The CATMA microarray - URGV
advertisement

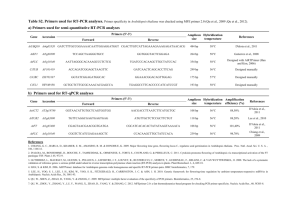
UMR INRA 116 -UEVE-ERLCNRS 8196 General information on transcriptome experiments with the “Complete Arabidopsis Transcriptome Microarray” CATMAv7 Validate by S. Balzergue date: XX.XX.XX General informations and conditions The CATMA microarray is available through collaborations between the URGV and other laboratories. The partner needs to send a request to Sandrine BALZERGUE (URGV) via email (balzerg@evry.inra.fr). The microarray production, and labelling and hybridizations of the samples will be performed by the URGV team (Transcriptome Group). The URGV provides the know-how in this collaboration but has no specific funding for that purpose. Thus the consumables costs (280€ TF/hybridization) will be paid by the partner. Specific tools for transcriptome analysis, including specific statistical methods are available at the URGV. As soon as the analyses are performed, an Excel file contains transcriptomic results will be sent to collaborator. Raw files can be sent to collaborator on request. Then the transcriptome results will be integrated in the database developed at the URGV: CATdb (MIAME compliant: Brazma et al., 2001. Nat Genet. 29(4):365-71). The data are also transferred in GeOmnibus (NCBI). Be careful if you do not plan to publish all data at the same time, fill 2 different files to get two accession numbers (if needed contact us for more information.). Be careful if you do not plan to publish all data at the same time, fill 2 different files for two accession numbers (if needed contact us for more information.) The data will be released for public access one year after the end of the project and their introduction into the databases. Nevertheless, there are exceptions that will be discussed before the beginning of each project: 1) if it’s an industrial collaboration 2) if it is within the framework of an ANR / KBBE project and the results are placed in the public one year after the end of the project itself only. 3) if the transcriptomic results has a value for filing patent Note: A quote can be made and sent to collaborator only if requested to Sandrine Balzergue (balzerg@evry.inra.fr). The collaborator must edit a purchase order in the amount specified by this quote and in a delay of 15 days after receipt of samples. Collaborator must send the original order at INRA-URGV, accounting department, 2 rue Gaston Cremieux 91000 Evry. If you want more information, please contact: secretariat@evry.inra.fr The CATMA microarray We developed a new version of the CATMA microarrays based on AGILENT technology (CATMA v7). In this new version, long primers instead of amplified GST are synthesized on the array. We designed the array in order to keep as much as possible the same specificity to Arabidopsis genes and to get (at least) the same coverage than the current version of the CATMA array. A single high density microarray slide contains four chambers, each containing 180000 primers representing all the Arabidopsis genes: 38360 primers corresponding to TAIRv8 annotation (including primers of mitochondrial and chloroplast genes) + around 1200 primers corresponding to EUGENE software predictions. Moreover, we included primers corresponding to reapeat elements, for miRNA/MIR, and for other RNAs (rRNA,tRNA, snRNA, soRNA) and finally 36 controls. Forward primer is triplicate in each chamber for robust analysis and Reverse UMR INRA 116 -UEVE-ERLCNRS 8196 General information on transcriptome experiments with the “Complete Arabidopsis Transcriptome Microarray” CATMAv7 Validate by S. Balzergue date: XX.XX.XX sense primers are also available on a support.. With this new CATMA array, we can perform more hybridizations at a same time, on a more stable support than the previous “in house spotted” array and at slightly lower cost. A normalization and statistical analysis method has been developed specifically for CATMAv7 by M.L. Martin-Magniette in collaboration with the 'Statistique et Génome' team from the unit UMR INRA/AgroParisTech MIA 518, Paris, France Sample preparation The labelling process includes an in-vitro transcription step (T7 pol.) so the RNA purity is the most critical factor of the success. Therefore the RNA have to be extracted with a column extraction kit (such as RNeasy for example with DNAseI step) . The samples will be controlled on the Agilent bioanalyzer at the URGV. Generally, 4µg of total RNA per sample are sufficient for running the experiment. If “difficult” samples, such as seeds for example, have to be used, please contact us for extra precautions. Repetitions Biological repetitions: At least two independant biological replicates are necessary. Technical repetitions : We perform systematically one dye-swap per biological replicate: Ex: - slide1: Control Cy3 – Treatment Cy5 - slide 2 : treatment Cy3 – Control Cy5 Procedure The protocols are available at : http://www-urgv.versailles.inra.fr/microarray/protocols.htm Summary of the protocol : - Checking of the total RNA (Bioanalyser Agilent). - Two-Color Microarray-Based Gene Expression Analysis Low Input Quick Amp Labeling (Agilent) - Washing and drying of the slides. - Scanning with constant PMT (photomultiplicators): the data normalization is performed at the statistical analysis step. After the statistical analysis the gene lists contain the log2 normalized intensities per samples, the log2 normalized ratios, and the p-values (FDR correction) which provide the threshold for the identification of the differentially expressed genes. Publication of the results In this scientific collaboration the URGV provides the know-how and expertise in transcriptome analysis including statistics, and advices in experimental design if necessary.. Only the costs of the chemicals are paid by the partner. For this reason at least one member of our team will be co-author of the first paper reporting these transcriptome results. The same convention will UMR INRA 116 -UEVE-ERLCNRS 8196 General information on transcriptome experiments with the “Complete Arabidopsis Transcriptome Microarray” CATMAv7 Validate by S. Balzergue date: XX.XX.XX be applied to the filing of Patent on the initiative of the collaborator and in which the transcriptome results will be used. Document to send with the request We need a short document containing : 1 – PROJECT TITLE 2 – Name and address of the partner 4 – description the project (briefly) 5 – Experimental design 6 – Number of slides, samples description (organ, harvesting stage according to Boyes et al. Plant Cell 2001, treatment…) 7 – Expected date of sample shipping _______________________