Exporting and importing records using Linux commands
advertisement

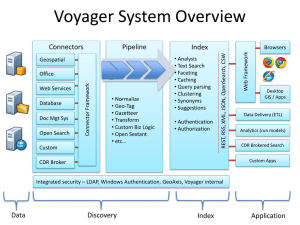
EXPORTING AND IMPORTING RECORDS USING LINUX COMMANDS 11/10/11spg, rev. 2/3/16 Prefer to work on the server when loading very large files of records--say 10,000 or so--which sometimes are too much for WebAdmin to handle. The three CTW libraries share the /m1/voyager/tmp workspace for bulk importing records. While you can run multiple jobs in succession if the data does not overlap, when importing records it’s probably best to do them in succession. If you wish to do them all at once, include the element “ -M” in the command line (see below) to allow multiple jobs in case case CC or TC jobs are running. Space jobs at least a minute apart in order to get separate log files; if run in closer succession the reports appear in the same log file (which is okay, it’s just harder to read). If a job seems not to have started within a reasonable time, ask the Systems Librarian to check what’s going on. Sometimes the process gets stuck due to a large job ahead of yours. She can remove that job file to allow yours to run. Doing so does not inhibit the completion of the previous job. Avoid spaces in file names. Use an underline (_) or run the letters together. If you want to preserve the original file name on your PC or the H drive, wait till a copy of the file is in the ftp client and change it there. Avoid upper-case letters except where specified To edit a command line use left and right arrow keys to move the cursor. To delete character-by-character use backspace. To copy/cut/paste use right-click. It’s okay to use the mouse to highlight text to be edited or deleted Relevant Linux commands are listed at the end of this document. There are many Unix/Linus cheat sheets on the web (search unix linus reference), e.g.: http://fosswire.com/post/2007/08/unixlinux-command-cheat-sheet/ http://www.computerhope.com/unix.htm http://www.scottklarr.com/topic/115/linux-unix-cheat-sheets---the-ultimate-collection/ (takes awhile to load) EXPORTING To date we have done this in WebAdmin only. If needed, ask the Systems Librarian how to do it. IMPORTING Importing is a two-step process. First you transfer the file to the server via ftp, then import it into Voyager. You must have two clients on your PC: SSH Secure File Transfer and SSH Secure Shell Client. If you don’t have them, contact ITS. You can work in either client but these guidelines assume the File Transfer client. Within File Transfer Client you need to create two profiles: a) ftp to Voyager (to tranfer files to the server) b) Voyager (to import records using Linux commands) For instructions see VOYAGER SERVER CONNECTION SETTINGS in the Cataloging folder. DELETING We typically use BibDelete, Location Changer, or Pick and Scan to delete records. It can also be done in WebAdmin but we haven’t tried that yet. For very large numbers of records perform the work on the server. You cannot delete records with item records (or POs, but we wouldn’t want to delete those anyway), so the first thing to do is delete the items. Compile a text file of item IDs to be deleted and use Location Changer or Pick and Scan to delete them. Do not also choose Delete empty holdings as that has an immediate impact on the index. Deleting bibs + MFHDs is a little tricky, so ask the Systems Librarian to do it if needed. First, create a text file of bib IDs. Use that file to export “interleaved” bibs + MFHDs using WebAdmin or on the server. On the server, import them with a command to delete MFHDs ( -r) and bibs ( -x). I. Import files to server via FTP Open the SSH Secure File Transfer Client. (You needn’t open the other client as you can do everything within this one.) Click Profile: Exporting and importing records using Linux commands -- p. 2 Choose: Password: ftp to Voyager [see chart] The left and right panes both show the “voyager” folder on the server. (If you don’t see this click the Home icon and scroll down to the voyager folder.) If you click on a folder on the left it will show the files it contains on the right. Or just doubleclick the folder on the right. If you don’t have one already, create a folder on the Voyager server into which you will transfer the files. In the right pane right-click and choose New Folder, name it, and save. Your folder name should be all lower-case and no spaces. If you prepend it with an identifier such as your name it will keep them all together, e.g. sallyeeboeets or sallyebrary Open the folder. On the menu bar click the up arrow icon to see your C drive (or wherever the file is located on your PC or the H drive). Select the desired file or files (within a folder you can select more than one. Click the Upload button on the lower right to transfer the file(s) to the server: Files are transferred in no particular order In addition to your files, another file called “nohup.out” may be created (see below). It refers to “no hangup, meaning that the process will continue to run even if you exit ftp. A nohup.out file may not be created if someone is running something active on the server, but that’s okay because your activity will be appended to the other When done you see your file(s) in the folder. Make sure that all expected files appear in full. This is a good time to rename them if needed (see “Avoid,” above) II. Import files to Voyager On the server, folders are called “directories.” Without leaving the previous window click Profile to connect to the Voyager server: Choose: Password: voyager [same as ftp to Voyager] Response: VGER] voyager@ctw : voyager/ => At this point you are in the voyager directory. Start typing immediately following $ or > and hit Enter after each command: tcsh (allows the use of the up arrow to move back through lines, and also the “bang” symbol (!) to execute a previous command line) cd <directory> to the desired directory, e.g. cd sallyreadexserialset (see below for more cd commands) Response: VGER] voyager@ctw : sallyreadexserialset/ => ls (list the files and directories in the current directory, to make sure they’re there and are the ones you mean to load) Exporting and importing records using Linux commands -- p. 3 Response (this directory has two files of records): 52-55.mrc 56-58.mrc nohup.out [may or may not be there] As in WebAdmin you need to indicate -M (allow running multiple bulk imports), the file name (-f), the bulk import rule (-i), and the operator ID(-o). By default, records will not be indexed until the next index regen, which is useful for very large files. (Records can still be found via Headings and Left-Anchored searches.) To index immediately, add -KADDKEY. Specify nohup at the beginning (“no hangup,” i.e. you can close the process on your PC but it will continue to run on the Voyager server). An easy way to create a command is to copy an existing one then edit it. Copy this line: /usr/bin/nohup /m1/voyager/wesdb/sbin/Pbulkimport -M -ffile name -ibulk import rule -ooperator ID -KADDKEY Paste it right here (when done loading, delete the line from this space so it is blank for the next time): Edit it to include file name, bulk import rule, and operator ID. If immediate indexing is not wanted leave off -KADDKEY, e.g.: /usr/bin/nohup /m1/voyager/wesdb/sbin/Pbulkimport -M -ffile3no2.mrc -iEB0350 -oEBSCO It’s okay to leave the bold/colored characters as is. Copy and paste your edited line into the command line using rightclick and Paste. Hit Enter. Only a portion of the command may appear, but that’s okay: Response: Sending output to nohup.out or, appending output to nohup.out There is no message when the process is done. Enter “ps -u” as described below and/or see Section III on checking the log.imp file. If desired, enter the following command to see if the process is running: ps -u USER PID %CPU %MEM VSZ RSS TTY STAT START voyager 2698 16.2 0.3 211712 39608 pts/2 S 16:53 /m1/voyager/bin/2008.2.0/bulkimport -d VGER -u wesdb/Cwesdb -fmsplit0.mrc -i voyager 10290 0.0 0.0 10480 2068 pts/3 Ss+ 16:34 voyager 15274 0.0 0.0 10224 1876 pts/2 Ss 15:43 voyager 19280 0.0 0.0 15848 1952 pts/2 S 15:43 voyager 19353 0.0 0.0 10476 912 pts/2 R+ 16:59 TIME COMMAND 1:00 -c /m1/voyager/wesdb/ini/voyager.ini 0:00 0:00 0:00 0:00 -ksh -ksh -csh ps -u It should look something like the above. Watch for error messages, however ignore this one: Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.7/FAQ If you are running more than one job at at time (not recommended) you will see them all: USER PID %CPU %MEM VSZ RSS TTY STAT START voyager 2698 13.3 0.5 241484 69452 pts/2 S 16:53 /m1/voyager/bin/2008.2.0/bulkimport -d VGER -u wesdb/Cwesdb -fmsplit0.mrc -i voyager 3478 8.9 0.1 190732 20160 pts/2 S 17:07 /m1/voyager/bin/2008.2.0/bulkimport -d VGER -u wesdb/Cwesdb -fmsplit1.mrc -i voyager 8370 9.0 0.1 189684 19356 pts/2 S 17:08 /m1/voyager/bin/2008.2.0/bulkimport -d VGER -u wesdb/Cwesdb -fmsplit2.mrc -i voyager 15274 0.0 0.0 10224 1876 pts/2 Ss 15:43 voyager 19280 0.0 0.0 15848 1952 pts/2 S 15:43 voyager 25122 0.0 0.0 10476 920 pts/2 R+ 17:09 TIME COMMAND 2:11 -c /m1/voyager/wesdb/ini/voyager.ini 0:08 -c /m1/voyager/wesdb/ini/voyager.ini 0:06 -c /m1/voyager/wesdb/ini/voyager.ini 0:00 -ksh 0:00 -csh 0:00 ps -u Exporting and importing records using Linux commands -- p. 4 A large file can take a long time to run. Enter ps -u as often as you wish to see the if the job is progressing (note the time in the area labeled R+). For more detail check the log.imp file (see section III below). Other commands that might be useful (see also SFTP2 Commands under Help): cd (change directory): Move up one directory in the hierarchy: cd Go to a directory within the current directory: cd sallyreadexserialset Now sallyreadexserialset is the current directory Change to another directory within the voyager/local directory (type the entire path or use “..” to indicate the current path): cd /m1/wesdb/voyager/local/sallyeebostc or cd ../sallyeebostc Now sallyeebostc is the current directory ls <full path> to list the files/directories in another directory without first changing to it (type the entire path or use “..” to indicate the current path): ls /m1/wesdb/voyager/local/sallyeebostc or ls ../sallyeebostc Now sallyeebostc is the current directory pwd (shows the current working directory) history (see a list of commands used so far) Response: 1 2 3 4 5 cd sallyreadexserialset ls /usr/bin/nohup /m1/voyager/wesdb/sbin/Pbulkimport -f52-55.mrc -iETEXT035 -oSERSET -X NOKEY ps history !6 (repeat a previous action based on line number) kill <process ID> e.g. kill 27227 (kill a process; if you’ve mistakenly repeated the same bulk import, kill the bulkimpo with the higher process ID) III. Check the log.imp file [If your job did not complete see “If a job does not complete,” in the box below.] When importing on the server there is no message that a job has completed nor will you receive an email. But you can check the log.imp file: Method 1 -- view the log.imp file in WebAdmin Find the log.imp file based on date. If there are no record counts at the bottom the load is not yet finished. When you have initiated an import from the server you apparently cannot click the refresh icon to watch the progress. If you do click it you’ll get an error message and won’t be able to open the file again. Use one of the two following methods. Exporting and importing records using Linux commands -- p. 5 Method 2 -- view the log.imp file in Notepad++ 1. Open the program Notepad++. On the right side, connect with the Voyager server by clicking the "Show NppFTP window" icon on the menu, then the connect icon in the NppFTP window, then Voyager: 2. If set up with an initial destination you will go to this screen immediately. If not, follow the path and it will show up each time you log in: /m1/voyager/wesdb 3. In the “rpt” folder are the recent Voyager reports created. Scroll down to the log.imp files. The files are in date order. If you don’t see any files for your date, go back to “rpt” and click the refresh icon. Double-click what you think might be your file to view it in the left pane of the application. If it’s not your file, try another. When you’ve opened the right file check for record counts at the bottom. If none the job is still running. To view its progress, double-click on the file name, repeating as needed. Note: When importing EOCRs or Bibnotes on the server the log.imp and other report files are in ucat/rpt instead of rpt. Exporting and importing records using Linux commands -- p. 6 Method 3 -- view the log.imp file by adding a command line in the process you are running: Enter command: more nohup.out It will give you the process ID, for example 14119 Use that ID to enter this command: ps –ef |grep 14119* The output is as follows. Take note of the log.imp file name (here shown in bold): voyager 9111 1 0 15:27 pts/0 00:00:00 ksh /tmp/Pdobulkimport.20160201.1527.14888 voyager 23092 31978 0 15:48 pts/1 00:00:00 grep 8918 Enter this command, pasting in the file name, to continually watch the output: tail –f /m1/voyager/wesdb/rpt/log.imp. 20160201.1527.14888 If you tire of watching the output, Ctrl-C to get out of the logfile If you see this the job is completed: tail: cannot open `20160201.1527.14888' for reading: No such file or directory tail: no files remaining For more info about log.imp files see POST-LOAD CHECKS. If a job does not complete. The main reason for this happening is that your job was still running at the time Voyager reset itself in the early morning. You’ll a popup message on your screen saying saying the process halted. In the log.imp file, note the record position number (not the record number itself) of the last completed action. Import the file once again but set “Begin with” to the next record number. You can reload in WebAdmin if the complete file not too big (maybe 5,000 records or less). Otherwise, do it on the server. Use the same command as before but add <space>b#### where #### is the record position umber, e.g.: /usr/bin/nohup /m1/voyager/wesdb/sbin/Pbulkimport -M -fmsplit1.mrc -iEB0350 -oEBSCO -b20382 IV. Retain or delete ftp folders/files In the FTP client you can delete files and folders when done but it is not necessary, especially folders you might use again. ------------------------------------------------------------------ Exporting and importing records using Linux commands -- p. 7 These parameters govern the bulk import program and are pulled from the Voyager 8.2 Technical User’s Guide, chapter 13. You can also see available commands when on the server by typing /m1/voyager/wesdb/sbin/Pbulkimport –help [space, hyphen, help] -f Filename -- required. The filename containing the records you are importing. The default location of the file is the /m1/voyager/xxxdb/sbin directory. If the file is in a different directory, use the complete path. -i Import code -- required. The Bulk Import Rule code. This is the code specified in the Code field, located on the Rule Name tab in the Cataloging - Bulk Import Rules section in the System Administration module. It instructs the system to use the Bulk Import Rule associated with the code specified and follow all of the rules defined therein. This is also where you specify whether all loaded records should be suppressed from the OPAC and whether MARC holdings (MFHDs) and Voyager item records should automatically be created. MFHDs may be in different locations. If the profile you select performs duplicate detection, note that if any single index listed in the duplication hierarchy in System Administration matches with more than 1000 records in the database, all duplicate detection will stop. Only the first 100 records above the matching threshold will be returned to the client. There is no limit to the number of indexes that can be put in the hierarchy to check. However, this will hurt the accuracy of the matching being performed. Also if the profile that you select has no indexes selected, the records are added unconditionally to the database. See Bulk Import Rules in the Voyager System Administration User’s Guide for more information. -o Operator name -- not required. The name of the operator importing the records. This information is recorded and used in Voyager to identify who last modified the record. -l Location Code -- not required. The code for the cataloging happening location (as defined in System Administration module) that will be used in Voyager to identify the location from which the record was last modified. -b Begin record -- not required. The first record in the file to be imported. For example, specifying the number 5 would instruct the program to begin importing from the fifth record in the file. This parameter is used with the -e parameter when importing fewer records than the entire file. -e End record -- not required. The last record in the file to be imported. For example, specifying the number 10 would instruct the program to stop importing after the tenth imported record. This parameter is used with the -b parameter when importing fewer records than the entire file. -m Load MFHDs -- not required. Must have interleaved file. Load MFHDs with bibliographic records from a single interleaved bib-MFHD file. -a MFHD location code -- not required. Must have interleaved file. After the -a parameter enter a location code, for example -aCIRC. Then for all incoming MFHDs, the location code listed will be used in the MFHDs 852 field, subfield b. The location codes are defined in the Locations section of System Administration. The location code must match the code in System Administration exactly (it is case sensitive). Therefore, if you use -aCIRC, as an example, the MFHDs will have the location CIRC. If used in conjuction with the -m parameter, it will act as a match point, and add a new MFHD with the location specified. -r Delete MFHDs -- not required. Use this variable to delete specified MFHDs from your database. The import file must be an interleaved file of bibliographic records and MFHDs. You cannot import a file of just MFHD records in an attempt to delete matching MFHDs from the database. First, the incoming bibliographic records are matched with the bibliographic records on the database. For all matching bibliographic records, holdings records Exporting and importing records using Linux commands -- p. 8 in the database with the same location code as the holdings records in the incoming file will be deleted. (The variable does not import records.) NOTE: You cannot delete records that are linked to an item record or purchase order. -x Delete bibliographic records -- not required. This option is used only with Delete MFHDs (-r). To delete bibliographic records, both -x and -r should be entered as part of the same Pbulkimport command. Use this variable to delete bibliographic records in your database that match the records in the data file. The import file must be an interleaved file of bibliographic records and MFHDs. This option does not import records. Records are only deleted from the database. The records in the file are matched with the records in the database. This means that the location in the record in the data file must match the owning library of the bibliographic record in the database. If any of the matching bibliographic records in the database do not have any MFHDs attached to them (after having been deleted using the -r command), the bibliographic record in the database will be deleted. If the import file contains only bibliographic records, it will delete those matching bibliographic records in the database if there is no linked MFHD and if the record is not linked to a purchase order. This option is generally used by Universal Catalog databases to allow the local libraries to create files containing any records that they have suppressed or deleted from their database so that they can be removed from the Universal Catalog database as well. For more information see the Voyager Universal Catalog User’s Guide. -k OK to export -- not required. Use this variable to select the OK to export check box on the System tab of bibliographic, authority, and holdings records on view in the Cataloging module. The date on which each MARC record was last marked OK to export displays in the Cataloging module, History tab of the record on view in the Cataloging module. -K ADDKEY Generate keyword index -- not required. This parameter and argument causes the records to be indexed. -h Help -- not required. This parameter provides online help about the Pbulkimport function. This flag cannot be used with any other parameters. -p Add Copy Number For New Item Records -- not required. This parameter specifies a single copy number to all newly created item records when it is used by itself. A number from 0 through 99999 (up to five places) may be specified consistent with the Cataloging client. NOTE: If -p is not used the copy number defaults to zero. -M Allow multiple bulk import processes -- not required but strongly suggested. Use the -M parameter to specify your intention to run multiple concurrent bulkimport sessions. This can be done safely if there is no data overlap between runs. ! IMPORTANT: Using -M assumes that you have confirmed that there is no data overlap that might be an issue for the multiple concurrent bulkimport sessions you are running with -M. When -M is not specified as a parameter for Pbulkimport, the Pbulkimport script checks for a running bulkimport process for the current database. If it finds a running bulkimport process it terminates and displays a message indicating that there is a bulkimport process that is already running.