(DOC), written by Gillian Santorelli (talks) and Isabelle Smith
advertisement
, written by Gillian Santorelli (talks) and Isabelle Smith")
Summary of Planning Cluster RCTs: Sample Size and ICCs presentation by
Sandra Eldridge
(Summary written by Gillian Santorelli, Leeds Institute of Clinical Trials Research, University of Leeds)
A cluster trial randomly allocated subjects as a group to either intervention or control arm.
They are often used to assess, for example, health education, guidelines and management
protocols. Trials involving general practices are often clustered; other examples include
communities, hospitals and school classes. Whilst reasons for using cluster randomisation
include possible contamination between intervention and control patients or same medical
staff treating all patients in a cluster, the main reasons tend to be due to logistics and cost,
and because the intervention itself takes place at cluster level.
Members of a cluster will be more similar to each other than a random sample of subjects,
for example they are more likely to be of a similar background, have chosen to belong to a
cluster, or are treated by the same health professionals. The implications of this type of
design are that the usual statistical assumptions of independence of participants does not
hold, so sample size calculations and analysis needs to account for the clustering design.
The effect that clustering has on sample size is that more participants are required to detect
the same difference. Loss of power is greater when there are a large number of patients per
cluster or when there is large variability between clusters. The effect of clustering can be
calculated using the Intracluster correlation coefficient (ICC), which is the variation between
clusters divided by the total variance. The ICC is applied to the sample size calculation to
account for the design effect. Estimating the ICC for the primary outcome can be
problematic, either because of sampling error (the width of the 95% confidence intervals is
wider for smaller numbers of clusters) or because no-one else has used the outcome in
question previously.
The ICC increases as the size of natural cluster decreases, and ICCs are generally larger for
process than for clinical outcomes. Where the outcome is binary, ICC decreases as
prevalence moves away from 50%. More efficient analysis can be used to correctly estimate
the ICC.
The number of clusters needed decreases as the cluster size decreases. Where cluster
sizes are variable, it is necessary to account for this using the coefficient of variation (cv),
although there is no need to use adjustment if the cv<0.23. The cv can be estimated by
using the range from expected minimum and maximum cluster sizes, by dividing the
standard deviation of the range by 4, by dividing the standard deviation by the mean, or
based on knowledge of clusters.
NB: a course based on the recently published book, A Practical Guide to Cluster
Randomised Trials in Health Services Research by Sandra Eldridge and Sally Kerry is
available to attend from 30 June 2014 to 4 July 2014 (split into two parts: Introductory
followed by advanced). Registration closes 23 June 2014. More details at:
http://eshop.qmul.ac.uk/browse/extra_info.asp?compid=1&modid=2&catid=1&prodid=433
Summary of Sample size by simulation presentation by Richard Hooper
(Summary written by Gillian Santorelli, Leeds Institute of Clinical Trials Research, University of Leeds)
Sample size calculation by simulation is a technique used in complex interventions to
introduce variance components and other nuisance parameters in order to reflect the
diversity of real populations.
Calculating power for a given sample size using simulation can easily be performed using
the Heuristic search algorithm in the ‘simsam’ command in Stata. ‘simsam’ calculates
sample size to achieve given power for any analysis under any model that can be
programmed in Stata.
Cluster randomised trials with time-to-event outcomes can be analysed using frailty models,
where each cluster has e.g. a gamma-distributed frailty. Frailty models are available in Stata
for Cox regression and parametric survival regression.
Simulation forces the analyst to confront certain issues:
1. When the analysis fails to produce a result. For example, when failure to converge
occurs when using stcox in Stata, leading to an error message; this is particularly
common with frailty analyses of CRTs. The simplest solution is to treat this (or any
other error) as a non-significant result. However, a better solution is to have a prespecified analysis plan for how to manage failure to converge.
2. What is the true Type I error rate. ‘simsam’ has an option to simulate “power” under
the null hypothesis, at the selected sample size. However, the true Type I error rate
is not always the same as the nominal Type I error rate. The general advice with
cluster-randomised trials is to ensure there are at least 40 clusters, and that the
cluster size is not too small and not variable.
To conclude, simulation offers an extremely versatile approach to determining sample size
or other design characteristics to achieve a given power; it provides a transparent solution
with is straightforward to validate; it can keep up with increasing complexity in trial design; it
forces you to think about the analysis in detail, and it allows you to evaluate other properties
of the chosen design/analysis.
Case Studies
(All summaries written by Isabelle Smith (i.l.smith@leeds.ac.uk) Leeds Institute of Clinical Trials
Research, University of Leeds)
Case Study 1: Optimal phase II Bryant and Day designs – a troublesome
example
Duncan Wilson (D.T.Wilson@leeds.ac.uk), Leeds Institute of Clinical Trials
Research, University of Leeds
This case study presentation began by providing some background to both a specific phase
II surgical trial and the proposed trial design methodology, that of Bryant and Day
(1995). The key points for consideration in the calculation of the sample size for the TAMIS
trial are as follows:
Efficacy (response) - Circumferential resection margin (CRM) positivity
CRM positivity rate > 25% deemed unacceptable
Expect around 5-15%
‘Response’=’non-CRM positivity’
Parameters - 𝑝𝑟0 = 0.75, 𝑝𝑟1 ∈ [0.85, 0.95]
Safety (toxicity) – Morbidity rate
Morbidity rate > 50% deemed unacceptable
Expect around 30-40%
Parameters - 𝑝𝑡0 = 0.5, 𝑝𝑡1 ∈ [0.6, 0.7]
Error rates
𝛼𝑟 = 𝛼𝑡 = 0.1
𝛽 ∈ {0.1, 0.2}
The Bryant and Day phase II design is a two stage design for two binary end points (efficacy
and safety). The null and alternative hypotheses for each endpoint, together with the desired
type I and type II error rates should be specified. For each of the two stages in this design, a
sample size is required in addition to a threshold value for efficacy and a threshold value for
safety. As the parameters for the TAMIS trial did not correspond to any of the 30 problems
considered in the original paper, the ‘Early Phase Clinical Trials’ software was used to find
the best design.
On closer inspection of the suggested designs, some unintuitive behaviour was noticed.
After further (manual) investigations it became clear that the software used had somehow
managed to ignore the error rate constraints, with the suggested trial designs often
underpowered.
In order to address this problem, a quick ‘local search’ optimisation algorithm, which used a
simple iterative heuristic to repeatedly improve upon an initial trial design, was written in R.
This algorithm worked well, in that it ran quickly, produced consistent results, and identified
designs which respected error rate constraints. The procedure consists of very simple code
and it is very flexible (eg we can changed the way we measure the size of the trial from
‘optimal’ to ‘minimax’).
In conclusion, it should be noted that published papers describing trial design methodology
provide only half the solution, as we still need to find a design that best satisfies the
proposed criteria. Where external software is used for this task, results should be
scrutinised. This is particularly true of closed software with little or no documentation, where
locating the source of any error will be difficult or impossible.
Case Study 2: ALPHA - Adaptive trial design with interim analysis to review
sample size
Isabelle Smith (i.l.smith@leeds.ac.uk) Leeds Institute of Clinical Trials Research,
University of Leeds
The ALPHA trial is a multi-centre, open, prospective, parallel group, adaptive RCT in
patients with chronic sever hand eczema. The primary objective of the study is to compare
Alitretinoin and Psolaren combined with UltraViolet A (PUVA) as first line therapy in terms of
disease activity at 12 weeks post randomisation. A number of tools were considered as the
primary outcome measure but we decided to use the Hand Eczema Severity Index (HECSI),
and to use the other tools as secondary outcome measures (for comparison with other
studies).
The existing data available for the HECSI in similar trials indicated that it tends to be
positively skewed so we have based our sample size on the log transformed scale and are
hence looking for a clinically significant fold change (1.3) in HECSI score. However, the data
available are very limited; therefore we have calculated the minimum and maximum sample
size (table 1) based on available data and we have planned an interim analysis after a
sufficient number of patients have been recruited in order to review the estimate of the
coefficient of variation used in the sample size calculation with an acceptable level of
precision. The sample size calculation for the interim analysis assumes a mean HECSI
score of 28, s.d. of 33.9 and thus a coefficient of variation (CV) of 1.2; by looking at the
confidence intervals around the CV we calculated that in order to obtain an estimate with
12.5% relative precision we require 364 patients.
Table 1: Minimum and maximum sample sizes
Minimum
Maximum
Fold change of 1.3
80% power
2 sided 5% significance level
Coefficient of variation (CV)=1.175
(s.d.=33.9, mean=28.85)
20% drop out rate
=500 patients
Fold change of 1.3
80% power
2 sided 5% significance level
Coefficient of variation (CV)=1.7
(s.d.=33.9, mean=20.3)
20% drop out rate
=780 patients
Case Study 3: Sample size calculation in surgical trials
Neil Corrigan (N.Corrigan@leeds.ac.uk) Leeds Institute of Clinical Trials Research,
University of Leeds
Within surgical RCTs patient outcomes are clustered within surgeon, patients are
randomised individually (stratified by surgeon) and so each surgeon performs both
interventions. However in a recent literature review, a large proportion of surgical trials do
not account for this clustering in their analysis and so they probably didn’t account for it in
their sample size calculations either which means the ‘surgeon effect’ is commonly not
accounted for (according to the recent literature review).
The current literature suggests that the naïve sample size calculation is too large. We know
apriori that we are going to adjust for the surgeon effect at analysis and, just like when you
adjust for any other important covariate that is associated with the outcome measure, this
will again yield a gain in power (i.e. a smaller sample size is required).
The current guidance is to consider a multi-level model with a random intercept for each
surgeon (i.e. each surgeon has their own intercept but all surgeons share a common slope):
𝑌 = 𝛽0 + 𝛽1 𝑋1𝑖𝑗 + 𝑢0𝑗 + 𝜖𝑖𝑗 , 𝐻0 : 𝛽1 = 0
This decreases the sample size requirement by a factor of (1 − 𝜌), 𝜌 = 𝐼𝐶𝐶
However, each surgeon may have varying degrees of skill and so it may be worth
considering a model with a random intercept and a random slope:
𝑌 = 𝛽0 + (𝛽1 + 𝑢𝑖𝑗 )𝑋1𝑖𝑗 + 𝑢0𝑗 + 𝜖𝑖𝑗 , 𝐻0 : 𝛽1 = 0
This model leads to a sample size inflation factor ≤ (1 + (𝑚 − 1)𝜌) where 𝑚=number of
patients per surgeon, and 𝜌 = 𝐼𝐶𝐶
By considering the latter we are ensuring that, in addition to powering for the most basic
unadjusted analysis which appropriately addresses the primary research question, we are
also ensuring that more comprehensive, adjusted analyses will also be sufficiently powered.
Case Study 4: Interim analysis of a musculoskeletal randomised cluster trial
Dan Green (d.j.green@keele.ac.uk), Keele University
The POST trial (Primary care Osteoarthritic Screening Tool) is a cluster randomised trial
designed to look at whether treating depressive symptoms leads to improved
musculoskeletal outcomes, as these often coincide. The screening tool used in the control
arm consists of a consultation question on pain intensity, whilst the intervention arm had the
consultation question on pain intensity and four further questions related to anxiety and
depression. It is logical to randomise at the practice level as there is potential of
confounding/bias is randomised at the GP/doctor level (ie contamination) and it is not
possible to randomise at the patient level.
There were 49 practices available for the study, with an average cluster size (m) of 30. The
ICC’s in Primary Care are often lower than 0.05, however, they are difficult to predict. For
example, a knee pain study reported an ICC of 0.014 but an ICC of 0.03 is consistent with
the literature (but is open to debate!). So, a variety of ICC’s were considered for varying
effect sizes, and given the number of available practices it was decided that an ICC of 0.03
should be used as a starting point as this requires 44 practices with an average cluster size
of 33 (table 2). To note, a dropout rate of 25% was assumed throughout the sample size
calculations.
Table 2: Number of practices (cluster size) required
Effect Size
ICC
0.01
0.02
0.03
0.04
0.05
0.1
121 (90) 148 (111) 175 (131) 202 (150) 229 (171)
0.2
31 (23)
37 (28)
44 (33)
51 (38)
58 (43)
0.3
14 (10)
17 (13)
20 (15)
23 (17)
26 (19)
An interim analysis, in order to review the ICC estimate, was planned after 2 blocks (13
practices). An analysis was conducted for three months’ worth of data for all primary and
secondary endpoints, and the ICC was calculated for each analysis. The ICC was less than
0.0025 for all analyses and therefore, the original ICC of 0.03 was too high. We considered
an ICC of 0.015 and with the current sample size the study had more than 95% more which
led to effect size of 1.5 instead of 2.0.
The study team decided not to reduce the sample size in order to allow for any additional
drop out, and the discussion within the YSS meeting also concluded that this was an
appropriate decision to make as the ICC at the end of the trial could have been higher than
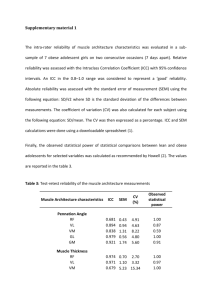
observed at the interim analysis.