Checking a Theory - Winona State University
advertisement

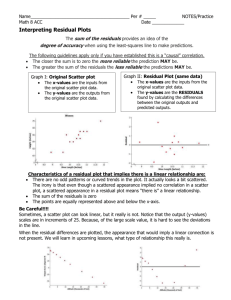
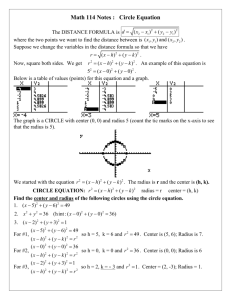
Handout #4: Checking a Theory Example 4.1: Consider the following subset of the variables from the Wisconsin Diagnostic Breast Cancer dataset that is commonly used by those studying machine learning. Original Source: W.N. Street, W.H. Wolberg and O.L. Mangasarian Nuclear feature extraction for breast tumor diagnosis. IS&T/SPIE 1993 International Symposium on Electronic Imaging: Science and Technology, volume 1905, pages 861-870, San Jose, CA, 1993. Snip-it of the dataset Benign (Non-cancerous) Malignant (Cancerous) Methods for Estimating Area Using Radius Using Perimeter 𝐴𝑟𝑒𝑎 = 𝜋 ∗ 𝑅𝑎𝑑𝑖𝑢𝑠 2 𝑃𝑒𝑟𝑖𝑚𝑒𝑡𝑒𝑟 = 2𝜋 ∗ 𝑅𝑎𝑑𝑖𝑢𝑠 1 Distribution of Area | Radius Consider the following plot that shows the relationship between cell area and radius. Understanding the Mean Function Use the relationship between Area and Radius of a circle to fit the following mean function to this data. 𝐸(𝐴𝑟𝑒𝑎 | 𝑅𝑎𝑑𝑖𝑢𝑠) = 𝜋 ∗ 𝑅𝑎𝑑𝑖𝑢𝑠 2 Software packages vary on their ability to fit a specified form for a mean function. For example, JMP has the ability to fit specific forms for linear functions, but not necessarily other types. One possible method to fitting this mean function is to simply create a new variable and use Formula editor. 2 In the Formula editor window, you can obtain the estimated mean function as follows. Click OK after the formula has been entered correctly. Each data value should have an Estimated Area | Radius value. Questions 1. The pattern in the plot above appears to have some curvature (i.e. the anticipated increase in area is not constant for all radius values). Does the mean function 𝐸(𝐴𝑟𝑒𝑎 | 𝑅𝑎𝑑𝑖𝑢𝑠) = 𝜋 ∗ 𝑅𝑎𝑑𝑖𝑢𝑠 2 allow for such curvature? Explain. 3 2. [Math Stuff] Obtain the first derivative of the mean function with respect to radius. That is, find 𝑑 𝐸(𝐴𝑟𝑒𝑎 𝑑 𝑅𝑎𝑑𝑖𝑢𝑠 | 𝑅𝑎𝑑𝑖𝑢𝑠). Is this derivative a function of radius? What does this imply about the rate of change in the specified mean function? 3. The Radius value for the 1st cell in our dataset is 17.99. Verify the calculation done in JMP for the Estimated Area | Radius for this 1st observation. To plot the mean function along with the data on the same graph in JMP, select Graph > Overlay Plot. We are conditioning on Radius, so place this variable on the x-axis. Place the actual data values (i.e. Area) and the estimated mean function (i.e. Estimated Area | Radius) in the Y box. This is shown here. 4 The following is a plot of Area | Radius with the estimated mean function created in JMP. Questions 4. Does this model appear to fit this data well? Discuss. 5. Do you anticipate the R2 value to be large (near 1) or small (near 0 for this fit? Explain your reasoning. [Hint: Has this model reduced the unexplained variation in cell area?] 5 Investigating the Residuals Next, we will consider the residuals from the above estimated mean function. Once again, JMP can be used to easily obtain the estimated residuals for each data point in your dataset. Create a new column in JMP called Residual. Use the formula editor to obtain the residual value for each data point. The output is displayed here. Recall, that the total unexplained variation in the conditional distribution is the sum of the squared residuals. Thus, I obtained a Residual Squared column so that these values can be easily summed up. 𝑇𝑜𝑡𝑎𝑙 𝑈𝑛𝑒𝑥𝑝𝑙𝑎𝑖𝑒𝑛𝑑 𝑉𝑎𝑟𝑖𝑎𝑡𝑖𝑜𝑛 = ∑ 𝑅𝑒𝑠𝑖𝑑𝑢𝑎𝑙𝑠 2 I added a Residual Squared column in JMP. 6 Next, let’s compute the coefficient of determination for our model. Step #1: Obtain Total Unexplained Variation in Marginal Distribution Step #2: Obtain the Total Unexplained Variation in o the conditional distribution of Area | Radius, o while using an estimated mean function of the form 𝐸̂ (𝐴𝑟𝑒𝑎 | 𝑅𝑎𝑑𝑖𝑢𝑠) = 𝜋 ∗ 𝑅𝑎𝑑𝑖𝑢𝑠 2 Comment: The Uncorrected SS value in JMP (shown here) is calculated as follows. This implies that obtaining the Residual2 column in JMP for the sole purpose of summing the values was not necessary. Instead, the Uncorrected SS value from the Residual column would have been sufficient. ∑ 𝐷𝑎𝑡𝑎 𝑉𝑎𝑙𝑢𝑒 2 Step #3: Compute the R2 value. 7 Questions 6. Does the computed R2 value agree with what you stated for Question 5 above? Discuss. 7. On the following plot, visually show how the total unexplained variation in marginal distribution and conditional distribution is computed. Marginal Distribution Conditional Distribution of Area | Radius (ignoring Radius) 8. The R2 value depends on the mean function being used. In particular, some mean functions are better than others. a. Explain how one might obtain an even better mean function that would result in an even larger R2 value. b. What might be a disadvantage to using your mean function instead of the one used here? c. If the notation that a cell tends to be circular in shape is wrong, would we expect the R2 to be lower or higher? Explain. 8 Investigating the Residuals, Part II This dataset included a variable called type in which the cell was identified as either being Benign (noncancerous) or Malignant (Cancerous). Of interest here is to investigate the mean function conditional on Radius AND Type. If both benign and malignant cells are circular in shape, then the conditional mean function will not depend on Type and is given by the quantity. 𝐸(𝐴𝑟𝑒𝑎 | 𝑅𝑎𝑑𝑖𝑢𝑠, 𝑇𝑦𝑝𝑒) = 𝜋 ∗ 𝑅𝑎𝑑𝑖𝑢𝑠 2 Likewise, the residuals would be computed exactly as above. 𝑅𝑒𝑠𝑖𝑑𝑢𝑎𝑙 = (𝐴𝑟𝑒𝑎 − 𝐸̂ (𝐴𝑟𝑒𝑎|𝑅𝑎𝑑𝑖𝑢𝑠, 𝑇𝑦𝑝𝑒)) In an effort to investigate how well the estimated mean function is doing for each Type, we will compute the R2 value for each Type separately here. Step #1: Obtain Total Unexplained Variation in Marginal Distribution Step #1a: If we want to compute the R2 separately for each Type, we need to determine the appropriate amount of Total Unexplained Variation in the Marginal Distribution for each Type. I have obtained these values and provided them here. o o Type = Benign: 19593769 Type = Malignant: 50749370 9 Step #2: Obtain the Total Unexplained Variation in o the conditional distribution of Area | Radius, Type o while using an estimated mean function of the form 𝐸̂ (𝐴𝑟𝑒𝑎 | 𝑅𝑎𝑑𝑖𝑢𝑠, 𝑇𝑦𝑝𝑒) = 𝜋 ∗ 𝑅𝑎𝑑𝑖𝑢𝑠 2 Type = Benign R2 = (19593769 – 48152.19) / 19593769 = 0.9975 Type = Malignant R2 = (50749370 – 142341.85) / 50749370 = 0.9972 Questions 9. Does the estimated mean function appear to fit both types of cells fairly well? Discuss. 10 Investigating the Variance Functions Next, we will consider the variability in the residuals as a function of Radius. That is, how do cells vary in area as a function of Radius? In an effort to keep the residuals on the same scale as the data, the |Residual| values are being displayed in the plot below. Legend: Benign : Red; Malignant : Blue Questions 10. Discuss some of the similarities and/or differences in the estimated variance functions between the two types of cells. 11. Most of the red dots (Benign) dots are near the left side of this plot, what does this imply about these cells? 12. Fill in the blank: If the cell radius is larger than __________, then a cell is likely to be malignant. Explain how you arrived at this value. 13. Is it true that cells whose |Residual| value is larger than 20 are likely to be malignant? Discuss. 11 Comparing |Residual| for the each Type The most straight-forward and direct comparison of the distribution of |Residual| for the two types of cells is a comparison of the respective density funcitons. Questions 14. What information is gained regarding the distribution of |Residual| from this plot? 15. How might this plot permit us to better classify cells as either Benign or Malignant? Discuss. [Comment: STAT 415: Multivariate Statistics discusses classification in much more detail.] 12 Comment: There is one last concern with the residuals that we have not considered, and that is the fact that our estimated mean function appears to be over-estimating the actual cell area. This pattern has been masked as the squared or absolute residuals have been used up to this point. The following graph clearly shows this over estimation as a function of the radius for each type of cell. Questions 16. How could this graph be used to improve the estimated mean function? Discuss. 17. Propose a better mean function. 𝐸(𝐴𝑟𝑒𝑎 | 𝑅𝑎𝑑𝑖𝑢𝑠) = 18. Would your answer above depend on the Type of cell? Should your method of making improvements depend on the cell type? If so, propose a better model conditional on Radius and Type. 𝐸(𝐴𝑟𝑒𝑎 | 𝑅𝑎𝑑𝑖𝑢𝑠, 𝑇𝑦𝑝𝑒: 𝐵𝑒𝑛𝑖𝑔𝑛) = 𝐸(𝐴𝑟𝑒𝑎 | 𝑅𝑎𝑑𝑖𝑢𝑠, 𝑇𝑦𝑝𝑒: 𝑀𝑎𝑙𝑖𝑔𝑛𝑎𝑛𝑡) = 13 Distribution of Area | Perimeter Next, we will investigate the ability of the perimeter to provide a reasonable estimate for cell area. Methods for Estimating Area Using Radius Using Perimeter 𝐴𝑟𝑒𝑎 = 𝜋 ∗ 𝑅𝑎𝑑𝑖𝑢𝑠 2 𝑃𝑒𝑟𝑖𝑚𝑒𝑡𝑒𝑟 = 2𝜋 ∗ 𝑅𝑎𝑑𝑖𝑢𝑠 Recall, the estimated mean function conditional on Radius had the form. 𝐸(𝐴𝑟𝑒𝑎 | 𝑅𝑎𝑑𝑖𝑢𝑠) = 𝜋 ∗ 𝑅𝑎𝑑𝑖𝑢𝑠 2 Question 1. [Math Stuff]: Consider the mean function given above. Rewrite this equation to obtain the estimated mean function for cell area conditional on perimeter instead of radius. Once again, JMP can be used to obtain the estimated mean function for each value in the dataset. 14 An overlay of this plot is given here. Notice that the estimated mean function based on perimeter clearly over-estimates cell area. The obvious over-estimation is very apparent when looking at the residuals from this fit as a function of perimeter. Comment: We will not consider the conditional distribution of Area | Perimeter using this stated mean function any further due the inadequacies of this model. 15 Example 4.2: John Keynes, one of the founders of modern macroeconomics and some say one of the most influential economists of the 20th century, proposed a very simple mathematical function for the relationship between personal income and consumption. Many now believe this function over simplifies the relationship too much. 𝐸(𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛| 𝐼𝑛𝑐𝑜𝑚𝑒) = 𝑐0 + 𝑐1 ∗ 𝐼𝑛𝑐𝑜𝑚𝑒 where 𝑐0 = autonomous consumption 𝑐1 = marginal propensity to consume (a.k.a MPC) Additional discussions regarding this function are given in the following Wiki entry. Wiki Entry for Consumption Function http://en.wikipedia.org/wiki/Consumption_function In an effort to empirically investigation this consumption function, I have collected data from Table 679 (Excel version) of the National Data Book. Source: 2012 Statistical Abstract, United States Census Bureau. Personal disposable income, Personal consumption, and several other variables are included in this dataset from 1929 up until 2010. All measurements are per capita and the units of measurement 16 are chained (2005) dollars. The chained dollars are used to equalize the differences of the purchasing power of the dollar over time. The government typically makes such adjustments when presenting economic data. A snip-it of this data is provided here and the entire dataset is given on our website, called Consumption US. Distribution of Consumption | Income A scatterplot of consumption as a function of income is shown first. We can see that aside from a few discrepancies, the relationship between consumption and income is fairly linear. 17 Next, we will add the y=x line to this graph. This can be done in JMP by first plotting the conditional distribution of Consumption | Income using Analyze > Fit Y by X. Once the graph has been obtained, you can select Fit Special from the drop-down menu. To plot the y=x line on the graph, constrain the intercept to be zero and the slope to be 1. This is shown here. Questions Consider again the consumption function proposed by Keynes. 𝐸(𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛| 𝐼𝑛𝑐𝑜𝑚𝑒) = 𝑐0 + 𝑐1 ∗ 𝐼𝑛𝑐𝑜𝑚𝑒 1. Rewrite this mean function under the assumption that the y-intercept = 0 and the slope = 1. 2. If the y-intercept is set to zero, then 𝑐0 = autonomous consumption would be equal to zero. What is the practical interpretation of this constraint? From a macroeconomic perspective, is this a reasonable assumption to make? 18 3. If the slope is set to 1, then 𝑐1 = marginal propensity to consume is equal to 1. Is this a reasonable assumption? Again, from a macroeconomic perspective is this reasonable? 4. Suppose your friend, who happened to recently fail Econ 202: Macroeconomics, believes the marginal propensity to consume should be close to zero. a. What is the practical interpretation of this restriction? b. If the marginal propensity to consume were zero, what pattern or trend would we expect for the mean function in the conditional distribution of Consumption | Income? Discuss. The scatterplot of Consumption | Income with the mean function 𝐸(𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛| 𝐼𝑛𝑐𝑜𝑚𝑒) = 𝐼𝑛𝑐𝑜𝑚𝑒 (i.e. y=x line) added. 19 Questions 5. Does a mean function of the form 𝐸̂ (𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛| 𝐼𝑛𝑐𝑜𝑚𝑒) = 𝐼𝑛𝑐𝑜𝑚𝑒 seem reasonable for this data? Discuss. 6. The data values appear to get further away from the y=x line as disposable personal income increases. What does this imply about the marginal propensity to consume? Does this empirical evidence agree with the following statement made by Kenyes, "… as income increases, consumption increases but not by as much as the increase in income."? Explain. Once again, the mean function and the corresponding residuals can easily be constructed via new variables in JMP. Mean Function: 𝐸̂ (𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛| 𝐼𝑛𝑐𝑜𝑚𝑒) = 𝐼𝑛𝑐𝑜𝑚𝑒 Residual: 𝑅𝑒𝑠𝑖𝑑𝑢𝑎𝑙 = (𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑖𝑜𝑛 − 𝐸̂ (𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛| 𝐼𝑛𝑐𝑜𝑚𝑒)) 20 Recall from the plot above, that the y=x line over-estimated actual consumption. This over-estimate results in most residuals being negative. In the following graph, these negative residuals are displayed as a function of disposable income. The discrepancies in the pattern in the above plot, may more easily be understood by considering a plot of the residuals as a function of year. Comment: The growth in disposable personal income is closely related to year. Thus, a plot that considers the residuals vs. year is reasonable to consider. 21 Questions 7. In these residual plots, there is a general decreasing trend. What does this imply about our mean function and the relationship between Consumption and Income? Discuss. 8. There is a substantial dip in the residuals near 1940. What does this imply about the relationship between consumption and income during this time? What major event was taking place in the United States (and the rest of the world) during this time? 9. After the current recession hit, many put blame on individuals that financially over-extended themselves (i.e. consumed beyond their means). Generally speaking, are people consuming (i.e. spending) more or less of their income now days compared to our parents and our grandparents? Discuss. 10. What has happened to consumption since the latest recession hit the United States in 2008? 22 Aside: Marginal Distribution of the Proportion of Consumption to Income John Keynes proposed that people within an economy only spend a certain proportion of their income and this is the purpose of the marginal propensity to consume constant in the proposed consumption function. This notation was supported in the residual plots as well. 𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛 𝑃𝑟𝑜𝑝𝑜𝑟𝑡𝑖𝑜𝑛 = 𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛 𝐷𝑖𝑠𝑝𝑜𝑠𝑎𝑏𝑙𝑒 𝐼𝑛𝑐𝑜𝑚𝑒 Marginal Distribution of Consumption Proportion Comments The average consumption proportion is about 0.90 or 90% with a standard deviation of about 0.04 or 4%. From the histogram, we can see that most often the consumption proportion is between 85% and 100%. There were some years in which the consumption proportion fell below 80% (i.e. I assume the years of World War II). This marginal distribution certainly does not ignore disposable income; however, it is difficult to see how this proportion is changing as a function of disposable income. 23 Distribution of Consumption | Income with Unconstrained Mean Function The conditional distribution of Consumption | Income is again considered here, but an unconstrained mean function will be fit to the observed data. That is, consider once at the consumption function proposed by Keynes. 𝐸(𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛| 𝐼𝑛𝑐𝑜𝑚𝑒) = 𝑐0 + 𝑐1 ∗ 𝐼𝑛𝑐𝑜𝑚𝑒 The following is a scatterplot of the original data with the unconstrained estimated mean function. The y=x line is shown as well for reference. Questions 11. What is the slope and y-intercept of the estimated mean function? a. Slope: __________________________ b. Y-Intercept: ______________________ 24 12. Give a mathematical description of the y-intercept and slope. a. Slope: b. Y-Intercept: 13. Give an economical description of the y-intercept and slope using the appropriate language (i.e. autonomous consumption and marginal propensity to consume). a. Slope: b. Y-Intercept: The unconstrained linear mean function can be obtained easily in JMP, simply select Fit Line from the graph’s drop down menu in JMP. 25 The predicated values and the residuals can be saved into your dataset by selecting these quantities from the drop-down menu for the fit. This is shown here. The mathematical representation of the predicted values and the residuals are provided here. 𝐸̂ (𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛|𝐼𝑛𝑐𝑜𝑚𝑒) = −391 + 0.93 ∗ 𝐼𝑛𝑐𝑜𝑚𝑒 𝑅𝑒𝑠𝑖𝑑𝑢𝑎𝑙 = (𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛 − 𝐸̂ (𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛 |𝐼𝑛𝑐𝑜𝑚𝑒)) The additional columns provided by JMP are shown here. Verify the following mathematical calculations for at least one year. 𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑 𝑉𝑎𝑙𝑢𝑒 = 𝐸̂ (𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛 |𝐼𝑛𝑐𝑜𝑚𝑒 = ______________) = −391 + 0.93 ∗ _____________ = 26 𝑅𝑒𝑠𝑖𝑑𝑎𝑢𝑙 = (𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛 − 𝐸̂ (𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛 |𝐼𝑛𝑐𝑜𝑚𝑒)) = ( ) − = Computing the R2 Value for the Consumption Function Next, we will compute the R2 value under the following conditions: Conditional Distribution: Consumption | Income Estimated Mean Function: Marginal Distribution Conditional Distribution using the estimated mean function 𝐸̂ (𝐶𝑜𝑛𝑠𝑢𝑚𝑝𝑡𝑖𝑜𝑛|𝐼𝑛𝑐𝑜𝑚𝑒) = −391 + 0.93 ∗ 𝐼𝑛𝑐𝑜𝑚𝑒 (ingoreing income) 𝑅2 = ( − ) = = 27 JMP automatically provides summaries for the fit of the estimated mean function. A partial listing of these summaries is provided here. Identify the following terms from this output. Sum of Squares for C. Total: Sum of Squares for Error: Sum of Squares for Model: R Square: Estimate for Intercept: Estimate for Disposable Personal Income: Mean of Response 28 Investigating the Residuals and Variance Function The first plot simple displays the residuals from our fit as a function of time. This plot consders the |Residuals| as a function of time. A kernal smoother (i.e. lowess curve) can be used to understand how the varibiity changes as a funciton of time. Notice the varition (i.e. volitiity) in the relationship between Consumption and Income has steadily increased since the mid 1990s or so. 29