cohort. The third approach was identical, except that the PS model (𝑃𝑆2 )
additionally included a random intercept for prescriber. When both 𝐶1 and 𝐶2 were measured, this
model was given by:
logit{Pr(𝑋𝑖𝑗 = 1)} = 𝛼̂0 + 𝛼̂1 𝐶1𝑖𝑗 + 𝛼̂2 𝐶2𝑖𝑗 + 𝑈𝑖
𝑈𝑖 ~𝑁(0, 𝜎̂ 2 ).
The third approach employed 1-to-1 matching on 𝑃𝑆1 , but matching was restricted to within prescriber
strata.
The final approach utilized IV analysis. Using the defined prescriber preference variable as the
IV, we estimated the relative effect of treatment adjusting for measured covariates via a two-stage
regression. When both 𝐶1 and 𝐶2 were measured, this regression is given by:
𝑝̂𝑋𝑖𝑗 = Pr(𝑋𝑖𝑗 = 1) = 𝜂̂ 0 + 𝜂̂ 1 𝐶1𝑖𝑗 + 𝜂̂ 2 𝐶2𝑖𝑗 + 𝜂̂ 𝐼𝑉 𝐼𝑉𝑖𝑗 ,
log{𝐸(𝑌𝑖𝑗 )} = 𝛽̂0 + 𝛽̂1 𝐶1𝑖𝑗 + 𝛽̂2 𝐶2𝑖𝑗 + 𝛽̂𝑋 𝑝̂𝑋𝑖𝑗
From the first stage, we extracted the predicted probability of treatment (𝑝̂𝑋𝑖𝑗 ), which was used in a
second stage log-linear Poisson model (28, 29). The estimated coefficient 𝛽̂𝑋 was taken to be the
estimated log RR from the IV analysis.
Appendix Figures
Appendix Figure 1: Bias of the log-RR estimates for all analysis approaches across the first 7 simulation
scenarios. Results are shown for settings with a true log-RR treatment effect of -1.0. The solid line
displays results from the crude, unadjusted analysis.
Appendix Figure 2: Bias of the log-RR estimates for all analysis approaches across simulation scenarios
8-13. Results are shown for settings with a true null treatment effect. The solid line displays results
from the crude, unadjusted analysis.
Appendix Figure 3: Bias of the log-RR estimates for all analysis approaches across simulation scenarios
8-13. Results are shown for settings with a true log-RR treatment effect of -1.0. The solid line displays
results from the crude, unadjusted analysis.
Appendix Figure 4: Imbalance across exposure groups and across IV groups in the first 7 simulation
scenarios. The left, middle, and right panels display imbalance on C1, C2, and Z, respectively. The solid
line is the crude imbalance across exposure groups before matching. Results are shown for settings
where C2 is observed.
Appendix Figure 5: Imbalance across exposure groups and across IV groups in simulation scenarios 8-13.
The left, middle, and right panels display imbalance on C1, C2, and Z, respectively. The solid line is the
crude imbalance across exposure groups before matching. Results are shown for settings where C2 is
unobserved.
Appendix Figure 6: Imbalance across exposure groups and across IV groups in simulation scenarios 8-13.
The left, middle, and right panels display imbalance on C1, C2, and Z, respectively. The solid line is the
crude imbalance across exposure groups before matching. Results are shown for settings where C2 is
observed.
Simulation code
risk.ratio <- function(x, y) {
n1 <- sum(x)
n0 <- sum(1-x)
r1 <- sum(y*x)/n1
r0 <- sum(y*(1-x))/n0
r1/r0
}
logit <- function(x) log(x/(1-x))
expit <- function(x) exp(x)/(1+exp(x))
library(lme4)
library(MatchIt)
presSim <- function(fname, a, b, theta, gamma, s2 = 1.2, nsim = 1000,
unmeas = FALSE, n=5000, np=1000) {
bal.c1 <- bal.c2 <- bal.pc <- matrix(nrow = nsim, ncol = 5)
res <- matrix(nrow = nsim, ncol = 5)
colnames(bal.c1) <- colnames(bal.c2) <- colnames(bal.pc) <- colnames(res) <c("crude", "regPS", "presPS", "stratPS", "z1")
covs <- switch(unmeas+1, c("c1", "c2"), "c1")
a0 <- a[1]; a1 <- a[2]; a2 <- a[3]
b0 <- b[1]; b1 <- b[2]; b2 <- b[3]; bx <- b[4]; bp <- b[5]
for(i in 1:nsim) {
dat <- data.frame("pres" = sample(np, n, replace=TRUE, prob=rep(1/1:10, np/10)),
"x" = 0, "y" = 0, "pc" = 0, "pp" = 0, "c1" = 0, "c2" = 0)
pc <- rbinom(np, 1, .4) # prescriber characteristic
dat$pc <- pc[dat$pres]
# mapped to the patient level
dat$pp <- rnorm(np, theta*pc, sd=sqrt(s2))[dat$pres] # prescriber preference
dat$c1 <- rnorm(n, gamma*dat$pc); dat$c2 <- rnorm(n, gamma*dat$pc)
dat$x <- rbinom(n, 1, expit(a0 + a1*dat$c1 + a2*dat$c2 + dat$pp))
dat$y <- rpois(n, exp(b0 + b1*dat$c1 + b2*dat$c2 + bx*dat$x + bp*dat$pc))
dat <- dat[order(dat$pres),]
# order within doc
dat$vn <- unlist(tapply(rep(1,nrow(dat)), dat$pres, cumsum)) # visit number
# create IV
z1 <- ifelse(dat$vn > 1, c(1,dat$x), NA)
# estimate ps models
form <- as.formula(paste("x ~ ", paste(covs, collapse = "+"), sep = ""))
fit <- glm(form, data = dat, family = "binomial")
dat$ps1 <- fitted(fit)
form <- as.formula(paste("x ~ (1|pres) + ", paste(covs, collapse = "+"), sep = ""))
fit <- glmer(form, data = dat, family = "binomial")
dat$ps2 <- fitted(fit)
##### Calculate balance and estimate treatment effects
# crude
res[i,1] <bal.c1[i,1]
bal.c2[i,1]
bal.pc[i,1]
risk.ratio(dat$x, dat$y)
<- mean(dat$c1[dat$x==1]) - mean(dat$c1[dat$x==0])
<- mean(dat$c2[dat$x==1]) - mean(dat$c2[dat$x==0])
<- mean(dat$pc[dat$x==1]) - mean(dat$pc[dat$x==0])
# ignore prescriber
m.out <- matchit(x ~ c1, data = dat, distance = dat$ps1,
caliper = 0.1)
m.dat <- match.data(m.out)
res[i,2] <- risk.ratio(m.dat$x, m.dat$y)
bal.c1[i,2] <- mean(m.dat$c1[m.dat$x==1]) - mean(m.dat$c1[m.dat$x==0])
bal.c2[i,2] <- mean(m.dat$c2[m.dat$x==1]) - mean(m.dat$c2[m.dat$x==0])
bal.pc[i,2] <- mean(m.dat$pc[m.dat$x==1]) - mean(m.dat$pc[m.dat$x==0])
# use prescriber as random effect in ps model (above)
m.out <- matchit(x ~ c1, data = dat, distance = dat$ps2,
caliper = 0.1)
m.dat <- match.data(m.out)
res[i,3] <- risk.ratio(m.dat$x, m.dat$y)
bal.c1[i,3] <- mean(m.dat$c1[m.dat$x==1]) - mean(m.dat$c1[m.dat$x==0])
bal.c2[i,3] <- mean(m.dat$c2[m.dat$x==1]) - mean(m.dat$c2[m.dat$x==0])
bal.pc[i,3] <- mean(m.dat$pc[m.dat$x==1]) - mean(m.dat$pc[m.dat$x==0])
# stratify on prescriber
m.out <- matchit(x ~ c1, data = dat, distance = dat$ps1,
exact = "pres", caliper = .1)
m.dat <- match.data(m.out)
res[i,4] <- risk.ratio(m.dat$x, m.dat$y)
bal.c1[i,4] <- mean(m.dat$c1[m.dat$x==1]) - mean(m.dat$c1[m.dat$x==0])
bal.c2[i,4] <- mean(m.dat$c2[m.dat$x==1]) - mean(m.dat$c2[m.dat$x==0])
bal.pc[i,4] <- mean(m.dat$pc[m.dat$x==1]) - mean(m.dat$pc[m.dat$x==0])
# IV analysis
form <- as.formula(paste("x ~ z1 + ", paste(covs, collapse = "+"), sep = ""))
fit1 <- glm(form, data = dat)
prd <- fitted(fit1)
form <- as.formula(paste("y ~ prd + ", paste(covs, collapse = "+"), sep = ""))
fit2 <- glm(form, family = poisson, data = dat[!is.na(z1),])
res[i,5] <- exp(coef(fit2)["prd"])
bal.c1[i,5] <- mean(dat$c1[z1==1], na.rm = T) - mean(dat$c1[z1==0], na.rm = T)
bal.c2[i,5] <- mean(dat$c2[z1==1], na.rm = T) - mean(dat$c2[z1==0], na.rm = T
bal.pc[i,5] <- mean(dat$pc[z1==1], na.rm = T) - mean(dat$pc[z1==0], na.rm = T)
}
save(bal.c1, bal.c2, bal.pc, res, gamma, theta, a, b, s2,
file = paste(fname, ".Rdata", sep = ""))
}