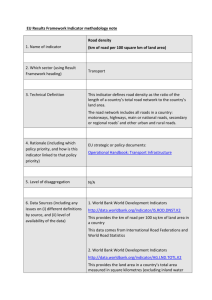
CAFI: Analytic Methods

CityMatCH
The National Organization of Urban MCH Leaders
CAFI: Analytic Methods
Pillar 2
Laurin Kasehagen, MA, PhD
2013
U n i v e r s i t y o f N e b r a s k a M e d i c a l C e n t e r
9 8 2 1 7 0 N e b r a s k a M e d i c a l C e n t e r
O m a h a , N E 6 8 1 9 8 - 2 1 7 0
Table of Contents
Analytic Methods for a Community Approach to Improving the Future of Our Youth ............................ 3
Always Be Prepared! A Motto for Boy Scouts, Epidemiologists, and Data Analysts! .............................. 3
Conducting Analyses with the Public Data Set ........................................................................................... 4
Accessing Restricted Data ........................................................................................................................... 4
Conducting a Stage 1 Analysis ..................................................................................................................... 5
Common Challenges in Using National Data for Local Level Estimates: Small Numbers and
Confidentiality ........................................................................................................................................... 5
Examine denominator size for each cell .............................................................................................. 7
Examine numerator size for each cell .................................................................................................. 7
Statistical Challenges and Potential Solutions .......................................................................................... 8
Addressing small numbers ................................................................................................................... 8
Using synthetic estimates .................................................................................................................... 9
Combining variable responses ............................................................................................................. 9
Including confidence intervals ............................................................................................................. 9
Setting thresholds for standard errors ................................................................................................ 9
Dealing with missing data .................................................................................................................... 9
Dealing with variables that have limited variation .............................................................................. 9
Using local data to verify NSCH data ................................................................................................... 9
Comparing Your Local Data to a Standard .............................................................................................. 10
Making Your Own Indicator .................................................................................................................... 10
Stage 1 Analysis Summary ........................................................................................................................ 10
Conducting a Stage 2 Analysis ................................................................................................................... 10
Iterative process ................................................................................................................................. 11
Problem analysis of the initial risk domain ........................................................................................ 11
Synthesis of Stage 1 and Stage 2 data ............................................................................................... 12
Prioritization ...................................................................................................................................... 12
Recommendations for action ............................................................................................................. 12
Stage 2 Analysis Summary ........................................................................................................................ 14
Summary: Analytic Methods Field Guide ................................................................................................ 15
References ................................................................................................................................................. 15
Analytic Methods for a Community
Approach to Improving the Future of our
Youth
In shaping this pilot project for local health departments (LHDs) and their community stakeholders, we realized that too few LHDs have the breadth of information on the emotional and physical health of the youth in their communities. To address this gap, we explored the use of restricted, local level data collected in a national surveillance system, the National
Survey of Children’s Health (NSCH). The NSCH collects information on health status as well as a number of factors that relate to child well-being, such as medical home, access to care, family interactions, parental health, school and afterschool experiences, and safe neighborhoods. In
2011-2012, the Survey also asked about uninsured children from some households, to assess their parents' awareness of, experience with, and interest in enrolling in the Medicaid and the State Children's Health Insurance
Program (CHIP).
While the data from the NSCH are robust and can be generalized at the national and state levels, application of the data at local levels comes with some caveats. In addition to the specific attention that needs to be paid to data issues, the approach for improving adolescent health emphasized in this field guide is embedded in the concepts of evidence-based public health. [Brownson et al. 2009; Brownson et al. 1999] We recommend that local health departments adopt and follow an evidencebased public health approach that includes the following elements:
making decisions using the best available peer-reviewed evidence (both quantitative and qualitative research);
using data and information systems systematically;
applying program-planning frameworks (that often have a foundation in behavioral science theory);
engaging the community in assessment and decision making;
conducting sound evaluation; and
disseminating what is learned to key stakeholders and decision makers.
[Brownson, Fielding, and Maylahn 2009, p
177]
This section of the field guide will highlight the analytic areas in which local epidemiologists and analysts should exercise caution when conducting and interpreting local area data from the NSCH.
Data
Community
Always Be Prepared! A Motto for Boy
Scouts, Epidemiologists, and Data
Analysts!
Before embarking upon the analysis train, we recommend that you formalize a step-by-step plan that sets out how you will analyze both the public data and restricted data. Specifying a data analysis plan in advance has some distinct advantages, the plan:
Helps restrain curious analysts from conducting fishing or data mining expeditions;
Helps analysts identify variables needed in the analysis and the inadvertent omission of important variables;
Helps analysts think about how variables are coded and how they may need to be recoded;
Helps analysts determine how they might measure an outcome of interest; and
Creates a roadmap for analysts to follow.
The plan is also useful if you intend to submit a research proposal for the use of restricted data.
A typical data analysis plan includes the following 7 elements.
1. Abstract. The abstract should contain an overview of the background, methods, results, conclusions, and the public health implications of the proposed analysis.
2. Research Questions.
This portion of the plan should specify the questions that you hope to answer with the analysis.
3. Description and Rationale for Use of
Restricted Data. The plan should include a discussion of how the data will be obtained, the underlying sampling methodology, how the data were weighted, sample size, and a list of the variables to be included in the analysis. For restricted data analyses, the plan should specify how the restricted data will be accessed through the National Center for Health Statistics. The plan also should include a discussion of how the data will be used and what the analyst hopes to do with findings.
4. Public Health Benefit.
The plan should briefly describe the benefit that will be derived from the use of the restricted data and analysis.
5. Methods and Analytic Strategies.
The plan should describe the proposed analytic strategies to be employed -- exploratory, descriptive, inferential, or some combination of these. The plan should also specify the model(s) to be run in the analysis.
6. Variable Specification.
In addition to a list of the variables to be included in the analysis, the plan should specify the primary outcome(s)
(e.g., the dependent variable(s)), covariates and independent variables. The plan should clearly identify the public variables and specify the restricted variables needed for the analysis. The plan should also specify how the variables are constructed, variable type (e.g., continuous, ordinal, or categorical), how the variables are coded and may be recoded, whether and how imputed variables will be used, whether and how summary variables will be used, and, in general, how the variables will be used in the analysis.
7. Anticipated Challenges and Solutions.
The plan should identify the challenges anticipated by the analyst and how the analyst proposes to resolve or deal with the identified challenges. At a minimum, the challenges should address missing data, reliability / quality of data, temporal data issues, small numbers, and outliers / extreme values. In the event, that the outcome has limited variation, the analyst should also determine how this will be addressed.
Conducting Analyses with the Public
Data Set
Before requesting restricted data, conduct an analysis of the public data set – the national data as well as a subset (e.g., your state ’s data).
This is beneficial to you because it will test your data analysis plan and help you have a good understanding of what the data are for the region, state, or nation. At a minimum, you should conduct the exploratory and descriptive analyses of the variables of interest. And, conduct the inferential statistics with the outcome of interest and the covariates and independent variables of interest.
The analytic results can give you clues as to the types of restricted (local level) data you need and the limitations of sample size. And, once you have the local level data, it will help you understand the ways in which your community differs and where local efforts should be concentrated.
Accessing Restricted Data
If you would like to access the restricted, local level data for the NSCH, the National Center for
Health Statistics has outlined the steps for acquiring access on their Research Data Center website -- http://www.cdc.gov/rdc/. In addition to specifying the data set and restricted variables that you would like to access, you will also need to determine the best mode for accessing the data and the statistical analysis software you will use. Further, you will need to prepare and submit a research proposal that outlines the need for the restricted data and how the data will be used to address a public health concern along with a public data set to which the restricted variables will be linked.
If your proposal is approved, then you will be granted access to conduct analyses (with certain limitations) for the period of time specified in your agreement with the National Center for
Health Statistics. You also might incur a onetime ‘set-up’ fee and monthly ‘access’ fees.
In most circumstances, you will only be able to analyze the data and see the output. You will not be able to access or see the restricted data in either table or individual record form.
In the alternative, you can work with CityMatCH to facilitate this request on your health department’s behalf. The CityMatCH epidemiologist will work with your LHD and conduct the Stage 1 analysis for you. These data can then be taken and supplemented by other local data in the Stage 2 analysis.
Conducting a Stage 1 Analysis
In preparing for both the Stage 1 and Stage 2 analyses, it may be helpful to outline a plan for analysis (see pp 1-2 of this document). This will help you to make sure that you have included all the necessary variables and identified all the analyses that you need to conduct – this is particularly helpful if access to the data is dependent upon a time-limited agreement.
Once you have obtained access to the data, we recommend that you perform the same types of analyses that you conducted with the public data set. This serves a couple of purposes. First, that the data set containing the restricted data elements is the same as the public data set, but for the newly linked restricted variables. And, second, it provides the local level data details necessary for understanding the disparities in health, risk factors, and assets of the youth in your community. These data can be compared to benchmarks such as the HP2020 indicators, or state / local benchmarks of health, or a comparison group with optimal outcomes. This process also will help you identify gaps and limitations in the data where additional analyses in Stage 2 will be helpful.
Common Challenges in Using National Data for Local Level Estimates: Small Numbers and Confidentiality
In October 2012, the Assessment Operations
Group (AOG) of the Washington State
Department of Health revised its Guidelines for
Working with Small Numbers (AOG Guidelines
2012), earlier versions of which were adopted by a number of both state and local health departments. [AOG/Washington State DoH.
Guidelines for working with Small Numbers ,
2012] In the Guidelines, the AOG addresses why small numbers are a concern when conducting public health assessments:
Public health policy decisions are fueled by information, which is often in the form of statistical data. Questions concerning health outcomes and related health behaviors … often are studied within small subgroups of a population ... [T]he need to better understand the relationships between environment, behavior, and health have led to increased demand for information about small populations.
These demands are often at odds with the need to preserve privacy and data confidentiality. Small numbers also raise statistical issues concerning the accuracy, and thus usefulness, of the data. [AOG
Guidelines 2012, page 2]
In general, problems with confidentiality arise when there are small denominators (population size represented in a specific cell in a table); and, problems with data reliability arise when there are small numerators (the number of cases in a specific cell in a table. In the case with using the NSCH restricted data, we can have confidentiality issues when the subpopulation of interest to the local health department is small (i.e., population size
[denominator] within a given cell is small). And, we can have data reliability issues because in many instances the unweighted case numbers may be small (i.e., number of cases in a given cell is small [numerator]). See Example 1 below.
Example 1.
In the case of Douglas County, we have a relatively small subpopulation (e.g., a small denominator) of the state data from the 2007 NSCH. While it is greater than 300, the potential risk of violating confidentiality when working with subgroups of the 391 youth. When we stratify the data by race / ethnicity, we have very small numerators for youth who are Hispanic, Black non-Hispanic, multi-racial non-
Hispanic, and other race non-Hispanic. In this example, even though the data have been de-identified, it may present an issue of confidentiality. In Douglas County, youth of color are a minority of the youth and it could be possible to identify certain youth using both race / ethnicity and secondary characteristics, such as age or special health need. Further, some of the strata for race / ethnicity have very small cell counts
(i.e., ‘other, NH’) (e.g., a small numerator) and thus may present both issues of confidentiality and reliability.
So, you may ask, “w hy do we question the reliability of statistics based on small numbers?
”
The AOG Guidelines state:
Analysts in maternal and child health who work in infant mortality are all too familiar with random variation and the fluctuation of annual rates, based on small numbers. Similar random variation may also be observed in these NSCH data from survey period to survey period. … random variation may be substantial when the measure, such a rate or percentage, has a small number of events in the numerator or a small denominator. Typically, rates based on large numbers provide stable estimates of the true, underlying rate. Conversely, rates based on small numbers may fluctuate dramatically from year to year, or differ considerably from one small place to another small place, even when differences are not meaningful. [AOG
Guidelines 2012, page 3]
Even in public data sets, there is the potential for a breach in confidentiality. For example, in a community, we might be aware of individuals with certain, reportable health conditions. So in both public data sets and restricted data sets, we establish rules or guidelines to help prevent the inadvertent, unintentional disclosure of confidential information. The guidelines restrict the disclosure of identifiable information (e.g., name, address, social security number, etc.) and they also may restrict the release or disclosure of case counts (numerator information) or
population size (denominator information) or a combination of this information. This is done to help ensure the privacy of the individuals who participated in the survey.
For our purposes, we concur with the recommendations of the AOG Guidelines and recommend the following when working with small numbers.
Examine denominator size for each cell.
For each variable in the analysis, run a crosstab of the independent or covariate against the dependent variable and “…consider the size of the denominators, i.e., the population size represented in each cell in the table. Generally, tabular data based on denominators greater than 300 persons per cell present minimal risk for individual identification. The risk of violating confidentiality increases substantially when data are tabulated for small subgroups of the population within small geographic areas. The analyst should exercise caution if the population size is between 100 and 300, and extreme caution is warranted when the population is less than 100.
” [Colorado Guidelines, page 2]
Examine numerator size for each cell.
“Second, data analysts should consider the number of events in each cell of a table to be released (i.e., the numerator for a rate calculation). If the count of cases or events in a cell is less than three, the data analyst needs to consider whether a breach of confidentiality is likely. A count of no events in the cell is clearly no threat to confidentiality, but a count of one or two events may be.
” [Colorado Guidelines, page
2] With restricted data from NCHS, cell counts below the established threshold (usually 5) are not reported (i.e., suppressed) to the researcher.
Cell suppression is used to withhold the data
(numerator) in the cell which fails to meet the threshold, followed by suppression of other cell values in order to avoid inadvertent disclosure through back-calculation. (See Example 2.)
Example 2.
In the case of Douglas County as well as the Nebraska reference group, we have a handful of youth who have repeated a grade in school. And, fewer than 5 youth who have ‘never / rarely / sometimes’ cared about doing well in school and doing all required homework. The actual count of youth below 5 has been suppressed. So, we don’t actually know those values. Likewise, we cannot calculate a percentage or confidence interval for these values.
The AOG Guidelines and the Colorado
Guidelines also identify a lesser known risk to confidentiality -- group identification. "Here, something confidential is revealed about a group of individuals identifiable by their age, race, or other reported [observable] characteristics.
While this type of disclosure has received less attention than individual disclosure, it represents an emerging concern and should be considered when deciding whether to publish [or disseminate] data. Note that this is more of a problem when the prevalence [of a characteristic or condition] is high (over 80%) [in the group rather] than when the prevalence ... is low."
[Colorado Guidelines, pp 3-4]
In summary, consider the following practices to assess and reduce confidentiality risks:
Be cautious when reporting rates or ratios based on denominators less than 300 and extremely cautious when denominators are less than 100.
Be cautious when reporting counts less than
[10 and be extremely cautious when reporting counts of 5 or less].
Be cautious when reporting a specific
(confidential) characteristic of a population if a very high proportion of the population has this characteristic.
When producing multiple tables, be careful that users cannot derive confidential information through a process of subtraction.
[Colorado Guidelines, page 4]
Statistical Challenges and Potential
Solutions
Working with local level data from the National
Survey of Children's Health or, for that matter, any national surveillance system, has some inherent challenges. Key challenges of which analysts should be aware, include: small cell counts (both numerator and denominator), missing data, and outcomes with limited variation.
Addressing small numbers.
In preparing a data table for dissemination, it is recommended that analysts first examine the counts in each cell of the table. If rates are desired and the numerator of any cell is less than 20, an effort should be made to increase the size of the numerator. (Use of 20 events as the threshold for reliability is consistent with standard CDC practice.)
Techniques that can be used to increase the size of the denominator as well as the numerator include:
Increasing the sample size by including both children and youth,
expanding the geographic area of study,
combining multiple years of data, and/or
collapsing or combining variable categories.
The first three techniques are forms of data aggregation. Aggregation increases the effective population size (the denominator), and numerators likely increase in number as well.
One potential solution to small numbers is to expand the sample size by increasing the age range of study. We recommend that the data be limited to youth between the ages of 10-17.
Interventions among the younger and older youth will tend to be more similar than those of younger children (i.e., under 10 or under 5).
Thus, we do not recommend increasing the age range of the sample in this type of study (e.g., 6-
17 years). We also recommend that if the sample size is sufficient, the data be stratified by age group to determine if there are differences between younger (10-13 years) and older (14-17 years) youth.
Another technique that you might consider is expanding the geographic scope of study. In some cases, this may not be politically acceptable, may not have the same underlying demographic characteristics, or it may not make sense from a service / programmatic perspective
(e.g., implementation of potential interventions).
However, if increasing the area of study from a city to a county / metropolitan statistical area or a county to tri-county region makes sense, then increasing the sample size could be advantageous and provide a better foundation for making generalizations to the youth population as a whole within a given geographic area. If sample size is sufficient, the data could be stratified to compare the smaller geographic unit of interest with the larger geographic unit.
Another technique that could be used to increase small cell counts is to combine multiple years of data. With regard to the NSCH data, depending on the indicator, we recommend that analysts explore combining prior survey years of data. For example, it may be possible to create a sufficient sample size with the geographic scope and age range by combining the data from the 2007 NSCH and the 2011-12 NSCH.
We recommend that the analyst
determine the indicators that are the same from 2 or more survey periods,
run data for the indicators of interest,
conduct a trend analysis or compare the data from different survey periods to see if significant differences between the survey periods exists, and o if no change in trend/significant difference between years, combining data may be possible. o if change in trend/significant difference, do not combine years of data.
If the small cell counts / small numbers occur in in racial / ethnic response categories, we recommend that the local health department identify supplemental data sources or collect its own data if no other source/option. Additional guidance it provided in the Appendices.
Using synthetic estimates.
If the analyst has exhausted all the potential ways to boost sample size, the analyst could use county, metropolitan statistical area, or state data and information about the local area to derive a synthetic estimate. (See Appendix VIII.) The synthetic estimates could then be compared to the raw data for the local area to determine whether the estimate is representative of the events locally observed.
Combining variable responses.
There are numerous multi-level variables -- Likert scale responses-- than that could be combined, and, thus, increase the cell size of numerators. For example, Likert responses of never, rarely, sometimes, usually, and always could be combined into a dichotomous response of never or ever or a 3-level response never/rarely, sometimes, usually/always. It is very helpful to know the underlying distribution of the responses and to use the distribution and knowledge of the question to create a meaningful combination of the responses. The aggregation of the values is appropriate when levels or categories can be meaningfully combined to produce a variable with information that can be used rather than suppressed or omitted altogether. Aggregation also is a primary method used to collapse a dataset in order to create tables with no small numbers as denominators or numerators in cells.
Including confidence intervals.
“The inclusion of confidence intervals for rates is strongly recommended regardless of the number of health events, but it is especially important when the count is less than 20. Generally, rates with fewer than 20 events in the numerator have very wide confidence intervals. For example, an infant death rate of 10 per 1,000, based on 20 deaths out of a population of 2,000 live births, has a Poisson-based 95% confidence interval between 6 and 15. Clearly, this is not very precise information and users of the data need to know this.
” [Colorado Guidelines, page 4]
“In instances where it is not feasible to incorporate confidence intervals into a data table it is recommended that analysts:
Always report the numerator on which the rate is based, and
include a footnote indicating that rates based on fewer than 20 events are likely to be unstable and imprecise.” [Colorado
Guidelines, page 4]
Setting thresholds for standard errors.
We also recommend that analysts set a threshold for standard errors (SE) to not greater than 0.3. [cite from NCHS?]
Dealing with missing data issues.
In general, only a handful of the questions / indicators have
>10% missing data. However, in the event that there is too much missing data (>10%) for a given indicator, you could look for an equivalent indicator from another data source (e.g.,
American Community Survey) and use this data as a proxy or to confirm / refute the NSCH data for the indicator of interest. Or, if a particular indicator has >10% missing, an alternative approach could be to run an analysis with missing, then without missing and determine if there are significant differences.
Dealing with variables that have limited variation.
Sometimes the analyst or epidemiologist will be asked to explore a variable in which there is very limited variation, i.e., almost all of the population has the same response. There is no power to be gained from looking at this type of variable – unless it is a potential confounder -- and including it in a family of independent variables can reduce the power to detect an overall impact. So, for example one can write “In order to limit noise caused by variables with minimal variation, questions for which 95 percent of observations have the same value within the relevant sample will be omitted from the analysis and will not be included in any indicators or hypothesis tests. In the event that omission decisions result in the exclusion of all constituent variables for an indicator, the indicator will be not be calculated.”
Using local data to verify NSCH data.
We also recommend that if the NSCH data is some of the only available data to the locality, try to verify some of the demographic / social determinant of health data with other census, population-level data (e.g., American
Community Survey). If the demographic or social determinant data differs significantly, document limitations and concerns. If NSCH data demographics are not representative per external data, we recommend that NSCH data for a locality not be stratified. If NSCH data cannot be compared with external data for reliability, then use data with caution.
Comparing Your Local Data to a Standard
There are several ways in which you can compare the findings from your community. For example, indicators from your data could be compared to
a national benchmark – HP2020,
a state benchmark,
a community benchmark, or
to an ideal reference population.
In the event, that HP2020 does not have an appropriate indicator or benchmark, we recommend that the analyst seek other sources, such as the Preconception Health Indicators,
Chronic Disease Indicators, or state and community benchmarks, and modify as needed.
Although, we recommend that analysts use selected HP2020 goals as a benchmark or reference to an 'ideal' health goal / indicator of the state or community, we recognize that many communities want to compare their outcomes with those of a reference population. We recommend that you work with the CityMatCH epidemiologist to select an appropriate reference population.
Making Your Own Indicator
For NSCH data, if no existing indicator is available, create one! Indicators of adolescent health have not yet been fully developed like indicators of preconception health or chronic disease. However, the NSCH, the Youth Risk
Behavior Surveillance System (YRBSS), and local surveys have a number of questions that provide insight to the health and well-being of youth. Some of these questions can be used as a marker for the health and assets of the youth in your communities.
If more than one existing indicator is available, use the best indicator for your purposes. For example, which is the best variable: maternal education? household education? or graduation rate? The best indicator might be the indicator in the NSCH data set and the one with the least amount of missing data. Consider the following in determining the best indicator for your analysis:
review NSCH to identify indicators that are comparable to an HP2020 indicator or state / community benchmarks, or
combine NSCH variables when appropriate as composite scores, or
seek alternative (e.g., YRBSS) or local data sources for equivalent benchmarks when NSCH variables do not contain the information that you are seeking.
Stage 1 Analysis Summary
CityMatCH can be the broker / agent to successfully work with local health departments to
obtain NSCH Stage 1 data,
conduct the initial analyses and subanalyses on Stage 1 data,
help identify initial risk domains,
help access local level data for Stage 2, and
help identify the potential interventions appropriate for a community that might address concerns across several domains.
For comparison in Stage 1, show the national data, state data, community data and the national benchmarks. If cities would like a reference group for Stage 1 -- rather than national or state benchmarks -- then the LHD may want to consider a reference population with similar demographics and good outcomes.
Depending on the capacity of the LHD,
CityMatCH can provide technical assistance and guidance for Stages 2 and 3.
Conducting a Stage 2 Analyses
Using the National Survey of Children's Health data enables analysis across more than a dozen preconception health and life course indicators, a number of chronic disease indicators, and measures of adolescent risks and assets.
Stage 2 data gathering and analysis are additional important steps that are necessary to identify the domains of concern for an intervention population, health disparities that need to be addressed, and health goals.
How will Stage 2 analysis be completed?
How can a problem analysis framework be used to better understand initial domains of concern?
How will the Stage 1 and Stage 2 information be synthesized?
How will areas of concern be prioritized?
How will recommendations for areas of concern be presented?
Iterative process.
A successful Stage 2 analysis incorporates an iterative process between the local health department and its community stakeholders to communicate the overall health of the adolescent population, the data from key indicators, and potential risk domains (and assets). We recommend that the level of technical assistance between the LHD and CityMatCH be scaled to reflect the capacity of the local health department.
Problem analysis of the initial risk domain.
To better understand the domain of concern, it may be helpful to brainstorm with your workgroup and complete a problem analysis. A problem analysis is a pictorial representation of the underlying factors that can impact
(negatively or positively) on a health outcome and how these factors relate to one another. A blank template for a problem analysis is included in the Appendices.
To introduce the idea of the problem analysis to your workgroup, you might consider having a facilitator and a script. See Script Example.
To develop the diagram, turn the problem or domain of interest into a clear statement.
Instead of placing “Breastfeeding” in the target indicator/problem area of the diagram, state
“Mothers choose not to continue breastfeeding.”
Try to be as specific as possible.
Use the correct levels of the diagram for your precursors. Using the correct levels will assist in a useful problem analysis. The levels help in identifying whether and how the factors are related to each other.
Script Example. “Now that we have some initial ideas about the domains of concern that face ou r community’s youth, it would be helpful to create a problem analysis diagram for the priority health problems that have been identified in our analysis. This diagram is intended to present a picture of the problem as we see it in our community. It provides a simple way to explain our best conclusions as to the causes of or risk factors associated with and the assets that buffer the problem in our community. It is also intended to present a more comprehensive understanding of how larger societal, local community and individual characteristics interact in creating the problem. The process also requires that we define the short or long term consequences of not intervening. We think that this understanding will help us to develop rational strategies, realistic objectives and evaluation measures that will reflect the impact of our strategies.”
The three levels reflect different domains that can impact the youth of interest.
The first level includes factors relevant to the particular youth or group of youth with the identified problem, e.g., genetic factors, biological factors, and personal behaviorsthat are directly or indirectly related to the identified problem.
The second level includes factors in the environment/community in which the youth resides, that affect the youth or are related to individual level factors, e.g., family poverty, poor quality schools, and inadequate health resources.
The third level includes larger societal factors that have a more global affect on the health and well-being of youth exposed to their effects e.g. state or national conditions, policies or attitudes.
To determine causal pathways answer the question, “How do these factors relate to one another and the problem statement?” Place
your causal pathways on the diagram or use separate sheets to draw pathways. Once a pathway is visualized, it presents possibilities for interventions. It also helps to identify the potential need for indicators and sources of data.
Can the same factor be active at more than one level? Yes, depending on whether your group thinks that there are ways to intervene at the local level, e.g., there may be lack of a national policy on universal health insurance for children, but county or city action can be initiated to redirect local funds to provide insurance. In the latter case, lack of insurance can be a factor at both the local institution level and the societal level.
How are the levels useful? The levels can assist in identifying whether and how factors relate to one another. This in turn helps us to make decisions about indicators, measurement, where to intervene, i.e., directly with the affected youth, with the family or local institutions or through policy or legislative action at the state or national level.
How are decisions made about those causal pathway(s) in which to intervene and best intervention point(s)?
This is the time to consider findings from the peer review literature, risk analysis and local input, such as special population concerns or resource availability.
Use literature reviews, survey results, interviews with experts and relevant data to assess the information presented in the diagram so far.
Know your county resources —what can your county feasibly do with its resources?
How many intervention strategies can be accomplished? In larger counties or those with more resources or where collaborations are able to tap multiple resources, more than one pathway and/or several points of interventions can be addressed.
Be sure to keep a record of the factors used in intervention decision-making so that you can summarize the process and supporting factors to the larger working group.
Once you have completed the problem analysis, use the Tables 1 and 2 below to identify the data sets and indicators that may help inform the domain of interest.
Synthesis of Stage 1 and Stage 2 data. The synthesis of the Stage 1 and Stage 2 information is also an iterative process among CityMatCH, the local health department and core community stakeholder workgroup. These collaborative participants are charged with reviewing the overall health of the adolescent population, the data from key indicators, and potential risk domains (and assets) from the Stage 1 and
Stage 2 data. Together, they will:
Use Stage 2 data to verify / validate Stage 1 data, and
Use Stage 2 data to provide additional local level detail about the state of adolescent health or particular risk domains.
Prioritization.
How will areas of concern be prioritized? Stage 1 data is the big picture and could be used to pin-point areas where additional research or exploratory analyses need to be conducted in an overall risk domain or disparities within a domain. Stage 2 data validates Stage 1 data and provides additional details about the risk domain or disparities.
Stage 1 and Stage 2 data together create a picture of a community's adolescent population health, assets, and potential problem areas.
The refined picture is then brought to the core community stakeholder workgroup for discussion.
Recommendations for action.
Recommendations for areas of concern will be supported by the data and the collaborative participants will work with community and with programmatic representatives to identify potential interventions with an evidence-base that fits the population of interest.
Potential sources of data for Stage 2 Analysis are shown in Table 1. (Note: These sources are examples and not exhaustive.)
Table 1. Stage 2 Data Sources
National Data Sources
American Community Survey (ACS) – community characteristics, level of poverty --
http://www.census.gov/acs/www/
Behavioral Risk Factor Surveillance System (BRFSS) -- older adolescent health (18-24 yrs); oversampling of children on different health topics --
http://www.cdc.gov/brfss/
Data on areas that have shortages of health professionals (HPSAs) and that are designated medically underserved areas (MUAs) --
http://hpsafind.hrsa.gov/HPSASearch.aspx
National Electronic Ijury Surveillance System (NEISS) --
http://www.cpsc.gov/en/Research--
Statistics/NEISS-Injury-Data/
National Immunization Survey (NIS) --
http://www.cdc.gov/nchs/nis.htm
Pregnancy Risk Assessment Monitoring System (PRAMS) --
http://www.cdc.gov/PRAMS/
SAMSHA data on mental / behavior health and substance use (e.g., emergency room data
(DAWN) and behavioral health prevalence data (NSDUH)) --
http://www.samhsa.gov/data/
Youth Risk Behavior Surveillance System (YRBSS) --
http://www.cdc.gov/HealthyYouth/yrbs/index.htm
State Data Sources
vital records -- birth, death
hospital discharge data
child death review
injury surveillance data
juvenile justice system data on gangs, victimization
CMS / Medicaid
school-nurse surveys
state specific surveys o California Health Interview Survey (CHIS) --
http://healthpolicy.ucla.edu/chis/Pages/default.aspx
o California Maternal Infant Health Assessment (MIHA) --
http://www.cdph.ca.gov/data/surveys/Pages/MaternalandInfantHealthAssessment(MI
HA)survey.aspx
o Oregon Healthy Teens Survey (OHT) --
http://public.health.oregon.gov/BirthDeathCertificates/Surveys/OregonHealthyTeens/P ages/index.aspx
Local Data Sources
school health / school-based health center data
local health department communicable disease / reportable data (communicable diseases,
sexually transmitted infections (STIs), reproductive health, lead poisoning)
WIC data child or adolescent health surveys o The Los Angeles Mommy and Baby (LAMB) Project – health of mothers before, during and just after pregnancy, oversamples for teen births --
http://publichealth.lacounty.gov/mch/LAMB/LAMB.html
o LA County Health Survey --
http://publichealth.lacounty.gov/ha/hasurveyintro.htm
ESRI / Community Analyst --
http://www.esri.com/software/arcgis/community-analyst/
Table 2. Exploring Supplemental Data Sources by Health Domain
Health Domain / Sub-Domain Data Set(s)
Stage 2 Analysis Summary
Stage 2 is about gathering additional, local level data and conducting additional analyses to better understand the domains of concern for an intervention population, health disparities that need to be addressed, and health goals. During
Stage 2, we recommend that your community determine:
Indicator(s)
Level of Data
(City, School, County,
State, Regional,
National, etc.)
How Stage 2 analysis will be completed,
Complete a problem analysis to better understand initial domains of concern,
Synthesize Stage 1 and Stage 2 information,
Prioritize the problems, and
Create initial recommendations for areas of concern.
.
Summary: Analytic Methods Field Guide
It is important for analysts to recognize that the process for identifying a problem, determining an intervention, and applying an evidence-based public health approach is not linear, nor is it necessarily circular as depicted below.
[Brownson, Fielding, and Maylahn 2009, p 189]
The process of analysis and fitting an intervention to the population is an iterative process, and, one which takes the information and involvement of many stakeholders throughout the community.
1. Community assessment
2. Quantifying the issue
3. Developing a concise statement of the issue
7. Evaluating the program or policy
4. Determining what is known through the scientific literature &
Conducting Stage 1 and Stage 2 analyses
6. Developing an action plan and implementing intervention
5. Developing and prioritizing program and policy options
References
Assessment Operations Group, Washington State Department of Health. Guidelines for Working with
Small Numbers . http://www.doh.wa.gov/Portals/1/Documents/5500/SmallNumbers.pdf
. Accessed
January 29, 2013.
Brownson, Fielding, and Maylahn. Evidence-based Public Health: A Fundamental Concept for Public
Health Practice, Annu Rev Public Health 2009, Vol 30:175-201.
Brownson, et al. Evidence-based Decision Making in Public Health, J Public Health Management Practice
1999, Vol 5(5):86-97.
Colorado Department of Public Health and Environment, Health Statistics Section. Guidelines for
Working with Small Numbers . http://www.cohid.dphe.state.co.us/smnumguidelines.html
. Accessed
January 29, 2013.
Glasgow & Emmons, How Can We Increase Translation of Research into Practice? Types of Evidence
Needed, Annu Rev Public Health 2007, Vol 28:413-433.