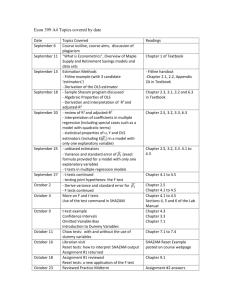
Ad 2.

Introduction
Please think about the below issues in the following terms:
1.
What is this? How can we describe this feature?
2.
Why do we care about it? What are the consequences of having this particular feature in the model? Why having it is bad?
3.
How to detect it? What statistical tests are applied?
4.
What is the remedy?
By analogy to a doctor visit:
1.
How can we describe this disease?
2.
Why do we care about this particular disease? Why leaving a patient uncured is dangerous?
What will be the consequences?
3.
How to detect a particular disease? What medical tests are applied?
4.
How to cure a patient? What medicament to apply?
To be honest:
Nonstationarity and autocorrelation and are most serious. Collinearity and influential observations are also serious. We will survive when heterscedascity or nonnormality occurs (especially in large samples).
Nonstationarity
This is a main reason why I reject models. When you model using time series this should be the first issue to check.
Ad 1. Expected value and/or variance and/ or autocorrelation function is nonconstant.
A special case of being nonstationary: having an unit root (more or less being a random walk).
In practice: when we plot time series plot for this variable, it has trends.
A.No relation but trends:
15
10
5
0
-5
35
30
25
20
1 2 3 4 5 6 7 8 9
Ряд1
Ряд2
25
20
15
10
5
B.Trends with relation:
30
Ряд1
Ряд2
0
1 2 3 4 5 6 7 8 9
Ad 2.
When we have nonstationary variables and build a model using them with OLS then OLS will show by t-statistics that explained variables are significant just because of trends not because of relations between variables (I can explain beer production in Poland by number of car accidents in India – probably both have upward trends and regression will be significant, but there is no relation between them). OLS t-statistics is not robust to nonstationarity. We risk spurious regression. OLS tstatistics cannot distinguish between A and B (plots). In both cases there will be significant parameters.
Ad3.
ADF test. H0: time series is not stationary (bad)
Ad 4.
Either cointegration analysis or differentiate time series and use OLS to differentiated time series
(differentiate until stationarity is applied).
Example in gretl: greene-> interest rate
Collinearity
Ad 1.
Explanatory variables (we focus only on Xs, Y is to some extend unimportant here) are correlated, collinear with each other. We may explain one of them by the rest.
Ad 2. a) When interpreting the model we want to say sentences like “when x_i increses by 1 then y increases by a_i ceteris paribus”. But when variables are correlated then change of x_i will happen simultaneously with change of x_j and/or x_k etc. So we cannot say ceteris paribus.
We cannot interpret parameters correctly. b) When variables are collinear then we have high standard errors of parameters. Recall tstatistics: t=a_i/S_i. If S_i (standard error) is high then t_i is small. If t_i is small then this variable is insignificant. Often it will be so that all variables will be insignificant using tstatistics. But F statistics of jointly significance will show that these variables are significant.
So t-student and F will give opposite conclusions (we are confused). c) Model will be unstable – deleting one or a few observations (not necessary influential measured by leverage h) will cause significant changes of parameters.
Ad3.
VIF
Ad 4.
Generally no good remedies. Sometimes when time series are nonstationary then colinearity will also occur. Differentiating of time series will help. Otherwise we may try to drop sequentially variables with highest VIf (with caution).
Example: gretl -> Longley. Estimate a model (employment explained by remaining variables), calculate vifs, calculate leverage, drop last observation, reestimate the model, compare the results.
Heteroscedascity
Ad 1. Nonconstant variance of the error term in time or space.
6
5
4
A.
Small variance
Small variane
3 Ряд1
2
1
0
0 0,5 1
B. High variance
1,5 2 2,5
If we had a choice: which points A or B we want to use for estimation, we would say A. However B is not so bad – they are more dispersed but they also form a line. OLS will approximate fit good parameters. How to apply a fact that A is better than B? Answer: apply weights. A – small weight, B – large weight.
OLS: ∑_e 2 _i -> min. Weighted OLS: : ∑_w_i*e 2 _i -> min. W_i would be large for A and small for B.
Ad 2. OLS is unbiased but inefficient. There are other techniques (weighted OLS) which have higher precision. Standard errors from OLS (used in t-statistics) may be misleading.
Ad. 3 White test. H0: no heteroscedascity (good).
Ad 4. Weighted OLS
Example in gretl:
Greene-> micro expenditure.
Use only observations with “expend>0” : menu-> sample-> restrict based on criterion : expend >0.
Plot expend vs. income.
See that the higher the income the higher the variance of expenditures.
Menu -> model -> other linear -> heteroscedascity corrected.
Press help for description how the weights are calculated. Explain expend by remaining variables
(but drop accept). Plot residuals vs income.
Normality of the error term.
Ad 1. Obvious. Residuals do not have normal distribution.
Ad 2. Statistical tests (t, F) in small samples are based on normality of e_i (in large samples – they are based on central limit theorem). So nonnormality distorts inference based on these tests.
Ad 3. Jarque-Berra test (or any other for normality). H0: normality (good).
Ad 4. Not much. Sometimes transformation of dependent variable helps (for example taking logs).
Increase number of observations (limited value of this hint).
8
6
4
2
-10
-12
-6
-8
0
-2
0
-4
Autocorrelation
Second reason why I reject models. Should be checked right after nonstationarity.
Ad 1.
Residuals (error terms) from different moments of time are correlated, they ‘influence’ each other.
We will mostly focus on correlation of order 1 i.e correlation between error terms in consecutive moments t, t-1: Corr(e_t, e e_{t-1}) is not equal to zero.
When we plot residuals against time we will see upward or downward trends (corr>0, more common) or strong oscillations around zero (corr<0, less common).
Corr>0
5 10 15 20 25
Ряд1
Corr<0:
1,5
1
0,5
0
0
-0,5
-1
5 10 15 20 25
Ряд1
-1,5 corr=0 (no autocorrelation, totally random sequence without any structure)
0,6
0,4
0,2
0
0
-0,2
5 10 15 20 25
Ряд1
-0,4
-0,6
Ad 2.
Autocorrelation as such tells nothing apart of violating assumptions of OLS. It is just a symptom of something else – something very serious.
C) is most common a) Relation between variables was nonlinear and we fitted a linear model.
Relation:
15000
10000
5000
0
0 5
-5000
Residuals (corr>0):
4000
10 15 20
2000
0
0 5 10 15 20
-2000 b) There was a seasonality in the data and we neglected it.
Relation:
80
60
40
20
0
0 10 y = 1,9394x + 2,1304
20 30 40
Residuals(corr>0 or corr<0 depending on the frequency):
10
5
Ряд1 0
-5
0
-10
10 20 30 40
c) There was an important explanatory variable that should be in the model, but we did not include it in the model.
C) is most common
Ad 3.
Durbin Watson test (DW): H0: no autocorrelation (good).
Or any other test for autocorrelation. DW cannot be applied when lagged explained variable is used.
Ad4. a) If there was a nonlinear relation – add nonlinearities (squares, logs) – no good guidelines what to choose b) Model seasonality. Simplest approach: add dummy variables for seasons. c) Those “important variables” are usually “lags (not logs) of variables that are in the model
(lags of explanatory variables or explained variables)
General to specific approach: build large model, with many variables, with many lags and then try do sequentially drop variables that are insignificant (F test for linear restrictions of join insignificance of last, k-th lag, then (k-1)th lag, etc until we achieve significant lag), use information criteria (AIC, BIC etc). Try not to leave gaps in lags (like 1,3,4-th lag. Where is 2?)
Example:
Verbeek: “Introduction to modern econometrics”, icecream dataset. http://www.econ.kuleuven.ac.be/gme/
Explain icecream consumption by remaining variables. Check autocorrelation. Add lagged temperature. Check for autocorrelation again.
Perform general to specific approach.