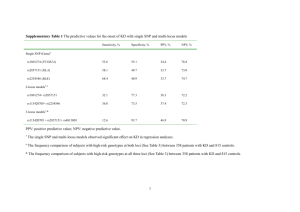
S1 Text - Figshare
advertisement

Text S1 Detailed description of BayesR Priors The Bayesian approach requires the assignment of prior distributions to all unknowns in the model. The population mean μ, was assigned an uninformative uniform prior density. We used the same four-distribution mixture of the SNP effects as Erbe et al. [1] The mixing proportions π = (p 1, ¼, p K ) are given a symmetric Dirichlet prior i.e. p (p 1, ¼, p 4 ) ~ D (d , ¼, d ) , with δ=1. Note that Erbe et al. [1] assigned a known value to the variance of all SNP effects (s g2 ), whereas here s g2 is informed from the data. The prior for s g2 is chosen to be of a scaled inverse - c 2 distribution, Inv - c 2 ( v0 ,S02 ) with known hyperparameters v0 and S02 . A scaled inverse - c 2 distribution was also assumed for s e2 . We used flat priors for the hyperparameters for both variances (vo = -2 and S02 = 0). Gibbs sampling On the basis of the prior specification, Gibbs sampling was used to generate samples from the posterior distributions of the parameters (using |. to denote conditioned on the data and all other parameters). The Gibbs sampler proceeds as follows: 1. Sample the overall mean from the full conditional posterior distribution æ n è i=1 æ p ö s e2 ö ÷ ø n ø m | . ~ N ç n -1 å ç yi - åxij b j ÷ , è j=1 2. Calculate the probability that SNP j is in distribution k. The likelihood of SNP j being in component k is: n 2 ö 1 æ n 2 1 LogL ( j, k ) = log (p k ) - 2 ç åyi - m j,k å xij yi ÷ - logV, ø 2 2s e è i=1 i=1 ( ) where yi is the phenotype of individual i corrected for the overall mean and the effects of all markers in the model, except marker j. p æ ö yi = ç yi - m - åxil bl ÷ è ø l¹ j and m jk = å å n x y i i=1 ij n 2 2 e i=1 ij x + s / s k2 logV is the likelihood of the reduced model including only the effect of SNP j and an residual effect: æ s k2 n 2 ö logV = n log (s ) + log ç 2 å xij +1÷ .Then the probability of SNP j being in ès ø 2 e e i=1 distribution k is K ( ) Pr x jÎk = 1/ å exp éë L ( i,l ) - L ( i, k ) ùû . l=1 Based on a value sampled from a uninform distribution assign component k to SNP j. 3. Sample the regression coefficient for SNP j from mixture component k from the full conditional posterior distribution. b jk | . ~ N ( m jk , Sk2 ) , where S = 2 k å s e2 n 2 i=1 ij x + s e2 / s k2 and m jk as above. 4. Repeat step 2 and 3 for SNP j+1,..,p. 5. Sample s g2 from the full conditional posterior distribution: p æ m b 2 + vo S02 ö å g j=1 j 2 2 ÷, s g | . ~ Inv - c ç v0 + mg , v0 + mg çè ÷ø where mg is the number of SNPs included in the current model. 6. Sample s e2 from the full conditional posterior distribution: ( n p æ åi=1 yi - m - å j=1 xij b j 2 2ç s e | . ~ Inv - c v0 + n, ç vo + n çè ) + v S ö÷ 2 7. Update the mixing proportion by sampling from the posterior: p | . ~ Dirichlet ( m1 + d , m2 + d ,m3 + d , m4 + d ) , where m1,…m4 are the number of markers in each distribution. 7. Compute new s k2 of the mixture components ì p ´ 0 ´ s 2 1 g ï ïï p 2 ´ 10 -4 ´ s g2 2 sk ~ í . -3 2 ï p 3 ´ 10 ´ s g ï -2 2 ïî p 4 ´ 10 ´ s g 2 o 0 ÷ ÷ø 8. Randomly permute the order of SNPs to provide global moves and to increase mixing. Computational efficiency gain Updating maker effects requires the computations of yi at step 2 of the algorithm. For example, for sampling the jth marker effect, it is considerably more efficient to p æ ö compute yi = ç yi - m - åxil bl ÷ in the form of yi = e i + xij b j . If the e i are stored then è ø l¹ j xij b j can be added to the residual for use in sampling the new marker effect b j , and once this is done the new residual is available by subtraction of the updated xij b j from yi (e.g., e i = yi - xij b j ). MCMC implementation For all analyses the Markov chain was run for 50,000 cycles with the first 20,000 samples discarded as burn-in. Posterior estimates of parameters are based on 3,000 samples drawing every 10th sample after burn in. Posterior analysis from the MCMC output After having generated samples from the posterior distributions model parameters are estimated by the sample means of their posterior probabilities respectively. Estimates of m, π, b , s g2 ,s e2 are averages over different regression models drawn conditional on different model vectors, known as “Bayesian model averaging”. The posterior inclusion probability (PIP), defined as the proportion of iterations that included a specific marker in the model, was used as a measure of the ability of the model to identify associated SNPs. Predictions Based on SNP effect estimates obtained from the training population phenotypes of the validation sample were predicted as: ŷi = m + å w b̂ jÎb j >0 ij ( j ) ( ) where b̂ j is the estimated effect of SNP j, wij = xij - 2 p j / 2 p j 1- p j and xij is the number of copies of the reference allele (0,1,2) at SNP j for individual i with pj being the frequency of the reference allele in the training population. 1. Erbe M, Hayes BJ, Matukumalli LK, Goswami S, Bowman PJ, et al. (2012) Improving accuracy of genomic predictions within and between dairy cattle breeds with imputed high-density single nucleotide polymorphism panels. J Dairy Sci 95: 4114-4129.