MC_prod_disun_final_04
advertisement

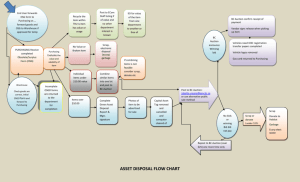
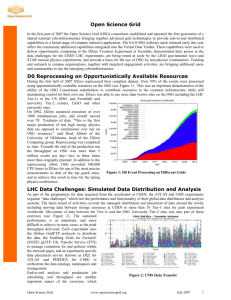
Monte Carlo Production An efficient and performant Monte Calro (MC) production system is crucial for delivering the large data samples of fully simulated and reconstructed events required for detector performance studies and physics analysis in CMS. The worldwide LHC Computing Grid (WLCG) which is mostly composed of the LHC Computing Grid (LCG) and Open Science Grid in the US (OSG), makes available of a large amount distributed computing, storage, and network resources for data processing. While the LCG and OSG provides the basic services for distributed computing, reliability and stability of both the grid services and the sites connected to them remain key issues, given the complexity of services and heterogeneity of resources in both grid flavors. A roubutst, scalable, automated and easy to maintain MC production system that can make an efficient use of both the grid resources is mandatory. Current Production System - ProdAgent The former CMS MC production system developed prior to 2006 had been used for several years and had shown a set of limitations such as : the lack of proper automation, monitoring, error handling, which were necessary for processing with a distributed environment with inherent instability and unreliability. The large central database in the old system was the source of a single point of failure. As a consequence, the production system was not efficient and robust enough, did not scale beyond running about thousand jobs in parallel and was very manpower-intensive. There was therefore the need for a new production system to automatically handle job preparation, submission, tracking, resubmission and data registration into the various data management databases (data bookkeeping service i.e DBS, location and transfer systems i.e. PhEDEx). In addition, the new CMS event data model (EDM) and software framework (CMSSW) made it possible to simplify the quite complex processing and publication workow in the old system. In particular, the lack of support for multi-step processing in a single job and the need of metadata generation from the event data in order to make the data available for further processing or analysis were two sources of big overhead. DISUN contributed to the redesign of the new MC production system at the design and implementation level, and the new production software that evolved as a result was called “ProdAgent”. The design of the new system (ProdAgent) aimed at automation, ease of maintenance, scalability, avoid single points of failure and support multiple Grid systems. In addition, ProdAgent integrated the production system with the new CMS event data model, data management system and data processing framework. The complete new production framework was a combination of several components : a) the production request management system (ProdRequest), and b) the actual production software (ProdAgent), and the c) ProdManager which was responsible of distributing the production workflows among all the instances of ProdAgents. The design was based on a pull approach i.e. the participating ProdAgents will pull the requests from the ProdManager system for processing when resources are available. ProdAgent was built as a set of loosely coupled components that cooperate to carry out production workflows. Components are python daemons that communicate through a mysql database. Components use an asynchronous subscribe/publish model for communication. Their states are persistently recorded in the database. Work is split into these atomic components that encapsulate specific functionalities. DISUN contributed significantly to the design/implementation/testing/debugging of several of these components which include: Requests management (queue, feedback and retrieval), job creation (process jobs and merge jobs), job submission, job tracking, and data management including movement using phedex, and data catalogs. Based on the initial and subsequent operational experiences over the past 4 years, the following contributions from DISUN were made periodically to improve the performance, scalability, and robustness of the ProdAgent, the condor batch system, job routing to the production sites and monitoring : Addition of error handler, trigger module, and job cleanup components in ProdAgent for the respective tasks Automatic monitoring of the health of all components and managing their states Implementation of better optimized/efficient database algorithm for the MergeSensor component with significantly improved database operations (5-7x faster) Parallelization of job creation/submission task (i.e. Bulk mode operation) enhanced the job creation/submission speed by 10x over the serial creation/submission mode Implementation of algorithm to manage multi-tier workflow processing (i.e. simulation, reconstruction, skimming etc.) in a single step to improve production efficiency and reduce overall latency in data delivery. Implementation of optimized algorithm for improved performance of the ResourceMonitor component for condor batch system Significant enhancement in the scalability of the condor batch software i.e. the ability of Condor to handle several tens of thousands of jobs at any given time without being too cpu-hungry in the process High performance dynamic routing of production jobs using the “JobRouter” (aka condor schedd-on-the-side) to OSG sites based on demand, workflow-to-site mapping, site availability and resource capabilities with “blackhole node” throttling ability Extension of MC production to CMS T3 and opportunistic (non-CMS sites) in the OSG with extensive testing/debugging etc Production Performance on the OSG : With constant improvements to the ProdAgent software, enhanced scalability of the Condor batch system including improved job routing, reliability of grid-middleware and operational stability at sites over the last 4 years, the performance of MC production on OSG has shown very consistent and significant improvement during this period. The volume of MC production has also steadily increased from year-to-year. This was possible due to a combination of a) the availability of increased computing resources at the sites over the years, b) clear and time tested procedure for quick and on demand installation/configuration of new production servers to expand production activities to additional computing resources when available, and c) increased operational expertise by the operators and their ability to quickly detect and resolve any production issues. The number of simultaneous running production jobs in OSG has gone up to 15000 (includes the resources at FNAL T1 and the 7 CMS T2s) in 2011 compared to the 2000 job slots that we started with at the beginning of 2006. With a well designed configuration of a production cluster at UW (includes several ProdAgent and MySQL database servers) coupled with a robust dynamic condor job routing mechanism, each single production server has demonstrated to handle 15K parallal running jobs without any significant performance issues. The increased production efficiency and quick error recovery cycle has enabled the MC production team in the US/OSG to consistently produce more than 50% of the total yearly MC statistics, with the rest coming from the LCG production sites/team. Around 25% of all the production workflows (out of ~ 10000 total workflows handled by all production teams) have been produced in the OSG over the last 3.5 years. This is because most of the large workflows were handled by the OSG team due to the large number of batch slots available at the US T2 (and FNAL) sites while most of the smaller workflows (many of them) were handled by the LCG teams. The reliability of the MC production at the CMS T2s and several T3s in OSG has steadily increased over the years. The performance of the grid middleware has also greatly improved and stabilized over the years due to significant improvement in the operations strategy, monitoring, and timely detection of issues by the site admin(s). The biggest chunk of time in running the production to-date is still spent on the various operations steps in ProdAgent that needs manual intervention by the operators and addressing the various production issues/problems promptly. Effective and prompt communication with the site admins in dealing with site related job failures has resulted in improved production quality and reduced wastage of resource usage consistently over the years. CMS Data Operations (DataOps) CMS has been routinely using most of the T2s (and the 7 T1 sites when available) for MC production over the past years. These resources are divided geographically into several groups of sites (regions attached to a T1 center), each of which is handled by a given production team. Up to 6 production teams (1 team for OSG sites and 5 teams for the LCG sites) have been routinely contributing to the global MC production in CMS. When necessary, a given production team is empowered to quickly install and configure multiple instances of ProdAgents, allowing parallel and faster submission of a large number of jobs, on demand. The standalone MC production group became a subgroup of the newly formed Data Operations group (DataOps) that took shape in early 2007. The MC production task within the DataOps group has since then been managed by two L3 level managers. Due to the excellent contribution, productivity, performance, and demonstrated capability of the OSG production team based at UW Madison, Ajit Mohapatra (UW) was appointed as one of the L3 manager/coordinator in 2008 and has been serving in that position for last 3.5 years. His responsibilities include the supervision of the 6 production teams (alongwith the 2nd coordinator), the coordination of the global CMS MC production, timely delivery, and all other relevant DataOps activity. Under the leadership of Ajit Mohapatra, every effort has been made to maximize the utilization of all available computing resources at sites in a consistent manner over time. As a result, over the years, the usage of total batch slots in OSG and LCG for MC production has gone up to 30K (includes the T1/T2 and some T3s) as shown in Fig.1. The number of events produced in the US/OSG has increased systematically over the years for past 6 years, as shown in Fig. 2. The significant jump in statistics in 2008 (from 2007) is primarily due to implementation of the bulk job submission mechanism and chain processing algorithm of multi-tier workflows in ProdAgent alongwith other operational improvements. This has enabled the DataOps group to produce and deliver the MC samples to the CMS user community in a timely manner for the past 3.5 years, and it continues today while CMS is actively taking collision data for the past 1.5 years. Future MC Production System – WMAgent The ProdAgent system has performed very well for past 3.5 years within it’s design goal and limitations. This is being replaced by the new CMS workload management system called the WMAgent which is currently being used for MC/data processing at the T1 sites. It is in the final phase of deployment/evaluation for MC production. It comes with more features than what ProdAgent was capable of and is built on years of operational experience with ProdAgent and is expected to significantly address the bottlenecks that was inherent to the ProdAgent system and improve the operational productivity. Figure 1: Snapshot of Simultaneous Running of MC Production Jobs at the OSG and LCG Sites (mostly T1s and T2s, and a few T3s) during May 2011. Figure 2: MC Production Statistics in the OSG for the past 6 years.